Fixed notebook markdowns for nbsphinx compatibility
This commit is contained in:
Родитель
908274c8c7
Коммит
919949bf1a
Различия файлов скрыты, потому что одна или несколько строк слишком длинны
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -14,6 +16,8 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"nbpresent": {
|
||||
"id": "29b9bd1d-766f-4422-ad96-de0accc1ce58"
|
||||
}
|
||||
|
|
@ -27,14 +31,17 @@
|
|||
"\n",
|
||||
"**Problem** (recap from CNTK 101):\n",
|
||||
"\n",
|
||||
"A cancer hospital has provided data and wants us to determine if a patient has a fatal [malignant][] cancer vs. a benign growth. This is known as a classification problem. To help classify each patient, we are given their age and the size of the tumor. Intuitively, one can imagine that younger patients and/or patient with small tumor size are less likely to have malignant cancer. The data set simulates this application where the each observation is a patient represented as a dot where red color indicates malignant and blue indicates a benign disease. Note: This is a toy example for learning, in real life there are large number of features from different tests/examination sources and doctors' experience that play into the diagnosis/treatment decision for a patient.\n",
|
||||
"[malignant]: https://en.wikipedia.org/wiki/Malignancy"
|
||||
"A cancer hospital has provided data and wants us to determine if a patient has a fatal [malignant](https://en.wikipedia.org/wiki/Malignancy) cancer vs. a benign growth. This is known as a classification problem. To help classify each patient, we are given their age and the size of the tumor. Intuitively, one can imagine that younger patients and/or patient with small tumor size are less likely to have malignant cancer. The data set simulates this application where the each observation is a patient represented as a dot where red color indicates malignant and blue indicates a benign disease. Note: This is a toy example for learning, in real life there are large number of features from different tests/examination sources and doctors' experience that play into the diagnosis/treatment decision for a patient."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -57,7 +64,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Goal**:\n",
|
||||
"Our goal is to learn a classifier that classifies any patient into either benign or malignant category given two features (age, tumor size). \n",
|
||||
|
|
@ -78,7 +88,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -101,7 +115,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"A feedforward neural network is an artificial neural network where connections between the units **do not** form a cycle.\n",
|
||||
"The feedforward neural network was the first and simplest type of artificial neural network devised. In this network, the information moves in only one direction, forward, from the input nodes, through the hidden nodes (if any) and to the output nodes. There are no cycles or loops in the network\n",
|
||||
|
|
@ -114,6 +131,8 @@
|
|||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"nbpresent": {
|
||||
"id": "138d1a78-02e2-4bd6-a20e-07b83f303563"
|
||||
}
|
||||
|
|
@ -137,7 +156,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data Generation\n",
|
||||
"This section can be *skipped* (next section titled <a href='#Model Creation'>Model Creation</a>) if you have gone through CNTK 101. \n",
|
||||
|
|
@ -151,7 +173,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -165,7 +189,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Input and Labels\n",
|
||||
"\n",
|
||||
|
|
@ -176,7 +203,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -199,7 +228,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -212,7 +243,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us visualize the input data. \n",
|
||||
"\n",
|
||||
|
|
@ -222,7 +256,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -251,9 +289,11 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"<a id='#Model Creation'></a>\n",
|
||||
"## Model Creation\n",
|
||||
"\n",
|
||||
"Our feed forward network will be relatively simple with 2 hidden layers (`num_hidden_layers`) with each layer having 50 hidden nodes (`hidden_layers_dim`)."
|
||||
|
|
@ -262,7 +302,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -285,7 +329,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The number of green nodes (refer to picture above) in each hidden layer is set to 50 in the example and the number of hidden layers (refer to the number of layers of green nodes) is 2. Fill in the following values:\n",
|
||||
"- num_hidden_layers\n",
|
||||
|
|
@ -298,7 +345,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -308,7 +357,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Network input and output: \n",
|
||||
"- **input** variable (a key CNTK concept): \n",
|
||||
|
|
@ -322,7 +374,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -337,7 +391,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Feed forward network setup\n",
|
||||
"Let us define the feedforward network one step at a time. The first layer takes an input feature vector ($\\bf{x}$) with dimensions `input_dim`, say $m$, and emits the output a.k.a. *evidence* (first hidden layer $\\bf{z_1}$ with dimension `hidden_layer_dim`, say $n$). Each feature in the input layer is connected with a node in the output layer by the weight which is represented by a matrix $\\bf{W}$ with dimensions ($m \\times n$). The first step is to compute the evidence for the entire feature set. Note: we use **bold** notations to denote matrix / vectors: \n",
|
||||
|
|
@ -355,7 +412,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -370,10 +429,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The next step is to convert the *evidence* (the output of the linear layer) through a non-linear function a.k.a. *activation functions* of your choice that would squash the evidence to activations using a choice of functions ([found here][]). **Sigmoid** or **Tanh** are historically popular. We will use **sigmoid** function in this tutorial. The output of the sigmoid function often is the input to the next layer or the output of the final layer. \n",
|
||||
"[found here]: https://docs.microsoft.com/en-us/cognitive-toolkit/Brainscript-Activation-Functions \n",
|
||||
"The next step is to convert the *evidence* (the output of the linear layer) through a non-linear function a.k.a. *activation functions* of your choice that would squash the evidence to activations using a choice of functions ([found here](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.Activation)). **Sigmoid** or **Tanh** are historically popular. We will use **sigmoid** function in this tutorial. The output of the sigmoid function often is the input to the next layer or the output of the final layer. \n",
|
||||
"\n",
|
||||
"**Question**: Try different activation functions by passing different them to `nonlinearity` value and get familiarized with using them."
|
||||
]
|
||||
|
|
@ -382,7 +443,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -394,7 +457,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Now that we have created one hidden layer, we need to iterate through the layers to create a fully connected classifier. Output of the first layer $\\bf{h_1}$ becomes the input to the next layer.\n",
|
||||
"\n",
|
||||
|
|
@ -415,7 +481,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -432,7 +500,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The network output `z` will be used to represent the output of a network across."
|
||||
]
|
||||
|
|
@ -441,7 +512,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -452,9 +525,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"While the aforementioned network helps us better understand how to implement a network using CNTK primitives, it is much more convenient and faster to use the [layers library](https://www.cntk.ai/pythondocs/layerref.html). It provides predefined commonly used “layers” (lego like blocks), which simplifies the design of networks that consist of standard layers layered on top of each other. For instance, ``dense_layer`` is already easily accessible through the [`Dense`](https://www.cntk.ai/pythondocs/layerref.html#dense) layer function to compose our deep model. We can pass the input variable (`input`) to this model to get the network output. \n",
|
||||
"While the aforementioned network helps us better understand how to implement a network using CNTK primitives, it is much more convenient and faster to use the [layers library](https://www.cntk.ai/pythondocs/layerref.html). It provides predefined commonly used “layers” (lego like blocks), which simplifies the design of networks that consist of standard layers layered on top of each other. For instance, ``dense_layer`` is already easily accessible through the [Dense](https://www.cntk.ai/pythondocs/layerref.html#dense) layer function to compose our deep model. We can pass the input variable (`input`) to this model to get the network output. \n",
|
||||
"\n",
|
||||
"**Suggested task**: Please go through the model defined above and the output of the `create_model` function and convince yourself that the implementation below encapsulates the code above."
|
||||
]
|
||||
|
|
@ -463,7 +539,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -481,7 +559,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Learning model parameters\n",
|
||||
"\n",
|
||||
|
|
@ -489,16 +570,15 @@
|
|||
"\n",
|
||||
"$$ \\textbf{p} = \\mathrm{softmax}(\\bf{z_{final~layer}})$$ \n",
|
||||
"\n",
|
||||
"One can see the `softmax` function as an activation function that maps the accumulated evidences to a probability distribution over the classes (Details of the [softmax function][]). Other choices of activation function can be [found here][].\n",
|
||||
"\n",
|
||||
"[softmax function]: https://www.cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax\n",
|
||||
"\n",
|
||||
"[found here]: https://docs.microsoft.com/en-us/cognitive-toolkit/Brainscript-Activation-Functions"
|
||||
"One can see the `softmax` function as an activation function that maps the accumulated evidences to a probability distribution over the classes (Details of the [softmax function](https://www.cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax)). Other choices of activation function can be [found here](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.Activation)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Training\n",
|
||||
"\n",
|
||||
|
|
@ -509,17 +589,16 @@
|
|||
"\n",
|
||||
"$$ H(p) = - \\sum_{j=1}^C y_j \\log (p_j) $$ \n",
|
||||
"\n",
|
||||
"where $p$ is our predicted probability from `softmax` function and $y$ represents the label. This label provided with the data for training is also called the ground-truth label. In the two-class example, the `label` variable has dimensions of two (equal to the `num_output_classes` or $C$). Generally speaking, if the task in hand requires classification into $C$ different classes, the label variable will have $C$ elements with 0 everywhere except for the class represented by the data point where it will be 1. Understanding the [details][] of this cross-entropy function is highly recommended.\n",
|
||||
"\n",
|
||||
"[`cross-entropy`]: http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.cross_entropy_with_softmax\n",
|
||||
"[details]: http://colah.github.io/posts/2015-09-Visual-Information/"
|
||||
"where $p$ is our predicted probability from `softmax` function and $y$ represents the label. This label provided with the data for training is also called the ground-truth label. In the two-class example, the `label` variable has dimensions of two (equal to the `num_output_classes` or $C$). Generally speaking, if the task in hand requires classification into $C$ different classes, the label variable will have $C$ elements with 0 everywhere except for the class represented by the data point where it will be 1. Understanding the [details](http://colah.github.io/posts/2015-09-Visual-Information/) of this cross-entropy function is highly recommended."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -528,9 +607,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Evaluation\n",
|
||||
"### Evaluation\n",
|
||||
"\n",
|
||||
"In order to evaluate the classification, one can compare the output of the network which for each observation emits a vector of evidences (can be converted into probabilities using `softmax` functions) with dimension equal to number of classes."
|
||||
]
|
||||
|
|
@ -539,7 +621,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -548,29 +632,30 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Configure training\n",
|
||||
"\n",
|
||||
"The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent][] (`sgd`) being one of the most popular one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent][] generate a new set model parameters in a single iteration. \n",
|
||||
"The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent](https://en.wikipedia.org/wiki/Stochastic_gradient_descent) (`sgd`) being one of the most popular one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent](http://www.statisticsviews.com/details/feature/5722691/Getting-to-the-Bottom-of-Regression-with-Gradient-Descent.html) generate a new set model parameters in a single iteration. \n",
|
||||
"\n",
|
||||
"The aforementioned model parameter update using a single observation at a time is attractive since it does not require the entire data set (all observation) to be loaded in memory and also requires gradient computation over fewer datapoints, thus allowing for training on large data sets. However, the updates generated using a single observation sample at a time can vary wildly between iterations. An intermediate ground is to load a small set of observations and use an average of the `loss` or error from that set to update the model parameters. This subset is called a *minibatch*.\n",
|
||||
"\n",
|
||||
"With minibatches we often sample observation from the larger training dataset. We repeat the process of model parameters update using different combination of training samples and over a period of time minimize the `loss` (and the error). When the incremental error rates are no longer changing significantly or after a preset number of maximum minibatches to train, we claim that our model is trained.\n",
|
||||
"\n",
|
||||
"One of the key parameter for optimization is called the `learning_rate`. For now, we can think of it as a scaling factor that modulates how much we change the parameters in any iteration. We will be covering more details in later tutorial. \n",
|
||||
"With this information, we are ready to create our trainer.\n",
|
||||
"\n",
|
||||
"[optimization]: https://en.wikipedia.org/wiki/Category:Convex_optimization\n",
|
||||
"[Stochastic Gradient Descent]: https://en.wikipedia.org/wiki/Stochastic_gradient_descent\n",
|
||||
"[gradient-decent]: http://www.statisticsviews.com/details/feature/5722691/Getting-to-the-Bottom-of-Regression-with-Gradient-Descent.html"
|
||||
"One of the key parameter for [optimization](https://en.wikipedia.org/wiki/Category:Convex_optimization) is called the `learning_rate`. For now, we can think of it as a scaling factor that modulates how much we change the parameters in any iteration. We will be covering more details in later tutorial. \n",
|
||||
"With this information, we are ready to create our trainer. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -583,7 +668,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"First lets create some helper functions that will be needed to visualize different functions associated with training."
|
||||
]
|
||||
|
|
@ -592,7 +680,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -620,9 +710,11 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"<a id='#Run the trainer'></a>\n",
|
||||
"### Run the trainer\n",
|
||||
"\n",
|
||||
"We are now ready to train our fully connected neural net. We want to decide what data we need to feed into the training engine.\n",
|
||||
|
|
@ -636,7 +728,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -650,7 +744,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -675,7 +771,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us plot the errors over the different training minibatches. Note that as we iterate the training loss decreases though we do see some intermediate bumps. The bumps indicate that during that iteration the model came across observations that it predicted incorrectly. This can happen with observations that are novel during model training.\n",
|
||||
"\n",
|
||||
|
|
@ -687,7 +786,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -737,9 +840,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Evaluation / Testing \n",
|
||||
"### Run evaluation / testing \n",
|
||||
"\n",
|
||||
"Now that we have trained the network, let us evaluate the trained network on data that hasn't been used for training. This is often called **testing**. Let us create some new data set and evaluate the average error and loss on this set. This is done using `trainer.test_minibatch`."
|
||||
]
|
||||
|
|
@ -747,7 +853,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -770,18 +880,24 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Note, this error is very comparable to our training error indicating that our model has good \"out of sample\" error a.k.a. generalization error. This implies that our model can very effectively deal with previously unseen observations (during the training process). This is key to avoid the phenomenon of overfitting."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We have so far been dealing with aggregate measures of error. Lets now get the probabilities associated with individual data points. For each observation, the `eval` function returns the probability distribution across all the classes. If you used the default parameters in this tutorial, then it would be a vector of 2 elements per observation. First let us route the network output through a softmax function.\n",
|
||||
"\n",
|
||||
"#### Why do we need to route the network output `netout` via `softmax`?\n",
|
||||
"**Why do we need to route the network output `netout` via `softmax`?**\n",
|
||||
"\n",
|
||||
"The way we have configured the network includes the output of all the activation nodes (e.g., the green layer in Figure 4). The output nodes (the orange layer in Figure 4), converts the activations into a probability. A simple and effective way is to route the activations via a softmax function."
|
||||
]
|
||||
|
|
@ -789,7 +905,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -814,7 +934,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -823,7 +945,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us test on previously unseen data."
|
||||
]
|
||||
|
|
@ -832,7 +957,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 28,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -842,7 +969,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -861,7 +992,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Exploration Suggestion**\n",
|
||||
|
|
@ -874,15 +1007,26 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Code link\n",
|
||||
"**Code link**\n",
|
||||
"\n",
|
||||
"If you want to try running the tutorial from python command prompt. Please run the [FeedForwardNet.py][] example.\n",
|
||||
"\n",
|
||||
"[FeedForwardNet.py]: https://github.com/Microsoft/CNTK/blob/release/2.1/Tutorials/NumpyInterop/FeedForwardNet.py"
|
||||
"If you want to try running the tutorial from python command prompt. Please run the [FeedForwardNet.py](https://github.com/Microsoft/CNTK/blob/release/2.1/Tutorials/NumpyInterop/FeedForwardNet.py) example."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
|
@ -902,7 +1046,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -3,7 +3,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 103 Part A: MNIST Data Loader\n",
|
||||
|
|
@ -11,18 +13,18 @@
|
|||
"This tutorial is targeted to individuals who are new to CNTK and to machine learning. We assume you have completed or are familiar with CNTK 101 and 102. In this tutorial, we will download and pre-process the MNIST digit images to be used for building different models to recognize handwritten digits. We will extend CNTK 101 and 102 to be applied to this data set. Additionally, we will introduce a convolutional network to achieve superior performance. This is the first example, where we will train and evaluate a neural network based model on real world data. \n",
|
||||
"\n",
|
||||
"CNTK 103 tutorial is divided into multiple parts:\n",
|
||||
"- Part A: Familiarize with the [MNIST][] database that will be used later in the tutorial\n",
|
||||
"- Subsequent parts in this 103 series would be using the MNIST data with different types of networks.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"[MNIST]: http://yann.lecun.com/exdb/mnist/\n",
|
||||
"\n"
|
||||
"- Part A: Familiarize with the [MNIST](http://yann.lecun.com/exdb/mnist/) database that will be used later in the tutorial\n",
|
||||
"- Subsequent parts in this 103 series would be using the MNIST data with different types of networks."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Import the relevant modules to be used later\n",
|
||||
|
|
@ -47,7 +49,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data download\n",
|
||||
"\n",
|
||||
|
|
@ -58,7 +63,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -120,7 +127,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Download the data\n",
|
||||
"\n",
|
||||
|
|
@ -130,7 +140,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -169,7 +183,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Visualize the data"
|
||||
]
|
||||
|
|
@ -177,7 +194,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -207,25 +228,30 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Save the images\n",
|
||||
"\n",
|
||||
"Save the images in a local directory. While saving the data we flatten the images to a vector (28x28 image pixels becomes an array of length 784 data points).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"The labels are encoded as [1-hot][] encoding (label of 3 with 10 digits becomes `0001000000`, where the first index corresponds to digit `0` and the last one corresponds to digit `9`.\n",
|
||||
"The labels are encoded as [1-hot]( https://en.wikipedia.org/wiki/One-hot) encoding (label of 3 with 10 digits becomes `0001000000`, where the first index corresponds to digit `0` and the last one corresponds to digit `9`.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"[1-hot]: https://en.wikipedia.org/wiki/One-hot"
|
||||
""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Save the data files into a format compatible with CNTK text reader\n",
|
||||
|
|
@ -251,7 +277,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -282,7 +312,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Suggested Explorations**\n",
|
||||
"\n",
|
||||
|
|
@ -291,18 +324,17 @@
|
|||
"There are several ways data alterations can be performed. CNTK readers automate a lot of these actions for you. However, to get a feel for how these transforms can impact training and test accuracies, we strongly encourage individuals to try one or more of data perturbation.\n",
|
||||
"\n",
|
||||
"- Shuffle the training data (rows to create a different). Hint: Use `permute_indices = np.random.permutation(train.shape[0])`. Then, run Part B of the tutorial with this newly permuted data.\n",
|
||||
"- Adding noise to the data can often improves [generalization error][]. You can augment the training set by adding noise (generated with numpy, hint: use `numpy.random`) to the training images. \n",
|
||||
"- Distort the images with [affine transformation][] (translations or rotations)\n",
|
||||
"\n",
|
||||
"[generalization error]: https://en.wikipedia.org/wiki/Generalization_error\n",
|
||||
"[affine transformation]: https://en.wikipedia.org/wiki/Affine_transformation\n"
|
||||
"- Adding noise to the data can often improves [generalization error](https://en.wikipedia.org/wiki/Generalization_error). You can augment the training set by adding noise (generated with numpy, hint: use `numpy.random`) to the training images. \n",
|
||||
"- Distort the images with [affine transformation](https://en.wikipedia.org/wiki/Affine_transformation) (translations or rotations)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -325,7 +357,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -14,6 +16,8 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"nbpresent": {
|
||||
"id": "29b9bd1d-766f-4422-ad96-de0accc1ce58"
|
||||
}
|
||||
|
|
@ -34,7 +38,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -57,7 +65,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Goal**:\n",
|
||||
"Our goal is to train a classifier that will identify the digits in the MNIST dataset. \n",
|
||||
|
|
@ -72,19 +83,25 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Logistic Regression\n",
|
||||
"[Logistic Regression](https://en.wikipedia.org/wiki/Logistic_regression) (LR) is a fundamental machine learning technique that uses a linear weighted combination of features and generates probability-based predictions of different classes. \n",
|
||||
"\n",
|
||||
"There are two basic forms of LR: **Binary LR** (with a single output that can predict two classes) and **multinomial LR** (with multiple outputs, each of which is used to predict a single class). \n",
|
||||
"\n",
|
||||
""
|
||||
""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In **Binary Logistic Regression** (see top of figure above), the input features are each scaled by an associated weight and summed together. The sum is passed through a squashing (aka activation) function and generates an output in [0,1]. This output value (which can be thought of as a probability) is then compared with a threshold (such as 0.5) to produce a binary label (0 or 1). This technique supports only classification problems with two output classes, hence the name binary LR. In the binary LR example shown above, the [sigmoid][] function is used as the squashing function.\n",
|
||||
"\n",
|
||||
|
|
@ -93,7 +110,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In **Multinomial Linear Regression** (see bottom of figure above), 2 or more output nodes are used, one for each output class to be predicted. Each summation node uses its own set of weights to scale the input features and sum them together. Instead of passing the summed output of the weighted input features through a sigmoid squashing function, the output is often passed through a [softmax][] function (which in addition to squashing, like the sigmoid, the softmax normalizes each nodes' output value using the sum of all unnormalized nodes). (Details in the context of MNIST image to follow)\n",
|
||||
"\n",
|
||||
|
|
@ -107,6 +127,8 @@
|
|||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"nbpresent": {
|
||||
"id": "138d1a78-02e2-4bd6-a20e-07b83f303563"
|
||||
}
|
||||
|
|
@ -131,7 +153,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Initialization"
|
||||
]
|
||||
|
|
@ -140,7 +165,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -151,7 +178,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data reading\n",
|
||||
"\n",
|
||||
|
|
@ -169,7 +199,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -188,7 +220,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -219,21 +255,27 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Model Creation\n",
|
||||
"## Model Creation\n",
|
||||
"\n",
|
||||
"A logistic regression (LR) network is a simple building block that has been effectively powering many ML \n",
|
||||
"applications in the past decade. The figure below summarizes the model in the context of the MNIST data.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"LR is a simple linear model that takes as input, a vector of numbers describing the properties of what we are classifying (also known as a feature vector, $\\bf \\vec{x}$, the pixels in the input MNIST digit image) and emits the *evidence* ($z$). For each of the 10 digits, there is a vector of weights corresponding to the input pixels as show in the figure. These 10 weight vectors define the weight matrix ($\\bf {W}$) with dimension of 10 x 784. Each feature in the input layer is connected with a summation node by a corresponding weight $w$ (individual weight values from the $\\bf{W}$ matrix). Note there are 10 such nodes, 1 corresponding to each digit to be classified. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The first step is to compute the evidence for an observation. \n",
|
||||
"\n",
|
||||
|
|
@ -246,7 +288,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Network input and output: \n",
|
||||
"- **input** variable (a key CNTK concept): \n",
|
||||
|
|
@ -260,7 +305,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -270,7 +317,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Logistic Regression network setup\n",
|
||||
"\n",
|
||||
|
|
@ -281,7 +331,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -293,7 +345,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"`z` will be used to represent the output of a network."
|
||||
]
|
||||
|
|
@ -302,7 +357,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -312,20 +369,22 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Learning model parameters\n",
|
||||
"\n",
|
||||
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function][] and other [activation][] functions).\n",
|
||||
"\n",
|
||||
"[softmax function]: http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax\n",
|
||||
"\n",
|
||||
"[activation]: https://docs.microsoft.com/en-us/cognitive-toolkit/Brainscript-Activation-Functions"
|
||||
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function](http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax) and other [activation](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.Activation) functions)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Training\n",
|
||||
"\n",
|
||||
|
|
@ -336,7 +395,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -345,9 +406,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Evaluation\n",
|
||||
"### Evaluation\n",
|
||||
"\n",
|
||||
"In order to evaluate the classification, one can compare the output of the network which for each observation emits a vector of evidences (can be converted into probabilities using `softmax` functions) with dimension equal to number of classes."
|
||||
]
|
||||
|
|
@ -356,7 +420,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -365,29 +431,30 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Configure training\n",
|
||||
"\n",
|
||||
"The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent][] (`sgd`) being one of the most popular one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent][] generate a new set model parameters in a single iteration. \n",
|
||||
"The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent](https://en.wikipedia.org/wiki/Stochastic_gradient_descent) (`sgd`) being one of the most popular one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent](http://www.statisticsviews.com/details/feature/5722691/Getting-to-the-Bottom-of-Regression-with-Gradient-Descent.html) generate a new set model parameters in a single iteration. \n",
|
||||
"\n",
|
||||
"The aforementioned model parameter update using a single observation at a time is attractive since it does not require the entire data set (all observation) to be loaded in memory and also requires gradient computation over fewer datapoints, thus allowing for training on large data sets. However, the updates generated using a single observation sample at a time can vary wildly between iterations. An intermediate ground is to load a small set of observations and use an average of the `loss` or error from that set to update the model parameters. This subset is called a *minibatch*.\n",
|
||||
"\n",
|
||||
"With minibatches, we often sample observation from the larger training dataset. We repeat the process of model parameters update using different combination of training samples and over a period of time minimize the `loss` (and the error). When the incremental error rates are no longer changing significantly or after a preset number of maximum minibatches to train, we claim that our model is trained.\n",
|
||||
"\n",
|
||||
"One of the key optimization parameter is called the `learning_rate`. For now, we can think of it as a scaling factor that modulates how much we change the parameters in any iteration. We will be covering more details in later tutorial. \n",
|
||||
"With this information, we are ready to create our trainer. \n",
|
||||
"\n",
|
||||
"[optimization]: https://en.wikipedia.org/wiki/Category:Convex_optimization\n",
|
||||
"[Stochastic Gradient Descent]: https://en.wikipedia.org/wiki/Stochastic_gradient_descent\n",
|
||||
"[gradient-decent]: http://www.statisticsviews.com/details/feature/5722691/Getting-to-the-Bottom-of-Regression-with-Gradient-Descent.html"
|
||||
"One of the key [optimization](https://en.wikipedia.org/wiki/Category:Convex_optimization) parameter is called the `learning_rate`. For now, we can think of it as a scaling factor that modulates how much we change the parameters in any iteration. We will be covering more details in later tutorial. \n",
|
||||
"With this information, we are ready to create our trainer. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -400,7 +467,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"First let us create some helper functions that will be needed to visualize different functions associated with training."
|
||||
]
|
||||
|
|
@ -409,7 +479,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -437,9 +509,11 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"<a id='#Run the trainer'></a>\n",
|
||||
"### Run the trainer\n",
|
||||
"\n",
|
||||
"We are now ready to train our fully connected neural net. We want to decide what data we need to feed into the training engine.\n",
|
||||
|
|
@ -451,7 +525,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -465,7 +541,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -524,7 +604,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us plot the errors over the different training minibatches. Note that as we iterate the training loss decreases though we do see some intermediate bumps. \n",
|
||||
"\n",
|
||||
|
|
@ -534,7 +617,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -584,9 +671,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Evaluation / Testing \n",
|
||||
"### Run evaluation / Testing \n",
|
||||
"\n",
|
||||
"Now that we have trained the network, let us evaluate the trained network on the test data. This is done using `trainer.test_minibatch`."
|
||||
]
|
||||
|
|
@ -594,7 +684,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -637,14 +731,20 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Note, this error is very comparable to our training error indicating that our model has good \"out of sample\" error a.k.a. generalization error. This implies that our model can very effectively deal with previously unseen observations (during the training process). This is key to avoid the phenomenon of overfitting."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We have so far been dealing with aggregate measures of error. Let us now get the probabilities associated with individual data points. For each observation, the `eval` function returns the probability distribution across all the classes. The classifier is trained to recognize digits, hence has 10 classes. First let us route the network output through a `softmax` function. This maps the aggregated activations across the network to probabilities across the 10 classes."
|
||||
]
|
||||
|
|
@ -653,7 +753,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -662,7 +764,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us a small minibatch sample from the test data."
|
||||
]
|
||||
|
|
@ -671,7 +776,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -692,7 +799,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -704,7 +813,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -722,7 +835,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us visualize some of the results"
|
||||
]
|
||||
|
|
@ -730,7 +846,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -763,7 +883,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Exploration Suggestion**\n",
|
||||
|
|
@ -790,7 +912,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -14,6 +16,8 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"nbpresent": {
|
||||
"id": "29b9bd1d-766f-4422-ad96-de0accc1ce58"
|
||||
}
|
||||
|
|
@ -34,7 +38,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -57,7 +65,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Goal**:\n",
|
||||
"Our goal is to train a classifier that will identify the digits in the MNIST dataset. Additionally, we aspire to achieve lower error rate with Multi-layer perceptron compared to Multi-class logistic regression. \n",
|
||||
|
|
@ -75,6 +86,8 @@
|
|||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"nbpresent": {
|
||||
"id": "138d1a78-02e2-4bd6-a20e-07b83f303563"
|
||||
}
|
||||
|
|
@ -98,7 +111,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data reading\n",
|
||||
"\n",
|
||||
|
|
@ -109,7 +125,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -120,7 +138,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In this tutorial we are using the MNIST data you have downloaded using CNTK_103A_MNIST_DataLoader notebook. The dataset has 60,000 training images and 10,000 test images with each image being 28 x 28 pixels. Thus the number of features is equal to 784 (= 28 x 28 pixels), 1 per pixel. The variable `num_output_classes` is set to 10 corresponding to the number of digits (0-9) in the dataset.\n",
|
||||
"\n",
|
||||
|
|
@ -136,7 +157,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -151,7 +174,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -179,25 +206,30 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"<a id='#Model Creation'></a>\n",
|
||||
"## Model Creation\n",
|
||||
"\n",
|
||||
"Our multi-layer perceptron will be relatively simple with 2 hidden layers (`num_hidden_layers`). The number of nodes in the hidden layer being a parameter specified by `hidden_layers_dim`. The figure below illustrates the entire model we will use in this tutorial in the context of MNIST data.\n",
|
||||
"\n",
|
||||
"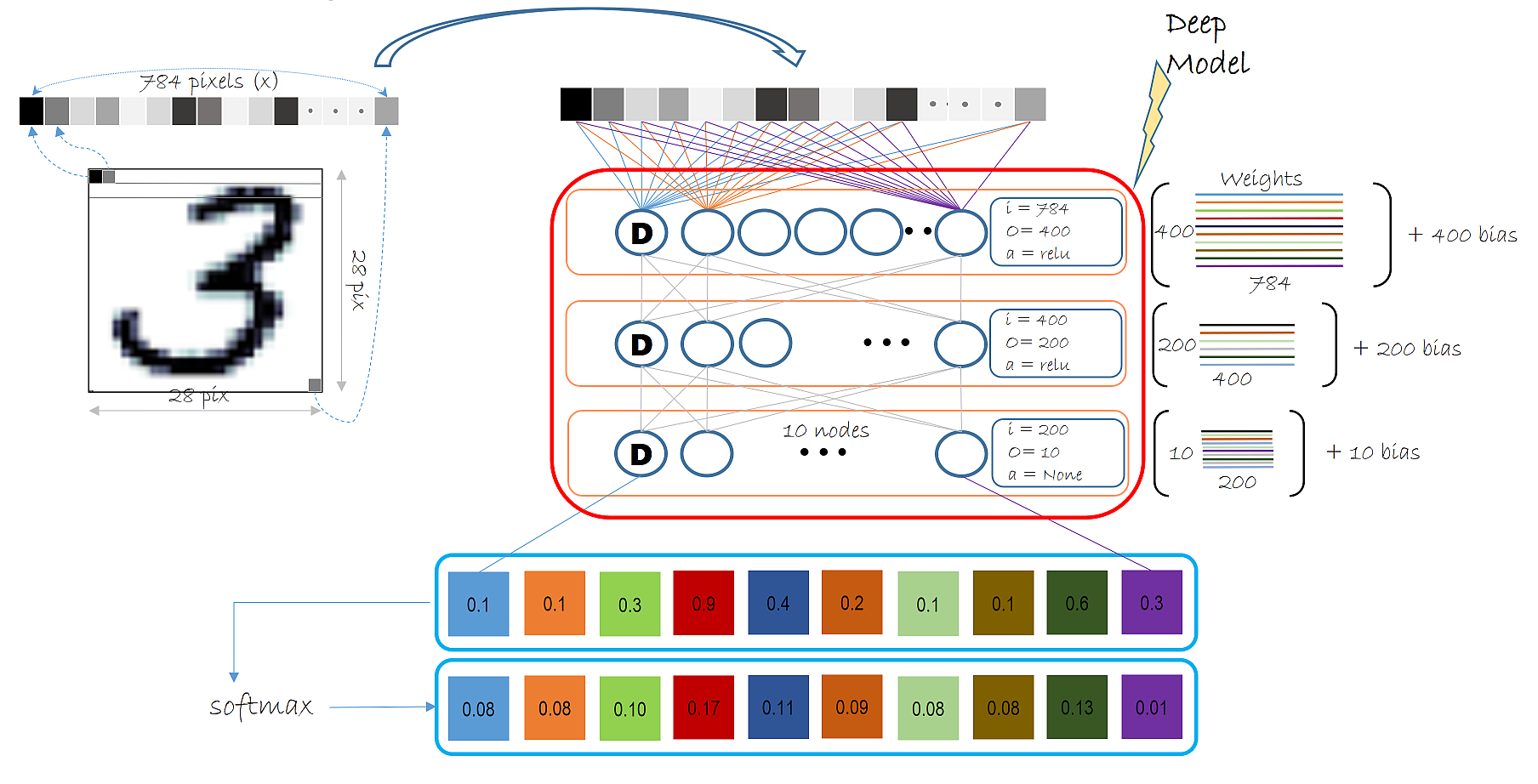"
|
||||
""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"If you are not familiar with the terms *hidden layer* and *number of hidden layers*, please refer back to CNTK 102 tutorial.\n",
|
||||
"\n",
|
||||
"Each Dense layer (as illustrated below) shows the input dimensions, output dimensions and activation function that layer uses. Specifically, the layer below shows: input dimension = 784 (1 dimension for each input pixel), output dimension = 400 (number of hidden nodes, a parameter specified by the user) and activation function being [relu](https://cntk.ai/pythondocs/cntk.ops.html?highlight=relu#cntk.ops.relu).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"In this model we have 2 dense layer called the hidden layers each with an activation function of `relu` and one output layer with no activation. \n",
|
||||
"\n",
|
||||
|
|
@ -212,7 +244,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -222,7 +256,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Network input and output: \n",
|
||||
"- **input** variable (a key CNTK concept): \n",
|
||||
|
|
@ -236,7 +273,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -246,7 +285,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Multi-layer Perceptron setup\n",
|
||||
"\n",
|
||||
|
|
@ -257,7 +299,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -274,7 +318,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"`z` will be used to represent the output of a network.\n",
|
||||
"\n",
|
||||
|
|
@ -292,7 +339,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -302,18 +351,22 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Learning model parameters\n",
|
||||
"\n",
|
||||
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function][]).\n",
|
||||
"\n",
|
||||
"[softmax function]: http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax"
|
||||
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function](http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax))."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Training\n",
|
||||
"\n",
|
||||
|
|
@ -324,7 +377,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -333,9 +388,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Evaluation\n",
|
||||
"### Evaluation\n",
|
||||
"\n",
|
||||
"In order to evaluate the classification, one can compare the output of the network which for each observation emits a vector of evidences (can be converted into probabilities using `softmax` functions) with dimension equal to number of classes."
|
||||
]
|
||||
|
|
@ -344,7 +402,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -353,29 +413,30 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Configure training\n",
|
||||
"\n",
|
||||
"The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent][] (`sgd`) being a basic one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent][] generate a new set model parameters in a single iteration. \n",
|
||||
"The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent](https://en.wikipedia.org/wiki/Stochastic_gradient_descent) (`sgd`) being a basic one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent](http://www.statisticsviews.com/details/feature/5722691/Getting-to-the-Bottom-of-Regression-with-Gradient-Descent.html) generate a new set model parameters in a single iteration. \n",
|
||||
"\n",
|
||||
"The aforementioned model parameter update using a single observation at a time is attractive since it does not require the entire data set (all observation) to be loaded in memory and also requires gradient computation over fewer datapoints, thus allowing for training on large data sets. However, the updates generated using a single observation sample at a time can vary wildly between iterations. An intermediate ground is to load a small set of observations and use an average of the `loss` or error from that set to update the model parameters. This subset is called a *minibatch*.\n",
|
||||
"\n",
|
||||
"With minibatches we often sample observation from the larger training dataset. We repeat the process of model parameters update using different combination of training samples and over a period of time minimize the `loss` (and the error). When the incremental error rates are no longer changing significantly or after a preset number of maximum minibatches to train, we claim that our model is trained.\n",
|
||||
"\n",
|
||||
"One of the key parameter for optimization is called the `learning_rate`. For now, we can think of it as a scaling factor that modulates how much we change the parameters in any iteration. We will be covering more details in later tutorial. \n",
|
||||
"With this information, we are ready to create our trainer. \n",
|
||||
"\n",
|
||||
"[optimization]: https://en.wikipedia.org/wiki/Category:Convex_optimization\n",
|
||||
"[Stochastic Gradient Descent]: https://en.wikipedia.org/wiki/Stochastic_gradient_descent\n",
|
||||
"[gradient-decent]: http://www.statisticsviews.com/details/feature/5722691/Getting-to-the-Bottom-of-Regression-with-Gradient-Descent.html"
|
||||
"One of the key parameter for [optimization](https://en.wikipedia.org/wiki/Category:Convex_optimization) is called the `learning_rate`. For now, we can think of it as a scaling factor that modulates how much we change the parameters in any iteration. We will be covering more details in later tutorial. \n",
|
||||
"With this information, we are ready to create our trainer. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -388,7 +449,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"First let us create some helper functions that will be needed to visualize different functions associated with training."
|
||||
]
|
||||
|
|
@ -397,7 +461,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -425,9 +491,11 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"<a id='#Run the trainer'></a>\n",
|
||||
"### Run the trainer\n",
|
||||
"\n",
|
||||
"We are now ready to train our fully connected neural net. We want to decide what data we need to feed into the training engine.\n",
|
||||
|
|
@ -439,7 +507,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -453,7 +523,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -512,7 +586,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us plot the errors over the different training minibatches. Note that as we iterate the training loss decreases though we do see some intermediate bumps. \n",
|
||||
"\n",
|
||||
|
|
@ -522,7 +599,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -572,9 +653,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Evaluation / Testing \n",
|
||||
"### Run evaluation / testing \n",
|
||||
"\n",
|
||||
"Now that we have trained the network, let us evaluate the trained network on the test data. This is done using `trainer.test_minibatch`."
|
||||
]
|
||||
|
|
@ -582,7 +666,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -625,7 +713,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Note, this error is very comparable to our training error indicating that our model has good \"out of sample\" error a.k.a. generalization error. This implies that our model can very effectively deal with previously unseen observations (during the training process). This is key to avoid the phenomenon of overfitting.\n",
|
||||
"\n",
|
||||
|
|
@ -634,7 +725,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We have so far been dealing with aggregate measures of error. Let us now get the probabilities associated with individual data points. For each observation, the `eval` function returns the probability distribution across all the classes. The classifier is trained to recognize digits, hence has 10 classes. First let us route the network output through a `softmax` function. This maps the aggregated activations across the network to probabilities across the 10 classes."
|
||||
]
|
||||
|
|
@ -643,7 +737,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -652,7 +748,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us a small minibatch sample from the test data."
|
||||
]
|
||||
|
|
@ -661,7 +760,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -682,7 +783,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -694,7 +797,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -712,7 +819,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us visualize some of the results"
|
||||
]
|
||||
|
|
@ -720,7 +830,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -753,7 +867,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Exploration Suggestion**\n",
|
||||
|
|
@ -765,13 +881,26 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Code link\n",
|
||||
"**Code link**\n",
|
||||
"\n",
|
||||
"If you want to try running the tutorial from Python command prompt please run the [SimpleMNIST.py](https://github.com/Microsoft/CNTK/tree/release/2.1/Examples/Image/Classification/MLP/Python) example."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
|
@ -791,7 +920,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -14,6 +16,8 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"nbpresent": {
|
||||
"id": "29b9bd1d-766f-4422-ad96-de0accc1ce58"
|
||||
}
|
||||
|
|
@ -42,7 +46,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -65,7 +73,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Goal**:\n",
|
||||
"Our goal is to train a classifier that will identify the digits in the MNIST dataset. \n",
|
||||
|
|
@ -84,6 +95,8 @@
|
|||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"nbpresent": {
|
||||
"id": "138d1a78-02e2-4bd6-a20e-07b83f303563"
|
||||
}
|
||||
|
|
@ -108,7 +121,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data reading\n",
|
||||
"In this section, we will read the data generated in CNTK 103 Part A (MNIST Data Loader).\n",
|
||||
|
|
@ -117,13 +133,13 @@
|
|||
"\n",
|
||||
"In previous tutorials, as shown below, we have always flattened the input image into a vector. With convoultional networks, we do not flatten the image in this way.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"**Input Dimensions**: \n",
|
||||
"\n",
|
||||
"In convolutional networks for images, the input data is often shaped as a 3D matrix (number of channels, image width, height), which preserves the spatial relationship between the pixels. In the figure above, the MNIST image is a single channel (grayscale) data, so the input dimension is specified as a (1, image width, image height) tuple. \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Natural scene color images are often presented as Red-Green-Blue (RGB) color channels. The input dimension of such images are specified as a (3, image width, image height) tuple. If one has RGB input data as a volumetric scan with volume width, volume height and volume depth representing the 3 axes, the input data format would be specified by a tuple of 4 values (3, volume width, volume height, volume depth). In this way CNTK enables specification of input images in arbitrary higher-dimensional space."
|
||||
]
|
||||
|
|
@ -132,7 +148,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -144,7 +162,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Data Format** The data is stored on our local machine in the CNTK CTF format. The CTF format is a simple text format that contains a set of samples with each sample containing a set of named fields and their data. For our MNIST data, each sample contains 2 fields: labels and feature, formatted as:\n",
|
||||
"\n",
|
||||
|
|
@ -155,14 +176,16 @@
|
|||
"\n",
|
||||
"The labels are [1-hot](https://en.wikipedia.org/wiki/One-hot) encoded (the label representing the output class of 3 becomes `0001000000` since we have 10 classes for the 10 possible digits), where the first index corresponds to digit `0` and the last one corresponds to digit `9`.\n",
|
||||
"\n",
|
||||
""
|
||||
""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -180,7 +203,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -213,30 +240,36 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"<a id='#Model Creation'></a>\n",
|
||||
"## CNN Model Creation\n",
|
||||
"\n",
|
||||
"CNN is a feedforward network made up of bunch of layers in such a way that the output of one layer becomes the input to the next layer (similar to MLP). In MLP, all possible pairs of input pixels are connected to the output nodes with each pair having a weight, thus leading to a combinatorial explosion of parameters to be learnt and also increasing the possibility of overfitting ([details](http://cs231n.github.io/neural-networks-1/)). Convolution layers take advantage of the spatial arrangement of the pixels and learn multiple filters that significantly reduce the amount of parameters in the network ([details](http://cs231n.github.io/convolutional-networks/)). The size of the filter is a parameter of the convolution layer. \n",
|
||||
"\n",
|
||||
"In this section, we introduce the basics of convolution operations. We show the illustrations in the context of RGB images (3 channels), eventhough the MNIST data we are using in this tutorial is a grayscale image (single channel).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"### Convolution Layer\n",
|
||||
"\n",
|
||||
"A convolution layer is a set of filters. Each filter is defined by a weight (**W**) matrix, and bias ($b$).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"These filters are scanned across the image performing the dot product between the weights and corresponding input value ($\\vec{x}^T$). The bias value is added to the output of the dot product and the resulting sum is optionally mapped through an activation function. This process is illustrated in the following animation."
|
||||
"These filters are scanned across the image performing the dot product between the weights and corresponding input value ($x$). The bias value is added to the output of the dot product and the resulting sum is optionally mapped through an activation function. This process is illustrated in the following animation."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -258,7 +291,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Convolution layers incorporate following key features:\n",
|
||||
"\n",
|
||||
|
|
@ -278,7 +314,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Strides and Pad parameters\n",
|
||||
"\n",
|
||||
|
|
@ -291,7 +330,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -344,7 +387,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Building our CNN models\n",
|
||||
"\n",
|
||||
|
|
@ -355,7 +401,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -365,20 +413,25 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The first model we build is a simple convolution only network. Here we have two convolutional layers. Since, our task is to detect the 10 digits in the MNIST database, the output of the network should be a vector of length 10, 1 element corresponding to each digit. This is achieved by projecting the output of the last convolutional layer using a dense layer with the output being `num_output_classes`. We have seen this before with Logistic Regression and MLP where features were mapped to the number of classes in the final layer. Also, note that since we will be using the `softmax` operation that is combined with the `cross entropy` loss function during training (see a few cells below), the final dense layer has no activation function associated with it.\n",
|
||||
"\n",
|
||||
"The following figure illustrates the model we are going to build. Note the parameters in the model below are to be experimented with. These are often called network hyperparameters. Increasing the filter shape leads to an increase in the number of model parameters, increases the compute time and helps the model better fit to the data. However, one runs the risk of [overfitting](https://en.wikipedia.org/wiki/Overfitting). Typically, the number of filters in the deeper layers are more than the number of filters in the layers before them. We have chosen 8, 16 for the first and second layers, respectively. These hyperparameters should be experimented with during model building.\n",
|
||||
"\n",
|
||||
""
|
||||
""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -401,7 +454,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us create an instance of the model and inspect the different components of the model. `z` will be used to represent the output of a network. In this model, we use the `relu` activation function. Note: using the `C.layers.default_options` is an elegant way to write concise models. This is key to minimizing modeling errors, saving precious debugging time."
|
||||
]
|
||||
|
|
@ -409,7 +465,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -431,7 +491,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Understanding number of model parameters to be estimated is key to deep learning since there is a direct dependency on the amount of data one needs to have. You need more data for a model that has larger number of parameters to prevent overfitting. In other words, with a fixed amount of data, one has to constrain the number of parameters. There is no golden rule between the amount of data one needs for a model. However, there are ways one can boost performance of model training with [data augmentation](https://deeplearningmania.quora.com/The-Power-of-Data-Augmentation-2). "
|
||||
]
|
||||
|
|
@ -439,7 +502,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -456,7 +523,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Understanding Parameters**:\n",
|
||||
"\n",
|
||||
|
|
@ -477,7 +547,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Knowledge check**: Does the dense layer shape align with the task (MNIST digit classification)?\n",
|
||||
"\n",
|
||||
|
|
@ -486,27 +559,27 @@
|
|||
"- Record the training error you get with `relu` as the activation function,\n",
|
||||
"- Now change to `sigmoid` as the activation function and see if you can improve your training error.\n",
|
||||
"\n",
|
||||
"*Quiz*: Different supported activation functions can be [found here][]. Which activation function gives the least training error?\n",
|
||||
"\n",
|
||||
"[found here]: https://docs.microsoft.com/en-us/cognitive-toolkit/Brainscript-Activation-Functions"
|
||||
"*Quiz*: Different supported activation functions can be [found here](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.Activation). Which activation function gives the least training error?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Learning model parameters\n",
|
||||
"\n",
|
||||
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function][] and other [activation][] functions).\n",
|
||||
"\n",
|
||||
"[softmax function]: http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax\n",
|
||||
"\n",
|
||||
"[activation]: https://docs.microsoft.com/en-us/cognitive-toolkit/Brainscript-Activation-Functions"
|
||||
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function](http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax) and other [activation](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.Activation) functions)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Training\n",
|
||||
"\n",
|
||||
|
|
@ -517,7 +590,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -529,7 +604,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Next we will need a helper function to perform the model training. First let us create additional helper functions that will be needed to visualize different functions associated with training."
|
||||
]
|
||||
|
|
@ -538,7 +616,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -566,7 +646,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Configure training\n",
|
||||
"\n",
|
||||
|
|
@ -577,7 +660,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -651,9 +736,11 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"<a id='#Run the trainer'></a>\n",
|
||||
"### Run the trainer and test model\n",
|
||||
"\n",
|
||||
"We are now ready to train our convolutional neural net. "
|
||||
|
|
@ -662,7 +749,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -705,7 +796,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Note, the average test error is very comparable to our training error indicating that our model has good \"out of sample\" error a.k.a. [generalization error](https://en.wikipedia.org/wiki/Generalization_error). This implies that our model can very effectively deal with previously unseen observations (during the training process). This is key to avoid [overfitting](https://en.wikipedia.org/wiki/Overfitting).\n",
|
||||
"\n",
|
||||
|
|
@ -715,7 +809,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -732,9 +830,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Evaluation / Prediction\n",
|
||||
"### Run evaluation / prediction\n",
|
||||
"We have so far been dealing with aggregate measures of error. Let us now get the probabilities associated with individual data points. For each observation, the `eval` function returns the probability distribution across all the classes. The classifier is trained to recognize digits, hence has 10 classes. First let us route the network output through a `softmax` function. This maps the aggregated activations across the network to probabilities across the 10 classes."
|
||||
]
|
||||
},
|
||||
|
|
@ -742,7 +843,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -751,7 +854,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us a small minibatch sample from the test data."
|
||||
]
|
||||
|
|
@ -760,7 +866,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -785,7 +893,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -797,7 +907,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -815,7 +929,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us visualize some of the results"
|
||||
]
|
||||
|
|
@ -823,7 +940,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -855,7 +976,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Pooling Layer\n",
|
||||
"\n",
|
||||
|
|
@ -869,7 +993,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Another alternative is average pooling, which emits that average value instead of the maximum value. The two different pooling opearations are summarized in the animation below."
|
||||
]
|
||||
|
|
@ -877,7 +1004,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -930,11 +1061,14 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Typical convolution network\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"A typical CNN contains a set of alternating convolution and pooling layers followed by a dense output layer for classification. You will find variants of this structure in many classical deep networks (VGG, AlexNet etc). This is in contrast to the MLP network we used in CNTK_103C, which consisted of 2 dense layers followed by a dense output layer. \n",
|
||||
"\n",
|
||||
|
|
@ -943,13 +1077,16 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Task: Create a network with MaxPooling\n",
|
||||
"\n",
|
||||
"Typical convolutional networks have interlacing convolution and max pool layers. The previous model had only convolution layer. In this section, you will create a model with the following architecture.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"You will use the CNTK [MaxPooling](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.MaxPooling) function to achieve this task. You will edit the `create_model` function below and add the MaxPooling operation. \n",
|
||||
"\n",
|
||||
|
|
@ -960,7 +1097,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -986,7 +1125,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Quiz**: How many parameters do we have in the model with MaxPooling and Convolution? Which of the two models produces lower error rate?\n",
|
||||
|
|
@ -999,7 +1140,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Solution"
|
||||
]
|
||||
|
|
@ -1007,7 +1151,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1065,7 +1213,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -1088,7 +1238,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -2,7 +2,10 @@
|
|||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Tutorial 104: Time Series Basics with Pandas and Finance Data\n",
|
||||
"\n",
|
||||
|
|
@ -20,7 +23,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -41,22 +46,28 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Importing stock data\n",
|
||||
"We first retrieve stock data using the method `get_stock_data`. This method downloads stock data on a daily timescale from Google finance (can be modified to get data from Yahoo Finance and many other sources). [Pandas datareader]( http://pandas-datareader.readthedocs.io/en/latest/remote_data.html) shows many use cases for the data reader."
|
||||
"## Read data\n",
|
||||
"We first retrieve stock data using the method `get_stock_data`. This method downloads stock data on a daily timescale from Google Finance (can be modified to get data from Yahoo Finance and many other sources). [Pandas datareader]( http://pandas-datareader.readthedocs.io/en/latest/remote_data.html) shows many use cases for the data reader."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# A method which obtains stock data from Google finance\n",
|
||||
"# Requires an Internet connection to retrieve stock data from Google finance\n", "\n",
|
||||
"# Requires an Internet connection to retrieve stock data from Google finance\n",
|
||||
"\n",
|
||||
"import time\n",
|
||||
"try:\n",
|
||||
" from pandas_datareader import data\n",
|
||||
|
|
@ -100,7 +111,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -161,16 +176,21 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Building the training paramaters\n",
|
||||
"## Build features\n",
|
||||
"\n",
|
||||
"The stock market behavior exhibits substantial [autocorrelation](https://en.wikipedia.org/wiki/Autocorrelation) ([reference](http://epchan.blogspot.com/2016/04/mean-reversion-momentum-and-volatility.html)). We use [ETF](http://www.investopedia.com/terms/e/etf.asp) `SPY` index representing the \"market\" of stock. This is the ETF that encompasses around top 500 companies in America by market capitalization. We will trade under the assumption that there is some short term autocorrelation that have predictive power in the market. \n",
|
||||
"\n",
|
||||
"### Predicting\n",
|
||||
"**Goal**\n",
|
||||
"\n",
|
||||
"* Whether or not the next data for the given stock/ETF will be above or below the current day.\n",
|
||||
"\n",
|
||||
"### Predictors\n",
|
||||
"**Model features**\n",
|
||||
"\n",
|
||||
"* The previous 8 days, classified if greater than the current day,\n",
|
||||
"\n",
|
||||
"* The volume changes as a percentage,\n",
|
||||
|
|
@ -183,7 +203,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -472,9 +496,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### What we are trying to predict\n",
|
||||
"**What are trying to predict**\n",
|
||||
"\n",
|
||||
"Here we are trying to predict whether or not the next days' trading will be above or below the current day. We will represent a predicted up day as a 1, else a 0 if the next day is the same or below. (Note: the market is unlikely going to close at the same price as it did the previous day). "
|
||||
]
|
||||
|
|
@ -483,7 +510,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -504,7 +533,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Here we are actually building the neural network itself. We will use a simple feedforward neural network (represented as `NN` in the plots) with 10 inputs and 50 dimensions.\n",
|
||||
|
|
@ -515,7 +546,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -531,16 +566,23 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Note, we are using `layers` library in this tutorial. The details documentation can be found [here](https://cntk.ai/pythondocs/layerref.html)."
|
||||
"## Model Creation\n",
|
||||
"\n",
|
||||
"We will be using a simple MLP network as our model using the `layers` library found [here](https://cntk.ai/pythondocs/layerref.html)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -573,7 +615,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -590,16 +634,27 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Number of passes through the data, how we train time series data\n",
|
||||
"## Training\n",
|
||||
"\n",
|
||||
"**Note**: Number of passes through the data, how we train time series data?\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"This tutorial will differ from other tutorials in the sense that here we will not randomly send data to the trainer, instead each minibatch will be fed sequentially in the order of the time dimension. This is key to time series data-handling where we want to \"weigh\" the data at the end of our sample a slightly higher. You can put in multiple passes, however you will notice significant performance degradation. Try it out! Additionally, multiple passes tend to overfit the financial timeseries data. This overfitting can be mitigated using standard ML approaches such as [L1 regularization](https://en.wikipedia.org/wiki/Regularization_%28mathematics%29)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -641,7 +696,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -691,7 +750,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -735,7 +798,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Notice the trend for the label prediction error is still close to 50%. Remember that this is time variant, therefore it is expected that the system will have some noise as it trains through time. It should be noted; the model is still learning the market. Additionally, since this time series data is so noisy, having an error rate below 50% is good (many trading firms have win-rates of near 50% and have made money nearly every day [VIRTU](https://en.wikipedia.org/wiki/Virtu_Financial#Trading_activity)). However note they are high frequency trading firm and can leverage themselves up with low winrate strategies (51%). Trying to classify and trade every single day is expensive from transaction fees perspective. Therefore, one approach would be to trade when we think we are more likely to win?\n",
|
||||
"\n",
|
||||
|
|
@ -745,7 +811,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -768,7 +838,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Here we see that we have an error rate near 50%. At first glance this may appear to not have learned the network, but let us examine further and see if we have some predictive power."
|
||||
]
|
||||
|
|
@ -777,7 +850,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -792,9 +867,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Evaluating our Data\n",
|
||||
"## Evaluation\n",
|
||||
"Here we take the output of our test set and compute the probabilities from the softmax function. Since we have probabilities we want to trade when there is a \"higher\" chance that we will be right, instead of just a >50% chance that the market will go in one direction. The goal is to find a signal, instead of trying to classify the market. Since the market is so noisy we want to only trade when we have an \"edge\" on the market. Moreover, trading frequently has higher fees (you have to pay each time you trade).\n",
|
||||
"\n",
|
||||
"We will say that if the prediction probability is greater than 55% (in either direction) we will take a position in the market. If it shows that the market will be up the next day with greater than 55% probability, we will take a 1-day long. If it is greater than a 55% chance that the next day will be below today's position we will take 1-day [short] (http://www.investopedia.com/university/shortselling/shortselling1.asp)(the same as borrowing a stock and buying it back). \n",
|
||||
|
|
@ -815,7 +893,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -852,7 +932,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -879,7 +963,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -945,7 +1033,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"This plot shows the % returns when we trade using SPY and NN based models only when we are > 55% sure of the predicted directionality.\n",
|
||||
"\n",
|
||||
|
|
@ -965,7 +1056,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1020,13 +1115,14 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The plot above shows the % returns when we trade every day using SPY and NN based models as compared to a confidence based trading show in previous plot. With frequent trading the volatility is higher and transaction fees (not accounted in this plot) will greatly eat into any profits.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Suggested exercises\n",
|
||||
"**Suggested exercises**\n",
|
||||
"Try changing the batch size, the network itself, the activation functions, and many other features and see how much it affects the output. Notice how it can change dramatically? This means what you have been training on might be noise and you need to refine either the model or more likely the inputs to the network itself. \n",
|
||||
"\n",
|
||||
"After you have completed the aforementioned exercise, experiment with applying the trained network to other timeseries data. Pick a stock in the S&P 500, pick something that is uncorrelated with the S&P 500, try a completely random dataset. How do you expect each of those to do? Should the performance match up with S&P 500 out of sample performance? How about the random data?\n"
|
||||
|
|
@ -1035,7 +1131,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1053,7 +1153,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Appendix\n",
|
||||
|
|
@ -1081,7 +1183,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -13,9 +15,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 105: Basic autoencoder with MNIST data\n",
|
||||
"# CNTK 105: Basic autoencoder (AE) with MNIST data\n",
|
||||
"\n",
|
||||
"**Prerequisites**: We assume that you have successfully downloaded the MNIST data by completing the tutorial titled CNTK_103A_MNIST_DataLoader.ipynb.\n",
|
||||
"\n",
|
||||
|
|
@ -36,7 +41,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -59,7 +68,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In this tutorial, we will use the [MNIST hand-written digits data](https://en.wikipedia.org/wiki/MNIST_database) to show how images can be encoded and decoded (restored) using feed-forward networks. We will visualize the original and the restored images. We illustrate feed forward network based on two autoencoders: simple and deep autoencoder. More advanced autoencoders will be covered in future 200 series tutorials."
|
||||
]
|
||||
|
|
@ -68,7 +80,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -90,7 +104,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"There are two run modes:\n",
|
||||
"- *Fast mode*: `isFast` is set to `True`. This is the default mode for the notebooks, which means we train for fewer iterations or train / test on limited data. This ensures functional correctness of the notebook though the models produced are far from what a completed training would produce.\n",
|
||||
|
|
@ -102,7 +119,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -111,7 +130,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data reading\n",
|
||||
"\n",
|
||||
|
|
@ -131,7 +153,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -146,7 +170,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -175,10 +203,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"<a id='#Model Creation'></a>\n",
|
||||
"## Model Creation\n",
|
||||
"## Model Creation (Simple AE)\n",
|
||||
"\n",
|
||||
"We start with a simple single fully-connected feedforward network as encoder and as decoder (as shown in the figure below):"
|
||||
]
|
||||
|
|
@ -186,7 +216,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -209,7 +243,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The input data is a set of hand written digits images each of 28 x 28 pixels. In this tutorial, we will consider each image as a linear array of 784 pixel values. These pixels are considered as an input having 784 dimensions, one per pixel. Since the goal of the autoencoder is to compress the data and reconstruct the original image, the output dimension is same as the input dimension. We will compress the input to mere 32 dimensions (referred to as the `encoding_dim`). Additionally, since the maximum input value is 255, we normalize the input between 0 and 1. "
|
||||
]
|
||||
|
|
@ -218,7 +255,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -237,9 +276,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Setup the network for training and testing\n",
|
||||
"### Train and test the model\n",
|
||||
"\n",
|
||||
"In previous tutorials, we have defined each of the training and testing phases separately. In this tutorial, we combine the two components in one place such that this template could be used as a recipe for your usage. \n",
|
||||
"\n",
|
||||
|
|
@ -262,7 +304,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -381,7 +425,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us train the simple autoencoder. We create a training and a test reader"
|
||||
]
|
||||
|
|
@ -389,7 +436,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -427,15 +478,22 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Visualize the simple autoencoder results"
|
||||
"## Visualize simple AE results"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -485,7 +543,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us plot the original and the decoded image. They should look visually similar."
|
||||
]
|
||||
|
|
@ -494,7 +555,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -514,7 +577,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -541,10 +608,12 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Deep Auto encoder\n",
|
||||
"## Model Creation (Deep AE)\n",
|
||||
"\n",
|
||||
"We do not have to limit ourselves to a single layer as encoder or decoder, we could instead use a stack of dense layers. Let us create a deep autoencoder."
|
||||
]
|
||||
|
|
@ -552,7 +621,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -575,7 +648,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The encoding dimensions are 128, 64 and 32 while the decoding dimensions are symmetrically opposite 64, 128 and 784. This increases the number of parameters used to model the transformation and achieves lower error rates at the cost of longer training duration and memory footprint. If we train this deep encoder for larger number iterations by turning the `isFast` flag to be `False`, we get a lower error and the reconstructed images are also marginally better. "
|
||||
]
|
||||
|
|
@ -584,7 +660,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -615,7 +693,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -654,15 +736,22 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Visualize the deep autoencoder results"
|
||||
"## Visualize deep AE results"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -697,7 +786,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us plot the original and the decoded image with the deep autoencoder. They should look visually similar."
|
||||
]
|
||||
|
|
@ -705,7 +797,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -731,7 +827,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We have shown how to encode and decode an input. In this section we will explore how we can compare one to another and also show how to extract an encoded input for a given input. For visualizing high dimension data in 2D, [t-SNE](http://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html) is probably one of the best methods. However, it typically requires relatively low-dimensional data. So a good strategy for visualizing similarity relationships in high-dimensional data is to encode data into a low-dimensional space (e.g. 32 dimensional) using an autoencoder first, extract the encoding of the input data followed by using t-SNE for mapping the compressed data to a 2D plane. \n",
|
||||
"\n",
|
||||
|
|
@ -746,7 +845,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -774,7 +875,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -803,7 +908,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We will [compute cosine distance](https://en.wikipedia.org/wiki/Cosine_similarity) between two images using `scipy`. "
|
||||
]
|
||||
|
|
@ -812,7 +920,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -827,7 +937,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -904,7 +1018,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Note: The cosine distance between the original images comparable to the distance between the corresponding decoded images. A value of 1 indicates high similarity between the images and 0 indicates no similarity.\n",
|
||||
"\n",
|
||||
|
|
@ -914,7 +1031,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -944,7 +1065,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us compare the distance between different digits."
|
||||
]
|
||||
|
|
@ -952,7 +1076,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1026,7 +1154,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Print the results of the deep encoder test error for regression testing"
|
||||
]
|
||||
|
|
@ -1034,7 +1165,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1052,7 +1187,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1069,9 +1208,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Suggested tasks\n",
|
||||
"**Suggested tasks**\n",
|
||||
"\n",
|
||||
"- Try different activation functions.\n",
|
||||
"- Find which images are more similar to one another (a) using original image and (b) decoded image.\n",
|
||||
|
|
@ -1085,7 +1227,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -1108,7 +1252,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -13,7 +15,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 106: Part A - Time series prediction with LSTM (Basics)\n",
|
||||
"\n",
|
||||
|
|
@ -28,7 +33,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
|
|
@ -52,7 +59,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In this tutorial we will use [LSTM](https://en.wikipedia.org/wiki/Long_short-term_memory) to implement our model. LSTMs are well suited for this task because their ability to learn from experience. For details on how LSTMs work, see [this excellent post](http://colah.github.io/posts/2015-08-Understanding-LSTMs). \n",
|
||||
"\n",
|
||||
|
|
@ -68,7 +78,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -88,7 +100,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"There are two run modes:\n",
|
||||
"- *Fast mode*: `isFast` is set to `True`. This is the default mode for the notebooks, which means we train for fewer iterations or train / test on limited data. This ensures functional correctness of the notebook though the models produced are far from what a completed training would produce.\n",
|
||||
|
|
@ -100,7 +115,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -109,7 +126,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data generation\n",
|
||||
"\n",
|
||||
|
|
@ -123,9 +143,10 @@
|
|||
" \\{y_{21}, y_{22}, \\cdots, y_{2N}\\}, \\cdots,\n",
|
||||
" \\{y_{k1}, y_{k2}, \\cdots, y_{kN}\\}]\n",
|
||||
"$$\n",
|
||||
"\n",
|
||||
"> In the above samples $y_{i,j}$, represents the observed function value for the $i^{th}$ batch and $j^{th}$ time point within the time window of $N$ points. \n",
|
||||
"\n",
|
||||
"The desired output ($L$) with `M` steps in the future: $$ L = [ \\{y_{1,N+M}\\},\n",
|
||||
"> The desired output ($L$) with `M` steps in the future: $$ L = [ \\{y_{1,N+M}\\},\n",
|
||||
" \\{y_{2,N+M}\\}, \\cdots, \\{y_{k,N+M}\\}]$$\n",
|
||||
"\n",
|
||||
"> Note: `k` is a function of the length of the time series and the number of windows of size `N` one can have for the time series.\n",
|
||||
|
|
@ -139,7 +160,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -159,7 +182,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -193,7 +218,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us generate and visualize the generated data"
|
||||
]
|
||||
|
|
@ -201,7 +229,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -227,7 +259,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Network modeling\n",
|
||||
"\n",
|
||||
|
|
@ -240,7 +275,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -256,14 +293,20 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Training the network"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We define the `next_batch()` iterator that produces batches we can feed to the training function. \n",
|
||||
"Note that because CNTK supports variable sequence length, we must feed the batches as list of sequences. This is a convenience function to generate small batches of data often referred to as minibatch."
|
||||
|
|
@ -273,7 +316,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -292,7 +337,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Setup everything else we need for training the model: define user specified training parameters, define inputs, outputs, model and the optimizer."
|
||||
]
|
||||
|
|
@ -301,7 +349,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -314,7 +364,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Key Insight**\n",
|
||||
"\n",
|
||||
|
|
@ -344,7 +397,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -380,7 +435,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We are ready to train. 100 epochs should yield acceptable results."
|
||||
]
|
||||
|
|
@ -388,7 +446,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -426,7 +488,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -446,7 +512,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Normally we would validate the training on the data that we set aside for validation but since the input data is small we can run validattion on all parts of the dataset."
|
||||
]
|
||||
|
|
@ -455,7 +524,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -471,7 +542,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -491,7 +566,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -509,7 +588,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Since we used a simple sin(x) function we should expect that the errors are the same for train, validation and test sets. For real datasets that will be different of course. We also plot the expected output (Y) and the prediction our model made to shows how well the simple LSTM approach worked."
|
||||
]
|
||||
|
|
@ -517,7 +599,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -546,7 +632,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Not perfect but close enough, considering the simplicity of the model.\n",
|
||||
|
|
@ -560,7 +648,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -569,7 +659,7 @@
|
|||
"metadata": {
|
||||
"anaconda-cloud": {},
|
||||
"kernelspec": {
|
||||
"display_name": "Python [default]",
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
|
|
@ -583,7 +673,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -2,7 +2,10 @@
|
|||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 106: Part B - Time series prediction with LSTM (IOT Data)\n",
|
||||
"\n",
|
||||
|
|
@ -14,7 +17,7 @@
|
|||
"\n",
|
||||
"Using historic daily production of a solar panel, we want to predict the total power production of the solar panel array for a day. We will be using the LSTM based time series prediction model developed in part A to predict the daily output of a solar panel based on the initial readings of the day. \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"We train the model with historical data of the solar panel. In our example we want to predict the total power production of the solar panel array for the day starting with the initial readings of the day. We start predicting after the first 2 readings and adjust the prediction with each new reading.\n",
|
||||
"\n",
|
||||
|
|
@ -30,10 +33,11 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Setup\n",
|
||||
"We need a few imports and constants throughout the tutorial that we define here."
|
||||
]
|
||||
},
|
||||
|
|
@ -41,7 +45,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -70,7 +76,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -80,7 +88,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"There are two run modes:\n",
|
||||
"- *Fast mode*: `isFast` is set to `True`. This is the default mode for the notebooks, which means we train for fewer iterations or train / test on limited data. This ensures functional correctness of the notebook though the models produced are far from what a completed training would produce.\n",
|
||||
|
|
@ -94,7 +105,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -106,9 +119,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Data generation\n",
|
||||
"## Data generation\n",
|
||||
"\n",
|
||||
"Our solar panel, emits two measures at every 30 min interval:\n",
|
||||
"- `solar.current` is the current production in Watt\n",
|
||||
|
|
@ -129,9 +145,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Pre-processing\n",
|
||||
"### Pre-processing\n",
|
||||
"Most of the code in this example is related to data preparation. Thankfully the pandas library make this easy.\n",
|
||||
"\n",
|
||||
"`generate_solar_data()` function performs the following tasks:\n",
|
||||
|
|
@ -145,7 +164,7 @@
|
|||
"\n",
|
||||
"**Note** if we have less than 8 datapoints for a day we skip over the day assuming something is missing in the raw data. If we get more than 14 data points in a day we truncate the readings.\n",
|
||||
"\n",
|
||||
"## Training / Testing / Validation data preparation\n",
|
||||
"### Training / Testing / Validation data preparation\n",
|
||||
"We start by reading the csv file for use with CNTK. The raw data is sorted by time and we should randomize it before splitting into training, validation and test datasets but this would make it impractical to visualize results in the tutorial. Hence, we split the dataset in the following manner: pick in sequence, 8 values for training, 1 for validation and 1 for test until there is no more data. This will spread training, validation and test datasets across the full timeline while preserving time order.\n"
|
||||
]
|
||||
},
|
||||
|
|
@ -153,7 +172,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -235,7 +256,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data caching\n",
|
||||
"For routine testing we would like to cache the data locally when available. If it is not available from the cache locations we shall download."
|
||||
|
|
@ -244,7 +268,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -268,9 +296,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Utility for data fetching\n",
|
||||
"**Utility for data fetching**\n",
|
||||
"\n",
|
||||
"`next_batch()` yields the next batch for training. We use variable size sequences supported by CNTK and batches are a list of numpy arrays where the numpy arrays have variable length. \n",
|
||||
"\n",
|
||||
|
|
@ -281,7 +312,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -300,16 +333,24 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Understand the data format\n",
|
||||
"**Understand the data format**\n",
|
||||
"\n",
|
||||
"You can now see the sequence we are going to feed to the LSTM. Note if we have less than 8 datapoints for a day we skip over the day assuming something is missing in the raw data. If we get more than 14 data points in a day we truncate the readings."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -331,7 +372,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -352,9 +397,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## LSTM network setup\n",
|
||||
"## Model Creation (LSTM network)\n",
|
||||
"\n",
|
||||
"Corresponding to the maximum possible 14 data points in the input sequence, we model our network with 14 LSTM cells, 1 cell for each data point we take during the day. Since the input sequences can be between 8 and 14 data points per sequence, we take the advantage of CNTK support for variable sequences as input to a LSTM so we can feed our sequences as-is with no additional need for padding.\n",
|
||||
"\n",
|
||||
|
|
@ -382,7 +430,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -400,9 +450,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Training\n",
|
||||
"## Training\n",
|
||||
"Before we can start training we need to bind our input variables for the model and define what optimizer we want to use. For this example we choose the `adam` optimizer. We choose `squared_error` as our loss function."
|
||||
]
|
||||
},
|
||||
|
|
@ -410,7 +463,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -444,7 +499,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Time to start training."
|
||||
]
|
||||
|
|
@ -452,7 +510,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -491,7 +553,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"A look how the loss function shows how the model is converging:"
|
||||
]
|
||||
|
|
@ -499,7 +564,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -518,7 +587,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let us validate the training validation and test dataset. We use mean squared error as measure which might be a little simplistic. A method that would define a ratio how many predictions have been inside a given tolerance would make a better measure."
|
||||
]
|
||||
|
|
@ -527,7 +599,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -543,7 +617,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -563,7 +641,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -581,9 +663,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Visualize the prediction\n",
|
||||
"## Visualize results\n",
|
||||
"\n",
|
||||
"Our model has been trained well, given the train, validation and test errors are in the same ball park. Predicted time series data renders well with visualization of the results. Let us take our newly created model, make predictions and plot them against the actual readings."
|
||||
]
|
||||
|
|
@ -592,6 +677,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": false
|
||||
},
|
||||
"outputs": [
|
||||
|
|
@ -623,7 +711,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"If we let the model train for 2000 epochs the predictions are close to the actual data and follow the right pattern."
|
||||
]
|
||||
|
|
@ -631,10 +722,12 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Suggested activity\n",
|
||||
"**Suggested activity**\n",
|
||||
"\n",
|
||||
"So what we do with this model? A practical application would be to generate alerts if the actual output is not in line with the prediction, for example if one of the panels is failing. The solar array that goes with our dataset has 16 panels. If we'd want to detect failure without generating false alerts, the accuracy of our prediction would need to be at least 1 - 1/16, around 94%. Our model is close to this but would most likely generate occasional false alerts.\n",
|
||||
"\n",
|
||||
|
|
@ -646,6 +739,15 @@
|
|||
"\n",
|
||||
"We hope this tutorial gets you started on time series prediction with neural networks."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
|
@ -665,7 +767,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -2,7 +2,10 @@
|
|||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 201A Part A: CIFAR-10 Data Loader\n",
|
||||
"\n",
|
||||
|
|
@ -23,7 +26,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -52,7 +57,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data download\n",
|
||||
"\n",
|
||||
|
|
@ -65,7 +73,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -76,7 +86,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We first setup a few helper functions to download the CIFAR data. The archive contains the files data_batch_1, data_batch_2, ..., data_batch_5, as well as test_batch. Each of these files is a Python \"pickled\" object produced with cPickle. To prepare the input data for use in CNTK we use three oprations:\n",
|
||||
"> `readBatch`: Unpack the pickle files\n",
|
||||
|
|
@ -84,14 +97,19 @@
|
|||
"> `loadData`: Compose the data into single train and test objects\n",
|
||||
"\n",
|
||||
"> `saveTxt`: As the name suggests, saves the label and the features into text files for both training and testing. \n",
|
||||
" "
|
||||
"\n",
|
||||
"### Read images\n",
|
||||
"\n",
|
||||
"Unpack the picked files and create a numpy stack."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -140,8 +158,13 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Save images\n",
|
||||
"\n",
|
||||
"In addition to saving the images in the text format, we would save the images in PNG format. In addition we also compute the mean of the image. `saveImage` and `saveMean` are two functions used for this purpose."
|
||||
]
|
||||
},
|
||||
|
|
@ -149,7 +172,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -194,7 +219,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"`saveTrainImages` and `saveTestImages` are simple wrapper functions to iterate through the data set."
|
||||
]
|
||||
|
|
@ -203,7 +231,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -245,7 +275,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -263,10 +295,23 @@
|
|||
"root_dir = os.getcwd()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Save labels and features\n",
|
||||
"\n",
|
||||
"Now we save the label and the features into text files for both training and testing"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -332,7 +377,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -13,22 +15,28 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 201B: Hands On Labs Image Recognition"
|
||||
"# CNTK 201B: Hands On Image Recognition"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"This hands-on lab shows how to implement image recognition task using [convolution network][] with CNTK v2 Python API. You will start with a basic feedforward CNN architecture to classify [CIFAR dataset](https://www.cs.toronto.edu/~kriz/cifar.html), then you will keep adding advanced features to your network. Finally, you will implement a VGG net and residual net like the one that won ImageNet competition but smaller in size.\n",
|
||||
"This tutorial shows how to implement image recognition task using [convolution network][] with CNTK v2 Python API. You will start with a basic feedforward CNN architecture to classify [CIFAR dataset](https://www.cs.toronto.edu/~kriz/cifar.html), then you will keep adding advanced features to your network. Finally, you will implement a VGG net and residual net like the one that won ImageNet competition but smaller in size.\n",
|
||||
"\n",
|
||||
"[convolution network]:https://en.wikipedia.org/wiki/Convolutional_neural_network\n",
|
||||
"\n",
|
||||
"## Introduction\n",
|
||||
"\n",
|
||||
"In this hands-on, you will practice the following:\n",
|
||||
"In this tutorial, you will practice the following:\n",
|
||||
"\n",
|
||||
"* Understanding subset of CNTK python API needed for image classification task.\n",
|
||||
"* Write a custom convolution network to classify CIFAR dataset.\n",
|
||||
|
|
@ -45,7 +53,7 @@
|
|||
"\n",
|
||||
"## Prerequisites\n",
|
||||
"\n",
|
||||
"CNTK 201A hands-on lab, in which you will download and prepare CIFAR dataset is a prerequisites for this lab. This tutorial depends on CNTK v2, so before starting this lab you will need to install CNTK v2. Furthermore, all the tutorials in this lab are done in python, therefore, you will need a basic knowledge of Python. \n",
|
||||
"Please run CNTK 201A image data downloader notebook to download and prepare CIFAR dataset. \n",
|
||||
"\n",
|
||||
"CNTK 102 lab is recommended but not a prerequisite for this tutorial. However, a basic understanding of Deep Learning is needed. Familiarity with basic convolution operations is highly desirable (Refer to CNTK tutorial 103D).\n",
|
||||
"\n",
|
||||
|
|
@ -57,7 +65,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -80,7 +92,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The above image is from: https://www.cs.toronto.edu/~kriz/cifar.html\n",
|
||||
"\n",
|
||||
|
|
@ -96,7 +111,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -119,7 +138,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The stack of feature maps output are the input to the next layer."
|
||||
]
|
||||
|
|
@ -127,7 +149,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -150,12 +176,15 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"> Gradient-Based Learning Applied to Document Recognition, Proceedings of the IEEE, 86(11):2278-2324, November 1998\n",
|
||||
"> Y. LeCun, L. Bottou, Y. Bengio and P. Haffner\n",
|
||||
"\n",
|
||||
"#### In CNTK:\n",
|
||||
"**In CNTK**:\n",
|
||||
"\n",
|
||||
"Here the [convolution][] layer in Python:\n",
|
||||
"\n",
|
||||
|
|
@ -185,7 +214,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -208,9 +241,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### In CNTK:\n",
|
||||
"**In CNTK**:\n",
|
||||
"\n",
|
||||
"Here the [pooling][] layer in Python:\n",
|
||||
"\n",
|
||||
|
|
@ -237,7 +273,7 @@
|
|||
"> Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"#### In CNTK:\n",
|
||||
"**In CNTK**:\n",
|
||||
"\n",
|
||||
"Dropout layer in Python:\n",
|
||||
"\n",
|
||||
|
|
@ -254,7 +290,7 @@
|
|||
"> Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift\n",
|
||||
"> Sergey Ioffe, Christian Szegedy\n",
|
||||
"\n",
|
||||
"#### In CNTK:\n",
|
||||
"**In CNTK**:\n",
|
||||
"\n",
|
||||
"[Batch normalization][] layer in Python:\n",
|
||||
"\n",
|
||||
|
|
@ -266,20 +302,17 @@
|
|||
"\n",
|
||||
"[Batch normalization]:https://www.cntk.ai/pythondocs/layerref.html#batchnormalization-layernormalization-stabilizer\n",
|
||||
"\n",
|
||||
"## Microsoft Cognitive Network Toolkit (CNTK)\n",
|
||||
"\n",
|
||||
"CNTK is a highly flexible computation graphs, each node take inputs as tensors and produce tensors as the result of the computation. Each node is exposed in Python API, which give you the flexibility of creating any custom graphs, you can also define your own node in Python or C++ using CPU, GPU or both.\n",
|
||||
"\n",
|
||||
"For Deep learning, you can use the low level API directly or you can use CNTK layered API. We will start with the low level API, then switch to the layered API in this lab.\n",
|
||||
"\n",
|
||||
"So let's first import the needed modules for this lab."
|
||||
"Let us begin by first importing the modules."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -301,7 +334,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In the block below, we check if we are running this notebook in the CNTK internal test machines by looking for environment variables defined there. We then select the right target device (GPU vs CPU) to test this notebook. In other cases, we use CNTK's default policy to use the best available device (GPU, if available, else CPU)."
|
||||
]
|
||||
|
|
@ -310,7 +346,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -321,68 +359,15 @@
|
|||
" C.device.try_set_default_device(C.device.gpu(0))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<img src=\"https://cntk.ai/jup/201/CNN.png\"/>"
|
||||
],
|
||||
"text/plain": [
|
||||
"<IPython.core.display.Image object>"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Figure 5\n",
|
||||
"Image(url=\"https://cntk.ai/jup/201/CNN.png\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Now that we imported the needed modules, let's implement our first CNN, as shown in Figure 5 above.\n",
|
||||
"\n",
|
||||
"Let's implement the above network using CNTK layer API:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def create_basic_model(input, out_dims):\n",
|
||||
" with C.layers.default_options(init=C.glorot_uniform(), activation=C.relu):\n",
|
||||
" net = C.layers.Convolution((5,5), 32, pad=True)(input)\n",
|
||||
" net = C.layers.MaxPooling((3,3), strides=(2,2))(net)\n",
|
||||
"## Data reading\n",
|
||||
"\n",
|
||||
" net = C.layers.Convolution((5,5), 32, pad=True)(net)\n",
|
||||
" net = C.layers.MaxPooling((3,3), strides=(2,2))(net)\n",
|
||||
"\n",
|
||||
" net = C.layers.Convolution((5,5), 64, pad=True)(net)\n",
|
||||
" net = C.layers.MaxPooling((3,3), strides=(2,2))(net)\n",
|
||||
" \n",
|
||||
" net = C.layers.Dense(64)(net)\n",
|
||||
" net = C.layers.Dense(out_dims, activation=None)(net)\n",
|
||||
" \n",
|
||||
" return net"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"To train the above model we need two things:\n",
|
||||
"* Read the training images and their corresponding labels.\n",
|
||||
"* Define a cost function, compute the cost for each mini-batch and update the model weights according to the cost value.\n",
|
||||
|
|
@ -402,7 +387,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -455,7 +442,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -477,17 +468,93 @@
|
|||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<img src=\"https://cntk.ai/jup/201/CNN.png\"/>"
|
||||
],
|
||||
"text/plain": [
|
||||
"<IPython.core.display.Image object>"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"Now let us write the training and validation loop."
|
||||
"# Figure 5\n",
|
||||
"Image(url=\"https://cntk.ai/jup/201/CNN.png\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Model creation (Basic CNN)\n",
|
||||
"\n",
|
||||
"Now that we imported the needed modules, let's implement our first CNN, as shown in Figure 5 above.\n",
|
||||
"\n",
|
||||
"Let's implement the above network using CNTK layer API:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def create_basic_model(input, out_dims):\n",
|
||||
" with C.layers.default_options(init=C.glorot_uniform(), activation=C.relu):\n",
|
||||
" net = C.layers.Convolution((5,5), 32, pad=True)(input)\n",
|
||||
" net = C.layers.MaxPooling((3,3), strides=(2,2))(net)\n",
|
||||
"\n",
|
||||
" net = C.layers.Convolution((5,5), 32, pad=True)(net)\n",
|
||||
" net = C.layers.MaxPooling((3,3), strides=(2,2))(net)\n",
|
||||
"\n",
|
||||
" net = C.layers.Convolution((5,5), 64, pad=True)(net)\n",
|
||||
" net = C.layers.MaxPooling((3,3), strides=(2,2))(net)\n",
|
||||
" \n",
|
||||
" net = C.layers.Dense(64)(net)\n",
|
||||
" net = C.layers.Dense(out_dims, activation=None)(net)\n",
|
||||
" \n",
|
||||
" return net"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Training and evaluation\n",
|
||||
"\n",
|
||||
"Now let us write the training and evaluation loop."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -622,7 +689,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -672,7 +743,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Although, this model is very simple, it still has too much code, we can do better. Here the same model in more terse format:"
|
||||
]
|
||||
|
|
@ -681,7 +755,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -703,7 +779,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -758,7 +838,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Now that we have a trained model, let us classify the following image of a truck. We use PIL to read the image."
|
||||
]
|
||||
|
|
@ -766,7 +849,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -791,7 +878,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -805,7 +894,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"During training we have subtracted the mean from the input images. Here we take an approximate value of the mean and subtract it from the image."
|
||||
]
|
||||
|
|
@ -814,7 +906,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -838,7 +932,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -858,8 +956,13 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Model: CNN with dropout\n",
|
||||
"\n",
|
||||
"Adding dropout layer, with drop rate of 0.25, before the last dense layer:"
|
||||
]
|
||||
},
|
||||
|
|
@ -867,7 +970,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -890,7 +995,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -940,8 +1049,13 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Model: CNN with BN\n",
|
||||
"\n",
|
||||
"Add batch normalization after each convolution and before the last dense layer:"
|
||||
]
|
||||
},
|
||||
|
|
@ -949,7 +1063,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -973,7 +1089,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1023,8 +1143,15 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Popular Model\n",
|
||||
"\n",
|
||||
"### VGG style network\n",
|
||||
"\n",
|
||||
"Let's implement an inspired VGG style network, using layer API, here the architecture:\n",
|
||||
"\n",
|
||||
"| VGG9 |\n",
|
||||
|
|
@ -1051,7 +1178,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1075,7 +1204,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1125,7 +1258,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Residual Network (ResNet)\n",
|
||||
"\n",
|
||||
|
|
@ -1135,7 +1271,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -1158,7 +1298,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The idea of the above block is 2 folds:\n",
|
||||
"\n",
|
||||
|
|
@ -1202,7 +1345,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1247,7 +1392,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let's write the full model:"
|
||||
]
|
||||
|
|
@ -1256,7 +1404,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 28,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1280,7 +1430,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1329,7 +1483,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -1352,7 +1508,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -2,7 +2,10 @@
|
|||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 202: Language Understanding with Recurrent Networks\n",
|
||||
"\n",
|
||||
|
|
@ -25,7 +28,7 @@
|
|||
"* recurrent networks ([Wikipedia page](https://en.wikipedia.org/wiki/Recurrent_neural_network))\n",
|
||||
"* text embedding ([Wikipedia page](https://en.wikipedia.org/wiki/Word_embedding))\n",
|
||||
"\n",
|
||||
"### Prerequisites\n",
|
||||
"## Prerequisites\n",
|
||||
"\n",
|
||||
"We assume that you have already [installed CNTK](https://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine).\n",
|
||||
"This tutorial requires CNTK V2. We strongly recommend to run this tutorial on a machine with\n",
|
||||
|
|
@ -34,13 +37,16 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Downloading the data\n",
|
||||
"## Data download\n",
|
||||
"\n",
|
||||
"In this tutorial we are going to use a (lightly preprocessed) version of the ATIS dataset. You can download the data automatically by running the cells below or by executing the manual instructions.\n",
|
||||
"\n",
|
||||
"#### Fallback manual instructions\n",
|
||||
"**Fallback manual instructions**\n",
|
||||
"Download the ATIS [training](https://github.com/Microsoft/CNTK/blob/release/2.1/Tutorials/SLUHandsOn/atis.train.ctf) \n",
|
||||
"and [test](https://github.com/Microsoft/CNTK/blob/release/2.1/Tutorials/SLUHandsOn/atis.test.ctf) \n",
|
||||
"files and put them at the same folder as this notebook. If you want to see how the model is \n",
|
||||
|
|
@ -53,7 +59,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
|
|
@ -106,9 +114,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Importing CNTK and other useful libraries\n",
|
||||
"**Importing libraries**: CNTK, math and numpy \n",
|
||||
"\n",
|
||||
"CNTK's Python module contains several submodules like `io`, `learner`, and `layers`. We also use NumPy in some cases since the results returned by CNTK work like NumPy arrays."
|
||||
]
|
||||
|
|
@ -117,7 +128,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -132,9 +145,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Task and Model Structure\n",
|
||||
"## Task Overview\n",
|
||||
"\n",
|
||||
"The task we want to approach in this tutorial is slot tagging.\n",
|
||||
"We use the [ATIS corpus](https://catalog.ldc.upenn.edu/LDC95S26).\n",
|
||||
|
|
@ -176,6 +192,8 @@
|
|||
"or a slot label that begins with `B-` for the first word, and with `I-` for any\n",
|
||||
"additional consecutive word that belongs to the same slot.\n",
|
||||
"\n",
|
||||
"## Model Creation\n",
|
||||
"\n",
|
||||
"The model we will use is a recurrent model consisting of an embedding layer,\n",
|
||||
"a recurrent LSTM cell, and a dense layer to compute the posterior probabilities:\n",
|
||||
"\n",
|
||||
|
|
@ -209,7 +227,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -237,7 +257,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Now we are ready to create a model and inspect it. \n",
|
||||
"\n",
|
||||
|
|
@ -251,7 +274,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -278,7 +305,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In our case we have input as one-hot encoded vector of length 943 and the output dimension `emb_dim` is set to 150. In the code below we pass the input variable `x` to our model `z`. This binds the model with input data of known shape. In this case, the input shape will be the size of the input vocabulary. With this modification, the parameter returned by the embed layer is completely specified (943, 150). **Note**: You can initialize the Embedding matrix with pre-computed vectors using [Word2Vec](https://en.wikipedia.org/wiki/Word2vec) or [GloVe](https://en.wikipedia.org/wiki/GloVe_%28machine_learning%29)."
|
||||
]
|
||||
|
|
@ -286,7 +316,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -304,10 +338,11 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## CNTK Configuration\n",
|
||||
"\n",
|
||||
"To train and test a model in CNTK, we need to create a model and specify how to read data and perform training and testing. \n",
|
||||
"\n",
|
||||
"In order to train we need to specify:\n",
|
||||
|
|
@ -318,7 +353,7 @@
|
|||
"\n",
|
||||
"[comment]: <> (For testing ...)\n",
|
||||
"\n",
|
||||
"### A Brief Look at Data and Data Reading\n",
|
||||
"## Data Reading\n",
|
||||
"\n",
|
||||
"We already looked at the data.\n",
|
||||
"But how do you generate this format?\n",
|
||||
|
|
@ -348,7 +383,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -363,7 +400,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -384,9 +425,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Trainer\n",
|
||||
"## Training\n",
|
||||
"\n",
|
||||
"We also must define the training criterion (loss function), and also an error metric to track. In most tutorials, we know the input dimensions and the corresponding labels. We directly create the loss and the error functions. In this tutorial we will do the same. However, we take a brief detour and learn about placeholders. This concept would be useful for Task 3. \n",
|
||||
"\n",
|
||||
|
|
@ -400,7 +444,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -426,7 +474,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"While the cell above works well when one has input parameters defined at network creation, it compromises readability. Hence we prefer creating functions as shown below"
|
||||
]
|
||||
|
|
@ -435,7 +486,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -449,7 +502,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -511,9 +566,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Running it\n",
|
||||
"**Run the trainer**\n",
|
||||
"\n",
|
||||
"You can find the complete recipe below."
|
||||
]
|
||||
|
|
@ -523,6 +581,8 @@
|
|||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": false
|
||||
},
|
||||
"outputs": [
|
||||
|
|
@ -557,7 +617,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"This shows how learning proceeds over epochs (passes through the data).\n",
|
||||
"For example, after four epochs, the loss, which is the cross-entropy criterion, \n",
|
||||
|
|
@ -585,7 +648,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Evaluating the model\n",
|
||||
"\n",
|
||||
|
|
@ -596,7 +662,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -628,7 +696,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Now we can measure the model accuracy by going through all the examples in the test set and using the ``test_minibatch`` method of the trainer created inside the evaluate function defined above. At the moment (when this tutorial was written) the Trainer constructor requires a learner (even if it is only used to perform ``test_minibatch``) so we have to specify a dummy learner. In the future it will be allowed to construct a Trainer without specifying a learner as long as the trainer only calls ``test_minibatch``"
|
||||
]
|
||||
|
|
@ -636,7 +707,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -691,7 +766,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The following block of code illustrates how to evaluate a single sequence. Additionally we show how one can pass in the information using NumPy arrays."
|
||||
]
|
||||
|
|
@ -699,7 +777,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -753,14 +835,17 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Modifying the Model\n",
|
||||
"\n",
|
||||
"In the following, you will be given tasks to practice modifying CNTK configurations.\n",
|
||||
"The solutions are given at the end of this document... but please try without!\n",
|
||||
"\n",
|
||||
"### A Word About [`Sequential()`](https://www.cntk.ai/pythondocs/layerref.html#sequential)\n",
|
||||
"**A Word About [`Sequential()`](https://www.cntk.ai/pythondocs/layerref.html#sequential)**\n",
|
||||
"\n",
|
||||
"Before jumping to the tasks, let's have a look again at the model we just ran.\n",
|
||||
"The model is described in what we call *function-composition style*.\n",
|
||||
|
|
@ -804,16 +889,17 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Task 1: Add Batch Normalization\n",
|
||||
"\n",
|
||||
"We now want to add new layers to the model, specifically batch normalization.\n",
|
||||
"\n",
|
||||
"Batch normalization is a popular technique for speeding up convergence.\n",
|
||||
"It is often used for image-processing setups, for example our other [hands-on lab on image\n",
|
||||
"recognition](./Hands-On-Labs-Image-Recognition).\n",
|
||||
"But could it work for recurrent models, too?\n",
|
||||
"It is often used for image-processing setups. But could it work for recurrent models, too?\n",
|
||||
"\n",
|
||||
"> Note: training with Batch Normalization is currently only supported on GPU.\n",
|
||||
"\n",
|
||||
|
|
@ -833,7 +919,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -853,7 +941,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Task 2: Add a Lookahead \n",
|
||||
"\n",
|
||||
|
|
@ -879,7 +970,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -899,7 +992,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Task 3: Bidirectional Recurrent Model\n",
|
||||
"\n",
|
||||
|
|
@ -966,7 +1062,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -986,7 +1084,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Works like a charm! This model achieves 0.30%, better than the lookahead model above.\n",
|
||||
"The bidirectional model has 40% less parameters than the lookahead one. However, if you go back and look closely\n",
|
||||
|
|
@ -997,15 +1098,22 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Solution 1: Adding Batch Normalization"
|
||||
"**Solution 1: Adding Batch Normalization**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1045,9 +1153,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Solution 2: Add a Lookahead"
|
||||
"**Solution 2: Add a Lookahead**"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -1055,6 +1166,8 @@
|
|||
"execution_count": 19,
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [
|
||||
|
|
@ -1100,15 +1213,22 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Solution 3: Bidirectional Recurrent Model"
|
||||
"**Solution 3: Bidirectional Recurrent Model**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1156,7 +1276,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -1165,7 +1287,7 @@
|
|||
"metadata": {
|
||||
"anaconda-cloud": {},
|
||||
"kernelspec": {
|
||||
"display_name": "Python [default]",
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
|
|
@ -1179,7 +1301,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -13,7 +15,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 203: Reinforcement Learning Basics\n",
|
||||
"\n",
|
||||
|
|
@ -28,7 +33,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -51,13 +60,17 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"**Problem**\n",
|
||||
"\n",
|
||||
"We will use the [CartPole](https://gym.openai.com/envs/CartPole-v0) environment from OpenAI's [gym](https://github.com/openai/gym) simulator to teach a cart to balance a pole. As described in the link above, in the CartPole example, a pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The system is controlled by applying a force of +1 or -1 to the cart. A reward of +1 is provided for every timestep that the pole remains upright. The episode ends when the pole is more than 15 degrees from vertical, or the cart moves more than 2.4 units from the center. See figure below for reference.\n",
|
||||
"\n",
|
||||
"**Goal**\n",
|
||||
"\n",
|
||||
"Our goal is to prevent the pole from falling over as the cart moves with the pole in upright position (perpendicular to the cart) as the starting state. More specifically if the pole is less than 15 degrees from vertical while the cart is within 2.4 units of the center we will collect reward. In this tutorial, we will train till we learn a set of actions (policies) that lead to an average reward of 200 or more over last 50 batches.\n",
|
||||
"\n",
|
||||
"In, RL terminology, the goal is to find _policies_ $a$, that maximize the _reward_ $r$ (feedback) through interaction with some environment (in this case the pole being balanced on the cart). So given a series of experiences $$s \\xrightarrow{a} r, s'$$ we then can learn how to choose action $a$ in a given state $s$ to maximize the accumulated reward $r$ over time:\n",
|
||||
|
|
@ -82,9 +95,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Before we start...\n",
|
||||
"## Prerequisites\n",
|
||||
"Please run the following cell from the menu above or select the cell below and hit `Shift + Enter` to ensure the environment is ready. Verify that the following imports work in your notebook."
|
||||
]
|
||||
},
|
||||
|
|
@ -92,7 +108,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -110,7 +128,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We use the following construct to install the OpenAI gym package if it is not installed. For users new to Jupyter environment, this construct can be used to install any python package. "
|
||||
]
|
||||
|
|
@ -119,7 +140,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -132,9 +155,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Select the notebook run mode\n",
|
||||
"**Select the notebook run mode**\n",
|
||||
"\n",
|
||||
"There are two run modes:\n",
|
||||
"- *Fast mode*: `isFast` is set to `True`. This is the default mode for the notebooks, which means we train for fewer iterations or train / test on limited data. This ensures functional correctness of the notebook though the models produced are far from what a completed training would produce.\n",
|
||||
|
|
@ -146,7 +172,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -156,15 +184,20 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CartPole: Data and Environment"
|
||||
"## CartPole: Data and Environment"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We will use the [CartPole](https://gym.openai.com/envs/CartPole-v0) environment from OpenAI's [gym](https://github.com/openai/gym) simulator to teach a cart to balance a pole. Please follow the links to get more details.\n",
|
||||
"\n",
|
||||
|
|
@ -187,9 +220,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Part 1: DQN\n",
|
||||
"## Part 1: DQN\n",
|
||||
"\n",
|
||||
"After a transition $(s,a,r,s')$, we are trying to move our value function $Q(s,a)$ closer to our target $r+\\gamma \\max_{a'}Q(s',a')$, where $\\gamma$ is a discount factor for future rewards and ranges in value between 0 and 1.\n",
|
||||
"\n",
|
||||
|
|
@ -201,18 +237,25 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Setting up the model\n",
|
||||
"\\begin{equation}\n",
|
||||
"### Model: DQN\n",
|
||||
"\n",
|
||||
"$$\n",
|
||||
"l_1 = relu( x W_1 + b_1) \\\\\n",
|
||||
"Q(s,a) = l_1 W_2 + b_2 \\\\\n",
|
||||
"\\end{equation}"
|
||||
"$$"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We will start with a slightly modified version for Keras, https://github.com/jaara/AI-blog/blob/master/CartPole-basic.py, published by Jaromír Janisch in his [AI blog](https://jaromiru.com/2016/09/27/lets-make-a-dqn-theory/), and will then incrementally convert it to use CNTK.\n",
|
||||
"\n",
|
||||
|
|
@ -225,7 +268,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -239,7 +284,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In the block below, we check if we are running this notebook in the CNTK internal test machines by looking for environment variables defined there. We then select the right target device (GPU vs CPU) to test this notebook. In other cases, we use CNTK's default policy to use the best available device (GPU, if available, else CPU)."
|
||||
]
|
||||
|
|
@ -248,7 +296,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -262,7 +312,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"STATE_COUNT = 4 (corresponding to $(x, \\dot{x}, \\theta, \\dot{\\theta})$),\n",
|
||||
"\n",
|
||||
|
|
@ -272,7 +325,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
|
|
@ -303,7 +360,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Note: in the cell below we highlight how one would do it in Keras. And a marked similarity with CNTK. While CNTK allows for more compact representation, we present a slightly verbose illustration for ease of learning.\n",
|
||||
"\n",
|
||||
|
|
@ -316,7 +376,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -369,7 +431,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The `Memory` class stores the different states, actions and rewards."
|
||||
]
|
||||
|
|
@ -378,7 +443,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -401,7 +468,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The `Agent` uses the `Brain` and `Memory` to replay the past actions to choose optimal set of actions that maximize the rewards."
|
||||
]
|
||||
|
|
@ -410,7 +480,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -480,11 +552,14 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Brain surgery\n",
|
||||
"### Training\n",
|
||||
"\n",
|
||||
"As any learning experiences, we expect to see the initial state of actions to be wild exploratory and over the iterations the system learns the range of actions that yield longer runs and collect more rewards. The tutorial below implements the [$\\epsilon$-greedy](https://en.wikipedia.org/wiki/Reinforcement_learning) approach. "
|
||||
"As any learning experiences, we expect to see the initial state of actions to be wild exploratory and over the iterations the system learns the range of actions that yield longer runs and collect more rewards. The tutorial below implements the [epsilon-greedy](https://en.wikipedia.org/wiki/Reinforcement_learning) approach (a.k.a. $\\epsilon$-greedy). "
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -492,6 +567,8 @@
|
|||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": false
|
||||
},
|
||||
"outputs": [],
|
||||
|
|
@ -516,7 +593,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Exploration - exploitation trade-off\n",
|
||||
"\n",
|
||||
|
|
@ -526,7 +606,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -558,7 +642,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We are now ready to train our agent using **DQN**. Note this would take anywhere between 2-10 min and we stop whenever the learner hits the average reward of 200 over past 50 batches. One would get better results if they could train the learner until say one hits a reward of 200 or higher for say larger number of runs. This is left as an exercise."
|
||||
]
|
||||
|
|
@ -566,7 +653,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -743,7 +834,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"If you run it, you should see something like\n",
|
||||
"```\n",
|
||||
|
|
@ -760,17 +854,24 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Task 1.1\n",
|
||||
"**Task 1.1**\n",
|
||||
"Rewrite the model without using the layer lib.\n",
|
||||
"#### Task 1.2\n",
|
||||
"\n",
|
||||
"**Task 1.2**\n",
|
||||
"Play with different [learners](https://cntk.ai/pythondocs/cntk.learner.html#module-cntk.learner). Which one works better? Worse? Think about which parameters you would need to adapt when switching from one learner to the other."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Running the DQN model"
|
||||
]
|
||||
|
|
@ -778,7 +879,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
|
|
@ -825,12 +930,16 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Part 2: Policy gradient\n",
|
||||
"## Part 2: Policy gradient (PG)\n",
|
||||
"**Goal:**\n",
|
||||
"\\begin{equation}\\text{maximize } E [R | \\pi_\\theta]\n",
|
||||
"\\end{equation}\n",
|
||||
"$$\n",
|
||||
"\\text{maximize } E [R | \\pi_\\theta]\n",
|
||||
"$$\n",
|
||||
"\n",
|
||||
"**Approach:**\n",
|
||||
"1. Collect experience (sample a bunch of trajectories through $(s,a)$ space)\n",
|
||||
|
|
@ -843,9 +952,13 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Rewards:\n",
|
||||
"### Rewards\n",
|
||||
"\n",
|
||||
"Remember, we get +1 reward for every time step, in which we still were in the game.\n",
|
||||
"\n",
|
||||
"The problem: we normally do not know, which action led to a continuation of the game, and which was actually a bad one. Our simple heuristic: actions in the beginning of the episode are good, and those towards the end are likely bad (they led to losing the game after all)."
|
||||
|
|
@ -855,7 +968,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -872,7 +987,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -903,7 +1022,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We normalize the rewards so that they tank below zero towards the end. gamma controls how late the rewards tank."
|
||||
]
|
||||
|
|
@ -911,7 +1033,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -944,7 +1070,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -978,14 +1108,18 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Setting up the model\n",
|
||||
"\\begin{equation}\n",
|
||||
"### Model: Policy Gradient\n",
|
||||
"\n",
|
||||
"$$\n",
|
||||
"l_1 = relu( x W_1 + b_1) \\\\\n",
|
||||
"l_2 = l_1 W_2 + b_2 \\\\\n",
|
||||
"\\pi(a|s) = sigmoid(l_2)\n",
|
||||
"\\end{equation}\n",
|
||||
"$$\n",
|
||||
"\n",
|
||||
"Note: in policy gradient approach, the output of the dense layer is mapped into to a 0-1 range via the sigmoid function."
|
||||
]
|
||||
|
|
@ -994,7 +1128,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1019,15 +1155,24 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Running the PG model\n",
|
||||
"\n",
|
||||
"**Policy Search**: The optimal policy search can be carried out with either gradient free approaches or by computing gradients over the policy space ($\\pi_\\theta$) which is parameterized by $\\theta$. In this tutorial, we use the classic forward (`loss.forward`) and back (`loss.backward`) propagation of errors over the parameterized space $\\theta$. In this case, $\\theta = \\{W_1, b_1, W_2, b_2\\}$, our model parameters. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1173,16 +1318,22 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# Solutions\n",
|
||||
"#### Solution 1.1"
|
||||
"**Solutions**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -1211,7 +1362,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -1241,7 +1396,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -1264,7 +1421,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -4,7 +4,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -13,7 +15,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 204: Sequence to Sequence Networks with Text Data\n",
|
||||
"\n",
|
||||
|
|
@ -28,7 +33,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -51,7 +60,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In this tutorial, we are going to be talking about the fourth paradigm: many-to-many where the length of the output does not necessarily equal the length of the input, also known as sequence-to-sequence networks. The input is a sequence with a dynamic length, and the output is also a sequence with some dynamic length. It is the logical extension of the many-to-one paradigm in that previously we were predicting some category (which could easily be one of `V` words where `V` is an entire vocabulary) and now we want to predict a whole sequence of those categories.\n",
|
||||
"\n",
|
||||
|
|
@ -65,7 +77,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -88,7 +104,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The basic sequence-to-sequence network passes the information from the encoder to the decoder by initializing the decoder RNN with the final hidden state of the encoder as its initial hidden state. The input is then a \"sequence start\" tag (`<s>` in the diagram above) which primes the decoder to start generating an output sequence. Then, whatever word (or note or image, etc.) it generates at that step is fed in as the input for the next step. The decoder keeps generating outputs until it hits the special \"end sequence\" tag (`</s>` above).\n",
|
||||
"\n",
|
||||
|
|
@ -98,7 +117,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -121,34 +144,41 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The `Attention` layer above takes the current value of the hidden state in the Decoder, all of the hidden states in the Encoder, and calculates an augmented version of the hidden state to use. More specifically, the contribution from the Encoder's hidden states will represent a weighted sum of all of its hidden states where the highest weight corresponds both to the biggest contribution to the augmented hidden state and to the hidden state that will be most important for the Decoder to consider when generating the next word."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Problem: Grapheme-to-Phoneme Conversion\n",
|
||||
"\n",
|
||||
"The [grapheme](https://en.wikipedia.org/wiki/Grapheme) to [phoneme](https://en.wikipedia.org/wiki/Phoneme) problem is a translation task that takes the letters of a word as the input sequence (the graphemes are the smallest units of a writing system) and outputs the corresponding phonemes; that is, the units of sound that make up a language. In other words, the system aims to generate an unambigious representation of how to pronounce a given input word.\n",
|
||||
"\n",
|
||||
"### Example\n",
|
||||
"**Example**\n",
|
||||
"\n",
|
||||
"The graphemes or the letters are translated into corresponding phonemes: \n",
|
||||
"\n",
|
||||
"> **Grapheme** : **|** T **|** A **|** N **|** G **|** E **|** R **|** \n",
|
||||
"**Phonemes** : **|** ~T **|** ~AE **|** ~NG **|** ~ER **|**\n",
|
||||
"\n",
|
||||
"\n"
|
||||
"**Phonemes** : **|** ~T **|** ~AE **|** ~NG **|** ~ER **|**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Task and Model Structure\n",
|
||||
"**Model structure overview**\n",
|
||||
"\n",
|
||||
"As discussed above, the task we are interested in solving is creating a model that takes some sequence as an input, and generates an output sequence based on the contents of the input. The model's job is to learn the mapping from the input sequence to the output sequence that it will generate. The job of the encoder is to come up with a good representation of the input that the decoder can use to generate a good output. For both the encoder and the decoder, the LSTM does a good job at this.\n",
|
||||
"\n",
|
||||
|
|
@ -157,9 +187,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Importing CNTK and other useful libraries\n",
|
||||
"**Importing CNTK and other useful libraries**\n",
|
||||
"\n",
|
||||
"CNTK is a Python module that contains several submodules like `io`, `learner`, `graph`, etc. We make extensive use of numpy as well."
|
||||
]
|
||||
|
|
@ -168,7 +201,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -186,7 +221,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -197,9 +234,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Downloading the data\n",
|
||||
"### Downloading the data\n",
|
||||
"\n",
|
||||
"In this tutorial we will use a lightly pre-processed version of the CMUDict (version 0.7b) dataset from http://www.speech.cs.cmu.edu/cgi-bin/cmudict. The CMUDict data refers to the Carnegie Mellon University Pronouncing Dictionary and is an open-source machine-readable pronunciation dictionary for North American English. The data is in the CNTKTextFormatReader format. Here is an example sequence pair from the data, where the input sequence (S0) is in the left column, and the output sequence (S1) is on the right:\n",
|
||||
"\n",
|
||||
|
|
@ -219,7 +259,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -269,9 +313,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Reader\n",
|
||||
"### Data Reader\n",
|
||||
"\n",
|
||||
"To efficiently collect our data, randomize it for training, and pass it to the network, we use the CNTKTextFormat reader. We will create a small function that will be called when training (or testing) that defines the names of the streams in our data, and how they are referred to in the raw training data."
|
||||
]
|
||||
|
|
@ -280,7 +327,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -306,7 +355,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -336,7 +389,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We will use the above to create a reader for our training data. Let's create it now:"
|
||||
]
|
||||
|
|
@ -345,7 +401,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -364,14 +422,20 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Now let's set our model hyperparameters..."
|
||||
"**Set our model hyperparameters**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We have a number of settings that control the complexity of our network, the shapes of our inputs, and other options such as whether we will use an embedding (and what size to use), and whether or not we will employ attention. We set them now as they will be made use of when we build the network graph in the following sections."
|
||||
]
|
||||
|
|
@ -380,7 +444,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -398,8 +464,13 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Model Creation\n",
|
||||
"\n",
|
||||
"We will set two more parameters now: the symbols used to denote the start of a sequence (sometimes called 'BOS') and the end of a sequence (sometimes called 'EOS'). In this case, our sequence-start symbol is the tag $<s>$ and our sequence-end symbol is the end-tag $</s>$.\n",
|
||||
"\n",
|
||||
"Sequence start and end tags are important in sequence-to-sequence networks for two reasons. The sequence start tag is a \"primer\" for the decoder; in other words, because we are generating an output sequence and RNNs require some input, the sequence start token \"primes\" the decoder to cause it to emit its first generated token. The sequence end token is important because the decoder will learn to output this token when the sequence is finished. Otherwise the network wouldn't know how long of a sequence to generate. For the code below, we setup the sequence start symbol as a `Constant` so that it can later be passed to the Decoder LSTM as its `initial_state`. Further, we get the sequence end symbol's index so that the Decoder can use it to know when to stop generating tokens."
|
||||
|
|
@ -409,7 +480,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -419,7 +492,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Step 1: setup the input to the network\n",
|
||||
"\n",
|
||||
|
|
@ -440,7 +516,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -453,7 +531,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Step 2: define the network\n",
|
||||
"\n",
|
||||
|
|
@ -469,7 +550,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -492,7 +577,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"For the decoder, we first define several sub-layers: the `Stabilizer` for the decoder input, the `Recurrence` blocks for each of the decoder's layers, the `Stabilizer` for the output of the stack of LSTMs, and the final `Dense` output layer. If we are using attention, then we also create an `AttentionModel` function `attention_model` which returns an augmented version of the decoder's hidden state with emphasis placed on the encoder hidden states that should be most used for the given step while generating the next output token.\n",
|
||||
"\n",
|
||||
|
|
@ -507,7 +595,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -580,14 +670,20 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The network that we defined above can be thought of as an \"abstract\" model that must first be wrapped to be used. In this case, we will use it first to create a \"training\" version of the model (where the history for the Decoder will be the ground-truth labels), and then we will use it to create a greedy \"decoding\" version of the model where the history for the Decoder will be the `hardmax` output of the network. Let's set up these model wrappers next."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Training\n",
|
||||
"\n",
|
||||
|
|
@ -598,7 +694,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -617,7 +715,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Above, we create the CNTK Function `model_train` again using the `@Function` decorator. This function takes the input sequence `input` and the output sequence `labels` as arguments. The `past_labels` are setup as the `history` for the model we created earlier by using the `Delay` layer. This will return the previous time-step value for the input `labels` with an `initial_state` of `sentence_start`. Therefore, if we give the labels `['a', 'b', 'c']`, then `past_labels` will contain `['<s>', 'a', 'b', 'c']` and then return our abstract base model called with the history `past_labels` and the input `input`.\n",
|
||||
"\n",
|
||||
|
|
@ -628,7 +729,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -652,7 +755,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Above we create a new CNTK Function `model_greedy` which this time only takes a single argument. This is of course because when using the model at test time we don't have any labels -- it is the model's job to create them for us! In this case, we use the `UnfoldFrom` layer which runs the base model with the current `history` and funnels it into the `hardmax`. The `hardmax`'s output then becomes part of the `history` and we keep unfolding the `Recurrence` until the `sentence_end_index` has been reached. The maximum length of the output sequence (the maximum unfolding of the Decoder) is determined by a multiplier passed to `length_increase`. In this case we set `length_increase` to `1.5` above so the maximum length of each output sequence is 1.5x its input.\n",
|
||||
"\n",
|
||||
|
|
@ -663,7 +769,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -684,7 +792,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Above, we create the criterion function which drops the sequence-start symbol from our labels for us, runs the model with the given `input` and `labels`, and uses the output to compare to our ground truth. We use the loss function `cross_entropy_with_softmax` and get the `classification_error` which gives us the percent-error per-word of our generation accuracy. The CNTK Function `criterion` returns these values as a tuple and the Python function `create_criterion_function(model)` returns that CNTK Function.\n",
|
||||
"\n",
|
||||
|
|
@ -695,7 +806,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -771,7 +884,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In the above function, we created one version of the model for training (plus its associated criterion function) and one version of the model for evaluation. Normally this latter version would not be required but here we have done it so that we can periodically sample from the non-training model to visually understand how our model is converging by seeing the kinds of sequences that it generates as the training progresses.\n",
|
||||
"\n",
|
||||
|
|
@ -784,7 +900,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -800,7 +918,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Inside the training loop, we proceed much like many other CNTK networks. We request the next bunch of minibatch data, we perform our training, and we print our progress to the screen using the `progress_printer`. Where we diverge from the norm, however, is where we run an evaluation using our `model_greedy` version of the network and run a single sequence, \"ABADI\" through to see what the network is currently predicting.\n",
|
||||
"\n",
|
||||
|
|
@ -811,7 +932,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -837,7 +960,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Let's try training our network for a small part of an epoch. In particular, we'll run through 25,000 tokens (about 3% of one epoch):"
|
||||
]
|
||||
|
|
@ -845,7 +971,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -925,7 +1055,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"As we can see above, while the loss has come down quite a ways, the output sequence is still quite a ways off from what we expect. Uncomment the code below to run for a full epoch (notice that we switch the `epoch_size` parameter to the actual size of the training data) and by the end of the first epoch you will already see a very good grapheme-to-phoneme translation model running!"
|
||||
]
|
||||
|
|
@ -934,7 +1067,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -944,7 +1079,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Testing the network\n",
|
||||
"\n",
|
||||
|
|
@ -958,6 +1096,8 @@
|
|||
"execution_count": 24,
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [],
|
||||
|
|
@ -972,7 +1112,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Now we need to define our testing function. We pass the `reader`, the learned `s2smodel`, and the vocabulary map `i2w` so that we can directly compare the model's predictions to the test set labels. We loop over the test set, evaluate the model on minibatches of size 512 for efficiency, and keep track of the error rate. Note that below we test *per-sequence*. This means that every single token in a generated sequence must match the tokens in the label for that sequence to be considered as correct."
|
||||
]
|
||||
|
|
@ -981,7 +1124,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1017,7 +1162,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Now we will evaluate the decoding using the above function. If you use the version of the model we trained above with just a small 50000 sample of the training data, you will get an error rate of 100% because we cannot possibly get every single token correct with such a small amount of training. However, if you uncommented the training line above that trains the network for a full epoch, you should have ended up with a much-improved model that showed approximately the following training statistics:\n",
|
||||
"\n",
|
||||
|
|
@ -1031,7 +1179,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1059,7 +1211,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"If you did not run the training for the full first epoch, the output above will be a `1.0` meaning 100% string error rate. If, however, you uncommented the line to perform training for a full epoch, you should get an output of `0.569`. A string error rate of `56.9` is actually not bad for a single pass over the data. Let's now modify the above `evaluate_decoding` function to output the per-phoneme error rate. This means that we are calculating the error at a higher precision and also makes things easier in some sense because with the string error rate we could have every phoneme correct but one in each example and still end up with a 100% error rate. Here is the modified version of that function:"
|
||||
|
|
@ -1069,7 +1223,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1110,7 +1266,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 28,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1138,14 +1298,20 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"If you're using the model that was trained for one full epoch, then you should get a phoneme error rate of around 10%. Not bad! This means that for each of the 383,294 phonemes in the test set, our model predicted nearly 90% of them correctly (if you used the quickly-trained version of the model then you will get an error rate of around 45%). Now, let's work with an interactive session where we can input our own input sequences and see how the model predicts their pronunciation (i.e. phonemes). Additionally, we will visualize the Decoder's attention for these samples to see which graphemes in the input it deemed to be important for each phoneme that it produces. Note that in the examples below the results will only be good if you use a model that has been trained for at least one epoch."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Interactive session\n",
|
||||
"\n",
|
||||
|
|
@ -1158,7 +1324,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1208,7 +1376,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The `translate` function above takes a list of letters input by the user as `tokens`, the greedy decoding version of our model `model_decoding`, the vocabulary `vocab`, a map of index to vocab `i2w`, and the `show_attention` option which determines if we will visualize the attention vectors or not.\n",
|
||||
"\n",
|
||||
|
|
@ -1223,7 +1394,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 30,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1256,7 +1429,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The above function simply creates a greedy decoder around our model and then continually asks the user for an input which we pass to our `translate` function. Visualizations of the attention will continue being appended to the notebook until you exit the loop by typing `quit`. Please uncomment the following line to try out the interaction session."
|
||||
]
|
||||
|
|
@ -1264,7 +1440,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 31,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1299,14 +1479,26 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Notice how the attention weights show how important different parts of the input are for generating different tokens in the output. For tasks like machine translation, where the order of one-to-one words often changes due to grammatical differences between languages, this becomes very interesting as we see the attention window move further away from the diagonal that is mostly displayed in grapheme-to-phoneme translations.\n",
|
||||
"\n",
|
||||
"## What's next\n",
|
||||
"**What's next**\n",
|
||||
"\n",
|
||||
"With the above model, you have the basics for training a powerful sequence-to-sequence model with attention in a number of distinct domains. The only major changes required are preparing a dataset with pairs input and output sequences and in general the rest of the building blocks will remain the same. Good luck, and have fun!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
|
|
@ -1326,7 +1518,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -2,7 +2,10 @@
|
|||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 205 Artistic Style Transfer\n",
|
||||
"\n",
|
||||
|
|
@ -19,7 +22,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -41,7 +46,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The pretrained model is a VGG network which we originally got from [this page](https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3). We host it in a place which permits easy downloading. Below we download it if it is not already available locally and load the weights into numpy arrays."
|
||||
]
|
||||
|
|
@ -49,7 +57,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -98,7 +110,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Next we define the VGG network as a CNTK graph. "
|
||||
]
|
||||
|
|
@ -107,7 +122,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -144,7 +161,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Defining the loss function\n",
|
||||
"\n",
|
||||
|
|
@ -152,6 +172,7 @@
|
|||
"$$\n",
|
||||
"L(x) = \\alpha C(x) + \\beta S(x) + T(x)\n",
|
||||
"$$\n",
|
||||
"\n",
|
||||
"where $\\alpha$ and $\\beta$ are weights on the content loss and the style loss, respectively. We have normalized the weights so that the weight in front of the total variation loss is 1. How are each of these terms computed?\n",
|
||||
"\n",
|
||||
" - The [total variation loss](https://en.wikipedia.org/wiki/Total_variation_denoising) $T(x)$ is the simplest one to understand: It measures the average sum of squared differences among adjacent pixel values and encourages the result $x$ to be a smooth image. We implement this by convolving the image with a kernel containing (-1,1) both horizontally and vertically, squaring the results and computing their average.\n",
|
||||
|
|
@ -165,7 +186,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -210,7 +233,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Instantiating the loss\n",
|
||||
"\n",
|
||||
|
|
@ -225,7 +251,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -324,7 +354,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Optimizing the loss\n",
|
||||
"\n",
|
||||
|
|
@ -347,7 +380,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -437,7 +474,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -473,7 +514,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -2,7 +2,10 @@
|
|||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 207: Sampled Softmax\n",
|
||||
"\n",
|
||||
|
|
@ -11,9 +14,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"#### Select the notebook runtime environment devices / settings\n",
|
||||
"**Select the notebook runtime environment devices / settings**\n",
|
||||
"\n",
|
||||
"Before we dive into the details we run some setup that is required for automated testing of this notebook. \n"
|
||||
]
|
||||
|
|
@ -22,7 +28,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -38,9 +46,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Basics\n",
|
||||
"## Basic concept\n",
|
||||
"\n",
|
||||
"The softmax function is used in neural networks if we want to interpret the network output as a probability distribution over a set of classes $C$ with $|C|=N_C$.\n",
|
||||
"\n",
|
||||
|
|
@ -66,7 +77,7 @@
|
|||
"\n",
|
||||
"$$cross\\_entropy := -log(p_t)$$\n",
|
||||
"\n",
|
||||
"## Sampled Softmax from the outside\n",
|
||||
"## Sampled Softmax\n",
|
||||
"\n",
|
||||
"For the normal softmax the CNTK Python-api provides the function [cross_entropy_with_softmax](https://cntk.ai/pythondocs/cntk.ops.html?highlight=softmax#cntk.ops.cross_entropy_with_softmax). This takes as input the $N_C$-dimensional vector $z$. As mentioned for our sampled softmax implementation we assume that this z is computed by $ z = W h + b $. In sampled softmax this has to be part of the whole implementation of the criterion.\n",
|
||||
"\n",
|
||||
|
|
@ -85,7 +96,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -140,7 +153,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"To give a better idea of what the inputs and outputs are and how this all differs from the normal softmax we give below a corresponding function using normal softmax:"
|
||||
]
|
||||
|
|
@ -149,7 +165,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -179,7 +197,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"As you can see the main differences to the api function `cross_entropy_with_softmax` are:\n",
|
||||
"* We include the mapping $ z = W h + b $ into the function.\n",
|
||||
|
|
@ -194,7 +215,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -393,7 +418,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In the above code we use two different methods to report training progress:\n",
|
||||
"1. Using a function that computes the average cross entropy on full softmax.\n",
|
||||
|
|
@ -430,7 +458,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -488,7 +520,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"In the example above we compare uniform sampling (red) vs sampling with the same distribution the classes have (blue).\n",
|
||||
|
|
@ -498,7 +532,9 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## What speedups to expect?\n",
|
||||
|
|
@ -516,7 +552,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -613,7 +653,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -2,7 +2,10 @@
|
|||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 208: Training Acoustic Model with Connectionist Temporal Classification (CTC) Criteria\n",
|
||||
"This tutorial assumes familiarity with 10\\* CNTK tutorials and basic knowledge of data representation in acoustic modelling tasks. It introduces some CNTK building blocks that can be used in training deep networks for speech recognition on the example of CTC training criteria.\n",
|
||||
|
|
@ -11,16 +14,20 @@
|
|||
"CNTK implementation of CTC is based on the paper by A. Graves et al. *\"Connectionist temporal classification: labeling unsegmented sequence data with recurrent neural networks\"*. CTC is a popular training criteria for sequence learning tasks, such as speech or handwriting. It doesn't require segmentation of training data nor post-processing of network outpus to convert them to labels. Thereby, it significantly simplifies training and decoding processes while achieving state of the art accuracy.\n",
|
||||
"\n",
|
||||
"CTC training runs on several sequences in parallel either on GPU or CPU, achieving maximal utilization of the hardware. \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Imports and Device Definition\n"
|
||||
"First let us import some of the necessary libraries including CNTK and setup the testing environment."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -66,9 +73,13 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Data Preparation\n",
|
||||
"## Read data\n",
|
||||
"\n",
|
||||
"CNTK consumes Acoustic Model (AM) training data in HTK/MLF format and typically expects 3 input files\n",
|
||||
"* [SCP file with features](https://github.com/Microsoft/CNTK/blob/master/Tests/EndToEndTests/Speech/Data/glob_0000.scp). SCP file contains mapping of utterance ids to corresponding feature files.\n",
|
||||
"* [MLF file with labels](https://github.com/Microsoft/CNTK/blob/master/Tests/EndToEndTests/Speech/Data/glob_0000.mlf). MLF (master label file) is a traditional format for representing transcription alignment to features. Even though the referenced MLF file contains label boundaries, they are not needed during CTC training and ignored. For more details on feature/label formats, refer to a copy of HTK book, e.g. [here](http://www1.icsi.berkeley.edu/Speech/docs/HTKBook3.2/)\n",
|
||||
|
|
@ -80,10 +91,13 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"\n",
|
||||
"# Type of features/labels and dimensions are application specific\n",
|
||||
"# Here we use rather small dimensional feature and the label set for the sake of keeping the train set compact.\n",
|
||||
"feature_dimension = 33\n",
|
||||
|
|
@ -108,17 +122,23 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Normalize Features and Define a Network with LSTM Layers\n",
|
||||
"We normalize the input features to zero mean and unit variance by subtracting the mean vector and multiplying by [inverse](https://en.wikipedia.org/wiki/Multiplicative_inverse) standard deviation, which are stored in separate files."
|
||||
"## Model creation\n",
|
||||
"\n",
|
||||
"In this block we first normalize the features and define a model with LSTM Layers. We normalize the input features to zero mean and unit variance by subtracting the mean vector and multiplying by [inverse](https://en.wikipedia.org/wiki/Multiplicative_inverse) standard deviation, which are stored in separate files."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -137,10 +157,13 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Define Training Parameters, Criteria and Error\n",
|
||||
"### Define training hyperparameters\n",
|
||||
"\n",
|
||||
"CTC criteria (loss) function is implemented by combination of the `labels_to_graph` and `forward_backward` functions. These functions are designed to generalize forward-backward viterbi-like functions which are very common in sequential modelling problems, e.g. speech or handwriting. `labels_to_graph` is designed to convert the input label sequence into graph representation suitable for particular forward-backward procedure, and `forward_backward` function performs the procedure itself. Currently, these functions only support CTC, and it's their default configuration."
|
||||
]
|
||||
},
|
||||
|
|
@ -148,7 +171,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -168,15 +193,21 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Train and Save the Model"
|
||||
"## Train"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [
|
||||
|
|
@ -218,16 +249,22 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"## Evaluate the Model"
|
||||
"## Evaluate "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -262,7 +299,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -285,7 +324,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
|
|
@ -2,21 +2,24 @@
|
|||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"# CNTK 301: Image Recognition with Deep Transfer Learning\n",
|
||||
"\n",
|
||||
"This hands-on tutorial shows how to use [Transfer Learning](https://en.wikipedia.org/wiki/Inductive_transfer) to take an existing trained model and adapt it to your own specialized domain. Note: This notebook will run only if you have GPU enabled machine.\n",
|
||||
"\n",
|
||||
"### Problem\n",
|
||||
"## Problem\n",
|
||||
"You have been given a set of flower images that needs to be classified into their respective categories. Image below shows a sampling of the data source. \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"However, the number of images is far less than what is needed to train a state-of-the-art classifier such as a [Residual Network](https://github.com/KaimingHe/deep-residual-networks). You have a rich annotated data set of images of natural scene images such as shown below (courtesy [t-SNE visualization site](http://cs.stanford.edu/people/karpathy/cnnembed/)).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"This tutorial introduces deep transfer learning as a means to leverage multiple data sources to overcome data scarcity problem.\n",
|
||||
"\n",
|
||||
|
|
@ -35,7 +38,7 @@
|
|||
"\n",
|
||||
"In our case, this means adapting a network trained on ImageNet images (dogs, cats, birds, etc.) to flowers, or sheep/wolves. However, Transfer Learning has also been successfully used to adapt existing neural models for translation, speech synthesis, and many other domains - it is a convenient way to bootstrap your learning process.\n",
|
||||
"\n",
|
||||
"### Importing CNTK and other useful libraries\n",
|
||||
"**Importing CNTK and other useful libraries**\n",
|
||||
"\n",
|
||||
"Microsoft's Cognitive Toolkit comes in Python form as `cntk`, and contains many useful submodules for IO, defining layers, training models, and interrogating trained models. We will need many of these for Transfer Learning, as well as some other common libraries for downloading files, unpacking/unzipping them, working with the file system, and loading matrices."
|
||||
]
|
||||
|
|
@ -44,7 +47,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -77,7 +82,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"There are two run modes:\n",
|
||||
"- *Fast mode*: `isFast` is set to `True`. This is the default mode for the notebooks, which means we train for fewer iterations or train / test on limited data. This ensures functional correctness of the notebook though the models produced are far from what a completed training would produce.\n",
|
||||
|
|
@ -91,7 +99,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -100,9 +110,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Downloading Data \n",
|
||||
"### Data Download\n",
|
||||
"\n",
|
||||
"Now, let us download our datasets. We use two datasets in this tutorial - one containing _a bunch_ of flowers images, and the other containing _just a few_ sheep and wolves. They're described in more detail below, but what we are doing here is just downloading and unpacking them.\n",
|
||||
"\n",
|
||||
|
|
@ -115,6 +128,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [
|
||||
|
|
@ -153,7 +169,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Note that we are setting the data root to coincide with the CNTK examples, so if you have run those some of the data might already exist. Alter the data root if you would like all of the input and output data to go elsewhere (i.e. if you have copied this notebook to your own space). The `download_unless_exists` method will try to download several times, but if that fails you might see an exception. It and the `write_to_file` method both - write to files, so if the data_root is not writeable or fills up you'll see exceptions there."
|
||||
]
|
||||
|
|
@ -161,7 +180,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -302,9 +325,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Trained Model Architecture\n",
|
||||
"### Pre-Trained Model (ResNet)\n",
|
||||
"\n",
|
||||
"For this task, we have chosen ResNet_18 as our trained model and will it as the base model. This model will be adapted using Transfer Learning for classification of flowers and animals. This model is a [Convolutional Neural Network](https://en.wikipedia.org/wiki/Convolutional_neural_network) built using [Residual Network](https://github.com/KaimingHe/deep-residual-networks) techniques. Convolutional Neural Networks build up layers of convolutions, transforming an input image and distilling it down until they start recognizing composite features, with deeper layers of convolutions recognizing complex patterns are made possible. The author of Keras has a [fantastic post](https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html) where he describes how Convolutional Networks \"see the world\" which gives a much more detailed explanation.\n",
|
||||
"\n",
|
||||
|
|
@ -318,7 +344,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -338,9 +368,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Interrogating the Model\n",
|
||||
"### Inspecting pre-trained model\n",
|
||||
"\n",
|
||||
"We print out all of the layers in ResNet_18 to show you how you can interrogate a model - to use a different model than ResNet_18 you would just need to discover the appropriate last hidden layer and feature layer to use. CNTK provides a convenient `get_node_outputs` method under `cntk.graph` to allow you to dump all of the model details. We can recognize the final hidden layer as the one before we start computing the final classification into the 1000 ImageNet classes (so in this case, `z.x`)."
|
||||
]
|
||||
|
|
@ -348,7 +381,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -459,9 +496,12 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### The Flowers Dataset\n",
|
||||
"### New dataset\n",
|
||||
"\n",
|
||||
"The Flowers dataset comes from the Oxford Visual Geometry Group, and contains 102 different categories of flowers common to the UK. It has roughly 8000 images split between train, test, and validation sets. The [VGG homepage for the dataset](http://www.robots.ox.ac.uk/~vgg/data/flowers/102/index.html) contains more details.\n",
|
||||
"\n",
|
||||
|
|
@ -474,7 +514,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -490,7 +532,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -563,7 +609,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Training the Transfer Learning Model\n",
|
||||
"\n",
|
||||
|
|
@ -576,7 +625,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -614,7 +665,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We will now train the model just like any other CNTK model training - instantiating an input source (in this case a `MinibatchSource` from our image data), defining the loss function, and training for a number of epochs. Since we are training a multi-class classifier network, the final layer is a cross-entropy Softmax, and the error function is classification error - both conveniently provided by utility functions in `cntk.ops`.\n",
|
||||
"\n",
|
||||
|
|
@ -625,7 +679,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -682,7 +738,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"When we evaluate the trained model on an image, we have to massage that image into the expected format. In our case we use `Image` to load the image from its path, resize it to the size expected by our model, reverse the color channels (RGB to BGR), and convert to a contiguous array along height, width, and color channels. This corresponds to the 224x224x3 flattened array on which our model was trained.\n",
|
||||
"\n",
|
||||
|
|
@ -693,7 +752,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -766,7 +827,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Finally, with all of these helper functions in place we can train the model and evaluate it on our flower dataset.\n",
|
||||
"\n",
|
||||
|
|
@ -781,6 +845,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": false
|
||||
},
|
||||
"outputs": [
|
||||
|
|
@ -836,10 +903,22 @@
|
|||
" print(\"Stored trained model at %s\" % flowers_model['model_file'])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Evaluate\n",
|
||||
"\n",
|
||||
"Evaluate the newly learnt flower classifier by transfering the learning from a pre-trained ResNet model."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true,
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [
|
||||
|
|
@ -866,7 +945,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -884,10 +967,12 @@
|
|||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Animals Dataset\n",
|
||||
"### With much smaller dataset\n",
|
||||
"\n",
|
||||
"With the Flowers dataset, we had hundreds of classes with hundreds of images. What if we had a smaller set of classes and images to work with, would transfer learning still work? Let us examine the Animals dataset we have downloaded, consisting of nothing but sheep and wolves and a much smaller set of images to work with (on the order of a dozen per class). Let us take a look at a few..."
|
||||
]
|
||||
|
|
@ -895,7 +980,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -967,7 +1056,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"The images are stored in `Train` and `Test` folders with the nested folder giving the class name (i.e. `Sheep` and `Wolf` folders). This is quite common, so it is useful to know how to convert that format into one that can be used for constructing the mapping files CNTK expects. `create_class_mapping_from_folder` looks at all nested folders in the root and turns their names into labels, and returns this as an array used by `create_map_file_from_folder`. That method walks those folders and writes their paths and label indices into a `map.txt` file in the root (e.g. `Train`, `Test`). Note the use of `abspath`, allowing you to specify relative \"root\" paths to the method, and then move the resulting map files or run from different directories without issue. "
|
||||
]
|
||||
|
|
@ -976,7 +1068,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
|
|
@ -1034,7 +1128,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"We can now train our model on our small domain and evaluate the results:"
|
||||
]
|
||||
|
|
@ -1042,7 +1139,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1079,7 +1180,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"Now that the model is trained for animals data. Lets us evaluate the images."
|
||||
]
|
||||
|
|
@ -1087,7 +1191,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
|
|
@ -1130,7 +1238,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### The Known Unknown\n",
|
||||
"\n",
|
||||
|
|
@ -1140,7 +1251,11 @@
|
|||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
|
|
@ -1196,7 +1311,10 @@
|
|||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"metadata": {
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"source": [
|
||||
"### Final Thoughts, and Caveats\n",
|
||||
"\n",
|
||||
|
|
@ -1209,7 +1327,9 @@
|
|||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"collapsed": true
|
||||
"collapsed": true,
|
||||
"deletable": true,
|
||||
"editable": true
|
||||
},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
|
|
@ -1232,7 +1352,7 @@
|
|||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.5.2"
|
||||
"version": "3.5.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
|
|
|||
Загрузка…
Ссылка в новой задаче