Updated and add MNIST LR tutorial
This commit is contained in:
Родитель
2ca0ca7b3d
Коммит
9833535973
|
|
@ -217,7 +217,13 @@
|
|||
"source": [
|
||||
"# Save the images\n",
|
||||
"\n",
|
||||
"Save the images in a local directory. While saving the data we flatten the images to a vector (28x28 image pixels becomes an array of length 784 data points) and the labels are encoded as [1-hot][] encoding (label of 3 with 10 digits becomes `0010000000`.\n",
|
||||
"Save the images in a local directory. While saving the data we flatten the images to a vector (28x28 image pixels becomes an array of length 784 data points).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"The labels are encoded as [1-hot][] encoding (label of 3 with 10 digits becomes `0001000000`, where the first index corresponds to digit `0` and the last one corresponds to digit `9`.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"[1-hot]: https://en.wikipedia.org/wiki/One-hot"
|
||||
]
|
||||
|
|
|
|||
Различия файлов скрыты, потому что одна или несколько строк слишком длинны
|
|
@ -27,9 +27,8 @@
|
|||
"\n",
|
||||
"## Introduction\n",
|
||||
"\n",
|
||||
"**Problem** (recap from the CNTK 101):\n",
|
||||
"\n",
|
||||
"The MNIST data comprises of hand-written digits with little background noise."
|
||||
"**Problem** \n",
|
||||
"As in CNTK 103B, we will continue to work on the same problem of recognizing digits in MNIST data. The MNIST data comprises of hand-written digits with little background noise."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -63,14 +62,14 @@
|
|||
"metadata": {},
|
||||
"source": [
|
||||
"**Goal**:\n",
|
||||
"Our goal is to train a classifier that will identify the digits in the MNIST dataset. \n",
|
||||
"Our goal is to train a classifier that will identify the digits in the MNIST dataset. Additionally, we aspire to achieve lower error rate with Multi-layer perceptron compared to Multi-class logistic regression. \n",
|
||||
"\n",
|
||||
"**Approach**:\n",
|
||||
"The same 5 stages we have used in the previous tutorial are applicable: Data reading, Data preprocessing, Creating a model, Learning the model parameters and Evaluating (a.k.a. testing/prediction) the model. \n",
|
||||
"- Data reading: We will use the CNTK Text reader \n",
|
||||
"- Data preprocessing: Covered in part A (suggested extension section). \n",
|
||||
"\n",
|
||||
"Rest of the steps are kept identical to CNTK 102. "
|
||||
"There is a high overlap with CNTK 102. Though this tutorial we adapt the same model to work on MNIST data with 10 classses instead of the 2 classes we used in CNTK 102.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -84,7 +83,8 @@
|
|||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Import the relevant components\n",
|
||||
"# Use a function definition from future version \n",
|
||||
"# (say 3.x while running 2.7 interpreter)\n",
|
||||
"from __future__ import print_function\n",
|
||||
"import matplotlib.image as mpimg\n",
|
||||
"import matplotlib.pyplot as plt\n",
|
||||
|
|
@ -142,7 +142,7 @@
|
|||
" |labels 0 0 0 0 0 0 0 1 0 0 |features 0 0 0 0 ... \n",
|
||||
" (784 integers each representing a pixel)\n",
|
||||
" \n",
|
||||
"In this tutorial we are going to use the image pixels corresponding the integer stream named \"features\". We define a `create_reader` function to read the training and test data using the [CTF deserializer](https://cntk.ai/pythondocs/cntk.io.html?highlight=ctfdeserializer#cntk.io.CTFDeserializer). The labels are [1-hot encoded](https://en.wikipedia.org/wiki/One-hot). \n"
|
||||
"In this tutorial we are going to use the image pixels corresponding the integer stream named \"features\". We define a `create_reader` function to read the training and test data using the [CTF deserializer](https://cntk.ai/pythondocs/cntk.io.html?highlight=ctfdeserializer#cntk.io.CTFDeserializer). The labels are [1-hot encoded](https://en.wikipedia.org/wiki/One-hot). Refer to CNTK 103A tutorial for data format visualizations. \n"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -199,33 +199,9 @@
|
|||
"<a id='#Model Creation'></a>\n",
|
||||
"## Model Creation\n",
|
||||
"\n",
|
||||
"Our multi-layer perceptron will be relatively simple with 2 hidden layers (`num_hidden_layers`) with each layer having 400 hidden nodes (`hidden_layers_dim`). "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<img src=\"http://cntk.ai/jup/cntk103_mlp.jpg\" width=\"200\" height=\"200\"/>"
|
||||
],
|
||||
"text/plain": [
|
||||
"<IPython.core.display.Image object>"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Figure 2\n",
|
||||
"Image(url= \"http://cntk.ai/jup/cntk103_mlp.jpg\", width=200, height=200)"
|
||||
"Our multi-layer perceptron will be relatively simple with 2 hidden layers (`num_hidden_layers`). The number of nodes in the hidden layer being a parameter specified by `hidden_layers_dim`. The figure below illustrates the entire model we will use in this tutorial in the context of MNIST data.\n",
|
||||
"\n",
|
||||
"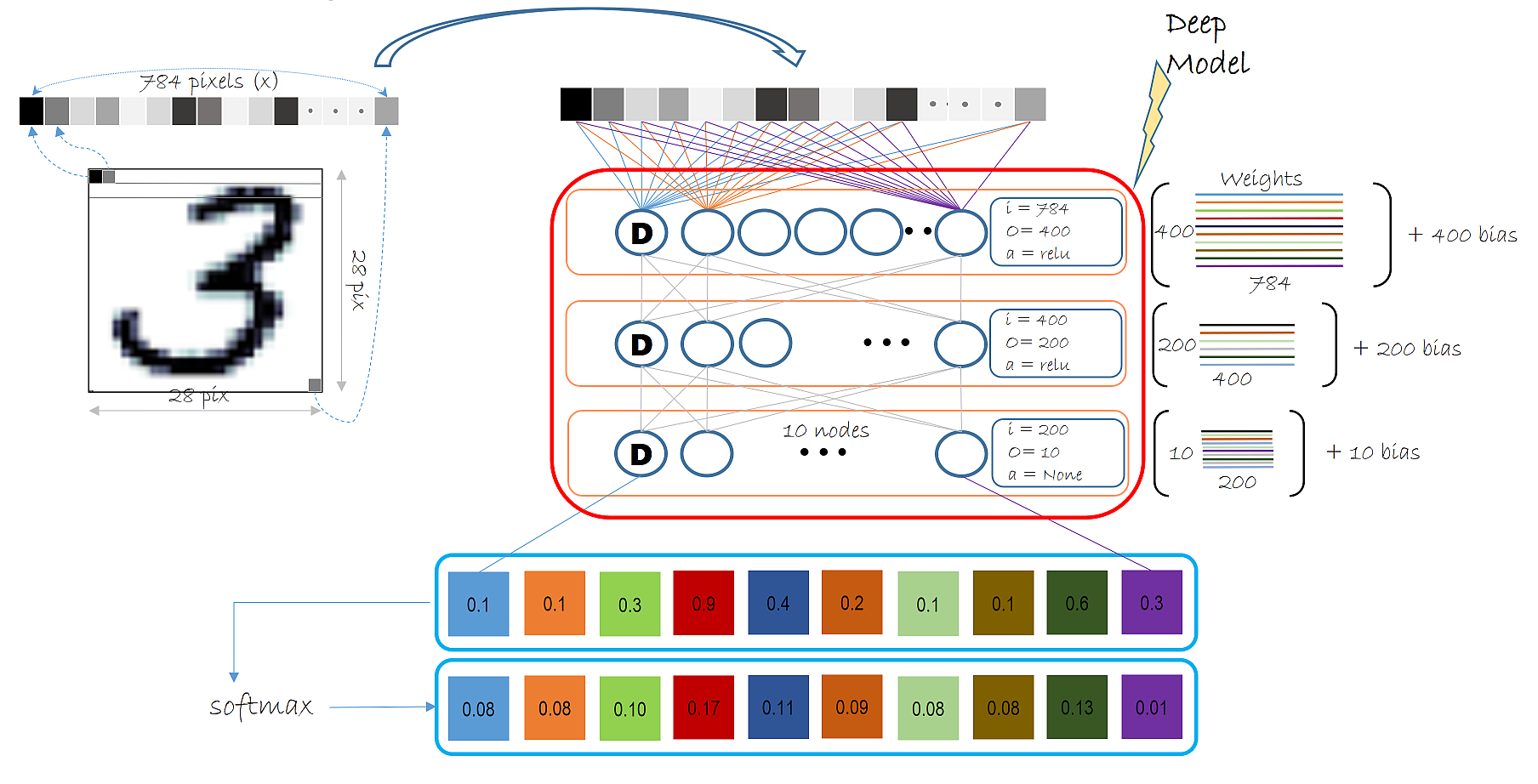"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -234,11 +210,17 @@
|
|||
"source": [
|
||||
"If you are not familiar with the terms *hidden_layer* and *number of hidden layers*, please refer back to CNTK 102 tutorial.\n",
|
||||
"\n",
|
||||
"For this tutorial: The number of green nodes (refer to picture above) in each hidden layer is set to 200 and the number of hidden layers (refer to the number of layers of green nodes) is 2. Fill in the following values:\n",
|
||||
"Each Dense layer (as illustrated below) shows the input dimensions, output dimensions and activation function that layer uses. Specifically, the layer below shows: input dimension = 784 (1 dimension for each input pixel), output dimension = 400 (number of hidden nodes, a parameter specified by the user) and activation function being [relu](https://cntk.ai/pythondocs/cntk.ops.html?highlight=relu#cntk.ops.relu).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"In this model we have 2 dense layer called the hidden layers each with an activation function of `relu` and one output layer with no activation. \n",
|
||||
"\n",
|
||||
"The output dimension (a.k.a. number of hidden nodes) in the 2 hidden layer is set to 400 and 200 in the illustration above. In the code below we keep both layers to have the same number of hidden nodes (set to 400). The number of hidden layers is 2. Fill in the following values:\n",
|
||||
"- num_hidden_layers\n",
|
||||
"- hidden_layers_dim\n",
|
||||
"\n",
|
||||
"Note: In this illustration, we have not shown the bias node (introduced in the logistic regression tutorial). Each hidden layer would have a bias node."
|
||||
"The final output layer emits a vector of 10 values. Since we will be using softmax to normalize the output of the model we do not use an activation function in this layer. The softmax operation comes bundled with the [loss function](https://cntk.ai/pythondocs/cntk.losses.html?highlight=cross_entropy_with_softmax#cntk.losses.cross_entropy_with_softmax) we will be using later in this tutorial."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -283,7 +265,7 @@
|
|||
"source": [
|
||||
"## Multi-layer Perceptron setup\n",
|
||||
"\n",
|
||||
"If you are not familiar with the multi-layer perceptron, please refer to CNTK 102. In this tutorial we are using the same network. "
|
||||
"The cell below is a direct translation of the illustration of the model shown above."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -311,16 +293,14 @@
|
|||
"source": [
|
||||
"`z` will be used to represent the output of a network.\n",
|
||||
"\n",
|
||||
"We introduced sigmoid function in CNTK 102, in this tutorial you should try different activation functions. You may choose to do this right away and take a peek into the performance later in the tutorial or run the preset tutorial and then choose to perform the suggested activity.\n",
|
||||
"We introduced sigmoid function in CNTK 102, in this tutorial you should try different activation functions in the hidden layer. You may choose to do this right away and take a peek into the performance later in the tutorial or run the preset tutorial and then choose to perform the suggested activity.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"** Suggested Activity **\n",
|
||||
"- Record the training error you get with `sigmoid` as the activation function\n",
|
||||
"- Now change to `relu` as the activation function and see if you can improve your training error\n",
|
||||
"\n",
|
||||
"*Quiz*: Different supported activation functions can be [found here][]. Which activation function gives the least training error?\n",
|
||||
"\n",
|
||||
"[found here]: https://github.com/Microsoft/CNTK/wiki/Activation-Functions"
|
||||
"*Quiz*: Name some of the different supported activation functions? Which activation function gives the least training error?"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -331,8 +311,8 @@
|
|||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Scale the input to 0-1 range by dividing each pixel by 256.\n",
|
||||
"z = create_model(input/256.0)"
|
||||
"# Scale the input to 0-1 range by dividing each pixel by 255.\n",
|
||||
"z = create_model(input/255.0)"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -341,11 +321,9 @@
|
|||
"source": [
|
||||
"### Learning model parameters\n",
|
||||
"\n",
|
||||
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function][] and other [activation][] functions).\n",
|
||||
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function][]).\n",
|
||||
"\n",
|
||||
"[softmax function]: http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax\n",
|
||||
"\n",
|
||||
"[activation]: https://github.com/Microsoft/CNTK/wiki/Activation-Functions"
|
||||
"[softmax function]: http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -394,7 +372,7 @@
|
|||
"source": [
|
||||
"### Configure training\n",
|
||||
"\n",
|
||||
"The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent][] (`sgd`) being one of the most popular one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent][] generate a new set model parameters in a single iteration. \n",
|
||||
"The trainer strives to reduce the `loss` function by different optimization approaches, [Stochastic Gradient Descent][] (`sgd`) being a basic one. Typically, one would start with random initialization of the model parameters. The `sgd` optimizer would calculate the `loss` or error between the predicted label against the corresponding ground-truth label and using [gradient-decent][] generate a new set model parameters in a single iteration. \n",
|
||||
"\n",
|
||||
"The aforementioned model parameter update using a single observation at a time is attractive since it does not require the entire data set (all observation) to be loaded in memory and also requires gradient computation over fewer datapoints, thus allowing for training on large data sets. However, the updates generated using a single observation sample at a time can vary wildly between iterations. An intermediate ground is to load a small set of observations and use an average of the `loss` or error from that set to update the model parameters. This subset is called a *minibatch*.\n",
|
||||
"\n",
|
||||
|
|
@ -670,7 +648,9 @@
|
|||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Note, this error is very comparable to our training error indicating that our model has good \"out of sample\" error a.k.a. generalization error. This implies that our model can very effectively deal with previously unseen observations (during the training process). This is key to avoid the phenomenon of overfitting."
|
||||
"Note, this error is very comparable to our training error indicating that our model has good \"out of sample\" error a.k.a. generalization error. This implies that our model can very effectively deal with previously unseen observations (during the training process). This is key to avoid the phenomenon of overfitting.\n",
|
||||
"\n",
|
||||
"**Huge** reduction in error compared to multi-class LR (from CNTK 103B)"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
|
|||
Загрузка…
Ссылка в новой задаче