|
|
||
|---|---|---|
| .. | ||
| intro-to-pipelines | ||
| nyc-taxi-data-regression-model-building | ||
| parallel-run | ||
| README.md | ||
| aml-pipelines-concept.png | ||
{kind=link}
README.md
Azure Machine Learning Pipeline
Overview
The Azure Machine Learning Pipelines enables data scientists to create and manage multiple simple and complex workflows concurrently. A typical pipeline would have multiple tasks to prepare data, train, deploy and evaluate models. Individual steps in the pipeline can make use of diverse compute options (for example: CPU for data preparation and GPU for training) and languages.
The Python-based Azure Machine Learning Pipeline SDK provides interfaces to work with Azure Machine Learning Pipelines. To get started quickly, the SDK includes imperative constructs for sequencing and parallelization of steps. With the use of declarative data dependencies, optimized execution of the tasks can be achieved. The SDK can be easily used from Jupyter Notebook or any other preferred IDE. The SDK includes a framework of pre-built modules for common tasks such as data transfer and compute provisioning.
Data management and reuse across pipelines and pipeline runs is simplified using named and strictly versioned data sources and named inputs and outputs for processing tasks. Pipelines enable collaboration across teams of data scientists by recording all intermediate tasks and data.
Learn more about how to create your first machine learning pipeline.
Why build pipelines?
With pipelines, you can optimize your workflow with simplicity, speed, portability, and reuse. When building pipelines with Azure Machine Learning, you can focus on what you know best — machine learning — rather than infrastructure.
Using distinct steps makes it possible to rerun only the steps you need as you tweak and test your workflow. Once the pipeline is designed, there is often more fine-tuning around the training loop of the pipeline. When you rerun a pipeline, the execution jumps to the steps that need to be rerun, such as an updated training script, and skips what hasn't changed. The same paradigm applies to unchanged scripts and metadata.
With Azure Machine Learning, you can use distinct toolkits and frameworks for each step in your pipeline. Azure coordinates between the various compute targets you use so that your intermediate data can be shared with the downstream compute targets easily.
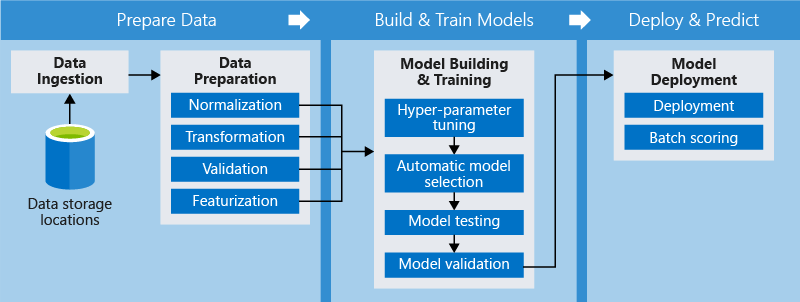
Azure Machine Learning Pipelines Features
Azure Machine Learning Pipelines optimize for simplicity, speed, and efficiency. The following key concepts make it possible for a data scientist to focus on ML rather than infrastructure.
Unattended execution: Schedule a few scripts to run in parallel or in sequence in a reliable and unattended manner. Since data prep and modeling can last days or weeks, you can now focus on other tasks while your pipeline is running.
Mixed and diverse compute: Use multiple pipelines that are reliably coordinated across heterogeneous and scalable computes and storages. Individual pipeline steps can be run on different compute targets, such as HDInsight, GPU Data Science VMs, and Databricks, to make efficient use of available compute options.
Reusability: Pipelines can be templatized for specific scenarios such as retraining and batch scoring. They can be triggered from external systems via simple REST calls.
Tracking and versioning: Instead of manually tracking data and result paths as you iterate, use the pipelines SDK to explicitly name and version your data sources, inputs, and outputs as well as manage scripts and data separately for increased productivity.
Notebooks
In this directory, there are two types of notebooks:
-
The first type of notebooks will introduce you to core Azure Machine Learning Pipelines features. Notebooks in this category are designed to go in sequence; they're all located in the intro-to-pipelines folder.
-
The second type of notebooks illustrate more sophisticated scenarios, and are independent of each other. These notebooks include:
- pipeline-batch-scoring.ipynb: This notebook demonstrates how to run a batch scoring job using Azure Machine Learning pipelines.
- pipeline-style-transfer.ipynb: This notebook demonstrates a multi-step pipeline that uses GPU compute. This sample also showcases how to use conda dependencies using runconfig when using Pipelines.
- nyc-taxi-data-regression-model-building.ipynb: This notebook is an AzureML Pipelines version of the previously published two part sample.
- file-dataset-image-inference-mnist.ipynb: This notebook demonstrates how to use ParallelRunStep to process unstructured data (file dataset).
- tabular-dataset-inference-iris.ipynb: This notebook demonstrates how to use ParallelRunStep to process structured data (tabular dataset).
