|
|
||
|---|---|---|
| .. | ||
| data | ||
| images | ||
| prompts | ||
| scripts | ||
| src | ||
| .gitignore | ||
| README.md | ||
| requirements.txt | ||
README.md
🤔🛠️🤖 CRITIC:
Large Language Models Can Self-Correct
with Tool-Interactive Critiquing
[Quick Start] • [Paper] • [Citation]
Repo for the paper "CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing" [ICLR'24]
🔥 News
- In our updated paper, we add CRITIC results of open-source LLaMA-2 models from 7B to 70B on three QA / commonsense reasoning tasks, and three mathematical code synthesis tasks.
💡 Introduction
For the first time, we find that LLMs' Self-Verification and Self-Correction are unreliable; and we propose CRITIC, which enables LLMs to validate and rectify themselves through interaction with external tools.
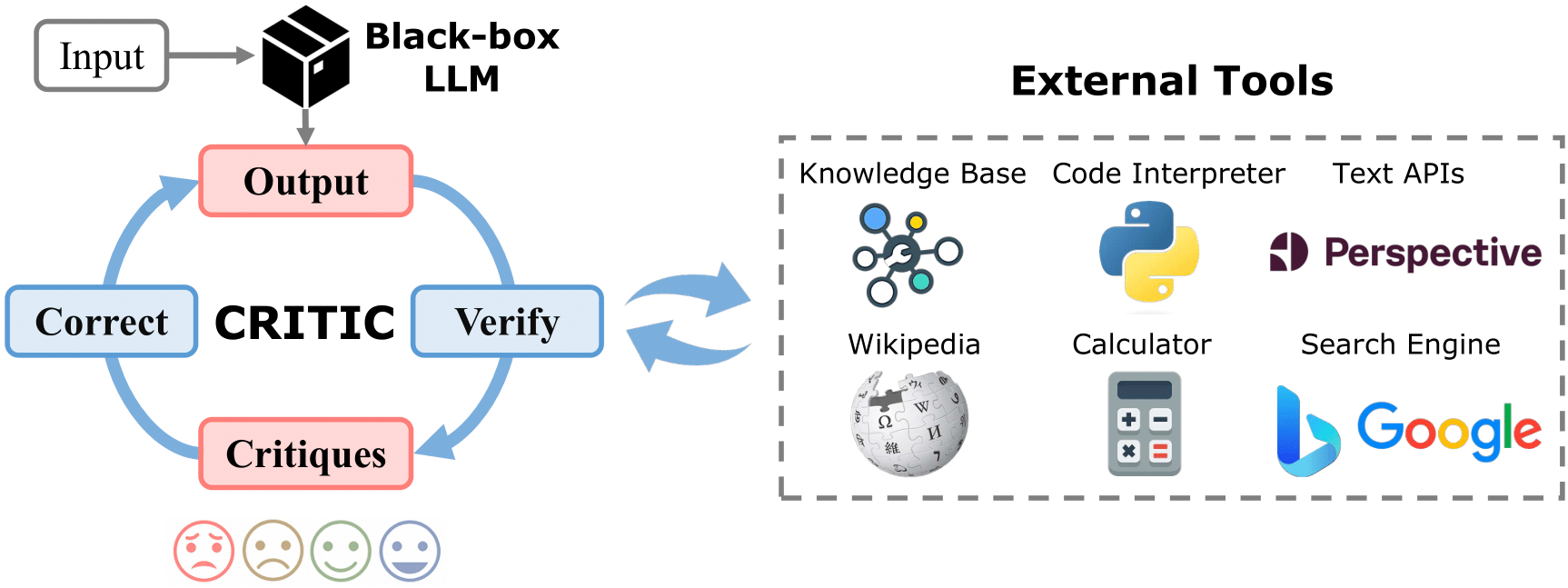
Humans typically utilize external tools to cross-check and refine their initial content, like using a search engine for fact-checking, or a code interpreter for debugging. Inspired by this observation, we introduce a framework called CRITIC that allows LLMs, which are essentially “black boxes” to validate and progressively amend their own outputs in a manner similar to human interaction with tools.
💬 Examples

🛠️ Setup
We recommend the use of conda environments:
conda create --name critic python=3.8
conda activate critic
pip install -r requirements.txt
Configure APIs:
-
Configure the LLMs API in
src/llms/api.py. -
For truthfulness evaluation and fact correction, configure the Google Search API in
src/tools/config.py. -
For toxicity reduction, you can follow this tutorial and configure Perspective API in
src/tools/config.py.
🔥🔥 For an alternative to Google API, try our free web scraping tools available at LLM-Agent-Web-Tools.
🚀 Quick Start
We provide example bash scripts for each task as follows:
Free-from Question Answering (Google)
- Inference:
bash scripts/run_qa_infer.sh - CRITIC:
bash scripts/run_qa_critic.sh - Evaluation:
python -m src.qa.evaluate
Mathematical Program Synthesis (Python Interpreter)
- Inference:
bash scripts/run_program_infer.sh - CRITIC:
bash scripts/run_program_critic.sh - Evaluation:
python -m src.program.evaluate
Toxicity Reduction (Perpective API)
- Inference:
bash scripts/run_toxicity_infer.sh - CRITIC:
bash scripts/run_toxicity_critic.sh - Evaluation:
python -m src.toxicity.evaluate
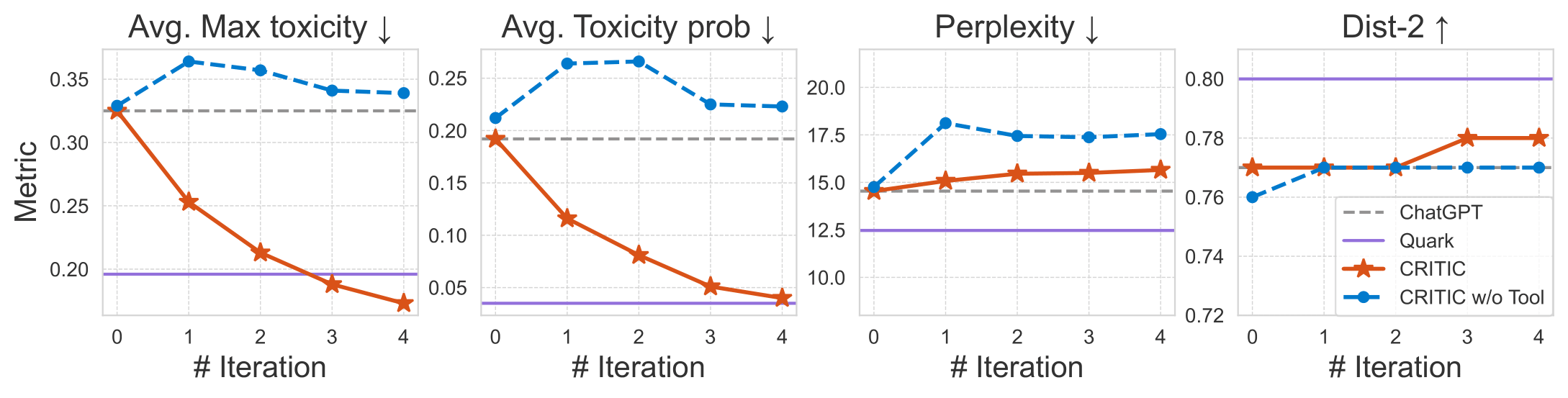
🎯 Results
Example results with gpt-3.5-turbo:
Free-from Question Answering:

Mathematical Program Synthesis:

Toxicity Reduction:
☕️ Citation
@inproceedings{
gou2024critic,
title={{CRITIC}: Large Language Models Can Self-Correct with Tool-Interactive Critiquing},
author={Zhibin Gou and Zhihong Shao and Yeyun Gong and yelong shen and Yujiu Yang and Nan Duan and Weizhu Chen},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=Sx038qxjek}
}