зеркало из https://github.com/microsoft/LightGBM.git
Add Some More GPU documentation (#401)
* add dummy gpu solver code * initial GPU code * fix crash bug * first working version * use asynchronous copy * use a better kernel for root * parallel read histogram * sparse features now works, but no acceleration, compute on CPU * compute sparse feature on CPU simultaneously * fix big bug; add gpu selection; add kernel selection * better debugging * clean up * add feature scatter * Add sparse_threshold control * fix a bug in feature scatter * clean up debug * temporarily add OpenCL kernels for k=64,256 * fix up CMakeList and definition USE_GPU * add OpenCL kernels as string literals * Add boost.compute as a submodule * add boost dependency into CMakeList * fix opencl pragma * use pinned memory for histogram * use pinned buffer for gradients and hessians * better debugging message * add double precision support on GPU * fix boost version in CMakeList * Add a README * reconstruct GPU initialization code for ResetTrainingData * move data to GPU in parallel * fix a bug during feature copy * update gpu kernels * update gpu code * initial port to LightGBM v2 * speedup GPU data loading process * Add 4-bit bin support to GPU * re-add sparse_threshold parameter * remove kMaxNumWorkgroups and allows an unlimited number of features * add feature mask support for skipping unused features * enable kernel cache * use GPU kernels withoug feature masks when all features are used * REAdme. * REAdme. * update README * fix typos (#349) * change compile to gcc on Apple as default * clean vscode related file * refine api of constructing from sampling data. * fix bug in the last commit. * more efficient algorithm to sample k from n. * fix bug in filter bin * change to boost from average output. * fix tests. * only stop training when all classes are finshed in multi-class. * limit the max tree output. change hessian in multi-class objective. * robust tree model loading. * fix test. * convert the probabilities to raw score in boost_from_average of classification. * fix the average label for binary classification. * Add boost_from_average to docs (#354) * don't use "ConvertToRawScore" for self-defined objective function. * boost_from_average seems doesn't work well in binary classification. remove it. * For a better jump link (#355) * Update Python-API.md * for a better jump in page A space is needed between `#` and the headers content according to Github's markdown format [guideline](https://guides.github.com/features/mastering-markdown/) After adding the spaces, we can jump to the exact position in page by click the link. * fixed something mentioned by @wxchan * Update Python-API.md * add FitByExistingTree. * adapt GPU tree learner for FitByExistingTree * avoid NaN output. * update boost.compute * fix typos (#361) * fix broken links (#359) * update README * disable GPU acceleration by default * fix image url * cleanup debug macro * remove old README * do not save sparse_threshold_ in FeatureGroup * add details for new GPU settings * ignore submodule when doing pep8 check * allocate workspace for at least one thread during builing Feature4 * move sparse_threshold to class Dataset * remove duplicated code in GPUTreeLearner::Split * Remove duplicated code in FindBestThresholds and BeforeFindBestSplit * do not rebuild ordered gradients and hessians for sparse features * support feature groups in GPUTreeLearner * Initial parallel learners with GPU support * add option device, cleanup code * clean up FindBestThresholds; add some omp parallel * constant hessian optimization for GPU * Fix GPUTreeLearner crash when there is zero feature * use np.testing.assert_almost_equal() to compare lists of floats in tests * travis for GPU * add tutorial and more GPU docs
This commit is contained in:
Родитель
61ad133b5c
Коммит
bbcd5f4d6d
|
|
@ -7,7 +7,7 @@ LightGBM is a gradient boosting framework that uses tree based learning algorith
|
|||
- Faster training speed and higher efficiency
|
||||
- Lower memory usage
|
||||
- Better accuracy
|
||||
- Parallel learning supported
|
||||
- Parallel and GPU learning supported
|
||||
- Capable of handling large-scale data
|
||||
|
||||
For more details, please refer to [Features](https://github.com/Microsoft/LightGBM/wiki/Features).
|
||||
|
|
@ -17,7 +17,7 @@ For more details, please refer to [Features](https://github.com/Microsoft/LightG
|
|||
News
|
||||
----
|
||||
|
||||
04/10/2017 : Support use GPU to accelerate the tree learning.
|
||||
04/10/2017 : LightGBM now supports GPU-accelerated tree learning. Please read our [GPU Tutorial](./docs/GPU-Tutorial.md) and [Performance Comparison](./docs/GPU-Performance.md).
|
||||
|
||||
02/20/2017 : Update to LightGBM v2.
|
||||
|
||||
|
|
@ -45,6 +45,7 @@ To get started, please follow the [Installation Guide](https://github.com/Micros
|
|||
* [**Examples**](https://github.com/Microsoft/LightGBM/tree/master/examples)
|
||||
* [**Features**](https://github.com/Microsoft/LightGBM/wiki/Features)
|
||||
* [**Parallel Learning Guide**](https://github.com/Microsoft/LightGBM/wiki/Parallel-Learning-Guide)
|
||||
* [**GPU Learning Tutorial**](./docs/GPU-Tutorial.md)
|
||||
* [**Configuration**](https://github.com/Microsoft/LightGBM/wiki/Configuration)
|
||||
* [**Document Indexer**](https://github.com/Microsoft/LightGBM/blob/master/docs/Readme.md)
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,177 @@
|
|||
GPU Tuning Guide and Performance Comparison
|
||||
============================================
|
||||
|
||||
How it works?
|
||||
--------------------------
|
||||
|
||||
In LightGBM, the main computation cost during training is building the feature
|
||||
histograms. We use an efficient algorithm on GPU to accelerate this process.
|
||||
The implementation is highly modular, and works for all learning tasks
|
||||
(classification, ranking, regression, etc). GPU acceleration also works in
|
||||
distributed learning settings. GPU algorithm implementation is based on OpenCL
|
||||
and can work with a wide range of GPUs.
|
||||
|
||||
Supported Hardware
|
||||
--------------------------
|
||||
|
||||
We target AMD Graphics Core Next (GCN) architecture and NVIDIA
|
||||
Maxwell and Pascal architectures. Most AMD GPUs released after 2012 and NVIDIA
|
||||
GPUs released after 2014 should be supported. We have tested the GPU
|
||||
implementation on the following GPUs:
|
||||
|
||||
- AMD RX 480 with AMDGPU-pro driver 16.60 on Ubuntu 16.10
|
||||
- AMD R9 280X (aka Radeon HD 7970) with fglrx driver 15.302.2301 on Ubuntu 16.10
|
||||
- NVIDIA GTX 1080 with driver 375.39 and CUDA 8.0 on Ubuntu 16.10
|
||||
- NVIDIA Titan X (Pascal) with driver 367.48 and CUDA 8.0 on Ubuntu 16.04
|
||||
- NVIDIA Tesla M40 with driver 375.39 and CUDA 7.5 on Ubuntu 16.04
|
||||
|
||||
Using the following hardware is discouraged:
|
||||
|
||||
- NVIDIA Kepler (K80, K40, K20, most GeForce GTX 700 series GPUs) or earlier
|
||||
NVIDIA GPUs. They don't support hardware atomic operations in local memory space
|
||||
and thus histogram construction will be slow.
|
||||
|
||||
- AMD VLIW4-based GPUs, including Radeon HD 6xxx series and earlier GPUs. These
|
||||
GPUs have been discontinued for years and are rarely seen nowadays.
|
||||
|
||||
|
||||
How to Achieve Good Speedup on GPU
|
||||
----------------------------------
|
||||
|
||||
1. You want to run a few datasets that we have verified with good speedup
|
||||
(including Higgs, epsilon, Bosch, etc) to ensure your
|
||||
setup is correct. If you have multiple GPUs, make sure to set
|
||||
`gpu_platform_id` and `gpu_device_id` to use the desired GPU.
|
||||
Also make sure your system is idle (especially when using a
|
||||
shared computer) to get accuracy performance measurements.
|
||||
|
||||
2. GPU works best on large scale and dense datasets. If dataset is too small,
|
||||
computing it on GPU is inefficient as the data transfer overhead can be
|
||||
significant. For dataset with a mixture of sparse and dense features, you
|
||||
can control the `sparse_threshold` parameter to make sure there are enough
|
||||
dense features to process on the GPU. If you have categorical features, use
|
||||
the `categorical_column` option and input them into LightGBM directly; do
|
||||
not convert them into one-hot variables. Make sure to check the run log and
|
||||
look at the reported number of sparse and dense features.
|
||||
|
||||
|
||||
3. To get good speedup with GPU, it is suggested to use a smaller number of
|
||||
bins. Setting `max_bin=63` is recommended, as it usually does not
|
||||
noticeably affect training accuracy on large datasets, but GPU training can
|
||||
be significantly faster than using the default bin size of 255. For some
|
||||
dataset, even using 15 bins is enough (`max_bin=15`); using 15 bins will
|
||||
maximize GPU performance. Make sure to check the run log and verify that the
|
||||
desired number of bins is used.
|
||||
|
||||
4. Try to use single precision training (`gpu_use_dp=false`) when possible,
|
||||
because most GPUs (especially NVIDIA consumer GPUs) have poor
|
||||
double-precision performance.
|
||||
|
||||
Performance Comparison
|
||||
--------------------------
|
||||
|
||||
We evaluate the training performance of GPU acceleration on the following datasets:
|
||||
|
||||
| Data | Task | Link | #Examples | #Feature| Comments|
|
||||
|----------|---------------|-------|-------|---------|---------|
|
||||
| Higgs | Binary classification | [link](https://archive.ics.uci.edu/ml/datasets/HIGGS) |10,500,000|28| use last 500,000 samples as test set |
|
||||
| Epsilon | Binary classification | [link](http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html) | 400,000 | 2,000 | use the provided test set |
|
||||
| Bosch | Binary classification | [link](https://www.kaggle.com/c/bosch-production-line-performance/data) | 1,000,000 | 968 | use the provided test set |
|
||||
| Yahoo LTR| Learning to rank | [link](https://webscope.sandbox.yahoo.com/catalog.php?datatype=c) |473,134|700| set1.train as train, set1.test as test |
|
||||
| MS LTR | Learning to rank | [link](http://research.microsoft.com/en-us/projects/mslr/) |2,270,296|137| {S1,S2,S3} as train set, {S5} as test set |
|
||||
| Expo | Binary classification (Categorical) | [link](http://stat-computing.org/dataexpo/2009/) |11,000,000|700| use last 1,000,000 as test set |
|
||||
|
||||
We used the following hardware to evaluate the performance of LightGBM GPU training.
|
||||
Our CPU reference is **a high-end dual socket Haswell-EP Xeon server with 28 cores**;
|
||||
GPUs include a budget GPU (RX 480) and a mainstream (GTX 1080) GPU installed on
|
||||
the same server. It is worth mentioning that **the GPUs used are not the best GPUs in
|
||||
the market**; if you are using a better GPU (like AMD RX 580, NVIDIA GTX 1080 Ti,
|
||||
Titan X Pascal, Titan Xp, Tesla P100, etc), you are likely to get a better speedup.
|
||||
|
||||
| Hardware | Peak FLOPS | Peak Memory BW | Cost (MSRP) |
|
||||
|------------------------------|--------------|----------------|-------------|
|
||||
| AMD Radeon RX 480 | 5,161 GFLOPS | 256 GB/s | $199 |
|
||||
| NVIDIA GTX 1080 | 8,228 GFLOPS | 320 GB/s | $499 |
|
||||
| 2x Xeon E5-2683v3 (28 cores) | 1,792 GFLOPS | 133 GB/s | $3,692 |
|
||||
|
||||
During benchmarking on CPU we used only 28 physical cores of the CPU, and did
|
||||
not use hyper-threading cores, because we found that using too many threads
|
||||
actually makes performance worse. The following shows the training configuration we used:
|
||||
|
||||
```
|
||||
max_bin = 63
|
||||
num_leaves = 255
|
||||
num_iterations = 500
|
||||
learning_rate = 0.1
|
||||
tree_learner = serial
|
||||
task = train
|
||||
is_train_metric = false
|
||||
min_data_in_leaf = 1
|
||||
min_sum_hessian_in_leaf = 100
|
||||
ndcg_eval_at = 1,3,5,10
|
||||
sparse_threshold=1.0
|
||||
device = gpu
|
||||
gpu_platform_id = 0
|
||||
gpu_device_id = 0
|
||||
num_thread = 28
|
||||
```
|
||||
|
||||
We use the configuration shown above, except for the
|
||||
Bosch dataset, we use a smaller `learning_rate=0.015` and set
|
||||
`min_sum_hessian_in_leaf=5`. For all GPU training we set
|
||||
`sparse_threshold=1`, and vary the max number of bins (255, 63 and 15). The
|
||||
GPU implementation is from commit
|
||||
[0bb4a82](https://github.com/Microsoft/LightGBM/commit/0bb4a82)
|
||||
of LightGBM, when the GPU support was just merged in.
|
||||
|
||||
The following table lists the accuracy on test set that CPU and GPU learner
|
||||
can achieve after 500 iterations. GPU with the same number of bins can achieve
|
||||
a similar level of accuracy as on the CPU, despite using single precision
|
||||
arithmetic. For most datasets, using 63 bins is sufficient.
|
||||
|
||||
| | CPU 255 bins | CPU 63 bins | CPU 15 bins | GPU 255 bins | GPU 63 bins | GPU 15 bins |
|
||||
|-------------------|--------------|-------------|-------------|--------------|-------------|-------------|
|
||||
| Higgs AUC | 0.845612 | 0.845239 | 0.841066 | 0.845612 | 0.845209 | 0.840748 |
|
||||
| Epsilon AUC | 0.950243 | 0.949952 | 0.948365 | 0.950057 | 0.949876 | 0.948365 |
|
||||
| Yahoo-LTR NDCG@1 | 0.730824 | 0.730165 | 0.729647 | 0.730936 | 0.732257 | 0.73114 |
|
||||
| Yahoo-LTR NDCG@3 | 0.738687 | 0.737243 | 0.736445 | 0.73698 | 0.739474 | 0.735868 |
|
||||
| Yahoo-LTR NDCG@5 | 0.756609 | 0.755729 | 0.754607 | 0.756206 | 0.757007 | 0.754203 |
|
||||
| Yahoo-LTR NDCG@10 | 0.79655 | 0.795827 | 0.795273 | 0.795894 | 0.797302 | 0.795584 |
|
||||
| Expo AUC | 0.776217 | 0.771566 | 0.743329 | 0.776285 | 0.77098 | 0.744078 |
|
||||
| MS-LTR NDCG@1 | 0.521265 | 0.521392 | 0.518653 | 0.521789 | 0.522163 | 0.516388 |
|
||||
| MS-LTR NDCG@3 | 0.503153 | 0.505753 | 0.501697 | 0.503886 | 0.504089 | 0.501691 |
|
||||
| MS-LTR NDCG@5 | 0.509236 | 0.510391 | 0.507193 | 0.509861 | 0.510095 | 0.50663 |
|
||||
| MS-LTR NDCG@10 | 0.527835 | 0.527304 | 0.524603 | 0.528009 | 0.527059 | 0.524722 |
|
||||
| Bosch AUC | 0.718115 | 0.721791 | 0.716677 | 0.717184 | 0.724761 | 0.717005 |
|
||||
|
||||
|
||||
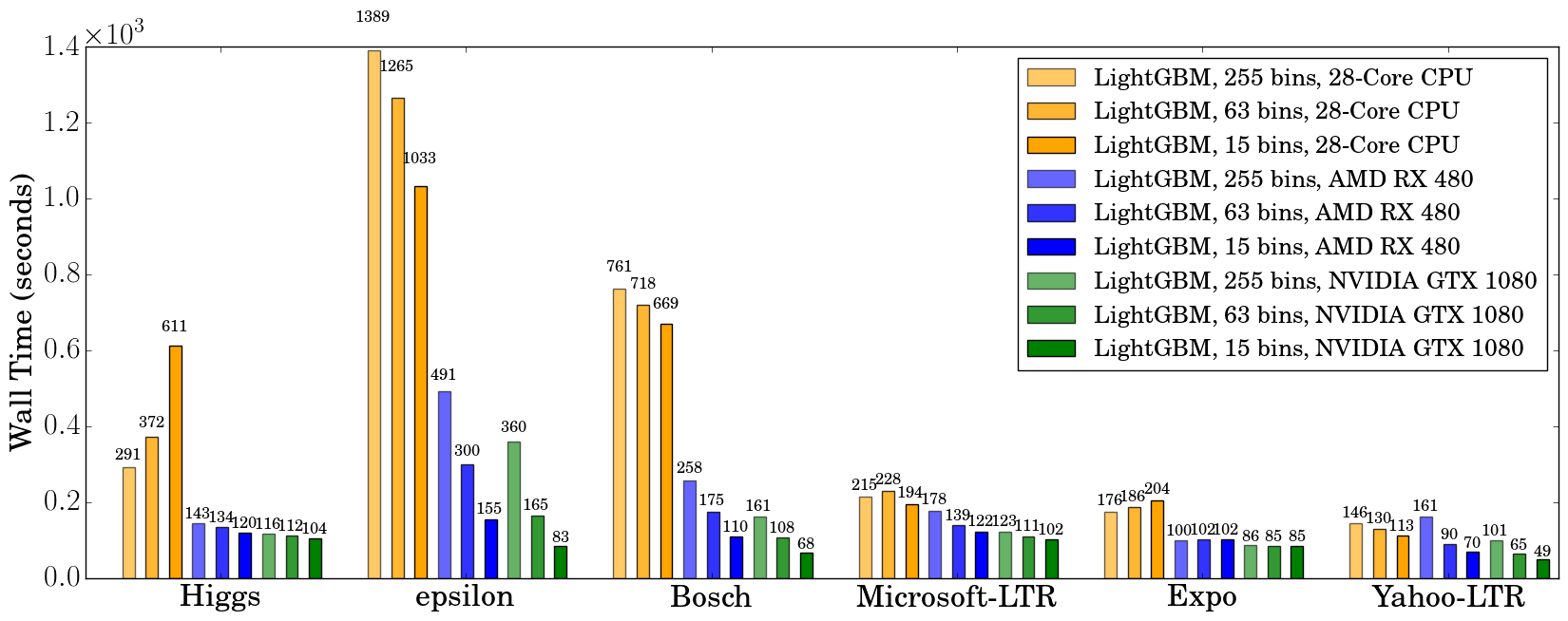
We record the wall clock time after 500 iterations, as shown in the figure below:
|
||||
|
||||
|
||||
|
||||
When using a GPU, it is advisable to use a bin size of 63 rather than 255,
|
||||
because it can speed up training significantly without noticeably affecting
|
||||
accuracy. On CPU, using a smaller bin size only marginally improves
|
||||
performance, sometimes even slows down training, like in Higgs (we can
|
||||
reproduce the same slowdown on two different machines, with different GCC
|
||||
versions). We found that GPU can achieve impressive acceleration on large and
|
||||
dense datasets like Higgs and Epsilon. Even on smaller and sparse datasets,
|
||||
a *budget* GPU can still compete and be faster than a 28-core Haswell server.
|
||||
|
||||
Memory Usage
|
||||
---------------
|
||||
|
||||
The next table shows GPU memory usage reported by `nvidia-smi` during training
|
||||
with 63 bins. We can see that even the largest dataset just uses about 1 GB of
|
||||
GPU memory, indicating that our GPU implementation can scale to huge
|
||||
datasets over 10x larger than Bosch or Epsilon. Also, we can observe that
|
||||
generally a larger dataset (using more GPU memory, like Epsilon or Bosch)
|
||||
has better speedup, because the overhead of invoking GPU functions becomes
|
||||
significant when the dataset is small.
|
||||
|
||||
| Datasets | Higgs | Epsilon | Bosch | MS-LTR | Expo |Yahoo-LTR |
|
||||
|-----------------------|-------|---------|--------|---------|-------|----------|
|
||||
| GPU Memory Usage (MB) | 611 | 901 | 1067 | 413 | 405 | 291 |
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,185 @@
|
|||
LightGBM GPU Tutorial
|
||||
==================================
|
||||
|
||||
The purpose of this document is to give you a quick step-by-step tutorial on GPU training.
|
||||
We will use the GPU instance on
|
||||
[Microsoft Azure cloud computing platform](https://azure.microsoft.com/)
|
||||
for demonstration, but you can use any machine with modern AMD or NVIDIA GPUs.
|
||||
|
||||
|
||||
GPU Setup
|
||||
-------------------------
|
||||
|
||||
You need to launch a `NV` type instance on Azure (available in East US, North
|
||||
Central US, South Central US, West Europe and Southeast Asia zones)
|
||||
and select Ubuntu 16.04 LTS as the operating system.
|
||||
For testing, the smallest `NV6` type virtual machine is sufficient, which includes
|
||||
1/2 M60 GPU, with 8 GB memory, 180 GB/s memory bandwidth and 4,825 GFLOPS peak
|
||||
computation power. Don't use the `NC` type instance as the GPUs (K80) are
|
||||
based on an older architecture (Kepler).
|
||||
|
||||
First we need to install minimal NVIDIA drivers and OpenCL development environment:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get install --no-install-recommends nvidia-375
|
||||
sudo apt-get install --no-install-recommends nvidia-opencl-icd-375 nvidia-opencl-dev opencl-headers
|
||||
```
|
||||
|
||||
After installing the drivers you need to restart the server.
|
||||
|
||||
```
|
||||
sudo init 6
|
||||
```
|
||||
|
||||
After about 30 seconds, the server should be up again.
|
||||
|
||||
If you are using a AMD GPU, you should download and install the
|
||||
[AMDGPU-Pro](http://support.amd.com/en-us/download/linux) driver and
|
||||
also install package `ocl-icd-libopencl1` and `ocl-icd-opencl-dev`.
|
||||
|
||||
Build LightGBM
|
||||
----------------------------
|
||||
|
||||
Now install necessary building tools and dependencies:
|
||||
```
|
||||
sudo apt-get install --no-install-recommends git cmake build-essential libboost-dev libboost-system-dev libboost-filesystem-dev
|
||||
```
|
||||
|
||||
The NV6 GPU instance has a 320 GB ultra-fast SSD mounted at /mnt. Let's use it
|
||||
as our workspace (skip this if you are using your own machine):
|
||||
|
||||
```
|
||||
sudo mkdir -p /mnt/workspace
|
||||
sudo chown $(whoami):$(whoami) /mnt/workspace
|
||||
cd /mnt/workspace
|
||||
```
|
||||
|
||||
Now we are ready to checkout LightGBM and compile it with GPU support:
|
||||
|
||||
```
|
||||
git clone --recursive https://github.com/Microsoft/LightGBM
|
||||
cd LightGBM
|
||||
mkdir build ; cd build
|
||||
cmake -DUSE_GPU=1 ..
|
||||
make -j$(nproc)
|
||||
cd ..
|
||||
```
|
||||
|
||||
You will see two binaries are generated, `lightgbm` and `lib_lightgbm.so`.
|
||||
|
||||
If you are building on OSX, you probably need to remove macro
|
||||
`BOOST_COMPUTE_USE_OFFLINE_CACHE` in `src/treelearner/gpu_tree_learner.h` to
|
||||
avoid a known crash bug in Boost.Compute.
|
||||
|
||||
Install Python Interface (optional)
|
||||
-----------------------------------
|
||||
|
||||
If you want to use the Python interface of LightGBM, you can install it now
|
||||
(along with some necessary Python package dependencies):
|
||||
|
||||
```
|
||||
sudo apt-get -y install python-pip
|
||||
sudo -H pip install setuptools numpy scipy scikit-learn -U
|
||||
cd python-package/
|
||||
sudo python setup.py install
|
||||
cd ..
|
||||
```
|
||||
|
||||
You need to set an additional parameter `"device" : "gpu"` (along with your other options
|
||||
like `learning_rate`, `num_leaves`, etc) to use GPU in Python.
|
||||
You can read our [Python Guide](https://github.com/Microsoft/LightGBM/tree/master/examples/python-guide)
|
||||
for more information on how to use the Python interface.
|
||||
|
||||
Dataset Preparation
|
||||
----------------------------
|
||||
|
||||
Using the following commands to prepare the Higgs dataset:
|
||||
|
||||
```
|
||||
git clone https://github.com/guolinke/boosting_tree_benchmarks.git
|
||||
cd boosting_tree_benchmarks/data
|
||||
wget "https://archive.ics.uci.edu/ml/machine-learning-databases/00280/HIGGS.csv.gz"
|
||||
gunzip HIGGS.csv.gz
|
||||
python higgs2libsvm.py
|
||||
cd ../..
|
||||
ln -s boosting_tree_benchmarks/data/higgs.train
|
||||
ln -s boosting_tree_benchmarks/data/higgs.test
|
||||
```
|
||||
|
||||
Now we create a configuration file for LightGBM by running the following commands
|
||||
(please copy the entire block and run it as a whole):
|
||||
|
||||
```
|
||||
cat > lightgbm_gpu.conf <<EOF
|
||||
max_bin = 63
|
||||
num_leaves = 255
|
||||
num_iterations = 50
|
||||
learning_rate = 0.1
|
||||
tree_learner = serial
|
||||
task = train
|
||||
is_train_metric = false
|
||||
min_data_in_leaf = 1
|
||||
min_sum_hessian_in_leaf = 100
|
||||
ndcg_eval_at = 1,3,5,10
|
||||
sparse_threshold = 1.0
|
||||
device = gpu
|
||||
gpu_platform_id = 0
|
||||
gpu_device_id = 0
|
||||
EOF
|
||||
echo "num_threads=$(nproc)" >> lightgbm_gpu.conf
|
||||
```
|
||||
|
||||
GPU is enabled in the configuration file we just created by setting `device=gpu`. It will use
|
||||
the first GPU installed on the system by default (`gpu_platform_id=0` and
|
||||
`gpu_device_id=0`).
|
||||
|
||||
Run Your First Learning Task on GPU
|
||||
-----------------------------------
|
||||
|
||||
Now we are ready to start GPU training! First we want to verify the GPU works
|
||||
correctly. Run the following command to train on GPU, and take a note of the
|
||||
AUC after 50 iterations:
|
||||
|
||||
```
|
||||
./lightgbm config=lightgbm_gpu.conf data=higgs.train valid=higgs.test objective=binary metric=auc
|
||||
```
|
||||
|
||||
Now train the same dataset on CPU using the following command. You should observe a similar AUC:
|
||||
|
||||
```
|
||||
./lightgbm config=lightgbm_gpu.conf data=higgs.train valid=higgs.test objective=binary metric=auc device=cpu
|
||||
```
|
||||
|
||||
Now we can make a speed test on GPU without calculating AUC after each iteration.
|
||||
|
||||
```
|
||||
./lightgbm config=lightgbm_gpu.conf data=higgs.train objective=binary metric=auc
|
||||
```
|
||||
|
||||
Speed test on CPU:
|
||||
|
||||
```
|
||||
./lightgbm config=lightgbm_gpu.conf data=higgs.train objective=binary metric=auc device=cpu
|
||||
```
|
||||
|
||||
You should observe over three times speedup on this GPU.
|
||||
|
||||
The GPU acceleration can be used on other tasks/metrics (regression, multi-class classification, ranking, etc)
|
||||
as well. For example, we can train the Higgs dataset on GPU as a regression task:
|
||||
|
||||
```
|
||||
./lightgbm config=lightgbm_gpu.conf data=higgs.train objective=regression_l2 metric=l2
|
||||
```
|
||||
|
||||
Also, you can compare the training speed with CPU:
|
||||
|
||||
```
|
||||
./lightgbm config=lightgbm_gpu.conf data=higgs.train objective=regression_l2 metric=l2 device=cpu
|
||||
```
|
||||
|
||||
Further Reading
|
||||
---------------
|
||||
|
||||
[GPU Tuning Guide and Performance Comparison](./GPU-Performance.md)
|
||||
|
||||
Загрузка…
Ссылка в новой задаче