|
|
||
|---|---|---|
| .github/workflows | ||
| .vscode | ||
| docs | ||
| src | ||
| .gitignore | ||
| CODE_OF_CONDUCT.md | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
| SUPPORT.md | ||
README.md
QuickStart Guide: Maximo Application Suite on Azure
This repository provides deployment guidance, scripts and best practices for running IBM Maximo Application Suite (Maximo or MAS) on OpenShift using the Azure Cloud. The instruction below have been tested with Maximo 8.7.x on OpenShift 4.8.x.
🚧 NOTE: The scripts contained within this repo were written with the intention of testing various configurations and integrations on Azure. They allow you to quickly deploy Maximo on Azure so that configurations can be evaluated.
🚧 WARNING this guide is currently under active development. If you would like to contribute or use this right now, please reach out so we can support you.
Table of Contents
- QuickStart Guide: Maximo Application Suite on Azure
- Table of Contents
- Getting Started
- Overview
- Step 1: Preparing Azure
- Step 2: Deploy and prepare OpenShift
- Step 3: Install dependencies for MAS
- Azure Files CSI drivers
- Enabling SAML authentication against Microsoft Entra ID
- Updating pull secrets
- Updating Worker Nodes
- Installing OpenShift Container Storage (Optional)
- Installing IBM Operator Catalog
- Installing cert-manager
- Installing MongoDB
- Installing Service Binding Operator
- Installing IBM Behavior Analytics Services Operator (BAS)
- Step 4: Installing MAS
- Step 5: Installing Cloud Pak for Data (Optional)
- Step 6: Install Visual Inspection (Optional)
- Step 7: Post Install Dependencies
- Step 8: Installing applications on top of Maximo
- Step 8a: Installing Manage
- Step 8b: Installing Health
- Step 8c: Installing Visual Inspection
- Step 8d: Installing Monitor and IoT
- Step 8e: Installing Predict
- Tips and Tricks
- Contributing
Getting Started
To move forward with a MAS install you will need a few basics:
- An active Azure subscription.
- A quota of at least 40 vCPU allowed for your VM type of choice (Dsv4 recommended). Request a quota increase if needed.
- You will need subscription owner permissions for the deployment.
- If you cannot obtain subscription level permissions, it is possible to target a resource group in the
install-config.yamlfile instead.
- If you cannot obtain subscription level permissions, it is possible to target a resource group in the
- A domain or subdomain. If you don't have one, you can register one through Azure using an App Service Domain.
- If you will be using a subdomain, you will need to delegate authority of the sub domain to the public Azure DNS Zone as described here
- Access to the IBM licensing service for IBM Maximo.
- IBM Entitlement Key.
These are normally provided by your organization. The IBM Entitlement key will be needed after your OpenShift cluster is deployed but you will not need the IBM License for Maximo until the last few steps. Once you have secured access to an Azure subscription, you need:
- An Application Registration (SPN) with Contributor and User Access Administrator access on the Subscription you are intending to deploy into. If you are not able to assign permissions at a resource group level, the prefered method is to create 2 resource groups:
- Template deployed resources (VNet, Storage Accounts, Bastion, JumpBox...etc)
- Installer (IPI) deployed resources (control nodes, worker nodes, load balancers...etc)
After these 2 resource groups are created, you will need to grant
OwnerorContributor+User Access Administratorto the SPN on both resource groups. The resource group for the template deployed resources should be used in the parameters file for the bicep file and the resoruce group for the installer should be added as a setting in theinstall-config.yamlfile the underplatform.azure.resourceGroupNamesection. More information can be found in the openshift installer docs and here: Step 1: Preparing Azure.
💡 TIP: It is recommended to use a Linux, Windows Subsystem for Linux or macOS system to complete the installation. You will need some command line binaries that are not as readily available on Windows.
For the installation you will need the OpenShift client. You can grab the OpenShift clients from Red Hat at their mirror. This will provide the oc CLI and also includes kubectl. To retrieve the certificates from pods required for configuration, you can also install openssl by installing the OpenSSL package through the OS package manager (apt, yum). Knowledge of Kubernetes is not required but recommended as a lot of Kubernetes concepts will come by.
After these services have been installed and configured, you can successfully install and configure Maximo Application Suite (MAS) on OpenShift running on Azure.
💡 NOTE: For the automated installation of OCP and MAS see this guide.
Overview
The goal of this guide is to deploy the Maximo Application Suite (MAS) within OpenShift running on Azure in a similiar configuration shown below:
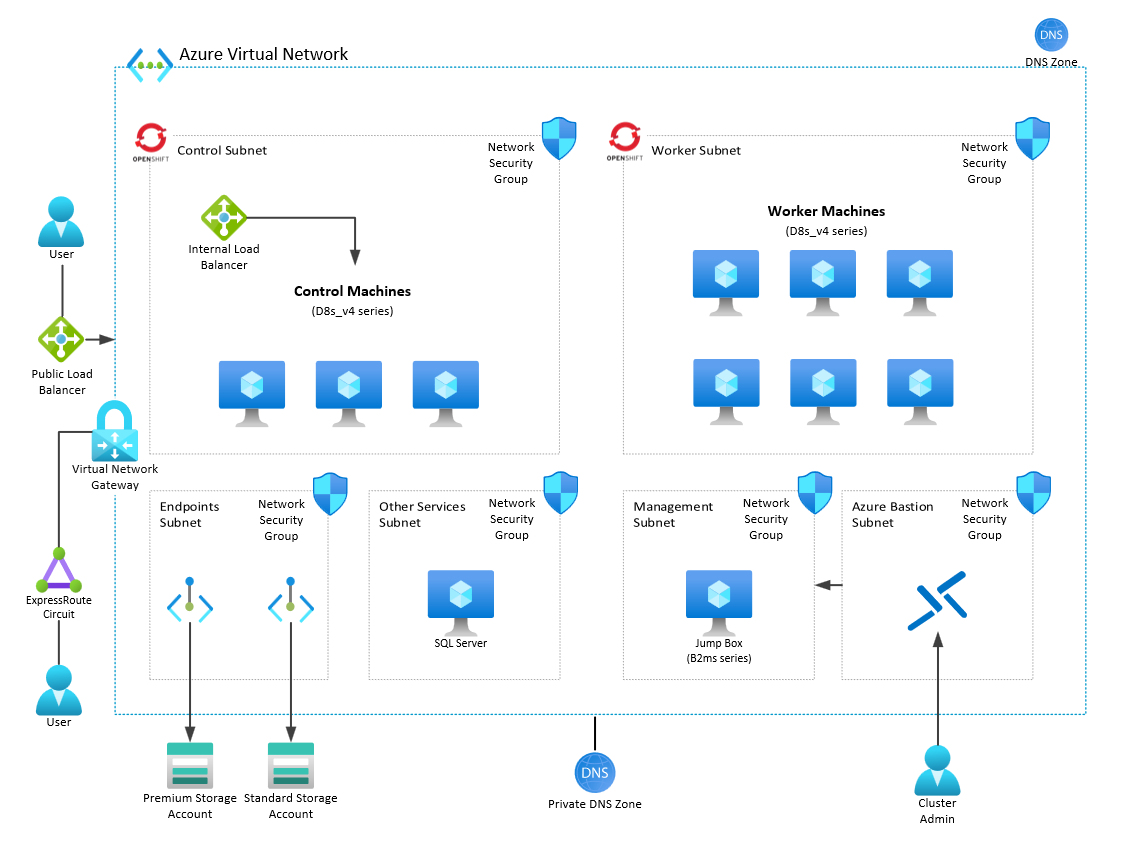
To accomplish this, you will need to execute the following steps:
- Prepare and configure Azure resources for OpenShift and MAS install
- Deploy OpenShift
- Install the dependencies for MAS
- Install MAS
- Install Cloud Pak for Data (Optional)
- Install Maximo Application Suite.
Step 1: Preparing Azure
Please follow this guide to configure Azure.
Step 2: Deploy and prepare OpenShift
💡 NOTE: IBM MAS supports Azure Red Hat OpenShift provided that the underlying versions of OpenShift and Cloud Pak for Data (CP4D) align.
Install OCP
Please follow this guide to configure OpenShift Container Platform on Azure.
Logging In
Once you have to OpenShift installed, visit the admin URL and try to log in to validate everything is up and running. The URL will look something like console-openshift-console.apps.{clustername}.{domain}.{extension}. The username is kubeadmin and the password was provided to you by the installer.
You will need to login to the oc CLI. You can get an easy way to do this by navigating the the Copy login page. You can find this on the top right of the screen:
Login by clicking on display token and use the oc login command to authenticate your oc client to your OpenShift deployment OR by exporting the KUKBECONFIG path.
export KUBECONFIG="$PWD/auth/kubeconfig"
💡 TIP: Copy the
occlient to your /usr/bin directory to access the client from any directory. This will be required for some installing scripts.
Step 3: Install dependencies for MAS
Maximo has a few requirements that have to be available before it can be installed. These are:
- JetStack cert-manager
- MongoDB CE
- Service Binding Operator
- IBM Behavioral Analytics Systems (BAS)
- IBM Suite Licensing Services (SLS)
Azure Files CSI drivers
Version: v1.12.0 (Newer versions may be supported)
💡 TIP: Copy the
ocandkubectlclient to your/usr/bindirectory to access the client from any directory. This will be required for some installing scripts.
💡 NOTE: Azure File Shares (SMB) does not support hard links for most services. Azure Premium Files (NFS) is required and recommended as the backend storage for various services support MAS. 🚧 WARNING Enabling
Secure Transfer Requiredon the storage account will block access to NFS shares on Azure Premium Files. This must be disabled to prevent Pods from failing to start.
Run the following commands to configure Azure Files within your cluster:
#Create directory for install files
mkdir /tmp/OCPInstall
mkdir /tmp/OCPInstall/QuickCluster
#Prepare openshift client for connectivity
export KUBECONFIG="$PWD/auth/kubeconfig"
#set variables for deployment
export deployRegion="eastus"
export resourceGroupName="myRG"
export tenantId="tenantId"
export subscriptionId="subscriptionId"
export clientId="clientId" #This account will be used by OCP to access azure files to create shares within Azure Storage.
export clientSecret="clientSecret"
export branchName="main"
#create directory to store modified files
mkdir customFiles
#Configure Azure Files Standard
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/storageclasses/azurefiles-standard.yaml -O ./azurefiles-standard.yaml
envsubst < ./azurefiles-standard.yaml > ./customFiles/azurefiles-standard.yaml
oc apply -f ./customFiles/azurefiles-standard.yaml
#Configure Azure Files Premium
#Create the azure.json file and upload as secret
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/storageclasses/azure.json -O ./azure.json
envsubst < ./azure.json > ./customFiles/azure.json
oc create secret generic azure-cloud-provider --from-literal=cloud-config=$(cat ./customFiles/azure.json | base64 | awk '{printf $0}'; echo) -n kube-system
#Grant access
oc adm policy add-scc-to-user privileged system:serviceaccount:kube-system:csi-azurefile-node-sa
#Install CSI Driver
oc create configmap azure-cred-file --from-literal=path="/etc/kubernetes/cloud.conf" -n kube-system
driver_version=v1.12.0
echo "Driver version " $driver_version
curl -skSL https://raw.githubusercontent.com/kubernetes-sigs/azurefile-csi-driver/master/deploy/install-driver.sh | bash -s $driver_version --
#Deploy premium Storage Class
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/storageclasses/azurefiles-premium.yaml -O ./azurefiles-premium.yaml
envsubst < ./azurefiles-premium.yaml > ./customFiles/azurefiles-premium.yaml
oc apply -f ./customFiles/azurefiles-premium.yaml
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/storageclasses/persistent-volume-binder.yaml
Enabling SAML authentication against Microsoft Entra ID
Maximo Application Suite supports SAML for authentication into the platform, including the use of Microsoft Entra ID as the SAML IdP. To enable Microsoft Entra ID as the SAML IdP you need to take the following steps:
- Open the Azure Portal and go to the Azure Active Directory blade. Register an Enterprise Application in Azure Active Directory, you may need permissions for this or have your global administrator create this for you
- Give it a name, e.g. Maximo SAML
- Select "Integrate any other application you don't find in the gallery"
- After deploying Maximo Application Suite, go to the Maximo administration portal and select "Configure SAML" (can also be found on the configuration panel) and fill out step 1. Name the service provider something that is convenient.
- Pick emailAddress as the nameid-format.
- Click on Generate file, wait and then Download file. Store this file, you need it in the next step.
- Switch back to the Azure Portal and go into the newly registered application. Click on single sign on and then select SAML. Click on upload metadata file and select the file you downloaded from the Maximo configuration panel and then click on Add.
- On the next page that opens, you can optionally put in the URL to the homepage for the Maximo workspace into the RelayState field. That allows you to SSO to the application from the Microsoft MyApps experience. Next press Save.
- On step 3 in the Microsoft Entra ID Portal authentication overview, you need to download the Federation Metadata XML. Switch back to Maximo's SAML configuration panel and in the step 3 there upload the Microsoft Entra ID Federation Metadata XML document.
The steps above have loaded the definitions of the SAML Endpoint into the Microsoft Entra ID Enterprise Application and into Maximo so that they can exchange the SAML messages and understand eachother. Next we need to create users in Maximo and grant those users access on Microsoft Entra ID to control the single sign-on.
-
Go to the Microsoft Entra ID Enterprise Application you created, click on users and groups. Click on add user/group and add a designated user (yourself) to the application. Take note of the UPN (email address) the user uses.
-
Switch back to Maximo and create a new user there with the following details
- Authentication type: SAML
- Username: the UPN used in Microsoft Entra ID - they have to match
- Primary email: the UPN used in Microsoft Entra ID
The rest of the fields can be populated as you like with whatever permissions necessary
-
Open a new browser window (in private), go to the Maximo home or admin page, enter your Microsoft Entra ID UPN, it should redirect you to Microsoft Entra ID for authentication and sign you in successfully.
Any errors can be reviewed by looking at the logs for the coreidp pods.
Updating pull secrets
You will need to update the pull secrets to make sure that all containers on OpenShift can pull from the IBM repositories. This means using your entitlement key to be able to pull the containers. This is needed specifically for the install of Db2wh, as there is no other way to slip your entitlement key in. Detailed steps can be found in the IBM Documentation for CP4D.
#Set Global Registry Config
oc extract secret/pull-secret -n openshift-config --keys=.dockerconfigjson --to=. --confirm
export encodedEntitlementKey=$(echo cp:$ENTITLEMENT_KEY | base64 -w0)
export emailAddress=$(cat .dockerconfigjson | jq -r '.auths["cloud.openshift.com"].email')
jq '.auths |= . + {"cp.icr.io": { "auth" : "$encodedEntitlementKey", "email" : "$emailAddress"}}' .dockerconfigjson > /tmp/OCPInstall/QuickCluster/dockerconfig.json
envsubst < /tmp/OCPInstall/QuickCluster/dockerconfig.json > /tmp/OCPInstall/QuickCluster/.dockerconfigjson
oc set data secret/pull-secret -n openshift-config --from-file=/tmp/OCPInstall/QuickCluster/.dockerconfigjson
Updating Worker Nodes
#Set variables to match your environment
export clusterInstanceName="clusterInstanceName"
export resourceGroupName="resourceGroupName"
export subnetWorkerNodeName="subnetWorkerNodeName"
export branchName="main"
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/machinesets/worker.yaml -O /tmp/OCPInstall/worker.yaml
export zone=1
export numReplicas=3
envsubst < /tmp/OCPInstall/worker.yaml > /tmp/OCPInstall/QuickCluster/worker.yaml
oc apply -f /tmp/OCPInstall/QuickCluster/worker.yaml
oc scale --replicas=0 machineset $(grep -A3 'name:' /tmp/OCPInstall/QuickCluster/worker.yaml | head -n1 | awk '{ print $2}') -n openshift-machine-api
oc scale --replicas=$numReplicas machineset $(grep -A3 'name:' /tmp/OCPInstall/QuickCluster/worker.yaml | head -n1 | awk '{ print $2}') -n openshift-machine-api
export zone=2
export numReplicas=3
envsubst < /tmp/OCPInstall/worker.yaml > /tmp/OCPInstall/QuickCluster/worker.yaml
oc apply -f /tmp/OCPInstall/QuickCluster/worker.yaml
oc scale --replicas=0 machineset $(grep -A3 'name:' /tmp/OCPInstall/QuickCluster/worker.yaml | head -n1 | awk '{ print $2}') -n openshift-machine-api
oc scale --replicas=$numReplicas machineset $(grep -A3 'name:' /tmp/OCPInstall/QuickCluster/worker.yaml | head -n1 | awk '{ print $2}') -n openshift-machine-api
export zone=3
export numReplicas=3
envsubst < /tmp/OCPInstall/worker.yaml > /tmp/OCPInstall/QuickCluster/worker.yaml
oc apply -f /tmp/OCPInstall/QuickCluster/worker.yaml
oc scale --replicas=0 machineset $(grep -A3 'name:' /tmp/OCPInstall/QuickCluster/worker.yaml | head -n1 | awk '{ print $2}') -n openshift-machine-api
oc scale --replicas=$numReplicas machineset $(grep -A3 'name:' /tmp/OCPInstall/QuickCluster/worker.yaml | head -n1 | awk '{ print $2}') -n openshift-machine-api
Installing OpenShift Container Storage (Optional)
💡 NOTE: If you are using Azure Premium Files OCS is not required.
OpenShift Container Storage provides ceph to our cluster. Ceph is used by a variety of Maximo services to store its data. Before we can deploy OCS, we need to make a new machineset for it as it is quite needy: a minimum of 30 vCPUs and 72GB of RAM is required. In our sizing we use 4x B8ms for this machineset, the bare minimum and put them on their own nodes so there's no resource contention. After the machineset we need the OCS operator. Alternatively, you can install it from the OperatorHub.
#Set variables to match your environment
export clusterInstanceName="clusterInstanceName"
export resourceGroupName="resourceGroupName"
export subnetWorkerNodeName="subnetWorkerNodeName"
export branchName="main"
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/machinesets/ocs.yaml -O ocs.yaml
export zone=1
export numReplicas=2
envsubst < ocs.yaml > /tmp/OCPInstall/QuickCluster/ocs.yaml
oc apply -f /tmp/OCPInstall/QuickCluster/ocs.yaml
export zone=2
export numReplicas=1
envsubst < ocs.yaml > /tmp/OCPInstall/QuickCluster/ocs.yaml
oc apply -f /tmp/OCPInstall/QuickCluster/ocs.yaml
# Create the namespace
oc create ns openshift-storage
# Install the operator
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/ocs/ocs-operator.yaml
After provisioning the cluster, go to the OpenShift Container Storage operator in the openshift-storage namespace and create a StorageCluster. Following settings (which are the default):
- managed-premium as StorageClass
- Requested capacity, 2TB or 0.5TB
- Selected nodes: you will see that the operator already pre-selects the nodes we just created. If not, pick the ocs-* nodes
Once you have completed these steps, you can proceed with the requirements for Maximo.
Installing IBM Operator Catalog
The IBM Operator Catalog is an index of operators available to automate deployment and maintenance of IBM Software products into Red Hat OpenShift clusters. Operators within this catalog have been built following Kubernetes best practices and IBM standards to provide a consistent integrated set of capabilities.
To install, run the following commands:
export branchName="main"
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/operatorcatalogs/catalog-source.yaml
To validate everything is up and running, check oc get catalogsource/ibm-operator-catalog -n openshift-marketplace.
oc get catalogsource/ibm-operator-catalog -n openshift-marketplace
NAME DISPLAY TYPE PUBLISHER AGE
ibm-operator-catalog IBM Operator Catalog grpc IBM 5d21h
Installing cert-manager
cert-manager is a Kubernetes add-on to automate the management and issuance of TLS certificates from various issuing sources. It is required for Maximo. For more installation and usage information check out the cert-manager documentation. Installation of cert-manager is relatively straight forward. Create a namespace and install:
oc create namespace cert-manager
oc apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.2.0/cert-manager.yaml
To validate everything is up and running, check oc get po -n cert-manager. If you have the kubectl cert-manager extension installed, you can also verify the install with kubectl cert-manager check api.
oc get po -n cert-manager
Output should be like this:
NAME READY STATUS RESTARTS AGE cert-manager-5597cff495-dh278 1/1 Running 0 2d1h cert-manager-cainjector-bd5f9c764-2j29c 1/1 Running 0 2d1h cert-manager-webhook-c4b5687dc-thh2b 1/1 Running 0 2d1h
Installing MongoDB
In this example, we will be installing the community edition of MongoDB on OpenShift using self signed certs. MongoDB Community Edition is the free version of MongoDB. This version does not come with enterprise support nor certain features typically required by enterprises. We recommend exploring the options below for production use:
💡 NOTE: Azure CosmosDB is currently not supported. Retryable writes are required by MAS which is currently not a feature of CosmosDB's MongoDB API offering.
If you are not using our globally available service, Azure CosmosDB, then we recommend starting with a minimum 3 node ReplicaSet, with 1 node in each availability zone (outside of the OpenShift cluster). Please verify your deployment will be in the the same region / zones your OpenShift cluster are deployed into.
To get started, you will clone a github repository and execute a few scripts:
#clone repo
git clone https://github.com/ibm-watson-iot/iot-docs.git
#navigate to the certs directory
cd iot-docs/mongodb/certs/
#generate self signed certs
./generateSelfSignedCert.sh
#navigate back a directory to: /mongodb/iot-docs/mongodb
cd ..
#export the following variables, replacing the password
export MONGODB_STORAGE_CLASS="managed-premium"
export MONGO_NAMESPACE=mongo
export MONGO_PASSWORD="<enterpassword>"
#install MongoDB
./install-mongo-ce.sh
This install can take up to 15 minutes. Once completed, verify the services are online by checking the status of the key: "status.phase":
oc get MongoDBCommunity -n mongo -o yaml | grep phase
status.phase = Running
Capture the connection string by running the following command:
oc get MongoDBCommunity -n mongo -o yaml | grep mongoUri
mongoUri: mongodb://mas-mongo-ce-0.mas-mongo-ce-svc.mongo.svc.cluster.local:27017,mas-mongo-ce-1.mas-mongo-ce-svc.mongo.svc.cluster.local:27017,mas-mongo-ce-2.mas-mongo-ce-svc.mongo.svc.cluster.local:27017
Installing Service Binding Operator
Service Binding Operator enables application developers to more easily bind applications together with operator managed backing services such as databases, without having to perform manual configuration of secrets, configmaps, etc.
We have to put this operator on manual approval and you can NOT and should NOT upgrade the operator to a newer version. Maximo requires 0.8.0 specifically. To install, run the following commands:
export branchName="main"
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/servicebinding/service-binding-operator.yaml
installplan=$(oc get installplan -n openshift-operators | grep -i service-binding | awk '{print $1}'); echo "installplan: $installplan"
oc patch installplan ${installplan} -n openshift-operators --type merge --patch '{"spec":{"approved":true}}'
To validate everything is up and running, check oc get csv service-binding-operator.v0.8.0.
oc get csv service-binding-operator.v0.8.0
# It should print the below, pay attention to the Succeeded.
NAME DISPLAY VERSION REPLACES PHASE
service-binding-operator.v0.8.0 Service Binding Operator 0.8.0 service-binding-operator.v0.7.1 Succeeded
Installing IBM Behavior Analytics Services Operator (BAS)
IBM Behavior Analytics Services Operator is a service that collects, transforms and transmits product usage data.
To install, run the following commands:
export branchName="main"
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/bas/bas-operator.yaml
Next, you will need to create 2 secrets. Be sure to update the username and password in the example below:
oc create secret generic database-credentials --from-literal=db_username=<enterusername> --from-literal=db_password=<enterpassword> -n ibm-bas
oc create secret generic grafana-credentials --from-literal=grafana_username=<enterusername> --from-literal=grafana_password=<enterpassword> -n ibm-bas
Finally, deploy the Analytics Proxy. This will take up to 30 minutes to complete:
# Deploy
export branchName="main"
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/bas/bas-service.yaml
# You can monitor the progress, keep an eye on the status section:
oc describe AnalyticsProxy analyticsproxy -n ibm-bas
# or use oc status
oc status
Once this is complete, retrieve the bas endpoint and the API Key for use when doing the initial setup of Maximo:
export branchName="main"
oc get routes bas-endpoint -n ibm-bas
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/bas/bas-api-key.yaml
To get the credentials and details from BAS, please see Setting up Maximo.
Installing IBM Suite License Service (SLS)
IBM Suite License Service (SLS) is a token-based licensing system based on Rational License Key Server (RLKS) with MongoDB as the data store.
To configure this service, you will need the following:
- IBM Entitlement Key
- MongoDB Info
- Hostnames and ports (27017 by default)
- Database Name
- Admin Credentials
Create a new project and store the docker secret with IBM entitlement key:
oc new-project ibm-sls
export ENTITLEMENT_KEY=<Entitlement Key>
oc create secret docker-registry ibm-entitlement --docker-server=cp.icr.io --docker-username=cp --docker-password=$ENTITLEMENT_KEY -n ibm-sls
Deploy the operator group and subscription configurations for both Suite Licensing Service (SLS) and the truststore manager operator (requirement for SLS)
export branchName="main"
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/sls/sls-operator.yaml
This will take a while, as usual, check its progress with oc get csv -n ibm-sls.
Once done, deploy the sls-service. For this we need to make sure the correct details for Mongo are provided. Grab the secrets and provide them to SLS. We do this by creating a secret for it. In case you forgot the MongoDB password, retrieve it:
oc extract secret/mas-mongo-ce-admin-password --to=- -n mongo
# Then create the secret:
oc create secret generic sls-mongo-credentials --from-literal=username=admin --from-literal=password=<MONGO_PASSWORD> -n ibm-sls
Review the provided sls-service.yaml to make sure the servers used in there are correct for your use case:
mongo:
configDb: admin
nodes:
- host: mas-mongo-ce-0.mas-mongo-ce-svc.mongo.svc.cluster.local
port: 27017
- host: mas-mongo-ce-1.mas-mongo-ce-svc.mongo.svc.cluster.local
port: 27017
- host: mas-mongo-ce-2.mas-mongo-ce-svc.mongo.svc.cluster.local
port: 27017
secretName: sls-mongo-credentials
Deploy the service configuration:
If you are happy with the default configuration then proceed with the following command:
# Deploy
export branchName="main"
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/sls/sls-service.yaml
If you prefer to modify the setup, pull down the config and edit it:
export branchName="main"
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/sls/sls-service.yaml -O sls-service.yaml
After editing:
oc apply -f sls-service.yaml
Wait for IBM SLS to come up, you can check its progress and also grab the connection details:
oc get LicenseService sls -n ibm-sls -o yaml
Step 4: Installing MAS
Maximo Application Suite (MAS) can be installed on OpenShift. IBM provides documentation for MAS on its documentation site. Make sure to refer to the documentation for Maximo 8.7.x, as that is the version we are describing throughout this document.
All of the steps below assume you are logged on to your OpenShift cluster and you have the oc CLI available.
Deploying using the Operator
In the step below, you will deploy the MAS operator and then configure the Suite service within the operator.
Lets deploy the operator:
export branchName="main"
oc apply -f https://raw.githubusercontent.com/Azure/maximo/$branchName/src/mas/mas-operator.yaml
Add the entitlement key secret to the mas project:
export ENTITLEMENT_KEY=<Entitlement Key>
oc create secret docker-registry ibm-entitlement --docker-server=cp.icr.io --docker-username=cp --docker-password=$ENTITLEMENT_KEY -n mas-nonprod-core
Check progress of the operator installation:
oc get csv -n mas-nonprod-core
Once it says succeeded for MAS, the Truststore and the Common Service Operator (ignore the Service Binding Operator) it is time to install MAS.
Pull down the mas service YAML file and export variables that will be updated within the file:
export clusterName=myclustername
export baseDomain=mydomain.com
export branchName="main"
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/mas/mas-service.yaml -O mas-service.yaml
envsubst < mas-service.yaml > mas-service-nonprod.yaml
oc apply -f mas-service-nonprod.yaml
Check the progress with:
oc describe Suite nonprod -n mas-nonprod-core
oc get all -n mas-nonprod-core
Once the route is up for the admin dashboard, we can proceed with the initial set up. Grab the username and password by extracting the secret:
oc extract secret/nonprod-credentials-superuser -n mas-nonprod-core --to=-
Skip the step below and proceed with the MAS set up.
Setting up MAS
You can get to MAS on the domain you specified, in our guide this is admin.<cluster_url> (which is in our set up <deployment_name>.apps.cluster.domain). Note that https is required for access. When using self signed certificates (like our example does), you will need to navigate to api.<cluster_url> page and accept any certificates warnings that pop up.
Next, navigate to the /initialsetup page on your MAS instance and accept the SSL certs. You'll be welcomed with a wizard and then a screen like this:
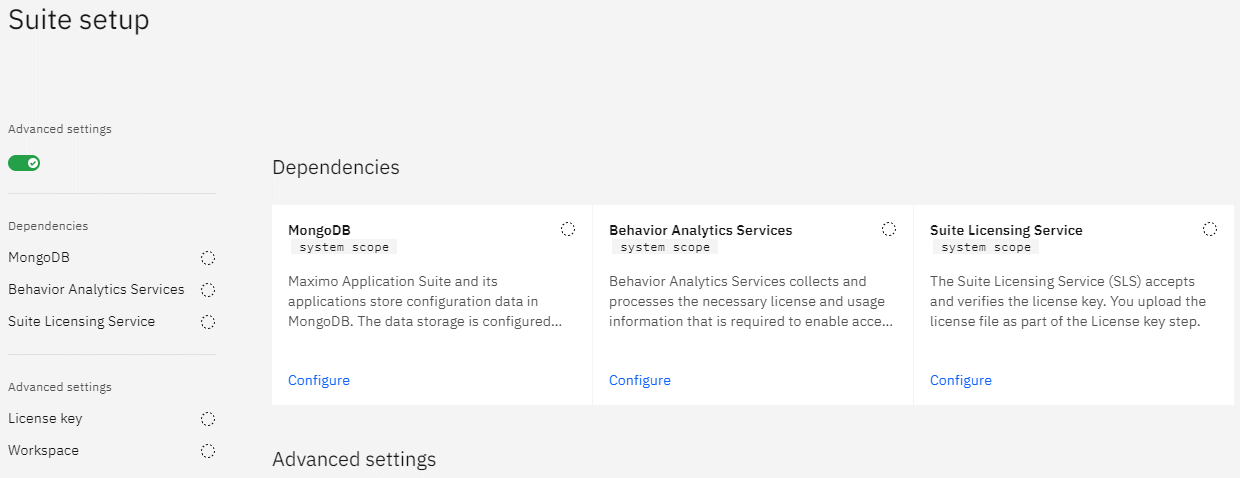
Configuring MongoDB
You can configure the MongoDB Settings using the following commands:
export branchName="main"
oc delete secret nonprod-usersupplied-mongo-creds-system -n mas-nonprod-core 2>/dev/null
sleep 1
oc create secret generic nonprod-usersupplied-mongo-creds-system --from-literal=username=admin --from-literal=password=$(oc extract secret/mas-mongo-ce-admin-password --to=- -n mongo) -n mas-nonprod-core
oc port-forward service/mas-mongo-ce-svc 7000:27017 -n mongo &> /dev/null &
PID=$!
sleep 1
rm -f outfile*
openssl s_client -connect localhost:7000 -servername localhost -showcerts 2>/dev/null | sed --quiet '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | csplit --prefix=outfile - "/-----END CERTIFICATE-----/+1" "{*}" --elide-empty-files --quiet
export mongoCert1=$(cat outfile00)
export mongoCert2=$(cat outfile01)
#mongoCert1=$(openssl s_client -showcerts -servername localhost -connect localhost:7000 </dev/null 2>/dev/null | openssl x509 -outform PEM)
kill $PID
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/mas/mongoCfg.yaml -O mongoCfg.yaml
envsubst < mongoCfg.yaml > mongoCfg-nonprod.yaml
yq eval ".spec.certificates[0].crt = \"$mongoCert1\"" -i mongoCfg-nonprod.yaml
yq eval ".spec.certificates[1].crt = \"$mongoCert2\"" -i mongoCfg-nonprod.yaml
oc apply -f mongoCfg-nonprod.yaml
Configuring BAS
You can configure the BAS Settings using the following commands:
export branchName="main"
oc delete secret nonprod-usersupplied-bas-creds-system -n mas-nonprod-core 2>/dev/null
sleep 1
oc create secret generic nonprod-usersupplied-bas-creds-system --from-literal=api_key=$(oc get secret bas-api-key -n ibm-bas --output="jsonpath={.data.apikey}" | base64 -d) -n mas-nonprod-core
basURL=$(oc get route bas-endpoint -n ibm-bas -o json | jq -r .status.ingress[0].host)
rm -f outfile*
openssl s_client -connect $basURL:443 -servername $basURL -showcerts 2>/dev/null | sed --quiet '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | csplit --prefix=outfile - "/-----END CERTIFICATE-----/+1" "{*}" --elide-empty-files --quiet
export basCert1=$(cat outfile00)
export basCert2=$(cat outfile01)
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/mas/basCfg.yaml -O basCfg.yaml
envsubst < basCfg.yaml > basCfg-nonprod.yaml
yq eval ".spec.certificates[0].crt = \"$basCert1\"" -i basCfg-nonprod.yaml
yq eval ".spec.certificates[1].crt = \"$basCert2\"" -i basCfg-nonprod.yaml
oc apply -f basCfg-nonprod.yaml
Configuring SLS
You can configure the SLS Settings using the following commands:
export branchName="main"
oc delete secret nonprod-usersupplied-sls-creds-system -n mas-nonprod-core 2>/dev/null
sleep 1
oc create secret generic nonprod-usersupplied-sls-creds-system --from-literal=registrationKey=$(oc get LicenseService sls -n ibm-sls --output json | jq -r .status.registrationKey) -n mas-nonprod-core
#oc exec -it sls-rlks-0 -n ibm-sls -- bash -c "echo | openssl s_client -servername sls.ibm-sls.svc -connect sls.ibm-sls.svc:443 -showcerts 2>/dev/null | sed -n -e '/BEGIN\ CERTIFICATE/,/END\ CERTIFICATE/ p'"
oc port-forward service/sls 7000:443 -n ibm-sls &> /dev/null &
PID=$!
sleep 1
rm -f outfile*
openssl s_client -connect localhost:7000 -servername localhost -showcerts 2>/dev/null | sed --quiet '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | csplit --prefix=outfile - "/-----END CERTIFICATE-----/+1" "{*}" --elide-empty-files --quiet
export slsCert1=$(cat outfile00)
export slsCert2=$(cat outfile01)
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/mas/slsCfg.yaml -O slsCfg.yaml
envsubst < slsCfg.yaml > slsCfg-nonprod.yaml
yq eval ".spec.certificates[0].crt = \"$slsCert1\"" -i slsCfg-nonprod.yaml
yq eval ".spec.certificates[1].crt = \"$slsCert2\"" -i slsCfg-nonprod.yaml
oc apply -f slsCfg-nonprod.yaml
The validation for SLS can take up to 10-15 minutes before it shows a green checkmark. Once it completes it will generate some details you need to generate the license.dat file.
Generate a license file and finalize workspace
With the configuration for all the pieces complete, you'll get a challenge from the SLS. You are provided with a hostname and an ethernet address. Click on the link to take you to the IBM License Center and create a license.dat file. If you have no access, work with someone who does. Take the license.dat and upload it into the page:
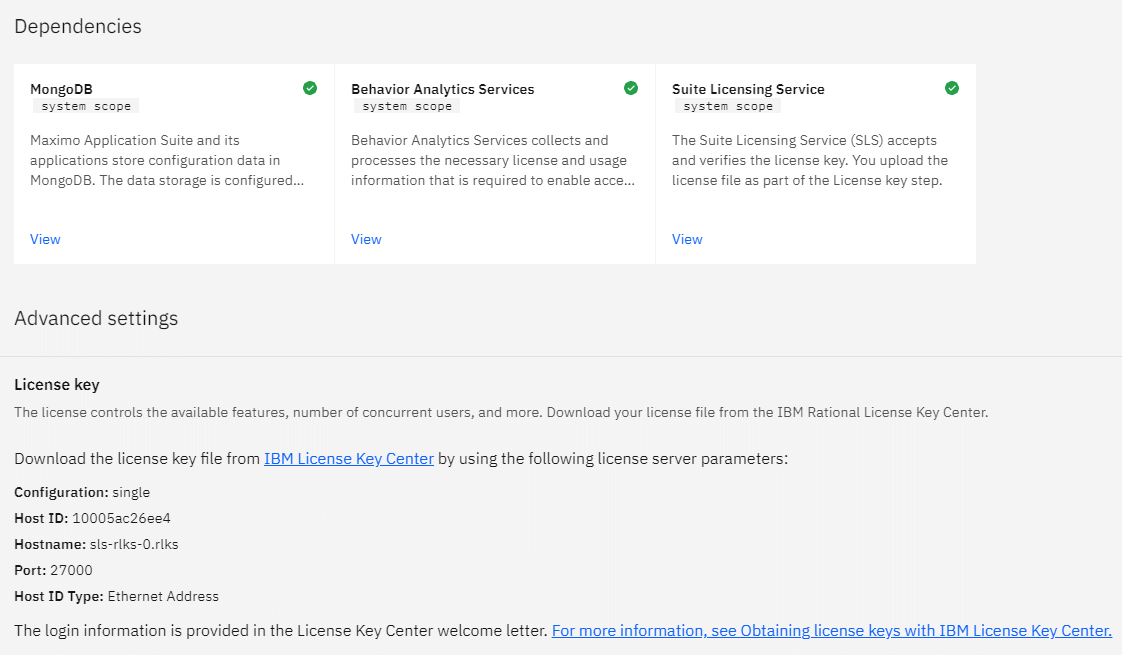
Once the license is loaded, set up a workspace. This has to be a unique name. Once done, hit "SAVE" and then "FINISH" on the top right. Maximo will now finalize the setup.
Step 5: Installing Cloud Pak for Data (Optional)
Installing CP4D 3.5
Cloud Pak for Data 3.5 will be installed using the cpd cli. CP4D 4.0 is not supported.
Create the namespace for the CLI to run against:
oc new-project cp4d
export ENTITLEMENT_KEY=<Entitlement Key>
oc -n cp4d create secret docker-registry ibm-registry --docker-server=cp.icr.io --docker-username=cp --docker-password=$ENTITLEMENT_KEY
Download and prepare the installer:
wget -nv https://github.com/IBM/cpd-cli/releases/download/v3.5.8/cpd-cli-linux-EE-3.5.8.tgz -O /tmp/cpd-cli-linux-EE-3.5.8.tgz
tar -xvzf /tmp/cpd-cli-linux-EE-3.5.8.tgz -C /tmp
sed -i "s/<enter_api_key>/$ENTITLEMENT_KEY/g" /tmp/repo.yaml
Run the following cpdcli commands:
#Install CP4D
./cpd-cli adm --accept-all-licenses --repo /tmp/repo.yaml --assembly lite --namespace cp4d --latest-dependency --apply
./cpd-cli install --accept-all-licenses --repo /tmp/repo.yaml --assembly lite --namespace cp4d --storageclass azurefiles-premium --latest-dependency
#Install db2wh
./cpd-cli adm --accept-all-licenses --repo /tmp/repo.yaml --assembly db2wh --namespace cp4d --latest-dependency --apply
./cpd-cli install --accept-all-licenses --repo /tmp/repo.yaml --assembly db2wh --namespace cp4d --storageclass azurefiles-premium --latest-dependency
Step 6: Install Visual Inspection (Optional)
Visual Inspection Requirements
If you wish to use Visual Inspection (VI), your OpenShift deployment must accomodate GPU-enabled worker nodes. To this end, this deployment contains a Machineset set specification in src/machinesets/worker-vi-tesla.yaml which will deploy Standard_NC12s_v3 Virtual Machines, which are GPU enabled with NVIDIA Tesla V100 GPUs, and you can modify this spec to increase the size of the VM per your needs.
Installing Visual Inspection Components
The included installer script includes parameters that can control if you wish to install Visual Inspection components during your deployment. This will take care of creating the machineset with GPU-enabled workers, installing all the required node discovery features, and the NVidia GPU operator. Please see the "" section about enabling Visual Inspection Pre-Requirements during your deployment.
Post-Deployment Steps
Once your cluster has been deployed, you can enable the Visual Inspection feature inside of MAS.
Step 7: Post Install Dependencies
Dedicated nodes
In order to use dedicated nodes for the db2wh deployment you need to create a new machineset with a taint of icp4data. Dedicated nodes are recommended for production deployments.
Apply the taint to your machine like so:
taints:
- effect: NoSchedule
key: icp4data
value: mas-manage-db2wh
We have provided a MachineSet definition in src/machinesets/db2.yaml that has the correct taints and recommend sizing for a small DB2 cluster. Install these machines before you deploy DB2. Do so as follows:
#Set variables to match your environment
export clusterInstanceName="clusterInstanceName"
export resourceGroupName="resourceGroupName"
export subnetWorkerNodeName="subnetWorkerNodeName"
export branchName="main"
wget -nv https://raw.githubusercontent.com/Azure/maximo/$branchName/src/machinesets/db2.yaml -O /tmp/OCPInstall/db2.yaml
export zone=1
#Setup DB2 MachineSet
export numReplicas=1
envsubst < /tmp/OCPInstall/db2.yaml > /tmp/OCPInstall/QuickCluster/db2.yaml
sudo -E /tmp/OCPInstall/oc apply -f /tmp/OCPInstall/QuickCluster/db2.yaml
export zone=2
#Setup DB2 MachineSet
export numReplicas=1
envsubst < /tmp/OCPInstall/db2.yaml > /tmp/OCPInstall/QuickCluster/db2.yaml
sudo -E /tmp/OCPInstall/oc apply -f /tmp/OCPInstall/QuickCluster/db2.yaml
When you deploy the db2 cluster, the taint it needs in the deployment is "mas-manage-db2wh". By default the db2wh can't see the machinesets from its service account (zen-databases-sa). Grant it permission to allow to see the machines so it can validate if taints and tolerations are going hand in hand.
💡 NOTE Do not use node selectors, because this can cause ceph to be unavailable on your DB2 nodes
oc adm policy add-cluster-role-to-user system:controller:persistent-volume-binder system:serviceaccount:cp4d:zen-databases-sa
Deploying Db2 Warehouse
In CP4D you will now see a "database" link pop up. If you go to instances and hit "New instance" on the top right you will be greeted with this:
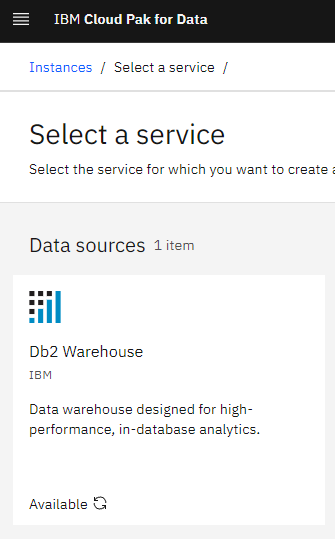
Click on it, press next and deploy. In this deployment we are using OCS as the certified deployment mechanism. The specifications are provided by IBM in their documentation.
Configuring MAS and getting the DB2WH connection string
Go to the configuration panel for Maximo by pressing on the cog on the top right or by going to https://<admin.maximocluster.domain>/config. It will ask you for some details that you can get from the CP4D DB2 overview. On your DB2 Warehouse instance, go to details. In the overview you will get the JDBC URL. Something like jdbc:db2://<CLUSTER_ACCESSIBLE_IP>:32209/BLUDB:user=admin;password=<password>;securityMechanism=9;encryptionAlgorithm=2. If you click on the copy icon, it gives you the required details.
Please read the Maximo documentation on how to specify the URL for DB2WH specifically as it depends on the Maximo application you are deploying. Especially so for manage and monitor (requires SSL).
To grab the URL check the svc endpoint that sits in front of the nodes. To get that, execute the following:
oc get svc -n cp4d | grep db2u-engn
Your URL should be formed like this: jdbc:db2://hostname:50001/BLUDB;sslConnection=true;.
Your hostname is in the list of services above. For example c-db2wh-1634180797242781-db2u-engn-svc.cp4d.svc ("service name".projectname.svc). The port is 50000 for plain or 50001 for SSL, you should use 50001. For the connection string to work with Monitor you MUST append :sslConnection=true; to the end of the connection string.
Installing Kafka
You need to use strimzi-0.22.x. Versions > 0.22 remove the betav1 APIs that the BAS Kafka services depend on. Strimzi comes as an operator, a service and a user that all need to be deployed.
Kafka is quite CPU and memory intensive and needs plenty of resources. You'll likely need to scale up your MachineSets to be able to host Kafka.
# Setup namespace, operator group and operator
oc apply -f strimzi-operator.yaml
# Wait for strimzi operator be completed
oc get csv -n strimzi-kafka
Once completed, allow Azure Files (backing for Kafka) and install the service (server, user)
oc policy add-role-to-user admin system:serviceaccount:kube-system:persistent-volume-binder -n strimzi-kafka
oc apply -f strimzi-service.yaml
Monitor for completion on the Kafka resource
# Grab the TLS cert from the Kafka service
oc get KafkaUser,Kafka -n strimzi-kafka -o yaml
# Grab the password
oc extract secret/masuser --to=- -n strimzi-kafka
To test if Kafka is up and running successfully on your cluster you can use kcat (kafkacat). We recommend testing Kafka, because getting the details right is a bit finicky, and if you get it wrong the IoT install fails and you can't really roll it back - meaning you need to reinstall mas.
To check with kcat, execute the following steps, fire up a kcat container:
oc debug --image edenhill/kcat:1.7.0 -n strimzi-kafka
Create a ca.pem fil on / with the details from the Kafka service. Next, execute the following kcat command:
kcat -b maskafka-kafka-2.maskafka-kafka-brokers.strimzi-kafka.svc:9093 -X security.protocol=SASL_SSL -X sasl.mechanism=SCRAM-SHA-512 -X sasl.username=masuser -X sasl.password=password -X ssl.ca.location=ca.pem -L
Output like this:
Metadata for all topics (from broker 2: sasl_ssl://maskafka-kafka-2.maskafka-kafka-brokers.strimzi-kafka.svc:9093/2): 3 brokers: broker 0 at maskafka-kafka-0.maskafka-kafka-brokers.strimzi-kafka.svc:9093 broker 2 at maskafka-kafka-2.maskafka-kafka-brokers.strimzi-kafka.svc:9093 broker 1 at maskafka-kafka-1.maskafka-kafka-brokers.strimzi-kafka.svc:9093 (controller) 0 topics:
Configuring MAS with Kafka
Enter all the brokers with port 9093 (TLS) or 9092 (non-TLS). The brokers are -kafka-.-kafka-broker..svc, e.g. maskafka-kafka-0.maskafka-kafka-brokers.strimzi-kafka.svc for a cluster called maskafka installed in namespace strimzi-kafka. You can see them listed with kcat too for convenience. To get the credentials for Kafka execute oc extract secret/mas-user --to=- -n strimzi-kafka.
Make sure to load the TLS cert onto the Kafka configuration or your connection to port 9093 will fail. If you use port 9092 (non-TLS) the TLS certificate isn't needed.
To get certs:
cd /tmp
oc port-forward service/maskafka-kafka-brokers 7000:9093 -n strimzi-kafka &> /dev/null &
PID=$!
echo QUIT | openssl s_client -connect localhost:7000 -servername localhost -showcerts 2>/dev/null | sed --quiet '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | csplit --prefix=/tmp/outfile - "/-----END CERTIFICATE-----/+1" "{*}"
--elide-empty-files --quiet
kill $PID
cat outfile00
cat outfile01
Setting up SMTP
If you need Maximo to send out emails, you'll need to provide an SMTP endpoint. It is not possible to run SMTP on Azure yourself, instead you should use Twilio SendGrid which is provided through the Azure Marketplace. You'll need to take the following steps:
- Set up SendGrid
- Identify yourself against SendGrid as the owner of the domain
- Configure the SMTP
- Configure Maximo to use the SMTP
First things first, go to the Azure portal and create a Twilio SendGrid account. Name it as you like, and pick a plan. Free 100 may suffice for most simple use cases. Click create and wait for the deployment to complete. You'll be redirected to Twilio and asked to provide a few more details.
Once that's completed, you need "authenticate a domain" - this will require a bit of editing of your DNS records. For DNS host selected Other and say no to the rewrite. Press Next.
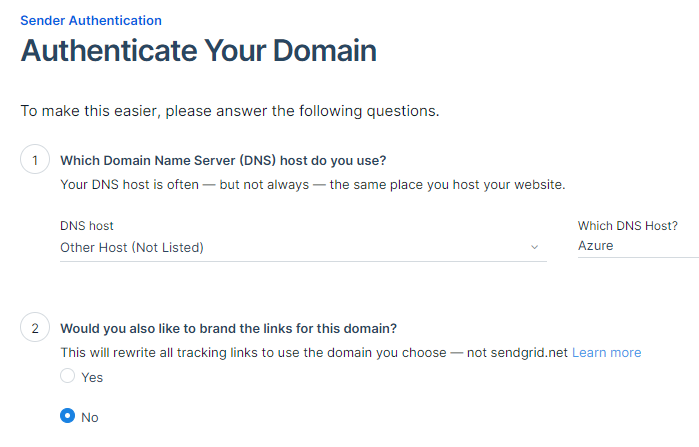
Next, you need to enter the domainname you want to use for sending the emails. You can reuse the domain and the public DNS zone you are using for Maximo. It has to be a public zone as Twilio needs to reach out to it. Press next. You'll now be asked to set up a set of DNS record sets into the public DNS zone you referenced. Create the record set as requested and pay close attention to the TYPE, which is CNAME. TTL of 1 hour is OK and set Alias to no.
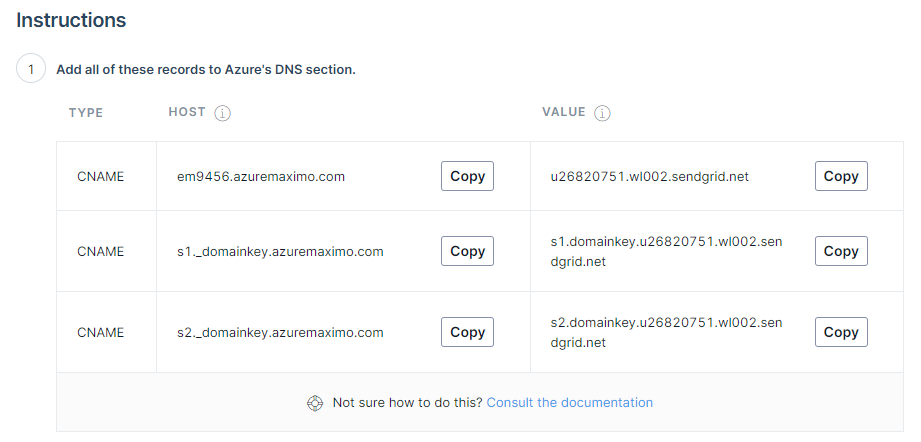
Azure's set up looks like this:
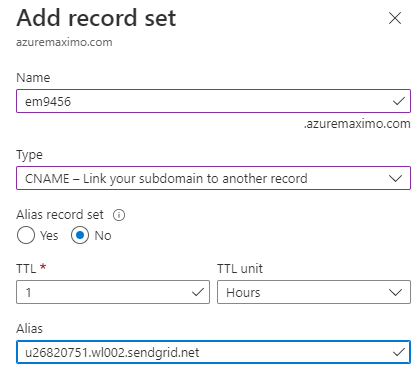
Once done, check "I've verified the records" and then press Verify. Your domain is now verified with Twilio and you are ready to send. If you get stuck, please review the Twilio documentation for SendGrid.
With the first two steps completed, we can go ahead and set up the SMTP Relay at Twilio. Go to set up an API Key for the SMTP relay](https://app.sendgrid.com/guide/integrate/langs/smtp). This will give you the SMTP credentials you need.
💡 NOTE: Do not base64 encode the details, the library does it for you and breaks if you do so. Fill out sender and recipient details, making sure that the sender is on the domain that you just configure for Twilio. The recipient is probably your email address. Press save.
Maximo will now send you an email. In the Twilio dashboard you can click on verify settings, and it should confirm that the email was sent to you.
Step 8: Installing applications on top of MAS
Maximo Application Suite is the base platform that one or more Maximo applications are installed on top of. Each application supports a variety of databases, but the requirements on the database are different per application. Generally speaking you can use SQL Server, Oracle or Db2. Azure SQL DB is currently not supported. As it stands right now, we you run DB2WH on OpenShift using Cloud Park for Data 3.5. You can back the DB2WH using Azure Files Premium.
🚧 WARNING you can not use the same database between Health and Monitor, you'll need two separate databases. Follow the flowchart below to determine what technologies you'll need to set up to meet the requirements for each of the applications.
graph TD
A[Start] --> B
B{Manage/VI only?} --> |Yes| C
C{Need a database?} --> |Yes| SQL[Install SQL Server on a VM] --> I
C ----> |No| I
B ----> |No| D[Install CP4D]
D --> E
E{Need manage?} --> |Yes| F
E ----> |No| G
F{Need health?} --> |Yes| Q[Set up a DB2WH ROW] --> G
F ----> |No| G
G{Need monitor?} --> |Yes| Mongo[Pick a Mongo] --> Kafka[Pick a Kafka] --> R[Set up a DB2WH on CP4D] --> IoT[Set up IoT Tools] --> H
G ----> |No| I
H{Need predict?} --> |Yes| WatsonStudio[Install Watson Studio] --> WatsonML[Install Watson ML] --> I
H ----> |No| I
I{Need VI?} --> |Yes| N[OpenShift 4.8.22 + Nvidia] --> Z
I ----> |No| Z
Z[End]
Installing Manage
Management requires only DB2WH. If you want to deploy Health, make sure to read the instructions on how to do so first. To start, go to the MAS admin panel, go to the catalog and click on Manage to set up the channel:
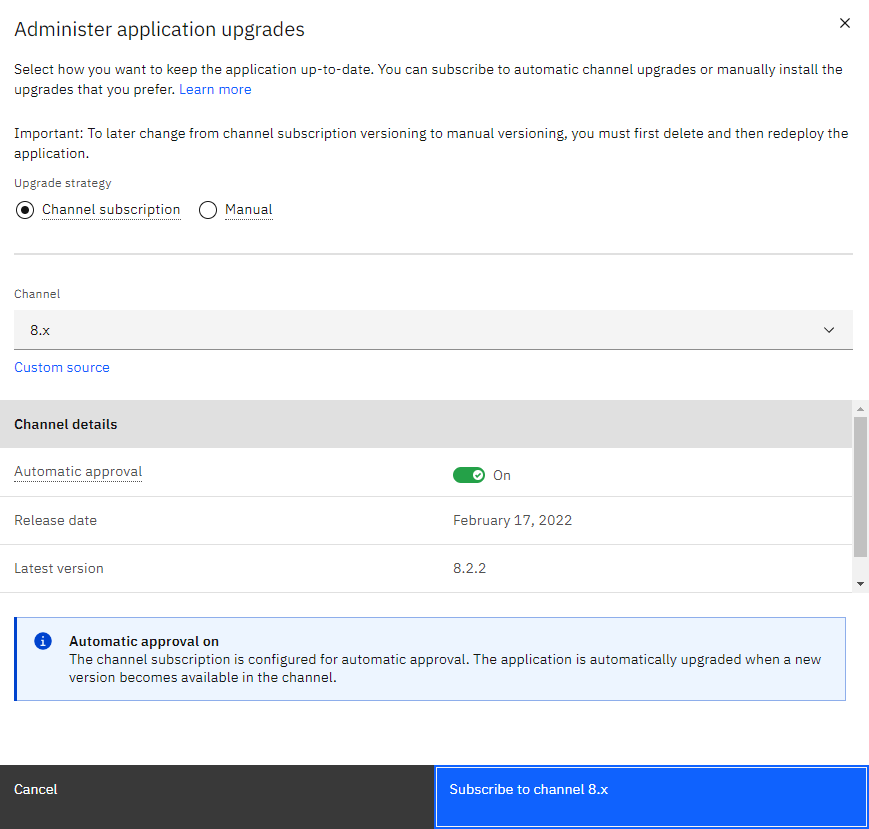
This will take a while, it installing the operator to a manage namespace that will deploy manage for you. Once that is done you'll need to activate it, which includes the configuration. One the activate button lights up, click it.
Next, configure the database. Grab the connection string for your DB2WH (either in COLUMN or ROW mode, depending on whether health is installed) as described above in the configuring MAS and getting the DB2WH connection string section.
❗IMPORTANT Make sure the connection string for the DB2WH includes
sslConnection=true;otherwise the install will fail. An example, correct, connection string is as follows:jdbc:db2://c-db2wh-1652286547816056-db2u-engn-svc.cp4d.svc:50001/BLUDB:sslConnection=true;
Enter the connection string, username and password (default admin/password) and check the SSL Enabled box. There are no additional driver settings and the certificates are not required unless the DB2WH is outside of the cluster. Click save and and then activate. This takes ~2 hours, have patience. After that manage is available in your workspace.
Installing Health
Health can be installed with or without Manage. For now we have only tested with manage and this is the recommended path.
It is important you make a choice to install Health before you install Manage itself as the database set up needs to be altered to support Health. If you have an existing installation of Manage, you may need to redeploy to support Health.
Current recommendation is to use DB2WH, this means you'll need to create a DB2WH using CP4D 3.5 and then configure it per IBM's instructions.
💡 NOTE: There are two errors in the script in step 4 of the configuration page. There needs to be a variable defined for $APP_HEAP_SZ and $LOCKTIMEOUT. You can use a value of 2048 for APP_HEAP_SZ and 300 for LOCKTIMEOUT.
Once you have set up the database, you can go ahead and install Health as part of Manage. Follow the installation instructions for Manage and make sure to check the Health checkbox on the Components overview.
Installing Visual Inspection
If you wish to use Visual Inspection or VI, OpenShift needs GPU-enabled worker nodes. There are few steps to go do this
- Deploy a machineset with GPU nodes in them
- Deploy the Node Feature Discovery operator, to discover the GPU capability
- Deploy the Nvidia Operator to install the Nvidia drivers onto the machines
❗IMPORTANT To make Nvidia GPUs work on OpenShift seamlessly you need OpenShift 4.8.22 or newer.
First you need to deploy VMs with GPUs in them. At src/machinesets/worker-vi-tesla.yaml there is a machineset provided that does this. Deploy it as follows:
#Set variables to match your environment
export clusterInstanceName="clusterInstanceName"
export resourceGroupName="resourceGroupName"
export subnetWorkerNodeName="subnetWorkerNodeName"
export branchName="main"
export zone=1
export numReplicas=1
wget -nv -qO- https://raw.githubusercontent.com/Azure/maximo/$branchName/src/machinesets/worker-vi-tesla.yaml | envsubst | oc apply -f -
The machineset deploys Standard_NC12s_v3 virtual machines. These machines are powered by NVIDIA Tesla V100 GPUs. If you need to run YOLOv3 models, you can deploy Ampere VMs instead - either ND A100v4 or ND A10v5
Once the machinesets have been deployed and came up, you need to install the Node Feature Discovery.
export branchName="main"
wget -nv -qO- https://raw.githubusercontent.com/Azure/maximo/$branchName/src/nfd/nfd-operator.yaml | envsubst | oc apply -f -
Once that one is up, it is time to install the Nvidia drivers. For that you need to install the Nvidia Operator, this will take care of the install of the GPU nodes based on the Node Feature Discovery. This takes a while to complete.
export branchName="main"
export nvidiaOperatorChannel="v1.9.0"
export nvidiaOperatorCSV="gpu-operator-certified.v1.9.1"
wget -nv -qO- https://raw.githubusercontent.com/Azure/maximo/$branchName/src/vi/nv-operator.yaml | envsubst | oc apply -f -
Once that is done you can proceed to deploying the Visual Inspection application on top of MAS. To deploy Visual Inspection, navigate to the catalog > Visual Inspection. After that click on deploy (ignore the VI Edge piece).
Installing IoT
IoT has 3 dependencies:
- DB2WH
- MongoDB
- Kafka Broker
Start by configuring the DB2WH. Grab the connection string for your Column based DB2WH instance as described above in the configuring MAS and getting the DB2WH connection string section.
❗IMPORTANT Make sure the connection string for the DB2WH includes
sslConnection=true;otherwise the install will fail. An example, correct, connection string is as follows:jdbc:db2://c-db2wh-1652286547816056-db2u-engn-svc.cp4d.svc:50001/BLUDB:sslConnection=true;
Enter the connection string, username and password (default admin/password) and check the SSL Enabled box. There are no additional driver settings and the certificates are not required unless the DB2WH is outside of the cluster. Click save and and then activate. This takes ~2 hours, have patience. After that manage is available in your workspace.
Next, if you have not already configured MongoDB, proceed to these steps: configure MongoDB.
Finally, configure the Kafka Broker by Installing Kafka and Configuring MAS with Kafka.
Once all of these dependencies have been configured, you can proceed to the MAS admin panel, go to the catalog and click on Tools > IoT to deploy and activate.
Installing Monitor
Monitor has 2 dependencies:
- DB2WH
- IoT
Start by configuring the DB2WH. Grab the connection string for your Column based DB2WH instance as described above in the configuring MAS and getting the DB2WH connection string section.
❗IMPORTANT Make sure the connection string for the DB2WH includes
sslConnection=true;otherwise the install will fail. An example, correct, connection string is as follows:jdbc:db2://c-db2wh-1652286547816056-db2u-engn-svc.cp4d.svc:50001/BLUDB:sslConnection=true;
Enter the connection string, username and password (default admin/password) and check the SSL Enabled box. There are no additional driver settings and the certificates are not required unless the DB2WH is outside of the cluster. Click save and and then activate. This takes ~2 hours, have patience. After that manage is available in your workspace.
IoT steps were completed in the Step 8d: Installing IoT.
Once all of these dependencies have been configured, you can proceed to the MAS admin panel, go to the catalog and click on Monitor to deploy and activate.
Installing Predict
To start the deployment of predict, DB2WH must be configured. For more information on configuring DB2WH see these steps: configuring MAS and getting the DB2WH connection string.
Following the deployment, you will need to configure the following:
- IBM Watson Studio
- IBM Watson Machine Learning
- Installing Health
- Installing Monitor
IBM Watson products must be installed on Cloud Pak for Data. To get started, follow these steps for Installing CP4D 3.5. Once this is complete, using the same installer, you can deploy the dependencies running the following commands:
#Login to cluster
export KUBECONFIG=/tmp/OCPInstall/QuickCluster/auth/kubeconfig
#Install Watson Studio
cpd-cli install --repo /tmp/repo.yaml --assembly wsl --namespace cp4d --storageclass azurefiles-premium --latest-dependency --accept-all-licenses
#Install Watson Machine Learning
cpd-cli install --repo /tmp/repo.yaml --assembly wml --namespace cp4d --storageclass azurefiles-premium --latest-dependency --accept-all-licenses
After these dependencies are configured, you may proceed to activating Predict.
💡 NOTE: During activation, you will be prompted to enter settings for the IBM Watson Studio. This information is the CP4D URL and the login credentials for CP4D.
Tips and Tricks
To get your credentials to login
For MAS: oc extract secret/nonprod-credentials-superuser -n mas-nonprod-core --to=-
Shutting down your cluster
One of the benefits of cloud is the ability to deallocate your instances and stopping to pay for them. OpenShift supports this and it is possible with Maximo. Snoozing is possible for up to a year or whenever your OpenShift certificates expire. Check the OpenShift documentation for specifics on the support for graceful shutdowns.
To shutdown your cluster you have to stop and deallocate your nodes. This can be done in two days, either by asking the nodes to shutdown themselves and deallocate through Azure or to stop and deallocate from Azure directly. Make sure to deallocate, otherwise your virtual machines will be continue to be billed.
To shut down the cluster gracefully from OpenShift:
for node in $(oc get nodes -o jsonpath='{.items[*].metadata.name}'); do oc debug node/${node} -- chroot /host shutdown -h 1; done
Next, go to the Azure Portal, select all the VMs that are part of the cluster and stop and deallocate them. When you start the cluster back up, do so by starting the Virtual Machines. It takes about 5 minutes for everything to find its spot again, so have a bit of patience and try to hit the OpenShift UI. Pay special attention on the overview page to any pods that are failing to start (e.g. crashloopbackoff) and delete/restart those pods if needed. Two pods do this every time the cluster starts: event-api-deployment and event-reader-deployment. Deleting and restarting them - api deployment first - fixes the problem.
Restarting Kafka inside BAS
The Kafka deployment inside of BAS sometimes gets messed up. It loses track of where it is supposed to be. To gracefully correct that, restart the kafka-zookeeper pod inside the BAS namespace, followed by the kafka-kafka-0 pod. If you look at the logs for the pod, you'll see that the zookeeper is cleaning up stale resources and the kafka pod will connect to the zookeeper again.
Pods refusing to schedule
Sometimes pods refuse to schedule saying they can't find nodes, this is particularly the case for OCS and Kafka. Most of this is to do with where the virtual machines are logically: their availability zones. Make sure you have worker nodes in each of the availability zones a region provides.
Grabbing username and password for CP4D and MAS
Here's a little script to grab login details for Maximo:
#!/bin/bash
echo "===== MAS ====="
oc extract secret/nonprod-credentials-superuser -n mas-nonprod-core --to=-
echo "===== CP4D ====="
echo "User = admin"
oc extract secret/admin-user-details -n cp4d --to=-
Contributing
This project welcomes contributions and suggestions. Most contributions require ou to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines.
Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.