1080 строки
56 KiB
Plaintext
1080 строки
56 KiB
Plaintext
{
|
|
"cells": [
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 1,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"from IPython.display import display, Image"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {
|
|
"nbpresent": {
|
|
"id": "29b9bd1d-766f-4422-ad96-de0accc1ce58"
|
|
}
|
|
},
|
|
"source": [
|
|
"# CNTK 103: Part D - Convolutional Neural Network with MNIST\n",
|
|
"\n",
|
|
"We assume that you have successfully completed CNTK 103 Part A (MNIST Data Loader).\n",
|
|
"\n",
|
|
"In this tutorial we will train a Convolutional Neural Network (CNN) on MNIST data. This notebook provides the recipe using the Python API. If you are looking for this example in BrainScript, please look [here](https://github.com/Microsoft/CNTK/tree/release/2.6/Examples/Image/GettingStarted)\n",
|
|
"\n",
|
|
"## Introduction\n",
|
|
"\n",
|
|
"A [convolutional neural network](https://en.wikipedia.org/wiki/Convolutional_neural_network) (CNN, or ConvNet) is a type of [feed-forward](https://en.wikipedia.org/wiki/Feedforward_neural_network) artificial neural network made up of neurons that have learnable weights and biases, very similar to ordinary multi-layer perceptron (MLP) networks introduced in 103C. The CNNs take advantage of the spatial nature of the data. In nature, we perceive different objects by their shapes, size and colors. For example, objects in a natural scene are typically edges, corners/vertices (defined by two of more edges), color patches etc. These primitives are often identified using different detectors (e.g., edge detection, color detector) or combination of detectors interacting to facilitate image interpretation (object classification, region of interest detection, scene description etc.) in real world vision related tasks. These detectors are also known as filters. Convolution is a mathematical operator that takes an image and a filter as input and produces a filtered output (representing say egdges, corners, colors etc in the input image). Historically, these filters are a set of weights that were often hand crafted or modeled with mathematical functions (e.g., [Gaussian](https://en.wikipedia.org/wiki/Gaussian_filter) / [Laplacian](http://homepages.inf.ed.ac.uk/rbf/HIPR2/log.htm) / [Canny](https://en.wikipedia.org/wiki/Canny_edge_detector) filter). The filter outputs are mapped through non-linear activation functions mimicking human brain cells called [neurons](https://en.wikipedia.org/wiki/Neuron).\n",
|
|
"\n",
|
|
"Convolutional networks provide a machinery to learn these filters from the data directly instead of explicit mathematical models and have been found to be superior (in real world tasks) compared to historically crafted filters. With convolutional networks, the focus is on learning the filter weights instead of learning individually fully connected pair-wise (between inputs and outputs) weights. In this way, the number of weights to learn is reduced when compared with the traditional MLP networks from the previous tutorials. In a convolutional network, one learns several filters ranging from few single digits to few thousands depending on the network complexity.\n",
|
|
"\n",
|
|
"Many of the CNN primitives have been shown to have a conceptually parallel components in brain's [visual cortex](https://en.wikipedia.org/wiki/Visual_cortex). The group of neurons cells in visual cortex emit responses when stimulated. This region is known as the receptive field (RF). Equivalently, in convolution the input region corresponding to the filter dimensions can be considered as the receptive field. Popular deep CNNs or ConvNets (such as [AlexNet](https://en.wikipedia.org/wiki/AlexNet), [VGG](https://arxiv.org/abs/1409.1556), [Inception](http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf), [ResNet](https://arxiv.org/pdf/1512.03385v1.pdf)) that are used for various [computer vision](https://en.wikipedia.org/wiki/Computer_vision) tasks have many of these architectural primitives (inspired from biology). \n",
|
|
"\n",
|
|
"In this tutorial, we will introduce the convolution operation and gain familiarity with the different parameters in CNNs.\n",
|
|
"\n",
|
|
"**Problem**:\n",
|
|
"As in CNTK 103C, we will continue to work on the same problem of recognizing digits in MNIST data. The MNIST data comprises of hand-written digits with little background noise."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 2,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"data": {
|
|
"text/html": [
|
|
"<img src=\"http://3.bp.blogspot.com/_UpN7DfJA0j4/TJtUBWPk0SI/AAAAAAAAABY/oWPMtmqJn3k/s1600/mnist_originals.png\" width=\"200\" height=\"200\"/>"
|
|
],
|
|
"text/plain": [
|
|
"<IPython.core.display.Image object>"
|
|
]
|
|
},
|
|
"execution_count": 2,
|
|
"metadata": {},
|
|
"output_type": "execute_result"
|
|
}
|
|
],
|
|
"source": [
|
|
"# Figure 1\n",
|
|
"Image(url= \"http://3.bp.blogspot.com/_UpN7DfJA0j4/TJtUBWPk0SI/AAAAAAAAABY/oWPMtmqJn3k/s1600/mnist_originals.png\", width=200, height=200)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"**Goal**:\n",
|
|
"Our goal is to train a classifier that will identify the digits in the MNIST dataset. \n",
|
|
"\n",
|
|
"**Approach**:\n",
|
|
"\n",
|
|
"The same 5 stages we have used in the previous tutorial are applicable: Data reading, Data preprocessing, Creating a model, Learning the model parameters and Evaluating (a.k.a. testing/prediction) the model. \n",
|
|
"- Data reading: We will use the CNTK Text reader \n",
|
|
"- Data preprocessing: Covered in part A (suggested extension section). \n",
|
|
"\n",
|
|
"In this tutorial, we will experiment with two models with different architectural components."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 3,
|
|
"metadata": {
|
|
"collapsed": true,
|
|
"nbpresent": {
|
|
"id": "138d1a78-02e2-4bd6-a20e-07b83f303563"
|
|
}
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"from __future__ import print_function # Use a function definition from future version (say 3.x from 2.7 interpreter)\n",
|
|
"import matplotlib.image as mpimg\n",
|
|
"import matplotlib.pyplot as plt\n",
|
|
"import numpy as np\n",
|
|
"import os\n",
|
|
"import sys\n",
|
|
"import time\n",
|
|
"\n",
|
|
"import cntk as C\n",
|
|
"import cntk.tests.test_utils\n",
|
|
"cntk.tests.test_utils.set_device_from_pytest_env() # (only needed for our build system)\n",
|
|
"C.cntk_py.set_fixed_random_seed(1) # fix a random seed for CNTK components\n",
|
|
"\n",
|
|
"%matplotlib inline"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Data reading\n",
|
|
"In this section, we will read the data generated in CNTK 103 Part A (MNIST Data Loader).\n",
|
|
"\n",
|
|
"We are using the MNIST data that you have downloaded using the CNTK_103A_MNIST_DataLoader notebook. The dataset has 60,000 training images and 10,000 test images with each image being 28 x 28 pixels. Thus the number of features is equal to 784 (= 28 x 28 pixels), 1 per pixel. The variable `num_output_classes` is set to 10 corresponding to the number of digits (0-9) in the dataset.\n",
|
|
"\n",
|
|
"In previous tutorials, as shown below, we have always flattened the input image into a vector. With convoultional networks, we do not flatten the image in this way.\n",
|
|
"\n",
|
|
"\n",
|
|
"\n",
|
|
"**Input Dimensions**: \n",
|
|
"\n",
|
|
"In convolutional networks for images, the input data is often shaped as a 3D matrix (number of channels, image width, height), which preserves the spatial relationship between the pixels. In the figure above, the MNIST image is a single channel (grayscale) data, so the input dimension is specified as a (1, image width, image height) tuple. \n",
|
|
"\n",
|
|
"\n",
|
|
"\n",
|
|
"Natural scene color images are often presented as Red-Green-Blue (RGB) color channels. The input dimension of such images are specified as a (3, image width, image height) tuple. If one has RGB input data as a volumetric scan with volume width, volume height and volume depth representing the 3 axes, the input data format would be specified by a tuple of 4 values (3, volume width, volume height, volume depth). In this way CNTK enables specification of input images in arbitrary higher-dimensional space."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 5,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"# Define the data dimensions\n",
|
|
"input_dim_model = (1, 28, 28) # images are 28 x 28 with 1 channel of color (gray)\n",
|
|
"input_dim = 28*28 # used by readers to treat input data as a vector\n",
|
|
"num_output_classes = 10"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"**Data Format** The data is stored on our local machine in the CNTK CTF format. The CTF format is a simple text format that contains a set of samples with each sample containing a set of named fields and their data. For our MNIST data, each sample contains 2 fields: labels and feature, formatted as:\n",
|
|
"\n",
|
|
" |labels 0 0 0 1 0 0 0 0 0 0 |features 0 255 0 123 ... \n",
|
|
" (784 integers each representing a pixel gray level)\n",
|
|
" \n",
|
|
"In this tutorial we are going to use the image pixels corresponding to the integer stream named \"features\". We define a `create_reader` function to read the training and test data using the [CTF deserializer](https://cntk.ai/pythondocs/cntk.io.html#cntk.io.CTFDeserializer). . \n",
|
|
"\n",
|
|
"The labels are [1-hot](https://en.wikipedia.org/wiki/One-hot) encoded (the label representing the output class of 3 becomes `0001000000` since we have 10 classes for the 10 possible digits), where the first index corresponds to digit `0` and the last one corresponds to digit `9`.\n",
|
|
"\n",
|
|
""
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 6,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"# Read a CTF formatted text (as mentioned above) using the CTF deserializer from a file\n",
|
|
"def create_reader(path, is_training, input_dim, num_label_classes):\n",
|
|
" \n",
|
|
" ctf = C.io.CTFDeserializer(path, C.io.StreamDefs(\n",
|
|
" labels=C.io.StreamDef(field='labels', shape=num_label_classes, is_sparse=False),\n",
|
|
" features=C.io.StreamDef(field='features', shape=input_dim, is_sparse=False)))\n",
|
|
" \n",
|
|
" return C.io.MinibatchSource(ctf,\n",
|
|
" randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 7,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Data directory is ..\\Examples\\Image\\DataSets\\MNIST\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# Ensure the training and test data is available for this tutorial.\n",
|
|
"# We search in two locations in the toolkit for the cached MNIST data set.\n",
|
|
"\n",
|
|
"data_found=False # A flag to indicate if train/test data found in local cache\n",
|
|
"for data_dir in [os.path.join(\"..\", \"Examples\", \"Image\", \"DataSets\", \"MNIST\"),\n",
|
|
" os.path.join(\"data\", \"MNIST\")]:\n",
|
|
" \n",
|
|
" train_file=os.path.join(data_dir, \"Train-28x28_cntk_text.txt\")\n",
|
|
" test_file=os.path.join(data_dir, \"Test-28x28_cntk_text.txt\")\n",
|
|
" \n",
|
|
" if os.path.isfile(train_file) and os.path.isfile(test_file):\n",
|
|
" data_found=True\n",
|
|
" break\n",
|
|
" \n",
|
|
"if not data_found:\n",
|
|
" raise ValueError(\"Please generate the data by completing CNTK 103 Part A\")\n",
|
|
" \n",
|
|
"print(\"Data directory is {0}\".format(data_dir))"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## CNN Model Creation\n",
|
|
"\n",
|
|
"CNN is a feedforward network made up of bunch of layers in such a way that the output of one layer becomes the input to the next layer (similar to MLP). In MLP, all possible pairs of input pixels are connected to the output nodes with each pair having a weight, thus leading to a combinatorial explosion of parameters to be learnt and also increasing the possibility of overfitting ([details](http://cs231n.github.io/neural-networks-1/)). Convolution layers take advantage of the spatial arrangement of the pixels and learn multiple filters that significantly reduce the amount of parameters in the network ([details](http://cs231n.github.io/convolutional-networks/)). The size of the filter is a parameter of the convolution layer. \n",
|
|
"\n",
|
|
"In this section, we introduce the basics of convolution operations. We show the illustrations in the context of RGB images (3 channels), eventhough the MNIST data we are using in this tutorial is a grayscale image (single channel).\n",
|
|
"\n",
|
|
"\n",
|
|
"\n",
|
|
"### Convolution Layer\n",
|
|
"\n",
|
|
"A convolution layer is a set of filters. Each filter is defined by a weight (**W**) matrix, and bias ($b$).\n",
|
|
"\n",
|
|
"\n",
|
|
"\n",
|
|
"These filters are scanned across the image performing the dot product between the weights and corresponding input value ($x$). The bias value is added to the output of the dot product and the resulting sum is optionally mapped through an activation function. This process is illustrated in the following animation."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 8,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"data": {
|
|
"text/html": [
|
|
"<img src=\"https://www.cntk.ai/jup/cntk103d_conv2d_final.gif\" width=\"300\"/>"
|
|
],
|
|
"text/plain": [
|
|
"<IPython.core.display.Image object>"
|
|
]
|
|
},
|
|
"execution_count": 8,
|
|
"metadata": {},
|
|
"output_type": "execute_result"
|
|
}
|
|
],
|
|
"source": [
|
|
"Image(url=\"https://www.cntk.ai/jup/cntk103d_conv2d_final.gif\", width= 300)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Convolution layers incorporate following key features:\n",
|
|
"\n",
|
|
" - Instead of being fully-connected to all pairs of input and output nodes , each convolution node is **locally-connected** to a subset of input nodes localized to a smaller input region, also referred to as receptive field (RF). The figure above illustrates a small 3 x 3 regions in the image as the RF region. In the case of an RGB, image there would be three such 3 x 3 regions, one each of the 3 color channels. \n",
|
|
" \n",
|
|
" \n",
|
|
" - Instead of having a single set of weights (as in a Dense layer), convolutional layers have multiple sets (shown in figure with multiple colors), called **filters**. Each filter detects features within each possible RF in the input image. The output of the convolution is a set of `n` sub-layers (shown in the animation below) where `n` is the number of filters (refer to the above figure). \n",
|
|
" \n",
|
|
" \n",
|
|
" - Within a sublayer, instead of each node having its own set of weights, a single set of **shared weights** are used by all nodes in that sublayer. This reduces the number of parameters to be learnt and thus overfitting. This also opens the door for several aspects of deep learning which has enabled very practical solutions to be built:\n",
|
|
" -- Handling larger images (say 512 x 512)\n",
|
|
" - Trying larger filter sizes (corresponding to a larger RF) say 11 x 11\n",
|
|
" - Learning more filters (say 128)\n",
|
|
" - Explore deeper architectures (100+ layers)\n",
|
|
" - Achieve translation invariance (the ability to recognize a feature independent of where they appear in the image). "
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"### Strides and Pad parameters\n",
|
|
"\n",
|
|
"**How are filters positioned?** In general, the filters are arranged in overlapping tiles, from left to right, and top to bottom. Each convolution layer has a parameter to specify the `filter_shape`, specifying the width and height of the filter in case most natural scene images. There is a parameter (`strides`) that controls the how far to step to right when moving the filters through multiple RF's in a row, and how far to step down when moving to the next row. The boolean parameter `pad` controls if the input should be padded around the edges to allow a complete tiling of the RF's near the borders. \n",
|
|
"\n",
|
|
"The animation above shows the results with a `filter_shape` = (3, 3), `strides` = (2, 2) and `pad` = False. The two animations below show the results when `pad` is set to True. First, with a stride of 2 and second having a stride of 1.\n",
|
|
"Note: the shape of the output (the teal layer) is different between the two stride settings. Many a times your decision to pad and the stride values to choose are based on the shape of the output layer needed."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 9,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"With stride = 2\n"
|
|
]
|
|
},
|
|
{
|
|
"data": {
|
|
"text/html": [
|
|
"<img src=\"https://www.cntk.ai/jup/cntk103d_padding_strides.gif\" width=\"200\" height=\"200\"/>"
|
|
],
|
|
"text/plain": [
|
|
"<IPython.core.display.Image object>"
|
|
]
|
|
},
|
|
"metadata": {},
|
|
"output_type": "display_data"
|
|
},
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"With stride = 1\n"
|
|
]
|
|
},
|
|
{
|
|
"data": {
|
|
"text/html": [
|
|
"<img src=\"https://www.cntk.ai/jup/cntk103d_same_padding_no_strides.gif\" width=\"200\" height=\"200\"/>"
|
|
],
|
|
"text/plain": [
|
|
"<IPython.core.display.Image object>"
|
|
]
|
|
},
|
|
"metadata": {},
|
|
"output_type": "display_data"
|
|
}
|
|
],
|
|
"source": [
|
|
"# Plot images with strides of 2 and 1 with padding turned on\n",
|
|
"images = [(\"https://www.cntk.ai/jup/cntk103d_padding_strides.gif\" , 'With stride = 2'),\n",
|
|
" (\"https://www.cntk.ai/jup/cntk103d_same_padding_no_strides.gif\", 'With stride = 1')]\n",
|
|
"\n",
|
|
"for im in images:\n",
|
|
" print(im[1])\n",
|
|
" display(Image(url=im[0], width=200, height=200))"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Building our CNN models\n",
|
|
"\n",
|
|
"In this CNN tutorial, we first define two containers. One for the input MNIST image and the second one being the labels corresponding to the 10 digits. When reading the data, the reader automatically maps the 784 pixels per image to a shape defined by `input_dim_model` tuple (in this example it is set to (1, 28, 28))."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 10,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"x = C.input_variable(input_dim_model)\n",
|
|
"y = C.input_variable(num_output_classes)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"The first model we build is a simple convolution only network. Here we have two convolutional layers. Since, our task is to detect the 10 digits in the MNIST database, the output of the network should be a vector of length 10, 1 element corresponding to each digit. This is achieved by projecting the output of the last convolutional layer using a dense layer with the output being `num_output_classes`. We have seen this before with Logistic Regression and MLP where features were mapped to the number of classes in the final layer. Also, note that since we will be using the `softmax` operation that is combined with the `cross entropy` loss function during training (see a few cells below), the final dense layer has no activation function associated with it.\n",
|
|
"\n",
|
|
"The following figure illustrates the model we are going to build. Note the parameters in the model below are to be experimented with. These are often called network hyperparameters. Increasing the filter shape leads to an increase in the number of model parameters, increases the compute time and helps the model better fit to the data. However, one runs the risk of [overfitting](https://en.wikipedia.org/wiki/Overfitting). Typically, the number of filters in the deeper layers are more than the number of filters in the layers before them. We have chosen 8, 16 for the first and second layers, respectively. These hyperparameters should be experimented with during model building.\n",
|
|
"\n",
|
|
""
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 11,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"# function to build model\n",
|
|
"\n",
|
|
"def create_model(features):\n",
|
|
" with C.layers.default_options(init=C.glorot_uniform(), activation=C.relu):\n",
|
|
" h = features\n",
|
|
" h = C.layers.Convolution2D(filter_shape=(5,5), \n",
|
|
" num_filters=8, \n",
|
|
" strides=(2,2), \n",
|
|
" pad=True, name='first_conv')(h)\n",
|
|
" h = C.layers.Convolution2D(filter_shape=(5,5), \n",
|
|
" num_filters=16, \n",
|
|
" strides=(2,2), \n",
|
|
" pad=True, name='second_conv')(h)\n",
|
|
" r = C.layers.Dense(num_output_classes, activation=None, name='classify')(h)\n",
|
|
" return r"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Let us create an instance of the model and inspect the different components of the model. `z` will be used to represent the output of a network. In this model, we use the `relu` activation function. Note: using the `C.layers.default_options` is an elegant way to write concise models. This is key to minimizing modeling errors, saving precious debugging time."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 12,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Output Shape of the first convolution layer: (8, 14, 14)\n",
|
|
"Bias value of the last dense layer: [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# Create the model\n",
|
|
"z = create_model(x)\n",
|
|
"\n",
|
|
"# Print the output shapes / parameters of different components\n",
|
|
"print(\"Output Shape of the first convolution layer:\", z.first_conv.shape)\n",
|
|
"print(\"Bias value of the last dense layer:\", z.classify.b.value)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Understanding number of model parameters to be estimated is key to deep learning since there is a direct dependency on the amount of data one needs to have. You need more data for a model that has larger number of parameters to prevent overfitting. In other words, with a fixed amount of data, one has to constrain the number of parameters. There is no golden rule between the amount of data one needs for a model. However, there are ways one can boost performance of model training with [data augmentation](https://deeplearningmania.quora.com/The-Power-of-Data-Augmentation-2). "
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 13,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Training 11274 parameters in 6 parameter tensors.\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# Number of parameters in the network\n",
|
|
"C.logging.log_number_of_parameters(z)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"**Understanding Parameters**:\n",
|
|
"\n",
|
|
"\n",
|
|
"Our model has 2 convolution layers each having a weight and bias. This adds up to 4 parameter tensors. Additionally the dense layer has weight and bias tensors. Thus, the 6 parameter tensors.\n",
|
|
"\n",
|
|
"Let us now count the number of parameters:\n",
|
|
"- *First convolution layer*: There are 8 filters each of size (1 x 5 x 5) where 1 is the number of channels in the input image. This adds up to 200 values in the weight matrix and 8 bias values.\n",
|
|
"\n",
|
|
"\n",
|
|
"- *Second convolution layer*: There are 16 filters each of size (8 x 5 x 5) where 8 is the number of channels in the input to the second layer (= output of the first layer). This adds up to 3200 values in the weight matrix and 16 bias values.\n",
|
|
"\n",
|
|
"\n",
|
|
"- *Last dense layer*: There are 16 x 7 x 7 input values and it produces 10 output values corresponding to the 10 digits in the MNIST dataset. This corresponds to (16 x 7 x 7) x 10 weight values and 10 bias values.\n",
|
|
"\n",
|
|
"Adding these up gives the 11274 parameters in the model."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"**Knowledge check**: Does the dense layer shape align with the task (MNIST digit classification)?\n",
|
|
"\n",
|
|
"** Suggested Activity **\n",
|
|
"- Try printing shapes and parameters of different network layers,\n",
|
|
"- Record the training error you get with `relu` as the activation function,\n",
|
|
"- Now change to `sigmoid` as the activation function and see if you can improve your training error.\n",
|
|
"\n",
|
|
"*Quiz*: Different supported activation functions can be [found here](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.Activation). Which activation function gives the least training error?"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"### Learning model parameters\n",
|
|
"\n",
|
|
"Same as the previous tutorial, we use the `softmax` function to map the accumulated evidences or activations to a probability distribution over the classes (Details of the [softmax function](http://cntk.ai/pythondocs/cntk.ops.html#cntk.ops.softmax) and other [activation](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.Activation) functions)."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Training\n",
|
|
"\n",
|
|
"Similar to CNTK 102, we minimize the cross-entropy between the label and predicted probability by the network. If this terminology sounds strange to you, please refer to the CNTK 102 for a refresher. Since we are going to build more than one model, we will create a few helper functions."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 14,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"def create_criterion_function(model, labels):\n",
|
|
" loss = C.cross_entropy_with_softmax(model, labels)\n",
|
|
" errs = C.classification_error(model, labels)\n",
|
|
" return loss, errs # (model, labels) -> (loss, error metric)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Next we will need a helper function to perform the model training. First let us create additional helper functions that will be needed to visualize different functions associated with training."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 15,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"# Define a utility function to compute the moving average sum.\n",
|
|
"# A more efficient implementation is possible with np.cumsum() function\n",
|
|
"def moving_average(a, w=5):\n",
|
|
" if len(a) < w:\n",
|
|
" return a[:] # Need to send a copy of the array\n",
|
|
" return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]\n",
|
|
"\n",
|
|
"\n",
|
|
"# Defines a utility that prints the training progress\n",
|
|
"def print_training_progress(trainer, mb, frequency, verbose=1):\n",
|
|
" training_loss = \"NA\"\n",
|
|
" eval_error = \"NA\"\n",
|
|
"\n",
|
|
" if mb%frequency == 0:\n",
|
|
" training_loss = trainer.previous_minibatch_loss_average\n",
|
|
" eval_error = trainer.previous_minibatch_evaluation_average\n",
|
|
" if verbose: \n",
|
|
" print (\"Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%\".format(mb, training_loss, eval_error*100))\n",
|
|
" \n",
|
|
" return mb, training_loss, eval_error"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"### Configure training\n",
|
|
"\n",
|
|
"In the previous tutorials we have described the concepts of `loss` function, the optimizers or [learners](https://cntk.ai/pythondocs/cntk.learners.html) and the associated machinery needed to train a model. Please refer to earlier tutorials for gaining familiarility with these concepts. In this tutorial, we combine model training and testing in a helper function below. \n"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 16,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"def train_test(train_reader, test_reader, model_func, num_sweeps_to_train_with=10):\n",
|
|
" \n",
|
|
" # Instantiate the model function; x is the input (feature) variable \n",
|
|
" # We will scale the input image pixels within 0-1 range by dividing all input value by 255.\n",
|
|
" model = model_func(x/255)\n",
|
|
" \n",
|
|
" # Instantiate the loss and error function\n",
|
|
" loss, label_error = create_criterion_function(model, y)\n",
|
|
" \n",
|
|
" # Instantiate the trainer object to drive the model training\n",
|
|
" learning_rate = 0.2\n",
|
|
" lr_schedule = C.learning_parameter_schedule(learning_rate)\n",
|
|
" learner = C.sgd(z.parameters, lr_schedule)\n",
|
|
" trainer = C.Trainer(z, (loss, label_error), [learner])\n",
|
|
" \n",
|
|
" # Initialize the parameters for the trainer\n",
|
|
" minibatch_size = 64\n",
|
|
" num_samples_per_sweep = 60000\n",
|
|
" num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size\n",
|
|
" \n",
|
|
" # Map the data streams to the input and labels.\n",
|
|
" input_map={\n",
|
|
" y : train_reader.streams.labels,\n",
|
|
" x : train_reader.streams.features\n",
|
|
" } \n",
|
|
" \n",
|
|
" # Uncomment below for more detailed logging\n",
|
|
" training_progress_output_freq = 500\n",
|
|
" \n",
|
|
" # Start a timer\n",
|
|
" start = time.time()\n",
|
|
"\n",
|
|
" for i in range(0, int(num_minibatches_to_train)):\n",
|
|
" # Read a mini batch from the training data file\n",
|
|
" data=train_reader.next_minibatch(minibatch_size, input_map=input_map) \n",
|
|
" trainer.train_minibatch(data)\n",
|
|
" print_training_progress(trainer, i, training_progress_output_freq, verbose=1)\n",
|
|
" \n",
|
|
" # Print training time\n",
|
|
" print(\"Training took {:.1f} sec\".format(time.time() - start))\n",
|
|
" \n",
|
|
" # Test the model\n",
|
|
" test_input_map = {\n",
|
|
" y : test_reader.streams.labels,\n",
|
|
" x : test_reader.streams.features\n",
|
|
" }\n",
|
|
"\n",
|
|
" # Test data for trained model\n",
|
|
" test_minibatch_size = 512\n",
|
|
" num_samples = 10000\n",
|
|
" num_minibatches_to_test = num_samples // test_minibatch_size\n",
|
|
"\n",
|
|
" test_result = 0.0 \n",
|
|
"\n",
|
|
" for i in range(num_minibatches_to_test):\n",
|
|
" \n",
|
|
" # We are loading test data in batches specified by test_minibatch_size\n",
|
|
" # Each data point in the minibatch is a MNIST digit image of 784 dimensions \n",
|
|
" # with one pixel per dimension that we will encode / decode with the \n",
|
|
" # trained model.\n",
|
|
" data = test_reader.next_minibatch(test_minibatch_size, input_map=test_input_map)\n",
|
|
" eval_error = trainer.test_minibatch(data)\n",
|
|
" test_result = test_result + eval_error\n",
|
|
"\n",
|
|
" # Average of evaluation errors of all test minibatches\n",
|
|
" print(\"Average test error: {0:.2f}%\".format(test_result*100 / num_minibatches_to_test))"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"### Run the trainer and test model\n",
|
|
"\n",
|
|
"We are now ready to train our convolutional neural net. "
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 17,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Minibatch: 0, Loss: 2.3132, Error: 87.50%\n",
|
|
"Minibatch: 500, Loss: 0.2041, Error: 10.94%\n",
|
|
"Minibatch: 1000, Loss: 0.1134, Error: 1.56%\n",
|
|
"Minibatch: 1500, Loss: 0.1540, Error: 3.12%\n",
|
|
"Minibatch: 2000, Loss: 0.0078, Error: 0.00%\n",
|
|
"Minibatch: 2500, Loss: 0.0240, Error: 1.56%\n",
|
|
"Minibatch: 3000, Loss: 0.0083, Error: 0.00%\n",
|
|
"Minibatch: 3500, Loss: 0.0581, Error: 3.12%\n",
|
|
"Minibatch: 4000, Loss: 0.0247, Error: 0.00%\n",
|
|
"Minibatch: 4500, Loss: 0.0389, Error: 1.56%\n",
|
|
"Minibatch: 5000, Loss: 0.0368, Error: 1.56%\n",
|
|
"Minibatch: 5500, Loss: 0.0015, Error: 0.00%\n",
|
|
"Minibatch: 6000, Loss: 0.0043, Error: 0.00%\n",
|
|
"Minibatch: 6500, Loss: 0.0120, Error: 0.00%\n",
|
|
"Minibatch: 7000, Loss: 0.0165, Error: 0.00%\n",
|
|
"Minibatch: 7500, Loss: 0.0097, Error: 0.00%\n",
|
|
"Minibatch: 8000, Loss: 0.0044, Error: 0.00%\n",
|
|
"Minibatch: 8500, Loss: 0.0037, Error: 0.00%\n",
|
|
"Minibatch: 9000, Loss: 0.0506, Error: 3.12%\n",
|
|
"Training took 30.4 sec\n",
|
|
"Average test error: 1.57%\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"def do_train_test():\n",
|
|
" global z\n",
|
|
" z = create_model(x)\n",
|
|
" reader_train = create_reader(train_file, True, input_dim, num_output_classes)\n",
|
|
" reader_test = create_reader(test_file, False, input_dim, num_output_classes)\n",
|
|
" train_test(reader_train, reader_test, z)\n",
|
|
" \n",
|
|
"do_train_test()"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Note, the average test error is very comparable to our training error indicating that our model has good \"out of sample\" error a.k.a. [generalization error](https://en.wikipedia.org/wiki/Generalization_error). This implies that our model can very effectively deal with previously unseen observations (during the training process). This is key to avoid [overfitting](https://en.wikipedia.org/wiki/Overfitting).\n",
|
|
"\n",
|
|
"Let us check what is the value of some of the network parameters. We will check the bias value of the output dense layer. Previously, it was all 0. Now you see there are non-zero values, indicating that a model parameters were updated during training."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 18,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Bias value of the last dense layer: [-0.03064867 -0.01484577 0.01883961 -0.27907506 0.10493447 -0.08710711\n",
|
|
" 0.00442157 -0.09873096 0.33425555 0.04781624]\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"print(\"Bias value of the last dense layer:\", z.classify.b.value)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"### Run evaluation / prediction\n",
|
|
"We have so far been dealing with aggregate measures of error. Let us now get the probabilities associated with individual data points. For each observation, the `eval` function returns the probability distribution across all the classes. The classifier is trained to recognize digits, hence has 10 classes. First let us route the network output through a `softmax` function. This maps the aggregated activations across the network to probabilities across the 10 classes."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 19,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"out = C.softmax(z)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Let us a small minibatch sample from the test data."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 20,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"# Read the data for evaluation\n",
|
|
"reader_eval=create_reader(test_file, False, input_dim, num_output_classes)\n",
|
|
"\n",
|
|
"eval_minibatch_size = 25\n",
|
|
"eval_input_map = {x: reader_eval.streams.features, y:reader_eval.streams.labels} \n",
|
|
"\n",
|
|
"data = reader_eval.next_minibatch(eval_minibatch_size, input_map=eval_input_map)\n",
|
|
"\n",
|
|
"img_label = data[y].asarray()\n",
|
|
"img_data = data[x].asarray()\n",
|
|
"\n",
|
|
"# reshape img_data to: M x 1 x 28 x 28 to be compatible with model\n",
|
|
"img_data = np.reshape(img_data, (eval_minibatch_size, 1, 28, 28))\n",
|
|
"\n",
|
|
"predicted_label_prob = [out.eval(img_data[i]) for i in range(len(img_data))]"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 21,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"# Find the index with the maximum value for both predicted as well as the ground truth\n",
|
|
"pred = [np.argmax(predicted_label_prob[i]) for i in range(len(predicted_label_prob))]\n",
|
|
"gtlabel = [np.argmax(img_label[i]) for i in range(len(img_label))]"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 22,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Label : [7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5, 4]\n",
|
|
"Predicted: [7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5, 4]\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"print(\"Label :\", gtlabel[:25])\n",
|
|
"print(\"Predicted:\", pred)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Let us visualize some of the results"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 23,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Image Label: 1\n"
|
|
]
|
|
},
|
|
{
|
|
"data": {
|
|
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAP4AAAD8CAYAAABXXhlaAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAFqFJREFUeJztnWtTG8uuQEXA2PhF9v//idm1QwA/wNi+H25pjkZWz4MY\n455eq2oKQwLZdTjLUndL6pvj8SgAUBY/vvs/AAAuD+IDFAjiAxQI4gMUCOIDFAjiAxQI4gMUyN0F\n/g0KBQC+j5voi0R8gAJBfIACQXyAAkF8gAJBfIACQXyAAkF8gAJBfIACQXyAAkF8gAJBfIACQXyA\nAkF8gAJBfIACQXyAAkF8gAJBfIACQXyAAkF8gAJBfIACQXyAAkF8gAJBfIACQXyAAkF8gAJBfIAC\nQXyAAkF8gAJBfIACQXyAAkF8gAJBfIACQXyAAkF8gAK5++7/ABgWx+Px5KN/rc/hcDh5LSJyc3NT\ne378+FH73P8d+3kbXf5OCSA+nJ3D4VB7VOzD4SD7/V4+Pj6Sz/F4lLu7O7m9va0++tc/fvw4+aiv\nEbsbiA9nRSXf7/fhs9vt5O3trXre399rn4uIjEYjub+/rx77+d3dXe0ZjUbVa80MoB3Eh7Nixdco\nvtvtqtdvb2+yXq9ls9nIer0+eS0iMplMks94PK69EWhGcXNzI7e3t7XlAqRBfDg7Vvz393fZ7XbV\nx81mIy8vL/L6+iqvr6/Va/0oIjKdTqtnNpvVPn94eJDxeCz7/b6SXtP8w+EgP378/361vhlADOLD\nWbERf7fbVam9pvSr1UpeXl7k6elJ/vz5U3uenp5ERGQ+n8tisZDFYlG9fnt7q+0F+Eh/d3dXRXv7\n34L8MYgPZ0V36W3E1/X7druV1Wolz8/P8vT0JP/999/Jczwe5fHxsfa8vb3JbrerbRiKSBXpR6OR\n7Pf76t+2siN/DOLD2bGpvqb52+1WNptNJf7v37/l33//lV+/flUff/36JSIi//zzj6xWK9lsNjXp\nVWCb3t/d3dXW+vrnyN4M4kMvfDrt/+xwOFTCv729VRt3q9VK1uv1SXqvKf7T05P8/v279vOi83z9\n9220H4/H1VGgSm/l543gFMSHT2HfAGykVem3220l/MvLS7V5p2v7l5cXWa1Wst1u5f39vSauLhE2\nm011hKebdprm69r+/v5eJpNJte7X/w4vP9RBfOhNVImnn+/3+1pq//r6Ks/Pz/L8/FxFdxVfj/Le\n399ra3TdGNxutzIajeT29lZE5GQXX6WfTqcnG37I3wziw6fw5bc2Wmuav16vK/E1ldf0vkvE3263\nlfS6Z6CVfaPRqJJev9+X/ZLup0F86E2q3t5HfJvq6y7+nz9/5PX1tVrzq/g+4r+/v1fpvWYA7+/v\ncjweq0g/m82qDUCf6otQxNME4sOniBpuoo09G/FV/M1mU236bbfbqrLPR3wRqX6m/rzD4VBF+vl8\nHmYM/jhPhDcBD+JDL/ymnpVej/FsxPfiPz8/12rztbhHI779GYfDoXoTsUU6s9lM5vO5LJfLmvg2\n1VcQPgbxoTdRpLcRv018jfD+o434+rOi47zFYiHL5bK2Oeg396AZxIfeRFHedt/5aj17lr9arU46\n9ny01p/ve+1t449+r4/ySN8NxIde2Ehva+dVSpu+62O786ywtl9f0cieerRRRzv19JyfXvx+ID70\nxkZ5TdVV7u12WxPf/pmV3kZrWwsgIrVyXD+IYzab1cTXfnx9Y/DVfrwZxCA+9CKK+Jrea4pvP/p1\nvI/2Xn4V2A7ZGI1G1WMjvh3OoZN4IuGR/xTEh97Ytb2XvmvE9zUAiqb6GuU1nddH+/N9xNdUPzWH\nD/nrID70wrfd2nN7f0QXrfHt7r1/RP4nvkZ6LdYZj8fV+b2N+FZ8G/H1Z0EM4kNvfMS3rbca8bWd\n1kZ8jfoi8fRdxXbe3d/fy3g8loeHB3l4eGjd3Iuk5w3gFMSHXtiIb4dt+KGZTTv6/udZfMTXSP/w\n8CCz2aza3BuPxyepvh+2ifBpEB9qNPXb65/76Tq2Ll9r8LWG3sqv1XlNaLutjfia4usMvijV92k+\nNIP40AkV1qb4Wj+/Wq2qgZnPz8/y+vpak3+323WSXqQ94usbQHSch/TdQXxoJKrNt9FexX95eTlp\nuf2M+CISbu5ptPcRnwKez4H4kMRuvim2A8/O0VPxbcT3DTRdsMd5urHn1/g+4kfre2gG8SHES+9T\n/Sji65Sdv4n4qeO8KOL7VB+6g/iQJJI/6rn3Ed9v8PUVX4t3Urv6GvGjzT3oBuLDCalBmlb8aMqO\nRnwdtKFn+p9Z49sJum0RX08BEL87iA8h0aaeHZQR7eprxPelu+dI9f05PhH/70B8CIlKan19vu25\nt+f4tn5fpY+m40RE4mvlnlbtefF1c0+/H9pBfKjRNF3ncDjUavBtF55vyvHdeF3TfN+ko+m+Xetr\nqW5T1R40g/hwgp+sY/vnvfjRk+rGa8LW2NsefD2rV+ltjX7UmQfdQHw4wUZ7PyIrEt3X59uJPL7n\nPsLX19vNPRvxNc23/fk24kN3EB9q+PW8bb/1QzdSab/NEtoivpfervF9xNdH/0wfUv3+ID6c4CO+\nHa9l1/GpN4Bob6Bt9LVN9VNrfI34uhRQ4ZG+P4gPJ6SGbTTJbp/oNKCP9D7V92t8O3zTfg/ydwfx\noUZTqh9t4kVfi2r821L9VMTX4zy7qx99D9L3A/HhhGiKrh+tZYtzogk7TUSTcPXxwzV1HW+/Bn8P\n4kONqFBHR2rZ++5U/L5n9W1z8/1ILTbvvgbEhxp+fW+n7Kj4frqOit8Ve1bvH1uD78/p4XwgPpxg\nO/Bs+61Kf66Irxt49mguKtBh8+78ID7UsKm+Xd9rPb5N9XV93zfi++M6v3tvxafz7mtAfKiRasbR\nVttzRHzbc2+LdHTnnlr8r4c6RzjBRnw/STc1QbdPI46/JstKH23u6d+H88H/mlAjFfF1c88P2Og6\nNluJKvNS4tOE83WQ6kONaI2vR3oqftSQ89l+e9trP51OZT6fJ+/Gg/OB+HCCLeDxl2La67H87bdt\nWOn9EM35fC7z+Vx+/vwpi8WiegOw47WI+OcD8aFG6hpsTfd1ZLZGe7u+jyK+lzUSfz6fy3K5lOVy\nKY+Pj7JcLmsjthD//CA+nOBLdlMRX4/yUmv8qBGnSfyfP3/WIr5O20H888PmHtTwEd/fhuvX937Y\nhpLqvtN6/JT4NuKT6n8dRHw4IYr4drCmbc5pivgip913fnR2JL6u+e18PcQ/L4gPNbpEfLu5ZyO+\nJ9VyayO+js1eLBaV+DpwgzX+14H4cEJTxI+O8jTia9RvSvOb1viPj4/y+PhYq+Aj1f8aEL8wmoZk\n6E24qYk7UR9+6jgvmqWXGrKh5/h6YYaW8NoOPUp2zwviF4g9fvOvo4Eb9mYcX6pri3ei8VrRo/Lb\nen2t4LMVe1TtfR2IXxj+sgwbsQ+HQ01w+9p+7jf2UlV7Kem9+LY7LxrAodEe+c8H4heI3byzc/P3\n+31jpLcdefaJ5E+l+j7d9xHfluj6SbpwPhC/MJpm5n98fISy+8e/WaSkb0rzo0Yd/WgzAoZwfA2I\nXyBRI44+UaT3bwR2aZBK9VNHeV0ifjSLj1T/vCB+Yfjx2f52nKZIr6l+anOwSf4+a3z/95H+/CB+\ngUTjs1X8VKS3r0VOjwWjM3z9vE18L7/93uhnwt+D+IWRivia5ts78PyV113n5vt1vF2v+zN6Pz+f\nvvvLgPgF4sX3HXhe9Lbbbi3+0kuN5vpxPp+ftNxSoHN5EL9Ami7E9Lfj9JmuI/K/mfl2iKZ9FouF\nTKfTWgMOkf7yIH5hpO7Gsym+vSijz4QdkdNGHD9Lz0Z8Kz4R/7IgfoGk1vhW+s+m+iJS263XDjyt\nxyfVvw4QvzB8uW6qIedvUn0f8bX1VvvsU6k+4l8O6iALpOvmXlstfoRf49ue+/l8LovFIpnqw+Xg\nf+3CsJdi2km69jgvtbnXZ1ffzsu3wzZSqT4R/7IgfoE0RfzUPL2um3v2KC81QjtK9VnjXxbW+IXR\nZY2farttq8cXkZMhG1b8xWJRS/UnkwnifxOIXyCf3dW32Pp5+zra2LNr/NRxHqn+ZUH8Amk6x2+a\nsKPY2nv/uT3KiyK+T/XtcR5cDsQvjKZa/c+c49vuOb+jn0r17QRdIv73gPgFYjfsos29aI1vN/fa\nZulFF2LaVN9O0LU9+Ih/ORC/MLpEfLurn4r4qXZbf5Sn5/h6hj+fz6u6fdb43wfiF0hbrX7XJp1I\n+raIv1gsah17+rDGvyyIPzC6zM23Ed4O2dDbcO0bgE33RdJpfird1zcAfROYTCa1IRzM1fseEH+A\nNM3NV7k3m41sNhtZr9eyXq9ltVpVz2azqd2RZ6/CtqRS/dQgDv8g/PeB+APDr+H9UEwvvpd/vV6H\nUb/pSM8O0fTy+xFbkfTIf3kQf4D4Wnxdx+vcfBVfhfcR36/3baovEhfvNEnv3wBSE3SR/3Ig/sBI\nleTqLr1K79N9lX69Xofz9tpS/WhufuoNwEd6hL88iD9Aomuu9Umt8a38mh2kynabjvKa1vn+Ljyi\n/feB+AMjOqrz47ObNvfW63W4NxB15zW9ATRt7qVKfuFyIP4ASV2YYWfkN8nvL8iwn6eux0pFfL+5\nd3dX/78cwn8PiD8wottwm+68j54moosx/ChtPyffrvkp1LkOEH+ApM7w9Y3ARnD/dEEFji681Dp8\ne901wl8fiD9grPB+va5PH+FFpLZzb8W3tfm2+cZv6MF1wNvwAPFR3MseSd9nmKa2397e3p405Hjx\nbaoP1wO/jYHSJv9nUnwlivgp8e1YLSL+9YD4AyUlvE/3+74B2M29ruIT8a8PfhsDIzqGa0r1+8zM\nV9oivr0R14pPxL8eEH+g+J19H+0/u6Pf1HqrQzfsLD2kv04Qf4DYtN5emBHdhmvfCLrgB2ra23J0\niKadp8fdeNcJx3kDw1ftacWerdDbbDatbbcizXPzfZT3F2boWl939hH/ukD8AWIbdOyUHRW/T7+9\nfx1Fez8+OzU3H64HxB8YNuKr+L7/3kZ8e1WW0mVuvh+mGV2RxTXY1wviDwzbktuU6tvRWk0DNX3r\nrD3Gs3Pzp9NpmOozRfc6YXNvYEQR36b6Kr2N+G399tEgzaaIn7oGG/GvByL+AOmT6kejtUTSbbdN\na3wVX3f2uSLrekH8gdEl1febe22jtXyfvZ+b7yO+b9Yh1b8+ED8zonW4/Vp0lBdFfF3j21RfJD1H\nz0rvu/K0Yk839fTrXnrEvx4QP1Oi0lwRCY/x/EDNtrn5baO0bMWe7cW3j+/MI9W/LhA/Q6JyWxW3\nTfy+5/hNI7Ss/PYuPD+Bh4296wPxMySqw/eTdb34Vv6uc/OjGXpe+ija+zvxaMu9PhA/M9o67yLx\n9Sivy9z81O04faK+TfGJ+NcJ4mdIaqRWNFU3WuM3zc231Xpe+rZor6l+NHGXiH9dIH6GRJN1ojn6\nOk7br/Hb5uanNvfaor0+0WUZbO5dF4ifISnpu0b8trn5UbVeU9S3V2Gr+CL1rj6i/XWB+Jnho70V\nXs/u7Rr+b+bme9H9cZ19dAffX5gB1wm/pQzR23D9RRkqut20a2rASRHV5Nu6/FRVHlE9HxA/M3y0\n93fj+VJcP26rDRvto7FaVnz9c3bu84Mdlwyxa3sb6XUzz4qv8n9mbn7UhZeK+Gze5QW/rczQiJ+6\nDdeK76vy+lyR1TRXz8/TI+LnB+JnSNttuKlUvwupmfl2mCYRP3/4bWWIrdLz4ttdfRXfXpTZRtvA\njdQan829vED8zGja3Eut8ftEfJHTVJ81/vDgt5UhvnjHH+v5Utyua/y2aG/HajE3P284zsuQVFtu\n6k68iFR1nb0B18/TWywWslgsTuRnwk5+IH5mpLrz+tyIG43N1q/Z9N5u6qn4y+WyNkkX8fME8TOk\n66WYTSl+VJPvz+99xF8ul7JYLGq7+5ruk+rnBeJnSirVtzv4qXQ/Et6KH53d21Tflu5yU06eIH6m\nRNHebub5aB/J74dt3NzchOf3fo2vywDm5ucL4mdI28aeH8kVzdJrG6/VFPH9IA57lg95gPgZ00X+\nPim/bc6JIr6u8fXNwX4k4ucF4mdGqhfftuZGLbmpqO9HZ/safU3n9Tx/MpmEI7cp4MkLflsZkqra\n02m6Ub2+j/ZRim8jeDQwM9oTIMrnCeJnRlO5rk7UTTXqRJdiRtLb9N1K74WPHsgDxM8Mn+r3FT+1\nsdcW8f0bALLnDeJniI/4dqjmZy7ETEkfCe/P/fVnQV4gfma0pfqpNX6Xu/HscM2U+NHobP2ZkA+I\nnyFta3x7Iabtx1eiI7zUE63zWdvnD8d5mWFHb9lx2rqr32eN7+WPon0q1RcRxM8YxL8y2nrmo158\nP3Ovy3jtVOWeP6Nv2tDjwox8IdXPELvO98M4+gzh8OJGETyV1rO2zxsifgZYaaPGHBv5rfhN8qd6\n8rus3ZE+f4j4V46XPmrDjW6/7Sq9/9jlsd/jX0MeIP4V46XXj362vp+75+XvOoIL6csB8a+UJum7\npvq+U8/iRe6a8iP9MGCNf+X4QRqR/NHGno/4+r1e1j7Cc3Q3HIj4V0xKet+W69P9vqO129J6pB8e\nRPyMadqca/s+e4bvC3lS5/f234K8QfzMsNLaarv7+/vqibKCLhV7ejmGrd5jss4wQfwr5ubmJkzR\no2k5OjHn/v7+5KjPy5uq1VfpbT8+QzeGCeJngL4B+IjdJv7Hx0dNYEtKeh2c6SM+0g8LxM+MplRf\n5+NppPeDMNvSfZ/qR405MAwQPxNs2u+jtY/49lw/Wqe3pfnRGh/xhwXHeVdO6tw9moirUV8jd0re\nKGtoi/rIPywQ/0qJJGvbkVf5NQOIZt53SfV9Hz7CDw9S/Qywab4Ka2+1nUwmMp1OZTabycfHx8lR\nnp23LyK1oz99o7BvGP5NI9ochLxB/EywO/sqvV5xNZ/PqzFbugywxTg+TZ/NZtWNt/rYu/CidJ9U\nf1gg/hXjz/HtulzX89PptJJe3xiaim+Ox6NMp9Pq0VtvJ5NJJb6VnyKeYYL4V04kv434bdJbYbWi\nT6N8JH7T5iAMB8TPAH+UZyP+fr+v/k5Tam47+lR8XSpEqX4U8ZF/OCB+JthdeRvx9Wt6nu+vq44m\n9miE949N9XWNz+beMEH8zLAR36b3usM/Go2S4usuv0Z3m95b8Yn4wwfxM0Mjvt/hH4/H8vHxIaPR\nqPq7PtJrRZ+//tq+9ht7rPGHCeJfGV166fUc3+7yq9QiUhvB5YdxqPj+DF+f6XRai/7s7A8TxM8U\nX4F3PB6rdbmm7rPZ7GTHX7OCqGhH9w1ms1m14afys8YfFoifIV54+3Xt1Ht4eDiRXht4osEbdslg\nd/1t1CfiDwfEz4yotdb+mUbySPrxeCyHw+HknjzfpON3+UejEan+wED8TLHi62tN98fjcfV3rPQP\nDw+V+Las1z5+jBcRf5ggfoaogJrqa2T3Y7S99LvdTo7HYzhkUx/fl6/LAdb4wwLxM8QP1bDjszX6\nq7R+BHc0wisa6WWzAX1NxB8ON23XMp+BL/8HSiL6faXu10s9/o3Df4yGdvivQzaEvzDEBxg2ofgs\n3AAKBPEBCgTxAQoE8QEKBPEBCgTxAQoE8QEKBPEBCgTxAQoE8QEKBPEBCgTxAQoE8QEKBPEBCgTx\nAQoE8QEKBPEBCgTxAQoE8QEK5BJTdpnOCHBlEPEBCgTxAQoE8QEKBPEBCgTxAQoE8QEKBPEBCgTx\nAQoE8QEKBPEBCgTxAQoE8QEKBPEBCgTxAQoE8QEKBPEBCgTxAQoE8QEKBPEBCgTxAQrk/wDrZmhf\ncrH18wAAAABJRU5ErkJggg==\n",
|
|
"text/plain": [
|
|
"<matplotlib.figure.Figure at 0x1361a571cf8>"
|
|
]
|
|
},
|
|
"metadata": {},
|
|
"output_type": "display_data"
|
|
}
|
|
],
|
|
"source": [
|
|
"# Plot a random image\n",
|
|
"sample_number = 5\n",
|
|
"plt.imshow(img_data[sample_number].reshape(28,28), cmap=\"gray_r\")\n",
|
|
"plt.axis('off')\n",
|
|
"\n",
|
|
"img_gt, img_pred = gtlabel[sample_number], pred[sample_number]\n",
|
|
"print(\"Image Label: \", img_pred)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Pooling Layer\n",
|
|
"\n",
|
|
"Often a times, one needs to control the number of parameters especially when having deep networks. For every layer of the convolution layer output (each layer, corresponds to the output of a filter), one can have a pooling layer. Pooling layers are typically introduced to:\n",
|
|
"- Reduce the dimensionality of the previous layer (speeding up the network),\n",
|
|
"- Makes the model more tolerant to changes in object location in the image. For example, even when a digit is shifted to one side of the image instead of being in the middle, the classifer would perform the classification task well.\n",
|
|
"\n",
|
|
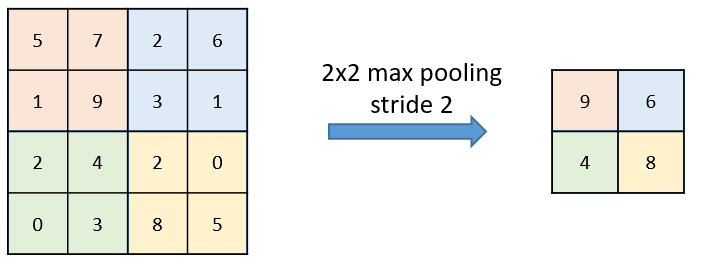
"The calculation on a pooling node is much simpler than a normal feedforward node. It has no weight, bias, or activation function. It uses a simple aggregation function (like max or average) to compute its output. The most commonly used function is \"max\" - a max pooling node simply outputs the maximum of the input values corresponding to the filter position of the input. The figure below shows the input values in a 4 x 4 region. The max pooling window size is 2 x 2 and starts from the top left corner. The maximum value within the window becomes the output of the region. Every time the model is shifted by the amount specified by the stride parameter (as shown in the figure below) and the maximum pooling operation is repeated. \n",
|
|
""
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Another alternative is average pooling, which emits that average value instead of the maximum value. The two different pooling opearations are summarized in the animation below."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 24,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Max pooling\n"
|
|
]
|
|
},
|
|
{
|
|
"data": {
|
|
"text/html": [
|
|
"<img src=\"https://www.cntk.ai/jup/c103d_max_pooling.gif\" width=\"200\" height=\"200\"/>"
|
|
],
|
|
"text/plain": [
|
|
"<IPython.core.display.Image object>"
|
|
]
|
|
},
|
|
"metadata": {},
|
|
"output_type": "display_data"
|
|
},
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Average pooling\n"
|
|
]
|
|
},
|
|
{
|
|
"data": {
|
|
"text/html": [
|
|
"<img src=\"https://www.cntk.ai/jup/c103d_average_pooling.gif\" width=\"200\" height=\"200\"/>"
|
|
],
|
|
"text/plain": [
|
|
"<IPython.core.display.Image object>"
|
|
]
|
|
},
|
|
"metadata": {},
|
|
"output_type": "display_data"
|
|
}
|
|
],
|
|
"source": [
|
|
"# Plot images with strides of 2 and 1 with padding turned on\n",
|
|
"images = [(\"https://www.cntk.ai/jup/c103d_max_pooling.gif\" , 'Max pooling'),\n",
|
|
" (\"https://www.cntk.ai/jup/c103d_average_pooling.gif\", 'Average pooling')]\n",
|
|
"\n",
|
|
"for im in images:\n",
|
|
" print(im[1])\n",
|
|
" display(Image(url=im[0], width=300, height=300))"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Typical convolution network\n",
|
|
"\n",
|
|
"\n",
|
|
"\n",
|
|
"A typical CNN contains a set of alternating convolution and pooling layers followed by a dense output layer for classification. You will find variants of this structure in many classical deep networks (VGG, AlexNet etc). This is in contrast to the MLP network we used in CNTK_103C, which consisted of 2 dense layers followed by a dense output layer. \n",
|
|
"\n",
|
|
"The illustrations are presented in the context of 2-dimensional (2D) images, but the concept and the CNTK components can operate on any dimensional data. The above schematic shows 2 convolution layer and 2 max-pooling layers. A typical strategy is to increase the number of filters in the deeper layers while reducing the spatial size of each intermediate layers. intermediate layers."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Task: Create a network with MaxPooling\n",
|
|
"\n",
|
|
"Typical convolutional networks have interlacing convolution and max pool layers. The previous model had only convolution layer. In this section, you will create a model with the following architecture.\n",
|
|
"\n",
|
|
"\n",
|
|
"\n",
|
|
"You will use the CNTK [MaxPooling](https://cntk.ai/pythondocs/cntk.layers.layers.html#cntk.layers.layers.MaxPooling) function to achieve this task. You will edit the `create_model` function below and add the MaxPooling operation. \n",
|
|
"\n",
|
|
"Hint: We provide the solution a few cells below. Refrain from looking ahead and try to add the layer yourself first."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 25,
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"# Modify this model\n",
|
|
"def create_model(features):\n",
|
|
" with C.layers.default_options(init = C.glorot_uniform(), activation = C.relu):\n",
|
|
" h = features\n",
|
|
" \n",
|
|
" h = C.layers.Convolution2D(filter_shape=(5,5), \n",
|
|
" num_filters=8, \n",
|
|
" strides=(2,2), \n",
|
|
" pad=True, name='first_conv')(h)\n",
|
|
" h = C.layers.Convolution2D(filter_shape=(5,5), \n",
|
|
" num_filters=16, \n",
|
|
" strides=(2,2), \n",
|
|
" pad=True, name='second_conv')(h)\n",
|
|
" r = C.layers.Dense(num_output_classes, activation = None, name='classify')(h)\n",
|
|
" return r\n",
|
|
" \n",
|
|
"# do_train_test()"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {
|
|
"collapsed": true
|
|
},
|
|
"source": [
|
|
"**Quiz**: How many parameters do we have in the model with MaxPooling and Convolution? Which of the two models produces lower error rate?\n",
|
|
"\n",
|
|
"\n",
|
|
"**Exploration Suggestion**\n",
|
|
"- Does the use of LeakyRelu help improve the error rate?\n",
|
|
"- What percentage of the parameter does the last dense layer contribute w.r.t. the overall number of parameters for (a) purely two convolutional layer and (b) alternating 2 convolutional and maxpooling layers "
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Solution"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 26,
|
|
"metadata": {},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Minibatch: 0, Loss: 2.3257, Error: 96.88%\n",
|
|
"Minibatch: 500, Loss: 0.0592, Error: 0.00%\n",
|
|
"Minibatch: 1000, Loss: 0.1007, Error: 3.12%\n",
|
|
"Minibatch: 1500, Loss: 0.1299, Error: 3.12%\n",
|
|
"Minibatch: 2000, Loss: 0.0077, Error: 0.00%\n",
|
|
"Minibatch: 2500, Loss: 0.0337, Error: 1.56%\n",
|
|
"Minibatch: 3000, Loss: 0.0038, Error: 0.00%\n",
|
|
"Minibatch: 3500, Loss: 0.0856, Error: 3.12%\n",
|
|
"Minibatch: 4000, Loss: 0.0052, Error: 0.00%\n",
|
|
"Minibatch: 4500, Loss: 0.0171, Error: 1.56%\n",
|
|
"Minibatch: 5000, Loss: 0.0266, Error: 1.56%\n",
|
|
"Minibatch: 5500, Loss: 0.0028, Error: 0.00%\n",
|
|
"Minibatch: 6000, Loss: 0.0070, Error: 0.00%\n",
|
|
"Minibatch: 6500, Loss: 0.0144, Error: 0.00%\n",
|
|
"Minibatch: 7000, Loss: 0.0083, Error: 0.00%\n",
|
|
"Minibatch: 7500, Loss: 0.0033, Error: 0.00%\n",
|
|
"Minibatch: 8000, Loss: 0.0114, Error: 0.00%\n",
|
|
"Minibatch: 8500, Loss: 0.0589, Error: 1.56%\n",
|
|
"Minibatch: 9000, Loss: 0.0186, Error: 1.56%\n",
|
|
"Training took 31.9 sec\n",
|
|
"Average test error: 1.05%\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# function to build model\n",
|
|
"def create_model(features):\n",
|
|
" with C.layers.default_options(init = C.layers.glorot_uniform(), activation = C.relu):\n",
|
|
" h = features\n",
|
|
" \n",
|
|
" h = C.layers.Convolution2D(filter_shape=(5,5), \n",
|
|
" num_filters=8, \n",
|
|
" strides=(1,1), \n",
|
|
" pad=True, name=\"first_conv\")(h)\n",
|
|
" h = C.layers.MaxPooling(filter_shape=(2,2), \n",
|
|
" strides=(2,2), name=\"first_max\")(h)\n",
|
|
" h = C.layers.Convolution2D(filter_shape=(5,5), \n",
|
|
" num_filters=16, \n",
|
|
" strides=(1,1), \n",
|
|
" pad=True, name=\"second_conv\")(h)\n",
|
|
" h = C.layers.MaxPooling(filter_shape=(3,3), \n",
|
|
" strides=(3,3), name=\"second_max\")(h)\n",
|
|
" r = C.layers.Dense(num_output_classes, activation = None, name=\"classify\")(h)\n",
|
|
" return r\n",
|
|
" \n",
|
|
"do_train_test()"
|
|
]
|
|
}
|
|
],
|
|
"metadata": {
|
|
"anaconda-cloud": {},
|
|
"kernelspec": {
|
|
"display_name": "Python 3",
|
|
"language": "python",
|
|
"name": "python3"
|
|
},
|
|
"language_info": {
|
|
"codemirror_mode": {
|
|
"name": "ipython",
|
|
"version": 3
|
|
},
|
|
"file_extension": ".py",
|
|
"mimetype": "text/x-python",
|
|
"name": "python",
|
|
"nbconvert_exporter": "python",
|
|
"pygments_lexer": "ipython3",
|
|
"version": "3.5.4"
|
|
}
|
|
},
|
|
"nbformat": 4,
|
|
"nbformat_minor": 1
|
|
}
|