diff --git a/tutorial/01_Prepare Train and Test Data.ipynb b/tutorial/01_Prepare Train and Test Data.ipynb
index dc34b83..f7b36fd 100644
--- a/tutorial/01_Prepare Train and Test Data.ipynb
+++ b/tutorial/01_Prepare Train and Test Data.ipynb
@@ -74,10 +74,6 @@
"3. Answers (A): For each Original question and its Duplications, we have found more than one answers have solved that question. In our analysis, we only select the Accepted answer or the answer with the highest score that solved the Original question. Therefore, it's 1-to-1 mapping between Original questions and Answers and many-to-1 mapping between Duplications and Original questions. Each Original question and its Duplications have an unique AnswerId.\n",
"4. Function Words: we consider a list of words that can only be used in between content words in the creation of phrases. This list of words, stored as a .txt file, is also used as Stop Words.\n",
"\n",
- "See the below Data Diagram to illustrate the relationship among Original Questions (Q), Duplications (D) and Answers (A):\n",
- "\n",
- " \n",
- "\n",
"The data schema is:\n",
"\n",
"| Dataset | Column Name | Description\n",
diff --git a/tutorial/02_Phrase Learning, Model Training & Evaluation.ipynb b/tutorial/02_Phrase Learning, Model Training & Evaluation.ipynb
index 9e1376d..30d9328 100644
--- a/tutorial/02_Phrase Learning, Model Training & Evaluation.ipynb
+++ b/tutorial/02_Phrase Learning, Model Training & Evaluation.ipynb
@@ -131,13 +131,13 @@
"source": [
"trainQ_url = 'https://mezsa.blob.core.windows.net/stackoverflownew/trainQ_tutorial.tsv'\n",
"testQ_url = 'https://mezsa.blob.core.windows.net/stackoverflownew/testQ_tutorial.tsv'\n",
- "answersC_url = 'https://mezsa.blob.core.windows.net/stackoverflownew/answersC_tutorial.tsv'\n",
+ "# answersC_url = 'https://mezsa.blob.core.windows.net/stackoverflownew/answersC_tutorial.tsv'\n",
"function_words_url = 'https://mezsa.blob.core.windows.net/stackoverflow/function_words.txt'\n",
"\n",
"# load datasets.\n",
"trainQ = pd.read_csv(trainQ_url, sep='\\t', index_col='Id', encoding='latin1')\n",
"testQ = pd.read_csv(testQ_url, sep='\\t', index_col='Id', encoding='latin1')\n",
- "answersC = pd.read_csv(answersC_url, sep='\\t', index_col='Id', encoding='latin1')\n",
+ "# answersC = pd.read_csv(answersC_url, sep='\\t', index_col='Id', encoding='latin1')\n",
"# Load the list of non-content bearing function words\n",
"functionwordHash = LoadListAsHash(function_words_url)"
]
diff --git a/tutorial/README.md b/tutorial/README.md
new file mode 100644
index 0000000..514b80f
--- /dev/null
+++ b/tutorial/README.md
@@ -0,0 +1,76 @@
+# QnA Matching Tutorial
+
+- [Overview](#overview)
+- [Data](#data)
+- [Description](#description)
+- [Customization](#customization)
+- [Contact](#contact)
+
+## Overview
+
+Question answering systems of specific topics are highly demanded but are not quite available yet. The common use cases we see in this type of scenario include but are not limited to:
+* Live chat support
+* Chat bot
+* Document match - find a subcategory of financial/legal/.. documents that answers a particular question
+
+Therefore, we have provided 2 Notebooks with step-by-step descriptions of how to match the correct answer to a given question. To solve this problem, we train the classification models on a set of pre-canned question-answer pairs and classify a new question to its correct answer class.
+
+
+## Data
+
+We use three sets of data in this series of notebooks. We collect the raw data from the Stack Overflow Database and extract all question-answer pairs related to the __"JavaScript"__ tag. For the question-answer pairs, we consider the following scenarios.
+
+1. Original Questions (Q): These questions have been asked and answered on the Stack Overflow.
+2. Duplications (D): There is a linkage among the questions. Some questions that have already been asked by others are linked to the previous/original questions as Duplications. In the Stack Overflow Database, this kind of linkage is determined by "LINK_TYPE_DUPE = 3". Each original question could have 0 to many duplications, which are considered as semantically equivalent to the original question.
+3. Answers (A): For each Original question and its Duplications, we have found more than one answers have solved that question. In our analysis, we only select the Accepted answer or the answer with the highest score that solved the Original question. Therefore, it's 1-to-1 mapping between Original questions and Answers and many-to-1 mapping between Duplications and Original questions. Each Original question and its Duplications have an unique AnswerId.
+4. Function Words: we consider a list of words that can only be used in between content words in the creation of phrases. This list of words, stored as a .txt file, is also used as Stop Words.
+
+See the below Data Diagram to illustrate the relationship among Original Questions (Q), Duplications (D) and Answers (A):
+
+
\n",
- "\n",
"The data schema is:\n",
"\n",
"| Dataset | Column Name | Description\n",
diff --git a/tutorial/02_Phrase Learning, Model Training & Evaluation.ipynb b/tutorial/02_Phrase Learning, Model Training & Evaluation.ipynb
index 9e1376d..30d9328 100644
--- a/tutorial/02_Phrase Learning, Model Training & Evaluation.ipynb
+++ b/tutorial/02_Phrase Learning, Model Training & Evaluation.ipynb
@@ -131,13 +131,13 @@
"source": [
"trainQ_url = 'https://mezsa.blob.core.windows.net/stackoverflownew/trainQ_tutorial.tsv'\n",
"testQ_url = 'https://mezsa.blob.core.windows.net/stackoverflownew/testQ_tutorial.tsv'\n",
- "answersC_url = 'https://mezsa.blob.core.windows.net/stackoverflownew/answersC_tutorial.tsv'\n",
+ "# answersC_url = 'https://mezsa.blob.core.windows.net/stackoverflownew/answersC_tutorial.tsv'\n",
"function_words_url = 'https://mezsa.blob.core.windows.net/stackoverflow/function_words.txt'\n",
"\n",
"# load datasets.\n",
"trainQ = pd.read_csv(trainQ_url, sep='\\t', index_col='Id', encoding='latin1')\n",
"testQ = pd.read_csv(testQ_url, sep='\\t', index_col='Id', encoding='latin1')\n",
- "answersC = pd.read_csv(answersC_url, sep='\\t', index_col='Id', encoding='latin1')\n",
+ "# answersC = pd.read_csv(answersC_url, sep='\\t', index_col='Id', encoding='latin1')\n",
"# Load the list of non-content bearing function words\n",
"functionwordHash = LoadListAsHash(function_words_url)"
]
diff --git a/tutorial/README.md b/tutorial/README.md
new file mode 100644
index 0000000..514b80f
--- /dev/null
+++ b/tutorial/README.md
@@ -0,0 +1,76 @@
+# QnA Matching Tutorial
+
+- [Overview](#overview)
+- [Data](#data)
+- [Description](#description)
+- [Customization](#customization)
+- [Contact](#contact)
+
+## Overview
+
+Question answering systems of specific topics are highly demanded but are not quite available yet. The common use cases we see in this type of scenario include but are not limited to:
+* Live chat support
+* Chat bot
+* Document match - find a subcategory of financial/legal/.. documents that answers a particular question
+
+Therefore, we have provided 2 Notebooks with step-by-step descriptions of how to match the correct answer to a given question. To solve this problem, we train the classification models on a set of pre-canned question-answer pairs and classify a new question to its correct answer class.
+
+
+## Data
+
+We use three sets of data in this series of notebooks. We collect the raw data from the Stack Overflow Database and extract all question-answer pairs related to the __"JavaScript"__ tag. For the question-answer pairs, we consider the following scenarios.
+
+1. Original Questions (Q): These questions have been asked and answered on the Stack Overflow.
+2. Duplications (D): There is a linkage among the questions. Some questions that have already been asked by others are linked to the previous/original questions as Duplications. In the Stack Overflow Database, this kind of linkage is determined by "LINK_TYPE_DUPE = 3". Each original question could have 0 to many duplications, which are considered as semantically equivalent to the original question.
+3. Answers (A): For each Original question and its Duplications, we have found more than one answers have solved that question. In our analysis, we only select the Accepted answer or the answer with the highest score that solved the Original question. Therefore, it's 1-to-1 mapping between Original questions and Answers and many-to-1 mapping between Duplications and Original questions. Each Original question and its Duplications have an unique AnswerId.
+4. Function Words: we consider a list of words that can only be used in between content words in the creation of phrases. This list of words, stored as a .txt file, is also used as Stop Words.
+
+See the below Data Diagram to illustrate the relationship among Original Questions (Q), Duplications (D) and Answers (A):
+
+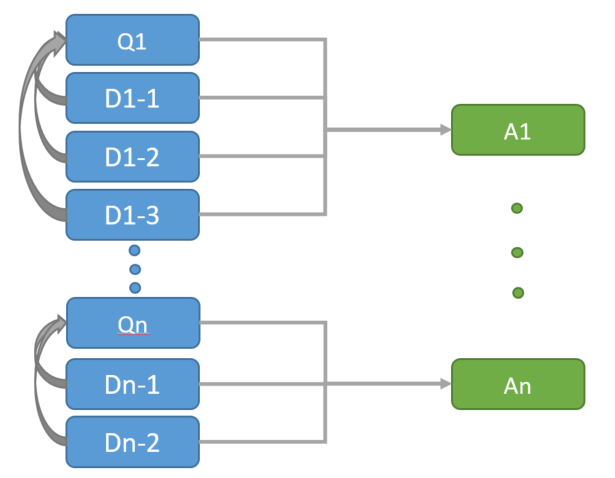 +
+The data schema and download links are available as below:
+
+| Dataset | Column Name | Description
+| ----------|------------|--------
+| [questions](https://mezsa.blob.core.windows.net/stackoverflow/orig-q.tsv.gz) | Id | the unique question ID (primary key)
+| | AnswerId | the unique answer ID per question
+| | Text0 | the raw text data including the question's title and body
+| | CreationDate | the timestamp of when the question has been asked
+| [dupes](https://mezsa.blob.core.windows.net/stackoverflow/dup-q.tsv.gz) | Id | the unique duplication ID (primary key)
+| | AnswerId | the answer ID associated with the duplication
+| | Text0 | the raw text data including the duplication's title and body
+| | CreationDate | the timestamp of when the duplication has been asked
+| [answers](https://mezsa.blob.core.windows.net/stackoverflow/ans.tsv.gz) | Id | the unique answer ID (primary key)
+| | text0 | the raw text data of the answer
+
+To retrieve the data in Python, please find the code in the section _Access sample data_ of the __01_Prepare Train and Test Data__ notebook.
+
+
+## Description
+
+The tutorial include 2 notebooks, which provide working code for each step of our Data Science process.
+
+__01_Prepare Train and Test Data__ shows how to pre-process and prepare the train & test data from these specific datasets.
+
+__02_Phrase Learning, Model Training & Evaluation__ demonstrates the phrase learning, model training and evaluation process.
+
+Note: This notebook series are built under Python 3.5 and NLTK 3.2.2.
+
+
+## Customization
+
+For someone wants to apply this tutorial on your own datasets, you can skip the __01_Prepare Train and Test Data__, prepare your train & test data separately and re-use the code in __02_Phrase Learning, Model Training & Evaluation__.
+
+__02_Phrase Learning, Model Training & Evaluation__ takes two _.tsv_ files (one for training and one for test) as inputs. In order to re-use the code, you need to prepare your train and test data to contain three columns _Id_, _AnswerId_ and _Text_.
+
+* _Id_: represents the unique question ID.
+* _AnswerId_: represents the answer ID that the question belongs to.
+* _Text_: contains the text in your questions.
+
+Once your data is prepared with the above format, you can modify the _trainQ_url_ and _testQ_url_ in the script to the path of your training and test set, respectively. The remaining script should be directly applicable.
+
+
+## Contact
+
+Please feel free to contact Katherine Zhao (mez@microsoft.com) and T.J. Hazen (TJ.Hazen@microsoft.com) with any question or comment.
+
+The data schema and download links are available as below:
+
+| Dataset | Column Name | Description
+| ----------|------------|--------
+| [questions](https://mezsa.blob.core.windows.net/stackoverflow/orig-q.tsv.gz) | Id | the unique question ID (primary key)
+| | AnswerId | the unique answer ID per question
+| | Text0 | the raw text data including the question's title and body
+| | CreationDate | the timestamp of when the question has been asked
+| [dupes](https://mezsa.blob.core.windows.net/stackoverflow/dup-q.tsv.gz) | Id | the unique duplication ID (primary key)
+| | AnswerId | the answer ID associated with the duplication
+| | Text0 | the raw text data including the duplication's title and body
+| | CreationDate | the timestamp of when the duplication has been asked
+| [answers](https://mezsa.blob.core.windows.net/stackoverflow/ans.tsv.gz) | Id | the unique answer ID (primary key)
+| | text0 | the raw text data of the answer
+
+To retrieve the data in Python, please find the code in the section _Access sample data_ of the __01_Prepare Train and Test Data__ notebook.
+
+
+## Description
+
+The tutorial include 2 notebooks, which provide working code for each step of our Data Science process.
+
+__01_Prepare Train and Test Data__ shows how to pre-process and prepare the train & test data from these specific datasets.
+
+__02_Phrase Learning, Model Training & Evaluation__ demonstrates the phrase learning, model training and evaluation process.
+
+Note: This notebook series are built under Python 3.5 and NLTK 3.2.2.
+
+
+## Customization
+
+For someone wants to apply this tutorial on your own datasets, you can skip the __01_Prepare Train and Test Data__, prepare your train & test data separately and re-use the code in __02_Phrase Learning, Model Training & Evaluation__.
+
+__02_Phrase Learning, Model Training & Evaluation__ takes two _.tsv_ files (one for training and one for test) as inputs. In order to re-use the code, you need to prepare your train and test data to contain three columns _Id_, _AnswerId_ and _Text_.
+
+* _Id_: represents the unique question ID.
+* _AnswerId_: represents the answer ID that the question belongs to.
+* _Text_: contains the text in your questions.
+
+Once your data is prepared with the above format, you can modify the _trainQ_url_ and _testQ_url_ in the script to the path of your training and test set, respectively. The remaining script should be directly applicable.
+
+
+## Contact
+
+Please feel free to contact Katherine Zhao (mez@microsoft.com) and T.J. Hazen (TJ.Hazen@microsoft.com) with any question or comment.