ObjectSpace._id2ref(id) can return any objects even if they are
unshareable, so this patch raises RangeError if it runs on multi-ractor
mode and the found object is unshareable.
Per ractor method cache (GH-#3842) only cached 1 page and this patch
caches several pages to keep at least 512 free slots if available.
If you increase the number of cached free slots, all cached slots
will be collected when the GC is invoked.
A program with multiple ractors can consume more objects per
unit time, so this patch set minimum/maximum free_slots to
relative to ractors count (upto 8).
Lazy sweep tries to collect free (unused) slots incrementally, and
it only collect a few pages. This patch makes lazy sweep collects
more objects (at least 2048 objects) and GC overhead of multi-ractor
execution will be reduced.
Write barrier requires VM lock because it accesses VM global bitmap
but RB_VM_LOCK_ENTER() can invoke GC because another ractor can wait
to invoke GC and RB_VM_LOCK_ENTER() is barrier point. This means that
before protecting by a write barrier, GC can invoke.
To prevent such situation, RB_VM_LOCK_ENTER_NO_BARRIER() is introduced.
This lock primitive does not become GC barrier points.
Now object allocation requires VM global lock to synchronize objspace.
However, of course, it introduces huge overhead.
This patch caches some slots (in a page) by each ractor and use cached
slots for object allocation. If there is no cached slots, acquire the global lock
and get new cached slots, or start GC (marking or lazy sweeping).
This seems to be breaking the build for some reason.
This command can reproduce it:
`make yes-test-all TESTS=--repeat-count=20`
This reverts commit 88bb1a672c.
Incremental sweeping should sweep until we find a slot for objects to
use. `heap_increment` was adding a page to the heap even though we
would sweep immediately after.
Co-authored-by: John Hawthorn <john@hawthorn.email>
To manage ractor-local data for C extension, the following APIs
are defined.
* rb_ractor_local_storage_value_newkey
* rb_ractor_local_storage_value
* rb_ractor_local_storage_value_set
* rb_ractor_local_storage_ptr_newkey
* rb_ractor_local_storage_ptr
* rb_ractor_local_storage_ptr_set
At first, you need to create a key of storage by
rb_ractor_local_(value|ptr)_newkey().
For ptr storage, it accepts the type of storage,
how to mark and how to free with ractor's lifetime.
rb_ractor_local_storage_value/set are used to access a VALUE
and rb_ractor_local_storage_ptr/set are used to access a pointer.
random.c uses this API.
Both explicit compaction routines (gc_compact and the verify references form)
need to clear the heap before executing compaction. Otherwise some
objects may not be alive, and we'll need the read barrier. The heap
must only contain *live* objects if we want to disable the read barrier
during explicit compaction.
The previous commit was missing the "clear the heap" phase from the
"verify references" explicit compaction function.
Fixes [Bug #17306]
Auto Compaction uses mprotect to implement a read barrier. mprotect can
only work on regions of memory that are a multiple of the OS page size.
Ruby's pages are a multiple of 4kb, but some platforms (like ppc64le)
don't have 4kb page sizes. This commit disables the features on those
platforms.
Fixes [Bug #17306]
To make some kind of Ractor related extensions, some functions
should be exposed.
* include/ruby/thread_native.h
* rb_native_mutex_*
* rb_native_cond_*
* include/ruby/ractor.h
* RB_OBJ_SHAREABLE_P(obj)
* rb_ractor_shareable_p(obj)
* rb_ractor_std*()
* rb_cRactor
and rm ractor_pub.h
and rename srcdir/ractor.h to srcdir/ractor_core.h
(to avoid conflict with include/ruby/ractor.h)
* `GC.auto_compact=`, `GC.auto_compact` can be used to control when
compaction runs. Setting `auto_compact=` to true will cause
compaction to occurr duing major collections. At the moment,
compaction adds significant overhead to major collections, so please
test first!
[Feature #17176]
As of 0b81a484f3, `ROBJECT_IVPTR` will
always return a value, so we don't need to test whether or not we got
one. T_OBJECTs always come to life as embedded objects, so they will
return an ivptr, and when they become "unembedded" they will have an
ivptr at that point too
We are seeing an error where code that is generated with MJIT contains
references to objects that have been moved. I believe this is due to a
race condition in the compaction function.
`gc_compact` has two steps:
1. Run a full GC to pin objects
2. Compact / update references
Step one is executed with `garbage_collect`. `garbage_collect` calls
`gc_enter` / `gc_exit`, these functions acquire a JIT lock and release a
JIT lock. So a lock is held for the duration of step 1.
Step two is executed by `gc_compact_after_gc`. It also holds a JIT
lock.
I believe the problem is that the JIT is free to execute between step 1
and step 2. It copies call cache values, but doesn't pin them when it
copies them. So the compactor thinks it's OK to move the call cache
even though it is not safe.
We need to hold a lock for the duration of `garbage_collect` *and*
`gc_compact_after_gc`. This patch introduces a lock level which
increments and decrements. The compaction function can increment and
decrement the lock level and prevent MJIT from executing during both
steps.
rb_objspace_reachable_objects_from(obj) is used to traverse all
reachable objects from obj. This function modify objspace but it
is not ractor-safe (thread-safe). This patch fix the problem.
Strategy:
(1) call GC mark process during_gc
(2) call Ractor-local custom mark func when !during_gc
Unshareable objects should not be touched from multiple ractors
so ObjectSpace.each_object should be restricted. On multi-ractor
mode, ObjectSpace.each_object only iterates shareable objects.
[Feature #17270]
iv_index_tbl manages instance variable indexes (ID -> index).
This data structure should be synchronized with other ractors
so introduce some VM locks.
This patch also introduced atomic ivar cache used by
set/getinlinecache instructions. To make updating ivar cache (IVC),
we changed iv_index_tbl data structure to manage (ID -> entry)
and an entry points serial and index. IVC points to this entry so
that cache update becomes atomically.
Heap allocated objects are never special constants. Since we're walking
the heap, we know none of these objects can be special. Also, adding
the object to the freelist will poison the object, so we can't check
that the type is T_NONE after poison.
When finalizers run (in `rb_objspace_call_finalizer`) the table is
copied to a linked list that is not managed by the GC. If compaction
runs, the references in the linked list can go bad.
Finalizer table shouldn't be used frequently, so lets pin references in
the table so that the linked list in `rb_objspace_call_finalizer` is
safe.
rb_obj_raw_info is called while printing out crash messages and
sometimes called during garbage collection. Calling rb_raise() in these
situations is undesirable because it can start executing ensure blocks.
This commit introduces Ractor mechanism to run Ruby program in
parallel. See doc/ractor.md for more details about Ractor.
See ticket [Feature #17100] to see the implementation details
and discussions.
[Feature #17100]
This commit does not complete the implementation. You can find
many bugs on using Ractor. Also the specification will be changed
so that this feature is experimental. You will see a warning when
you make the first Ractor with `Ractor.new`.
I hope this feature can help programmers from thread-safety issues.
Previously, when an object is first initialized, ROBJECT_EMBED isn't
set. This means that for brand new objects, ROBJECT_NUMIV(obj) is 0 and
ROBJECT_IV_INDEX_TBL(obj) is NULL.
Previously, this combination meant that the inline cache would never be
initialized when setting an ivar on an object for the first time since
iv_index_tbl was NULL, and if it were it would never be used because
ROBJECT_NUMIV was 0. Both cases always fell through to the generic
rb_ivar_set which would then set the ROBJECT_EMBED flag and initialize
the ivar array.
This commit changes rb_class_allocate_instance to set the ROBJECT_EMBED
flag on the object initially and to initialize all members of the
embedded array to Qundef. This allows the inline cache to be set
correctly on first use and to be used on future uses.
This moves rb_class_allocate_instance to gc.c, so that it has access to
newobj_of. This seems appropriate given that there are other allocating
methods in this file (ex. rb_data_object_wrap, rb_imemo_new).
Ruby strings don't always have a null terminator, so we can't use
it as a regular C string. By reading only the first len bytes of
the Ruby string, we won't read past the end of the Ruby string.
`rb_objspace_call_finalizer` creates zombies, but does not do the correct accounting (it should increment `heap_pages_final_slots` whenever it creates a zombie). When we do correct accounting, `heap_pages_final_slots` should never underflow (the check for underflow was introduced in 39725a4db6).
The implementation moves the accounting from the functions that call `make_zombie` into `make_zombie` itself, which reduces code duplication.
Before this commit, iclasses were "shady", or not protected by write
barriers. Because of that, the GC needs to spend more time marking these
objects than otherwise.
Applications that make heavy use of modules should see reduction in GC
time as they have a significant number of live iclasses on the heap.
- Put logic for iclass method table ownership into a function
- Remove calls to WB_UNPROTECT and insert write barriers for iclasses
This commit relies on the following invariant: for any non oirigin
iclass `I`, `RCLASS_M_TBL(I) == RCLASS_M_TBL(RBasic(I)->klass)`. This
invariant did not hold prior to 98286e9 for classes and modules that
have prepended modules.
[Feature #16984]
To optimize the sweep phase, there is bit operation to set mark
bits for out-of-range bits in the last bit_t.
However, if there is no out-of-ragnge bits, it set all last bit_t
as mark bits and it braek the assumption (unmarked objects will
be swept).
GC_DEBUG=1 makes sizeof(RVALUE)=64 on my machine and this condition
happens.
It took me one Saturday to debug this.
imemo_callcache and imemo_callinfo were not handled by the `objspace`
module and were showing up as "unknown" in the dump. Extract the code for
naming imemos and use that in both the GC and the `objspace` module.
This commit expands heap pages to be exactly 16KiB and eliminates the
`REQUIRED_SIZE_BY_MALLOC` constant.
I believe the goal of `REQUIRED_SIZE_BY_MALLOC` was to make the heap
pages consume some multiple of OS page size. 16KiB is convenient because
OS page size is typically 4KiB, so one Ruby page is four OS pages.
Do not guess how malloc works
=============================
We should not try to guess how `malloc` works and instead request (and
use) four OS pages.
Here is my reasoning:
1. Not all mallocs will store metadata in the same region as user requested
memory. jemalloc specifically states[1]:
> Information about the states of the runs is stored as a page map at the beginning of each chunk.
2. We're using `posix_memalign` to request memory. This means that the
first address must be divisible by the alignment. Our allocation is
page aligned, so if malloc is storing metadata *before* the page,
then we've already crossed page boundaries.
3. Some allocators like glibc will use the memory at the end of the
page. I am able to demonstrate that glibc will return pointers
within the page boundary that contains `heap_page_body`[2]. We
*expected* the allocation to look like this:
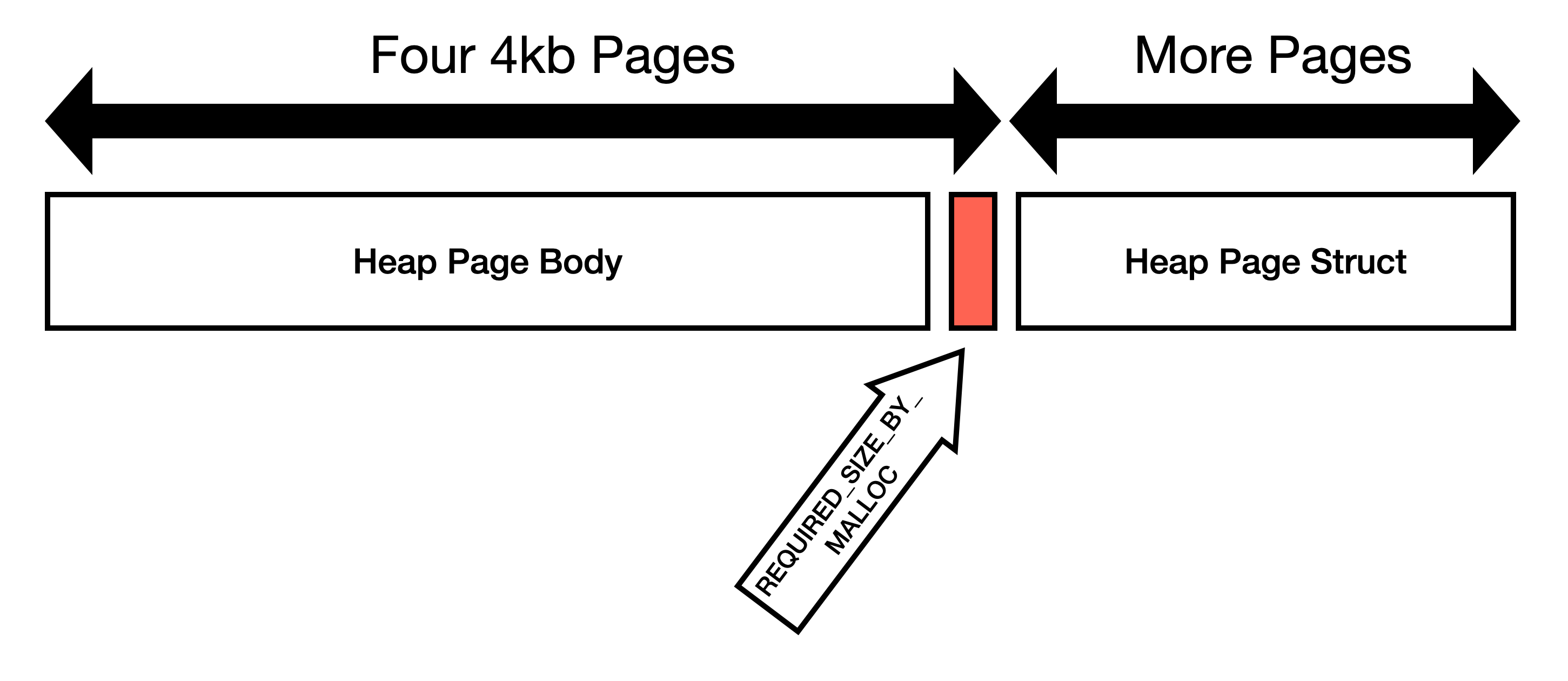
But since `heap_page` is allocated immediately after
`heap_page_body`[3], instead the layout looks like this:
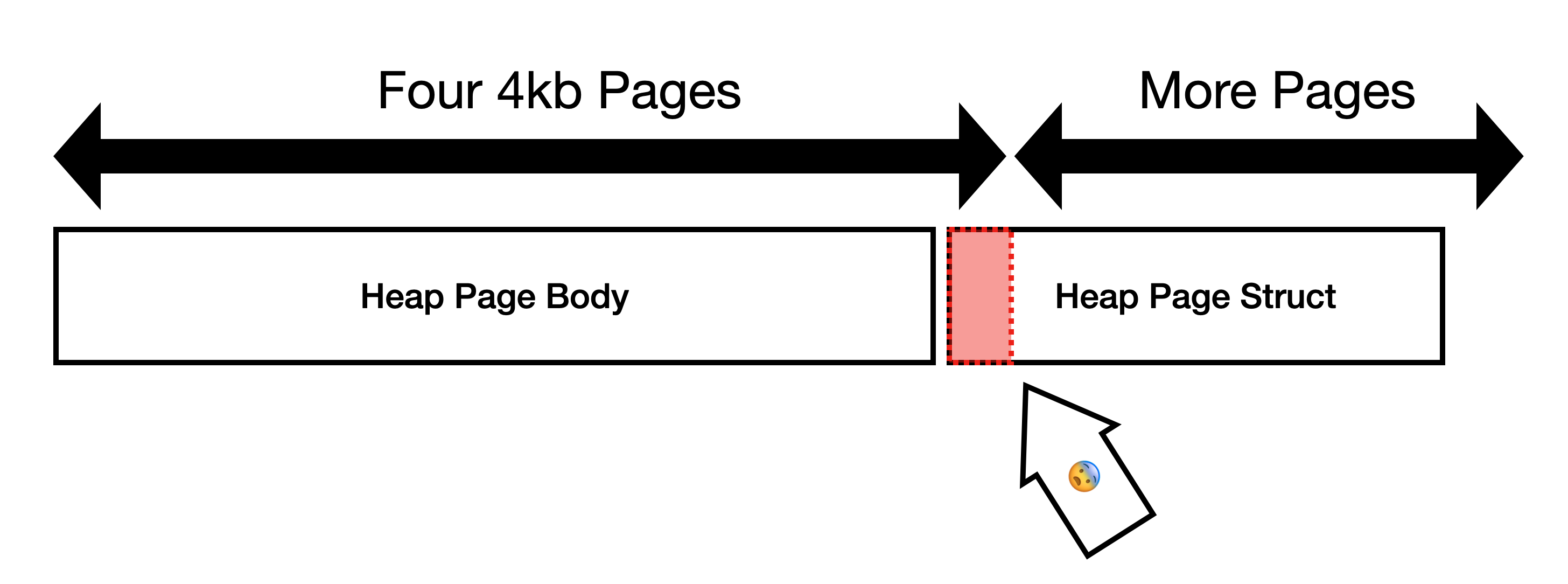
This is not optimal because `heap_page` gets allocated immediately
after `heap_page_body`. We frequently write to `heap_page`, so the
bottom OS page of `heap_page_body` is very likely to be copied.
One more object per page
========================
In jemalloc, allocation requests are rounded to the nearest boundary,
which in this case is 16KiB[4], so `REQUIRED_SIZE_BY_MALLOC` space is
just wasted on jemalloc.
On glibc, the space is not wasted, but instead it is very likely to
cause page faults.
Instead of wasting space or causing page faults, lets just use the space
to store one more Ruby object. Using the space to store one more Ruby
object will prevent page faults, stop wasting space, decrease memory
usage, decrease GC time, etc.
1. https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
2. 33390d15e7
3 289a28e68f/gc.c (L1757-L1763)
4. https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf page 4
Co-authored-by: John Hawthorn <john@hawthorn.email>
This commit converts RMoved slots to a doubly linked list. I want to
convert this to a doubly linked list because the read barrier (currently
in development) must remove nodes from the moved list sometimes.
Removing nodes from the list is much easier if the list is doubly
linked. In addition, we can reuse the list manipulation routines.
Ensure that the argument is an Integer or implicitly convert to,
before dereferencing as a Bignum. Addressed a regression in
b99833baec.
Reported by u75615 at https://hackerone.com/reports/898614
This reverts commit 02b216e5a7.
This reverts commit 9b8825b6f9.
I found that combining sweep and move is not safe. I don't think that
we can do compaction concurrently with _anything_ unless there is a read
barrier installed.
Here is a simple example. A class object is freed, and during it's free
step, it tries to remove itself from its parent's subclass list.
However, during the sweep step, the parent class was moved and the
"currently being freed" class didn't have references updated yet. So we
get a segv like this:
```
(lldb) bt
* thread #1, name = 'ruby', stop reason = signal SIGSEGV
* frame #0: 0x0000560763e344cb ruby`rb_st_lookup at st.c:320:43
frame #1: 0x0000560763e344cb ruby`rb_st_lookup(tab=0x2f7469672f6e6f72, key=3809, value=0x0000560765bf2270) at st.c:1010
frame #2: 0x0000560763e8f16a ruby`rb_search_class_path at variable.c:99:9
frame #3: 0x0000560763e8f141 ruby`rb_search_class_path at variable.c:145
frame #4: 0x0000560763e8f141 ruby`rb_search_class_path(klass=94589785585880) at variable.c:191
frame #5: 0x0000560763ec744e ruby`rb_vm_bugreport at vm_dump.c:996:17
frame #6: 0x0000560763f5b958 ruby`rb_bug_for_fatal_signal at error.c:675:5
frame #7: 0x0000560763e27dad ruby`sigsegv(sig=<unavailable>, info=<unavailable>, ctx=<unavailable>) at signal.c:955:5
frame #8: 0x00007f8b891d33c0 libpthread.so.0`___lldb_unnamed_symbol1$$libpthread.so.0 + 1
frame #9: 0x0000560763efa8bb ruby`rb_class_remove_from_super_subclasses(klass=94589790314280) at class.c:93:56
frame #10: 0x0000560763d10cb7 ruby`gc_sweep_step at gc.c:2674:2
frame #11: 0x0000560763d1187b ruby`gc_sweep at gc.c:4540:2
frame #12: 0x0000560763d101f0 ruby`gc_start at gc.c:6797:6
frame #13: 0x0000560763d15153 ruby`rb_gc_compact at gc.c:7479:12
frame #14: 0x0000560763eb4eb8 ruby`vm_exec_core at vm_insnhelper.c:5183:13
frame #15: 0x0000560763ea9bae ruby`rb_vm_exec at vm.c:1953:22
frame #16: 0x0000560763eac08d ruby`rb_yield at vm.c:1132:9
frame #17: 0x0000560763edb4f2 ruby`rb_ary_collect at array.c:3186:9
frame #18: 0x0000560763e9ee15 ruby`vm_call_cfunc_with_frame at vm_insnhelper.c:2575:12
frame #19: 0x0000560763eb2e66 ruby`vm_exec_core at vm_insnhelper.c:4177:11
frame #20: 0x0000560763ea9bae ruby`rb_vm_exec at vm.c:1953:22
frame #21: 0x0000560763eac08d ruby`rb_yield at vm.c:1132:9
frame #22: 0x0000560763edb4f2 ruby`rb_ary_collect at array.c:3186:9
frame #23: 0x0000560763e9ee15 ruby`vm_call_cfunc_with_frame at vm_insnhelper.c:2575:12
frame #24: 0x0000560763eb2e66 ruby`vm_exec_core at vm_insnhelper.c:4177:11
frame #25: 0x0000560763ea9bae ruby`rb_vm_exec at vm.c:1953:22
frame #26: 0x0000560763ceee01 ruby`rb_ec_exec_node(ec=0x0000560765afa530, n=0x0000560765b088e0) at eval.c:296:2
frame #27: 0x0000560763cf3b7b ruby`ruby_run_node(n=0x0000560765b088e0) at eval.c:354:12
frame #28: 0x0000560763cee4a3 ruby`main(argc=<unavailable>, argv=<unavailable>) at main.c:50:9
frame #29: 0x00007f8b88e560b3 libc.so.6`__libc_start_main + 243
frame #30: 0x0000560763cee4ee ruby`_start + 46
(lldb) f 9
frame #9: 0x0000560763efa8bb ruby`rb_class_remove_from_super_subclasses(klass=94589790314280) at class.c:93:56
90
91 *RCLASS_EXT(klass)->parent_subclasses = entry->next;
92 if (entry->next) {
-> 93 RCLASS_EXT(entry->next->klass)->parent_subclasses = RCLASS_EXT(klass)->parent_subclasses;
94 }
95 xfree(entry);
96 }
(lldb) command script import -r misc/lldb_cruby.py
lldb scripts for ruby has been installed.
(lldb) rp entry->next->klass
(struct RMoved) $1 = (flags = 30, destination = 94589792806680, next = 94589784369160)
(lldb)
```
We don't need to resolve symbols when freeing cc tables, so this commit
just changes the id table iterator to look at values rather than keys
and values.
This commit combines the sweep step with moving objects. With this
commit, we can do:
```ruby
GC.start(compact: true)
```
This code will do the following 3 steps:
1. Fully mark the heap
2. Sweep + Move objects
3. Update references
By default, this will compact in order that heap pages are allocated.
In other words, objects will be packed towards older heap pages (as
opposed to heap pages with more pinned objects like `GC.compact` does).
If a module has an origin, and that module is included in another
module or class, previously the iclass created for the module had
an origin pointer to the module's origin instead of the iclass's
origin.
Setting the origin pointer correctly requires using a stack, since
the origin iclass is not created until after the iclass itself.
Use a hidden ruby array to implement that stack.
Correctly assigning the origin pointers in the iclass caused a
use-after-free in GC. If a module with an origin is included
in a class, the iclass shares a method table with the module
and the iclass origin shares a method table with module origin.
Mark iclass origin with a flag that notes that even though the
iclass is an origin, it shares a method table, so the method table
should not be garbage collected. The shared method table will be
garbage collected when the module origin is garbage collected.
I've tested that this does not introduce a memory leak.
This change caused a VM assertion failure, which was traced to callable
method entries using the incorrect defined_class. Update
rb_vm_check_redefinition_opt_method and find_defined_class_by_owner
to treat iclass origins different than class origins to avoid this
issue.
This also includes a fix for Module#included_modules to skip
iclasses with origins.
Fixes [Bug #16736]
If a module has an origin, and that module is included in another
module or class, previously the iclass created for the module had
an origin pointer to the module's origin instead of the iclass's
origin.
Setting the origin pointer correctly requires using a stack, since
the origin iclass is not created until after the iclass itself.
Use a hidden ruby array to implement that stack.
Correctly assigning the origin pointers in the iclass caused a
use-after-free in GC. If a module with an origin is included
in a class, the iclass shares a method table with the module
and the iclass origin shares a method table with module origin.
Mark iclass origin with a flag that notes that even though the
iclass is an origin, it shares a method table, so the method table
should not be garbage collected. The shared method table will be
garbage collected when the module origin is garbage collected.
I've tested that this does not introduce a memory leak.
This also includes a fix for Module#included_modules to skip
iclasses with origins.
Fixes [Bug #16736]
Ruby's GC is incremental, meaning that during the mark phase (and also
the sweep phase) programs are allowed to run. This means that programs
can allocate objects before the mark or sweep phase have actually
completed. Those objects may not have had a chance to be marked, so we
can't know if they are movable or not. Something that references the
newly created object might have called the pinning function during the
mark phase, but since the mark phase hasn't run we can't know if there
is a "pinning" relationship.
To be conservative, we must only allow objects that are not pinned but
also marked to move.
This patch allows global variables that have been assigned in Ruby to
move. I added a new function for the GC to call that will update
global references and introduced a new callback in the global variable
struct for updating references.
Only pure Ruby global variables are supported right now, other
references will be pinned.
No objects should ever reference a `T_MOVED` slot. If they do, it's
absolutely a bug. If we kill the process when `T_MOVED` is pushed on
the mark stack it will make it easier to identify which object holds a
reference that hasn't been updated.
We only need to loop `T_MASK` times once. Also, not every value between
0 and `T_MASK` is an actual Ruby type. Before this change, some
integers were being added to the result hash even though they aren't
actual types. This patch omits considered / moved entries that total 0,
cleaning up the result hash and eliminating these "fake types".
This compile-time option has been broken for years (at least since
commit 49369ef173, according to git
bisect). Let's delete codes that no longer works.
ISO/IEC 9899:1999 section 6.10.3 paragraph 11 explicitly states that
"If there are sequences of preprocessing tokens within the list of
arguments that would otherwise act as preprocessing directives, the
behavior is undefined."
rb_str_new_cstr is in fact a macro. We cannot do this.
This patch contains several ideas:
(1) Disposable inline method cache (IMC) for race-free inline method cache
* Making call-cache (CC) as a RVALUE (GC target object) and allocate new
CC on cache miss.
* This technique allows race-free access from parallel processing
elements like RCU.
(2) Introduce per-Class method cache (pCMC)
* Instead of fixed-size global method cache (GMC), pCMC allows flexible
cache size.
* Caching CCs reduces CC allocation and allow sharing CC's fast-path
between same call-info (CI) call-sites.
(3) Invalidate an inline method cache by invalidating corresponding method
entries (MEs)
* Instead of using class serials, we set "invalidated" flag for method
entry itself to represent cache invalidation.
* Compare with using class serials, the impact of method modification
(add/overwrite/delete) is small.
* Updating class serials invalidate all method caches of the class and
sub-classes.
* Proposed approach only invalidate the method cache of only one ME.
See [Feature #16614] for more details.
Now, rb_call_info contains how to call the method with tuple of
(mid, orig_argc, flags, kwarg). Most of cases, kwarg == NULL and
mid+argc+flags only requires 64bits. So this patch packed
rb_call_info to VALUE (1 word) on such cases. If we can not
represent it in VALUE, then use imemo_callinfo which contains
conventional callinfo (rb_callinfo, renamed from rb_call_info).
iseq->body->ci_kw_size is removed because all of callinfo is VALUE
size (packed ci or a pointer to imemo_callinfo).
To access ci information, we need to use these functions:
vm_ci_mid(ci), _flag(ci), _argc(ci), _kwarg(ci).
struct rb_call_info_kw_arg is renamed to rb_callinfo_kwarg.
rb_funcallv_with_cc() and rb_method_basic_definition_p_with_cc()
is temporary removed because cd->ci should be marked.
On s390x, TestFiber#test_stack_size fails with SEGV.
https://rubyci.org/logs/rubyci.s3.amazonaws.com/rhel_zlinux/ruby-master/log/20200205T223421Z.fail.html.gz
```
TestFiber#test_stack_size [/home/chkbuild/build/20200205T223421Z/ruby/test/ruby/test_fiber.rb:356]:
pid 23844 killed by SIGABRT (signal 6) (core dumped)
| -e:1:in `times': stack level too deep (SystemStackError)
| from -e:1:in `rec'
| from -e:1:in `block (3 levels) in rec'
| from -e:1:in `times'
| from -e:1:in `block (2 levels) in rec'
| from -e:1:in `times'
| from -e:1:in `block in rec'
| from -e:1:in `times'
| from -e:1:in `rec'
| ... 172 levels...
| from -e:1:in `block in rec'
| from -e:1:in `times'
| from -e:1:in `rec'
| from -e:1:in `block in <main>'
| -e: [BUG] Segmentation fault at 0x0000000000000000
```
This change tries a similar fix with
ef64ab917e and
3ddbba84b5.
Saves comitters' daily life by avoid #include-ing everything from
internal.h to make each file do so instead. This would significantly
speed up incremental builds.
We take the following inclusion order in this changeset:
1. "ruby/config.h", where _GNU_SOURCE is defined (must be the very
first thing among everything).
2. RUBY_EXTCONF_H if any.
3. Standard C headers, sorted alphabetically.
4. Other system headers, maybe guarded by #ifdef
5. Everything else, sorted alphabetically.
Exceptions are those win32-related headers, which tend not be self-
containing (headers have inclusion order dependencies).
One day, I could not resist the way it was written. I finally started
to make the code clean. This changeset is the beginning of a series of
housekeeping commits. It is a simple refactoring; split internal.h into
files, so that we can divide and concur in the upcoming commits. No
lines of codes are either added or removed, except the obvious file
headers/footers. The generated binary is identical to the one before.
I am trying to fix this error:
http://ci.rvm.jp/results/trunk-gc_compact@silicon-docker/2491596
Somehow we have a page in the `free_pages` list that is full. This
commit refactors the code so that any time we add a page to the
`free_pages` list, we do it via `heap_add_freepage`. That function then
asserts that the free slots on that page are not 0.
This changeset makes no difference unless GC_DEBUG is on. When that flag is
set, struct RVALUE is bigger than struct RObject. We have to take care of the
additional fields. Otherwise we get a SIGSEGV like shown below.
The way obj is initialized in this patch works for both GC_DEBUG is on and off.
See also ISO/IEC 9899:1999 section 6.7.8 paragraph #21.
```
Program received signal SIGSEGV, Segmentation fault.
__strlen_avx2 () at ../sysdeps/x86_64/multiarch/strlen-avx2.S:62
62 ../sysdeps/x86_64/multiarch/strlen-avx2.S: No such file or directory
(gdb) bt
#0 __strlen_avx2 () at ../sysdeps/x86_64/multiarch/strlen-avx2.S:62
#1 0x00005555557dd9a7 in BSD_vfprintf (fp=0x7fffffff6be0, fmt0=0x5555558f3059 "@%s:%d", ap=0x7fffffff6dd0) at vsnprintf.c:1027
#2 0x00005555557db6f5 in ruby_do_vsnprintf (str=0x555555bfc58d <obj_info_buffers+1325> "", n=211, fmt=0x5555558f3059 "@%s:%d", ap=0x7fffffff6dd0) at sprintf.c:1022
#3 0x00005555557db909 in ruby_snprintf (str=0x555555bfc58d <obj_info_buffers+1325> "", n=211, fmt=0x5555558f3059 "@%s:%d") at sprintf.c:1040
#4 0x0000555555661ef4 in rb_raw_obj_info (buff=0x555555bfc560 <obj_info_buffers+1280> "0x0000555555d2bfa0 [0 ] T_STRING (String)", buff_size=256, obj=93825000456096) at gc.c:11449
#5 0x000055555565baaf in obj_info (obj=93825000456096) at gc.c:11612
#6 0x000055555565bae1 in rgengc_remembered (objspace=0x555555c0a1c0, obj=93825000456096) at gc.c:6618
#7 0x0000555555666987 in newobj_init (klass=93824999964192, flags=5, v1=0, v2=0, v3=0, wb_protected=1, objspace=0x555555c0a1c0, obj=93825000456096) at gc.c:2134
#8 0x0000555555666e49 in newobj_slowpath (klass=93824999964192, flags=5, v1=0, v2=0, v3=0, objspace=0x555555c0a1c0, wb_protected=1) at gc.c:2209
#9 0x0000555555666b94 in newobj_slowpath_wb_protected (klass=93824999964192, flags=5, v1=0, v2=0, v3=0, objspace=0x555555c0a1c0) at gc.c:2220
#10 0x000055555565751b in newobj_of (klass=93824999964192, flags=5, v1=0, v2=0, v3=0, wb_protected=1) at gc.c:2256
#11 0x00005555556575ca in rb_wb_protected_newobj_of (klass=93824999964192, flags=5) at gc.c:2272
#12 0x00005555557f36ea in str_alloc (klass=93824999964192) at string.c:728
#13 0x00005555557f2128 in rb_str_buf_new (capa=0) at string.c:1317
#14 0x000055555578c66d in rb_reg_preprocess (p=0x555555cc8148 "^-(.)(.+)?", end=0x555555cc8152 "", enc=0x555555cc7c80, fixed_enc=0x7fffffff74e8, err=0x7fffffff75f0 "") at re.c:2682
#15 0x000055555578ea13 in rb_reg_initialize (obj=93825000046736, s=0x555555cc8148 "^-(.)(.+)?", len=10, enc=0x555555cc7c80, options=0, err=0x7fffffff75f0 "", sourcefile=0x555555d1a5c0 "lib/optparse.rb", sourceline=1460) at re.c:2808
#16 0x000055555578e285 in rb_reg_initialize_str (obj=93825000046736, str=93825000046904, options=0, err=0x7fffffff75f0 "", sourcefile=0x555555d1a5c0 "lib/optparse.rb", sourceline=1460) at re.c:2869
#17 0x000055555578ee02 in rb_reg_compile (str=93825000046904, options=0, sourcefile=0x555555d1a5c0 "lib/optparse.rb", sourceline=1460) at re.c:2958
#18 0x0000555555748dfb in rb_parser_reg_compile (p=0x555555d1f760, str=93825000046904, options=0) at parse.y:12157
#19 0x00005555557581c3 in parser_reg_compile (p=0x555555d1f760, str=93825000046904, options=0) at parse.y:12151
#20 0x00005555557580ac in reg_compile (p=0x555555d1f760, str=93825000046904, options=0) at parse.y:12167
#21 0x0000555555746ebb in new_regexp (p=0x555555d1f760, node=0x555555dece68, options=0, loc=0x7fffffff89e8) at parse.y:10072
#22 0x000055555573d1f5 in ruby_yyparse (p=0x555555d1f760) at parse.y:4395
#23 0x000055555574a582 in yycompile0 (arg=93825000404832) at parse.y:5945
#24 0x00005555558c6898 in rb_suppress_tracing (func=0x55555574a470 <yycompile0>, arg=93825000404832) at vm_trace.c:427
#25 0x0000555555748290 in yycompile (vparser=93824999283456, p=0x555555d1f760, fname=93824999283624, line=1) at parse.y:5994
#26 0x00005555557481ae in rb_parser_compile_file_path (vparser=93824999283456, fname=93824999283624, file=93824999283400, start=1) at parse.y:6098
#27 0x00005555557cdd35 in load_file_internal (argp_v=140737488331760) at ruby.c:2023
#28 0x00005555556438c5 in rb_ensure (b_proc=0x5555557cd610 <load_file_internal>, data1=140737488331760, e_proc=0x5555557cddd0 <restore_load_file>, data2=140737488331760) at eval.c:1128
#29 0x00005555557cb68b in load_file (parser=93824999283456, fname=93824999283624, f=93824999283400, script=0, opt=0x7fffffffa468) at ruby.c:2142
#30 0x00005555557cb339 in rb_parser_load_file (parser=93824999283456, fname_v=93824999283624) at ruby.c:2164
#31 0x00005555556ba3e1 in load_iseq_eval (ec=0x555555c0a650, fname=93824999283624) at load.c:579
#32 0x00005555556b857a in require_internal (ec=0x555555c0a650, fname=93824999284352, exception=1) at load.c:1016
#33 0x00005555556b7967 in rb_require_string (fname=93824999284464) at load.c:1105
#34 0x00005555556b7939 in rb_f_require (obj=93824999994824, fname=93824999284464) at load.c:811
#35 0x00005555558b7ae0 in call_cfunc_1 (recv=93824999994824, argc=1, argv=0x7ffff7ecd0a8, func=0x5555556b7920 <rb_f_require>) at vm_insnhelper.c:2348
#36 0x00005555558a8889 in vm_call_cfunc_with_frame (ec=0x555555c0a650, reg_cfp=0x7ffff7fccfa0, calling=0x7fffffffaab0, cd=0x555555d76a10, empty_kw_splat=0) at vm_insnhelper.c:2513
#37 0x000055555589fb5c in vm_call_cfunc (ec=0x555555c0a650, reg_cfp=0x7ffff7fccfa0, calling=0x7fffffffaab0, cd=0x555555d76a10) at vm_insnhelper.c:2538
#38 0x000055555589f22e in vm_call_method_each_type (ec=0x555555c0a650, cfp=0x7ffff7fccfa0, calling=0x7fffffffaab0, cd=0x555555d76a10) at vm_insnhelper.c:2924
#39 0x000055555589ef47 in vm_call_method (ec=0x555555c0a650, cfp=0x7ffff7fccfa0, calling=0x7fffffffaab0, cd=0x555555d76a10) at vm_insnhelper.c:3038
#40 0x0000555555866dbd in vm_call_general (ec=0x555555c0a650, reg_cfp=0x7ffff7fccfa0, calling=0x7fffffffaab0, cd=0x555555d76a10) at vm_insnhelper.c:3075
#41 0x00005555558ae557 in vm_sendish (ec=0x555555c0a650, reg_cfp=0x7ffff7fccfa0, cd=0x555555d76a10, block_handler=0, method_explorer=0x5555558ae5d0 <vm_search_method_wrap>) at vm_insnhelper.c:4021
#42 0x000055555587745b in vm_exec_core (ec=0x555555c0a650, initial=0) at insns.def:801
#43 0x0000555555899b9c in rb_vm_exec (ec=0x555555c0a650, mjit_enable_p=1) at vm.c:1907
#44 0x000055555589aaf0 in rb_iseq_eval_main (iseq=0x555555c1da80) at vm.c:2166
#45 0x0000555555641f0b in rb_ec_exec_node (ec=0x555555c0a650, n=0x555555c1da80) at eval.c:277
#46 0x0000555555641d62 in ruby_run_node (n=0x555555c1da80) at eval.c:335
#47 0x000055555557a188 in main (argc=11, argv=0x7fffffffc848) at main.c:50
(gdb) fr 7
#7 0x0000555555666987 in newobj_init (klass=93824999964192, flags=5, v1=0, v2=0, v3=0, wb_protected=1, objspace=0x555555c0a1c0, obj=93825000456096) at gc.c:2134
2134 if (rgengc_remembered(objspace, (VALUE)obj)) rb_bug("newobj: %s is remembered.", obj_info(obj));
(gdb) p ((struct RVALUE*)obj)->file
$1 = 0x65a5992b0fb25ce7 <error: Cannot access memory at address 0x65a5992b0fb25ce7>
(gdb)
```
Introduce new RUBY_DEBUG option 'ci' to inform Ruby interpreter
that an interpreter is running on CI environment.
With this option, `rb_bug()` shows more information includes
method entry information, local variables information for each
control frame.
Decades ago, among all the data that a class has, its method
table was no doubt the most frequently accessed data. Previous
data structures were based on that assumption.
Today that is no longer true. The most frequently accessed field
moved to class_serial. That field is not always as wide as VALUE
but if it is, let us swap m_tbl and class_serial.
Calculating -------------------------------------
ours trunk
Optcarrot Lan_Master.nes 47.363 46.630 fps
Comparison:
Optcarrot Lan_Master.nes
ours: 47.4 fps
trunk: 46.6 fps - 1.02x slower
This is significantly faster than checking BUILTIN_TYPEs because we
access significantly less memory. We also use popcount to count entire
words at a time.
The only functional difference from the previous implementation is that
T_ZOMBIE objects will no longer be counted. However those are temporary
objects which should be small in number, and this method has always been
an estimate.
Previously we would count the pinned objects on each comparison. Since
sorting is O(N log N) and we calculated this on both left and right
pages on each comparison this resulted in a extra iterations over the
slots.
These functions are used from within a compilation unit so we can
make them static, for better binary size. This changeset reduces
the size of generated ruby binary from 26,590,128 bytes to
26,584,472 bytes on my macihne.
This removes the related tests, and puts the related specs behind
version guards. This affects all code in lib, including some
libraries that may want to support older versions of Ruby.
This removes the security features added by $SAFE = 1, and warns for access
or modification of $SAFE from Ruby-level, as well as warning when calling
all public C functions related to $SAFE.
This modifies some internal functions that took a safe level argument
to no longer take the argument.
rb_require_safe now warns, rb_require_string has been added as a
version that takes a VALUE and does not warn.
One public C function that still takes a safe level argument and that
this doesn't warn for is rb_eval_cmd. We may want to consider
adding an alternative method that does not take a safe level argument,
and warn for rb_eval_cmd.
Previously we were passing the memory_id. This was broken previously if
compaction was run (which changes the memory_id) and now that object_id
is a monotonically increasing number it was always broken.
This commit fixes this by defering removal from the object_id table
until finalizers have run (for objects with finalizers) and also copying
the SEEN_OBJ_ID flag onto the zombie objects.
This changes object_id from being based on the objects location in
memory (or a nearby memory location in the case of a conflict) to be
based on an always increasing number.
This number is a Ruby Integer which allows it to overflow the size of a
pointer without issue (very unlikely to happen in real programs
especially on 64-bit, but a nice guarantee).
This changes obj_to_id_tbl and id_to_obj_tbl to both be maps of Ruby
objects to Ruby objects (previously they were Ruby object to C integer)
which simplifies updating them after compaction as we can run them
through gc_update_table_refs.
Co-authored-by: Aaron Patterson <tenderlove@ruby-lang.org>
This changes object_id from being based on the objects location in
memory (or a nearby memory location in the case of a conflict) to be
based on an always increasing number.
This number is a Ruby Integer which allows it to overflow the size of a
pointer without issue (very unlikely to happen in real programs
especially on 64-bit, but a nice guarantee).
This changes obj_to_id_tbl and id_to_obj_tbl to both be maps of Ruby
objects to Ruby objects (previously they were Ruby object to C integer)
which simplifies updating them after compaction as we can run them
through gc_update_table_refs.
Co-authored-by: Aaron Patterson <tenderlove@ruby-lang.org>
This commit is to attempt fixing this error:
http://ci.rvm.jp/results/trunk-gc-asserts@ruby-sky1/2353281
Each non-full heap_page struct contains a reference to the next page
that contains free slots. Compaction could fill any page, including
pages that happen to be linked to as "pages which contain free slots".
To fix this, we'll iterate each page, and rebuild the "free page list"
depending on the number of actual free slots on that page. If there are
no free slots on the page, we'll set the free_next pointer to NULL.
Finally we'll pop one page off the "free page list" and set it as the
"using page" for the next allocation.
This commit is to attempt fixing this error:
http://ci.rvm.jp/results/trunk-gc-asserts@ruby-sky1/2353281
Each non-full heap_page struct contains a reference to the next page
that contains free slots. Compaction could fill any page, including
pages that happen to be linked to as "pages which contain free slots".
To fix this, we'll iterate each page, and rebuild the "free page list"
depending on the number of actual free slots on that page. If there are
no free slots on the page, we'll set the free_next pointer to NULL.
Finally we'll pop one page off the "free page list" and set it as the
"using page" for the next allocation.
When we compact the heap, various st tables are updated, particularly
the table that contains the object id map. Updating an st table can
cause a GC to occur, and we need to prevent any GC from happening while
moving or updating references.
This reverts commit 60a7f9f446.
We can't have Ruby objects pointing at T_ZOMBIE objects otherwise we get
an error in the GC. We need to find a different way to update
references.
When we run finalizers we have to copy all of the finalizers to a new
data structure because a finalizer could add another finalizer and we
need to keep draining the "real" finalizer table until it's empty.
We don't want Ruby programs to mutate the finalizers that we're
iterating over as well.
Before this commit we would copy the finalizers in to a linked list.
The problem with this approach is that if compaction happens, the linked
list will need to be updated. But the GC doesn't know about the
existence of the linked list, so it could not update references. This
commit changes the linked list to be a Ruby array so that when
compaction happens, the arrays will automatically be updated and all
references remain valid.
Simple comparison between proc/ifunc/method invocations:
```
proc 15.209M (± 1.6%) i/s - 76.138M in 5.007413s
ifunc 15.195M (± 1.7%) i/s - 76.257M in 5.020106s
method 9.836M (± 1.2%) i/s - 49.272M in 5.009984s
```
As `proc` and `ifunc` have no significant difference, chosen the
latter for arity check.
Requested by ko1 that ability of calling rb_raise from anywhere
outside of GVL is "too much". Give up that part, move the GVL
aquisition routine into gc.c, and make our new gc_raise().
Now that allocation routines like ALLOC_N() can raise exceptions
on integer overflows. This is a problem when the calling thread
has no GVL. Memory allocations has been allowed without it, but
can still fail.
Let's just relax rb_raise's restriction so that we can call it
with or without GVL. With GVL the behaviour is unchanged. With
no GVL, wait for it.
Also, integer overflows can theoretically occur during GC when
we expand the object space. We cannot do so much then. Call
rb_memerror and let that routine abort the process.
This changeset is to kill future possibility of bugs similar to
CVE-2019-11932. The vulnerability occurs when reallocarray(3)
(which is a variant of realloc(3) and roughly resembles our
ruby_xmalloc2()) returns NULL. In our C API, ruby_xmalloc()
never returns NULL to raise NoMemoryError instead. ruby_xfree()
does not return NULL by definition. ruby_xrealloc() on the other
hand, _did_ return NULL, _and_ also raised sometimes. It is very
confusing. Let's not do that. x-series APIs shall raise on
error and shall not return NULL.
This changeset basically replaces `ruby_xmalloc(x * y)` into
`ruby_xmalloc2(x, y)`. Some convenient functions are also
provided for instance `rb_xmalloc_mul_add(x, y, z)` which allocates
x * y + z byes.
I'd like to call `gc_compact` after major GC, but before the GC
finishes. This means we can't allocate any objects inside `gc_compact`.
So in this commit I'm just pulling the compaction statistics allocation
outside the `gc_compact` function so we can safely call it.
This function has been used wrongly always at first, "allocate a
buffer then wrap it with tmpbuf". This order can cause a memory
leak, as tmpbuf creation also can raise a NoMemoryError exception.
The right order is "create a tmpbuf then allocate&wrap a buffer".
So the argument of this function is rather harmful than just
useless.
TODO:
* Rename this function to more proper name, as it is not used
"temporary" (function local) purpose.
* Allocate and wrap at once safely, like `ALLOCV`.
This reverts commits: 10d6a3aca78ba48c1b85fba8627dc1dd883de5ba6c6a25feca167e6b48f17cb96d41a53207979278595b3c4fdd1521f7cf89c11c5e69accf336082033632a812c0f56506be0d86427a3219 .
The reason for the revert is that we observe ABA problem around
inline method cache. When a cache misshits, we search for a
method entry. And if the entry is identical to what was cached
before, we reuse the cache. But the commits we are reverting here
introduced situations where a method entry is freed, then the
identical memory region is used for another method entry. An
inline method cache cannot detect that ABA.
Here is a code that reproduce such situation:
```ruby
require 'prime'
class << Integer
alias org_sqrt sqrt
def sqrt(n)
raise
end
GC.stress = true
Prime.each(7*37){} rescue nil # <- Here we populate CC
class << Object.new; end
# These adjacent remove-then-alias maneuver
# frees a method entry, then immediately
# reuses it for another.
remove_method :sqrt
alias sqrt org_sqrt
end
Prime.each(7*37).to_a # <- SEGV
```
Now that we have eliminated most destructive operations over the
rb_method_entry_t / rb_callable_method_entry_t, let's make them
mostly immutabe and mark them const.
One exception is rb_export_method(), which destructively modifies
visibilities of method entries. I have left that operation as is
because I suspect that destructiveness is the nature of that
function.
Most (if not all) of the fields of rb_method_definition_t are never
meant to be modified once after they are stored. Marking them const
makes it possible for compilers to warn on unintended modifications.
[feature #16035]
This goes one step farther than what nobu did in [feature #13498]
With this patch, special objects such as static symbols, integers, etc can be used as either key or values inside WeakMap. They simply don't have a finalizer defined on them.
This is useful if you need to deduplicate value objects
After 5e86b005c0, I now think ANYARGS is
dangerous and should be extinct. This commit deletes ANYARGS from
st_foreach. I strongly believe that this commit should have had come
with b0af0592fd, which added extra
parameter to st_foreach callbacks.
After 5e86b005c0, I now think ANYARGS is
dangerous and should be extinct. This commit deletes ANYARGS from
rb_proc_new / rb_fiber_new, and applies RB_BLOCK_CALL_FUNC_ARGLIST
wherever necessary.
After 5e86b005c0, I now think ANYARGS is
dangerous and should be extinct. This commit deletes ANYARGS from
rb_ensure, which also revealed many arity / type mismatches.
I'm afraid the keys to this hash are just integers, and those integers
may look like VALUE pointers when they are not. Since we don't mark the
keys to this hash, it's probably safe to say that none of them have
moved, so we shouldn't try to update the references either.
As `rb_objspace_each_objects_without_setup` doesn't reset and
restore `dont_incremental` flag, renamed the bare iterator as
`objspace_each_objects_without_setup`. `objspace_each_objects`
calls it when called with the flag disabled, wrap the arguments
otherwise only.
Renaming this function. "No pin" leaks some implementation details. We
just want users to know that if they mark this object, the reference may
move and they'll need to update the reference accordingly.
On macOS Mojave, the child process invoked in TestFiber#test_stack_size
gets stuck because the stack overflow detection is too late.
(ko1 figured out the mechanism of the failure.)
This change attempts to detect stack overflow earlier.
The last time we committed this, we were asking the VM to write to the
ep. But VM assertions check if the ENV data is the correct type, which
if it's a T_MOVED pointer it's not the correct type. So the vm
assertions would fail. This time we just directly write to it from the
GC and that bypasses the vm assertion checks.
PC modification in gc_event_hook_body was careless. There are (so
to say) abnormal iseqs stored in the cfp. We have to check sanity
before we touch the PC.
This has not been fixed because there was no way to (ab)use the
setup from pure-Ruby. However by using our official C APIs it is
possible to touch such frame(s), resulting in SEGV.
Fixes [Bug #14834].
RHash::ifnone should be protected by write-barriers so this field
should be const. However, to introduce GC.compact, the const was
removed. This commit revert this removing `const` and modify
gc.c `TYPED_UPDATE_IF_MOVED` to remove `const` forcely by a type cast.
Shared arrays created by Array#dup and so on points
a shared_root object to manage lifetime of Array buffer.
However, sometimes shared_root is called only shared so
it is confusing. So I fixed these wording "shared" to "shared_root".
* RArray::heap::aux::shared -> RArray::heap::aux::shared_root
* ARY_SHARED() -> ARY_SHARED_ROOT()
* ARY_SHARED_NUM() -> ARY_SHARED_ROOT_REFCNT()
Also, add some debug_counters to count shared array objects.
* ary_shared_create: shared ary by Array#dup and so on.
* ary_shared: finished in shard.
* ary_shared_root_occupied: shared_root but has only 1 refcnt.
The number (ary_shared - ary_shared_root_occupied) is meaningful.
It has caused CI failures.
* d0cd0866d8
Disable GC during rb_objspace_reachable_object_p
* 89cef1c56b
Version guard for [Feature #15974]
* 796eeb6339.
Fix up [Feature #15974]
* 928260c2a6.
Warn in verbose mode on defining a finalizer that captures the object
Various things can cause GC to occur when compaction is running, for
example resizing the object identity map:
```
frame #24: 0x000000010c784a10 ruby`gc_grey [inlined] push_mark_stack(stack=<unavailable>, data=<unavailable>) at gc.c:4311:42
frame #25: 0x000000010c7849ff ruby`gc_grey(objspace=0x00007fc56c804400, obj=140485906037400) at gc.c:4907
frame #26: 0x000000010c78f881 ruby`gc_start at gc.c:6464:8
frame #27: 0x000000010c78f5d1 ruby`gc_start [inlined] gc_marks_start(objspace=0x00007fc56c804400, full_mark=<unavailable>) at gc.c:6009
frame #28: 0x000000010c78f3c0 ruby`gc_start at gc.c:6291
frame #29: 0x000000010c78f399 ruby`gc_start(objspace=0x00007fc56c804400, reason=<unavailable>) at gc.c:7104
frame #30: 0x000000010c78930c ruby`objspace_xmalloc0 [inlined] objspace_malloc_fixup(objspace=<unavailable>, mem=0x000000011372a000, size=<unavailable>) at gc.c:9665:5
frame #31: 0x000000010c7892f5 ruby`objspace_xmalloc0(objspace=0x00007fc56c804400, size=12582912) at gc.c:9707
frame #32: 0x000000010c89bc13 ruby`st_init_table_with_size(type=<unavailable>, size=<unavailable>) at st.c:605:39
frame #33: 0x000000010c89c5e2 ruby`rebuild_table_if_necessary [inlined] rebuild_table(tab=0x00007fc56c40b250) at st.c:780:19
frame #34: 0x000000010c89c5ac ruby`rebuild_table_if_necessary(tab=0x00007fc56c40b250) at st.c:1142
frame #35: 0x000000010c89c379 ruby`st_insert(tab=0x00007fc56c40b250, key=140486132605040, value=140485922918920) at st.c:1161:5
frame #36: 0x000000010c794a16 ruby`gc_compact_heap [inlined] gc_move(objspace=0x00007fc56c804400, scan=<unavailable>, free=<unavailable>, moved_list=140485922918960) at gc.c:7441:9
frame #37: 0x000000010c794917 ruby`gc_compact_heap(objspace=0x00007fc56c804400, comparator=<unavailable>) at gc.c:7695
frame #38: 0x000000010c79410d ruby`gc_compact [inlined] gc_compact_after_gc(objspace=0x00007fc56c804400, use_toward_empty=1, use_double_pages=<unavailable>, use_verifier=1) at gc.c:0:22
```
We *definitely* need the heap to be in a consistent state during
compaction, so this commit sets the current state to "during_gc" so that
nothing will trigger a GC until the heap finishes compacting.
This fixes the bug we saw when running the tests for https://github.com/ruby/ruby/pull/2264
{kind=link}
{kind=link}