зеркало из https://github.com/microsoft/SynapseML.git
chore: bump to v0.11.2 (#2011)
This commit is contained in:
Родитель
e487c69640
Коммит
1e80aa15ba
30
README.md
30
README.md
|
|
@ -11,10 +11,10 @@ SynapseML requires Scala 2.12, Spark 3.2+, and Python 3.8+.
|
|||
| Topics | Links |
|
||||
| :------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| Build | [](https://msdata.visualstudio.com/A365/_build/latest?definitionId=17563&branchName=master) [](https://codecov.io/gh/Microsoft/SynapseML) [](https://github.com/psf/black) |
|
||||
| Version | [](https://github.com/Microsoft/SynapseML/releases) [](https://github.com/Microsoft/SynapseML/releases) [](#sbt) |
|
||||
| Docs | [](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/index.html#package) [](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/index.html) [](https://arxiv.org/abs/1810.08744) |
|
||||
| Version | [](https://github.com/Microsoft/SynapseML/releases) [](https://github.com/Microsoft/SynapseML/releases) [](#sbt) |
|
||||
| Docs | [](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/index.html#package) [](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/index.html) [](https://arxiv.org/abs/1810.08744) |
|
||||
| Support | [](https://gitter.im/Microsoft/MMLSpark?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge) [](mailto:synapseml-support@microsoft.com) |
|
||||
| Binder | [](https://mybinder.org/v2/gh/microsoft/SynapseML/v0.11.1?labpath=notebooks%2Ffeatures) |
|
||||
| Binder | [](https://mybinder.org/v2/gh/microsoft/SynapseML/v0.11.2?labpath=notebooks%2Ffeatures) |
|
||||
<!-- markdownlint-disable MD033 -->
|
||||
<details open>
|
||||
<summary>
|
||||
|
|
@ -94,7 +94,7 @@ In Azure Synapse notebooks please place the following in the first cell of your
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2-spark3.3",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -110,7 +110,7 @@ In Azure Synapse notebooks please place the following in the first cell of your
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -130,7 +130,7 @@ cloud](http://community.cloud.databricks.com), create a new [library from Maven
|
|||
coordinates](https://docs.databricks.com/user-guide/libraries.html#libraries-from-maven-pypi-or-spark-packages)
|
||||
in your workspace.
|
||||
|
||||
For the coordinates use: `com.microsoft.azure:synapseml_2.12:0.11.1`
|
||||
For the coordinates use: `com.microsoft.azure:synapseml_2.12:0.11.2`
|
||||
with the resolver: `https://mmlspark.azureedge.net/maven`. Ensure this library is
|
||||
attached to your target cluster(s).
|
||||
|
||||
|
|
@ -138,7 +138,7 @@ Finally, ensure that your Spark cluster has at least Spark 3.2 and Scala 2.12. I
|
|||
|
||||
You can use SynapseML in both your Scala and PySpark notebooks. To get started with our example notebooks import the following databricks archive:
|
||||
|
||||
`https://mmlspark.blob.core.windows.net/dbcs/SynapseMLExamplesv0.11.1.dbc`
|
||||
`https://mmlspark.blob.core.windows.net/dbcs/SynapseMLExamplesv0.11.2.dbc`
|
||||
|
||||
### Microsoft Fabric
|
||||
|
||||
|
|
@ -151,7 +151,7 @@ In Microsoft Fabric notebooks please place the following in the first cell of yo
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2-spark3.3",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -167,7 +167,7 @@ In Microsoft Fabric notebooks please place the following in the first cell of yo
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -186,7 +186,7 @@ the above example, or from python:
|
|||
```python
|
||||
import pyspark
|
||||
spark = pyspark.sql.SparkSession.builder.appName("MyApp") \
|
||||
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.1") \
|
||||
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.2") \
|
||||
.getOrCreate()
|
||||
import synapse.ml
|
||||
```
|
||||
|
|
@ -197,9 +197,9 @@ SynapseML can be conveniently installed on existing Spark clusters via the
|
|||
`--packages` option, examples:
|
||||
|
||||
```bash
|
||||
spark-shell --packages com.microsoft.azure:synapseml_2.12:0.11.1
|
||||
pyspark --packages com.microsoft.azure:synapseml_2.12:0.11.1
|
||||
spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.1 MyApp.jar
|
||||
spark-shell --packages com.microsoft.azure:synapseml_2.12:0.11.2
|
||||
pyspark --packages com.microsoft.azure:synapseml_2.12:0.11.2
|
||||
spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.2 MyApp.jar
|
||||
```
|
||||
|
||||
### SBT
|
||||
|
|
@ -208,7 +208,7 @@ If you are building a Spark application in Scala, add the following lines to
|
|||
your `build.sbt`:
|
||||
|
||||
```scala
|
||||
libraryDependencies += "com.microsoft.azure" % "synapseml_2.12" % "0.11.1"
|
||||
libraryDependencies += "com.microsoft.azure" % "synapseml_2.12" % "0.11.2"
|
||||
```
|
||||
|
||||
### Apache Livy and HDInsight
|
||||
|
|
@ -222,7 +222,7 @@ Excluding certain packages from the library may be necessary due to current issu
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind"
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -220,7 +220,7 @@ publishDotnetBase := {
|
|||
packDotnetAssemblyCmd(join(dotnetBaseDir, "target").getAbsolutePath, dotnetBaseDir)
|
||||
val packagePath = join(dotnetBaseDir,
|
||||
// Update the version whenever there's a new release
|
||||
"target", s"SynapseML.DotnetBase.${dotnetedVersion("0.11.1")}.nupkg").getAbsolutePath
|
||||
"target", s"SynapseML.DotnetBase.${dotnetedVersion("0.11.2")}.nupkg").getAbsolutePath
|
||||
publishDotnetAssemblyCmd(packagePath, genSleetConfig.value)
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@
|
|||
<IsPackable>true</IsPackable>
|
||||
|
||||
<Description>SynapseML .NET Base</Description>
|
||||
<Version>0.11.1</Version>
|
||||
<Version>0.11.2</Version>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
|
|
|
|||
|
|
@ -53,7 +53,7 @@ object DotnetCodegen {
|
|||
|
|
||||
| <ItemGroup>
|
||||
| <PackageReference Include="Microsoft.Spark" Version="2.1.1" />
|
||||
| <PackageReference Include="SynapseML.DotnetBase" Version="0.11.1" />
|
||||
| <PackageReference Include="SynapseML.DotnetBase" Version="0.11.2" />
|
||||
| <PackageReference Include="IgnoresAccessChecksToGenerator" Version="0.4.0" PrivateAssets="All" />
|
||||
| $newtonsoftDep
|
||||
| </ItemGroup>
|
||||
|
|
|
|||
|
|
@ -89,7 +89,7 @@ object DotnetTestGen {
|
|||
| <IncludeAssets>runtime; build; native; contentfiles; analyzers</IncludeAssets>
|
||||
| </PackageReference>
|
||||
| <PackageReference Include="Microsoft.Spark" Version="2.1.1" />
|
||||
| <PackageReference Include="SynapseML.DotnetBase" Version="0.11.1" />
|
||||
| <PackageReference Include="SynapseML.DotnetBase" Version="0.11.2" />
|
||||
| <PackageReference Include="SynapseML.DotnetE2ETest" Version="${conf.dotnetVersion}" />
|
||||
| <PackageReference Include="SynapseML.$curProject" Version="${conf.dotnetVersion}" />
|
||||
| $referenceCore
|
||||
|
|
|
|||
|
|
@ -15,66 +15,66 @@
|
|||
"\n",
|
||||
"### Vision\n",
|
||||
"[**Computer Vision**](https://azure.microsoft.com/services/cognitive-services/computer-vision/)\n",
|
||||
"- Describe: provides description of an image in human readable language ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/vision/DescribeImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.DescribeImage))\n",
|
||||
"- Analyze (color, image type, face, adult/racy content): analyzes visual features of an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/vision/AnalyzeImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.AnalyzeImage))\n",
|
||||
"- OCR: reads text from an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/vision/OCR.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.OCR))\n",
|
||||
"- Recognize Text: reads text from an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/vision/RecognizeText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.RecognizeText))\n",
|
||||
"- Thumbnail: generates a thumbnail of user-specified size from the image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/vision/GenerateThumbnails.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.GenerateThumbnails))\n",
|
||||
"- Recognize domain-specific content: recognizes domain-specific content (celebrity, landmark) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/vision/RecognizeDomainSpecificContent.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.RecognizeDomainSpecificContent))\n",
|
||||
"- Tag: identifies list of words that are relevant to the input image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/vision/TagImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.TagImage))\n",
|
||||
"- Describe: provides description of an image in human readable language ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/DescribeImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.DescribeImage))\n",
|
||||
"- Analyze (color, image type, face, adult/racy content): analyzes visual features of an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/AnalyzeImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.AnalyzeImage))\n",
|
||||
"- OCR: reads text from an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/OCR.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.OCR))\n",
|
||||
"- Recognize Text: reads text from an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/RecognizeText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.RecognizeText))\n",
|
||||
"- Thumbnail: generates a thumbnail of user-specified size from the image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/GenerateThumbnails.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.GenerateThumbnails))\n",
|
||||
"- Recognize domain-specific content: recognizes domain-specific content (celebrity, landmark) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/RecognizeDomainSpecificContent.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.RecognizeDomainSpecificContent))\n",
|
||||
"- Tag: identifies list of words that are relevant to the input image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/TagImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.TagImage))\n",
|
||||
"\n",
|
||||
"[**Face**](https://azure.microsoft.com/services/cognitive-services/face/)\n",
|
||||
"- Detect: detects human faces in an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/face/DetectFace.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.DetectFace))\n",
|
||||
"- Verify: verifies whether two faces belong to a same person, or a face belongs to a person ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/face/VerifyFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.VerifyFaces))\n",
|
||||
"- Identify: finds the closest matches of the specific query person face from a person group ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/face/IdentifyFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.IdentifyFaces))\n",
|
||||
"- Find similar: finds similar faces to the query face in a face list ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/face/FindSimilarFace.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.FindSimilarFace))\n",
|
||||
"- Group: divides a group of faces into disjoint groups based on similarity ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/face/GroupFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.GroupFaces))\n",
|
||||
"- Detect: detects human faces in an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/DetectFace.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.DetectFace))\n",
|
||||
"- Verify: verifies whether two faces belong to a same person, or a face belongs to a person ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/VerifyFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.VerifyFaces))\n",
|
||||
"- Identify: finds the closest matches of the specific query person face from a person group ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/IdentifyFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.IdentifyFaces))\n",
|
||||
"- Find similar: finds similar faces to the query face in a face list ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/FindSimilarFace.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.FindSimilarFace))\n",
|
||||
"- Group: divides a group of faces into disjoint groups based on similarity ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/GroupFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.GroupFaces))\n",
|
||||
"\n",
|
||||
"### Speech\n",
|
||||
"[**Speech Services**](https://azure.microsoft.com/services/cognitive-services/speech-services/)\n",
|
||||
"- Speech-to-text: transcribes audio streams ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/speech/SpeechToText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.SpeechToText))\n",
|
||||
"- Conversation Transcription: transcribes audio streams into live transcripts with identified speakers. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/speech/ConversationTranscription.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.ConversationTranscription))\n",
|
||||
"- Text to Speech: Converts text to realistic audio ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/speech/TextToSpeech.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.TextToSpeech))\n",
|
||||
"- Speech-to-text: transcribes audio streams ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/speech/SpeechToText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.SpeechToText))\n",
|
||||
"- Conversation Transcription: transcribes audio streams into live transcripts with identified speakers. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/speech/ConversationTranscription.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.ConversationTranscription))\n",
|
||||
"- Text to Speech: Converts text to realistic audio ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/speech/TextToSpeech.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.TextToSpeech))\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"### Language\n",
|
||||
"[**Text Analytics**](https://azure.microsoft.com/services/cognitive-services/text-analytics/)\n",
|
||||
"- Language detection: detects language of the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/text/LanguageDetector.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.LanguageDetector))\n",
|
||||
"- Key phrase extraction: identifies the key talking points in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/text/KeyPhraseExtractor.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.KeyPhraseExtractor))\n",
|
||||
"- Named entity recognition: identifies known entities and general named entities in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/text/NER.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.NER))\n",
|
||||
"- Sentiment analysis: returns a score between 0 and 1 indicating the sentiment in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/text/TextSentiment.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.TextSentiment))\n",
|
||||
"- Healthcare Entity Extraction: Extracts medical entities and relationships from text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/text/AnalyzeHealthText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.AnalyzeHealthText))\n",
|
||||
"- Language detection: detects language of the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/LanguageDetector.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.LanguageDetector))\n",
|
||||
"- Key phrase extraction: identifies the key talking points in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/KeyPhraseExtractor.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.KeyPhraseExtractor))\n",
|
||||
"- Named entity recognition: identifies known entities and general named entities in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/NER.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.NER))\n",
|
||||
"- Sentiment analysis: returns a score between 0 and 1 indicating the sentiment in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/TextSentiment.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.TextSentiment))\n",
|
||||
"- Healthcare Entity Extraction: Extracts medical entities and relationships from text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/AnalyzeHealthText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.AnalyzeHealthText))\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"### Translation\n",
|
||||
"[**Translator**](https://azure.microsoft.com/services/cognitive-services/translator/)\n",
|
||||
"- Translate: Translates text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Translate.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Translate))\n",
|
||||
"- Transliterate: Converts text in one language from one script to another script. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Transliterate.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Transliterate))\n",
|
||||
"- Detect: Identifies the language of a piece of text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Detect.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Detect))\n",
|
||||
"- BreakSentence: Identifies the positioning of sentence boundaries in a piece of text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/translate/BreakSentence.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.BreakSentence))\n",
|
||||
"- Dictionary Lookup: Provides alternative translations for a word and a small number of idiomatic phrases. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DictionaryLookup.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DictionaryLookup))\n",
|
||||
"- Dictionary Examples: Provides examples that show how terms in the dictionary are used in context. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DictionaryExamples.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DictionaryExamples))\n",
|
||||
"- Document Translation: Translates documents across all supported languages and dialects while preserving document structure and data format. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DocumentTranslator.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DocumentTranslator))\n",
|
||||
"- Translate: Translates text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Translate.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Translate))\n",
|
||||
"- Transliterate: Converts text in one language from one script to another script. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Transliterate.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Transliterate))\n",
|
||||
"- Detect: Identifies the language of a piece of text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Detect.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Detect))\n",
|
||||
"- BreakSentence: Identifies the positioning of sentence boundaries in a piece of text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/BreakSentence.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.BreakSentence))\n",
|
||||
"- Dictionary Lookup: Provides alternative translations for a word and a small number of idiomatic phrases. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DictionaryLookup.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DictionaryLookup))\n",
|
||||
"- Dictionary Examples: Provides examples that show how terms in the dictionary are used in context. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DictionaryExamples.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DictionaryExamples))\n",
|
||||
"- Document Translation: Translates documents across all supported languages and dialects while preserving document structure and data format. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DocumentTranslator.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DocumentTranslator))\n",
|
||||
"\n",
|
||||
"### Form Recognizer\n",
|
||||
"[**Form Recognizer**](https://azure.microsoft.com/services/form-recognizer/)\n",
|
||||
"- Analyze Layout: Extract text and layout information from a given document. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeLayout.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeLayout))\n",
|
||||
"- Analyze Receipts: Detects and extracts data from receipts using optical character recognition (OCR) and our receipt model, enabling you to easily extract structured data from receipts such as merchant name, merchant phone number, transaction date, transaction total, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeReceipts.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeReceipts))\n",
|
||||
"- Analyze Business Cards: Detects and extracts data from business cards using optical character recognition (OCR) and our business card model, enabling you to easily extract structured data from business cards such as contact names, company names, phone numbers, emails, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeBusinessCards.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeBusinessCards))\n",
|
||||
"- Analyze Invoices: Detects and extracts data from invoices using optical character recognition (OCR) and our invoice understanding deep learning models, enabling you to easily extract structured data from invoices such as customer, vendor, invoice ID, invoice due date, total, invoice amount due, tax amount, ship to, bill to, line items and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeInvoices.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeInvoices))\n",
|
||||
"- Analyze ID Documents: Detects and extracts data from identification documents using optical character recognition (OCR) and our ID document model, enabling you to easily extract structured data from ID documents such as first name, last name, date of birth, document number, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeIDDocuments.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeIDDocuments))\n",
|
||||
"- Analyze Custom Form: Extracts information from forms (PDFs and images) into structured data based on a model created from a set of representative training forms. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeCustomModel.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeCustomModel))\n",
|
||||
"- Get Custom Model: Get detailed information about a custom model. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/GetCustomModel.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/ListCustomModels.html))\n",
|
||||
"- List Custom Models: Get information about all custom models. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/form/ListCustomModels.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.ListCustomModels))\n",
|
||||
"- Analyze Layout: Extract text and layout information from a given document. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeLayout.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeLayout))\n",
|
||||
"- Analyze Receipts: Detects and extracts data from receipts using optical character recognition (OCR) and our receipt model, enabling you to easily extract structured data from receipts such as merchant name, merchant phone number, transaction date, transaction total, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeReceipts.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeReceipts))\n",
|
||||
"- Analyze Business Cards: Detects and extracts data from business cards using optical character recognition (OCR) and our business card model, enabling you to easily extract structured data from business cards such as contact names, company names, phone numbers, emails, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeBusinessCards.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeBusinessCards))\n",
|
||||
"- Analyze Invoices: Detects and extracts data from invoices using optical character recognition (OCR) and our invoice understanding deep learning models, enabling you to easily extract structured data from invoices such as customer, vendor, invoice ID, invoice due date, total, invoice amount due, tax amount, ship to, bill to, line items and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeInvoices.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeInvoices))\n",
|
||||
"- Analyze ID Documents: Detects and extracts data from identification documents using optical character recognition (OCR) and our ID document model, enabling you to easily extract structured data from ID documents such as first name, last name, date of birth, document number, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeIDDocuments.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeIDDocuments))\n",
|
||||
"- Analyze Custom Form: Extracts information from forms (PDFs and images) into structured data based on a model created from a set of representative training forms. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeCustomModel.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeCustomModel))\n",
|
||||
"- Get Custom Model: Get detailed information about a custom model. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/GetCustomModel.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/ListCustomModels.html))\n",
|
||||
"- List Custom Models: Get information about all custom models. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/ListCustomModels.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.ListCustomModels))\n",
|
||||
"\n",
|
||||
"### Decision\n",
|
||||
"[**Anomaly Detector**](https://azure.microsoft.com/services/cognitive-services/anomaly-detector/)\n",
|
||||
"- Anomaly status of latest point: generates a model using preceding points and determines whether the latest point is anomalous ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/anomaly/DetectLastAnomaly.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.anomaly.html#module-synapse.ml.cognitive.anomaly.DetectLastAnomaly))\n",
|
||||
"- Find anomalies: generates a model using an entire series and finds anomalies in the series ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/anomaly/DetectAnomalies.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.anomaly.html#module-synapse.ml.cognitive.anomaly.DetectAnomalies))\n",
|
||||
"- Anomaly status of latest point: generates a model using preceding points and determines whether the latest point is anomalous ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/anomaly/DetectLastAnomaly.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.anomaly.html#module-synapse.ml.cognitive.anomaly.DetectLastAnomaly))\n",
|
||||
"- Find anomalies: generates a model using an entire series and finds anomalies in the series ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/anomaly/DetectAnomalies.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.anomaly.html#module-synapse.ml.cognitive.anomaly.DetectAnomalies))\n",
|
||||
"\n",
|
||||
"### Search\n",
|
||||
"- [Bing Image search](https://azure.microsoft.com/services/cognitive-services/bing-image-search-api/) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/bing/BingImageSearch.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.bing.html#module-synapse.ml.cognitive.bing.BingImageSearch))\n",
|
||||
"- [Azure Cognitive search](https://docs.microsoft.com/azure/search/search-what-is-azure-search) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/com/microsoft/azure/synapse/ml/cognitive/search/AzureSearchWriter$.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cognitive.search.html#module-synapse.ml.cognitive.search.AzureSearchWriter))"
|
||||
"- [Bing Image search](https://azure.microsoft.com/services/cognitive-services/bing-image-search-api/) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/bing/BingImageSearch.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.bing.html#module-synapse.ml.cognitive.bing.BingImageSearch))\n",
|
||||
"- [Azure Cognitive search](https://docs.microsoft.com/azure/search/search-what-is-azure-search) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/search/AzureSearchWriter$.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.search.html#module-synapse.ml.cognitive.search.AzureSearchWriter))"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
|
|||
|
|
@ -35,7 +35,7 @@
|
|||
"# Create an Azure Databricks cluster and install the following libs\n",
|
||||
"\n",
|
||||
"1. In Cluster Libraries install from library source Maven:\n",
|
||||
"Coordinates: com.microsoft.azure:synapseml_2.12:0.11.1\n",
|
||||
"Coordinates: com.microsoft.azure:synapseml_2.12:0.11.2\n",
|
||||
"Repository: https://mmlspark.azureedge.net/maven\n",
|
||||
"\n",
|
||||
"2. In Cluster Libraries install from PyPI the library called plotly"
|
||||
|
|
|
|||
|
|
@ -15,15 +15,15 @@
|
|||
"\n",
|
||||
"This sample demonstrates the use of several members of the synapseml library:\n",
|
||||
"- [`TrainRegressor`\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.train.html?#module-synapse.ml.train.TrainRegressor)\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.train.html?#module-synapse.ml.train.TrainRegressor)\n",
|
||||
"- [`SummarizeData`\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.stages.html?#module-synapse.ml.stages.SummarizeData)\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.stages.html?#module-synapse.ml.stages.SummarizeData)\n",
|
||||
"- [`CleanMissingData`\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.featurize.html?#module-synapse.ml.featurize.CleanMissingData)\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.featurize.html?#module-synapse.ml.featurize.CleanMissingData)\n",
|
||||
"- [`ComputeModelStatistics`\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.train.html?#module-synapse.ml.train.ComputeModelStatistics)\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.train.html?#module-synapse.ml.train.ComputeModelStatistics)\n",
|
||||
"- [`FindBestModel`\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.automl.html?#module-synapse.ml.automl.FindBestModel)\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.automl.html?#module-synapse.ml.automl.FindBestModel)\n",
|
||||
"\n",
|
||||
"First, import the pandas package so that we can read and parse the datafile\n",
|
||||
"using `pandas.read_csv()`"
|
||||
|
|
|
|||
|
|
@ -16,11 +16,11 @@
|
|||
"\n",
|
||||
"This sample demonstrates how to use the following APIs:\n",
|
||||
"- [`TrainRegressor`\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.train.html?#module-synapse.ml.train.TrainRegressor)\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.train.html?#module-synapse.ml.train.TrainRegressor)\n",
|
||||
"- [`ComputePerInstanceStatistics`\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.train.html?#module-synapse.ml.train.ComputePerInstanceStatistics)\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.train.html?#module-synapse.ml.train.ComputePerInstanceStatistics)\n",
|
||||
"- [`DataConversion`\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.featurize.html?#module-synapse.ml.featurize.DataConversion)\n",
|
||||
" ](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.featurize.html?#module-synapse.ml.featurize.DataConversion)\n",
|
||||
"\n",
|
||||
"First, import the pandas package"
|
||||
]
|
||||
|
|
|
|||
2
start
2
start
|
|
@ -3,7 +3,7 @@
|
|||
export OPENMPI_VERSION="3.1.2"
|
||||
export SPARK_VERSION="3.2.3"
|
||||
export HADOOP_VERSION="2.7"
|
||||
export SYNAPSEML_VERSION="0.11.1" # Binder compatibility version
|
||||
export SYNAPSEML_VERSION="0.11.2" # Binder compatibility version
|
||||
|
||||
echo "Beginning Spark Session..."
|
||||
exec "$@"
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
FROM mcr.microsoft.com/oss/mirror/docker.io/library/ubuntu:20.04
|
||||
|
||||
ARG SYNAPSEML_VERSION=0.11.1
|
||||
ARG SYNAPSEML_VERSION=0.11.2
|
||||
ARG DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
ENV SPARK_VERSION=3.2.3
|
||||
|
|
|
|||
|
|
@ -15,9 +15,9 @@ docker build . --build-arg SYNAPSEML_VERSION=<YOUR-VERSION-HERE> -f tools/docker
|
|||
|
||||
eg.
|
||||
|
||||
For building image with SynapseML version 0.11.1, run:
|
||||
For building image with SynapseML version 0.11.2, run:
|
||||
```
|
||||
docker build . --build-arg SYNAPSEML_VERSION=0.11.1 -f tools/docker/demo/Dockerfile -t synapseml:0.11.1
|
||||
docker build . --build-arg SYNAPSEML_VERSION=0.11.2 -f tools/docker/demo/Dockerfile -t synapseml:0.11.2
|
||||
```
|
||||
|
||||
# Run the image
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ syanpseMLConf = pyspark.SparkConf().setAll(
|
|||
(
|
||||
"spark.jars.packages",
|
||||
"com.microsoft.azure:synapseml_2.12:"
|
||||
+ os.getenv("SYNAPSEML_VERSION", "0.11.1")
|
||||
+ os.getenv("SYNAPSEML_VERSION", "0.11.2")
|
||||
+ ",org.apache.hadoop:hadoop-azure:2.7.0,org.apache.hadoop:hadoop-common:2.7.0,com.microsoft.azure:azure-storage:2.0.0",
|
||||
),
|
||||
(
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
FROM mcr.microsoft.com/oss/mirror/docker.io/library/ubuntu:20.04
|
||||
|
||||
ARG SYNAPSEML_VERSION=0.11.1
|
||||
ARG SYNAPSEML_VERSION=0.11.2
|
||||
ARG DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
ENV SPARK_VERSION=3.2.3
|
||||
|
|
|
|||
|
|
@ -25,8 +25,8 @@ submillisecond latency web services, backed by your Spark cluster.
|
|||
|
||||
SynapseML requires Scala 2.12, Spark 3.2+, and Python 3.8+.
|
||||
See the API documentation [for
|
||||
Scala](https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/index.html#package) and [for
|
||||
PySpark](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/index.html).
|
||||
Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/index.html#package) and [for
|
||||
PySpark](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/index.html).
|
||||
|
||||
import Link from '@docusaurus/Link';
|
||||
|
||||
|
|
|
|||
|
|
@ -21,12 +21,12 @@ Restarting the cluster automatically installs horovod v0.25.0 with pytorch_light
|
|||
You could install the single synapseml-deep-learning wheel package to get the full functionality of deep vision classification.
|
||||
Run the following command:
|
||||
```powershell
|
||||
pip install synapseml==0.11.1
|
||||
pip install synapseml==0.11.2
|
||||
```
|
||||
|
||||
An alternative is installing the SynapseML jar package in library management section, by adding:
|
||||
```
|
||||
Coordinate: com.microsoft.azure:synapseml_2.12:0.11.1
|
||||
Coordinate: com.microsoft.azure:synapseml_2.12:0.11.2
|
||||
Repository: https://mmlspark.azureedge.net/maven
|
||||
```
|
||||
:::note
|
||||
|
|
|
|||
|
|
@ -13,8 +13,8 @@ Make sure you have followed the guidance in [.NET installation](../reference/dot
|
|||
Install NuGet packages by running following command:
|
||||
```powershell
|
||||
dotnet add package Microsoft.Spark --version 2.1.1
|
||||
dotnet add package SynapseML.Lightgbm --version 0.11.1
|
||||
dotnet add package SynapseML.Core --version 0.11.1
|
||||
dotnet add package SynapseML.Lightgbm --version 0.11.2
|
||||
dotnet add package SynapseML.Core --version 0.11.2
|
||||
```
|
||||
|
||||
Use the following code in your main program file:
|
||||
|
|
@ -91,7 +91,7 @@ namespace SynapseMLApp
|
|||
|
||||
Run `dotnet build` to build the project. Then navigate to build output directory, and run following command:
|
||||
```powershell
|
||||
spark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner --packages com.microsoft.azure:synapseml_2.12:0.11.1,org.apache.hadoop:hadoop-azure:3.3.1 --master local microsoft-spark-3-2_2.12-2.1.1.jar dotnet SynapseMLApp.dll
|
||||
spark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner --packages com.microsoft.azure:synapseml_2.12:0.11.2,org.apache.hadoop:hadoop-azure:3.3.1 --master local microsoft-spark-3-2_2.12-2.1.1.jar dotnet SynapseMLApp.dll
|
||||
```
|
||||
:::note
|
||||
Here we added two packages: synapseml_2.12 for SynapseML's scala source, and hadoop-azure to support reading files from ADLS.
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ For Spark3.2 pool:
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -30,7 +30,7 @@ For Spark3.3 pool:
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2-spark3.3",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -47,8 +47,8 @@ installed via pip with `pip install pyspark`.
|
|||
```python
|
||||
import pyspark
|
||||
spark = pyspark.sql.SparkSession.builder.appName("MyApp") \
|
||||
# Use 0.11.1-spark3.3 version for Spark3.3 and 0.11.1 version for Spark3.2
|
||||
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.1") \
|
||||
# Use 0.11.2-spark3.3 version for Spark3.3 and 0.11.2 version for Spark3.2
|
||||
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.2") \
|
||||
.config("spark.jars.repositories", "https://mmlspark.azureedge.net/maven") \
|
||||
.getOrCreate()
|
||||
import synapse.ml
|
||||
|
|
@ -61,8 +61,8 @@ your `build.sbt`:
|
|||
|
||||
```scala
|
||||
resolvers += "SynapseML" at "https://mmlspark.azureedge.net/maven"
|
||||
// Use 0.11.1 version for Spark3.2 and 0.11.1-spark3.3 for Spark3.3
|
||||
libraryDependencies += "com.microsoft.azure" % "synapseml_2.12" % "0.11.1"
|
||||
// Use 0.11.2 version for Spark3.2 and 0.11.2-spark3.3 for Spark3.3
|
||||
libraryDependencies += "com.microsoft.azure" % "synapseml_2.12" % "0.11.2"
|
||||
```
|
||||
|
||||
## Spark package
|
||||
|
|
@ -71,10 +71,10 @@ SynapseML can be conveniently installed on existing Spark clusters via the
|
|||
`--packages` option, examples:
|
||||
|
||||
```bash
|
||||
# Please use 0.11.1-spark3.3 version for Spark3.3 and 0.11.1 version for Spark3.2
|
||||
spark-shell --packages com.microsoft.azure:synapseml_2.12:0.11.1
|
||||
pyspark --packages com.microsoft.azure:synapseml_2.12:0.11.1
|
||||
spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.1 MyApp.jar
|
||||
# Please use 0.11.2-spark3.3 version for Spark3.3 and 0.11.2 version for Spark3.2
|
||||
spark-shell --packages com.microsoft.azure:synapseml_2.12:0.11.2
|
||||
pyspark --packages com.microsoft.azure:synapseml_2.12:0.11.2
|
||||
spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.2 MyApp.jar
|
||||
```
|
||||
|
||||
A similar technique can be used in other Spark contexts too. For example, you can use SynapseML
|
||||
|
|
@ -89,8 +89,8 @@ cloud](http://community.cloud.databricks.com), create a new [library from Maven
|
|||
coordinates](https://docs.databricks.com/user-guide/libraries.html#libraries-from-maven-pypi-or-spark-packages)
|
||||
in your workspace.
|
||||
|
||||
For the coordinates use: `com.microsoft.azure:synapseml_2.12:0.11.1` for Spark3.2 Cluster and
|
||||
`com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3` for Spark3.3 Cluster;
|
||||
For the coordinates use: `com.microsoft.azure:synapseml_2.12:0.11.2` for Spark3.2 Cluster and
|
||||
`com.microsoft.azure:synapseml_2.12:0.11.2-spark3.3` for Spark3.3 Cluster;
|
||||
Add the resolver: `https://mmlspark.azureedge.net/maven`. Ensure this library is
|
||||
attached to your target cluster(s).
|
||||
|
||||
|
|
@ -98,7 +98,7 @@ Finally, ensure that your Spark cluster has at least Spark 3.2 and Scala 2.12.
|
|||
|
||||
You can use SynapseML in both your Scala and PySpark notebooks. To get started with our example notebooks, import the following databricks archive:
|
||||
|
||||
`https://mmlspark.blob.core.windows.net/dbcs/SynapseMLExamplesv0.11.1.dbc`
|
||||
`https://mmlspark.blob.core.windows.net/dbcs/SynapseMLExamplesv0.11.2.dbc`
|
||||
|
||||
## Microsoft Fabric
|
||||
|
||||
|
|
@ -111,7 +111,7 @@ In Microsoft Fabric notebooks please place the following in the first cell of yo
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -128,7 +128,7 @@ In Microsoft Fabric notebooks please place the following in the first cell of yo
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2-spark3.3",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -148,8 +148,8 @@ Excluding certain packages from the library may be necessary due to current issu
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
# Please use 0.11.1 version for Spark3.2 and 0.11.1-spark3.3 version for Spark3.3
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1",
|
||||
# Please use 0.11.2 version for Spark3.2 and 0.11.2-spark3.3 version for Spark3.3
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind"
|
||||
}
|
||||
}
|
||||
|
|
@ -162,8 +162,8 @@ In Azure Synapse, "spark.yarn.user.classpath.first" should be set to "true" to o
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
# Please use 0.11.1 version for Spark3.2 and 0.11.1-spark3.3 version for Spark3.3
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1",
|
||||
# Please use 0.11.2 version for Spark3.2 and 0.11.2-spark3.3 version for Spark3.3
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -55,7 +55,7 @@ Installing all dependencies may be time-consuming. When complete, run:
|
|||
library(sparklyr)
|
||||
library(dplyr)
|
||||
config <- spark_config()
|
||||
config$sparklyr.defaultPackages <- "com.microsoft.azure:synapseml_2.12:0.11.1"
|
||||
config$sparklyr.defaultPackages <- "com.microsoft.azure:synapseml_2.12:0.11.2"
|
||||
sc <- spark_connect(master = "local", config = config)
|
||||
...
|
||||
```
|
||||
|
|
@ -120,7 +120,7 @@ and then use spark_connect with method = "databricks":
|
|||
|
||||
```R
|
||||
install.packages("devtools")
|
||||
devtools::install_url("https://mmlspark.azureedge.net/rrr/synapseml-0.11.1.zip")
|
||||
devtools::install_url("https://mmlspark.azureedge.net/rrr/synapseml-0.11.2.zip")
|
||||
library(sparklyr)
|
||||
library(dplyr)
|
||||
sc <- spark_connect(method = "databricks")
|
||||
|
|
|
|||
|
|
@ -18,50 +18,50 @@ sidebar_label: CyberML
|
|||
In other words, it returns a sample from the complement set.
|
||||
|
||||
## feature engineering: [indexers.py](https://github.com/microsoft/SynapseML/blob/master/core/src/main/python/synapse/ml/cyber/feature/indexers.py)
|
||||
1. [IdIndexer](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.indexers.IdIndexer)
|
||||
1. [IdIndexer](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.indexers.IdIndexer)
|
||||
is a SparkML [Estimator](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Estimator.html).
|
||||
Given a dataframe, it creates an IdIndexerModel (described next) for categorical features. The model
|
||||
maps each partition and column seen in the given dataframe to an ID,
|
||||
for each partition or one consecutive range for all partition and column values.
|
||||
2. [IdIndexerModel](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.indexers.IdIndexerModel)
|
||||
2. [IdIndexerModel](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.indexers.IdIndexerModel)
|
||||
is a SparkML [Transformer](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Transformer.html).
|
||||
Given a dataframe maps each partition and column field to a consecutive integer ID.
|
||||
Partitions or column values not encountered in the estimator are mapped to 0.
|
||||
The model can operate in two modes, either create consecutive integer ID independently
|
||||
3. [MultiIndexer](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.indexers.MultiIndexer)
|
||||
3. [MultiIndexer](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.indexers.MultiIndexer)
|
||||
is a SparkML [Estimator](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Estimator.html).
|
||||
Uses multiple IdIndexers to generate a MultiIndexerModel (described next) for categorical features. The model
|
||||
contains multiple IdIndexers for multiple partitions and columns.
|
||||
4. [MultiIndexerModel](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.indexers.MultiIndexerModel)
|
||||
4. [MultiIndexerModel](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.indexers.MultiIndexerModel)
|
||||
is a SparkML [Transformer](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Transformer.html).
|
||||
Given a dataframe maps each partition and column field to a consecutive integer ID.
|
||||
Partitions or column values not encountered in the estimator are mapped to 0.
|
||||
The model can operate in two modes, either create consecutive integer ID independently
|
||||
|
||||
## feature engineering: [scalers.py](https://github.com/microsoft/SynapseML/blob/master/core/src/main/python/synapse/ml/cyber/feature/scalers.py)
|
||||
1. [StandardScalarScaler](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.scalers.StandardScalarScaler)
|
||||
1. [StandardScalarScaler](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.scalers.StandardScalarScaler)
|
||||
is a SparkML [Estimator](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Estimator.html).
|
||||
Given a dataframe it creates a StandardScalarScalerModel (described next) which normalizes
|
||||
any given dataframe according to the mean and standard deviation calculated on the
|
||||
dataframe given to the estimator.
|
||||
2. [StandardScalarScalerModel](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.scalers.StandardScalarScalerModel)
|
||||
2. [StandardScalarScalerModel](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.scalers.StandardScalarScalerModel)
|
||||
is a SparkML [Transformer](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Transformer.html).
|
||||
Given a dataframe with a value column x, the transformer changes its value as follows:
|
||||
x'=(x-mean)/stddev. That is, if the transformer is given the same dataframe the estimator
|
||||
was given then the value column will have a mean of 0.0 and a standard deviation of 1.0.
|
||||
3. [LinearScalarScaler](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.scalers.LinearScalarScaler)
|
||||
3. [LinearScalarScaler](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.scalers.LinearScalarScaler)
|
||||
is a SparkML [Estimator](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Estimator.html).
|
||||
Given a dataframe it creates a LinearScalarScalerModel (described next) which normalizes
|
||||
any given dataframe according to the minimum and maximum values calculated on the
|
||||
dataframe given to the estimator.
|
||||
4. [LinearScalarScalerModel](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.scalers.LinearScalarScalerModel)
|
||||
4. [LinearScalarScalerModel](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.feature.html#synapse.ml.cyber.feature.scalers.LinearScalarScalerModel)
|
||||
is a SparkML [Transformer](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Transformer.html).
|
||||
Given a dataframe with a value column x, the transformer changes its value such that
|
||||
if the transformer is given the same dataframe the estimator
|
||||
was given then the value column will be scaled linearly to the given ranges.
|
||||
|
||||
## access anomalies: [collaborative_filtering.py](https://github.com/microsoft/SynapseML/blob/master/core/src/main/python/synapse/ml/cyber/anomaly/collaborative_filtering.py)
|
||||
1. [AccessAnomaly](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.anomaly.html#synapse.ml.cyber.anomaly.collaborative_filtering.AccessAnomaly)
|
||||
1. [AccessAnomaly](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.anomaly.html#synapse.ml.cyber.anomaly.collaborative_filtering.AccessAnomaly)
|
||||
is a SparkML [Estimator](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Estimator.html).
|
||||
Given a dataframe, the estimator generates an AccessAnomalyModel (described next). The model
|
||||
can detect anomalous access of users to resources where the access
|
||||
|
|
@ -69,14 +69,14 @@ sidebar_label: CyberML
|
|||
a resource from Finance. This result is based solely on access patterns rather than explicit features.
|
||||
Internally, the code is based on Collaborative Filtering as implemented in Spark, using
|
||||
Matrix Factorization with Alternating Least Squares.
|
||||
2. [AccessAnomalyModel](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.anomaly.html#synapse.ml.cyber.anomaly.collaborative_filtering.AccessAnomalyModel)
|
||||
2. [AccessAnomalyModel](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.anomaly.html#synapse.ml.cyber.anomaly.collaborative_filtering.AccessAnomalyModel)
|
||||
is a SparkML [Transformer](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Transformer.html).
|
||||
Given a dataframe the transformer computes a value between (-inf, inf) where positive
|
||||
values indicate an anomaly score. Anomaly scores are computed to have a mean of 1.0
|
||||
and a standard deviation of 1.0 over the original dataframe given to the estimator.
|
||||
3. [ModelNormalizeTransformer](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.anomaly.html#synapse.ml.cyber.anomaly.collaborative_filtering.ModelNormalizeTransformer)
|
||||
3. [ModelNormalizeTransformer](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.anomaly.html#synapse.ml.cyber.anomaly.collaborative_filtering.ModelNormalizeTransformer)
|
||||
is a SparkML [Transformer](https://spark.apache.org/docs/2.2.0/api/java/index.html?org/apache/spark/ml/Transformer.html).
|
||||
This transformer is used internally by AccessAnomaly to normalize a model to generate
|
||||
anomaly scores with mean 0.0 and standard deviation of 1.0.
|
||||
4. [AccessAnomalyConfig](https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/synapse.ml.cyber.anomaly.html#synapse.ml.cyber.anomaly.collaborative_filtering.AccessAnomalyConfig)
|
||||
4. [AccessAnomalyConfig](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cyber.anomaly.html#synapse.ml.cyber.anomaly.collaborative_filtering.AccessAnomalyConfig)
|
||||
contains the default values for AccessAnomaly.
|
||||
|
|
|
|||
|
|
@ -32,7 +32,7 @@ You can now select one of the sample notebooks and run it, or create your own.
|
|||
In the preceding docker command, `mcr.microsoft.com/mmlspark/release` specifies the project and image name that you
|
||||
want to run. There's another component implicit here: the _tsag_ (=
|
||||
version) that you want to use. Specifying it explicitly looks like
|
||||
`mcr.microsoft.com/mmlspark/release:0.11.1` for the `0.11.1` tag.
|
||||
`mcr.microsoft.com/mmlspark/release:0.11.2` for the `0.11.2` tag.
|
||||
|
||||
Leaving `mcr.microsoft.com/mmlspark/release` by itself has an implicit `latest` tag, so it's
|
||||
equivalent to `mcr.microsoft.com/mmlspark/release:latest`. The `latest` tag is identical to the
|
||||
|
|
@ -48,7 +48,7 @@ that you'll probably want to use can look as follows:
|
|||
docker run -it --rm \
|
||||
-p 127.0.0.1:80:8888 \
|
||||
-v ~/myfiles:/notebooks/myfiles \
|
||||
mcr.microsoft.com/mmlspark/release:0.11.1
|
||||
mcr.microsoft.com/mmlspark/release:0.11.2
|
||||
```
|
||||
|
||||
In this example, backslashes are for readability; you
|
||||
|
|
@ -58,7 +58,7 @@ path and line breaks looks a little different:
|
|||
docker run -it --rm `
|
||||
-p 127.0.0.1:80:8888 `
|
||||
-v C:\myfiles:/notebooks/myfiles `
|
||||
mcr.microsoft.com/mmlspark/release:0.11.1
|
||||
mcr.microsoft.com/mmlspark/release:0.11.2
|
||||
|
||||
Let's break this command and go over the meaning of each part:
|
||||
|
||||
|
|
@ -141,7 +141,7 @@ Let's break this command and go over the meaning of each part:
|
|||
model.write().overwrite().save('myfiles/myTrainedModel.mml')
|
||||
```
|
||||
|
||||
- **`mcr.microsoft.com/mmlspark/release:0.11.1`**
|
||||
- **`mcr.microsoft.com/mmlspark/release:0.11.2`**
|
||||
|
||||
Finally, this argument specifies an explicit version tag for the image that we want to
|
||||
run.
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@ for a Windows x64 machine or jdk-8u231-macosx-x64.dmg for macOS. Then, use the c
|
|||
### 3. Install Apache Spark
|
||||
|
||||
[Download and install Apache Spark](https://spark.apache.org/downloads.html) with version >= 3.2.0.
|
||||
(SynapseML v0.11.1 only supports spark version >= 3.2.0)
|
||||
(SynapseML v0.11.2 only supports spark version >= 3.2.0)
|
||||
|
||||
Extract downloaded zipped files (with 7-Zip app on Windows or `tar` on linux) and remember the location of
|
||||
extracted files, we take `~/bin/spark-3.2.0-bin-hadoop3.2/` as an example here.
|
||||
|
|
@ -127,7 +127,7 @@ In your command prompt or terminal, run the following command:
|
|||
dotnet add package Microsoft.Spark --version 2.1.1
|
||||
```
|
||||
:::note
|
||||
This tutorial uses Microsoft.Spark version 2.1.1 as SynapseML 0.11.1 depends on it.
|
||||
This tutorial uses Microsoft.Spark version 2.1.1 as SynapseML 0.11.2 depends on it.
|
||||
Change to corresponding version if necessary.
|
||||
:::
|
||||
|
||||
|
|
@ -137,7 +137,7 @@ In your command prompt or terminal, run the following command:
|
|||
```powershell
|
||||
# Update Nuget Config to include SynapseML Feed
|
||||
dotnet nuget add source https://mmlspark.blob.core.windows.net/synapsemlnuget/index.json -n SynapseMLFeed
|
||||
dotnet add package SynapseML.Cognitive --version 0.11.1
|
||||
dotnet add package SynapseML.Cognitive --version 0.11.2
|
||||
```
|
||||
The `dotnet nuget add` command adds SynapseML's resolver to the source, so that our package can be found.
|
||||
|
||||
|
|
@ -202,7 +202,7 @@ namespace SynapseMLApp
|
|||
of Apache Spark applications, which manages the context and information of your application. A DataFrame is a way of organizing
|
||||
data into a set of named columns.
|
||||
|
||||
Create a [TextSentiment](https://mmlspark.blob.core.windows.net/docs/0.11.1/dotnet/classSynapse_1_1ML_1_1Cognitive_1_1TextSentiment.html)
|
||||
Create a [TextSentiment](https://mmlspark.blob.core.windows.net/docs/0.11.2/dotnet/classSynapse_1_1ML_1_1Cognitive_1_1TextSentiment.html)
|
||||
instance, set corresponding subscription key and other configurations. Then, apply transformation to the dataframe,
|
||||
which analyzes the sentiment based on each row, and stores result into output column.
|
||||
|
||||
|
|
@ -218,9 +218,9 @@ dotnet build
|
|||
Navigate to your build output directory. For example, in Windows you could run `cd bin\Debug\net5.0`.
|
||||
Use the spark-submit command to submit your application to run on Apache Spark.
|
||||
```powershell
|
||||
spark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner --packages com.microsoft.azure:synapseml_2.12:0.11.1 --master local microsoft-spark-3-2_2.12-2.1.1.jar dotnet SynapseMLApp.dll
|
||||
spark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner --packages com.microsoft.azure:synapseml_2.12:0.11.2 --master local microsoft-spark-3-2_2.12-2.1.1.jar dotnet SynapseMLApp.dll
|
||||
```
|
||||
`--packages com.microsoft.azure:synapseml_2.12:0.11.1` specifies the dependency on synapseml_2.12 version 0.11.1;
|
||||
`--packages com.microsoft.azure:synapseml_2.12:0.11.2` specifies the dependency on synapseml_2.12 version 0.11.2;
|
||||
`microsoft-spark-3-2_2.12-2.1.1.jar` specifies Microsoft.Spark version 2.1.1 and Spark version 3.2
|
||||
:::note
|
||||
This command assumes you have downloaded Apache Spark and added it to your PATH environment variable so that you can use spark-submit.
|
||||
|
|
@ -238,7 +238,7 @@ When your app runs, the sentiment analysis result is written to the console.
|
|||
+-----------------------------------------+--------+-----+--------------------------------------------------+
|
||||
```
|
||||
Congratulations! You successfully authored and ran a .NET for SynapseML app.
|
||||
Refer to the [developer docs](https://mmlspark.blob.core.windows.net/docs/0.11.1/dotnet/index.html) for API guidance.
|
||||
Refer to the [developer docs](https://mmlspark.blob.core.windows.net/docs/0.11.2/dotnet/index.html) for API guidance.
|
||||
|
||||
## Next
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@ const math = require('remark-math')
|
|||
const katex = require('rehype-katex')
|
||||
const path = require('path');
|
||||
const { all_examples } = require('./src/plugins/examples');
|
||||
let version = "0.11.1";
|
||||
let version = "0.11.2";
|
||||
|
||||
module.exports = {
|
||||
title: 'SynapseML',
|
||||
|
|
@ -15,7 +15,7 @@ module.exports = {
|
|||
trailingSlash: true,
|
||||
customFields: {
|
||||
examples: all_examples(),
|
||||
version: "0.11.1",
|
||||
version: "0.11.2",
|
||||
},
|
||||
stylesheets: [
|
||||
{
|
||||
|
|
@ -94,11 +94,11 @@ module.exports = {
|
|||
},
|
||||
{
|
||||
label: 'Python API Reference',
|
||||
to: 'https://mmlspark.blob.core.windows.net/docs/0.11.1/pyspark/index.html',
|
||||
to: 'https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/index.html',
|
||||
},
|
||||
{
|
||||
label: 'Scala API Reference',
|
||||
to: 'https://mmlspark.blob.core.windows.net/docs/0.11.1/scala/index.html',
|
||||
to: 'https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/index.html',
|
||||
},
|
||||
],
|
||||
},
|
||||
|
|
|
|||
|
|
@ -275,7 +275,7 @@ function Home() {
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2-spark3.3",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -290,7 +290,7 @@ function Home() {
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -309,7 +309,7 @@ function Home() {
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2-spark3.3",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -324,7 +324,7 @@ function Home() {
|
|||
{
|
||||
"name": "synapseml",
|
||||
"conf": {
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.2,org.apache.spark:spark-avro_2.12:3.3.1",
|
||||
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
|
||||
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
|
||||
"spark.yarn.user.classpath.first": "true",
|
||||
|
|
@ -339,9 +339,9 @@ function Home() {
|
|||
SynapseML can be conveniently installed on existing Spark
|
||||
clusters via the --packages option, examples:
|
||||
<CodeSnippet
|
||||
snippet={`spark-shell --packages com.microsoft.azure:synapseml_2.12:0.11.1 # Please use 0.11.1 version for Spark3.2 and 0.11.1-spark3.3 version for Spark3.3
|
||||
pyspark --packages com.microsoft.azure:synapseml_2.12:0.11.1
|
||||
spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.1 MyApp.jar `}
|
||||
snippet={`spark-shell --packages com.microsoft.azure:synapseml_2.12:0.11.2 # Please use 0.11.2 version for Spark3.2 and 0.11.2-spark3.3 version for Spark3.3
|
||||
pyspark --packages com.microsoft.azure:synapseml_2.12:0.11.2
|
||||
spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.2 MyApp.jar `}
|
||||
lang="bash"
|
||||
></CodeSnippet>
|
||||
This can be used in other Spark contexts too. For example, you
|
||||
|
|
@ -369,12 +369,12 @@ spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.1 MyApp.jar `}
|
|||
<p>For the coordinates:</p>
|
||||
Spark 3.3 Cluster:
|
||||
<CodeSnippet
|
||||
snippet={`com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3`}
|
||||
snippet={`com.microsoft.azure:synapseml_2.12:0.11.2-spark3.3`}
|
||||
lang="bash"
|
||||
></CodeSnippet>
|
||||
Spark 3.2 Cluster:
|
||||
<CodeSnippet
|
||||
snippet={`com.microsoft.azure:synapseml_2.12:0.11.1`}
|
||||
snippet={`com.microsoft.azure:synapseml_2.12:0.11.2`}
|
||||
lang="bash"
|
||||
></CodeSnippet>
|
||||
with the resolver:
|
||||
|
|
@ -392,7 +392,7 @@ spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.1 MyApp.jar `}
|
|||
notebooks. To get started with our example notebooks import
|
||||
the following databricks archive:
|
||||
<CodeSnippet
|
||||
snippet={`https://mmlspark.blob.core.windows.net/dbcs/SynapseMLExamplesv0.11.1.dbc`}
|
||||
snippet={`https://mmlspark.blob.core.windows.net/dbcs/SynapseMLExamplesv0.11.2.dbc`}
|
||||
lang="bash"
|
||||
></CodeSnippet>
|
||||
</TabItem>
|
||||
|
|
@ -430,7 +430,7 @@ spark-submit --packages com.microsoft.azure:synapseml_2.12:0.11.1 MyApp.jar `}
|
|||
<CodeSnippet
|
||||
snippet={`import pyspark
|
||||
spark = (pyspark.sql.SparkSession.builder.appName("MyApp")
|
||||
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.1") # Please use 0.11.1 version for Spark3.2 and 0.11.1-spark3.3 version for Spark3.3
|
||||
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.2") # Please use 0.11.2 version for Spark3.2 and 0.11.2-spark3.3 version for Spark3.3
|
||||
.config("spark.jars.repositories", "https://mmlspark.azureedge.net/maven")
|
||||
.getOrCreate())
|
||||
import synapse.ml`}
|
||||
|
|
@ -442,19 +442,19 @@ import synapse.ml`}
|
|||
following lines to your build.sbt:
|
||||
<CodeSnippet
|
||||
snippet={`resolvers += "SynapseML" at "https://mmlspark.azureedge.net/maven"
|
||||
libraryDependencies += "com.microsoft.azure" %% "synapseml_2.12" % "0.11.1" // Please use 0.11.1 version for Spark3.2 and 0.11.1-spark3.3 version for Spark3.3`}
|
||||
libraryDependencies += "com.microsoft.azure" %% "synapseml_2.12" % "0.11.2" // Please use 0.11.2 version for Spark3.2 and 0.11.2-spark3.3 version for Spark3.3`}
|
||||
lang="jsx"
|
||||
></CodeSnippet>
|
||||
</TabItem>
|
||||
<TabItem value="dotnet">
|
||||
To try out SynapseML with .NET, you should add SynapseML's assembly into reference:
|
||||
<CodeSnippet
|
||||
snippet={`dotnet add package SynapseML.Cognitive --version 0.11.1
|
||||
dotnet add package SynapseML.Core --version 0.11.1
|
||||
dotnet add package SynapseML.Lightgbm --version 0.11.1
|
||||
dotnet add package SynapseML.DeepLearning --version 0.11.1
|
||||
dotnet add package SynapseML.Opencv --version 0.11.1
|
||||
dotnet add package SynapseML.Vw --version 0.11.1`}
|
||||
snippet={`dotnet add package SynapseML.Cognitive --version 0.11.2
|
||||
dotnet add package SynapseML.Core --version 0.11.2
|
||||
dotnet add package SynapseML.Lightgbm --version 0.11.2
|
||||
dotnet add package SynapseML.DeepLearning --version 0.11.2
|
||||
dotnet add package SynapseML.Opencv --version 0.11.2
|
||||
dotnet add package SynapseML.Vw --version 0.11.2`}
|
||||
lang="bash"
|
||||
></CodeSnippet>
|
||||
For detailed installation, please refer this{" "}
|
||||
|
|
|
|||
|
|
@ -0,0 +1,55 @@
|
|||
---
|
||||
title: SynapseML
|
||||
sidebar_label: Introduction
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
import useBaseUrl from "@docusaurus/useBaseUrl";
|
||||
|
||||
<div style={{textAlign: 'left'}}><img src={useBaseUrl("/img/logo.svg")} /></div>
|
||||
|
||||
# SynapseML
|
||||
|
||||
SynapseML is an ecosystem of tools aimed towards expanding the distributed computing framework
|
||||
[Apache Spark](https://github.com/apache/spark) in several new directions.
|
||||
SynapseML adds many deep learning and data science tools to the Spark ecosystem,
|
||||
including seamless integration of Spark Machine Learning pipelines with [Microsoft Cognitive Toolkit
|
||||
(CNTK)](https://github.com/Microsoft/CNTK), [LightGBM](https://github.com/Microsoft/LightGBM) and
|
||||
[OpenCV](http://www.opencv.org/). These tools enable powerful and highly scalable predictive and analytical models
|
||||
for many types of datasources.
|
||||
|
||||
SynapseML also brings new networking capabilities to the Spark Ecosystem. With the HTTP on Spark project, users
|
||||
can embed **any** web service into their SparkML models. In this vein, SynapseML provides easy to use
|
||||
SparkML transformers for a wide variety of [Azure Cognitive Services](https://azure.microsoft.com/en-us/services/cognitive-services/). For production grade deployment, the Spark Serving project enables high throughput,
|
||||
submillisecond latency web services, backed by your Spark cluster.
|
||||
|
||||
SynapseML requires Scala 2.12, Spark 3.2+, and Python 3.8+.
|
||||
See the API documentation [for
|
||||
Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/index.html#package) and [for
|
||||
PySpark](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/index.html).
|
||||
|
||||
import Link from '@docusaurus/Link';
|
||||
|
||||
<Link to="/docs/getting_started/installation" className="button button--lg button--outline button--block button--primary">Get Started</Link>
|
||||
|
||||
## Examples
|
||||
|
||||
import NotebookExamples from "@theme/NotebookExamples";
|
||||
|
||||
<NotebookExamples/>
|
||||
|
||||
## Explore our Features
|
||||
|
||||
import FeatureCards from "@theme/FeatureCards";
|
||||
|
||||
<FeatureCards/>
|
||||
|
||||
## Papers
|
||||
|
||||
- [Large Scale Intelligent Microservices](https://arxiv.org/abs/2009.08044)
|
||||
|
||||
- [Conditional Image Retrieval](https://arxiv.org/abs/2007.07177)
|
||||
|
||||
- [SynapseML: Unifying Machine Learning Ecosystems at Massive Scales](https://arxiv.org/abs/1810.08744)
|
||||
|
||||
- [Flexible and Scalable Deep Learning with MMLSpark](https://arxiv.org/abs/1804.04031)
|
||||
|
|
@ -0,0 +1,164 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## LightGBMClassifier
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import *
|
||||
|
||||
lgbmClassifier = (LightGBMClassifier()
|
||||
.setFeaturesCol("features")
|
||||
.setRawPredictionCol("rawPrediction")
|
||||
.setDefaultListenPort(12402)
|
||||
.setNumLeaves(5)
|
||||
.setNumIterations(10)
|
||||
.setObjective("binary")
|
||||
.setLabelCol("labels")
|
||||
.setLeafPredictionCol("leafPrediction")
|
||||
.setFeaturesShapCol("featuresShap"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.lightgbm._
|
||||
|
||||
val lgbmClassifier = (new LightGBMClassifier()
|
||||
.setFeaturesCol("features")
|
||||
.setRawPredictionCol("rawPrediction")
|
||||
.setDefaultListenPort(12402)
|
||||
.setNumLeaves(5)
|
||||
.setNumIterations(10)
|
||||
.setObjective("binary")
|
||||
.setLabelCol("labels")
|
||||
.setLeafPredictionCol("leafPrediction")
|
||||
.setFeaturesShapCol("featuresShap"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="LightGBMClassifier"
|
||||
py="synapse.ml.lightgbm.html#module-synapse.ml.lightgbm.LightGBMClassifier"
|
||||
scala="com/microsoft/azure/synapse/ml/lightgbm/LightGBMClassifier.html"
|
||||
csharp="classSynapse_1_1ML_1_1Lightgbm_1_1LightGBMClassifier.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/lightgbm/src/main/scala/com/microsoft/azure/synapse/ml/lightgbm/LightGBMClassifier.scala" />
|
||||
|
||||
|
||||
## LightGBMRanker
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import *
|
||||
|
||||
lgbmRanker = (LightGBMRanker()
|
||||
.setLabelCol("labels")
|
||||
.setFeaturesCol("features")
|
||||
.setGroupCol("query")
|
||||
.setDefaultListenPort(12402)
|
||||
.setRepartitionByGroupingColumn(False)
|
||||
.setNumLeaves(5)
|
||||
.setNumIterations(10))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.lightgbm._
|
||||
|
||||
val lgbmRanker = (new LightGBMRanker()
|
||||
.setLabelCol("labels")
|
||||
.setFeaturesCol("features")
|
||||
.setGroupCol("query")
|
||||
.setDefaultListenPort(12402)
|
||||
.setRepartitionByGroupingColumn(false)
|
||||
.setNumLeaves(5)
|
||||
.setNumIterations(10))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="LightGBMRanker"
|
||||
py="synapse.ml.lightgbm.html#module-synapse.ml.lightgbm.LightGBMRanker"
|
||||
scala="com/microsoft/azure/synapse/ml/lightgbm/LightGBMRanker.html"
|
||||
csharp="classSynapse_1_1ML_1_1Lightgbm_1_1LightGBMRanker.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/lightgbm/src/main/scala/com/microsoft/azure/synapse/ml/lightgbm/LightGBMRanker.scala" />
|
||||
|
||||
|
||||
## LightGBMRegressor
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import *
|
||||
|
||||
lgbmRegressor = (LightGBMRegressor()
|
||||
.setLabelCol("labels")
|
||||
.setFeaturesCol("features")
|
||||
.setDefaultListenPort(12402)
|
||||
.setNumLeaves(5)
|
||||
.setNumIterations(10))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.lightgbm._
|
||||
|
||||
val lgbmRegressor = (new LightGBMRegressor()
|
||||
.setLabelCol("labels")
|
||||
.setFeaturesCol("features")
|
||||
.setDefaultListenPort(12402)
|
||||
.setNumLeaves(5)
|
||||
.setNumIterations(10))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="LightGBMRegressor"
|
||||
py="synapse.ml.lightgbm.html#module-synapse.ml.lightgbm.LightGBMRegressor"
|
||||
scala="com/microsoft/azure/synapse/ml/lightgbm/LightGBMRegressor.html"
|
||||
csharp="classSynapse_1_1ML_1_1Lightgbm_1_1LightGBMRegressor.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/lightgbm/src/main/scala/com/microsoft/azure/synapse/ml/lightgbm/LightGBMRegressor.scala" />
|
||||
|
|
@ -0,0 +1,112 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## VowpalWabbitRegressor
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.vw import *
|
||||
|
||||
vw = (VowpalWabbitRegressor()
|
||||
.setLabelCol("Y1")
|
||||
.setFeaturesCol("features")
|
||||
.setPredictionCol("pred"))
|
||||
|
||||
vwRegressor = (VowpalWabbitRegressor()
|
||||
.setNumPasses(20)
|
||||
.setPassThroughArgs("--holdout_off --loss_function quantile -q :: -l 0.1"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.vw._
|
||||
|
||||
val vw = (new VowpalWabbitRegressor()
|
||||
.setLabelCol("Y1")
|
||||
.setFeaturesCol("features")
|
||||
.setPredictionCol("pred"))
|
||||
|
||||
val vwRegressor = (new VowpalWabbitRegressor()
|
||||
.setNumPasses(20)
|
||||
.setPassThroughArgs("--holdout_off --loss_function quantile -q :: -l 0.1"))
|
||||
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VowpalWabbitRegressor"
|
||||
py="synapse.ml.vw.html#module-synapse.ml.vw.VowpalWabbitRegressor"
|
||||
scala="com/microsoft/azure/synapse/ml/vw/VowpalWabbitRegressor.html"
|
||||
csharp="classSynapse_1_1ML_1_1Vw_1_1VowpalWabbitRegressor.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/vw/src/main/scala/com/microsoft/azure/synapse/ml/vw/VowpalWabbitRegressor.scala" />
|
||||
|
||||
|
||||
## VowpalWabbitContextualBandit
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.vw import *
|
||||
|
||||
cb = (VowpalWabbitContextualBandit()
|
||||
.setPassThroughArgs("--cb_explore_adf --epsilon 0.2 --quiet")
|
||||
.setLabelCol("cost")
|
||||
.setProbabilityCol("prob")
|
||||
.setChosenActionCol("chosen_action")
|
||||
.setSharedCol("shared_features")
|
||||
.setFeaturesCol("action_features")
|
||||
.setUseBarrierExecutionMode(False))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.vw._
|
||||
|
||||
val cb = (new VowpalWabbitContextualBandit()
|
||||
.setPassThroughArgs("--cb_explore_adf --epsilon 0.2 --quiet")
|
||||
.setLabelCol("cost")
|
||||
.setProbabilityCol("prob")
|
||||
.setChosenActionCol("chosen_action")
|
||||
.setSharedCol("shared_features")
|
||||
.setFeaturesCol("action_features")
|
||||
.setUseBarrierExecutionMode(false))
|
||||
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VowpalWabbitContextualBandit"
|
||||
py="synapse.ml.vw.html#module-synapse.ml.vw.VowpalWabbitContextualBandit"
|
||||
scala="com/microsoft/azure/synapse/ml/vw/VowpalWabbitContextualBandit.html"
|
||||
csharp="classSynapse_1_1ML_1_1Vw_1_1VowpalWabbitContextualBandit.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/vw/src/main/scala/com/microsoft/azure/synapse/ml/vw/VowpalWabbitContextualBandit.scala" />
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## DoubleMLEstimator
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.causal import *
|
||||
from pyspark.ml.classification import LogisticRegression
|
||||
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, BooleanType
|
||||
|
||||
schema = StructType([
|
||||
StructField("Treatment", BooleanType()),
|
||||
StructField("Outcome", BooleanType()),
|
||||
StructField("col2", DoubleType()),
|
||||
StructField("col3", DoubleType()),
|
||||
StructField("col4", DoubleType())
|
||||
])
|
||||
|
||||
|
||||
df = spark.createDataFrame([
|
||||
(False, True, 0.30, 0.66, 0.2),
|
||||
(True, False, 0.38, 0.53, 1.5),
|
||||
(False, True, 0.68, 0.98, 3.2),
|
||||
(True, False, 0.15, 0.32, 6.6),
|
||||
(False, True, 0.50, 0.65, 2.8),
|
||||
(True, True, 0.40, 0.54, 3.7),
|
||||
(False, True, 0.78, 0.97, 8.1),
|
||||
(True, False, 0.12, 0.32, 10.2),
|
||||
(False, True, 0.35, 0.63, 1.8),
|
||||
(True, False, 0.45, 0.57, 4.3),
|
||||
(False, True, 0.75, 0.97, 7.2),
|
||||
(True, True, 0.16, 0.32, 11.7)], schema
|
||||
)
|
||||
|
||||
dml = (DoubleMLEstimator()
|
||||
.setTreatmentCol("Treatment")
|
||||
.setTreatmentModel(LogisticRegression())
|
||||
.setOutcomeCol("Outcome")
|
||||
.setOutcomeModel(LogisticRegression())
|
||||
.setMaxIter(20))
|
||||
|
||||
dmlModel = dml.fit(df)
|
||||
dmlModel.getAvgTreatmentEffect()
|
||||
dmlModel.getConfidenceInterval()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.causal._
|
||||
import org.apache.spark.ml.classification.LogisticRegression
|
||||
|
||||
val df = (Seq(
|
||||
(false, true, 0.50, 0.60, 0),
|
||||
(true, false, 0.40, 0.50, 1),
|
||||
(false, true, 0.78, 0.99, 2),
|
||||
(true, false, 0.12, 0.34, 3),
|
||||
(false, true, 0.50, 0.60, 0),
|
||||
(true, false, 0.40, 0.50, 1),
|
||||
(false, true, 0.78, 0.99, 2),
|
||||
(true, false, 0.12, 0.34, 3),
|
||||
(false, false, 0.50, 0.60, 0),
|
||||
(true, true, 0.40, 0.50, 1),
|
||||
(false, true, 0.78, 0.99, 2),
|
||||
(true, false, 0.12, 0.34, 3))
|
||||
.toDF("Treatment", "Outcome", "col2", "col3", "col4"))
|
||||
|
||||
val dml = (new DoubleMLEstimator()
|
||||
.setTreatmentCol("Treatment")
|
||||
.setTreatmentModel(new LogisticRegression())
|
||||
.setOutcomeCol("Outcome")
|
||||
.setOutcomeModel(new LogisticRegression())
|
||||
.setMaxIter(20))
|
||||
|
||||
val dmlModel = dml.fit(df)
|
||||
dmlModel.getAvgTreatmentEffect
|
||||
dmlModel.getConfidenceInterval
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DoubleMLEstimator"
|
||||
py="synapse.ml.causal.html#module-synapse.ml.causal.DoubleMLEstimator"
|
||||
scala="com/microsoft/azure/synapse/ml/causal/DoubleMLEstimator.html"
|
||||
csharp="classSynapse_1_1ML_1_1Causal_1_1DoubleMLEstimator.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/causal/DoubleMLEstimator.scala" />
|
||||
|
|
@ -0,0 +1,97 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## SimpleFitMultivariateAnomaly
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
anomalyKey = os.environ.get("ANOMALY_API_KEY", getSecret("anomaly-api-key"))
|
||||
startTime = "2021-01-01T00:00:00Z"
|
||||
endTime = "2021-01-03T01:59:00Z"
|
||||
timestampColumn = "timestamp"
|
||||
inputColumns = ["feature0", "feature1", "feature2"]
|
||||
intermediateSaveDir = "wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
|
||||
|
||||
simpleFitMultivariateAnomaly = (SimpleFitMultivariateAnomaly()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation("westus2")
|
||||
.setOutputCol("result")
|
||||
.setStartTime(startTime)
|
||||
.setEndTime(endTime)
|
||||
.setIntermediateSaveDir(intermediateSaveDir)
|
||||
.setTimestampCol(timestampColumn)
|
||||
.setInputCols(inputColumns)
|
||||
.setSlidingWindow(50))
|
||||
|
||||
# uncomment below for fitting your own dataframe
|
||||
# model = simpleFitMultivariateAnomaly.fit(df)
|
||||
# simpleFitMultivariateAnomaly.cleanUpIntermediateData()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.anomaly.FitMultivariateAnomaly
|
||||
|
||||
val startTime: String = "2021-01-01T00:00:00Z"
|
||||
val endTime: String = "2021-01-02T12:00:00Z"
|
||||
val timestampColumn: String = "timestamp"
|
||||
val inputColumns: Array[String] = Array("feature0", "feature1", "feature2")
|
||||
val intermediateSaveDir: String = "wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
|
||||
val anomalyKey = sys.env.getOrElse("ANOMALY_API_KEY", None)
|
||||
|
||||
val simpleFitMultivariateAnomaly = (new SimpleFitMultivariateAnomaly()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation("westus2")
|
||||
.setOutputCol("result")
|
||||
.setStartTime(startTime)
|
||||
.setEndTime(endTime)
|
||||
.setIntermediateSaveDir(intermediateSaveDir)
|
||||
.setTimestampCol(timestampColumn)
|
||||
.setInputCols(inputColumns)
|
||||
.setSlidingWindow(50))
|
||||
|
||||
val df = (spark.read.format("csv")
|
||||
.option("header", True)
|
||||
.load("wasbs://datasets@mmlspark.blob.core.windows.net/MAD/mad_example.csv"))
|
||||
|
||||
val model = simpleFitMultivariateAnomaly.fit(df)
|
||||
|
||||
val result = (model
|
||||
.setStartTime(startTime)
|
||||
.setEndTime(endTime)
|
||||
.setOutputCol("result")
|
||||
.setTimestampCol(timestampColumn)
|
||||
.setInputCols(inputColumns)
|
||||
.transform(df))
|
||||
|
||||
result.show()
|
||||
|
||||
simpleFitMultivariateAnomaly.cleanUpIntermediateData()
|
||||
model.cleanUpIntermediateData()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="SimpleFitMultivariateAnomaly"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.SimpleFitMultivariateAnomaly"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/SimpleFitMultivariateAnomaly.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1SimpleFitMultivariateAnomaly.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/MultivariateAnomalyDetection.scala" />
|
||||
|
|
@ -0,0 +1,214 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## AutoML
|
||||
|
||||
### FindBestModel
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.automl import *
|
||||
from synapse.ml.train import *
|
||||
from pyspark.ml.classification import RandomForestClassifier
|
||||
|
||||
df = (spark.createDataFrame([
|
||||
(0, 2, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, 0.50, 1),
|
||||
(0, 4, 0.78, 0.99, 2),
|
||||
(1, 5, 0.12, 0.34, 3),
|
||||
(0, 1, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, 0.50, 1),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3),
|
||||
(0, 0, 0.50, 0.60, 0),
|
||||
(1, 2, 0.40, 0.50, 1),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3)
|
||||
], ["Label", "col1", "col2", "col3", "col4"]))
|
||||
|
||||
# mocking models
|
||||
randomForestClassifier = (TrainClassifier()
|
||||
.setModel(RandomForestClassifier()
|
||||
.setMaxBins(32)
|
||||
.setMaxDepth(5)
|
||||
.setMinInfoGain(0.0)
|
||||
.setMinInstancesPerNode(1)
|
||||
.setNumTrees(20)
|
||||
.setSubsamplingRate(1.0)
|
||||
.setSeed(0))
|
||||
.setFeaturesCol("mlfeatures")
|
||||
.setLabelCol("Label"))
|
||||
model = randomForestClassifier.fit(df)
|
||||
|
||||
findBestModel = (FindBestModel()
|
||||
.setModels([model, model])
|
||||
.setEvaluationMetric("accuracy"))
|
||||
bestModel = findBestModel.fit(df)
|
||||
bestModel.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.automl._
|
||||
import com.microsoft.azure.synapse.ml.train._
|
||||
import spark.implicits._
|
||||
import org.apache.spark.ml.Transformer
|
||||
|
||||
val df = (Seq(
|
||||
(0, 2, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, 0.50, 1),
|
||||
(0, 4, 0.78, 0.99, 2),
|
||||
(1, 5, 0.12, 0.34, 3),
|
||||
(0, 1, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, 0.50, 1),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3),
|
||||
(0, 0, 0.50, 0.60, 0),
|
||||
(1, 2, 0.40, 0.50, 1),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3)
|
||||
).toDF("Label", "col1", "col2", "col3", "col4"))
|
||||
|
||||
// mocking models
|
||||
val randomForestClassifier = (new TrainClassifier()
|
||||
.setModel(
|
||||
new RandomForestClassifier()
|
||||
.setMaxBins(32)
|
||||
.setMaxDepth(5)
|
||||
.setMinInfoGain(0.0)
|
||||
.setMinInstancesPerNode(1)
|
||||
.setNumTrees(20)
|
||||
.setSubsamplingRate(1.0)
|
||||
.setSeed(0L))
|
||||
.setFeaturesCol("mlfeatures")
|
||||
.setLabelCol("Label"))
|
||||
val model = randomForestClassifier.fit(df)
|
||||
|
||||
val findBestModel = (new FindBestModel()
|
||||
.setModels(Array(model.asInstanceOf[Transformer], model.asInstanceOf[Transformer]))
|
||||
.setEvaluationMetric("accuracy"))
|
||||
val bestModel = findBestModel.fit(df)
|
||||
bestModel.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="FindBestModel"
|
||||
py="synapse.ml.automl.html#module-synapse.ml.automl.FindBestModel"
|
||||
scala="com/microsoft/azure/synapse/ml/automl/FindBestModel.html"
|
||||
csharp="classSynapse_1_1ML_1_1Automl_1_1FindBestModel.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/automl/FindBestModel.scala" />
|
||||
|
||||
|
||||
### TuneHyperparameters
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.automl import *
|
||||
from synapse.ml.train import *
|
||||
from pyspark.ml.classification import LogisticRegression, RandomForestClassifier, GBTClassifier
|
||||
|
||||
|
||||
df = (spark.createDataFrame([
|
||||
(0, 1, 1, 1, 1, 1, 1.0, 3, 1, 1),
|
||||
(0, 1, 1, 1, 1, 2, 1.0, 1, 1, 1),
|
||||
(0, 1, 1, 1, 1, 2, 1.0, 2, 1, 1),
|
||||
(0, 1, 2, 3, 1, 2, 1.0, 3, 1, 1),
|
||||
(0, 3, 1, 1, 1, 2, 1.0, 3, 1, 1)
|
||||
], ["Label", "Clump_Thickness", "Uniformity_of_Cell_Size",
|
||||
"Uniformity_of_Cell_Shape", "Marginal_Adhesion", "Single_Epithelial_Cell_Size",
|
||||
"Bare_Nuclei", "Bland_Chromatin", "Normal_Nucleoli", "Mitoses"]))
|
||||
|
||||
logReg = LogisticRegression()
|
||||
randForest = RandomForestClassifier()
|
||||
gbt = GBTClassifier()
|
||||
smlmodels = [logReg, randForest, gbt]
|
||||
mmlmodels = [TrainClassifier(model=model, labelCol="Label") for model in smlmodels]
|
||||
|
||||
paramBuilder = (HyperparamBuilder()
|
||||
.addHyperparam(logReg, logReg.regParam, RangeHyperParam(0.1, 0.3))
|
||||
.addHyperparam(randForest, randForest.numTrees, DiscreteHyperParam([5,10]))
|
||||
.addHyperparam(randForest, randForest.maxDepth, DiscreteHyperParam([3,5]))
|
||||
.addHyperparam(gbt, gbt.maxBins, RangeHyperParam(8,16))
|
||||
.addHyperparam(gbt, gbt.maxDepth, DiscreteHyperParam([3,5])))
|
||||
searchSpace = paramBuilder.build()
|
||||
# The search space is a list of params to tuples of estimator and hyperparam
|
||||
randomSpace = RandomSpace(searchSpace)
|
||||
|
||||
bestModel = TuneHyperparameters(
|
||||
evaluationMetric="accuracy", models=mmlmodels, numFolds=2,
|
||||
numRuns=len(mmlmodels) * 2, parallelism=2,
|
||||
paramSpace=randomSpace.space(), seed=0).fit(df)
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.automl._
|
||||
import com.microsoft.azure.synapse.ml.train._
|
||||
import spark.implicits._
|
||||
|
||||
val logReg = new LogisticRegression()
|
||||
val randForest = new RandomForestClassifier()
|
||||
val gbt = new GBTClassifier()
|
||||
val smlmodels = Seq(logReg, randForest, gbt)
|
||||
val mmlmodels = smlmodels.map(model => new TrainClassifier().setModel(model).setLabelCol("Label"))
|
||||
|
||||
val paramBuilder = new HyperparamBuilder()
|
||||
.addHyperparam(logReg.regParam, new DoubleRangeHyperParam(0.1, 0.3))
|
||||
.addHyperparam(randForest.numTrees, new DiscreteHyperParam(List(5,10)))
|
||||
.addHyperparam(randForest.maxDepth, new DiscreteHyperParam(List(3,5)))
|
||||
.addHyperparam(gbt.maxBins, new IntRangeHyperParam(8,16))
|
||||
.addHyperparam(gbt.maxDepth, new DiscreteHyperParam(List(3,5)))
|
||||
val searchSpace = paramBuilder.build()
|
||||
val randomSpace = new RandomSpace(searchSpace)
|
||||
|
||||
val dataset: DataFrame = Seq(
|
||||
(0, 1, 1, 1, 1, 1, 1.0, 3, 1, 1),
|
||||
(0, 1, 1, 1, 1, 2, 1.0, 1, 1, 1),
|
||||
(0, 1, 1, 1, 1, 2, 1.0, 2, 1, 1),
|
||||
(0, 1, 2, 3, 1, 2, 1.0, 3, 1, 1),
|
||||
(0, 3, 1, 1, 1, 2, 1.0, 3, 1, 1))
|
||||
.toDF("Label", "Clump_Thickness", "Uniformity_of_Cell_Size",
|
||||
"Uniformity_of_Cell_Shape", "Marginal_Adhesion", "Single_Epithelial_Cell_Size",
|
||||
"Bare_Nuclei", "Bland_Chromatin", "Normal_Nucleoli", "Mitoses")
|
||||
|
||||
val tuneHyperparameters = new TuneHyperparameters().setEvaluationMetric("accuracy")
|
||||
.setModels(mmlmodels.toArray).setNumFolds(2).setNumRuns(mmlmodels.length * 2)
|
||||
.setParallelism(1).setParamSpace(randomSpace).setSeed(0)
|
||||
tuneHyperparameters.fit(dataset).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TuneHyperparameters"
|
||||
py="synapse.ml.automl.html#module-synapse.ml.automl.TuneHyperparameters"
|
||||
scala="com/microsoft/azure/synapse/ml/automl/TuneHyperparameters.html"
|
||||
csharp="classSynapse_1_1ML_1_1Automl_1_1TuneHyperparameters.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/automl/TuneHyperparameters.scala" />
|
||||
|
|
@ -0,0 +1,332 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## Featurize
|
||||
|
||||
### CleanMissingData
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize import *
|
||||
|
||||
dataset = spark.createDataFrame([
|
||||
(0, 2, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, None, None),
|
||||
(0, 4, 0.78, 0.99, 2),
|
||||
(1, 5, 0.12, 0.34, 3),
|
||||
(0, 1, 0.50, 0.60, 0),
|
||||
(None, None, None, None, None),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3),
|
||||
(0, None, 0.50, 0.60, 0),
|
||||
(1, 2, 0.40, 0.50, None),
|
||||
(0, 3, None, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3)
|
||||
], ["col1", "col2", "col3", "col4", "col5"])
|
||||
|
||||
cmd = (CleanMissingData()
|
||||
.setInputCols(dataset.columns)
|
||||
.setOutputCols(dataset.columns)
|
||||
.setCleaningMode("Mean"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize._
|
||||
import java.lang.{Boolean => JBoolean, Double => JDouble, Integer => JInt}
|
||||
import spark.implicits._
|
||||
|
||||
def createMockDataset: DataFrame = {
|
||||
Seq[(JInt, JInt, JDouble, JDouble, JInt)](
|
||||
(0, 2, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, null, null),
|
||||
(0, 4, 0.78, 0.99, 2),
|
||||
(1, 5, 0.12, 0.34, 3),
|
||||
(0, 1, 0.50, 0.60, 0),
|
||||
(null, null, null, null, null),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3),
|
||||
(0, null, 0.50, 0.60, 0),
|
||||
(1, 2, 0.40, 0.50, null),
|
||||
(0, 3, null, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3))
|
||||
.toDF("col1", "col2", "col3", "col4", "col5")
|
||||
}
|
||||
|
||||
val dataset = createMockDataset
|
||||
val cmd = (new CleanMissingData()
|
||||
.setInputCols(dataset.columns)
|
||||
.setOutputCols(dataset.columns)
|
||||
.setCleaningMode("Mean"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="CleanMissingData"
|
||||
py="synapse.ml.featurize.html#module-synapse.ml.featurize.CleanMissingData"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/CleanMissingData.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1CleanMissingData.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/CleanMissingData.scala" />
|
||||
|
||||
|
||||
### CountSelector
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize import *
|
||||
from pyspark.ml.linalg import Vectors
|
||||
|
||||
df = spark.createDataFrame([
|
||||
(Vectors.sparse(3, [(0, 1.0), (2, 2.0)]), Vectors.dense(1.0, 0.1, 0)),
|
||||
(Vectors.sparse(3, [(0, 1.0), (2, 2.0)]), Vectors.dense(1.0, 0.1, 0))
|
||||
], ["col1", "col2"])
|
||||
|
||||
cs = CountSelector().setInputCol("col1").setOutputCol("col3")
|
||||
|
||||
cs.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize._
|
||||
import org.apache.spark.ml.linalg.Vectors
|
||||
import spark.implicits._
|
||||
|
||||
val df = Seq(
|
||||
(Vectors.sparse(3, Seq((0, 1.0), (2, 2.0))), Vectors.dense(1.0, 0.1, 0)),
|
||||
(Vectors.sparse(3, Seq((0, 1.0), (2, 2.0))), Vectors.dense(1.0, 0.1, 0))
|
||||
).toDF("col1", "col2")
|
||||
|
||||
val cs = (new CountSelector()
|
||||
.setInputCol("col1")
|
||||
.setOutputCol("col3"))
|
||||
|
||||
cs.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="CountSelector"
|
||||
py="synapse.ml.featurize.html#module-synapse.ml.featurize.CountSelector"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/CountSelector.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1CountSelector.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/CountSelector.scala" />
|
||||
|
||||
|
||||
### Featurize
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize import *
|
||||
|
||||
dataset = spark.createDataFrame([
|
||||
(0, 2, 0.50, 0.60, "pokemon are everywhere"),
|
||||
(1, 3, 0.40, 0.50, "they are in the woods"),
|
||||
(0, 4, 0.78, 0.99, "they are in the water"),
|
||||
(1, 5, 0.12, 0.34, "they are in the fields"),
|
||||
(0, 3, 0.78, 0.99, "pokemon - gotta catch em all")
|
||||
], ["Label", "col1", "col2", "col3"])
|
||||
|
||||
feat = (Featurize()
|
||||
.setNumFeatures(10)
|
||||
.setOutputCol("testColumn")
|
||||
.setInputCols(["col1", "col2", "col3"])
|
||||
.setOneHotEncodeCategoricals(False))
|
||||
|
||||
feat.fit(dataset).transform(dataset).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize._
|
||||
import spark.implicits._
|
||||
|
||||
val dataset = Seq(
|
||||
(0, 2, 0.50, 0.60, "pokemon are everywhere"),
|
||||
(1, 3, 0.40, 0.50, "they are in the woods"),
|
||||
(0, 4, 0.78, 0.99, "they are in the water"),
|
||||
(1, 5, 0.12, 0.34, "they are in the fields"),
|
||||
(0, 3, 0.78, 0.99, "pokemon - gotta catch em all")).toDF("Label", "col1", "col2", "col3")
|
||||
|
||||
val featureColumns = dataset.columns.filter(_ != "Label")
|
||||
|
||||
val feat = (new Featurize()
|
||||
.setNumFeatures(10)
|
||||
.setOutputCol("testColumn")
|
||||
.setInputCols(featureColumns)
|
||||
.setOneHotEncodeCategoricals(false))
|
||||
|
||||
feat.fit(dataset).transform(dataset).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="Featurize"
|
||||
py="synapse.ml.featurize.html#module-synapse.ml.featurize.Featurize"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/Featurize.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1Featurize.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/Featurize.scala" />
|
||||
|
||||
|
||||
### ValueIndexer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize import *
|
||||
|
||||
df = spark.createDataFrame([
|
||||
(-3, 24, 0.32534, True, "piano"),
|
||||
(1, 5, 5.67, False, "piano"),
|
||||
(-3, 5, 0.32534, False, "guitar")
|
||||
], ["int", "long", "double", "bool", "string"])
|
||||
|
||||
vi = ValueIndexer().setInputCol("string").setOutputCol("string_cat")
|
||||
|
||||
vi.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize._
|
||||
import spark.implicits._
|
||||
|
||||
val df = Seq[(Int, Long, Double, Boolean, String)](
|
||||
(-3, 24L, 0.32534, true, "piano"),
|
||||
(1, 5L, 5.67, false, "piano"),
|
||||
(-3, 5L, 0.32534, false, "guitar")).toDF("int", "long", "double", "bool", "string")
|
||||
|
||||
val vi = new ValueIndexer().setInputCol("string").setOutputCol("string_cat")
|
||||
|
||||
vi.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ValueIndexer"
|
||||
py="synapse.ml.featurize.html#module-synapse.ml.featurize.ValueIndexer"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/ValueIndexer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1ValueIndexer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/ValueIndexer.scala" />
|
||||
|
||||
## Featurize Text
|
||||
|
||||
### TextFeaturizer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize.text import *
|
||||
|
||||
dfRaw = spark.createDataFrame([
|
||||
(0, "Hi I"),
|
||||
(1, "I wish for snow today"),
|
||||
(2, "we Cant go to the park, because of the snow!"),
|
||||
(3, "")
|
||||
], ["label", "sentence"])
|
||||
|
||||
tfRaw = (TextFeaturizer()
|
||||
.setInputCol("sentence")
|
||||
.setOutputCol("features")
|
||||
.setNumFeatures(20))
|
||||
|
||||
tfRaw.fit(dfRaw).transform(dfRaw).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize.text._
|
||||
import spark.implicits._
|
||||
|
||||
val dfRaw = Seq((0, "Hi I"),
|
||||
(1, "I wish for snow today"),
|
||||
(2, "we Cant go to the park, because of the snow!"),
|
||||
(3, "")).toDF("label", "sentence")
|
||||
|
||||
val tfRaw = (new TextFeaturizer()
|
||||
.setInputCol("sentence")
|
||||
.setOutputCol("features")
|
||||
.setNumFeatures(20))
|
||||
|
||||
tfRaw.fit(dfRaw).transform(dfRaw).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TextFeaturizer"
|
||||
py="synapse.ml.featurize.text.html#module-synapse.ml.featurize.text.TextFeaturizer"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/text/TextFeaturizer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1Text_1_1TextFeaturizer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/text/TextFeaturizer.scala" />
|
||||
|
|
@ -0,0 +1,65 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Isolation Forest
|
||||
|
||||
### IsolationForest
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.isolationforest import *
|
||||
|
||||
isolationForest = (IsolationForest()
|
||||
.setNumEstimators(100)
|
||||
.setBootstrap(False)
|
||||
.setMaxSamples(256)
|
||||
.setMaxFeatures(1.0)
|
||||
.setFeaturesCol("features")
|
||||
.setPredictionCol("predictedLabel")
|
||||
.setScoreCol("outlierScore")
|
||||
.setContamination(0.02)
|
||||
.setContaminationError(0.02 * 0.01)
|
||||
.setRandomSeed(1))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.isolationforest._
|
||||
import spark.implicits._
|
||||
|
||||
val isolationForest = (new IsolationForest()
|
||||
.setNumEstimators(100)
|
||||
.setBootstrap(false)
|
||||
.setMaxSamples(256)
|
||||
.setMaxFeatures(1.0)
|
||||
.setFeaturesCol("features")
|
||||
.setPredictionCol("predictedLabel")
|
||||
.setScoreCol("outlierScore")
|
||||
.setContamination(0.02)
|
||||
.setContaminationError(0.02 * 0.01)
|
||||
.setRandomSeed(1))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="IsolationForest"
|
||||
py="synapse.ml.isolationforest.html#module-synapse.ml.isolationforest.IsolationForest"
|
||||
scala="com/microsoft/azure/synapse/ml/isolationforest/IsolationForest.html"
|
||||
csharp="classSynapse_1_1ML_1_1Isolationforest_1_1IsolationForest.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/isolationforest/IsolationForest.scala" />
|
||||
|
|
@ -0,0 +1,92 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## NN
|
||||
|
||||
### ConditionalKNN
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.nn import *
|
||||
|
||||
cknn = (ConditionalKNN()
|
||||
.setOutputCol("matches")
|
||||
.setFeaturesCol("features"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.nn._
|
||||
import spark.implicits._
|
||||
|
||||
val cknn = (new ConditionalKNN()
|
||||
.setOutputCol("matches")
|
||||
.setFeaturesCol("features"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ConditionalKNN"
|
||||
py="synapse.ml.nn.html#module-synapse.ml.nn.ConditionalKNN"
|
||||
scala="com/microsoft/azure/synapse/ml/nn/ConditionalKNN.html"
|
||||
csharp="classSynapse_1_1ML_1_1Nn_1_1ConditionalKNN.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/nn/ConditionalKNN.scala" />
|
||||
|
||||
|
||||
### KNN
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.nn import *
|
||||
|
||||
knn = (KNN()
|
||||
.setOutputCol("matches"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.nn._
|
||||
import spark.implicits._
|
||||
|
||||
val knn = (new KNN()
|
||||
.setOutputCol("matches"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="KNN"
|
||||
py="synapse.ml.nn.html#module-synapse.ml.nn.KNN"
|
||||
scala="com/microsoft/azure/synapse/ml/nn/KNN.html"
|
||||
csharp="classSynapse_1_1ML_1_1Nn_1_1KNN.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/nn/KNN.scala" />
|
||||
|
|
@ -0,0 +1,379 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Recommendation
|
||||
|
||||
### RecommendationIndexer, RankingEvaluator, RankingAdapter and RankingTrainValidationSplit
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.recommendation import *
|
||||
from pyspark.ml.recommendation import ALS
|
||||
from pyspark.ml.tuning import *
|
||||
|
||||
ratings = (spark.createDataFrame([
|
||||
("11", "Movie 01", 2),
|
||||
("11", "Movie 03", 1),
|
||||
("11", "Movie 04", 5),
|
||||
("11", "Movie 05", 3),
|
||||
("11", "Movie 06", 4),
|
||||
("11", "Movie 07", 1),
|
||||
("11", "Movie 08", 5),
|
||||
("11", "Movie 09", 3),
|
||||
("22", "Movie 01", 4),
|
||||
("22", "Movie 02", 5),
|
||||
("22", "Movie 03", 1),
|
||||
("22", "Movie 05", 3),
|
||||
("22", "Movie 06", 3),
|
||||
("22", "Movie 07", 5),
|
||||
("22", "Movie 08", 1),
|
||||
("22", "Movie 10", 3),
|
||||
("33", "Movie 01", 4),
|
||||
("33", "Movie 03", 1),
|
||||
("33", "Movie 04", 5),
|
||||
("33", "Movie 05", 3),
|
||||
("33", "Movie 06", 4),
|
||||
("33", "Movie 08", 1),
|
||||
("33", "Movie 09", 5),
|
||||
("33", "Movie 10", 3),
|
||||
("44", "Movie 01", 4),
|
||||
("44", "Movie 02", 5),
|
||||
("44", "Movie 03", 1),
|
||||
("44", "Movie 05", 3),
|
||||
("44", "Movie 06", 4),
|
||||
("44", "Movie 07", 5),
|
||||
("44", "Movie 08", 1),
|
||||
("44", "Movie 10", 3)
|
||||
], ["customerIDOrg", "itemIDOrg", "rating"])
|
||||
.dropDuplicates()
|
||||
.cache())
|
||||
|
||||
recommendationIndexer = (RecommendationIndexer()
|
||||
.setUserInputCol("customerIDOrg")
|
||||
.setUserOutputCol("customerID")
|
||||
.setItemInputCol("itemIDOrg")
|
||||
.setItemOutputCol("itemID")
|
||||
.setRatingCol("rating"))
|
||||
|
||||
transformedDf = (recommendationIndexer.fit(ratings)
|
||||
.transform(ratings).cache())
|
||||
|
||||
als = (ALS()
|
||||
.setNumUserBlocks(1)
|
||||
.setNumItemBlocks(1)
|
||||
.setUserCol("customerID")
|
||||
.setItemCol("itemID")
|
||||
.setRatingCol("rating")
|
||||
.setSeed(0))
|
||||
|
||||
evaluator = (RankingEvaluator()
|
||||
.setK(3)
|
||||
.setNItems(10))
|
||||
|
||||
adapter = (RankingAdapter()
|
||||
.setK(evaluator.getK())
|
||||
.setRecommender(als))
|
||||
|
||||
adapter.fit(transformedDf).transform(transformedDf).show()
|
||||
|
||||
paramGrid = (ParamGridBuilder()
|
||||
.addGrid(als.regParam, [1.0])
|
||||
.build())
|
||||
|
||||
tvRecommendationSplit = (RankingTrainValidationSplit()
|
||||
.setEstimator(als)
|
||||
.setEvaluator(evaluator)
|
||||
.setEstimatorParamMaps(paramGrid)
|
||||
.setTrainRatio(0.8)
|
||||
.setUserCol(recommendationIndexer.getUserOutputCol())
|
||||
.setItemCol(recommendationIndexer.getItemOutputCol())
|
||||
.setRatingCol("rating"))
|
||||
|
||||
tvRecommendationSplit.fit(transformedDf).transform(transformedDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.recommendation._
|
||||
import org.apache.spark.ml.recommendation.ALS
|
||||
import org.apache.spark.ml.tuning._
|
||||
import spark.implicits._
|
||||
|
||||
val ratings = (Seq(
|
||||
("11", "Movie 01", 2),
|
||||
("11", "Movie 03", 1),
|
||||
("11", "Movie 04", 5),
|
||||
("11", "Movie 05", 3),
|
||||
("11", "Movie 06", 4),
|
||||
("11", "Movie 07", 1),
|
||||
("11", "Movie 08", 5),
|
||||
("11", "Movie 09", 3),
|
||||
("22", "Movie 01", 4),
|
||||
("22", "Movie 02", 5),
|
||||
("22", "Movie 03", 1),
|
||||
("22", "Movie 05", 3),
|
||||
("22", "Movie 06", 3),
|
||||
("22", "Movie 07", 5),
|
||||
("22", "Movie 08", 1),
|
||||
("22", "Movie 10", 3),
|
||||
("33", "Movie 01", 4),
|
||||
("33", "Movie 03", 1),
|
||||
("33", "Movie 04", 5),
|
||||
("33", "Movie 05", 3),
|
||||
("33", "Movie 06", 4),
|
||||
("33", "Movie 08", 1),
|
||||
("33", "Movie 09", 5),
|
||||
("33", "Movie 10", 3),
|
||||
("44", "Movie 01", 4),
|
||||
("44", "Movie 02", 5),
|
||||
("44", "Movie 03", 1),
|
||||
("44", "Movie 05", 3),
|
||||
("44", "Movie 06", 4),
|
||||
("44", "Movie 07", 5),
|
||||
("44", "Movie 08", 1),
|
||||
("44", "Movie 10", 3))
|
||||
.toDF("customerIDOrg", "itemIDOrg", "rating")
|
||||
.dropDuplicates()
|
||||
.cache())
|
||||
|
||||
val recommendationIndexer = (new RecommendationIndexer()
|
||||
.setUserInputCol("customerIDOrg")
|
||||
.setUserOutputCol("customerID")
|
||||
.setItemInputCol("itemIDOrg")
|
||||
.setItemOutputCol("itemID")
|
||||
.setRatingCol("rating"))
|
||||
|
||||
val transformedDf = (recommendationIndexer.fit(ratings)
|
||||
.transform(ratings).cache())
|
||||
|
||||
val als = (new ALS()
|
||||
.setNumUserBlocks(1)
|
||||
.setNumItemBlocks(1)
|
||||
.setUserCol("customerID")
|
||||
.setItemCol("itemID")
|
||||
.setRatingCol("rating")
|
||||
.setSeed(0))
|
||||
|
||||
val evaluator = (new RankingEvaluator()
|
||||
.setK(3)
|
||||
.setNItems(10))
|
||||
|
||||
val adapter = (new RankingAdapter()
|
||||
.setK(evaluator.getK)
|
||||
.setRecommender(als))
|
||||
|
||||
adapter.fit(transformedDf).transform(transformedDf).show()
|
||||
|
||||
val paramGrid = (new ParamGridBuilder()
|
||||
.addGrid(als.regParam, Array(1.0))
|
||||
.build())
|
||||
|
||||
val tvRecommendationSplit = (new RankingTrainValidationSplit()
|
||||
.setEstimator(als)
|
||||
.setEvaluator(evaluator)
|
||||
.setEstimatorParamMaps(paramGrid)
|
||||
.setTrainRatio(0.8)
|
||||
.setUserCol(recommendationIndexer.getUserOutputCol)
|
||||
.setItemCol(recommendationIndexer.getItemOutputCol)
|
||||
.setRatingCol("rating"))
|
||||
|
||||
tvRecommendationSplit.fit(transformedDf).transform(transformedDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="RecommendationIndexer"
|
||||
py="synapse.ml.recommendation.html#module-synapse.ml.recommendation.RecommendationIndexer"
|
||||
scala="com/microsoft/azure/synapse/ml/recommendation/RecommendationIndexer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Recommendation_1_1RecommendationIndexer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/recommendation/RecommendationIndexer.scala" />
|
||||
<DocTable className="RankingEvaluator"
|
||||
py="synapse.ml.recommendation.html#module-synapse.ml.recommendation.RankingEvaluator"
|
||||
scala="com/microsoft/azure/synapse/ml/recommendation/RankingEvaluator.html"
|
||||
csharp="classSynapse_1_1ML_1_1Recommendation_1_1RankingEvaluator.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/recommendation/RankingEvaluator.scala" />
|
||||
<DocTable className="RankingAdapter"
|
||||
py="synapse.ml.recommendation.html#module-synapse.ml.recommendation.RankingAdapter"
|
||||
scala="com/microsoft/azure/synapse/ml/recommendation/RankingAdapter.html"
|
||||
csharp="classSynapse_1_1ML_1_1Recommendation_1_1RankingAdapter.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/recommendation/RankingAdapter.scala" />
|
||||
<DocTable className="RankingTrainValidationSplit"
|
||||
py="synapse.ml.recommendation.html#module-synapse.ml.recommendation.RankingTrainValidationSplit"
|
||||
scala="com/microsoft/azure/synapse/ml/recommendation/RankingTrainValidationSplit.html"
|
||||
csharp="classSynapse_1_1ML_1_1Recommendation_1_1RankingTrainValidationSplit.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/recommendation/RankingTrainValidationSplit.scala" />
|
||||
|
||||
|
||||
### SAR
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.recommendation import *
|
||||
|
||||
ratings = (spark.createDataFrame([
|
||||
("11", "Movie 01", 2),
|
||||
("11", "Movie 03", 1),
|
||||
("11", "Movie 04", 5),
|
||||
("11", "Movie 05", 3),
|
||||
("11", "Movie 06", 4),
|
||||
("11", "Movie 07", 1),
|
||||
("11", "Movie 08", 5),
|
||||
("11", "Movie 09", 3),
|
||||
("22", "Movie 01", 4),
|
||||
("22", "Movie 02", 5),
|
||||
("22", "Movie 03", 1),
|
||||
("22", "Movie 05", 3),
|
||||
("22", "Movie 06", 3),
|
||||
("22", "Movie 07", 5),
|
||||
("22", "Movie 08", 1),
|
||||
("22", "Movie 10", 3),
|
||||
("33", "Movie 01", 4),
|
||||
("33", "Movie 03", 1),
|
||||
("33", "Movie 04", 5),
|
||||
("33", "Movie 05", 3),
|
||||
("33", "Movie 06", 4),
|
||||
("33", "Movie 08", 1),
|
||||
("33", "Movie 09", 5),
|
||||
("33", "Movie 10", 3),
|
||||
("44", "Movie 01", 4),
|
||||
("44", "Movie 02", 5),
|
||||
("44", "Movie 03", 1),
|
||||
("44", "Movie 05", 3),
|
||||
("44", "Movie 06", 4),
|
||||
("44", "Movie 07", 5),
|
||||
("44", "Movie 08", 1),
|
||||
("44", "Movie 10", 3)
|
||||
], ["customerIDOrg", "itemIDOrg", "rating"])
|
||||
.dropDuplicates()
|
||||
.cache())
|
||||
|
||||
recommendationIndexer = (RecommendationIndexer()
|
||||
.setUserInputCol("customerIDOrg")
|
||||
.setUserOutputCol("customerID")
|
||||
.setItemInputCol("itemIDOrg")
|
||||
.setItemOutputCol("itemID")
|
||||
.setRatingCol("rating"))
|
||||
|
||||
algo = (SAR()
|
||||
.setUserCol("customerID")
|
||||
.setItemCol("itemID")
|
||||
.setRatingCol("rating")
|
||||
.setTimeCol("timestamp")
|
||||
.setSupportThreshold(1)
|
||||
.setSimilarityFunction("jacccard")
|
||||
.setActivityTimeFormat("EEE MMM dd HH:mm:ss Z yyyy"))
|
||||
|
||||
adapter = (RankingAdapter()
|
||||
.setK(5)
|
||||
.setRecommender(algo))
|
||||
|
||||
res1 = recommendationIndexer.fit(ratings).transform(ratings).cache()
|
||||
|
||||
adapter.fit(res1).transform(res1).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.recommendation._
|
||||
import spark.implicits._
|
||||
|
||||
val ratings = (Seq(
|
||||
("11", "Movie 01", 2),
|
||||
("11", "Movie 03", 1),
|
||||
("11", "Movie 04", 5),
|
||||
("11", "Movie 05", 3),
|
||||
("11", "Movie 06", 4),
|
||||
("11", "Movie 07", 1),
|
||||
("11", "Movie 08", 5),
|
||||
("11", "Movie 09", 3),
|
||||
("22", "Movie 01", 4),
|
||||
("22", "Movie 02", 5),
|
||||
("22", "Movie 03", 1),
|
||||
("22", "Movie 05", 3),
|
||||
("22", "Movie 06", 3),
|
||||
("22", "Movie 07", 5),
|
||||
("22", "Movie 08", 1),
|
||||
("22", "Movie 10", 3),
|
||||
("33", "Movie 01", 4),
|
||||
("33", "Movie 03", 1),
|
||||
("33", "Movie 04", 5),
|
||||
("33", "Movie 05", 3),
|
||||
("33", "Movie 06", 4),
|
||||
("33", "Movie 08", 1),
|
||||
("33", "Movie 09", 5),
|
||||
("33", "Movie 10", 3),
|
||||
("44", "Movie 01", 4),
|
||||
("44", "Movie 02", 5),
|
||||
("44", "Movie 03", 1),
|
||||
("44", "Movie 05", 3),
|
||||
("44", "Movie 06", 4),
|
||||
("44", "Movie 07", 5),
|
||||
("44", "Movie 08", 1),
|
||||
("44", "Movie 10", 3))
|
||||
.toDF("customerIDOrg", "itemIDOrg", "rating")
|
||||
.dropDuplicates()
|
||||
.cache())
|
||||
|
||||
val recommendationIndexer = (new RecommendationIndexer()
|
||||
.setUserInputCol("customerIDOrg")
|
||||
.setUserOutputCol("customerID")
|
||||
.setItemInputCol("itemIDOrg")
|
||||
.setItemOutputCol("itemID")
|
||||
.setRatingCol("rating"))
|
||||
|
||||
val algo = (new SAR()
|
||||
.setUserCol("customerID")
|
||||
.setItemCol("itemID")
|
||||
.setRatingCol("rating")
|
||||
.setTimeCol("timestamp")
|
||||
.setSupportThreshold(1)
|
||||
.setSimilarityFunction("jacccard")
|
||||
.setActivityTimeFormat("EEE MMM dd HH:mm:ss Z yyyy"))
|
||||
|
||||
val adapter = (new RankingAdapter()
|
||||
.setK(5)
|
||||
.setRecommender(algo))
|
||||
|
||||
val res1 = recommendationIndexer.fit(ratings).transform(ratings).cache()
|
||||
|
||||
adapter.fit(res1).transform(res1).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="SAR"
|
||||
py="synapse.ml.recommendation.html#module-synapse.ml.recommendation.SAR"
|
||||
scala="com/microsoft/azure/synapse/ml/recommendation/SAR.html"
|
||||
csharp="classSynapse_1_1ML_1_1Recommendation_1_1SAR.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/recommendation/SAR.scala" />
|
||||
|
|
@ -0,0 +1,219 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Stages
|
||||
|
||||
### ClassBalancer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.stages import *
|
||||
|
||||
df = (spark.createDataFrame([
|
||||
(0, 1.0, "Hi I"),
|
||||
(1, 1.0, "I wish for snow today"),
|
||||
(2, 2.0, "I wish for snow today"),
|
||||
(3, 2.0, "I wish for snow today"),
|
||||
(4, 2.0, "I wish for snow today"),
|
||||
(5, 2.0, "I wish for snow today"),
|
||||
(6, 0.0, "I wish for snow today"),
|
||||
(7, 1.0, "I wish for snow today"),
|
||||
(8, 0.0, "we Cant go to the park, because of the snow!"),
|
||||
(9, 2.0, "")
|
||||
], ["index", "label", "sentence"]))
|
||||
|
||||
cb = ClassBalancer().setInputCol("label")
|
||||
|
||||
cb.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.stages._
|
||||
|
||||
val df = Seq(
|
||||
(0, 1.0, "Hi I"),
|
||||
(1, 1.0, "I wish for snow today"),
|
||||
(2, 2.0, "I wish for snow today"),
|
||||
(3, 2.0, "I wish for snow today"),
|
||||
(4, 2.0, "I wish for snow today"),
|
||||
(5, 2.0, "I wish for snow today"),
|
||||
(6, 0.0, "I wish for snow today"),
|
||||
(7, 1.0, "I wish for snow today"),
|
||||
(8, 0.0, "we Cant go to the park, because of the snow!"),
|
||||
(9, 2.0, "")).toDF("index", "label", "sentence")
|
||||
|
||||
val cb = new ClassBalancer().setInputCol("label")
|
||||
|
||||
cb.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ClassBalancer"
|
||||
py="synapse.ml.stages.html#module-synapse.ml.stages.ClassBalancer"
|
||||
scala="com/microsoft/azure/synapse/ml/stages/ClassBalancer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Stages_1_1ClassBalancer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/stages/ClassBalancer.scala" />
|
||||
|
||||
|
||||
### MultiColumnAdapter
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.stages import *
|
||||
from pyspark.ml.feature import Tokenizer
|
||||
|
||||
df = (spark.createDataFrame([
|
||||
(0, "This is a test", "this is one too"),
|
||||
(1, "could be a test", "bar"),
|
||||
(2, "foo", "bar"),
|
||||
(3, "foo", "maybe not")
|
||||
], ["label", "words1", "words2"]))
|
||||
|
||||
stage1 = Tokenizer()
|
||||
mca = (MultiColumnAdapter()
|
||||
.setBaseStage(stage1)
|
||||
.setInputCols(["words1", "words2"])
|
||||
.setOutputCols(["output1", "output2"]))
|
||||
|
||||
mca.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.stages._
|
||||
import org.apache.spark.ml.feature.Tokenizer
|
||||
|
||||
val df = (Seq(
|
||||
(0, "This is a test", "this is one too"),
|
||||
(1, "could be a test", "bar"),
|
||||
(2, "foo", "bar"),
|
||||
(3, "foo", "maybe not"))
|
||||
.toDF("label", "words1", "words2"))
|
||||
|
||||
val stage1 = new Tokenizer()
|
||||
val mca = (new MultiColumnAdapter()
|
||||
.setBaseStage(stage1)
|
||||
.setInputCols(Array[String]("words1", "words2"))
|
||||
.setOutputCols(Array[String]("output1", "output2")))
|
||||
|
||||
mca.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="MultiColumnAdapter"
|
||||
py="synapse.ml.stages.html#module-synapse.ml.stages.MultiColumnAdapter"
|
||||
scala="com/microsoft/azure/synapse/ml/stages/MultiColumnAdapter.html"
|
||||
csharp="classSynapse_1_1ML_1_1Stages_1_1MultiColumnAdapter.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/stages/MultiColumnAdapter.scala" />
|
||||
|
||||
|
||||
### Timer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.stages import *
|
||||
from pyspark.ml.feature import *
|
||||
|
||||
df = (spark.createDataFrame([
|
||||
(0, "Hi I"),
|
||||
(1, "I wish for snow today"),
|
||||
(2, "we Cant go to the park, because of the snow!"),
|
||||
(3, "")
|
||||
], ["label", "sentence"]))
|
||||
|
||||
tok = (Tokenizer()
|
||||
.setInputCol("sentence")
|
||||
.setOutputCol("tokens"))
|
||||
|
||||
df2 = Timer().setStage(tok).fit(df).transform(df)
|
||||
|
||||
df3 = HashingTF().setInputCol("tokens").setOutputCol("hash").transform(df2)
|
||||
|
||||
idf = IDF().setInputCol("hash").setOutputCol("idf")
|
||||
timer = Timer().setStage(idf)
|
||||
|
||||
timer.fit(df3).transform(df3).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.stages._
|
||||
import org.apache.spark.ml.feature._
|
||||
|
||||
val df = (Seq(
|
||||
(0, "Hi I"),
|
||||
(1, "I wish for snow today"),
|
||||
(2, "we Cant go to the park, because of the snow!"),
|
||||
(3, "")
|
||||
).toDF("label", "sentence"))
|
||||
|
||||
val tok = (new Tokenizer()
|
||||
.setInputCol("sentence")
|
||||
.setOutputCol("tokens"))
|
||||
|
||||
val df2 = new Timer().setStage(tok).fit(df).transform(df)
|
||||
|
||||
val df3 = new HashingTF().setInputCol("tokens").setOutputCol("hash").transform(df2)
|
||||
|
||||
val idf = new IDF().setInputCol("hash").setOutputCol("idf")
|
||||
val timer = new Timer().setStage(idf)
|
||||
|
||||
timer.fit(df3).transform(df3).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="Timer"
|
||||
py="synapse.ml.stages.html#module-synapse.ml.stages.Timer"
|
||||
scala="com/microsoft/azure/synapse/ml/stages/Timer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Stages_1_1Timer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/stages/Timer.scala" />
|
||||
|
|
@ -0,0 +1,171 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Train
|
||||
|
||||
### TrainClassifier
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.train import *
|
||||
from pyspark.ml.classification import LogisticRegression
|
||||
|
||||
df = spark.createDataFrame([
|
||||
(0, 2, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, 0.50, 1),
|
||||
(0, 4, 0.78, 0.99, 2),
|
||||
(1, 5, 0.12, 0.34, 3),
|
||||
(0, 1, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, 0.50, 1),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3),
|
||||
(0, 0, 0.50, 0.60, 0),
|
||||
(1, 2, 0.40, 0.50, 1),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3)],
|
||||
["Label", "col1", "col2", "col3", "col4"]
|
||||
)
|
||||
|
||||
tc = (TrainClassifier()
|
||||
.setModel(LogisticRegression())
|
||||
.setLabelCol("Label"))
|
||||
|
||||
tc.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.train._
|
||||
import org.apache.spark.ml.classification.LogisticRegression
|
||||
|
||||
val df = (Seq(
|
||||
(0, 2, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, 0.50, 1),
|
||||
(0, 4, 0.78, 0.99, 2),
|
||||
(1, 5, 0.12, 0.34, 3),
|
||||
(0, 1, 0.50, 0.60, 0),
|
||||
(1, 3, 0.40, 0.50, 1),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3),
|
||||
(0, 0, 0.50, 0.60, 0),
|
||||
(1, 2, 0.40, 0.50, 1),
|
||||
(0, 3, 0.78, 0.99, 2),
|
||||
(1, 4, 0.12, 0.34, 3))
|
||||
.toDF("Label", "col1", "col2", "col3", "col4"))
|
||||
|
||||
val tc = (new TrainClassifier()
|
||||
.setModel(new LogisticRegression())
|
||||
.setLabelCol("Label"))
|
||||
|
||||
tc.fit(df).transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TrainClassifier"
|
||||
py="synapse.ml.train.html#module-synapse.ml.train.TrainClassifier"
|
||||
scala="com/microsoft/azure/synapse/ml/train/TrainClassifier.html"
|
||||
csharp="classSynapse_1_1ML_1_1Train_1_1TrainClassifier.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/train/TrainClassifier.scala" />
|
||||
|
||||
|
||||
### TrainRegressor
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.train import *
|
||||
from pyspark.ml.regression import LinearRegression
|
||||
|
||||
dataset = (spark.createDataFrame([
|
||||
(0.0, 2, 0.50, 0.60, 0.0),
|
||||
(1.0, 3, 0.40, 0.50, 1.0),
|
||||
(2.0, 4, 0.78, 0.99, 2.0),
|
||||
(3.0, 5, 0.12, 0.34, 3.0),
|
||||
(0.0, 1, 0.50, 0.60, 0.0),
|
||||
(1.0, 3, 0.40, 0.50, 1.0),
|
||||
(2.0, 3, 0.78, 0.99, 2.0),
|
||||
(3.0, 4, 0.12, 0.34, 3.0),
|
||||
(0.0, 0, 0.50, 0.60, 0.0),
|
||||
(1.0, 2, 0.40, 0.50, 1.0),
|
||||
(2.0, 3, 0.78, 0.99, 2.0),
|
||||
(3.0, 4, 0.12, 0.34, 3.0)],
|
||||
["label", "col1", "col2", "col3", "col4"]))
|
||||
|
||||
linearRegressor = (LinearRegression()
|
||||
.setRegParam(0.3)
|
||||
.setElasticNetParam(0.8))
|
||||
trainRegressor = (TrainRegressor()
|
||||
.setModel(linearRegressor)
|
||||
.setLabelCol("label"))
|
||||
|
||||
trainRegressor.fit(dataset).transform(dataset).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.train._
|
||||
import org.apache.spark.ml.regression.LinearRegression
|
||||
|
||||
val dataset = (spark.createDataFrame(Seq(
|
||||
(0.0, 2, 0.50, 0.60, 0.0),
|
||||
(1.0, 3, 0.40, 0.50, 1.0),
|
||||
(2.0, 4, 0.78, 0.99, 2.0),
|
||||
(3.0, 5, 0.12, 0.34, 3.0),
|
||||
(0.0, 1, 0.50, 0.60, 0.0),
|
||||
(1.0, 3, 0.40, 0.50, 1.0),
|
||||
(2.0, 3, 0.78, 0.99, 2.0),
|
||||
(3.0, 4, 0.12, 0.34, 3.0),
|
||||
(0.0, 0, 0.50, 0.60, 0.0),
|
||||
(1.0, 2, 0.40, 0.50, 1.0),
|
||||
(2.0, 3, 0.78, 0.99, 2.0),
|
||||
(3.0, 4, 0.12, 0.34, 3.0)))
|
||||
.toDF("label", "col1", "col2", "col3", "col4"))
|
||||
|
||||
val linearRegressor = (new LinearRegression()
|
||||
.setRegParam(0.3)
|
||||
.setElasticNetParam(0.8))
|
||||
val trainRegressor = (new TrainRegressor()
|
||||
.setModel(linearRegressor)
|
||||
.setLabelCol("label"))
|
||||
|
||||
trainRegressor.fit(dataset).transform(dataset).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TrainRegressor"
|
||||
py="synapse.ml.train.html#module-synapse.ml.train.TrainRegressor"
|
||||
scala="com/microsoft/azure/synapse/ml/train/TrainRegressor.html"
|
||||
csharp="classSynapse_1_1ML_1_1Train_1_1TrainRegressor.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/train/TrainRegressor.scala" />
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
---
|
||||
title: Estimators - Causal
|
||||
sidebar_label: Causal Inference
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
# Causal Inference
|
||||
|
||||
import DoubleMLEstimator, {toc as DoubleMLEstimatorTOC} from './causal/_causalInferenceDML.md';
|
||||
|
||||
<DoubleMLEstimator/>
|
||||
|
||||
export const toc = [...DoubleMLEstimatorTOC]
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
---
|
||||
title: Estimators - Cognitive
|
||||
sidebar_label: Cognitive
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
|
||||
import MAD, {toc as MADTOC} from './cognitive/_MAD.md';
|
||||
|
||||
<MAD/>
|
||||
|
||||
export const toc = [...MADTOC]
|
||||
|
|
@ -0,0 +1,42 @@
|
|||
---
|
||||
title: Estimators - Core
|
||||
sidebar_label: Core
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
|
||||
import AutoML, {toc as AutoMLTOC} from './core/_AutoML.md';
|
||||
|
||||
<AutoML/>
|
||||
|
||||
|
||||
import Featurize, {toc as FeaturizeTOC} from './core/_Featurize.md';
|
||||
|
||||
<Featurize/>
|
||||
|
||||
|
||||
import IsolationForest, {toc as IsolationForestTOC} from './core/_IsolationForest.md';
|
||||
|
||||
<IsolationForest/>
|
||||
|
||||
|
||||
import NN, {toc as NNTOC} from './core/_NN.md';
|
||||
|
||||
<NN/>
|
||||
|
||||
|
||||
import Recommendation, {toc as RecommendationTOC} from './core/_Recommendation.md';
|
||||
|
||||
<Recommendation/>
|
||||
|
||||
|
||||
import Stages, {toc as StagesTOC} from './core/_Stages.md';
|
||||
|
||||
<Stages/>
|
||||
|
||||
import Train, {toc as TrainTOC} from './core/_Train.md';
|
||||
|
||||
<Train/>
|
||||
|
||||
export const toc = [...AutoMLTOC, ...FeaturizeTOC, ...IsolationForestTOC,
|
||||
...NNTOC, ...RecommendationTOC, ...StagesTOC, ...TrainTOC]
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
---
|
||||
title: Estimators - LightGBM
|
||||
sidebar_label: LightGBM
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
# LightGBM
|
||||
|
||||
import LightGBM, {toc as LightGBMTOC} from './_LightGBM.md';
|
||||
|
||||
<LightGBM/>
|
||||
|
||||
export const toc = [...LightGBMTOC]
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
---
|
||||
title: Estimators - Vowpal Wabbit
|
||||
sidebar_label: Vowpal Wabbit
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
# Vowpal Wabbit
|
||||
|
||||
import VW, {toc as VWTOC} from './_VW.md';
|
||||
|
||||
<VW/>
|
||||
|
||||
export const toc = [...VWTOC]
|
||||
|
|
@ -0,0 +1,121 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## ImageTransformer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.opencv import *
|
||||
from pyspark.sql.types import FloatType
|
||||
|
||||
# images = (spark.read.format("image")
|
||||
# .option("dropInvalid", True)
|
||||
# .load("wasbs://publicwasb@mmlspark.blob.core.windows.net/explainers/images/david-lusvardi-dWcUncxocQY-unsplash.jpg"))
|
||||
|
||||
it = (ImageTransformer(inputCol="image", outputCol="features")
|
||||
.resize(224, True)
|
||||
.centerCrop(height=224, width=224)
|
||||
.normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], color_scale_factor = 1/255)
|
||||
.setTensorElementType(FloatType()))
|
||||
|
||||
# it.transform(images).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.opencv._
|
||||
|
||||
val images = (spark.read.format("image")
|
||||
.option("dropInvalid", true)
|
||||
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/explainers/images/david-lusvardi-dWcUncxocQY-unsplash.jpg"))
|
||||
|
||||
val it = (new ImageTransformer()
|
||||
.setOutputCol("out")
|
||||
.resize(height = 15, width = 10))
|
||||
|
||||
it.transform(images).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ImageTransformer"
|
||||
py="synapse.ml.opencv.html#module-synapse.ml.opencv.ImageTransformer"
|
||||
scala="com/microsoft/azure/synapse/ml/opencv/ImageTransformer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Opencv_1_1ImageTransformer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/opencv/src/main/scala/com/microsoft/azure/synapse/ml/opencv/ImageTransformer.scala" />
|
||||
|
||||
|
||||
## ImageSetAugmenter
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.opencv import *
|
||||
|
||||
# images = (spark.read.format("image")
|
||||
# .option("dropInvalid", True)
|
||||
# .load("wasbs://publicwasb@mmlspark.blob.core.windows.net/explainers/images/david-lusvardi-dWcUncxocQY-unsplash.jpg"))
|
||||
|
||||
isa = (ImageSetAugmenter()
|
||||
.setInputCol("image")
|
||||
.setOutputCol("augmented")
|
||||
.setFlipLeftRight(True)
|
||||
.setFlipUpDown(True))
|
||||
|
||||
# it.transform(images).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.opencv._
|
||||
|
||||
val images = (spark.read.format("image")
|
||||
.option("dropInvalid", true)
|
||||
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/explainers/images/david-lusvardi-dWcUncxocQY-unsplash.jpg"))
|
||||
|
||||
val isa = (new ImageSetAugmenter()
|
||||
.setInputCol("image")
|
||||
.setOutputCol("augmented")
|
||||
.setFlipLeftRight(true)
|
||||
.setFlipUpDown(true))
|
||||
|
||||
isa.transform(images).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ImageSetAugmenter"
|
||||
py="synapse.ml.opencv.html#module-synapse.ml.opencv.ImageSetAugmenter"
|
||||
scala="com/microsoft/azure/synapse/ml/opencv/ImageSetAugmenter.html"
|
||||
csharp="classSynapse_1_1ML_1_1Opencv_1_1ImageSetAugmenter.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/opencv/src/main/scala/com/microsoft/azure/synapse/ml/opencv/ImageSetAugmenter.scala" />
|
||||
|
|
@ -0,0 +1,297 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## VectorZipper
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
{label: `.NET`, value: `csharp`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.vw import *
|
||||
|
||||
df = spark.createDataFrame([
|
||||
("action1_f", "action2_f"),
|
||||
("action1_f", "action2_f"),
|
||||
("action1_f", "action2_f"),
|
||||
("action1_f", "action2_f")
|
||||
], ["action1", "action2"])
|
||||
|
||||
actionOneFeaturizer = (VowpalWabbitFeaturizer()
|
||||
.setInputCols(["action1"])
|
||||
.setOutputCol("sequence_one"))
|
||||
|
||||
actionTwoFeaturizer = (VowpalWabbitFeaturizer()
|
||||
.setInputCols(["action2"])
|
||||
.setOutputCol("sequence_two"))
|
||||
|
||||
seqDF = actionTwoFeaturizer.transform(actionOneFeaturizer.transform(df))
|
||||
|
||||
vectorZipper = (VectorZipper()
|
||||
.setInputCols(["sequence_one", "sequence_two"])
|
||||
.setOutputCol("out"))
|
||||
|
||||
vectorZipper.transform(seqDF).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.vw._
|
||||
|
||||
val df = (Seq(
|
||||
("action1_f", "action2_f"),
|
||||
("action1_f", "action2_f"),
|
||||
("action1_f", "action2_f"),
|
||||
("action1_f", "action2_f")
|
||||
).toDF("action1", "action2"))
|
||||
|
||||
val actionOneFeaturizer = (new VowpalWabbitFeaturizer()
|
||||
.setInputCols(Array("action1"))
|
||||
.setOutputCol("sequence_one"))
|
||||
|
||||
val actionTwoFeaturizer = (new VowpalWabbitFeaturizer()
|
||||
.setInputCols(Array("action2"))
|
||||
.setOutputCol("sequence_two"))
|
||||
|
||||
val seqDF = actionTwoFeaturizer.transform(actionOneFeaturizer.transform(df))
|
||||
|
||||
val vectorZipper = (new VectorZipper()
|
||||
.setInputCols(Array("sequence_one", "sequence_two"))
|
||||
.setOutputCol("out"))
|
||||
|
||||
vectorZipper.transform(seqDF).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="csharp">
|
||||
|
||||
```csharp
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using Synapse.ML.Vw;
|
||||
using Microsoft.Spark.Sql;
|
||||
using Microsoft.Spark.Sql.Types;
|
||||
|
||||
namespace SynapseMLApp
|
||||
{
|
||||
class Program
|
||||
{
|
||||
static void Main(string[] args)
|
||||
{
|
||||
SparkSession spark =
|
||||
SparkSession
|
||||
.Builder()
|
||||
.AppName("Example")
|
||||
.GetOrCreate();
|
||||
|
||||
DataFrame df = spark.CreateDataFrame(
|
||||
new List<GenericRow>
|
||||
{
|
||||
new GenericRow(new object[] {"action1_f", "action2_f"}),
|
||||
new GenericRow(new object[] {"action1_f", "action2_f"}),
|
||||
new GenericRow(new object[] {"action1_f", "action2_f"}),
|
||||
new GenericRow(new object[] {"action1_f", "action2_f"})
|
||||
},
|
||||
new StructType(new List<StructField>
|
||||
{
|
||||
new StructField("action1", new StringType()),
|
||||
new StructField("action2", new StringType())
|
||||
})
|
||||
);
|
||||
|
||||
var actionOneFeaturizer = new VowpalWabbitFeaturizer()
|
||||
.SetInputCols(new string[]{"action1"})
|
||||
.SetOutputCol("sequence_one");
|
||||
var actionTwoFeaturizer = new VowpalWabbitFeaturizer()
|
||||
.SetInputCols(new string[]{"action2"})
|
||||
.SetOutputCol("sequence_two");
|
||||
var seqDF = actionTwoFeaturizer.Transform(actionOneFeaturizer.Transform(df));
|
||||
|
||||
var vectorZipper = new VectorZipper()
|
||||
.SetInputCols(new string[]{"sequence_one", "sequence_two"})
|
||||
.SetOutputCol("out");
|
||||
vectorZipper.Transform(seqDF).Show();
|
||||
|
||||
spark.Stop();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VectorZipper"
|
||||
py="synapse.ml.vw.html#module-synapse.ml.vw.VectorZipper"
|
||||
scala="com/microsoft/azure/synapse/ml/vw/VectorZipper.html"
|
||||
csharp="classSynapse_1_1ML_1_1Vw_1_1VectorZipper.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/vw/src/main/scala/com/microsoft/azure/synapse/ml/vw/VectorZipper.scala" />
|
||||
|
||||
|
||||
## VowpalWabbitClassifier
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.vw import *
|
||||
|
||||
vw = (VowpalWabbitClassifier()
|
||||
.setNumBits(10)
|
||||
.setLearningRate(3.1)
|
||||
.setPowerT(0)
|
||||
.setLabelConversion(False))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.vw._
|
||||
|
||||
val vw = (new VowpalWabbitClassifier()
|
||||
.setNumBits(10)
|
||||
.setLearningRate(3.1)
|
||||
.setPowerT(0)
|
||||
.setLabelConversion(false))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VowpalWabbitClassifier"
|
||||
py="synapse.ml.vw.html#module-synapse.ml.vw.VowpalWabbitClassifier"
|
||||
scala="com/microsoft/azure/synapse/ml/vw/VowpalWabbitClassifier.html"
|
||||
csharp="classSynapse_1_1ML_1_1Vw_1_1VowpalWabbitClassifier.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/vw/src/main/scala/com/microsoft/azure/synapse/ml/vw/VowpalWabbitClassifier.scala" />
|
||||
|
||||
|
||||
## VowpalWabbitFeaturizer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.vw import *
|
||||
|
||||
featurizer = (VowpalWabbitFeaturizer()
|
||||
.setStringSplitInputCols(["in"])
|
||||
.setPreserveOrderNumBits(2)
|
||||
.setNumBits(18)
|
||||
.setPrefixStringsWithColumnName(False)
|
||||
.setOutputCol("features"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.vw._
|
||||
|
||||
val featurizer = (new VowpalWabbitFeaturizer()
|
||||
.setStringSplitInputCols(Array("in"))
|
||||
.setPreserveOrderNumBits(2)
|
||||
.setNumBits(18)
|
||||
.setPrefixStringsWithColumnName(false)
|
||||
.setOutputCol("features"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VowpalWabbitFeaturizer"
|
||||
py="synapse.ml.vw.html#module-synapse.ml.vw.VowpalWabbitFeaturizer"
|
||||
scala="com/microsoft/azure/synapse/ml/vw/VowpalWabbitFeaturizer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Vw_1_1VowpalWabbitFeaturizer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/vw/src/main/scala/com/microsoft/azure/synapse/ml/vw/VowpalWabbitFeaturizer.scala" />
|
||||
|
||||
|
||||
## VowpalWabbitInteractions
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.vw import *
|
||||
|
||||
interactions = (VowpalWabbitInteractions()
|
||||
.setInputCols(["v1"])
|
||||
.setOutputCol("out"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.vw._
|
||||
import org.apache.spark.ml.linalg._
|
||||
|
||||
case class Data(v1: Vector, v2: Vector, v3: Vector)
|
||||
|
||||
val df = spark.createDataFrame(Seq(Data(
|
||||
Vectors.dense(Array(1.0, 2.0, 3.0)),
|
||||
Vectors.sparse(8, Array(5), Array(4.0)),
|
||||
Vectors.sparse(11, Array(8, 9), Array(7.0, 8.0))
|
||||
)))
|
||||
|
||||
val interactions = (new VowpalWabbitInteractions()
|
||||
.setInputCols(Array("v1"))
|
||||
.setOutputCol("out"))
|
||||
|
||||
interactions.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VowpalWabbitInteractions"
|
||||
py="synapse.ml.vw.html#module-synapse.ml.vw.VowpalWabbitInteractions"
|
||||
scala="com/microsoft/azure/synapse/ml/vw/VowpalWabbitInteractions.html"
|
||||
csharp="classSynapse_1_1ML_1_1Vw_1_1VowpalWabbitInteractions.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/vw/src/main/scala/com/microsoft/azure/synapse/ml/vw/VowpalWabbitInteractions.scala" />
|
||||
|
|
@ -0,0 +1,319 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Anomaly Detection
|
||||
|
||||
### DetectLastAnomaly
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
from pyspark.sql.functions import lit
|
||||
|
||||
anomalyKey = os.environ.get("ANOMALY_API_KEY", getSecret("anomaly-api-key"))
|
||||
df = (spark.createDataFrame([
|
||||
("1972-01-01T00:00:00Z", 826.0),
|
||||
("1972-02-01T00:00:00Z", 799.0),
|
||||
("1972-03-01T00:00:00Z", 890.0),
|
||||
("1972-04-01T00:00:00Z", 900.0),
|
||||
("1972-05-01T00:00:00Z", 766.0),
|
||||
("1972-06-01T00:00:00Z", 805.0),
|
||||
("1972-07-01T00:00:00Z", 821.0),
|
||||
("1972-08-01T00:00:00Z", 20000.0),
|
||||
("1972-09-01T00:00:00Z", 883.0),
|
||||
("1972-10-01T00:00:00Z", 898.0),
|
||||
("1972-11-01T00:00:00Z", 957.0),
|
||||
("1972-12-01T00:00:00Z", 924.0),
|
||||
("1973-01-01T00:00:00Z", 881.0),
|
||||
("1973-02-01T00:00:00Z", 837.0),
|
||||
("1973-03-01T00:00:00Z", 90000.0)
|
||||
], ["timestamp", "value"])
|
||||
.withColumn("group", lit(1))
|
||||
.withColumn("inputs", struct(col("timestamp"), col("value")))
|
||||
.groupBy(col("group"))
|
||||
.agg(sort_array(collect_list(col("inputs"))).alias("inputs")))
|
||||
|
||||
dla = (DetectLastAnomaly()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation("westus2")
|
||||
.setOutputCol("anomalies")
|
||||
.setSeriesCol("inputs")
|
||||
.setGranularity("monthly")
|
||||
.setErrorCol("errors"))
|
||||
|
||||
dla.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.anomaly.DetectLastAnomaly
|
||||
import spark.implicits._
|
||||
import org.apache.spark.sql.functions.{col, collect_list, lit, sort_array, struct}
|
||||
|
||||
val anomalyKey = sys.env.getOrElse("ANOMALY_API_KEY", None)
|
||||
val df = (Seq(
|
||||
("1972-01-01T00:00:00Z", 826.0),
|
||||
("1972-02-01T00:00:00Z", 799.0),
|
||||
("1972-03-01T00:00:00Z", 890.0),
|
||||
("1972-04-01T00:00:00Z", 900.0),
|
||||
("1972-05-01T00:00:00Z", 766.0),
|
||||
("1972-06-01T00:00:00Z", 805.0),
|
||||
("1972-07-01T00:00:00Z", 821.0),
|
||||
("1972-08-01T00:00:00Z", 20000.0),
|
||||
("1972-09-01T00:00:00Z", 883.0),
|
||||
("1972-10-01T00:00:00Z", 898.0),
|
||||
("1972-11-01T00:00:00Z", 957.0),
|
||||
("1972-12-01T00:00:00Z", 924.0),
|
||||
("1973-01-01T00:00:00Z", 881.0),
|
||||
("1973-02-01T00:00:00Z", 837.0),
|
||||
("1973-03-01T00:00:00Z", 90000.0)
|
||||
).toDF("timestamp","value")
|
||||
.withColumn("group", lit(1))
|
||||
.withColumn("inputs", struct(col("timestamp"), col("value")))
|
||||
.groupBy(col("group"))
|
||||
.agg(sort_array(collect_list(col("inputs"))).alias("inputs")))
|
||||
|
||||
val dla = (new DetectLastAnomaly()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation("westus2")
|
||||
.setOutputCol("anomalies")
|
||||
.setSeriesCol("inputs")
|
||||
.setGranularity("monthly")
|
||||
.setErrorCol("errors"))
|
||||
|
||||
dla.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DetectLastAnomaly"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.DetectLastAnomaly"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/DetectLastAnomaly.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1DetectLastAnomaly.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/AnomalyDetection.scala" />
|
||||
|
||||
### DetectAnomalies
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
anomalyKey = os.environ.get("ANOMALY_API_KEY", getSecret("anomaly-api-key"))
|
||||
df = (spark.createDataFrame([
|
||||
("1972-01-01T00:00:00Z", 826.0),
|
||||
("1972-02-01T00:00:00Z", 799.0),
|
||||
("1972-03-01T00:00:00Z", 890.0),
|
||||
("1972-04-01T00:00:00Z", 900.0),
|
||||
("1972-05-01T00:00:00Z", 766.0),
|
||||
("1972-06-01T00:00:00Z", 805.0),
|
||||
("1972-07-01T00:00:00Z", 821.0),
|
||||
("1972-08-01T00:00:00Z", 20000.0),
|
||||
("1972-09-01T00:00:00Z", 883.0),
|
||||
("1972-10-01T00:00:00Z", 898.0),
|
||||
("1972-11-01T00:00:00Z", 957.0),
|
||||
("1972-12-01T00:00:00Z", 924.0),
|
||||
("1973-01-01T00:00:00Z", 881.0),
|
||||
("1973-02-01T00:00:00Z", 837.0),
|
||||
("1973-03-01T00:00:00Z", 90000.0)
|
||||
], ["timestamp", "value"])
|
||||
.withColumn("group", lit(1))
|
||||
.withColumn("inputs", struct(col("timestamp"), col("value")))
|
||||
.groupBy(col("group"))
|
||||
.agg(sort_array(collect_list(col("inputs"))).alias("inputs")))
|
||||
|
||||
da = (DetectAnomalies()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation("westus2")
|
||||
.setOutputCol("anomalies")
|
||||
.setSeriesCol("inputs")
|
||||
.setGranularity("monthly"))
|
||||
|
||||
da.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.anomaly.DetectAnomalies
|
||||
import spark.implicits._
|
||||
|
||||
val anomalyKey = sys.env.getOrElse("ANOMALY_API_KEY", None)
|
||||
val df = (Seq(
|
||||
("1972-01-01T00:00:00Z", 826.0),
|
||||
("1972-02-01T00:00:00Z", 799.0),
|
||||
("1972-03-01T00:00:00Z", 890.0),
|
||||
("1972-04-01T00:00:00Z", 900.0),
|
||||
("1972-05-01T00:00:00Z", 766.0),
|
||||
("1972-06-01T00:00:00Z", 805.0),
|
||||
("1972-07-01T00:00:00Z", 821.0),
|
||||
("1972-08-01T00:00:00Z", 20000.0),
|
||||
("1972-09-01T00:00:00Z", 883.0),
|
||||
("1972-10-01T00:00:00Z", 898.0),
|
||||
("1972-11-01T00:00:00Z", 957.0),
|
||||
("1972-12-01T00:00:00Z", 924.0),
|
||||
("1973-01-01T00:00:00Z", 881.0),
|
||||
("1973-02-01T00:00:00Z", 837.0),
|
||||
("1973-03-01T00:00:00Z", 90000.0)
|
||||
).toDF("timestamp","value")
|
||||
.withColumn("group", lit(1))
|
||||
.withColumn("inputs", struct(col("timestamp"), col("value")))
|
||||
.groupBy(col("group"))
|
||||
.agg(sort_array(collect_list(col("inputs"))).alias("inputs")))
|
||||
|
||||
val da = (new DetectAnomalies()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation("westus2")
|
||||
.setOutputCol("anomalies")
|
||||
.setSeriesCol("inputs")
|
||||
.setGranularity("monthly"))
|
||||
|
||||
da.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DetectAnomalies"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.DetectAnomalies"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/DetectAnomalies.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1DetectAnomalies.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/AnomalyDetection.scala" />
|
||||
|
||||
### SimpleDetectAnomalies
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
anomalyKey = os.environ.get("ANOMALY_API_KEY", getSecret("anomaly-api-key"))
|
||||
df = (spark.createDataFrame([
|
||||
("1972-01-01T00:00:00Z", 826.0, 1.0),
|
||||
("1972-02-01T00:00:00Z", 799.0, 1.0),
|
||||
("1972-03-01T00:00:00Z", 890.0, 1.0),
|
||||
("1972-04-01T00:00:00Z", 900.0, 1.0),
|
||||
("1972-05-01T00:00:00Z", 766.0, 1.0),
|
||||
("1972-06-01T00:00:00Z", 805.0, 1.0),
|
||||
("1972-07-01T00:00:00Z", 821.0, 1.0),
|
||||
("1972-08-01T00:00:00Z", 20000.0, 1.0),
|
||||
("1972-09-01T00:00:00Z", 883.0, 1.0),
|
||||
("1972-10-01T00:00:00Z", 898.0, 1.0),
|
||||
("1972-11-01T00:00:00Z", 957.0, 1.0),
|
||||
("1972-12-01T00:00:00Z", 924.0, 1.0),
|
||||
("1973-01-01T00:00:00Z", 881.0, 1.0),
|
||||
("1973-02-01T00:00:00Z", 837.0, 1.0),
|
||||
("1973-03-01T00:00:00Z", 90000.0, 1.0),
|
||||
("1972-01-01T00:00:00Z", 826.0, 2.0),
|
||||
("1972-02-01T00:00:00Z", 799.0, 2.0),
|
||||
("1972-03-01T00:00:00Z", 890.0, 2.0),
|
||||
("1972-04-01T00:00:00Z", 900.0, 2.0),
|
||||
("1972-05-01T00:00:00Z", 766.0, 2.0),
|
||||
("1972-06-01T00:00:00Z", 805.0, 2.0),
|
||||
("1972-07-01T00:00:00Z", 821.0, 2.0),
|
||||
("1972-08-01T00:00:00Z", 20000.0, 2.0),
|
||||
("1972-09-01T00:00:00Z", 883.0, 2.0),
|
||||
("1972-10-01T00:00:00Z", 898.0, 2.0),
|
||||
("1972-11-01T00:00:00Z", 957.0, 2.0),
|
||||
("1972-12-01T00:00:00Z", 924.0, 2.0),
|
||||
("1973-01-01T00:00:00Z", 881.0, 2.0),
|
||||
("1973-02-01T00:00:00Z", 837.0, 2.0),
|
||||
("1973-03-01T00:00:00Z", 90000.0, 2.0)
|
||||
], ["timestamp", "value", "group"]))
|
||||
|
||||
sda = (SimpleDetectAnomalies()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation("westus2")
|
||||
.setOutputCol("anomalies")
|
||||
.setGroupbyCol("group")
|
||||
.setGranularity("monthly"))
|
||||
|
||||
sda.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.anomaly.SimpleDetectAnomalies
|
||||
import spark.implicits._
|
||||
|
||||
val anomalyKey = sys.env.getOrElse("ANOMALY_API_KEY", None)
|
||||
val baseSeq = Seq(
|
||||
("1972-01-01T00:00:00Z", 826.0),
|
||||
("1972-02-01T00:00:00Z", 799.0),
|
||||
("1972-03-01T00:00:00Z", 890.0),
|
||||
("1972-04-01T00:00:00Z", 900.0),
|
||||
("1972-05-01T00:00:00Z", 766.0),
|
||||
("1972-06-01T00:00:00Z", 805.0),
|
||||
("1972-07-01T00:00:00Z", 821.0),
|
||||
("1972-08-01T00:00:00Z", 20000.0),
|
||||
("1972-09-01T00:00:00Z", 883.0),
|
||||
("1972-10-01T00:00:00Z", 898.0),
|
||||
("1972-11-01T00:00:00Z", 957.0),
|
||||
("1972-12-01T00:00:00Z", 924.0),
|
||||
("1973-01-01T00:00:00Z", 881.0),
|
||||
("1973-02-01T00:00:00Z", 837.0),
|
||||
("1973-03-01T00:00:00Z", 9000.0)
|
||||
)
|
||||
val df = (baseSeq.map(p => (p._1,p._2,1.0))
|
||||
.++(baseSeq.map(p => (p._1,p._2,2.0)))
|
||||
.toDF("timestamp","value","group"))
|
||||
|
||||
val sda = (new SimpleDetectAnomalies()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation("westus2")
|
||||
.setOutputCol("anomalies")
|
||||
.setGroupbyCol("group")
|
||||
.setGranularity("monthly"))
|
||||
|
||||
sda.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="SimpleDetectAnomalies"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.SimpleDetectAnomalies"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/SimpleDetectAnomalies.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1SimpleDetectAnomalies.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/AnomalyDetection.scala" />
|
||||
|
|
@ -0,0 +1,153 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## Azure Search
|
||||
|
||||
### AzureSearch
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
azureSearchKey = os.environ.get("AZURE_SEARCH_KEY", getSecret("azure-search-key"))
|
||||
testServiceName = "mmlspark-azure-search"
|
||||
|
||||
indexName = "test-website"
|
||||
|
||||
def createSimpleIndexJson(indexName):
|
||||
json_str = """
|
||||
{
|
||||
"name": "%s",
|
||||
"fields": [
|
||||
{
|
||||
"name": "id",
|
||||
"type": "Edm.String",
|
||||
"key": true,
|
||||
"facetable": false
|
||||
},
|
||||
{
|
||||
"name": "fileName",
|
||||
"type": "Edm.String",
|
||||
"searchable": false,
|
||||
"sortable": false,
|
||||
"facetable": false
|
||||
},
|
||||
{
|
||||
"name": "text",
|
||||
"type": "Edm.String",
|
||||
"filterable": false,
|
||||
"sortable": false,
|
||||
"facetable": false
|
||||
}
|
||||
]
|
||||
}
|
||||
"""
|
||||
|
||||
return json_str % indexName
|
||||
|
||||
df = (spark.createDataFrame([
|
||||
("upload", "0", "file0", "text0"),
|
||||
("upload", "1", "file1", "text1"),
|
||||
("upload", "2", "file2", "text2"),
|
||||
("upload", "3", "file3", "text3")
|
||||
], ["searchAction", "id", "fileName", "text"]))
|
||||
|
||||
ad = (AddDocuments()
|
||||
.setSubscriptionKey(azureSearchKey)
|
||||
.setServiceName(testServiceName)
|
||||
.setOutputCol("out")
|
||||
.setErrorCol("err")
|
||||
.setIndexName(indexName)
|
||||
.setActionCol("searchAction"))
|
||||
|
||||
ad.transform(df).show()
|
||||
|
||||
AzureSearchWriter.writeToAzureSearch(df,
|
||||
subscriptionKey=azureSearchKey,
|
||||
actionCol="searchAction",
|
||||
serviceName=testServiceName,
|
||||
indexJson=createSimpleIndexJson(indexName))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.search.{AddDocuments, AzureSearchWriter}
|
||||
import spark.implicits._
|
||||
|
||||
val azureSearchKey = sys.env.getOrElse("AZURE_SEARCH_KEY", None)
|
||||
val testServiceName = "mmlspark-azure-search"
|
||||
|
||||
val indexName = "test-website"
|
||||
|
||||
def createSimpleIndexJson(indexName: String) = {
|
||||
s"""
|
||||
|{
|
||||
| "name": "$indexName",
|
||||
| "fields": [
|
||||
| {
|
||||
| "name": "id",
|
||||
| "type": "Edm.String",
|
||||
| "key": true,
|
||||
| "facetable": false
|
||||
| },
|
||||
| {
|
||||
| "name": "fileName",
|
||||
| "type": "Edm.String",
|
||||
| "searchable": false,
|
||||
| "sortable": false,
|
||||
| "facetable": false
|
||||
| },
|
||||
| {
|
||||
| "name": "text",
|
||||
| "type": "Edm.String",
|
||||
| "filterable": false,
|
||||
| "sortable": false,
|
||||
| "facetable": false
|
||||
| }
|
||||
| ]
|
||||
| }
|
||||
""".stripMargin
|
||||
}
|
||||
|
||||
val df = ((0 until 4)
|
||||
.map(i => ("upload", s"$i", s"file$i", s"text$i"))
|
||||
.toDF("searchAction", "id", "fileName", "text"))
|
||||
|
||||
val ad = (new AddDocuments()
|
||||
.setSubscriptionKey(azureSearchKey)
|
||||
.setServiceName(testServiceName)
|
||||
.setOutputCol("out")
|
||||
.setErrorCol("err")
|
||||
.setIndexName(indexName)
|
||||
.setActionCol("searchAction"))
|
||||
|
||||
ad.transform(df).show()
|
||||
|
||||
AzureSearchWriter.write(df,
|
||||
Map("subscriptionKey" -> azureSearchKey,
|
||||
"actionCol" -> "searchAction",
|
||||
"serviceName" -> testServiceName,
|
||||
"indexJson" -> createSimpleIndexJson(indexName)))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AzureSearch"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AzureSearch"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AzureSearch.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AddDocuments.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/AzureSearch.scala" />
|
||||
|
|
@ -0,0 +1,95 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## Bing Image Search
|
||||
|
||||
### BingImageSearch
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
bingSearchKey = os.environ.get("BING_SEARCH_KEY", getSecret("bing-search-key"))
|
||||
|
||||
# Number of images Bing will return per query
|
||||
imgsPerBatch = 10
|
||||
# A list of offsets, used to page into the search results
|
||||
offsets = [(i*imgsPerBatch,) for i in range(100)]
|
||||
# Since web content is our data, we create a dataframe with options on that data: offsets
|
||||
bingParameters = spark.createDataFrame(offsets, ["offset"])
|
||||
|
||||
# Run the Bing Image Search service with our text query
|
||||
bingSearch = (BingImageSearch()
|
||||
.setSubscriptionKey(bingSearchKey)
|
||||
.setOffsetCol("offset")
|
||||
.setQuery("Martin Luther King Jr. quotes")
|
||||
.setCount(imgsPerBatch)
|
||||
.setOutputCol("images"))
|
||||
|
||||
# Transformer that extracts and flattens the richly structured output of Bing Image Search into a simple URL column
|
||||
getUrls = BingImageSearch.getUrlTransformer("images", "url")
|
||||
|
||||
# This displays the full results returned
|
||||
bingSearch.transform(bingParameters).show()
|
||||
|
||||
# Since we have two services, they are put into a pipeline
|
||||
pipeline = PipelineModel(stages=[bingSearch, getUrls])
|
||||
|
||||
# Show the results of your search: image URLs
|
||||
pipeline.transform(bingParameters).show()
|
||||
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.bing.BingImageSearch
|
||||
import spark.implicits._
|
||||
|
||||
val bingSearchKey = sys.env.getOrElse("BING_SEARCH_KEY", None)
|
||||
|
||||
// Number of images Bing will return per query
|
||||
val imgsPerBatch = 10
|
||||
// A list of offsets, used to page into the search results
|
||||
val offsets = (0 until 100).map(i => i*imgsPerBatch)
|
||||
// Since web content is our data, we create a dataframe with options on that data: offsets
|
||||
val bingParameters = Seq(offsets).toDF("offset")
|
||||
|
||||
// Run the Bing Image Search service with our text query
|
||||
val bingSearch = (new BingImageSearch()
|
||||
.setSubscriptionKey(bingSearchKey)
|
||||
.setOffsetCol("offset")
|
||||
.setQuery("Martin Luther King Jr. quotes")
|
||||
.setCount(imgsPerBatch)
|
||||
.setOutputCol("images"))
|
||||
|
||||
// Transformer that extracts and flattens the richly structured output of Bing Image Search into a simple URL column
|
||||
val getUrls = BingImageSearch.getUrlTransformer("images", "url")
|
||||
|
||||
// This displays the full results returned
|
||||
bingSearch.transform(bingParameters).show()
|
||||
|
||||
// Show the results of your search: image URLs
|
||||
getUrls.transform(bingSearch.transform(bingParameters)).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="BingImageSearch"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.BingImageSearch"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/BingImageSearch.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1BingImageSearch.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/BingImageSearch.scala" />
|
||||
|
|
@ -0,0 +1,547 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Computer Vision
|
||||
|
||||
### OCR
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test1.jpg", ),
|
||||
], ["url", ])
|
||||
|
||||
ocr = (OCR()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setDetectOrientation(True)
|
||||
.setOutputCol("ocr"))
|
||||
|
||||
ocr.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.vision.OCR
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/OCR/test1.jpg"
|
||||
).toDF("url")
|
||||
|
||||
|
||||
val ocr = (new OCR()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setDetectOrientation(true)
|
||||
.setOutputCol("ocr"))
|
||||
|
||||
ocr.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="OCR"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.OCR"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/OCR.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1OCR.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/ComputerVision.scala" />
|
||||
|
||||
|
||||
### AnalyzeImage
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test1.jpg", "en"),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test2.png", None),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test3.png", "en")
|
||||
], ["image", "language"])
|
||||
|
||||
|
||||
ai = (AnalyzeImage()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("image")
|
||||
.setLanguageCol("language")
|
||||
.setVisualFeatures(["Categories", "Tags", "Description", "Faces", "ImageType", "Color", "Adult", "Objects", "Brands"])
|
||||
.setDetails(["Celebrities", "Landmarks"])
|
||||
.setOutputCol("features"))
|
||||
|
||||
ai.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.vision.AnalyzeImage
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test1.jpg", "en"),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test2.png", null),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test3.png", "en")
|
||||
).toDF("url", "language")
|
||||
|
||||
val ai = (new AnalyzeImage()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setLanguageCol("language")
|
||||
.setVisualFeatures(Seq("Categories", "Tags", "Description", "Faces", "ImageType", "Color", "Adult", "Objects", "Brands"))
|
||||
.setDetails(Seq("Celebrities", "Landmarks"))
|
||||
.setOutputCol("features"))
|
||||
|
||||
ai.transform(df).select("url", "features").show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AnalyzeImage"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AnalyzeImage"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AnalyzeImage.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AnalyzeImage.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/ComputerVision.scala" />
|
||||
|
||||
|
||||
### RecognizeText
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test1.jpg", ),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test2.png", ),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test3.png", )
|
||||
], ["url", ])
|
||||
|
||||
rt = (RecognizeText()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setMode("Printed")
|
||||
.setOutputCol("ocr")
|
||||
.setConcurrency(5))
|
||||
|
||||
rt.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.vision.RecognizeText
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/OCR/test1.jpg",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/OCR/test2.png",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/OCR/test3.png"
|
||||
).toDF("url")
|
||||
|
||||
val rt = (new RecognizeText()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setMode("Printed")
|
||||
.setOutputCol("ocr")
|
||||
.setConcurrency(5))
|
||||
|
||||
rt.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="RecognizeText"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.RecognizeText"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/RecognizeText.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1RecognizeText.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/ComputerVision.scala" />
|
||||
|
||||
|
||||
### ReadImage
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test1.jpg", ),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test2.png", ),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/OCR/test3.png", )
|
||||
], ["url", ])
|
||||
|
||||
ri = (ReadImage()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("ocr")
|
||||
.setConcurrency(5))
|
||||
|
||||
ri.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.vision.ReadImage
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/OCR/test1.jpg",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/OCR/test2.png",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/OCR/test3.png"
|
||||
).toDF("url")
|
||||
|
||||
val ri = (new ReadImage()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("ocr")
|
||||
.setConcurrency(5))
|
||||
|
||||
ri.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ReadImage"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.ReadImage"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/ReadImage.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1ReadImage.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/ComputerVision.scala" />
|
||||
|
||||
|
||||
### RecognizeDomainSpecificContent
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg", )
|
||||
], ["url", ])
|
||||
|
||||
celeb = (RecognizeDomainSpecificContent()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setModel("celebrities")
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("celebs"))
|
||||
|
||||
celeb.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.vision.RecognizeDomainSpecificContent
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg"
|
||||
).toDF("url")
|
||||
|
||||
val celeb = (new RecognizeDomainSpecificContent()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setModel("celebrities")
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("celebs"))
|
||||
|
||||
celeb.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="RecognizeDomainSpecificContent"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.RecognizeDomainSpecificContent"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/RecognizeDomainSpecificContent.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1RecognizeDomainSpecificContent.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/ComputerVision.scala" />
|
||||
|
||||
|
||||
### GenerateThumbnails
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg", )
|
||||
], ["url", ])
|
||||
|
||||
gt = (GenerateThumbnails()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setHeight(50)
|
||||
.setWidth(50)
|
||||
.setSmartCropping(True)
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("thumbnails"))
|
||||
|
||||
gt.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.vision.GenerateThumbnails
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df: DataFrame = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg"
|
||||
).toDF("url")
|
||||
|
||||
val gt = (new GenerateThumbnails()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setHeight(50)
|
||||
.setWidth(50)
|
||||
.setSmartCropping(true)
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("thumbnails"))
|
||||
|
||||
gt.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="GenerateThumbnails"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.GenerateThumbnails"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/GenerateThumbnails.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1GenerateThumbnails.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/ComputerVision.scala" />
|
||||
|
||||
|
||||
### TagImage
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg", )
|
||||
], ["url", ])
|
||||
|
||||
ti = (TagImage()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("tags"))
|
||||
|
||||
ti.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.vision.TagImage
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg"
|
||||
).toDF("url")
|
||||
|
||||
val ti = (new TagImage()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("tags"))
|
||||
|
||||
ti.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TagImage"
|
||||
py="synapse.ml.cognitive.html#module-mmlspark.cognitive.TagImage"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/TagImage.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1TagImage.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/ComputerVision.scala" />
|
||||
|
||||
|
||||
### DescribeImage
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg", )
|
||||
], ["url", ])
|
||||
|
||||
di = (DescribeImage()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setMaxCandidates(3)
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("descriptions"))
|
||||
|
||||
di.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.vision.DescribeImage
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg"
|
||||
).toDF("url")
|
||||
|
||||
val di = (new DescribeImage()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setMaxCandidates(3)
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("descriptions"))
|
||||
|
||||
di.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DescribeImage"
|
||||
py="synapse.ml.cognitive.html#module-mmlspark.cognitive.DescribeImage"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/DescribeImage.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1DescribeImage.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/ComputerVision.scala" />
|
||||
|
|
@ -0,0 +1,414 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Face
|
||||
|
||||
### DetectFace
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg",),
|
||||
], ["url"])
|
||||
|
||||
face = (DetectFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("detected_faces")
|
||||
.setReturnFaceId(True)
|
||||
.setReturnFaceLandmarks(False)
|
||||
.setReturnFaceAttributes(["age", "gender", "headPose", "smile", "facialHair", "glasses", "emotion",
|
||||
"hair", "makeup", "occlusion", "accessories", "blur", "exposure", "noise"]))
|
||||
|
||||
face.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.face.DetectFace
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df: DataFrame = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg"
|
||||
).toDF("url")
|
||||
|
||||
val face = (new DetectFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("face")
|
||||
.setReturnFaceId(true)
|
||||
.setReturnFaceLandmarks(true)
|
||||
.setReturnFaceAttributes(Seq(
|
||||
"age", "gender", "headPose", "smile", "facialHair", "glasses", "emotion",
|
||||
"hair", "makeup", "occlusion", "accessories", "blur", "exposure", "noise")))
|
||||
|
||||
face.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DetectFace"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.DetectFace"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/DetectFace.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1DetectFace.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/Face.scala" />
|
||||
|
||||
|
||||
### FindSimilarFace
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg",),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg",),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test3.jpg",)
|
||||
], ["url"])
|
||||
|
||||
detector = (DetectFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("detected_faces")
|
||||
.setReturnFaceId(True)
|
||||
.setReturnFaceLandmarks(False)
|
||||
.setReturnFaceAttributes([]))
|
||||
|
||||
faceIdDF = detector.transform(df).select("detected_faces").select(col("detected_faces").getItem(0).getItem("faceId").alias("id"))
|
||||
faceIds = [row.asDict()['id'] for row in faceIdDF.collect()]
|
||||
|
||||
findSimilar = (FindSimilarFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("similar")
|
||||
.setFaceIdCol("id")
|
||||
.setFaceIds(faceIds))
|
||||
|
||||
findSimilar.transform(faceIdDF).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.face.{DetectFace, FindSimilarFace}
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df: DataFrame = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test3.jpg"
|
||||
).toDF("url")
|
||||
val detector = (new DetectFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("detected_faces")
|
||||
.setReturnFaceId(true)
|
||||
.setReturnFaceLandmarks(false)
|
||||
.setReturnFaceAttributes(Seq()))
|
||||
|
||||
val faceIdDF = (detector.transform(df)
|
||||
.select(col("detected_faces").getItem(0).getItem("faceId").alias("id"))
|
||||
.cache())
|
||||
val faceIds = faceIdDF.collect().map(row => row.getAs[String]("id"))
|
||||
|
||||
val findSimilar = (new FindSimilarFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("similar")
|
||||
.setFaceIdCol("id")
|
||||
.setFaceIds(faceIds))
|
||||
|
||||
findSimilar.transform(faceIdDF).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="FindSimilarFace"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.FindSimilarFace"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/FindSimilarFace.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1FindSimilarFace.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/Face.scala" />
|
||||
|
||||
|
||||
### GroupFaces
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg",),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg",),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test3.jpg",)
|
||||
], ["url"])
|
||||
|
||||
detector = (DetectFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("detected_faces")
|
||||
.setReturnFaceId(True)
|
||||
.setReturnFaceLandmarks(False)
|
||||
.setReturnFaceAttributes([]))
|
||||
|
||||
faceIdDF = detector.transform(df).select("detected_faces").select(col("detected_faces").getItem(0).getItem("faceId").alias("id"))
|
||||
faceIds = [row.asDict()['id'] for row in faceIdDF.collect()]
|
||||
|
||||
group = (GroupFaces()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("grouping")
|
||||
.setFaceIds(faceIds))
|
||||
|
||||
group.transform(faceIdDF).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.face.{DetectFace, GroupFaces}
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df: DataFrame = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test3.jpg"
|
||||
).toDF("url")
|
||||
val detector = (new DetectFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("detected_faces")
|
||||
.setReturnFaceId(true)
|
||||
.setReturnFaceLandmarks(false)
|
||||
.setReturnFaceAttributes(Seq()))
|
||||
|
||||
val faceIdDF = (detector.transform(df)
|
||||
.select(col("detected_faces").getItem(0).getItem("faceId").alias("id"))
|
||||
.cache())
|
||||
val faceIds = faceIdDF.collect().map(row => row.getAs[String]("id"))
|
||||
|
||||
val group = (new GroupFaces()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("grouping")
|
||||
.setFaceIds(faceIds))
|
||||
|
||||
group.transform(faceIdDF).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="GroupFaces"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.GroupFaces"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/GroupFaces.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1GroupFaces.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/Face.scala" />
|
||||
|
||||
|
||||
### IdentifyFaces
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
pgId = "PUT_YOUR_PERSON_GROUP_ID"
|
||||
|
||||
identifyFaces = (IdentifyFaces()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setFaceIdsCol("faces")
|
||||
.setPersonGroupId(pgId)
|
||||
.setOutputCol("identified_faces"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.face.IdentifyFaces
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val pgId = "PUT_YOUR_PERSON_GROUP_ID"
|
||||
|
||||
val identifyFaces = (new IdentifyFaces()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setFaceIdsCol("faces")
|
||||
.setPersonGroupId(pgId)
|
||||
.setOutputCol("identified_faces"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="IdentifyFaces"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.IdentifyFaces"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/IdentifyFaces.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1IdentifyFaces.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/Face.scala" />
|
||||
|
||||
|
||||
### VerifyFaces
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg",),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg",),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/DSIR/test3.jpg",)
|
||||
], ["url"])
|
||||
|
||||
detector = (DetectFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("detected_faces")
|
||||
.setReturnFaceId(True)
|
||||
.setReturnFaceLandmarks(False)
|
||||
.setReturnFaceAttributes([]))
|
||||
|
||||
faceIdDF = detector.transform(df).select("detected_faces").select(col("detected_faces").getItem(0).getItem("faceId").alias("faceId1"))
|
||||
faceIdDF2 = faceIdDF.withColumn("faceId2", lit(faceIdDF.take(1)[0].asDict()['faceId1']))
|
||||
|
||||
verify = (VerifyFaces()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("same")
|
||||
.setFaceId1Col("faceId1")
|
||||
.setFaceId2Col("faceId2"))
|
||||
|
||||
verify.transform(faceIdDF2).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.face.{DetectFace, VerifyFaces}
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df: DataFrame = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test3.jpg"
|
||||
).toDF("url")
|
||||
|
||||
val detector = (new DetectFace()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("detected_faces")
|
||||
.setReturnFaceId(true)
|
||||
.setReturnFaceLandmarks(false)
|
||||
.setReturnFaceAttributes(Seq()))
|
||||
|
||||
val faceIdDF = (detector.transform(df)
|
||||
.select(col("detected_faces").getItem(0).getItem("faceId").alias("faceId1"))
|
||||
.cache())
|
||||
val faceIdDF2 = faceIdDF.withColumn("faceId2", lit(faceIdDF.take(1).head.getString(0)))
|
||||
|
||||
val verify = (new VerifyFaces()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("same")
|
||||
.setFaceId1Col("faceId1")
|
||||
.setFaceId2Col("faceId2"))
|
||||
|
||||
verify.transform(faceIdDF2).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VerifyFaces"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.VerifyFaces"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/VerifyFaces.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1VerifyFaces.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/Face.scala" />
|
||||
|
|
@ -0,0 +1,616 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## Form Recognizer
|
||||
|
||||
### AnalyzeLayout
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
imageDf = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/layout1.jpg",)
|
||||
], ["source",])
|
||||
|
||||
analyzeLayout = (AnalyzeLayout()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("layout")
|
||||
.setConcurrency(5))
|
||||
|
||||
(analyzeLayout.transform(imageDf)
|
||||
.withColumn("lines", flatten(col("layout.analyzeResult.readResults.lines")))
|
||||
.withColumn("readLayout", col("lines.text"))
|
||||
.withColumn("tables", flatten(col("layout.analyzeResult.pageResults.tables")))
|
||||
.withColumn("cells", flatten(col("tables.cells")))
|
||||
.withColumn("pageLayout", col("cells.text"))
|
||||
.select("source", "readLayout", "pageLayout")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.AnalyzeLayout
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val imageDf = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/layout1.jpg"
|
||||
).toDF("source")
|
||||
|
||||
val analyzeLayout = (new AnalyzeLayout()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("layout")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeLayout.transform(imageDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AnalyzeLayout"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AnalyzeLayout"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AnalyzeLayout.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AnalyzeLayout.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizer.scala" />
|
||||
|
||||
|
||||
### AnalyzeReceipts
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
imageDf = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/receipt1.png",),
|
||||
("https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/receipt1.png",)
|
||||
], ["image",])
|
||||
|
||||
analyzeReceipts = (AnalyzeReceipts()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("image")
|
||||
.setOutputCol("receipts")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeReceipts.transform(imageDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.AnalyzeReceipts
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val imageDf = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/receipt1.png",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/receipt1.png"
|
||||
).toDF("source")
|
||||
|
||||
val analyzeReceipts = (new AnalyzeReceipts()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("receipts")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeReceipts.transform(imageDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AnalyzeReceipts"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AnalyzeReceipts"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AnalyzeReceipts.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AnalyzeReceipts.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizer.scala" />
|
||||
|
||||
|
||||
### AnalyzeBusinessCards
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
imageDf = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/business_card.jpg",)
|
||||
], ["source",])
|
||||
|
||||
analyzeBusinessCards = (AnalyzeBusinessCards()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("businessCards")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeBusinessCards.transform(imageDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.AnalyzeBusinessCards
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val imageDf = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/business_card.jpg"
|
||||
).toDF("source")
|
||||
|
||||
val analyzeBusinessCards = (new AnalyzeBusinessCards()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("businessCards")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeBusinessCards.transform(imageDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AnalyzeBusinessCards"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AnalyzeBusinessCards"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AnalyzeBusinessCards.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AnalyzeBusinessCards.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizer.scala" />
|
||||
|
||||
|
||||
### AnalyzeInvoices
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
imageDf = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/invoice2.png",)
|
||||
], ["source",])
|
||||
|
||||
analyzeInvoices = (AnalyzeInvoices()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("invoices")
|
||||
.setConcurrency(5))
|
||||
|
||||
(analyzeInvoices
|
||||
.transform(imageDf)
|
||||
.withColumn("documents", explode(col("invoices.analyzeResult.documentResults.fields")))
|
||||
.select("source", "documents")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.AnalyzeInvoices
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val imageDf = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/invoice2.png"
|
||||
).toDF("source")
|
||||
|
||||
val analyzeInvoices = (new AnalyzeInvoices()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("invoices")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeInvoices.transform(imageD4).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AnalyzeInvoices"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AnalyzeInvoices"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AnalyzeInvoices.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AnalyzeInvoices.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizer.scala" />
|
||||
|
||||
|
||||
### AnalyzeIDDocuments
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
imageDf = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/id1.jpg",)
|
||||
], ["source",])
|
||||
|
||||
analyzeIDDocuments = (AnalyzeIDDocuments()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("ids")
|
||||
.setConcurrency(5))
|
||||
|
||||
(analyzeIDDocuments
|
||||
.transform(imageDf)
|
||||
.withColumn("documents", explode(col("ids.analyzeResult.documentResults.fields")))
|
||||
.select("source", "documents")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.AnalyzeIDDocuments
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val imageDf = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/id1.jpg"
|
||||
).toDF("source")
|
||||
|
||||
val analyzeIDDocuments = (new AnalyzeIDDocuments()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("ids")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeIDDocuments.transform(imageDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AnalyzeIDDocuments"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AnalyzeIDDocuments"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AnalyzeIDDocuments.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AnalyzeIDDocuments.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizer.scala" />
|
||||
|
||||
|
||||
### AnalyzeCustomModel
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
modelId = "02bc2f58-2beb-4ae3-84fb-08f011b2f7b8" # put your own modelId here
|
||||
imageDf = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/invoice2.png",)
|
||||
], ["source",])
|
||||
|
||||
analyzeCustomModel = (AnalyzeCustomModel()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setModelId(modelId)
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("output")
|
||||
.setConcurrency(5))
|
||||
|
||||
(analyzeCustomModel
|
||||
.transform(imageDf)
|
||||
.withColumn("keyValuePairs", flatten(col("output.analyzeResult.pageResults.keyValuePairs")))
|
||||
.withColumn("keys", col("keyValuePairs.key.text"))
|
||||
.withColumn("values", col("keyValuePairs.value.text"))
|
||||
.withColumn("keyValuePairs", create_map(lit("key"), col("keys"), lit("value"), col("values")))
|
||||
.select("source", "keyValuePairs")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.AnalyzeCustomModel
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val modelId = "02bc2f58-2beb-4ae3-84fb-08f011b2f7b8" // put your own modelId here
|
||||
val imageDf = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/invoice2.png"
|
||||
).toDF("source")
|
||||
|
||||
val analyzeCustomModel = (new AnalyzeCustomModel()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setModelId(modelId)
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("output")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeCustomModel.transform(imageDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AnalyzeCustomModel"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AnalyzeCustomModel"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AnalyzeCustomModel.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AnalyzeCustomModel.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizer.scala" />
|
||||
|
||||
|
||||
### GetCustomModel
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
modelId = "02bc2f58-2beb-4ae3-84fb-08f011b2f7b8" # put your own modelId here
|
||||
emptyDf = spark.createDataFrame([("",)])
|
||||
|
||||
getCustomModel = (GetCustomModel()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setModelId(modelId)
|
||||
.setIncludeKeys(True)
|
||||
.setOutputCol("model")
|
||||
.setConcurrency(5))
|
||||
|
||||
(getCustomModel
|
||||
.transform(emptyDf)
|
||||
.withColumn("modelInfo", col("model.ModelInfo"))
|
||||
.withColumn("trainResult", col("model.TrainResult"))
|
||||
.select("modelInfo", "trainResult")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.GetCustomModel
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val modelId = "02bc2f58-2beb-4ae3-84fb-08f011b2f7b8" // put your own modelId here
|
||||
val emptyDf = Seq("").toDF()
|
||||
|
||||
val getCustomModel = (new GetCustomModel()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setModelId(modelId)
|
||||
.setIncludeKeys(true)
|
||||
.setOutputCol("model")
|
||||
.setConcurrency(5))
|
||||
|
||||
getCustomModel.transform(emptyDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="GetCustomModel"
|
||||
py="synapse.ml.cognitive.html#module-mmlspark.cognitive.GetCustomModel"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/GetCustomModel.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1GetCustomModel.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizer.scala" />
|
||||
|
||||
|
||||
### ListCustomModels
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
emptyDf = spark.createDataFrame([("",)])
|
||||
|
||||
listCustomModels = (ListCustomModels()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOp("full")
|
||||
.setOutputCol("models")
|
||||
.setConcurrency(5))
|
||||
|
||||
(listCustomModels
|
||||
.transform(emptyDf)
|
||||
.withColumn("modelIds", col("models.modelList.modelId"))
|
||||
.select("modelIds")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.ListCustomModels
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val emptyDf = Seq("").toDF()
|
||||
|
||||
val listCustomModels = (new ListCustomModels()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOp("full")
|
||||
.setOutputCol("models")
|
||||
.setConcurrency(5))
|
||||
|
||||
listCustomModels.transform(emptyDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ListCustomModels"
|
||||
py="synapse.ml.cognitive.html#module-mmlspark.cognitive.ListCustomModels"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/ListCustomModels.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1ListCustomModels.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizer.scala" />
|
||||
|
||||
|
||||
## Form Recognizer V3
|
||||
|
||||
### AnalyzeDocument
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
imageDf = spark.createDataFrame([
|
||||
("https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/layout1.jpg",)
|
||||
], ["source",])
|
||||
|
||||
analyzeDocument = (AnalyzeDocument()
|
||||
# For supported prebuilt models, please go to documentation page for details
|
||||
.setPrebuiltModelId("prebuilt-layout")
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("result")
|
||||
.setConcurrency(5))
|
||||
|
||||
(analyzeDocument.transform(imageDf)
|
||||
.withColumn("content", col("result.analyzeResult.content"))
|
||||
.withColumn("cells", flatten(col("result.analyzeResult.tables.cells")))
|
||||
.withColumn("cells", col("cells.content"))
|
||||
.select("source", "result", "content", "cells")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.form.AnalyzeDocument
|
||||
import spark.implicits._
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val imageDf = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/layout1.jpg"
|
||||
).toDF("source")
|
||||
|
||||
val analyzeDocument = (new AnalyzeDocument()
|
||||
.setPrebuiltModelId("prebuilt-layout")
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("result")
|
||||
.setConcurrency(5))
|
||||
|
||||
analyzeDocument.transform(imageDf).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="AnalyzeDocument"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.AnalyzeDocument"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/AnalyzeDocument.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1AnalyzeDocument.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/FormRecognizerV3.scala" />
|
||||
|
|
@ -0,0 +1,144 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## Speech To Text
|
||||
|
||||
### SpeechToText
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
import requests
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
link = "https://mmlspark.blob.core.windows.net/datasets/Speech/audio2.wav"
|
||||
audioBytes = requests.get(link).content
|
||||
df = spark.createDataFrame([(audioBytes,)
|
||||
], ["audio"])
|
||||
|
||||
stt = (SpeechToText()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("text")
|
||||
.setAudioDataCol("audio")
|
||||
.setLanguage("en-US")
|
||||
.setFormat("simple"))
|
||||
|
||||
stt.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.speech.SpeechToText
|
||||
import org.apache.commons.compress.utils.IOUtils
|
||||
import spark.implicits._
|
||||
import java.net.URL
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val audioBytes = IOUtils.toByteArray(new URL("https://mmlspark.blob.core.windows.net/datasets/Speech/test1.wav").openStream())
|
||||
|
||||
val df: DataFrame = Seq(
|
||||
Tuple1(audioBytes)
|
||||
).toDF("audio")
|
||||
|
||||
val stt = (new SpeechToText()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("text")
|
||||
.setAudioDataCol("audio")
|
||||
.setLanguage("en-US")
|
||||
.setFormat("simple"))
|
||||
|
||||
stt.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="SpeechToText"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.SpeechToText"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/SpeechToText.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1SpeechToText.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/SpeechToText.scala" />
|
||||
|
||||
|
||||
### SpeechToTextSDK
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
import requests
|
||||
|
||||
cognitiveKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([("https://mmlspark.blob.core.windows.net/datasets/Speech/audio2.wav",)
|
||||
], ["url"])
|
||||
|
||||
speech_to_text = (SpeechToTextSDK()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("text")
|
||||
.setAudioDataCol("url")
|
||||
.setLanguage("en-US")
|
||||
.setProfanity("Masked"))
|
||||
|
||||
speech_to_text.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.speech.SpeechToTextSDK
|
||||
import spark.implicits._
|
||||
import org.apache.commons.compress.utils.IOUtils
|
||||
import java.net.URL
|
||||
|
||||
val cognitiveKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df: DataFrame = Seq(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/Speech/audio2.wav"
|
||||
).toDF("url")
|
||||
|
||||
val speech_to_text = (new SpeechToTextSDK()
|
||||
.setSubscriptionKey(cognitiveKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("text")
|
||||
.setAudioDataCol("url")
|
||||
.setLanguage("en-US")
|
||||
.setProfanity("Masked"))
|
||||
|
||||
speech_to_text.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="SpeechToTextSDK"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.SpeechToTextSDK"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/SpeechToTextSDK.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1SpeechToTextSDK.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/SpeechToTextSDK.scala" />
|
||||
|
|
@ -0,0 +1,416 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## Text Analytics
|
||||
|
||||
### EntityDetector
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
textKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("1", "Microsoft released Windows 10"),
|
||||
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
|
||||
], ["id", "text"])
|
||||
|
||||
entity = (EntityDetector()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguage("en")
|
||||
.setOutputCol("replies")
|
||||
.setErrorCol("error"))
|
||||
|
||||
entity.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.text.EntityDetector
|
||||
import spark.implicits._
|
||||
import org.apache.spark.sql.functions.{col, flatten}
|
||||
|
||||
val textKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
("1", "Microsoft released Windows 10"),
|
||||
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
|
||||
).toDF("id", "text")
|
||||
|
||||
val entity = (new EntityDetector()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguage("en")
|
||||
.setOutputCol("replies"))
|
||||
|
||||
entity.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="EntityDetector"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.EntityDetector"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/EntityDetector.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1EntityDetector.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextAnalytics.scala" />
|
||||
|
||||
|
||||
### KeyPhraseExtractor
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
textKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("en", "Hello world. This is some input text that I love."),
|
||||
("fr", "Bonjour tout le monde"),
|
||||
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
|
||||
], ["lang", "text"])
|
||||
|
||||
keyPhrase = (KeyPhraseExtractor()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguageCol("lang")
|
||||
.setOutputCol("replies")
|
||||
.setErrorCol("error"))
|
||||
|
||||
keyPhrase.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.text.KeyPhraseExtractor
|
||||
import spark.implicits._
|
||||
|
||||
val textKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
("en", "Hello world. This is some input text that I love."),
|
||||
("fr", "Bonjour tout le monde"),
|
||||
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer."),
|
||||
("en", null)
|
||||
).toDF("lang", "text")
|
||||
|
||||
val keyPhrase = (new KeyPhraseExtractor()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguageCol("lang")
|
||||
.setOutputCol("replies"))
|
||||
|
||||
keyPhrase.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="KeyPhraseExtractor"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.KeyPhraseExtractor"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/KeyPhraseExtractor.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1KeyPhraseExtractor.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextAnalytics.scala" />
|
||||
|
||||
|
||||
### LanguageDetector
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
textKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("Hello World",),
|
||||
("Bonjour tout le monde",),
|
||||
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
|
||||
("你好",),
|
||||
("こんにちは",),
|
||||
(":) :( :D",)
|
||||
], ["text",])
|
||||
|
||||
language = (LanguageDetector()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("language")
|
||||
.setErrorCol("error"))
|
||||
|
||||
language.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.text.LanguageDetector
|
||||
import spark.implicits._
|
||||
|
||||
val textKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
"Hello World",
|
||||
"Bonjour tout le monde",
|
||||
"La carretera estaba atascada. Había mucho tráfico el día de ayer.",
|
||||
":) :( :D"
|
||||
).toDF("text")
|
||||
|
||||
val language = (new LanguageDetector()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setOutputCol("replies"))
|
||||
|
||||
language.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="LanguageDetector"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.LanguageDetector"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/LanguageDetector.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1LanguageDetector.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextAnalytics.scala" />
|
||||
|
||||
|
||||
### NER
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
textKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("1", "en", "I had a wonderful trip to Seattle last week."),
|
||||
("2", "en", "I visited Space Needle 2 times.")
|
||||
], ["id", "language", "text"])
|
||||
|
||||
ner = (NER()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguageCol("language")
|
||||
.setOutputCol("replies")
|
||||
.setErrorCol("error"))
|
||||
|
||||
ner.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.text.NER
|
||||
import spark.implicits._
|
||||
|
||||
val textKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
("1", "en", "I had a wonderful trip to Seattle last week."),
|
||||
("2", "en", "I visited Space Needle 2 times.")
|
||||
).toDF("id", "language", "text")
|
||||
|
||||
val ner = (new NER()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguage("en")
|
||||
.setOutputCol("response"))
|
||||
|
||||
ner.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="NER"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.NER"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/NER.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1NER.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextAnalytics.scala" />
|
||||
|
||||
|
||||
### PII
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
textKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("1", "en", "My SSN is 859-98-0987"),
|
||||
("2", "en",
|
||||
"Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
|
||||
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
|
||||
], ["id", "language", "text"])
|
||||
|
||||
pii = (PII()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguage("en")
|
||||
.setOutputCol("response"))
|
||||
|
||||
pii.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.text.PII
|
||||
import spark.implicits._
|
||||
|
||||
val textKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
("1", "en", "My SSN is 859-98-0987"),
|
||||
("2", "en",
|
||||
"Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
|
||||
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
|
||||
).toDF("id", "language", "text")
|
||||
|
||||
val pii = (new PII()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguage("en")
|
||||
.setOutputCol("response"))
|
||||
|
||||
pii.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="PII"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.PII"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/PII.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1PII.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextAnalytics.scala" />
|
||||
|
||||
|
||||
### TextSentiment
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
textKey = os.environ.get("COGNITIVE_API_KEY", getSecret("cognitive-api-key"))
|
||||
df = spark.createDataFrame([
|
||||
("I am so happy today, its sunny!", "en-US"),
|
||||
("I am frustrated by this rush hour traffic", "en-US"),
|
||||
("The cognitive services on spark aint bad", "en-US"),
|
||||
], ["text", "language"])
|
||||
|
||||
sentiment = (TextSentiment()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("sentiment")
|
||||
.setErrorCol("error")
|
||||
.setLanguageCol("language"))
|
||||
|
||||
sentiment.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.text.TextSentiment
|
||||
import spark.implicits._
|
||||
|
||||
val textKey = sys.env.getOrElse("COGNITIVE_API_KEY", None)
|
||||
val df = Seq(
|
||||
("en", "Hello world. This is some input text that I love."),
|
||||
("fr", "Bonjour tout le monde"),
|
||||
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer."),
|
||||
(null, "ich bin ein berliner"),
|
||||
(null, null),
|
||||
("en", null)
|
||||
).toDF("lang", "text")
|
||||
|
||||
val sentiment = (new TextSentiment()
|
||||
.setSubscriptionKey(textKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguageCol("lang")
|
||||
.setModelVersion("latest")
|
||||
.setShowStats(true)
|
||||
.setOutputCol("replies"))
|
||||
|
||||
sentiment.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TextSentiment"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.TextSentiment"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/TextSentiment.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1TextSentiment.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextAnalytics.scala" />
|
||||
|
|
@ -0,0 +1,492 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## Translator
|
||||
|
||||
### Translate
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
translatorKey = os.environ.get("TRANSLATOR_KEY", getSecret("translator-key"))
|
||||
df = spark.createDataFrame([
|
||||
(["Hello, what is your name?", "Bye"],)
|
||||
], ["text",])
|
||||
|
||||
translate = (Translate()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setTextCol("text")
|
||||
.setToLanguage(["zh-Hans", "fr"])
|
||||
.setOutputCol("translation")
|
||||
.setConcurrency(5))
|
||||
|
||||
(translate
|
||||
.transform(df)
|
||||
.withColumn("translation", flatten(col("translation.translations")))
|
||||
.withColumn("translation", col("translation.text"))
|
||||
.select("translation")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.translate.Translate
|
||||
import spark.implicits._
|
||||
import org.apache.spark.sql.functions.{col, flatten}
|
||||
|
||||
val translatorKey = sys.env.getOrElse("TRANSLATOR_KEY", None)
|
||||
val df = Seq(List("Hello, what is your name?", "Bye")).toDF("text")
|
||||
|
||||
val translate = (new Translate()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setTextCol("text")
|
||||
.setToLanguage(Seq("zh-Hans", "fr"))
|
||||
.setOutputCol("translation")
|
||||
.setConcurrency(5))
|
||||
|
||||
(translate
|
||||
.transform(df)
|
||||
.withColumn("translation", flatten(col("translation.translations")))
|
||||
.withColumn("translation", col("translation.text"))
|
||||
.select("translation")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="Translate"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.Translate"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/Translate.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1Translate.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextTranslator.scala" />
|
||||
|
||||
|
||||
### Transliterate
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
translatorKey = os.environ.get("TRANSLATOR_KEY", getSecret("translator-key"))
|
||||
df = spark.createDataFrame([
|
||||
(["こんにちは", "さようなら"],)
|
||||
], ["text",])
|
||||
|
||||
transliterate = (Transliterate()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguage("ja")
|
||||
.setFromScript("Jpan")
|
||||
.setToScript("Latn")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(transliterate
|
||||
.transform(df)
|
||||
.withColumn("text", col("result.text"))
|
||||
.withColumn("script", col("result.script"))
|
||||
.select("text", "script")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.translate.Transliterate
|
||||
import spark.implicits._
|
||||
import org.apache.spark.sql.functions.col
|
||||
|
||||
val translatorKey = sys.env.getOrElse("TRANSLATOR_KEY", None)
|
||||
val df = Seq(List("こんにちは", "さようなら")).toDF("text")
|
||||
|
||||
val transliterate = (new Transliterate()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setLanguage("ja")
|
||||
.setFromScript("Jpan")
|
||||
.setToScript("Latn")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(transliterate
|
||||
.transform(df)
|
||||
.withColumn("text", col("result.text"))
|
||||
.withColumn("script", col("result.script"))
|
||||
.select("text", "script")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="Transliterate"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.Transliterate"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/Transliterate.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1Transliterate.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextTranslator.scala" />
|
||||
|
||||
|
||||
### Detect
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
translatorKey = os.environ.get("TRANSLATOR_KEY", getSecret("translator-key"))
|
||||
df = spark.createDataFrame([
|
||||
(["Hello, what is your name?"],)
|
||||
], ["text",])
|
||||
|
||||
detect = (Detect()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(detect
|
||||
.transform(df)
|
||||
.withColumn("language", col("result.language"))
|
||||
.select("language")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.translate.Detect
|
||||
import spark.implicits._
|
||||
import org.apache.spark.sql.functions.col
|
||||
|
||||
val translatorKey = sys.env.getOrElse("TRANSLATOR_KEY", None)
|
||||
val df = Seq(List("Hello, what is your name?")).toDF("text")
|
||||
|
||||
val detect = (new Detect()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(detect
|
||||
.transform(df)
|
||||
.withColumn("language", col("result.language"))
|
||||
.select("language")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="Detect"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.Detect"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/Detect.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1Detect.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextTranslator.scala" />
|
||||
|
||||
|
||||
### BreakSentence
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
translatorKey = os.environ.get("TRANSLATOR_KEY", getSecret("translator-key"))
|
||||
df = spark.createDataFrame([
|
||||
(["Hello, what is your name?"],)
|
||||
], ["text",])
|
||||
|
||||
breakSentence = (BreakSentence()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(breakSentence
|
||||
.transform(df)
|
||||
.withColumn("sentLen", flatten(col("result.sentLen")))
|
||||
.select("sentLen")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.translate.BreakSentence
|
||||
import spark.implicits._
|
||||
import org.apache.spark.sql.functions.{col, flatten}
|
||||
|
||||
val translatorKey = sys.env.getOrElse("TRANSLATOR_KEY", None)
|
||||
val df = Seq(List("Hello, what is your name?")).toDF("text")
|
||||
|
||||
val breakSentence = (new BreakSentence()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(breakSentence
|
||||
.transform(df)
|
||||
.withColumn("sentLen", flatten(col("result.sentLen")))
|
||||
.select("sentLen")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="BreakSentence"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.BreakSentence"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/BreakSentence.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1BreakSentence.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextTranslator.scala" />
|
||||
|
||||
|
||||
### DictionaryLookup
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
translatorKey = os.environ.get("TRANSLATOR_KEY", getSecret("translator-key"))
|
||||
df = spark.createDataFrame([
|
||||
(["fly"],)
|
||||
], ["text",])
|
||||
|
||||
dictionaryLookup = (DictionaryLookup()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setFromLanguage("en")
|
||||
.setToLanguage("es")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(dictionaryLookup
|
||||
.transform(df)
|
||||
.withColumn("translations", flatten(col("result.translations")))
|
||||
.withColumn("normalizedTarget", col("translations.normalizedTarget"))
|
||||
.select("normalizedTarget")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.translate.DictionaryLookup
|
||||
import spark.implicits._
|
||||
import org.apache.spark.sql.functions.{col, flatten}
|
||||
|
||||
val translatorKey = sys.env.getOrElse("TRANSLATOR_KEY", None)
|
||||
val df = Seq(List("fly")).toDF("text")
|
||||
|
||||
val dictionaryLookup = (new DictionaryLookup()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setFromLanguage("en")
|
||||
.setToLanguage("es")
|
||||
.setTextCol("text")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(dictionaryLookup
|
||||
.transform(df)
|
||||
.withColumn("translations", flatten(col("result.translations")))
|
||||
.withColumn("normalizedTarget", col("translations.normalizedTarget"))
|
||||
.select("normalizedTarget")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DictionaryLookup"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.DictionaryLookup"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/DictionaryLookup.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1DictionaryLookup.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextTranslator.scala" />
|
||||
|
||||
|
||||
### DictionaryExamples
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
translatorKey = os.environ.get("TRANSLATOR_KEY", getSecret("translator-key"))
|
||||
df = (spark.createDataFrame([
|
||||
("fly", "volar")
|
||||
], ["text", "translation"])
|
||||
.withColumn("textAndTranslation", array(struct(col("text"), col("translation")))))
|
||||
|
||||
dictionaryExamples = (DictionaryExamples()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setFromLanguage("en")
|
||||
.setToLanguage("es")
|
||||
.setTextAndTranslationCol("textAndTranslation")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(dictionaryExamples
|
||||
.transform(df)
|
||||
.withColumn("examples", flatten(col("result.examples")))
|
||||
.select("examples")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.translate.{DictionaryExamples, TextAndTranslation}
|
||||
import spark.implicits._
|
||||
import org.apache.spark.sql.functions.{col, flatten}
|
||||
|
||||
val translatorKey = sys.env.getOrElse("TRANSLATOR_KEY", None)
|
||||
val df = Seq(List(TextAndTranslation("fly", "volar"))).toDF("textAndTranslation")
|
||||
|
||||
val dictionaryExamples = (new DictionaryExamples()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setLocation("eastus")
|
||||
.setFromLanguage("en")
|
||||
.setToLanguage("es")
|
||||
.setTextAndTranslationCol("textAndTranslation")
|
||||
.setOutputCol("result"))
|
||||
|
||||
(dictionaryExamples
|
||||
.transform(df)
|
||||
.withColumn("examples", flatten(col("result.examples")))
|
||||
.select("examples")).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DictionaryExamples"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.DictionaryExamples"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/DictionaryExamples.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1DictionaryExamples.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/TextTranslator.scala" />
|
||||
|
||||
|
||||
### DocumentTranslator
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
translatorKey = os.environ.get("TRANSLATOR_KEY", getSecret("translator-key"))
|
||||
translatorName = os.environ.get("TRANSLATOR_NAME", "mmlspark-translator")
|
||||
|
||||
documentTranslator = (DocumentTranslator()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setServiceName(translatorName)
|
||||
.setSourceUrlCol("sourceUrl")
|
||||
.setTargetsCol("targets")
|
||||
.setOutputCol("translationStatus"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.cognitive.translate.DocumentTranslator
|
||||
import spark.implicits._
|
||||
|
||||
val translatorKey = sys.env.getOrElse("TRANSLATOR_KEY", None)
|
||||
val translatorName = sys.env.getOrElse("TRANSLATOR_NAME", None)
|
||||
|
||||
val documentTranslator = (new DocumentTranslator()
|
||||
.setSubscriptionKey(translatorKey)
|
||||
.setServiceName(translatorName)
|
||||
.setSourceUrlCol("sourceUrl")
|
||||
.setTargetsCol("targets")
|
||||
.setOutputCol("translationStatus"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DocumentTranslator"
|
||||
py="synapse.ml.cognitive.html#module-synapse.ml.cognitive.DocumentTranslator"
|
||||
scala="com/microsoft/azure/synapse/ml/cognitive/DocumentTranslator.html"
|
||||
csharp="classSynapse_1_1ML_1_1Cognitive_1_1DocumentTranslator.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/cognitive/src/main/scala/com/microsoft/azure/synapse/ml/cognitive/DocumentTranslator.scala" />
|
||||
|
|
@ -0,0 +1,574 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Explainers
|
||||
|
||||
### ImageLIME
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model = ONNXModel()
|
||||
|
||||
lime = (ImageLIME()
|
||||
.setModel(model)
|
||||
.setOutputCol("weights")
|
||||
.setInputCol("image")
|
||||
.setCellSize(150.0)
|
||||
.setModifier(50.0)
|
||||
.setNumSamples(500)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClassesCol("top2pred")
|
||||
.setSamplingFraction(0.7))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.explainers._
|
||||
import com.microsoft.azure.synapse.ml.onnx._
|
||||
import spark.implicits._
|
||||
|
||||
val model = (new ONNXModel())
|
||||
|
||||
val lime = (new ImageLIME()
|
||||
.setModel(model)
|
||||
.setOutputCol("weights")
|
||||
.setInputCol("image")
|
||||
.setCellSize(150.0)
|
||||
.setModifier(50.0)
|
||||
.setNumSamples(500)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClassesCol("top2pred")
|
||||
.setSamplingFraction(0.7))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ImageLIME"
|
||||
py="synapse.ml.explainers.html#module-synapse.ml.explainers.ImageLIME"
|
||||
scala="com/microsoft/azure/synapse/ml/explainers/ImageLIME.html"
|
||||
csharp="classSynapse_1_1ML_1_1Explainers_1_1ImageLIME.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/explainers/ImageLIME.scala" />
|
||||
|
||||
|
||||
### ImageSHAP
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model = ONNXModel()
|
||||
|
||||
shap = (
|
||||
ImageSHAP()
|
||||
.setModel(model)
|
||||
.setOutputCol("shaps")
|
||||
.setSuperpixelCol("superpixels")
|
||||
.setInputCol("image")
|
||||
.setCellSize(150.0)
|
||||
.setModifier(50.0)
|
||||
.setNumSamples(500)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClassesCol("top2pred")
|
||||
)
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.explainers._
|
||||
import com.microsoft.azure.synapse.ml.onnx._
|
||||
import spark.implicits._
|
||||
|
||||
val model = (new ONNXModel())
|
||||
|
||||
val shap = (new ImageSHAP()
|
||||
.setModel(model)
|
||||
.setOutputCol("shaps")
|
||||
.setSuperpixelCol("superpixels")
|
||||
.setInputCol("image")
|
||||
.setCellSize(150.0)
|
||||
.setModifier(50.0)
|
||||
.setNumSamples(500)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClassesCol("top2pred")
|
||||
))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ImageSHAP"
|
||||
py="synapse.ml.explainers.html#module-synapse.ml.explainers.ImageSHAP"
|
||||
scala="com/microsoft/azure/synapse/ml/explainers/ImageSHAP.html"
|
||||
csharp="classSynapse_1_1ML_1_1Explainers_1_1ImageSHAP.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/explainers/ImageSHAP.scala" />
|
||||
|
||||
|
||||
### TabularLIME
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model = ONNXModel()
|
||||
data = spark.createDataFrame([
|
||||
(-6.0, 0),
|
||||
(-5.0, 0),
|
||||
(5.0, 1),
|
||||
(6.0, 1)
|
||||
], ["col1", "label"])
|
||||
|
||||
lime = (TabularLIME()
|
||||
.setModel(model)
|
||||
.setInputCols(["col1"])
|
||||
.setOutputCol("weights")
|
||||
.setBackgroundData(data)
|
||||
.setKernelWidth(0.001)
|
||||
.setNumSamples(1000)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClasses([0, 1]))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.explainers._
|
||||
import com.microsoft.azure.synapse.ml.onnx._
|
||||
import spark.implicits._
|
||||
|
||||
val model = (new ONNXModel())
|
||||
val data = Seq(
|
||||
(-6.0, 0),
|
||||
(-5.0, 0),
|
||||
(5.0, 1),
|
||||
(6.0, 1)
|
||||
).toDF("col1", "label")
|
||||
|
||||
val lime = (new TabularLIME()
|
||||
.setInputCols(Array("col1"))
|
||||
.setOutputCol("weights")
|
||||
.setBackgroundData(data)
|
||||
.setKernelWidth(0.001)
|
||||
.setNumSamples(1000)
|
||||
.setModel(model)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClasses(Array(0, 1)))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TabularLIME"
|
||||
py="synapse.ml.explainers.html#module-synapse.ml.explainers.TabularLIME"
|
||||
scala="com/microsoft/azure/synapse/ml/explainers/TabularLIME.html"
|
||||
csharp="classSynapse_1_1ML_1_1Explainers_1_1TabularLIME.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/explainers/TabularLIME.scala" />
|
||||
|
||||
|
||||
### TabularSHAP
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model = ONNXModel()
|
||||
data = spark.createDataFrame([
|
||||
(-5.0, "a", -5.0, 0),
|
||||
(-5.0, "b", -5.0, 0),
|
||||
(5.0, "a", 5.0, 1),
|
||||
(5.0, "b", 5.0, 1)
|
||||
]*100, ["col1", "label"])
|
||||
|
||||
shap = (TabularSHAP()
|
||||
.setInputCols(["col1", "col2", "col3"])
|
||||
.setOutputCol("shapValues")
|
||||
.setBackgroundData(data)
|
||||
.setNumSamples(1000)
|
||||
.setModel(model)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClasses([1]))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.explainers._
|
||||
import com.microsoft.azure.synapse.ml.onnx._
|
||||
import spark.implicits._
|
||||
|
||||
val model = (new ONNXModel())
|
||||
val data = (1 to 100).flatMap(_ => Seq(
|
||||
(-5d, "a", -5d, 0),
|
||||
(-5d, "b", -5d, 0),
|
||||
(5d, "a", 5d, 1),
|
||||
(5d, "b", 5d, 1)
|
||||
)).toDF("col1", "col2", "col3", "label")
|
||||
|
||||
val shap = (new TabularSHAP()
|
||||
.setInputCols(Array("col1", "col2", "col3"))
|
||||
.setOutputCol("shapValues")
|
||||
.setBackgroundData(data)
|
||||
.setNumSamples(1000)
|
||||
.setModel(model)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClasses(Array(1)))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TabularSHAP"
|
||||
py="synapse.ml.explainers.html#module-synapse.ml.explainers.TabularSHAP"
|
||||
scala="com/microsoft/azure/synapse/ml/explainers/TabularSHAP.html"
|
||||
csharp="classSynapse_1_1ML_1_1Explainers_1_1TabularSHAP.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/explainers/TabularSHAP.scala" />
|
||||
|
||||
|
||||
### TextLIME
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model = ONNXModel()
|
||||
|
||||
lime = (TextLIME()
|
||||
.setModel(model)
|
||||
.setInputCol("text")
|
||||
.setTargetCol("prob")
|
||||
.setTargetClasses([1])
|
||||
.setOutputCol("weights")
|
||||
.setTokensCol("tokens")
|
||||
.setSamplingFraction(0.7)
|
||||
.setNumSamples(1000))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.explainers._
|
||||
import com.microsoft.azure.synapse.ml.onnx._
|
||||
import spark.implicits._
|
||||
|
||||
val model = (new ONNXModel())
|
||||
|
||||
val lime = (new TextLIME()
|
||||
.setModel(model)
|
||||
.setInputCol("text")
|
||||
.setTargetCol("prob")
|
||||
.setTargetClasses(Array(1))
|
||||
.setOutputCol("weights")
|
||||
.setTokensCol("tokens")
|
||||
.setSamplingFraction(0.7)
|
||||
.setNumSamples(1000))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TextLIME"
|
||||
py="synapse.ml.explainers.html#module-synapse.ml.explainers.TextLIME"
|
||||
scala="com/microsoft/azure/synapse/ml/explainers/TextLIME.html"
|
||||
csharp="classSynapse_1_1ML_1_1Explainers_1_1TextLIME.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/explainers/TextLIME.scala" />
|
||||
|
||||
|
||||
### TextSHAP
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model = ONNXModel()
|
||||
|
||||
shap = (TextSHAP()
|
||||
.setModel(model)
|
||||
.setInputCol("text")
|
||||
.setTargetCol("prob")
|
||||
.setTargetClasses([1])
|
||||
.setOutputCol("weights")
|
||||
.setTokensCol("tokens")
|
||||
.setNumSamples(1000))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.explainers._
|
||||
import com.microsoft.azure.synapse.ml.onnx._
|
||||
import spark.implicits._
|
||||
|
||||
val model = (new ONNXModel())
|
||||
|
||||
val shap = (new TextSHAP()
|
||||
.setModel(model)
|
||||
.setInputCol("text")
|
||||
.setTargetCol("prob")
|
||||
.setTargetClasses(Array(1))
|
||||
.setOutputCol("weights")
|
||||
.setTokensCol("tokens")
|
||||
.setNumSamples(1000))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="TextSHAP"
|
||||
py="synapse.ml.explainers.html#module-synapse.ml.explainers.TextSHAP"
|
||||
scala="com/microsoft/azure/synapse/ml/explainers/TextSHAP.html"
|
||||
csharp="classSynapse_1_1ML_1_1Explainers_1_1TextSHAP.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/explainers/TextSHAP.scala" />
|
||||
|
||||
|
||||
### VectorLIME
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model = ONNXModel()
|
||||
|
||||
df = spark.createDataFrame([
|
||||
([0.2729799734928408, -0.4637273304253777, 1.565593782147994], 4.541185129673482),
|
||||
([1.9511879801376864, 1.495644437589599, -0.4667847796501322], 0.19526424470709836)
|
||||
])
|
||||
|
||||
lime = (VectorLIME()
|
||||
.setModel(model)
|
||||
.setBackgroundData(df)
|
||||
.setInputCol("features")
|
||||
.setTargetCol("label")
|
||||
.setOutputCol("weights")
|
||||
.setNumSamples(1000))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.explainers._
|
||||
import spark.implicits._
|
||||
import breeze.linalg.{*, DenseMatrix => BDM}
|
||||
import breeze.stats.distributions.Rand
|
||||
import org.apache.spark.ml.linalg.Vectors
|
||||
import org.apache.spark.ml.regression.LinearRegression
|
||||
|
||||
val d1 = 3
|
||||
val d2 = 1
|
||||
val coefficients: BDM[Double] = new BDM(d1, d2, Array(1.0, -1.0, 2.0))
|
||||
|
||||
val df = {
|
||||
val nRows = 100
|
||||
val intercept: Double = math.random()
|
||||
|
||||
val x: BDM[Double] = BDM.rand(nRows, d1, Rand.gaussian)
|
||||
val y = x * coefficients + intercept
|
||||
|
||||
val xRows = x(*, ::).iterator.toSeq.map(dv => Vectors.dense(dv.toArray))
|
||||
val yRows = y(*, ::).iterator.toSeq.map(dv => dv(0))
|
||||
xRows.zip(yRows).toDF("features", "label")
|
||||
}
|
||||
|
||||
val model: LinearRegressionModel = new LinearRegression().fit(df)
|
||||
|
||||
val lime = (new VectorLIME()
|
||||
.setModel(model)
|
||||
.setBackgroundData(df)
|
||||
.setInputCol("features")
|
||||
.setTargetCol(model.getPredictionCol)
|
||||
.setOutputCol("weights")
|
||||
.setNumSamples(1000))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VectorLIME"
|
||||
py="synapse.ml.explainers.html#module-synapse.ml.explainers.VectorLIME"
|
||||
scala="com/microsoft/azure/synapse/ml/explainers/VectorLIME.html"
|
||||
csharp="classSynapse_1_1ML_1_1Explainers_1_1VectorLIME.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/explainers/VectorLIME.scala" />
|
||||
|
||||
|
||||
### VectorSHAP
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model = ONNXModel()
|
||||
|
||||
shap = (VectorSHAP()
|
||||
.setInputCol("features")
|
||||
.setOutputCol("shapValues")
|
||||
.setNumSamples(1000)
|
||||
.setModel(model)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClasses([1]))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.explainers._
|
||||
import spark.implicits._
|
||||
import breeze.linalg.{*, DenseMatrix => BDM}
|
||||
import breeze.stats.distributions.RandBasis
|
||||
import org.apache.spark.ml.classification.LogisticRegression
|
||||
import org.apache.spark.ml.linalg.Vectors
|
||||
|
||||
val randBasis = RandBasis.withSeed(123)
|
||||
val m: BDM[Double] = BDM.rand[Double](1000, 5, randBasis.gaussian)
|
||||
val l: BDV[Double] = m(*, ::).map {
|
||||
row =>
|
||||
if (row(2) + row(3) > 0.5) 1d else 0d
|
||||
}
|
||||
val data = m(*, ::).iterator.zip(l.valuesIterator).map {
|
||||
case (f, l) => (f.toSpark, l)
|
||||
}.toSeq.toDF("features", "label")
|
||||
|
||||
val model = new LogisticRegression()
|
||||
.setFeaturesCol("features")
|
||||
.setLabelCol("label")
|
||||
.fit(data)
|
||||
|
||||
val shap = (new VectorSHAP()
|
||||
.setInputCol("features")
|
||||
.setOutputCol("shapValues")
|
||||
.setBackgroundData(data)
|
||||
.setNumSamples(1000)
|
||||
.setModel(model)
|
||||
.setTargetCol("probability")
|
||||
.setTargetClasses(Array(1))
|
||||
|
||||
val infer = Seq(
|
||||
Tuple1(Vectors.dense(1d, 1d, 1d, 1d, 1d))
|
||||
) toDF "features"
|
||||
val predicted = model.transform(infer)
|
||||
shap.transform(predicted).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="VectorSHAP"
|
||||
py="synapse.ml.explainers.html#module-synapse.ml.explainers.VectorSHAP"
|
||||
scala="com/microsoft/azure/synapse/ml/explainers/VectorSHAP.html"
|
||||
csharp="classSynapse_1_1ML_1_1Explainers_1_1VectorSHAP.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/explainers/VectorSHAP.scala" />
|
||||
|
|
@ -0,0 +1,282 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Featurize
|
||||
|
||||
### DataConversion
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize import *
|
||||
|
||||
df = spark.createDataFrame([
|
||||
(True, 1, 2, 3, 4, 5.0, 6.0, "7", "8.0"),
|
||||
(False, 9, 10, 11, 12, 14.5, 15.5, "16", "17.456"),
|
||||
(True, -127, 345, 666, 1234, 18.91, 20.21, "100", "200.12345")
|
||||
], ["bool", "byte", "short", "int", "long", "float", "double", "intstring", "doublestring"])
|
||||
|
||||
dc = (DataConversion()
|
||||
.setCols(["byte"])
|
||||
.setConvertTo("boolean"))
|
||||
|
||||
dc.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize._
|
||||
import spark.implicits._
|
||||
|
||||
val df = Seq(
|
||||
(true: Boolean, 1: Byte, 2: Short, 3: Integer, 4: Long, 5.0F, 6.0, "7", "8.0"),
|
||||
(false, 9: Byte, 10: Short, 11: Integer, 12: Long, 14.5F, 15.5, "16", "17.456"),
|
||||
(true, -127: Byte, 345: Short, Short.MaxValue + 100, (Int.MaxValue).toLong + 100, 18.91F, 20.21, "100", "200.12345"))
|
||||
.toDF("bool", "byte", "short", "int", "long", "float", "double", "intstring", "doublestring")
|
||||
|
||||
val dc = (new DataConversion()
|
||||
.setCols(Array("byte"))
|
||||
.setConvertTo("boolean"))
|
||||
|
||||
dc.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="DataConversion"
|
||||
py="synapse.ml.featurize.html#module-synapse.ml.featurize.DataConversion"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/DataConversion.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1DataConversion.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/DataConversion.scala" />
|
||||
|
||||
|
||||
### IndexToValue
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize import *
|
||||
|
||||
df = spark.createDataFrame([
|
||||
(-3, 24, 0.32534, True, "piano"),
|
||||
(1, 5, 5.67, False, "piano"),
|
||||
(-3, 5, 0.32534, False, "guitar")
|
||||
], ["int", "long", "double", "bool", "string"])
|
||||
|
||||
df2 = ValueIndexer().setInputCol("string").setOutputCol("string_cat").fit(df).transform(df)
|
||||
|
||||
itv = (IndexToValue()
|
||||
.setInputCol("string_cat")
|
||||
.setOutputCol("string_noncat"))
|
||||
|
||||
itv.transform(df2).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize._
|
||||
import spark.implicits._
|
||||
|
||||
val df = Seq[(Int, Long, Double, Boolean, String)](
|
||||
(-3, 24L, 0.32534, true, "piano"),
|
||||
(1, 5L, 5.67, false, "piano"),
|
||||
(-3, 5L, 0.32534, false, "guitar")).toDF("int", "long", "double", "bool", "string")
|
||||
|
||||
val df2 = new ValueIndexer().setInputCol("string").setOutputCol("string_cat").fit(df).transform(df)
|
||||
|
||||
val itv = (new IndexToValue()
|
||||
.setInputCol("string_cat")
|
||||
.setOutputCol("string_noncat"))
|
||||
|
||||
itv.transform(df2).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="IndexToValue"
|
||||
py="synapse.ml.featurize.html#module-synapse.ml.featurize.IndexToValue"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/IndexToValue.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1IndexToValue.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/IndexToValue.scala" />
|
||||
|
||||
|
||||
## Featurize Text
|
||||
|
||||
### MultiNGram
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize.text import *
|
||||
from pyspark.ml.feature import Tokenizer
|
||||
|
||||
dfRaw = spark.createDataFrame([
|
||||
(0, "Hi I"),
|
||||
(1, "I wish for snow today"),
|
||||
(2, "we Cant go to the park, because of the snow!"),
|
||||
(3, ""),
|
||||
(4, "1 2 3 4 5 6 7 8 9")
|
||||
], ["label", "sentence"])
|
||||
|
||||
dfTok = (Tokenizer()
|
||||
.setInputCol("sentence")
|
||||
.setOutputCol("tokens")
|
||||
.transform(dfRaw))
|
||||
|
||||
mng = (MultiNGram()
|
||||
.setLengths([1, 3, 4])
|
||||
.setInputCol("tokens")
|
||||
.setOutputCol("ngrams"))
|
||||
|
||||
mng.transform(dfTok).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize.text._
|
||||
import org.apache.spark.ml.feature.Tokenizer
|
||||
import spark.implicits._
|
||||
|
||||
val dfRaw = (Seq(
|
||||
(0, "Hi I"),
|
||||
(1, "I wish for snow today"),
|
||||
(2, "we Cant go to the park, because of the snow!"),
|
||||
(3, ""),
|
||||
(4, (1 to 10).map(_.toString).mkString(" ")))
|
||||
.toDF("label", "sentence"))
|
||||
|
||||
val dfTok = (new Tokenizer()
|
||||
.setInputCol("sentence")
|
||||
.setOutputCol("tokens")
|
||||
.transform(dfRaw))
|
||||
|
||||
val mng = (new MultiNGram()
|
||||
.setLengths(Array(1, 3, 4))
|
||||
.setInputCol("tokens")
|
||||
.setOutputCol("ngrams"))
|
||||
|
||||
mng.transform(dfTok).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="MultiNGram"
|
||||
py="synapse.ml.featurize.text.html#module-synapse.ml.featurize.text.MultiNGram"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/text/MultiNGram.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1Text_1_1MultiNGram.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/text/MultiNGram.scala" />
|
||||
|
||||
|
||||
### PageSplitter
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize.text import *
|
||||
|
||||
df = spark.createDataFrame([
|
||||
("words words words wornssaa ehewjkdiw weijnsikjn xnh", ),
|
||||
("s s s s s s", ),
|
||||
("hsjbhjhnskjhndwjnbvckjbnwkjwenbvfkjhbnwevkjhbnwejhkbnvjkhnbndjkbnd", ),
|
||||
("hsjbhjhnskjhndwjnbvckjbnwkjwenbvfkjhbnwevkjhbnwejhkbnvjkhnbndjkbnd 190872340870271091309831097813097130i3u709781", ),
|
||||
("", ),
|
||||
(None, )
|
||||
], ["text"])
|
||||
|
||||
ps = (PageSplitter()
|
||||
.setInputCol("text")
|
||||
.setMaximumPageLength(20)
|
||||
.setMinimumPageLength(10)
|
||||
.setOutputCol("pages"))
|
||||
|
||||
ps.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.featurize.text._
|
||||
import spark.implicits._
|
||||
|
||||
val df = Seq(
|
||||
"words words words wornssaa ehewjkdiw weijnsikjn xnh",
|
||||
"s s s s s s",
|
||||
"hsjbhjhnskjhndwjnbvckjbnwkjwenbvfkjhbnwevkjhbnwejhkbnvjkhnbndjkbnd",
|
||||
"hsjbhjhnskjhndwjnbvckjbnwkjwenbvfkjhbnwevkjhbnwejhkbnvjkhnbndjkbnd " +
|
||||
"190872340870271091309831097813097130i3u709781",
|
||||
"",
|
||||
null
|
||||
).toDF("text")
|
||||
|
||||
val ps = (new PageSplitter()
|
||||
.setInputCol("text")
|
||||
.setMaximumPageLength(20)
|
||||
.setMinimumPageLength(10)
|
||||
.setOutputCol("pages"))
|
||||
|
||||
ps.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="PageSplitter"
|
||||
py="synapse.ml.featurize.text.html#module-synapse.ml.featurize.text.PageSplitter"
|
||||
scala="com/microsoft/azure/synapse/ml/featurize/text/PageSplitter.html"
|
||||
csharp="classSynapse_1_1ML_1_1Featurize_1_1Text_1_1PageSplitter.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/featurize/text/PageSplitter.scala" />
|
||||
|
|
@ -0,0 +1,341 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## IO
|
||||
|
||||
### HTTPTransformer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.io.http import *
|
||||
from pyspark.sql.functions import udf, col
|
||||
from requests import Request
|
||||
|
||||
def world_bank_request(country):
|
||||
return Request("GET", "http://api.worldbank.org/v2/country/{}?format=json".format(country))
|
||||
|
||||
df = (spark.createDataFrame([("br",), ("usa",)], ["country"])
|
||||
.withColumn("request", http_udf(world_bank_request)(col("country"))))
|
||||
|
||||
ht = (HTTPTransformer()
|
||||
.setConcurrency(3)
|
||||
.setInputCol("request")
|
||||
.setOutputCol("response"))
|
||||
|
||||
ht.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.io.http._
|
||||
|
||||
val ht = (new HTTPTransformer()
|
||||
.setConcurrency(3)
|
||||
.setInputCol("request")
|
||||
.setOutputCol("response"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="HTTPTransformer"
|
||||
py="synapse.ml.io.http.html#module-synapse.ml.io.http.HTTPTransformer"
|
||||
scala="com/microsoft/azure/synapse/ml/io/http/HTTPTransformer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Io_1_1Http_1_1HTTPTransformer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/io/http/HTTPTransformer.scala" />
|
||||
|
||||
|
||||
### SimpleHTTPTransformer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.io.http import *
|
||||
from pyspark.sql.types import StringType, StructType
|
||||
|
||||
sht = (SimpleHTTPTransformer()
|
||||
.setInputCol("data")
|
||||
.setOutputParser(JSONOutputParser()
|
||||
.setDataType(StructType().add("blah", StringType())))
|
||||
.setUrl("PUT_YOUR_URL")
|
||||
.setOutputCol("results")
|
||||
.setConcurrency(3))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.io.http._
|
||||
import org.apache.spark.sql.types.{StringType, StructType}
|
||||
|
||||
val sht = (new SimpleHTTPTransformer()
|
||||
.setInputCol("data")
|
||||
.setOutputParser(new JSONOutputParser()
|
||||
.setDataType(new StructType().add("blah", StringType)))
|
||||
.setUrl("PUT_YOUR_URL")
|
||||
.setOutputCol("results")
|
||||
.setConcurrency(3))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="SimpleHTTPTransformer"
|
||||
py="synapse.ml.io.http.html#module-synapse.ml.io.http.SimpleHTTPTransformer"
|
||||
scala="com/microsoft/azure/synapse/ml/io/http/SimpleHTTPTransformer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Io_1_1Http_1_1SimpleHTTPTransformer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/io/http/SimpleHTTPTransformer.scala" />
|
||||
|
||||
|
||||
### JSONInputParser
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.io.http import *
|
||||
|
||||
jsonIP = (JSONInputParser()
|
||||
.setInputCol("data")
|
||||
.setOutputCol("out")
|
||||
.setUrl("PUT_YOUR_URL"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.io.http._
|
||||
|
||||
val jsonIP = (new JSONInputParser()
|
||||
.setInputCol("data")
|
||||
.setOutputCol("out")
|
||||
.setUrl("PUT_YOUR_URL"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="JSONInputParser"
|
||||
py="synapse.ml.io.http.html#module-synapse.ml.io.http.JSONInputParser"
|
||||
scala="com/microsoft/azure/synapse/ml/io/http/JSONInputParser.html"
|
||||
csharp="classSynapse_1_1ML_1_1Io_1_1Http_1_1JSONInputParser.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/io/http/JSONInputParser.scala" />
|
||||
|
||||
|
||||
### JSONOutputParser
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.io.http import *
|
||||
from pyspark.sql.types import StringType, StructType
|
||||
|
||||
jsonOP = (JSONOutputParser()
|
||||
.setDataType(StructType().add("foo", StringType()))
|
||||
.setInputCol("unparsedOutput")
|
||||
.setOutputCol("parsedOutput"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.io.http._
|
||||
import org.apache.spark.sql.types.{StringType, StructType}
|
||||
|
||||
val jsonOP = (new JSONOutputParser()
|
||||
.setDataType(new StructType().add("foo", StringType))
|
||||
.setInputCol("unparsedOutput")
|
||||
.setOutputCol("parsedOutput"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="JSONOutputParser"
|
||||
py="synapse.ml.io.http.html#module-synapse.ml.io.http.JSONOutputParser"
|
||||
scala="com/microsoft/azure/synapse/ml/io/http/JSONOutputParser.html"
|
||||
csharp="classSynapse_1_1ML_1_1Io_1_1Http_1_1JSONOutputParser.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/io/http/JSONOutputParser.scala" />
|
||||
|
||||
|
||||
### StringOutputParser
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.io.http import *
|
||||
|
||||
sop = (StringOutputParser()
|
||||
.setInputCol("unparsedOutput")
|
||||
.setOutputCol("out"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.io.http._
|
||||
|
||||
val sop = (new StringOutputParser()
|
||||
.setInputCol("unparsedOutput")
|
||||
.setOutputCol("out"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="StringOutputParser"
|
||||
py="synapse.ml.io.http.html#module-synapse.ml.io.http.StringOutputParser"
|
||||
scala="com/microsoft/azure/synapse/ml/io/http/StringOutputParser.html"
|
||||
csharp="classSynapse_1_1ML_1_1Io_1_1Http_1_1StringOutputParser.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/io/http/StringOutputParser.scala" />
|
||||
|
||||
|
||||
### CustomInputParser
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.io.http import *
|
||||
|
||||
cip = (CustomInputParser()
|
||||
.setInputCol("data")
|
||||
.setOutputCol("out"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.io.http._
|
||||
|
||||
val cip = (new CustomInputParser()
|
||||
.setInputCol("data")
|
||||
.setOutputCol("out")
|
||||
.setUDF({ x: Int => new HttpPost(s"http://$x") }))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="CustomInputParser"
|
||||
py="synapse.ml.io.http.html#module-synapse.ml.io.http.CustomInputParser"
|
||||
scala="com/microsoft/azure/synapse/ml/io/http/CustomInputParser.html"
|
||||
csharp="classSynapse_1_1ML_1_1Io_1_1Http_1_1CustomInputParser.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/io/http/CustomInputParser.scala" />
|
||||
|
||||
|
||||
### CustomOutputParser
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.io.http import *
|
||||
|
||||
cop = (CustomOutputParser()
|
||||
.setInputCol("unparsedOutput")
|
||||
.setOutputCol("out"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.io.http._
|
||||
|
||||
val cop = (new CustomOutputParser()
|
||||
.setInputCol("unparsedOutput")
|
||||
.setOutputCol("out"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="CustomOutputParser"
|
||||
py="synapse.ml.io.http.html#module-synapse.ml.io.http.CustomOutputParser"
|
||||
scala="com/microsoft/azure/synapse/ml/io/http/CustomOutputParser.html"
|
||||
csharp="classSynapse_1_1ML_1_1Io_1_1Http_1_1CustomOutputParser.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/io/http/CustomOutputParser.scala" />
|
||||
|
|
@ -0,0 +1,150 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Image
|
||||
|
||||
### UnrollImage
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.image import *
|
||||
from azure.storage.blob import *
|
||||
# images = (spark.read.format("image")
|
||||
# .option("dropInvalid", True)
|
||||
# .load("wasbs://datasets@mmlspark.blob.core.windows.net/LIME/greyscale.jpg"))
|
||||
# rit = (ResizeImageTransformer()
|
||||
# .setOutputCol("out")
|
||||
# .setHeight(15)
|
||||
# .setWidth(10))
|
||||
# preprocessed = rit.transform(images)
|
||||
unroll = (UnrollImage()
|
||||
.setInputCol("out")
|
||||
.setOutputCol("final"))
|
||||
# unroll.transform(preprocessed).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.image._
|
||||
import spark.implicits._
|
||||
val images = (spark.read.format("image")
|
||||
.option("dropInvalid", true)
|
||||
.load("wasbs://datasets@mmlspark.blob.core.windows.net/LIME/greyscale.jpg"))
|
||||
val rit = (new ResizeImageTransformer()
|
||||
.setOutputCol("out")
|
||||
.setHeight(15)
|
||||
.setWidth(10))
|
||||
val preprocessed = rit.transform(images)
|
||||
val unroll = (new UnrollImage()
|
||||
.setInputCol(rit.getOutputCol)
|
||||
.setOutputCol("final"))
|
||||
unroll.transform(preprocessed).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="UnrollImage"
|
||||
py="synapse.ml.image.html#module-synapse.ml.image.UnrollImage"
|
||||
scala="com/microsoft/azure/synapse/ml/image/UnrollImage.html"
|
||||
csharp="classSynapse_1_1ML_1_1Image_1_1UnrollImage.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/image/UnrollImage.scala" />
|
||||
|
||||
|
||||
### UnrollBinaryImage
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.image import *
|
||||
unroll = (UnrollBinaryImage()
|
||||
.setInputCol("input_col")
|
||||
.setOutputCol("final"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.image._
|
||||
import spark.implicits._
|
||||
val unroll = (new UnrollBinaryImage()
|
||||
.setInputCol("input_col")
|
||||
.setOutputCol("final"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="UnrollBinaryImage"
|
||||
py="synapse.ml.image.html#module-synapse.ml.image.UnrollBinaryImage"
|
||||
scala="com/microsoft/azure/synapse/ml/image/UnrollBinaryImage.html"
|
||||
csharp="classSynapse_1_1ML_1_1Image_1_1UnrollBinaryImage.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/image/UnrollBinaryImage.scala" />
|
||||
|
||||
### SuperpixelTransformer
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.image import *
|
||||
|
||||
spt = (SuperpixelTransformer()
|
||||
.setInputCol("images"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.image._
|
||||
|
||||
val spt = (new SuperpixelTransformer()
|
||||
.setInputCol("images"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="SuperpixelTransformer"
|
||||
py="synapse.ml.lime.html#module-synapse.ml.image.SuperpixelTransformer"
|
||||
scala="com/microsoft/azure/synapse/ml/image/SuperpixelTransformer.html"
|
||||
csharp="classSynapse_1_1ML_1_1Image_1_1SuperpixelTransformer.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/image/SuperpixelTransformer.scala" />
|
||||
Разница между файлами не показана из-за своего большого размера
Загрузить разницу
|
|
@ -0,0 +1,151 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
|
||||
|
||||
## Train
|
||||
|
||||
### ComputeModelStatistics
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.train import *
|
||||
from numpy import random
|
||||
|
||||
df = spark.createDataFrame(
|
||||
[(random.rand(), random.rand()) for _ in range(2048)], ["label", "prediction"]
|
||||
)
|
||||
|
||||
cms = (ComputeModelStatistics()
|
||||
.setLabelCol("label")
|
||||
.setScoredLabelsCol("prediction")
|
||||
.setEvaluationMetric("classification"))
|
||||
|
||||
cms.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.train._
|
||||
import scala.util.Random
|
||||
|
||||
val rand = new Random(1337)
|
||||
val df = (Seq.fill(2048)(rand.nextDouble())
|
||||
.zip(Seq.fill(2048)(rand.nextDouble()))
|
||||
.toDF("label", "prediction"))
|
||||
|
||||
val cms = (new ComputeModelStatistics()
|
||||
.setLabelCol("label")
|
||||
.setScoredLabelsCol("prediction")
|
||||
.setEvaluationMetric("classification"))
|
||||
|
||||
cms.transform(df).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ComputeModelStatistics"
|
||||
py="synapse.ml.train.html#module-synapse.ml.train.ComputeModelStatistics"
|
||||
scala="com/microsoft/azure/synapse/ml/train/ComputeModelStatistics.html"
|
||||
csharp="classSynapse_1_1ML_1_1Train_1_1ComputeModelStatistics.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/train/ComputeModelStatistics.scala" />
|
||||
|
||||
|
||||
### ComputePerInstanceStatistics
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
|
||||
|
||||
|
||||
<!--pytest-codeblocks:cont-->
|
||||
|
||||
```python
|
||||
from synapse.ml.train import *
|
||||
|
||||
cps = (ComputePerInstanceStatistics()
|
||||
.setLabelCol("label")
|
||||
.setScoredLabelsCol("LogRegScoredLabelsCol")
|
||||
.setScoresCol("LogRegScoresCol")
|
||||
.setScoredProbabilitiesCol("LogRegProbCol")
|
||||
.setEvaluationMetric("classification"))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.train._
|
||||
import org.apache.spark.ml.classification.LogisticRegression
|
||||
import org.apache.spark.ml.feature.FastVectorAssembler
|
||||
|
||||
val logisticRegression = (new LogisticRegression()
|
||||
.setRegParam(0.3)
|
||||
.setElasticNetParam(0.8)
|
||||
.setMaxIter(10)
|
||||
.setLabelCol("label")
|
||||
.setPredictionCol("LogRegScoredLabelsCol")
|
||||
.setRawPredictionCol("LogRegScoresCol")
|
||||
.setProbabilityCol("LogRegProbCol")
|
||||
.setFeaturesCol("features"))
|
||||
|
||||
val dataset = spark.createDataFrame(Seq(
|
||||
(0.0, 2, 0.50, 0.60, 0.0),
|
||||
(1.0, 3, 0.40, 0.50, 1.0),
|
||||
(2.0, 4, 0.78, 0.99, 2.0),
|
||||
(3.0, 5, 0.12, 0.34, 3.0),
|
||||
(0.0, 1, 0.50, 0.60, 0.0),
|
||||
(1.0, 3, 0.40, 0.50, 1.0),
|
||||
(2.0, 3, 0.78, 0.99, 2.0),
|
||||
(3.0, 4, 0.12, 0.34, 3.0),
|
||||
(0.0, 0, 0.50, 0.60, 0.0),
|
||||
(1.0, 2, 0.40, 0.50, 1.0),
|
||||
(2.0, 3, 0.78, 0.99, 2.0),
|
||||
(3.0, 4, 0.12, 0.34, 3.0)))
|
||||
.toDF("label", "col1", "col2", "col3", "prediction")
|
||||
|
||||
val assembler = (new FastVectorAssembler()
|
||||
.setInputCols(Array("col1", "col2", "col3"))
|
||||
.setOutputCol("features"))
|
||||
val assembledDataset = assembler.transform(dataset)
|
||||
val model = logisticRegression.fit(assembledDataset)
|
||||
val scoredData = model.transform(assembledDataset)
|
||||
|
||||
val cps = (new ComputePerInstanceStatistics()
|
||||
.setLabelCol("label")
|
||||
.setScoredLabelsCol("LogRegScoredLabelsCol")
|
||||
.setScoresCol("LogRegScoresCol")
|
||||
.setScoredProbabilitiesCol("LogRegProbCol")
|
||||
.setEvaluationMetric("classification"))
|
||||
|
||||
cps.transform(scoredData).show()
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ComputePerInstanceStatistics"
|
||||
py="synapse.ml.train.html#module-synapse.ml.train.ComputePerInstanceStatistics"
|
||||
scala="com/microsoft/azure/synapse/ml/train/ComputePerInstanceStatistics.html"
|
||||
csharp="classSynapse_1_1ML_1_1Train_1_1ComputePerInstanceStatistics.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/core/src/main/scala/com/microsoft/azure/synapse/ml/train/ComputePerInstanceStatistics.scala" />
|
||||
|
|
@ -0,0 +1,46 @@
|
|||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
import DocTable from "@theme/DocumentationTable";
|
||||
|
||||
|
||||
## ONNXModel
|
||||
|
||||
<Tabs
|
||||
defaultValue="py"
|
||||
values={[
|
||||
{label: `Python`, value: `py`},
|
||||
{label: `Scala`, value: `scala`},
|
||||
]}>
|
||||
<TabItem value="py">
|
||||
|
||||
```py
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
model_path = "PUT_YOUR_MODEL_PATH"
|
||||
onnx_ml = (ONNXModel()
|
||||
.setModelLocation(model_path)
|
||||
.setFeedDict({"float_input": "features"})
|
||||
.setFetchDict({"prediction": "output_label", "rawProbability": "output_probability"}))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="scala">
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.onnx._
|
||||
|
||||
val model_path = "PUT_YOUR_MODEL_PATH"
|
||||
val onnx_ml = (new ONNXModel()
|
||||
.setModelLocation(model_path)
|
||||
.setFeedDict(Map("float_input" -> "features"))
|
||||
.setFetchDict(Map("prediction" -> "output_label", "rawProbability" -> "output_probability")))
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
<DocTable className="ONNXModel"
|
||||
py="synapse.ml.onnx.html#module-synapse.ml.onnx.ONNXModel"
|
||||
scala="com/microsoft/azure/synapse/ml/onnx/ONNXModel.html"
|
||||
csharp="classSynapse_1_1ML_1_1Onnx_1_1ONNXModel.html"
|
||||
sourceLink="https://github.com/microsoft/SynapseML/blob/master/deep-learning/src/main/scala/com/microsoft/azure/synapse/ml/onnx/ONNXModel.scala" />
|
||||
|
|
@ -0,0 +1,55 @@
|
|||
---
|
||||
title: Transformers - Cognitive
|
||||
sidebar_label: Cognitive
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
|
||||
import TextAnalytics, {toc as TextAnalyticsTOC} from './cognitive/_TextAnalytics.md';
|
||||
|
||||
<TextAnalytics/>
|
||||
|
||||
|
||||
import Translator, {toc as TranslatorTOC} from './cognitive/_Translator.md';
|
||||
|
||||
<Translator/>
|
||||
|
||||
|
||||
import ComputerVision, {toc as ComputerVisionTOC} from './cognitive/_ComputerVision.md';
|
||||
|
||||
<ComputerVision/>
|
||||
|
||||
|
||||
import FormRecognizer, {toc as FormRecognizerTOC} from './cognitive/_FormRecognizer.md';
|
||||
|
||||
<FormRecognizer/>
|
||||
|
||||
|
||||
import AnomalyDetection, {toc as AnomalyDetectionTOC} from './cognitive/_AnomalyDetection.md';
|
||||
|
||||
<AnomalyDetection/>
|
||||
|
||||
|
||||
import Face, {toc as FaceTOC} from './cognitive/_Face.md';
|
||||
|
||||
<Face/>
|
||||
|
||||
|
||||
import SpeechToText, {toc as SpeechToTextTOC} from './cognitive/_SpeechToText.md';
|
||||
|
||||
<SpeechToText/>
|
||||
|
||||
|
||||
import AzureSearch, {toc as AzureSearchTOC} from './cognitive/_AzureSearch.md';
|
||||
|
||||
<AzureSearch/>
|
||||
|
||||
|
||||
import BingImageSearch, {toc as BingImageSearchTOC} from './cognitive/_BingImageSearch.md';
|
||||
|
||||
<BingImageSearch/>
|
||||
|
||||
|
||||
export const toc = [...TextAnalyticsTOC, ...TranslatorTOC, ...ComputerVisionTOC,
|
||||
...FormRecognizerTOC, ...AnomalyDetectionTOC, ...FaceTOC, ...SpeechToTextTOC,
|
||||
...AzureSearchTOC, ...BingImageSearchTOC]
|
||||
|
|
@ -0,0 +1,38 @@
|
|||
---
|
||||
title: Transformers - Core
|
||||
sidebar_label: Core
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
|
||||
import Explainers, {toc as ExplainersTOC} from './core/_Explainers.md';
|
||||
|
||||
<Explainers/>
|
||||
|
||||
|
||||
import Featurize, {toc as FeaturizeTOC} from './core/_Featurize.md';
|
||||
|
||||
<Featurize/>
|
||||
|
||||
|
||||
import Image, {toc as ImageTOC} from './core/_Image.md';
|
||||
|
||||
<Image/>
|
||||
|
||||
|
||||
import IO, {toc as IOTOC} from './core/_IO.md';
|
||||
|
||||
<IO/>
|
||||
|
||||
|
||||
import Stages, {toc as StagesTOC} from './core/_Stages.md';
|
||||
|
||||
<Stages/>
|
||||
|
||||
|
||||
import Train, {toc as TrainTOC} from './core/_Train.md';
|
||||
|
||||
<Train/>
|
||||
|
||||
export const toc = [...ExplainersTOC, ...FeaturizeTOC, ...ImageTOC,
|
||||
...IOTOC, ...StagesTOC, ...TrainTOC]
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
---
|
||||
title: Deep Learning
|
||||
sidebar_label: Deep Learning
|
||||
---
|
||||
|
||||
import ONNXModel, {toc as ONNXModelTOC} from './deep_learning/_ONNXModel.md';
|
||||
|
||||
<ONNXModel/>
|
||||
|
||||
export const toc = [...ONNXModelTOC]
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
---
|
||||
title: Transformers - OpenCV
|
||||
sidebar_label: OpenCV
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
# OpenCV
|
||||
|
||||
import OpenCV, {toc as OpenCVTOC} from './_OpenCV.md';
|
||||
|
||||
<OpenCV/>
|
||||
|
||||
export const toc = [...OpenCVTOC]
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
---
|
||||
title: Transformers - Vowpal Wabbit
|
||||
sidebar_label: Vowpal Wabbit
|
||||
hide_title: true
|
||||
---
|
||||
|
||||
# Vowpal Wabbit
|
||||
|
||||
import VW, {toc as VWTOC} from './_VW.md';
|
||||
|
||||
<VW/>
|
||||
|
||||
export const toc = [...VWTOC]
|
||||
|
|
@ -0,0 +1,101 @@
|
|||
---
|
||||
title: Effects of Outreach Efforts
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Startup Investment Attribution - Understand Outreach Effort's Effect"
|
||||
|
||||

|
||||
|
||||
**This sample notebook aims to show the application of using SynapseML's DoubleMLEstimator for inferring causality using observational data.**
|
||||
|
||||
A startup that sells software would like to know whether its outreach efforts were successful in attracting new customers or boosting consumption among existing customers. In other words, they would like to learn the treatment effect of each investment on customers' software usage.
|
||||
|
||||
In an ideal world, the startup would run several randomized experiments where each customer would receive a random assortment of investments. However, this can be logistically prohibitive or strategically unsound: the startup might not have the resources to design such experiments or they might not want to risk losing out on big opportunities due to lack of incentives.
|
||||
|
||||
In this customer scenario walkthrough, we show how SynapseML causal package can use historical investment data to learn the investment effect.
|
||||
|
||||
## Background
|
||||
In this scenario, a startup that sells software provides discounts incentives to its customer. A customer might be given or not.
|
||||
|
||||
The startup has historical data on these investments for 2,000 customers, as well as how much revenue these customers generated in the year after the investments were made. They would like to use this data to learn the optimal incentive policy for each existing or new customer in order to maximize the return on investment (ROI).
|
||||
|
||||
The startup faces a challenge: the dataset is biased because historically the larger customers received the most incentives. Thus, they need a causal model that can remove the bias.
|
||||
|
||||
## Data
|
||||
The data* contains ~2,000 customers and is comprised of:
|
||||
|
||||
* Customer features: details about the industry, size, revenue, and technology profile of each customer.
|
||||
* Interventions: information about which incentive was given to a customer.
|
||||
* Outcome: the amount of product the customer bought in the year after the incentives were given.
|
||||
|
||||
|
||||
| Feature Name | Type | Details |
|
||||
|-----------------|------|---------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Global Flag | W | whether the customer has global offices |
|
||||
| Major Flag | W | whether the customer is a large consumer in their industry (as opposed to SMC - Small Medium Corporation - or SMB - Small Medium Business) |
|
||||
| SMC Flag | W | whether the customer is a Small Medium Corporation (SMC, as opposed to major and SMB) |
|
||||
| Commercial Flag | W | whether the customer's business is commercial (as opposed to public secor) |
|
||||
| IT Spend | W | $ spent on IT-related purchases |
|
||||
| Employee Count | W | number of employees |
|
||||
| PC Count | W | number of PCs used by the customer | |
|
||||
| Discount | T | whether the customer was given a discount (binary) |
|
||||
| Revenue | Y | $ Revenue from customer given by the amount of software purchased |
|
||||
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Import the sample multi-attribution data
|
||||
data = (
|
||||
spark.read.format("csv")
|
||||
.option("inferSchema", True)
|
||||
.option("header", True)
|
||||
.load(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/multi_attribution_sample.csv"
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
# Get Causal Effects with SynapseML DoubleMLEstimator
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.causal import *
|
||||
from pyspark.ml.classification import LogisticRegression
|
||||
from pyspark.ml.regression import LinearRegression
|
||||
|
||||
treatmentColumn = "Discount"
|
||||
outcomeColumn = "Revenue"
|
||||
|
||||
dml = (
|
||||
DoubleMLEstimator()
|
||||
.setTreatmentModel(LogisticRegression())
|
||||
.setTreatmentCol(treatmentColumn)
|
||||
.setOutcomeModel(LinearRegression())
|
||||
.setOutcomeCol(outcomeColumn)
|
||||
.setMaxIter(20)
|
||||
)
|
||||
|
||||
model = dml.fit(data)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Get average treatment effect, it returns a numeric value, e.g. 5166.78324
|
||||
# It means, on average, customers who received a discount spent $5,166 more on software
|
||||
model.getAvgTreatmentEffect()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Get treatment effect's confidence interval, e.g. [4765.826181160708, 5371.2817538168965]
|
||||
model.getConfidenceInterval()
|
||||
```
|
||||
|
|
@ -0,0 +1,153 @@
|
|||
---
|
||||
title: Heterogeneous Effects of Outreach Efforts
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Startup Investment Attribution - Understand Outreach Effort's Effect"
|
||||
|
||||

|
||||
|
||||
**This sample notebook aims to show the application of using SynapseML's DoubleMLEstimator for inferring causality using observational data.**
|
||||
|
||||
A startup that sells software would like to know whether its outreach efforts were successful in attracting new customers or boosting consumption among existing customers. In other words, they would like to learn the treatment effect of each investment on customers' software usage.
|
||||
|
||||
In an ideal world, the startup would run several randomized experiments where each customer would receive a random assortment of investments. However, this can be logistically prohibitive or strategically unsound: the startup might not have the resources to design such experiments or they might not want to risk losing out on big opportunities due to lack of incentives.
|
||||
|
||||
In this customer scenario walkthrough, we show how SynapseML causal package can use historical investment data to learn the investment effect.
|
||||
|
||||
## Background
|
||||
In this scenario, a startup that sells software provides discounts incentives to its customer. A customer might be given or not.
|
||||
|
||||
The startup has historical data on these investments for 2,000 customers, as well as how much revenue these customers generated in the year after the investments were made. They would like to use this data to learn the optimal incentive policy for each existing or new customer in order to maximize the return on investment (ROI).
|
||||
|
||||
The startup faces a challenge: the dataset is biased because historically the larger customers received the most incentives. Thus, they need a causal model that can remove the bias.
|
||||
|
||||
## Data
|
||||
The data* contains ~2,000 customers and is comprised of:
|
||||
|
||||
* Customer features: details about the industry, size, revenue, and technology profile of each customer.
|
||||
* Interventions: information about which incentive was given to a customer.
|
||||
* Outcome: the amount of product the customer bought in the year after the incentives were given.
|
||||
|
||||
|
||||
| Feature Name | Type | Details |
|
||||
|-----------------|------|---------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Global Flag | W | whether the customer has global offices |
|
||||
| Major Flag | W | whether the customer is a large consumer in their industry (as opposed to SMC - Small Medium Corporation - or SMB - Small Medium Business) |
|
||||
| SMC Flag | W | whether the customer is a Small Medium Corporation (SMC, as opposed to major and SMB) |
|
||||
| Commercial Flag | W | whether the customer's business is commercial (as opposed to public secor) |
|
||||
| IT Spend | W | dollar spent on IT-related purchases |
|
||||
| Employee Count | W | number of employees |
|
||||
| PC Count | W | number of PCs used by the customer | |
|
||||
| Size | X | customer's size given by their yearly total revenue | |
|
||||
| Discount | T | whether the customer was given a discount (binary) |
|
||||
| Revenue | Y | $ Revenue from customer given by the amount of software purchased |
|
||||
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Import the sample multi-attribution data
|
||||
data = (
|
||||
spark.read.format("csv")
|
||||
.option("inferSchema", True)
|
||||
.option("header", True)
|
||||
.load(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/multi_attribution_sample.csv"
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
# Get Heterogenous Causal Effects with SynapseML OrthoDML Estimator
|
||||
|
||||
|
||||
```python
|
||||
data.columns
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.causal import *
|
||||
from pyspark.ml import Pipeline
|
||||
from synapse.ml.causal import *
|
||||
from pyspark.ml.feature import VectorAssembler
|
||||
from pyspark.sql.types import IntegerType, BooleanType, DateType, DoubleType
|
||||
import matplotlib.pyplot as plt
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
treatmentColumn = "Discount"
|
||||
outcomeColumn = "Revenue"
|
||||
confounderColumns = [
|
||||
"Global Flag",
|
||||
"Major Flag",
|
||||
"SMC Flag",
|
||||
"Commercial Flag",
|
||||
"Employee Count",
|
||||
"PC Count",
|
||||
]
|
||||
heteroColumns = ["Size", "IT Spend"]
|
||||
heterogeneityVecCol = "XVec"
|
||||
confounderVecCol = "XWVec"
|
||||
|
||||
data = data.withColumn(treatmentColumn, data.Discount.cast(DoubleType()))
|
||||
|
||||
heterogeneityVector = VectorAssembler(
|
||||
inputCols=heteroColumns, outputCol=heterogeneityVecCol
|
||||
)
|
||||
|
||||
confounderVector = VectorAssembler(
|
||||
inputCols=confounderColumns, outputCol=confounderVecCol
|
||||
)
|
||||
|
||||
pipeline = Pipeline(stages=[heterogeneityVector, confounderVector])
|
||||
|
||||
ppfit = pipeline.fit(data).transform(data)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
### Create the Ortho Forest DML Estimator Model
|
||||
mtTransform = (
|
||||
OrthoForestDMLEstimator()
|
||||
.setNumTrees(100)
|
||||
.setTreatmentCol(treatmentColumn)
|
||||
.setOutcomeCol(outcomeColumn)
|
||||
.setHeterogeneityVecCol(heterogeneityVecCol)
|
||||
.setConfounderVecCol(confounderVecCol)
|
||||
.setMaxDepth(10)
|
||||
.setMinSamplesLeaf(10)
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
### Fit the model for the data
|
||||
finalModel = mtTransform.fit(ppfit)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
### Transform the input data to see the model in action
|
||||
finalPred = finalModel.transform(ppfit)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
### Get the data in Pandas
|
||||
pd_final = finalPred.toPandas()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
### Plot and see the non-linear effects
|
||||
plt.scatter("Size", mtTransform.getOutputCol(), data=pd_final)
|
||||
```
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
---
|
||||
title: Causal Inference
|
||||
hide_title: true
|
||||
sidebar_label: About
|
||||
---
|
||||
|
||||
## Causal Inference on Apache Spark
|
||||
|
||||
### What is Causal Inference?
|
||||
One challenge that has taken the spotlight in recent years is using machine learning to drive decision makings in policy and business.
|
||||
Often, businesses and policymakers would like to study whether an incentive or intervention will lead to a desired outcome and by how much.
|
||||
For example, if we give customers a discount (treatment), how much more will they purchase in the future (outcome).
|
||||
Traditionally, people use correlation analysis or prediction model to understand correlated factors, but going from prediction to an
|
||||
impactful decision isn't always straightforward as correlation doesn't imply causation. In many cases, confounding variables influence
|
||||
both the probability of treatment and the outcome, introducing more non-causal correlation.
|
||||
|
||||
Causal inference helps to bridge the gap between prediction and decision-making.
|
||||
|
||||
### Causal Inference language
|
||||
| Term | Example |
|
||||
|-----------------|--------------------------------------------------------------------|
|
||||
| Treatment (T) | Seeing an advertisement |
|
||||
| Outcome (Y) | Probability of buying a specific new game |
|
||||
| Confounders (W) | Current gaming habits, past purchases, customer location, platform |
|
||||
|
||||
### Causal Inference and Double machine learning
|
||||
The gold standard approach to isolating causal questions is to run an experiment that randomly assigns the treatment to some customers.
|
||||
Randomization eliminates any relationship between the confounders and the probability of treatment,
|
||||
so any differences between treated and untreated customers can only reflect the direct causal effect of the treatment on the outcome (treatment effect).
|
||||
However, in many cases, treatments experiments are either impossible or cost prohibitive.
|
||||
As a result, we look toward causal inference methods that allow us to estimate the treatment effect using observational data.
|
||||
|
||||
The SynapseML causal package implements a technique "Double machine learning", which can be used to estimate the average treatment effect via machine learning models.
|
||||
Unlike regression-based approaches that make strict parametric assumptions, this machine learning-based approach allows us to model non-linear relationships between the confounders, treatment, and outcome.
|
||||
|
||||
### Usage
|
||||
In PySpark, you can run the `DoubleMLEstimator` via:
|
||||
|
||||
```python
|
||||
from pyspark.ml.classification import LogisticRegression
|
||||
from synapse.ml.causal import DoubleMLEstimator
|
||||
dml = (DoubleMLEstimator()
|
||||
.setTreatmentCol("Treatment")
|
||||
.setTreatmentModel(LogisticRegression())
|
||||
.setOutcomeCol("Outcome")
|
||||
.setOutcomeModel(LogisticRegression())
|
||||
.setMaxIter(20))
|
||||
dmlModel = dml.fit(dataset)
|
||||
```
|
||||
> Note: all columns except "Treatment" and "Outcome" in your dataset will be used as confounders.
|
||||
|
||||
> Note: For discrete treatment, the treatment column must be `int` or `bool`. `0` and `False` will be treated as the control group.
|
||||
|
||||
After fitting the model, you can get average treatment effect and confidence interval:
|
||||
```python
|
||||
dmlModel.getAvgTreatmentEffect()
|
||||
dmlModel.getConfidenceInterval()
|
||||
```
|
||||
|
||||
For an end to end application, check out the DoubleMLEstimator [notebook
|
||||
example](../Effects%20of%20Outreach%20Efforts).
|
||||
|
|
@ -0,0 +1,90 @@
|
|||
---
|
||||
title: Classification - Adult Census with Vowpal Wabbit
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Classification - Adult Census using Vowpal Wabbit in SynapseML
|
||||
|
||||
In this example, we predict incomes from the *Adult Census* dataset using Vowpal Wabbit (VW) classifier in SynapseML.
|
||||
First, we read the data and split it into train and test sets as in this [example](https://github.com/Microsoft/SynapseML/blob/master/notebooks/Classification%20-%20Adult%20Census.ipynb
|
||||
).
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
data = spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/AdultCensusIncome.parquet"
|
||||
)
|
||||
data = data.select(["education", "marital-status", "hours-per-week", "income"])
|
||||
train, test = data.randomSplit([0.75, 0.25], seed=123)
|
||||
train.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Next, we define a pipeline that includes feature engineering and training of a VW classifier. We use a featurizer provided by VW that hashes the feature names.
|
||||
Note that VW expects classification labels being -1 or 1. Thus, the income category is mapped to this space before feeding training data into the pipeline.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import when, col
|
||||
from pyspark.ml import Pipeline
|
||||
from synapse.ml.vw import VowpalWabbitFeaturizer, VowpalWabbitClassifier
|
||||
|
||||
# Define classification label
|
||||
train = (
|
||||
train.withColumn("label", when(col("income").contains("<"), 0.0).otherwise(1.0))
|
||||
.repartition(1)
|
||||
.cache()
|
||||
)
|
||||
print(train.count())
|
||||
|
||||
# Specify featurizer
|
||||
vw_featurizer = VowpalWabbitFeaturizer(
|
||||
inputCols=["education", "marital-status", "hours-per-week"], outputCol="features"
|
||||
)
|
||||
|
||||
# Define VW classification model
|
||||
args = "--loss_function=logistic --quiet --holdout_off"
|
||||
vw_model = VowpalWabbitClassifier(
|
||||
featuresCol="features", labelCol="label", passThroughArgs=args, numPasses=10
|
||||
)
|
||||
|
||||
# Create a pipeline
|
||||
vw_pipeline = Pipeline(stages=[vw_featurizer, vw_model])
|
||||
```
|
||||
|
||||
Then, we are ready to train the model by fitting the pipeline with the training data.
|
||||
|
||||
|
||||
```python
|
||||
# Train the model
|
||||
vw_trained = vw_pipeline.fit(train)
|
||||
```
|
||||
|
||||
After the model is trained, we apply it to predict the income of each sample in the test set.
|
||||
|
||||
|
||||
```python
|
||||
# Making predictions
|
||||
test = test.withColumn("label", when(col("income").contains("<"), 0.0).otherwise(1.0))
|
||||
prediction = vw_trained.transform(test)
|
||||
prediction.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Finally, we evaluate the model performance using `ComputeModelStatistics` function which will compute confusion matrix, accuracy, precision, recall, and AUC by default for classification models.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
|
||||
metrics = ComputeModelStatistics(
|
||||
evaluationMetric="classification", labelCol="label", scoredLabelsCol="prediction"
|
||||
).transform(prediction)
|
||||
metrics.toPandas()
|
||||
```
|
||||
|
|
@ -0,0 +1,73 @@
|
|||
---
|
||||
title: Classification - Adult Census
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## Classification - Adult Census
|
||||
|
||||
In this example, we try to predict incomes from the *Adult Census* dataset.
|
||||
|
||||
First, we import the packages (use `help(synapse)` to view contents),
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
```
|
||||
|
||||
Now let's read the data and split it to train and test sets:
|
||||
|
||||
|
||||
```python
|
||||
data = spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/AdultCensusIncome.parquet"
|
||||
)
|
||||
data = data.select(["education", "marital-status", "hours-per-week", "income"])
|
||||
train, test = data.randomSplit([0.75, 0.25], seed=123)
|
||||
train.limit(10).toPandas()
|
||||
```
|
||||
|
||||
`TrainClassifier` can be used to initialize and fit a model, it wraps SparkML classifiers.
|
||||
You can use `help(synapse.ml.train.TrainClassifier)` to view the different parameters.
|
||||
|
||||
Note that it implicitly converts the data into the format expected by the algorithm: tokenize
|
||||
and hash strings, one-hot encodes categorical variables, assembles the features into a vector
|
||||
and so on. The parameter `numFeatures` controls the number of hashed features.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import TrainClassifier
|
||||
from pyspark.ml.classification import LogisticRegression
|
||||
|
||||
model = TrainClassifier(
|
||||
model=LogisticRegression(), labelCol="income", numFeatures=256
|
||||
).fit(train)
|
||||
```
|
||||
|
||||
Finally, we save the model so it can be used in a scoring program.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
if running_on_synapse():
|
||||
model.write().overwrite().save(
|
||||
"abfss://synapse@mmlsparkeuap.dfs.core.windows.net/models/AdultCensus.mml"
|
||||
)
|
||||
elif running_on_synapse_internal():
|
||||
model.write().overwrite().save("Files/models/AdultCensus.mml")
|
||||
elif running_on_databricks():
|
||||
model.write().overwrite().save("dbfs:/AdultCensus.mml")
|
||||
elif running_on_binder():
|
||||
model.write().overwrite().save("/tmp/AdultCensus.mml")
|
||||
else:
|
||||
print(f"{current_platform()} platform not supported")
|
||||
```
|
||||
|
|
@ -0,0 +1,228 @@
|
|||
---
|
||||
title: Classification - Before and After SynapseML
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## Classification - Before and After SynapseML
|
||||
|
||||
### 1. Introduction
|
||||
|
||||
<p><img src="https://images-na.ssl-images-amazon.com/images/G/01/img16/books/bookstore/landing-page/1000638_books_landing-page_bookstore-photo-01.jpg" title="Image from https://images-na.ssl-images-amazon.com/images/G/01/img16/books/bookstore/landing-page/1000638_books_landing-page_bookstore-photo-01.jpg" /><br /></p>
|
||||
|
||||
In this tutorial, we perform the same classification task in two
|
||||
different ways: once using plain **`pyspark`** and once using the
|
||||
**`synapseml`** library. The two methods yield the same performance,
|
||||
but one of the two libraries is drastically simpler to use and iterate
|
||||
on (can you guess which one?).
|
||||
|
||||
The task is simple: Predict whether a user's review of a book sold on
|
||||
Amazon is good (rating > 3) or bad based on the text of the review. We
|
||||
accomplish this by training LogisticRegression learners with different
|
||||
hyperparameters and choosing the best model.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
### 2. Read the data
|
||||
|
||||
We download and read in the data. We show a sample below:
|
||||
|
||||
|
||||
```python
|
||||
rawData = spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/BookReviewsFromAmazon10K.parquet"
|
||||
)
|
||||
rawData.show(5)
|
||||
```
|
||||
|
||||
### 3. Extract more features and process data
|
||||
|
||||
Real data however is more complex than the above dataset. It is common
|
||||
for a dataset to have features of multiple types: text, numeric,
|
||||
categorical. To illustrate how difficult it is to work with these
|
||||
datasets, we add two numerical features to the dataset: the **word
|
||||
count** of the review and the **mean word length**.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import udf
|
||||
from pyspark.sql.types import *
|
||||
|
||||
|
||||
def wordCount(s):
|
||||
return len(s.split())
|
||||
|
||||
|
||||
def wordLength(s):
|
||||
import numpy as np
|
||||
|
||||
ss = [len(w) for w in s.split()]
|
||||
return round(float(np.mean(ss)), 2)
|
||||
|
||||
|
||||
wordLengthUDF = udf(wordLength, DoubleType())
|
||||
wordCountUDF = udf(wordCount, IntegerType())
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.stages import UDFTransformer
|
||||
|
||||
wordLength = "wordLength"
|
||||
wordCount = "wordCount"
|
||||
wordLengthTransformer = UDFTransformer(
|
||||
inputCol="text", outputCol=wordLength, udf=wordLengthUDF
|
||||
)
|
||||
wordCountTransformer = UDFTransformer(
|
||||
inputCol="text", outputCol=wordCount, udf=wordCountUDF
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml import Pipeline
|
||||
|
||||
data = (
|
||||
Pipeline(stages=[wordLengthTransformer, wordCountTransformer])
|
||||
.fit(rawData)
|
||||
.transform(rawData)
|
||||
.withColumn("label", rawData["rating"] > 3)
|
||||
.drop("rating")
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
data.show(5)
|
||||
```
|
||||
|
||||
### 4a. Classify using pyspark
|
||||
|
||||
To choose the best LogisticRegression classifier using the `pyspark`
|
||||
library, need to *explicitly* perform the following steps:
|
||||
|
||||
1. Process the features:
|
||||
* Tokenize the text column
|
||||
* Hash the tokenized column into a vector using hashing
|
||||
* Merge the numeric features with the vector in the step above
|
||||
2. Process the label column: cast it into the proper type.
|
||||
3. Train multiple LogisticRegression algorithms on the `train` dataset
|
||||
with different hyperparameters
|
||||
4. Compute the area under the ROC curve for each of the trained models
|
||||
and select the model with the highest metric as computed on the
|
||||
`test` dataset
|
||||
5. Evaluate the best model on the `validation` set
|
||||
|
||||
As you can see below, there is a lot of work involved and a lot of
|
||||
steps where something can go wrong!
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml.feature import Tokenizer, HashingTF
|
||||
from pyspark.ml.feature import VectorAssembler
|
||||
|
||||
# Featurize text column
|
||||
tokenizer = Tokenizer(inputCol="text", outputCol="tokenizedText")
|
||||
numFeatures = 10000
|
||||
hashingScheme = HashingTF(
|
||||
inputCol="tokenizedText", outputCol="TextFeatures", numFeatures=numFeatures
|
||||
)
|
||||
tokenizedData = tokenizer.transform(data)
|
||||
featurizedData = hashingScheme.transform(tokenizedData)
|
||||
|
||||
# Merge text and numeric features in one feature column
|
||||
featureColumnsArray = ["TextFeatures", "wordCount", "wordLength"]
|
||||
assembler = VectorAssembler(inputCols=featureColumnsArray, outputCol="features")
|
||||
assembledData = assembler.transform(featurizedData)
|
||||
|
||||
# Select only columns of interest
|
||||
# Convert rating column from boolean to int
|
||||
processedData = assembledData.select("label", "features").withColumn(
|
||||
"label", assembledData.label.cast(IntegerType())
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml.evaluation import BinaryClassificationEvaluator
|
||||
from pyspark.ml.classification import LogisticRegression
|
||||
|
||||
# Prepare data for learning
|
||||
train, test, validation = processedData.randomSplit([0.60, 0.20, 0.20], seed=123)
|
||||
|
||||
# Train the models on the 'train' data
|
||||
lrHyperParams = [0.05, 0.1, 0.2, 0.4]
|
||||
logisticRegressions = [
|
||||
LogisticRegression(regParam=hyperParam) for hyperParam in lrHyperParams
|
||||
]
|
||||
evaluator = BinaryClassificationEvaluator(
|
||||
rawPredictionCol="rawPrediction", metricName="areaUnderROC"
|
||||
)
|
||||
metrics = []
|
||||
models = []
|
||||
|
||||
# Select the best model
|
||||
for learner in logisticRegressions:
|
||||
model = learner.fit(train)
|
||||
models.append(model)
|
||||
scoredData = model.transform(test)
|
||||
metrics.append(evaluator.evaluate(scoredData))
|
||||
bestMetric = max(metrics)
|
||||
bestModel = models[metrics.index(bestMetric)]
|
||||
|
||||
# Get AUC on the validation dataset
|
||||
scoredVal = bestModel.transform(validation)
|
||||
print(evaluator.evaluate(scoredVal))
|
||||
```
|
||||
|
||||
### 4b. Classify using synapseml
|
||||
|
||||
Life is a lot simpler when using `synapseml`!
|
||||
|
||||
1. The **`TrainClassifier`** Estimator featurizes the data internally,
|
||||
as long as the columns selected in the `train`, `test`, `validation`
|
||||
dataset represent the features
|
||||
|
||||
2. The **`FindBestModel`** Estimator finds the best model from a pool of
|
||||
trained models by finding the model which performs best on the `test`
|
||||
dataset given the specified metric
|
||||
|
||||
3. The **`ComputeModelStatistics`** Transformer computes the different
|
||||
metrics on a scored dataset (in our case, the `validation` dataset)
|
||||
at the same time
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import TrainClassifier, ComputeModelStatistics
|
||||
from synapse.ml.automl import FindBestModel
|
||||
|
||||
# Prepare data for learning
|
||||
train, test, validation = data.randomSplit([0.60, 0.20, 0.20], seed=123)
|
||||
|
||||
# Train the models on the 'train' data
|
||||
lrHyperParams = [0.05, 0.1, 0.2, 0.4]
|
||||
logisticRegressions = [
|
||||
LogisticRegression(regParam=hyperParam) for hyperParam in lrHyperParams
|
||||
]
|
||||
lrmodels = [
|
||||
TrainClassifier(model=lrm, labelCol="label", numFeatures=10000).fit(train)
|
||||
for lrm in logisticRegressions
|
||||
]
|
||||
|
||||
# Select the best model
|
||||
bestModel = FindBestModel(evaluationMetric="AUC", models=lrmodels).fit(test)
|
||||
|
||||
|
||||
# Get AUC on the validation dataset
|
||||
predictions = bestModel.transform(validation)
|
||||
metrics = ComputeModelStatistics().transform(predictions)
|
||||
print(
|
||||
"Best model's AUC on validation set = "
|
||||
+ "{0:.2f}%".format(metrics.first()["AUC"] * 100)
|
||||
)
|
||||
```
|
||||
|
|
@ -0,0 +1,71 @@
|
|||
---
|
||||
title: Classification - Sentiment Analysis Quickstart
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# A 5-minute tour of SynapseML
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
# Step 1: Load our Dataset
|
||||
|
||||
|
||||
```python
|
||||
train, test = (
|
||||
spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/BookReviewsFromAmazon10K.parquet"
|
||||
)
|
||||
.limit(1000)
|
||||
.cache()
|
||||
.randomSplit([0.8, 0.2])
|
||||
)
|
||||
|
||||
display(train)
|
||||
```
|
||||
|
||||
# Step 2: Make our Model
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml import Pipeline
|
||||
from synapse.ml.featurize.text import TextFeaturizer
|
||||
from synapse.ml.lightgbm import LightGBMRegressor
|
||||
|
||||
model = Pipeline(
|
||||
stages=[
|
||||
TextFeaturizer(inputCol="text", outputCol="features"),
|
||||
LightGBMRegressor(featuresCol="features", labelCol="rating"),
|
||||
]
|
||||
).fit(train)
|
||||
```
|
||||
|
||||
# Step 3: Predict!
|
||||
|
||||
|
||||
```python
|
||||
display(model.transform(test))
|
||||
```
|
||||
|
||||
# Alternate route: Let the Cognitive Services handle it
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import TextSentiment
|
||||
from synapse.ml.core.platform import find_secret
|
||||
|
||||
model = TextSentiment(
|
||||
textCol="text",
|
||||
outputCol="sentiment",
|
||||
subscriptionKey=find_secret("cognitive-api-key"),
|
||||
).setLocation("eastus")
|
||||
|
||||
display(model.transform(test))
|
||||
```
|
||||
|
|
@ -0,0 +1,225 @@
|
|||
---
|
||||
title: Classification - Twitter Sentiment with Vowpal Wabbit
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Twitter Sentiment Classification using Vowpal Wabbit in SynapseML
|
||||
|
||||
In this example, we show how to build a sentiment classification model using Vowpal Wabbit (VW) in SynapseML. The data set we use to train and evaluate the model is [Sentiment140](http://help.sentiment140.com/for-students/?source=post_page---------------------------) twitter data. First, we import a few packages that we need.
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
import re
|
||||
import urllib.request
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
from zipfile import ZipFile
|
||||
from bs4 import BeautifulSoup
|
||||
from pyspark.sql.functions import udf, rand, when, col
|
||||
from pyspark.sql.types import StructType, StructField, DoubleType, StringType
|
||||
from pyspark.ml import Pipeline
|
||||
from pyspark.ml.feature import CountVectorizer, RegexTokenizer
|
||||
from synapse.ml.vw import VowpalWabbitClassifier
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
from pyspark.mllib.evaluation import BinaryClassificationMetrics
|
||||
import matplotlib.pyplot as plt
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# URL to download the sentiment140 dataset and data file names
|
||||
DATA_URL = "https://mmlspark.blob.core.windows.net/publicwasb/twittersentimenttrainingandtestdata.zip"
|
||||
TRAIN_FILENAME = "training.1600000.processed.noemoticon.csv"
|
||||
TEST_FILENAME = "testdata.manual.2009.06.14.csv"
|
||||
# Folder for storing the downloaded data
|
||||
DATA_FOLDER = "data"
|
||||
# Data column names
|
||||
COL_NAMES = ["label", "id", "date", "query_string", "user", "text"]
|
||||
# Text encoding type of the data
|
||||
ENCODING = "iso-8859-1"
|
||||
```
|
||||
|
||||
## Data Preparation
|
||||
|
||||
We use [Sentiment140](http://help.sentiment140.com/for-students/?source=post_page---------------------------) twitter data which originated from a Stanford research project to train and evaluate VW classification model on Spark. The same dataset has been used in a previous [Azure Machine Learning sample](https://github.com/Azure-Samples/MachineLearningSamples-TwitterSentimentPrediction) on twitter sentiment prediction. Before using the data to build the classification model, we first download and clean up the data.
|
||||
|
||||
|
||||
```python
|
||||
def download_data(url, data_folder=DATA_FOLDER, filename="downloaded_data.zip"):
|
||||
"""Download and extract data from url"""
|
||||
|
||||
data_dir = "./" + DATA_FOLDER
|
||||
if not os.path.exists(data_dir):
|
||||
os.makedirs(data_dir)
|
||||
downloaded_filepath = os.path.join(data_dir, filename)
|
||||
print("Downloading data...")
|
||||
urllib.request.urlretrieve(url, downloaded_filepath)
|
||||
print("Extracting data...")
|
||||
zipfile = ZipFile(downloaded_filepath)
|
||||
zipfile.extractall(data_dir)
|
||||
zipfile.close()
|
||||
print("Finished data downloading and extraction.")
|
||||
|
||||
|
||||
download_data(DATA_URL)
|
||||
```
|
||||
|
||||
Let's read the training data into a Spark DataFrame.
|
||||
|
||||
|
||||
```python
|
||||
df_train = pd.read_csv(
|
||||
os.path.join(".", DATA_FOLDER, TRAIN_FILENAME),
|
||||
header=None,
|
||||
names=COL_NAMES,
|
||||
encoding=ENCODING,
|
||||
)
|
||||
df_train = spark.createDataFrame(df_train, verifySchema=False)
|
||||
```
|
||||
|
||||
We can take a look at the training data and check how many samples it has. We should see that there are 1.6 million samples in the training data. There are 6 fields in the training data:
|
||||
* label: the sentiment of the tweet (0.0 = negative, 2.0 = neutral, 4.0 = positive)
|
||||
* id: the id of the tweet
|
||||
* date: the date of the tweet
|
||||
* query_string: The query used to extract the data. If there is no query, then this value is NO_QUERY.
|
||||
* user: the user that tweeted
|
||||
* text: the text of the tweet
|
||||
|
||||
|
||||
```python
|
||||
df_train.limit(10).toPandas()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
print("Number of training samples: ", df_train.count())
|
||||
```
|
||||
|
||||
Before training the model, we randomly permute the data to mix negative and positive samples. This is helpful for properly training online learning algorithms like VW. To speed up model training, we use a subset of the data to train the model. If training with the full training set, typically you will see better performance of the model on the test set.
|
||||
|
||||
|
||||
```python
|
||||
df_train = (
|
||||
df_train.orderBy(rand())
|
||||
.limit(100000)
|
||||
.withColumn("label", when(col("label") > 0, 1.0).otherwise(0.0))
|
||||
.select(["label", "text"])
|
||||
)
|
||||
```
|
||||
|
||||
## VW SynapseML Training
|
||||
|
||||
Now we are ready to define a pipeline which consists of feature engineering steps and the VW model.
|
||||
|
||||
|
||||
```python
|
||||
# Specify featurizers
|
||||
tokenizer = RegexTokenizer(inputCol="text", outputCol="words")
|
||||
|
||||
count_vectorizer = CountVectorizer(inputCol="words", outputCol="features")
|
||||
|
||||
# Define VW classification model
|
||||
args = "--loss_function=logistic --quiet --holdout_off"
|
||||
vw_model = VowpalWabbitClassifier(
|
||||
featuresCol="features", labelCol="label", passThroughArgs=args, numPasses=10
|
||||
)
|
||||
|
||||
# Create a pipeline
|
||||
vw_pipeline = Pipeline(stages=[tokenizer, count_vectorizer, vw_model])
|
||||
```
|
||||
|
||||
With the prepared training data, we can fit the model pipeline as follows.
|
||||
|
||||
|
||||
```python
|
||||
vw_trained = vw_pipeline.fit(df_train)
|
||||
```
|
||||
|
||||
## Model Performance Evaluation
|
||||
|
||||
After training the model, we evaluate the performance of the model using the test set which is manually labeled.
|
||||
|
||||
|
||||
```python
|
||||
df_test = pd.read_csv(
|
||||
os.path.join(".", DATA_FOLDER, TEST_FILENAME),
|
||||
header=None,
|
||||
names=COL_NAMES,
|
||||
encoding=ENCODING,
|
||||
)
|
||||
df_test = spark.createDataFrame(df_test, verifySchema=False)
|
||||
```
|
||||
|
||||
We only use positive and negative tweets in the test set to evaluate the model, since our model is a binary classification model trained with only positive and negative tweets.
|
||||
|
||||
|
||||
```python
|
||||
print("Number of test samples before filtering: ", df_test.count())
|
||||
df_test = (
|
||||
df_test.filter(col("label") != 2.0)
|
||||
.withColumn("label", when(col("label") > 0, 1.0).otherwise(0.0))
|
||||
.select(["label", "text"])
|
||||
)
|
||||
print("Number of test samples after filtering: ", df_test.count())
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Make predictions
|
||||
predictions = vw_trained.transform(df_test)
|
||||
predictions.limit(10).toPandas()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Compute model performance metrics
|
||||
metrics = ComputeModelStatistics(
|
||||
evaluationMetric="classification", labelCol="label", scoredLabelsCol="prediction"
|
||||
).transform(predictions)
|
||||
metrics.toPandas()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Utility class for plotting ROC curve (https://stackoverflow.com/questions/52847408/pyspark-extract-roc-curve)
|
||||
class CurveMetrics(BinaryClassificationMetrics):
|
||||
def __init__(self, *args):
|
||||
super(CurveMetrics, self).__init__(*args)
|
||||
|
||||
def get_curve(self, method):
|
||||
rdd = getattr(self._java_model, method)().toJavaRDD()
|
||||
points = []
|
||||
for row in rdd.collect():
|
||||
points += [(float(row._1()), float(row._2()))]
|
||||
return points
|
||||
|
||||
|
||||
preds = predictions.select("label", "probability").rdd.map(
|
||||
lambda row: (float(row["probability"][1]), float(row["label"]))
|
||||
)
|
||||
roc_points = CurveMetrics(preds).get_curve("roc")
|
||||
|
||||
# Plot ROC curve
|
||||
fig = plt.figure()
|
||||
x_val = [x[0] for x in roc_points]
|
||||
y_val = [x[1] for x in roc_points]
|
||||
plt.title("ROC curve on test set")
|
||||
plt.xlabel("False positive rate")
|
||||
plt.ylabel("True positive rate")
|
||||
plt.plot(x_val, y_val)
|
||||
# Use display() if you're on Azure Databricks or you can do plt.show()
|
||||
plt.show()
|
||||
```
|
||||
|
||||
You should see an ROC curve like the following after the above cell is executed.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/20047467/69376052-9b0a3380-0c77-11ea-9266-11aa44350cbe.png" width="400" height="320" />
|
||||
|
|
@ -0,0 +1,152 @@
|
|||
---
|
||||
title: CognitiveServices - Advanced Usage Async, Batching, and Multi-Key
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Cognitive Services Advanced Guide: Asynchrony, Batching, Multi-Key
|
||||
|
||||
## Step 1: Imports and Keys
|
||||
|
||||
|
||||
```
|
||||
import os
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import running_on_synapse, find_secret
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
if running_on_synapse():
|
||||
from notebookutils.visualization import display
|
||||
|
||||
service_key = find_secret("cognitive-api-key")
|
||||
service_loc = "eastus"
|
||||
```
|
||||
|
||||
## Step 2: Basic Usage
|
||||
|
||||
Image 1 | Image 2 | Image 3
|
||||
:-------------------------:|:-------------------------:|:----------------------:|
|
||||
!<img src="https://raw.githubusercontent.com/Azure-Samples/cognitive-services-sample-data-files/master/ComputerVision/Images/objects.jpg" width="300" /> | <img src="https://raw.githubusercontent.com/Azure-Samples/cognitive-services-sample-data-files/master/ComputerVision/Images/dog.jpg" width="300" /> | <img src="https://raw.githubusercontent.com/Azure-Samples/cognitive-services-sample-data-files/master/ComputerVision/Images/house.jpg" width="300" />
|
||||
|
||||
|
||||
```
|
||||
from synapse.ml.cognitive.vision import AnalyzeImage
|
||||
|
||||
# Create a dataframe with the image URLs
|
||||
base_url = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-sample-data-files/master/ComputerVision/Images/"
|
||||
image_df = spark.createDataFrame(
|
||||
[(base_url + "objects.jpg",), (base_url + "dog.jpg",), (base_url + "house.jpg",)],
|
||||
["image"],
|
||||
)
|
||||
|
||||
# Run the Computer Vision service. Analyze Image extracts infortmation from/about the images.
|
||||
analyzer = (
|
||||
AnalyzeImage()
|
||||
.setLocation(service_loc)
|
||||
.setSubscriptionKey(service_key)
|
||||
.setVisualFeatures(
|
||||
["Categories", "Color", "Description", "Faces", "Objects", "Tags"]
|
||||
)
|
||||
.setOutputCol("analysis_results")
|
||||
.setImageUrlCol("image")
|
||||
.setErrorCol("error")
|
||||
)
|
||||
|
||||
image_results = analyzer.transform(image_df).cache()
|
||||
```
|
||||
|
||||
#### First we'll look at the full response objects:
|
||||
|
||||
|
||||
```
|
||||
display(image_results)
|
||||
```
|
||||
|
||||
#### We can select out just what we need:
|
||||
|
||||
|
||||
```
|
||||
display(image_results.select("analysis_results.description.captions.text"))
|
||||
```
|
||||
|
||||
#### What's going on under the hood
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Cog%20Service%20NB/cog_service.svg" width="300" />
|
||||
|
||||
When we call the cognitive service transformer, we start cognitive service clients on each of your spark workers.
|
||||
These clients send requests to the cloud, and turn the JSON responses into Spark Struct Types so that you can access any field that the service returns.
|
||||
|
||||
## Step 3: Asynchronous Usage
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Cog%20Service%20NB/async_parallelism.svg" width="700"/>
|
||||
|
||||
Apache Spark ordinarily parallelizes a computation to all of it's worker threads. When working with services however this parallelism doesent fully maximize throughput because workers sit idle as requests are processed on the server. The `concurrency` parameter makes sure that each worker can stay busy as they wait for requests to complete.
|
||||
|
||||
|
||||
```
|
||||
display(analyzer.setConcurrency(3).transform(image_df))
|
||||
```
|
||||
|
||||
#### Faster without extra hardware:
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Cog%20Service%20NB/async_relative%20(2).png" width="500" />
|
||||
|
||||
## Step 4: Batching
|
||||
|
||||
|
||||
```
|
||||
from synapse.ml.cognitive.text import TextSentiment
|
||||
|
||||
# Create a dataframe
|
||||
text_df = spark.createDataFrame(
|
||||
[
|
||||
("I am so happy today, its sunny!",),
|
||||
("I am frustrated by this rush hour traffic",),
|
||||
("The cognitive services on spark is pretty lit",),
|
||||
],
|
||||
["text"],
|
||||
)
|
||||
|
||||
sentiment = (
|
||||
TextSentiment()
|
||||
.setTextCol("text")
|
||||
.setLocation(service_loc)
|
||||
.setSubscriptionKey(service_key)
|
||||
.setOutputCol("sentiment")
|
||||
.setErrorCol("error")
|
||||
.setBatchSize(10)
|
||||
)
|
||||
|
||||
# Show the results of your text query
|
||||
display(sentiment.transform(text_df).select("text", "sentiment.document.sentiment"))
|
||||
```
|
||||
|
||||
## Step 5: Multi-Key
|
||||
|
||||
|
||||
```
|
||||
from synapse.ml.cognitive.text import TextSentiment
|
||||
from pyspark.sql.functions import udf
|
||||
import random
|
||||
|
||||
service_key_2 = find_secret("cognitive-api-key-2")
|
||||
keys = [service_key, service_key_2]
|
||||
|
||||
|
||||
@udf
|
||||
def random_key():
|
||||
return keys[random.randint(0, len(keys) - 1)]
|
||||
|
||||
|
||||
image_df2 = image_df.withColumn("key", random_key())
|
||||
|
||||
results = analyzer.setSubscriptionKeyCol("key").transform(image_df2)
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
display(results.select("key", "analysis_results.description.captions.text"))
|
||||
```
|
||||
|
||||
## Learn More
|
||||
- [Explore other cogntive services](https://microsoft.github.io/SynapseML/docs/features/cognitive_services/CognitiveServices%20-%20Overview/)
|
||||
- [Read our paper "Large-Scale Intelligent Microservices"](https://arxiv.org/abs/2009.08044)
|
||||
|
|
@ -0,0 +1,67 @@
|
|||
---
|
||||
title: CognitiveServices - Analyze Text
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Cognitive Services - Analyze Text
|
||||
|
||||
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import running_on_synapse, find_secret
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
if running_on_synapse():
|
||||
from notebookutils.visualization import display
|
||||
|
||||
cognitive_key = find_secret("cognitive-api-key")
|
||||
cognitive_location = "eastus"
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
df = spark.createDataFrame(
|
||||
data=[
|
||||
["en", "Hello Seattle"],
|
||||
["en", "There once was a dog who lived in London and thought she was a human"],
|
||||
],
|
||||
schema=["language", "text"],
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
display(df)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
text_analyze = (
|
||||
TextAnalyze()
|
||||
.setLocation(cognitive_location)
|
||||
.setSubscriptionKey(cognitive_key)
|
||||
.setTextCol("text")
|
||||
.setOutputCol("textAnalysis")
|
||||
.setErrorCol("error")
|
||||
.setLanguageCol("language")
|
||||
.setEntityRecognitionParams(
|
||||
{"model-version": "latest"}
|
||||
) # Can pass parameters to each model individually
|
||||
.setIncludePii(False) # Users can manually exclude tasks to speed up analysis
|
||||
.setIncludeEntityLinking(False)
|
||||
.setIncludeSentimentAnalysis(False)
|
||||
)
|
||||
|
||||
df_results = text_analyze.transform(df)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
display(df_results)
|
||||
```
|
||||
|
|
@ -0,0 +1,161 @@
|
|||
---
|
||||
title: CognitiveServices - Celebrity Quote Analysis
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Celebrity Quote Analysis with The Cognitive Services on Spark
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/SparkSummit2/cog_services.png" width="800" />
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
from pyspark.ml import PipelineModel
|
||||
from pyspark.sql.functions import col, udf
|
||||
from pyspark.ml.feature import SQLTransformer
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import find_secret
|
||||
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
# put your service keys here
|
||||
cognitive_key = find_secret("cognitive-api-key")
|
||||
cognitive_location = "eastus"
|
||||
bing_search_key = find_secret("bing-search-key")
|
||||
```
|
||||
|
||||
### Extracting celebrity quote images using Bing Image Search on Spark
|
||||
|
||||
Here we define two Transformers to extract celebrity quote images.
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Cog%20Service%20NB/step%201.png" width="600" />
|
||||
|
||||
|
||||
```python
|
||||
imgsPerBatch = 10 # the number of images Bing will return for each query
|
||||
offsets = [
|
||||
(i * imgsPerBatch,) for i in range(100)
|
||||
] # A list of offsets, used to page into the search results
|
||||
bingParameters = spark.createDataFrame(offsets, ["offset"])
|
||||
|
||||
bingSearch = (
|
||||
BingImageSearch()
|
||||
.setSubscriptionKey(bing_search_key)
|
||||
.setOffsetCol("offset")
|
||||
.setQuery("celebrity quotes")
|
||||
.setCount(imgsPerBatch)
|
||||
.setOutputCol("images")
|
||||
)
|
||||
|
||||
# Transformer to that extracts and flattens the richly structured output of Bing Image Search into a simple URL column
|
||||
getUrls = BingImageSearch.getUrlTransformer("images", "url")
|
||||
```
|
||||
|
||||
### Recognizing Images of Celebrities
|
||||
This block identifies the name of the celebrities for each of the images returned by the Bing Image Search.
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Cog%20Service%20NB/step%202.png" width="600" />
|
||||
|
||||
|
||||
```python
|
||||
celebs = (
|
||||
RecognizeDomainSpecificContent()
|
||||
.setSubscriptionKey(cognitive_key)
|
||||
.setLocation(cognitive_location)
|
||||
.setModel("celebrities")
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("celebs")
|
||||
)
|
||||
|
||||
# Extract the first celebrity we see from the structured response
|
||||
firstCeleb = SQLTransformer(
|
||||
statement="SELECT *, celebs.result.celebrities[0].name as firstCeleb FROM __THIS__"
|
||||
)
|
||||
```
|
||||
|
||||
### Reading the quote from the image.
|
||||
This stage performs OCR on the images to recognize the quotes.
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Cog%20Service%20NB/step%203.png" width="600" />
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.stages import UDFTransformer
|
||||
|
||||
recognizeText = (
|
||||
RecognizeText()
|
||||
.setSubscriptionKey(cognitive_key)
|
||||
.setLocation(cognitive_location)
|
||||
.setImageUrlCol("url")
|
||||
.setMode("Printed")
|
||||
.setOutputCol("ocr")
|
||||
.setConcurrency(5)
|
||||
)
|
||||
|
||||
|
||||
def getTextFunction(ocrRow):
|
||||
if ocrRow is None:
|
||||
return None
|
||||
return "\n".join([line.text for line in ocrRow.recognitionResult.lines])
|
||||
|
||||
|
||||
# this transformer wil extract a simpler string from the structured output of recognize text
|
||||
getText = (
|
||||
UDFTransformer()
|
||||
.setUDF(udf(getTextFunction))
|
||||
.setInputCol("ocr")
|
||||
.setOutputCol("text")
|
||||
)
|
||||
```
|
||||
|
||||
### Understanding the Sentiment of the Quote
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Cog%20Service%20NB/step4.jpg" width="600" />
|
||||
|
||||
|
||||
```python
|
||||
sentimentTransformer = (
|
||||
TextSentiment()
|
||||
.setLocation(cognitive_location)
|
||||
.setSubscriptionKey(cognitive_key)
|
||||
.setTextCol("text")
|
||||
.setOutputCol("sentiment")
|
||||
)
|
||||
|
||||
# Extract the sentiment score from the API response body
|
||||
getSentiment = SQLTransformer(
|
||||
statement="SELECT *, sentiment.document.sentiment as sentimentLabel FROM __THIS__"
|
||||
)
|
||||
```
|
||||
|
||||
### Tying it all together
|
||||
|
||||
Now that we have built the stages of our pipeline it's time to chain them together into a single model that can be used to process batches of incoming data
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Cog%20Service%20NB/full_pipe_2.jpg" width="800" />
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.stages import SelectColumns
|
||||
|
||||
# Select the final coulmns
|
||||
cleanupColumns = SelectColumns().setCols(
|
||||
["url", "firstCeleb", "text", "sentimentLabel"]
|
||||
)
|
||||
|
||||
celebrityQuoteAnalysis = PipelineModel(
|
||||
stages=[
|
||||
bingSearch,
|
||||
getUrls,
|
||||
celebs,
|
||||
firstCeleb,
|
||||
recognizeText,
|
||||
getText,
|
||||
sentimentTransformer,
|
||||
getSentiment,
|
||||
cleanupColumns,
|
||||
]
|
||||
)
|
||||
|
||||
celebrityQuoteAnalysis.transform(bingParameters).show(5)
|
||||
```
|
||||
|
|
@ -0,0 +1,123 @@
|
|||
---
|
||||
title: CognitiveServices - Create Audiobooks
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Create audiobooks using neural Text to speech
|
||||
|
||||
## Step 1: Load libraries and add service information
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
if running_on_synapse():
|
||||
from notebookutils import mssparkutils
|
||||
from notebookutils.visualization import display
|
||||
|
||||
# Fill this in with your cognitive service information
|
||||
service_key = find_secret(
|
||||
"cognitive-api-key"
|
||||
) # Replace this line with a string like service_key = "dddjnbdkw9329"
|
||||
service_loc = "eastus"
|
||||
|
||||
storage_container = "audiobooks"
|
||||
storage_key = find_secret("madtest-storage-key")
|
||||
storage_account = "anomalydetectiontest"
|
||||
```
|
||||
|
||||
## Step 2: Attach the storage account to hold the audio files
|
||||
|
||||
|
||||
```python
|
||||
spark_key_setting = f"fs.azure.account.key.{storage_account}.blob.core.windows.net"
|
||||
spark.sparkContext._jsc.hadoopConfiguration().set(spark_key_setting, storage_key)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
from os.path import exists, join
|
||||
|
||||
mount_path = f"wasbs://{storage_container}@{storage_account}.blob.core.windows.net/"
|
||||
if running_on_synapse():
|
||||
mount_dir = join("/synfs", mssparkutils.env.getJobId(), storage_container)
|
||||
if not exists(mount_dir):
|
||||
mssparkutils.fs.mount(
|
||||
mount_path, f"/{storage_container}", {"accountKey": storage_key}
|
||||
)
|
||||
elif running_on_databricks():
|
||||
if not exists(f"/dbfs/mnt/{storage_container}"):
|
||||
dbutils.fs.mount(
|
||||
source=mount_path,
|
||||
mount_point=f"/mnt/{storage_container}",
|
||||
extra_configs={spark_key_setting: storage_key},
|
||||
)
|
||||
```
|
||||
|
||||
## Step 3: Read in text data
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import udf
|
||||
|
||||
|
||||
@udf
|
||||
def make_audio_filename(part):
|
||||
return f"wasbs://{storage_container}@{storage_account}.blob.core.windows.net/alice_in_wonderland/part_{part}.wav"
|
||||
|
||||
|
||||
df = (
|
||||
spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/alice_in_wonderland.parquet"
|
||||
)
|
||||
.repartition(10)
|
||||
.withColumn("filename", make_audio_filename("part"))
|
||||
)
|
||||
|
||||
display(df)
|
||||
```
|
||||
|
||||
## Step 4: Synthesize audio from text
|
||||
|
||||
<div>
|
||||
<img src="https://marhamilresearch4.blob.core.windows.net/gutenberg-public/Notebook/NeuralTTS_hero.jpeg" width="500" />
|
||||
</div>
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import TextToSpeech
|
||||
|
||||
tts = (
|
||||
TextToSpeech()
|
||||
.setSubscriptionKey(service_key)
|
||||
.setTextCol("text")
|
||||
.setLocation(service_loc)
|
||||
.setErrorCol("error")
|
||||
.setVoiceName("en-US-SteffanNeural")
|
||||
.setOutputFileCol("filename")
|
||||
)
|
||||
|
||||
audio = tts.transform(df).cache()
|
||||
display(audio)
|
||||
```
|
||||
|
||||
## Step 5: Listen to an audio file
|
||||
|
||||
|
||||
```python
|
||||
from IPython.display import Audio
|
||||
|
||||
|
||||
def get_audio_file(num):
|
||||
if running_on_databricks():
|
||||
return f"/dbfs/mnt/{storage_container}/alice_in_wonderland/part_{num}.wav"
|
||||
else:
|
||||
return join(mount_dir, f"alice_in_wonderland/part_{num}.wav")
|
||||
|
||||
|
||||
Audio(filename=get_audio_file(1))
|
||||
```
|
||||
|
|
@ -0,0 +1,374 @@
|
|||
---
|
||||
title: CognitiveServices - Create a Multilingual Search Engine from Forms
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Tutorial: Create a custom search engine and question-answering system
|
||||
|
||||
In this tutorial, learn how to index and query large data loaded from a Spark cluster. You'll set up a Jupyter Notebook that performs the following actions:
|
||||
|
||||
> + Load various forms (invoices) into a data frame in an Apache Spark session
|
||||
> + Analyze them to determine their features
|
||||
> + Assemble the resulting output into a tabular data structure
|
||||
> + Write the output to a search index hosted in Azure Cognitive Search
|
||||
> + Explore and query over the content you created
|
||||
|
||||
## 1 - Set up dependencies
|
||||
|
||||
We start by importing packages and connecting to the Azure resources used in this workflow.
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import running_on_synapse, find_secret
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
if running_on_synapse():
|
||||
from notebookutils.visualization import display
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
subprocess.check_call([sys.executable, "-m", "pip", "install", "openai"])
|
||||
|
||||
cognitive_key = find_secret("cognitive-api-key")
|
||||
cognitive_location = "eastus"
|
||||
|
||||
translator_key = find_secret("translator-key")
|
||||
translator_location = "eastus"
|
||||
|
||||
search_key = find_secret("azure-search-key")
|
||||
search_service = "mmlspark-azure-search"
|
||||
search_index = "form-demo-index-5"
|
||||
|
||||
openai_key = find_secret("openai-api-key")
|
||||
openai_service_name = "synapseml-openai"
|
||||
openai_deployment_name = "gpt-35-turbo"
|
||||
openai_url = f"https://{openai_service_name}.openai.azure.com/"
|
||||
```
|
||||
|
||||
## 2 - Load data into Spark
|
||||
|
||||
This code loads a few external files from an Azure storage account that's used for demo purposes. The files are various invoices, and they're read into a data frame.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import udf
|
||||
from pyspark.sql.types import StringType
|
||||
|
||||
|
||||
def blob_to_url(blob):
|
||||
[prefix, postfix] = blob.split("@")
|
||||
container = prefix.split("/")[-1]
|
||||
split_postfix = postfix.split("/")
|
||||
account = split_postfix[0]
|
||||
filepath = "/".join(split_postfix[1:])
|
||||
return "https://{}/{}/{}".format(account, container, filepath)
|
||||
|
||||
|
||||
df2 = (
|
||||
spark.read.format("binaryFile")
|
||||
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
|
||||
.select("path")
|
||||
.limit(10)
|
||||
.select(udf(blob_to_url, StringType())("path").alias("url"))
|
||||
.cache()
|
||||
)
|
||||
|
||||
display(df2)
|
||||
```
|
||||
|
||||
<img src="https://mmlsparkdemo.blob.core.windows.net/ignite2021/form_svgs/Invoice11205.svg" width="40%"/>
|
||||
|
||||
## 3 - Apply form recognition
|
||||
|
||||
This code loads the [AnalyzeInvoices transformer](https://microsoft.github.io/SynapseML/docs/documentation/transformers/transformers_cognitive/#analyzeinvoices) and passes a reference to the data frame containing the invoices. It calls the pre-built invoice model of Azure Forms Analyzer.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import AnalyzeInvoices
|
||||
|
||||
analyzed_df = (
|
||||
AnalyzeInvoices()
|
||||
.setSubscriptionKey(cognitive_key)
|
||||
.setLocation(cognitive_location)
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("invoices")
|
||||
.setErrorCol("errors")
|
||||
.setConcurrency(5)
|
||||
.transform(df2)
|
||||
.cache()
|
||||
)
|
||||
|
||||
display(analyzed_df)
|
||||
```
|
||||
|
||||
## 4 - Simplify form recognition output
|
||||
|
||||
This code uses the [FormOntologyLearner](https://mmlspark.blob.core.windows.net/docs/0.10.0/pyspark/synapse.ml.cognitive.html#module-synapse.ml.cognitive.FormOntologyTransformer), a transformer that analyzes the output of Form Recognizer transformers and infers a tabular data structure. The output of AnalyzeInvoices is dynamic and varies based on the features detected in your content.
|
||||
|
||||
FormOntologyLearner extends the utility of the AnalyzeInvoices transformer by looking for patterns that can be used to create a tabular data structure. Organizing the output into multiple columns and rows makes for simpler downstream analysis.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import FormOntologyLearner
|
||||
|
||||
organized_df = (
|
||||
FormOntologyLearner()
|
||||
.setInputCol("invoices")
|
||||
.setOutputCol("extracted")
|
||||
.fit(analyzed_df)
|
||||
.transform(analyzed_df)
|
||||
.select("url", "extracted.*")
|
||||
.cache()
|
||||
)
|
||||
|
||||
display(organized_df)
|
||||
```
|
||||
|
||||
With our nice tabular dataframe, we can flatten the nested tables found in the forms with some SparkSQL
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import explode, col
|
||||
|
||||
itemized_df = (
|
||||
organized_df.select("*", explode(col("Items")).alias("Item"))
|
||||
.drop("Items")
|
||||
.select("Item.*", "*")
|
||||
.drop("Item")
|
||||
)
|
||||
|
||||
display(itemized_df)
|
||||
```
|
||||
|
||||
## 5 - Add translations
|
||||
|
||||
This code loads [Translate](https://microsoft.github.io/SynapseML/docs/documentation/transformers/transformers_cognitive/#translate), a transformer that calls the Azure Translator service in Cognitive Services. The original text, which is in English in the "Description" column, is machine-translated into various languages. All of the output is consolidated into "output.translations" array.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import Translate
|
||||
|
||||
translated_df = (
|
||||
Translate()
|
||||
.setSubscriptionKey(translator_key)
|
||||
.setLocation(translator_location)
|
||||
.setTextCol("Description")
|
||||
.setErrorCol("TranslationError")
|
||||
.setOutputCol("output")
|
||||
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
|
||||
.setConcurrency(5)
|
||||
.transform(itemized_df)
|
||||
.withColumn("Translations", col("output.translations")[0])
|
||||
.drop("output", "TranslationError")
|
||||
.cache()
|
||||
)
|
||||
|
||||
display(translated_df)
|
||||
```
|
||||
|
||||
## 6 - Translate products to emojis with OpenAI 🤯
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive.openai import OpenAIPrompt
|
||||
from pyspark.sql.functions import trim, split
|
||||
|
||||
emoji_template = """
|
||||
Your job is to translate item names into emoji. Do not add anything but the emoji and end the translation with a comma
|
||||
|
||||
Two Ducks: 🦆🦆,
|
||||
Light Bulb: 💡,
|
||||
Three Peaches: 🍑🍑🍑,
|
||||
Two kitchen stoves: ♨️♨️,
|
||||
A red car: 🚗,
|
||||
A person and a cat: 🧍🐈,
|
||||
A {Description}: """
|
||||
|
||||
prompter = (
|
||||
OpenAIPrompt()
|
||||
.setSubscriptionKey(openai_key)
|
||||
.setDeploymentName(openai_deployment_name)
|
||||
.setUrl(openai_url)
|
||||
.setMaxTokens(5)
|
||||
.setPromptTemplate(emoji_template)
|
||||
.setErrorCol("error")
|
||||
.setOutputCol("Emoji")
|
||||
)
|
||||
|
||||
emoji_df = (
|
||||
prompter.transform(translated_df)
|
||||
.withColumn("Emoji", trim(split(col("Emoji"), ",").getItem(0)))
|
||||
.drop("error", "prompt")
|
||||
.cache()
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
display(emoji_df.select("Description", "Emoji"))
|
||||
```
|
||||
|
||||
## 7 - Infer vendor adress continent with OpenAI
|
||||
|
||||
|
||||
```python
|
||||
continent_template = """
|
||||
Which continent does the following address belong to?
|
||||
|
||||
Pick one value from Europe, Australia, North America, South America, Asia, Africa, Antarctica.
|
||||
|
||||
Dont respond with anything but one of the above. If you don't know the answer or cannot figure it out from the text, return None. End your answer with a comma.
|
||||
|
||||
Address: "6693 Ryan Rd, North Whales",
|
||||
Continent: Europe,
|
||||
Address: "6693 Ryan Rd",
|
||||
Continent: None,
|
||||
Address: "{VendorAddress}",
|
||||
Continent:"""
|
||||
|
||||
continent_df = (
|
||||
prompter.setOutputCol("Continent")
|
||||
.setPromptTemplate(continent_template)
|
||||
.transform(emoji_df)
|
||||
.withColumn("Continent", trim(split(col("Continent"), ",").getItem(0)))
|
||||
.drop("error", "prompt")
|
||||
.cache()
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
display(continent_df.select("VendorAddress", "Continent"))
|
||||
```
|
||||
|
||||
## 8 - Create an Azure Search Index for the Forms
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
from pyspark.sql.functions import monotonically_increasing_id, lit
|
||||
|
||||
(
|
||||
continent_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
|
||||
.withColumn("SearchAction", lit("upload"))
|
||||
.writeToAzureSearch(
|
||||
subscriptionKey=search_key,
|
||||
actionCol="SearchAction",
|
||||
serviceName=search_service,
|
||||
indexName=search_index,
|
||||
keyCol="DocID",
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
## 9 - Try out a search query
|
||||
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
search_url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2019-05-06".format(
|
||||
search_service, search_index
|
||||
)
|
||||
requests.post(
|
||||
search_url, json={"search": "door"}, headers={"api-key": search_key}
|
||||
).json()
|
||||
```
|
||||
|
||||
## 10 - Build a simple chatbot that can use Azure Search as a tool 🧠🔧
|
||||
#
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/notebooks/chatbot_flow_2.svg" width="40%" />
|
||||
|
||||
|
||||
```python
|
||||
import json
|
||||
import openai
|
||||
|
||||
openai.api_type = "azure"
|
||||
openai.api_base = openai_url
|
||||
openai.api_key = openai_key
|
||||
openai.api_version = "2023-03-15-preview"
|
||||
|
||||
chat_context_prompt = f"""
|
||||
You are a chatbot designed to answer questions with the help of a search engine that has the following information:
|
||||
|
||||
{continent_df.columns}
|
||||
|
||||
If you dont know the answer to a question say "I dont know". Do not lie or hallucinate information. Be brief. If you need to use the search engine to solve the please output a json in the form of {{"query": "example_query"}}
|
||||
"""
|
||||
|
||||
|
||||
def search_query_prompt(question):
|
||||
return f"""
|
||||
Given the search engine above, what would you search for to answer the following question?
|
||||
|
||||
Question: "{question}"
|
||||
|
||||
Please output a json in the form of {{"query": "example_query"}}
|
||||
"""
|
||||
|
||||
|
||||
def search_result_prompt(query):
|
||||
search_results = requests.post(
|
||||
search_url, json={"search": query}, headers={"api-key": search_key}
|
||||
).json()
|
||||
return f"""
|
||||
|
||||
You previously ran a search for "{query}" which returned the following results:
|
||||
|
||||
{search_results}
|
||||
|
||||
You should use the results to help you answer questions. If you dont know the answer to a question say "I dont know". Do not lie or hallucinate information. Be Brief and mention which query you used to solve the problem.
|
||||
"""
|
||||
|
||||
|
||||
def prompt_gpt(messages):
|
||||
response = openai.ChatCompletion.create(
|
||||
engine=openai_deployment_name, messages=messages, max_tokens=None, top_p=0.95
|
||||
)
|
||||
return response["choices"][0]["message"]["content"]
|
||||
|
||||
|
||||
def custom_chatbot(question):
|
||||
while True:
|
||||
try:
|
||||
query = json.loads(
|
||||
prompt_gpt(
|
||||
[
|
||||
{"role": "system", "content": chat_context_prompt},
|
||||
{"role": "user", "content": search_query_prompt(question)},
|
||||
]
|
||||
)
|
||||
)["query"]
|
||||
|
||||
return prompt_gpt(
|
||||
[
|
||||
{"role": "system", "content": chat_context_prompt},
|
||||
{"role": "system", "content": search_result_prompt(query)},
|
||||
{"role": "user", "content": question},
|
||||
]
|
||||
)
|
||||
except Exception as e:
|
||||
raise e
|
||||
```
|
||||
|
||||
## 11 - Asking our chatbot a question
|
||||
|
||||
|
||||
```python
|
||||
custom_chatbot("What did Luke Diaz buy?")
|
||||
```
|
||||
|
||||
## 12 - A quick double check
|
||||
|
||||
|
||||
```python
|
||||
display(
|
||||
continent_df.where(col("CustomerName") == "Luke Diaz")
|
||||
.select("Description")
|
||||
.distinct()
|
||||
)
|
||||
```
|
||||
|
|
@ -0,0 +1,107 @@
|
|||
---
|
||||
title: CognitiveServices - Custom Search for Art
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
<h1>Creating a searchable Art Database with The MET's open-access collection</h1>
|
||||
|
||||
In this example, we show how you can enrich data using Cognitive Skills and write to an Azure Search Index using SynapseML. We use a subset of The MET's open-access collection and enrich it by passing it through 'Describe Image' and a custom 'Image Similarity' skill. The results are then written to a searchable index.
|
||||
|
||||
|
||||
```python
|
||||
import os, sys, time, json, requests
|
||||
from pyspark.ml import Transformer, Estimator, Pipeline
|
||||
from pyspark.ml.feature import SQLTransformer
|
||||
from pyspark.sql.functions import lit, udf, col, split
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
cognitive_key = find_secret("cognitive-api-key")
|
||||
cognitive_loc = "eastus"
|
||||
azure_search_key = find_secret("azure-search-key")
|
||||
search_service = "mmlspark-azure-search"
|
||||
search_index = "test"
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
data = (
|
||||
spark.read.format("csv")
|
||||
.option("header", True)
|
||||
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/metartworks_sample.csv")
|
||||
.withColumn("searchAction", lit("upload"))
|
||||
.withColumn("Neighbors", split(col("Neighbors"), ",").cast("array<string>"))
|
||||
.withColumn("Tags", split(col("Tags"), ",").cast("array<string>"))
|
||||
.limit(25)
|
||||
)
|
||||
```
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/CognitiveSearchHyperscale/MetArtworkSamples.png" width="800" />
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import AnalyzeImage
|
||||
from synapse.ml.stages import SelectColumns
|
||||
|
||||
# define pipeline
|
||||
describeImage = (
|
||||
AnalyzeImage()
|
||||
.setSubscriptionKey(cognitive_key)
|
||||
.setLocation(cognitive_loc)
|
||||
.setImageUrlCol("PrimaryImageUrl")
|
||||
.setOutputCol("RawImageDescription")
|
||||
.setErrorCol("Errors")
|
||||
.setVisualFeatures(
|
||||
["Categories", "Description", "Faces", "ImageType", "Color", "Adult"]
|
||||
)
|
||||
.setConcurrency(5)
|
||||
)
|
||||
|
||||
df2 = (
|
||||
describeImage.transform(data)
|
||||
.select("*", "RawImageDescription.*")
|
||||
.drop("Errors", "RawImageDescription")
|
||||
)
|
||||
```
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/CognitiveSearchHyperscale/MetArtworksProcessed.png" width="800" />
|
||||
|
||||
Before writing the results to a Search Index, you must define a schema which must specify the name, type, and attributes of each field in your index. Refer [Create a basic index in Azure Search](https://docs.microsoft.com/en-us/azure/search/search-what-is-an-index) for more information.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
df2.writeToAzureSearch(
|
||||
subscriptionKey=azure_search_key,
|
||||
actionCol="searchAction",
|
||||
serviceName=search_service,
|
||||
indexName=search_index,
|
||||
keyCol="ObjectID",
|
||||
)
|
||||
```
|
||||
|
||||
The Search Index can be queried using the [Azure Search REST API](https://docs.microsoft.com/rest/api/searchservice/) by sending GET or POST requests and specifying query parameters that give the criteria for selecting matching documents. For more information on querying refer [Query your Azure Search index using the REST API](https://docs.microsoft.com/en-us/rest/api/searchservice/Search-Documents)
|
||||
|
||||
|
||||
```python
|
||||
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2019-05-06".format(
|
||||
search_service, search_index
|
||||
)
|
||||
requests.post(
|
||||
url, json={"search": "Glass"}, headers={"api-key": azure_search_key}
|
||||
).json()
|
||||
```
|
||||
|
|
@ -0,0 +1,235 @@
|
|||
---
|
||||
title: CognitiveServices - LangchainTransformer
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Using the LangChain Transformer
|
||||
|
||||
LangChain is a software development framework designed to simplify the creation of applications using large language models (LLMs). Chains in LangChain go beyond just a single LLM call and are sequences of calls (can be a call to an LLM or a different utility), automating the execution of a series of calls and actions.
|
||||
To make it easier to scale up the LangChain execution on a large dataset, we have integrated LangChain with the distributed machine learning library [SynapseML](https://www.microsoft.com/en-us/research/blog/synapseml-a-simple-multilingual-and-massively-parallel-machine-learning-library/). This integration makes it easy to use the [Apache Spark](https://spark.apache.org/) distributed computing framework to process millions of data with the LangChain Framework.
|
||||
|
||||
This tutorial shows how to apply LangChain at scale for paper summarization and organization. We start with a table of arxiv links and apply the LangChain Transformerto automatically extract the corresponding paper title, authors, summary, and some related works.
|
||||
|
||||
## Step 1: Prerequisites
|
||||
|
||||
The key prerequisites for this quickstart include a working Azure OpenAI resource, and an Apache Spark cluster with SynapseML installed. We suggest creating a Synapse workspace, but an Azure Databricks, HDInsight, or Spark on Kubernetes, or even a python environment with the `pyspark` package will work. If you need to use the last component of the chain - An agent with web searching capabilities, you also need a SerpAPIKey.
|
||||
|
||||
1. An Azure OpenAI resource – request access [here](https://customervoice.microsoft.com/Pages/ResponsePage.aspx?id=v4j5cvGGr0GRqy180BHbR7en2Ais5pxKtso_Pz4b1_xUOFA5Qk1UWDRBMjg0WFhPMkIzTzhKQ1dWNyQlQCN0PWcu) before [creating a resource](https://docs.microsoft.com/en-us/azure/cognitive-services/openai/how-to/create-resource?pivots=web-portal#create-a-resource)
|
||||
1. [Create a Synapse workspace](https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started-create-workspace)
|
||||
1. [Create a serverless Apache Spark pool](https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started-analyze-spark#create-a-serverless-apache-spark-pool)
|
||||
1. Get a SerpAPIKey from [SerpApi](https://serpapi.com/).
|
||||
|
||||
## Step 2: Import this guide as a notebook
|
||||
|
||||
The next step is to add this code into your Spark cluster. You can either create a notebook in your Spark platform and copy the code into this notebook to run the demo. Or download the notebook and import it into Synapse Analytics
|
||||
|
||||
1. Import the notebook [into the Synapse Workspace](https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-development-using-notebooks#create-a-notebook) or if using Databricks [into the Databricks Workspace](https://docs.microsoft.com/en-us/azure/databricks/notebooks/notebooks-manage#create-a-notebook)
|
||||
1. Install SynapseML on your cluster. Please see the installation instructions for Synapse at the bottom of [the SynapseML website](https://microsoft.github.io/SynapseML/). Note that this requires pasting an additional cell at the top of the notebook you just imported
|
||||
1. Connect your notebook to a cluster and follow along, editing and running the cells below.
|
||||
|
||||
|
||||
```
|
||||
# This cell ensures make magic command like '%pip install' works on synapse scheduled spark jobs
|
||||
from synapse.ml.core.platform import running_on_synapse
|
||||
|
||||
if running_on_synapse():
|
||||
from IPython import get_ipython
|
||||
from IPython.terminal.interactiveshell import TerminalInteractiveShell
|
||||
|
||||
try:
|
||||
shell = TerminalInteractiveShell.instance()
|
||||
except:
|
||||
pass
|
||||
from notebookutils.visualization import display
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
%pip install langchain openai pdf2image pdfminer.six pytesseract unstructured
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
import os, openai, langchain, uuid
|
||||
from langchain.llms import AzureOpenAI, OpenAI
|
||||
from langchain.agents import load_tools, initialize_agent, AgentType
|
||||
from langchain.chat_models import AzureChatOpenAI
|
||||
from langchain.chains import TransformChain, LLMChain, SimpleSequentialChain
|
||||
from langchain.document_loaders import OnlinePDFLoader
|
||||
from langchain.prompts import PromptTemplate
|
||||
import pyspark.sql.functions as f
|
||||
from synapse.ml.cognitive.langchain import LangchainTransformer
|
||||
from synapse.ml.core.platform import running_on_synapse, find_secret
|
||||
```
|
||||
|
||||
## Step 3: Fill in the service information and construct the LLM
|
||||
Next, please edit the cell in the notebook to point to your service. In particular set the `model_name`, `deployment_name`, `openai_api_base`, and `open_api_key` variables to match those for your OpenAI service. Please feel free to replace `find_secret` with your key as follows
|
||||
|
||||
`openai_api_key = "99sj2w82o...."`
|
||||
|
||||
Note: If using SerpAPI you'll need to first [create a key](https://serpapi.com/dashboard)
|
||||
|
||||
|
||||
```
|
||||
os.environ["SERPAPI_API_KEY"] = "YOURSERPAPIKEY"
|
||||
openai_api_key = find_secret("openai-api-key")
|
||||
openai_api_base = "https://synapseml-openai.openai.azure.com/"
|
||||
openai_api_version = "2022-12-01"
|
||||
openai_api_type = "azure"
|
||||
|
||||
os.environ["OPENAI_API_TYPE"] = openai_api_type
|
||||
os.environ["OPENAI_API_VERSION"] = openai_api_version
|
||||
os.environ["OPENAI_API_BASE"] = openai_api_base
|
||||
os.environ["OPENAI_API_KEY"] = openai_api_key
|
||||
llm = AzureOpenAI(
|
||||
deployment_name="text-davinci-003",
|
||||
model_name="text-davinci-003",
|
||||
temperature=0.1,
|
||||
verbose=True,
|
||||
)
|
||||
```
|
||||
|
||||
## Step 4: Basic Usage of LangChain Transformer
|
||||
|
||||
### Create a chain
|
||||
We will start by demonstrating the basic usage with a simple chain that creates definitions for input words
|
||||
|
||||
|
||||
```
|
||||
copy_prompt = PromptTemplate(
|
||||
input_variables=["technology"],
|
||||
template="Define the following word: {technology}",
|
||||
)
|
||||
|
||||
chain = LLMChain(llm=llm, prompt=copy_prompt)
|
||||
transformer = (
|
||||
LangchainTransformer()
|
||||
.setInputCol("technology")
|
||||
.setOutputCol("definition")
|
||||
.setChain(chain)
|
||||
.setSubscriptionKey(openai_api_key)
|
||||
.setUrl(openai_api_base)
|
||||
)
|
||||
```
|
||||
|
||||
### Create a dataset and apply the chain
|
||||
|
||||
|
||||
```
|
||||
# construction of test dataframe
|
||||
df = spark.createDataFrame(
|
||||
[(0, "docker"), (1, "spark"), (2, "python")], ["label", "technology"]
|
||||
)
|
||||
display(transformer.transform(df))
|
||||
```
|
||||
|
||||
### Save and load the LangChain transformer
|
||||
LangChain Transformers can be saved and loaded. Note that LangChain serialization only works for chains that don't have memory.
|
||||
|
||||
|
||||
```
|
||||
temp_dir = "tmp"
|
||||
if not os.path.exists(temp_dir):
|
||||
os.mkdir(temp_dir)
|
||||
path = os.path.join(temp_dir, "langchainTransformer")
|
||||
transformer.save(path)
|
||||
loaded = LangchainTransformer.load(path)
|
||||
display(loaded.transform(df))
|
||||
```
|
||||
|
||||
## Step 5: Using LangChain for Large scale literature review
|
||||
|
||||
### Create a Sequential Chain for paper summarization
|
||||
|
||||
We will now construct a Sequential Chain for extracting structured information from an arxiv link. In particular, we will ask langchain to extract the title, author information, and a summary of the paper content. After that, we use a web search tool to find the recent papers written by the first author.
|
||||
|
||||
To summarize, our sequential chain contains the following steps:
|
||||
|
||||
1. **Transform Chain**: Extract Paper Content from arxiv Link **=>**
|
||||
1. **LLMChain**: Summarize the Paper, extract paper title and authors **=>**
|
||||
1. **Transform Chain**: to generate the prompt **=>**
|
||||
1. **Agent with Web Search Tool**: Use Web Search to find the recent papers by the first author (this part is commented out as it needs the SerpAPIKey to run successfully)
|
||||
|
||||
|
||||
```
|
||||
def paper_content_extraction(inputs: dict) -> dict:
|
||||
arxiv_link = inputs["arxiv_link"]
|
||||
loader = OnlinePDFLoader(arxiv_link)
|
||||
pages = loader.load_and_split()
|
||||
return {"paper_content": pages[0].page_content + pages[1].page_content}
|
||||
|
||||
|
||||
def prompt_generation(inputs: dict) -> dict:
|
||||
output = inputs["Output"]
|
||||
prompt = (
|
||||
"find the paper title, author, summary in the paper description below, output them. After that, Use websearch to find out 3 recent papers of the first author in the author section below (first author is the first name separated by comma) and list the paper titles in bullet points: <Paper Description Start>\n"
|
||||
+ output
|
||||
+ "<Paper Description End>."
|
||||
)
|
||||
return {"prompt": prompt}
|
||||
|
||||
|
||||
paper_content_extraction_chain = TransformChain(
|
||||
input_variables=["arxiv_link"],
|
||||
output_variables=["paper_content"],
|
||||
transform=paper_content_extraction,
|
||||
verbose=False,
|
||||
)
|
||||
|
||||
paper_summarizer_template = """You are a paper summarizer, given the paper content, it is your job to summarize the paper into a short summary, and extract authors and paper title from the paper content.
|
||||
Here is the paper content:
|
||||
{paper_content}
|
||||
Output:
|
||||
paper title, authors and summary.
|
||||
"""
|
||||
prompt = PromptTemplate(
|
||||
input_variables=["paper_content"], template=paper_summarizer_template
|
||||
)
|
||||
summarize_chain = LLMChain(llm=llm, prompt=prompt, verbose=False)
|
||||
|
||||
sequential_chain = SimpleSequentialChain(
|
||||
chains=[paper_content_extraction_chain, summarize_chain]
|
||||
)
|
||||
|
||||
"""
|
||||
Uncomment the following when you have a SerpAPIKey to enable the final websearch component of the chain.
|
||||
"""
|
||||
# prompt_generation_chain = TransformChain(input_variables=["Output"], output_variables=["prompt"], transform=prompt_generation, verbose=False)
|
||||
# tools = load_tools(["serpapi"], llm=llm)
|
||||
# web_search_agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=False)
|
||||
# sequential_chain = SimpleSequentialChain(chains=[
|
||||
# paper_content_extraction_chain, summarize_chain, prompt_generation_chain, web_search_agent
|
||||
# ])
|
||||
```
|
||||
|
||||
### Apply the LangChain transformer to perform this workload at scale
|
||||
|
||||
We can now use our chain at scale using the `LangchainTransformer`
|
||||
|
||||
|
||||
```
|
||||
paper_df = spark.createDataFrame(
|
||||
[
|
||||
(0, "https://arxiv.org/pdf/2107.13586.pdf"),
|
||||
(1, "https://arxiv.org/pdf/2101.00190.pdf"),
|
||||
(2, "https://arxiv.org/pdf/2103.10385.pdf"),
|
||||
(3, "https://arxiv.org/pdf/2110.07602.pdf"),
|
||||
],
|
||||
["label", "arxiv_link"],
|
||||
)
|
||||
|
||||
# construct langchain transformer using the paper summarizer chain define above
|
||||
paper_info_extractor = (
|
||||
LangchainTransformer()
|
||||
.setInputCol("arxiv_link")
|
||||
.setOutputCol("paper_info")
|
||||
.setChain(sequential_chain)
|
||||
.setSubscriptionKey(openai_api_key)
|
||||
.setUrl(openai_api_base)
|
||||
)
|
||||
|
||||
|
||||
# extract paper information from arxiv links, the paper information needs to include:
|
||||
# paper title, paper authors, brief paper summary, and recent papers published by the first author
|
||||
display(paper_info_extractor.transform(paper_df))
|
||||
```
|
||||
|
|
@ -0,0 +1,644 @@
|
|||
---
|
||||
title: CognitiveServices - Multivariate Anomaly Detection
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Recipe: Cognitive Services - Multivariate Anomaly Detection
|
||||
This recipe shows how you can use SynapseML and Azure Cognitive Services on Apache Spark for multivariate anomaly detection. Multivariate anomaly detection allows for the detection of anomalies among many variables or time series, taking into account all the inter-correlations and dependencies between the different variables. In this scenario, we use SynapseML to train a model for multivariate anomaly detection using the Azure Cognitive Services, and we then use to the model to infer multivariate anomalies within a dataset containing synthetic measurements from three IoT sensors.
|
||||
|
||||
To learn more about the Anomaly Detector Cognitive Service please refer to [ this documentation page](https://docs.microsoft.com/en-us/azure/cognitive-services/anomaly-detector/).
|
||||
|
||||
### Prerequisites
|
||||
- An Azure subscription - [Create one for free](https://azure.microsoft.com/en-us/free/)
|
||||
|
||||
### Setup
|
||||
#### Create an Anomaly Detector resource
|
||||
Follow the instructions below to create an `Anomaly Detector` resource using the Azure portal or alternatively, you can also use the Azure CLI to create this resource.
|
||||
|
||||
- In the Azure Portal, click `Create` in your resource group, and then type `Anomaly Detector`. Click on the Anomaly Detector resource.
|
||||
- Give the resource a name, and ideally use the same region as the rest of your resource group. Use the default options for the rest, and then click `Review + Create` and then `Create`.
|
||||
- Once the Anomaly Detector resource is created, open it and click on the `Keys and Endpoints` panel on the left. Copy the key for the Anomaly Detector resource into the `ANOMALY_API_KEY` environment variable, or store it in the `anomalyKey` variable in the cell below.
|
||||
|
||||
#### Create a Storage Account resource
|
||||
In order to save intermediate data, you will need to create an Azure Blob Storage Account. Within that storage account, create a container for storing the intermediate data. Make note of the container name, and copy the connection string to that container. You will need this later to populate the `containerName` variable and the `BLOB_CONNECTION_STRING` environment variable.
|
||||
|
||||
#### Enter your service keys
|
||||
Let's start by setting up the environment variables for our service keys. The next cell sets the `ANOMALY_API_KEY` and the `BLOB_CONNECTION_STRING` environment variables based on the values stored in our Azure Key Vault. If you are running this in your own environment, make sure you set these environment variables before you proceed.
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import find_secret
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
|
||||
<div class="ansiout"></div>
|
||||
|
||||
|
||||
Now, lets read the `ANOMALY_API_KEY` and `BLOB_CONNECTION_STRING` environment variables and set the `containerName` and `location` variables.
|
||||
|
||||
|
||||
```python
|
||||
# An Anomaly Dectector subscription key
|
||||
anomalyKey = find_secret("anomaly-api-key")
|
||||
# Your storage account name
|
||||
storageName = "anomalydetectiontest"
|
||||
# A connection string to your blob storage account
|
||||
storageKey = find_secret("madtest-storage-key")
|
||||
# A place to save intermediate MVAD results
|
||||
intermediateSaveDir = (
|
||||
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
|
||||
)
|
||||
# The location of the anomaly detector resource that you created
|
||||
location = "westus2"
|
||||
```
|
||||
|
||||
|
||||
|
||||
<div class="ansiout"></div>
|
||||
|
||||
|
||||
First we will connect to our storage account so that anomaly detector can save intermediate results there:
|
||||
|
||||
|
||||
```python
|
||||
spark.sparkContext._jsc.hadoopConfiguration().set(
|
||||
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
|
||||
)
|
||||
```
|
||||
|
||||
Let's import all the necessary modules.
|
||||
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
import pyspark
|
||||
from pyspark.sql.functions import col
|
||||
from pyspark.sql.functions import lit
|
||||
from pyspark.sql.types import DoubleType
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
import synapse.ml
|
||||
from synapse.ml.cognitive import *
|
||||
```
|
||||
|
||||
|
||||
|
||||
<div class="ansiout"></div>
|
||||
|
||||
|
||||
Now, let's read our sample data into a Spark DataFrame.
|
||||
|
||||
|
||||
```python
|
||||
df = (
|
||||
spark.read.format("csv")
|
||||
.option("header", "true")
|
||||
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
|
||||
)
|
||||
|
||||
df = (
|
||||
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
|
||||
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
|
||||
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
|
||||
)
|
||||
|
||||
# Let's inspect the dataframe:
|
||||
df.show(5)
|
||||
```
|
||||
|
||||
We can now create an `estimator` object, which will be used to train our model. In the cell below, we specify the start and end times for the training data. We also specify the input columns to use, and the name of the column that contains the timestamps. Finally, we specify the number of data points to use in the anomaly detection sliding window, and we set the connection string to the Azure Blob Storage Account.
|
||||
|
||||
|
||||
```python
|
||||
trainingStartTime = "2020-06-01T12:00:00Z"
|
||||
trainingEndTime = "2020-07-02T17:55:00Z"
|
||||
timestampColumn = "timestamp"
|
||||
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
|
||||
|
||||
estimator = (
|
||||
SimpleFitMultivariateAnomaly()
|
||||
.setSubscriptionKey(anomalyKey)
|
||||
.setLocation(location)
|
||||
.setStartTime(trainingStartTime)
|
||||
.setEndTime(trainingEndTime)
|
||||
.setIntermediateSaveDir(intermediateSaveDir)
|
||||
.setTimestampCol(timestampColumn)
|
||||
.setInputCols(inputColumns)
|
||||
.setSlidingWindow(200)
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
|
||||
<div class="ansiout"></div>
|
||||
|
||||
|
||||
Now that we have created the `estimator`, let's fit it to the data:
|
||||
|
||||
|
||||
```python
|
||||
model = estimator.fit(df)
|
||||
```
|
||||
|
||||
|
||||
|
||||
<div class="ansiout"></div>
|
||||
|
||||
|
||||
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in. It will then show the results.
|
||||
|
||||
|
||||
```python
|
||||
inferenceStartTime = "2020-07-02T18:00:00Z"
|
||||
inferenceEndTime = "2020-07-06T05:15:00Z"
|
||||
|
||||
result = (
|
||||
model.setStartTime(inferenceStartTime)
|
||||
.setEndTime(inferenceEndTime)
|
||||
.setOutputCol("results")
|
||||
.setErrorCol("errors")
|
||||
.setInputCols(inputColumns)
|
||||
.setTimestampCol(timestampColumn)
|
||||
.transform(df)
|
||||
)
|
||||
|
||||
result.show(5)
|
||||
```
|
||||
|
||||
When we called `.show(5)` in the previous cell, it showed us the first five rows in the dataframe. The results were all `null` because they were not inside the inference window.
|
||||
|
||||
To show the results only for the inferred data, lets select the columns we need. We can then order the rows in the dataframe by ascending order, and filter the result to only show the rows that are in the range of the inference window. In our case `inferenceEndTime` is the same as the last row in the dataframe, so can ignore that.
|
||||
|
||||
Finally, to be able to better plot the results, lets convert the Spark dataframe to a Pandas dataframe.
|
||||
|
||||
This is what the next cell does:
|
||||
|
||||
|
||||
```python
|
||||
rdf = (
|
||||
result.select(
|
||||
"timestamp",
|
||||
*inputColumns,
|
||||
"results.interpretation",
|
||||
"isAnomaly",
|
||||
"results.severity"
|
||||
)
|
||||
.orderBy("timestamp", ascending=True)
|
||||
.filter(col("timestamp") >= lit(inferenceStartTime))
|
||||
.toPandas()
|
||||
)
|
||||
|
||||
rdf
|
||||
```
|
||||
|
||||
|
||||
|
||||
<div class="ansiout">/databricks/spark/python/pyspark/sql/pandas/conversion.py:92: UserWarning: toPandas attempted Arrow optimization because 'spark.sql.execution.arrow.pyspark.enabled' is set to true; however, failed by the reason below:
|
||||
Unable to convert the field contributors. If this column is not necessary, you may consider dropping it or converting to primitive type before the conversion.
|
||||
Direct cause: Unsupported type in conversion to Arrow: ArrayType(StructType(List(StructField(contributionScore,DoubleType,true),StructField(variable,StringType,true))),true)
|
||||
Attempting non-optimization as 'spark.sql.execution.arrow.pyspark.fallback.enabled' is set to true.
|
||||
warnings.warn(msg)
|
||||
Out[8]: </div>
|
||||
|
||||
|
||||
|
||||
<div>
|
||||
|
||||
<table border="1" class="dataframe">
|
||||
<thead>
|
||||
<tr >
|
||||
<th></th>
|
||||
<th>timestamp</th>
|
||||
<th>sensor_1</th>
|
||||
<th>sensor_2</th>
|
||||
<th>sensor_3</th>
|
||||
<th>contributors</th>
|
||||
<th>isAnomaly</th>
|
||||
<th>severity</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>0</th>
|
||||
<td>2020-07-02T18:00:00Z</td>
|
||||
<td>1.069680</td>
|
||||
<td>0.393173</td>
|
||||
<td>3.129125</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>1</th>
|
||||
<td>2020-07-02T18:05:00Z</td>
|
||||
<td>0.932784</td>
|
||||
<td>0.214959</td>
|
||||
<td>3.077339</td>
|
||||
<td>[(0.5516611337661743, series_1), (0.3133429884...</td>
|
||||
<td>True</td>
|
||||
<td>0.06478</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>2</th>
|
||||
<td>2020-07-02T18:10:00Z</td>
|
||||
<td>1.012214</td>
|
||||
<td>0.466037</td>
|
||||
<td>2.909561</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>3</th>
|
||||
<td>2020-07-02T18:15:00Z</td>
|
||||
<td>1.122182</td>
|
||||
<td>0.398438</td>
|
||||
<td>3.029489</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>4</th>
|
||||
<td>2020-07-02T18:20:00Z</td>
|
||||
<td>1.091310</td>
|
||||
<td>0.282137</td>
|
||||
<td>2.948016</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>...</th>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>995</th>
|
||||
<td>2020-07-06T04:55:00Z</td>
|
||||
<td>-0.443438</td>
|
||||
<td>0.768980</td>
|
||||
<td>-0.710800</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>996</th>
|
||||
<td>2020-07-06T05:00:00Z</td>
|
||||
<td>-0.529400</td>
|
||||
<td>0.822140</td>
|
||||
<td>-0.944681</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>997</th>
|
||||
<td>2020-07-06T05:05:00Z</td>
|
||||
<td>-0.377911</td>
|
||||
<td>0.738591</td>
|
||||
<td>-0.871468</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>998</th>
|
||||
<td>2020-07-06T05:10:00Z</td>
|
||||
<td>-0.501993</td>
|
||||
<td>0.727775</td>
|
||||
<td>-0.786263</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>999</th>
|
||||
<td>2020-07-06T05:15:00Z</td>
|
||||
<td>-0.404138</td>
|
||||
<td>0.806980</td>
|
||||
<td>-0.883521</td>
|
||||
<td>None</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
<p>1000 rows × 7 columns</p>
|
||||
</div>
|
||||
|
||||
|
||||
Let's now format the `interpretation` column that stores the contribution score from each sensor to the detected anomalies. The next cell formats this data, and splits the contribution score of each sensor into its own column.
|
||||
|
||||
|
||||
```python
|
||||
def parse(x):
|
||||
if len(x) > 0:
|
||||
return dict([item[:2] for item in x])
|
||||
else:
|
||||
return {"sensor_1": 0, "sensor_2": 0, "sensor_3": 0}
|
||||
|
||||
|
||||
rdf["contributors"] = rdf["interpretation"].apply(parse)
|
||||
rdf = pd.concat(
|
||||
[
|
||||
rdf.drop(["contributors"], axis=1),
|
||||
pd.json_normalize(rdf["contributors"]).rename(
|
||||
columns={
|
||||
"sensor_1": "series_1",
|
||||
"sensor_2": "series_2",
|
||||
"sensor_3": "series_3",
|
||||
}
|
||||
),
|
||||
],
|
||||
axis=1,
|
||||
)
|
||||
rdf
|
||||
```
|
||||
|
||||
|
||||
|
||||
<div class="ansiout">Out[9]: </div>
|
||||
|
||||
|
||||
|
||||
<div>
|
||||
|
||||
<table border="1" class="dataframe">
|
||||
<thead>
|
||||
<tr >
|
||||
<th></th>
|
||||
<th>timestamp</th>
|
||||
<th>sensor_1</th>
|
||||
<th>sensor_2</th>
|
||||
<th>sensor_3</th>
|
||||
<th>isAnomaly</th>
|
||||
<th>severity</th>
|
||||
<th>series_0</th>
|
||||
<th>series_1</th>
|
||||
<th>series_2</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>0</th>
|
||||
<td>2020-07-02T18:00:00Z</td>
|
||||
<td>1.069680</td>
|
||||
<td>0.393173</td>
|
||||
<td>3.129125</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>1</th>
|
||||
<td>2020-07-02T18:05:00Z</td>
|
||||
<td>0.932784</td>
|
||||
<td>0.214959</td>
|
||||
<td>3.077339</td>
|
||||
<td>True</td>
|
||||
<td>0.06478</td>
|
||||
<td>0.313343</td>
|
||||
<td>0.551661</td>
|
||||
<td>0.134996</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>2</th>
|
||||
<td>2020-07-02T18:10:00Z</td>
|
||||
<td>1.012214</td>
|
||||
<td>0.466037</td>
|
||||
<td>2.909561</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>3</th>
|
||||
<td>2020-07-02T18:15:00Z</td>
|
||||
<td>1.122182</td>
|
||||
<td>0.398438</td>
|
||||
<td>3.029489</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>4</th>
|
||||
<td>2020-07-02T18:20:00Z</td>
|
||||
<td>1.091310</td>
|
||||
<td>0.282137</td>
|
||||
<td>2.948016</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>...</th>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
<td>...</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>995</th>
|
||||
<td>2020-07-06T04:55:00Z</td>
|
||||
<td>-0.443438</td>
|
||||
<td>0.768980</td>
|
||||
<td>-0.710800</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>996</th>
|
||||
<td>2020-07-06T05:00:00Z</td>
|
||||
<td>-0.529400</td>
|
||||
<td>0.822140</td>
|
||||
<td>-0.944681</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>997</th>
|
||||
<td>2020-07-06T05:05:00Z</td>
|
||||
<td>-0.377911</td>
|
||||
<td>0.738591</td>
|
||||
<td>-0.871468</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>998</th>
|
||||
<td>2020-07-06T05:10:00Z</td>
|
||||
<td>-0.501993</td>
|
||||
<td>0.727775</td>
|
||||
<td>-0.786263</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>999</th>
|
||||
<td>2020-07-06T05:15:00Z</td>
|
||||
<td>-0.404138</td>
|
||||
<td>0.806980</td>
|
||||
<td>-0.883521</td>
|
||||
<td>False</td>
|
||||
<td>0.00000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
<td>0.000000</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
<p>1000 rows × 9 columns</p>
|
||||
</div>
|
||||
|
||||
|
||||
Great! We now have the contribution scores of sensors 1, 2, and 3 in the `series_0`, `series_1`, and `series_2` columns respectively.
|
||||
|
||||
Let's run the next cell to plot the results. The `minSeverity` parameter in the first line specifies the minimum severity of the anomalies to be plotted.
|
||||
|
||||
|
||||
```python
|
||||
minSeverity = 0.1
|
||||
|
||||
|
||||
####### Main Figure #######
|
||||
plt.figure(figsize=(23, 8))
|
||||
plt.plot(
|
||||
rdf["timestamp"],
|
||||
rdf["sensor_1"],
|
||||
color="tab:orange",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="sensor_1",
|
||||
)
|
||||
plt.plot(
|
||||
rdf["timestamp"],
|
||||
rdf["sensor_2"],
|
||||
color="tab:green",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="sensor_2",
|
||||
)
|
||||
plt.plot(
|
||||
rdf["timestamp"],
|
||||
rdf["sensor_3"],
|
||||
color="tab:blue",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="sensor_3",
|
||||
)
|
||||
plt.grid(axis="y")
|
||||
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
|
||||
plt.legend()
|
||||
|
||||
anoms = list(rdf["severity"] >= minSeverity)
|
||||
_, _, ymin, ymax = plt.axis()
|
||||
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
|
||||
|
||||
plt.legend()
|
||||
plt.title(
|
||||
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
|
||||
)
|
||||
plt.show()
|
||||
|
||||
####### Severity Figure #######
|
||||
plt.figure(figsize=(23, 1))
|
||||
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
|
||||
plt.plot(
|
||||
rdf["timestamp"],
|
||||
rdf["severity"],
|
||||
color="black",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="Severity score",
|
||||
)
|
||||
plt.plot(
|
||||
rdf["timestamp"],
|
||||
[minSeverity] * len(rdf["severity"]),
|
||||
color="red",
|
||||
line,
|
||||
linewidth=1,
|
||||
label="minSeverity",
|
||||
)
|
||||
plt.grid(axis="y")
|
||||
plt.legend()
|
||||
plt.ylim([0, 1])
|
||||
plt.title("Severity of the detected anomalies")
|
||||
plt.show()
|
||||
|
||||
####### Contributors Figure #######
|
||||
plt.figure(figsize=(23, 1))
|
||||
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
|
||||
plt.bar(
|
||||
rdf["timestamp"], rdf["series_1"], width=2, color="tab:orange", label="sensor_1"
|
||||
)
|
||||
plt.bar(
|
||||
rdf["timestamp"],
|
||||
rdf["series_2"],
|
||||
width=2,
|
||||
color="tab:green",
|
||||
label="sensor_2",
|
||||
bottom=rdf["series_1"],
|
||||
)
|
||||
plt.bar(
|
||||
rdf["timestamp"],
|
||||
rdf["series_3"],
|
||||
width=2,
|
||||
color="tab:blue",
|
||||
label="sensor_3",
|
||||
bottom=rdf["series_1"] + rdf["series_2"],
|
||||
)
|
||||
plt.grid(axis="y")
|
||||
plt.legend()
|
||||
plt.ylim([0, 1])
|
||||
plt.title("The contribution of each sensor to the detected anomaly")
|
||||
plt.show()
|
||||
```
|
||||
|
||||
<img width="1300" src="https://mmlspark.blob.core.windows.net/graphics/mvad_plot.png"/>
|
||||
|
||||
The plots above show the raw data from the sensors (inside the inference window) in orange, green, and blue. The red vertical lines in the first figure show the detected anomalies that have a severity greater than or equal to `minSeverity`.
|
||||
|
||||
The second plot shows the severity score of all the detected anomalies, with the `minSeverity` threshold shown in the dotted red line.
|
||||
|
||||
Finally, the last plot shows the contribution of the data from each sensor to the detected anomalies. This helps us diagnose and understand the most likely cause of each anomaly.
|
||||
|
|
@ -0,0 +1,213 @@
|
|||
---
|
||||
title: CognitiveServices - OpenAI Embedding
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Embedding Text with Azure OpenAI
|
||||
|
||||
The Azure OpenAI service can be used to solve a large number of natural language tasks through prompting the completion API. To make it easier to scale your prompting workflows from a few examples to large datasets of examples we have integrated the Azure OpenAI service with the distributed machine learning library [SynapseML](https://www.microsoft.com/en-us/research/blog/synapseml-a-simple-multilingual-and-massively-parallel-machine-learning-library/). This integration makes it easy to use the [Apache Spark](https://spark.apache.org/) distributed computing framework to process millions of prompts with the OpenAI service. This tutorial shows how to apply large language models to generate embeddings for large datasets of text.
|
||||
|
||||
## Step 1: Prerequisites
|
||||
|
||||
The key prerequisites for this quickstart include a working Azure OpenAI resource, and an Apache Spark cluster with SynapseML installed. We suggest creating a Synapse workspace, but an Azure Databricks, HDInsight, or Spark on Kubernetes, or even a python environment with the `pyspark` package will work.
|
||||
|
||||
1. An Azure OpenAI resource – request access [here](https://customervoice.microsoft.com/Pages/ResponsePage.aspx?id=v4j5cvGGr0GRqy180BHbR7en2Ais5pxKtso_Pz4b1_xUOFA5Qk1UWDRBMjg0WFhPMkIzTzhKQ1dWNyQlQCN0PWcu) before [creating a resource](https://docs.microsoft.com/en-us/azure/cognitive-services/openai/how-to/create-resource?pivots=web-portal#create-a-resource)
|
||||
1. [Create a Synapse workspace](https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started-create-workspace)
|
||||
1. [Create a serverless Apache Spark pool](https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started-analyze-spark#create-a-serverless-apache-spark-pool)
|
||||
|
||||
|
||||
## Step 2: Import this guide as a notebook
|
||||
|
||||
The next step is to add this code into your Spark cluster. You can either create a notebook in your Spark platform and copy the code into this notebook to run the demo. Or download the notebook and import it into Synapse Analytics
|
||||
|
||||
1. [Download this demo as a notebook](https://github.com/microsoft/SynapseML/blob/master/notebooks/features/cognitive_services/CognitiveServices%20-%20OpenAI%20Embedding.ipynb) (click Raw, then save the file)
|
||||
1. Import the notebook [into the Synapse Workspace](https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-development-using-notebooks#create-a-notebook) or if using Databricks [into the Databricks Workspace](https://docs.microsoft.com/en-us/azure/databricks/notebooks/notebooks-manage#create-a-notebook)
|
||||
1. Install SynapseML on your cluster. Please see the installation instructions for Synapse at the bottom of [the SynapseML website](https://microsoft.github.io/SynapseML/). Note that this requires pasting an additional cell at the top of the notebook you just imported
|
||||
3. Connect your notebook to a cluster and follow along, editing and rnnung the cells below.
|
||||
|
||||
## Step 3: Fill in your service information
|
||||
|
||||
Next, please edit the cell in the notebook to point to your service. In particular set the `service_name`, `deployment_name`, `location`, and `key` variables to match those for your OpenAI service:
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import running_on_synapse, find_secret
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
if running_on_synapse():
|
||||
from notebookutils.visualization import display
|
||||
|
||||
# Fill in the following lines with your service information
|
||||
# Learn more about selecting which embedding model to choose: https://openai.com/blog/new-and-improved-embedding-model
|
||||
service_name = "synapseml-openai"
|
||||
deployment_name_embeddings = "text-embedding-ada-002"
|
||||
|
||||
key = find_secret("openai-api-key") # please replace this with your key as a string
|
||||
|
||||
assert key is not None and service_name is not None
|
||||
```
|
||||
|
||||
## Step 4: Load Data
|
||||
|
||||
In this demo we will explore a dataset of fine food reviews
|
||||
|
||||
|
||||
```python
|
||||
import pyspark.sql.functions as F
|
||||
|
||||
df = (
|
||||
spark.read.options(inferSchema="True", delimiter=",", header=True)
|
||||
.csv("wasbs://publicwasb@mmlspark.blob.core.windows.net/fine_food_reviews_1k.csv")
|
||||
.repartition(5)
|
||||
)
|
||||
|
||||
df = df.withColumn(
|
||||
"combined",
|
||||
F.format_string("Title: %s; Content: %s", F.trim(df.Summary), F.trim(df.Text)),
|
||||
)
|
||||
|
||||
display(df)
|
||||
```
|
||||
|
||||
## Step 5: Generate Embeddings
|
||||
|
||||
We will first generate embeddings for the reviews using the SynapseML OpenAIEmbedding client.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import OpenAIEmbedding
|
||||
|
||||
embedding = (
|
||||
OpenAIEmbedding()
|
||||
.setSubscriptionKey(key)
|
||||
.setDeploymentName(deployment_name_embeddings)
|
||||
.setCustomServiceName(service_name)
|
||||
.setTextCol("combined")
|
||||
.setErrorCol("error")
|
||||
.setOutputCol("embeddings")
|
||||
)
|
||||
|
||||
completed_df = embedding.transform(df).cache()
|
||||
display(completed_df)
|
||||
```
|
||||
|
||||
## Step 6: Reduce Embedding dimensionality for Visualization
|
||||
We reduce the dimensionality to 2 dimensions using t-SNE decomposition.
|
||||
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
from sklearn.manifold import TSNE
|
||||
import numpy as np
|
||||
|
||||
collected = list(completed_df.collect())
|
||||
matrix = np.array([[r["embeddings"]] for r in collected])[:, 0, :].astype(np.float64)
|
||||
scores = np.array([[r["Score"]] for r in collected]).reshape(-1)
|
||||
|
||||
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="pca")
|
||||
vis_dims = tsne.fit_transform(matrix)
|
||||
vis_dims.shape
|
||||
```
|
||||
|
||||
## Step 7: Plot the embeddings
|
||||
|
||||
We now use t-SNE to reduce the dimensionality of the embeddings from 1536 to 2. Once the embeddings are reduced to two dimensions, we can plot them in a 2D scatter plot. We colour each review by its star rating, ranging from red for negative reviews, to green for positive reviews. We can observe a decent data separation even in the reduced 2 dimensions.
|
||||
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
import matplotlib
|
||||
import numpy as np
|
||||
|
||||
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
|
||||
x = [x for x, y in vis_dims]
|
||||
y = [y for x, y in vis_dims]
|
||||
color_indices = scores - 1
|
||||
|
||||
colormap = matplotlib.colors.ListedColormap(colors)
|
||||
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
|
||||
for score in [0, 1, 2, 3, 4]:
|
||||
avg_x = np.array(x)[scores - 1 == score].mean()
|
||||
avg_y = np.array(y)[scores - 1 == score].mean()
|
||||
color = colors[score]
|
||||
plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)
|
||||
|
||||
plt.title("Amazon ratings visualized in language using t-SNE")
|
||||
```
|
||||
|
||||
## Step 8: Build a fast vector index to over review embeddings
|
||||
|
||||
We will use SynapseML's KNN estimator to build a fast cosine-similarity retrieval engine.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.nn import *
|
||||
|
||||
knn = (
|
||||
KNN()
|
||||
.setFeaturesCol("embeddings")
|
||||
.setValuesCol("id")
|
||||
.setOutputCol("output")
|
||||
.setK(10)
|
||||
)
|
||||
|
||||
knn_index = knn.fit(completed_df)
|
||||
```
|
||||
|
||||
## Step 8: Build the retrieval model pipeline
|
||||
|
||||
Note: The data types of the ID columns in the document and query dataframes should be the same. For some OpenAI models, users should use separate models for embedding documents and queries. These models are denoted by the "-doc" and "-query" suffixes respectively.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml import PipelineModel
|
||||
|
||||
embedding_query = (
|
||||
OpenAIEmbedding()
|
||||
.setSubscriptionKey(key)
|
||||
.setDeploymentName(deployment_name_embeddings)
|
||||
.setCustomServiceName(service_name)
|
||||
.setTextCol("query")
|
||||
.setErrorCol("error")
|
||||
.setOutputCol("embeddings")
|
||||
)
|
||||
|
||||
retrieval_model = PipelineModel(stages=[embedding_query, knn_index])
|
||||
```
|
||||
|
||||
## Step 9: Retrieve results
|
||||
|
||||
|
||||
```python
|
||||
query_df = (
|
||||
spark.createDataFrame(
|
||||
[
|
||||
(
|
||||
0,
|
||||
"desserts",
|
||||
),
|
||||
(
|
||||
1,
|
||||
"disgusting",
|
||||
),
|
||||
]
|
||||
)
|
||||
.toDF("id", "query")
|
||||
.withColumn("id", F.col("id").cast("int"))
|
||||
)
|
||||
|
||||
|
||||
df_matches = retrieval_model.transform(query_df).cache()
|
||||
|
||||
df_result = (
|
||||
df_matches.withColumn("match", F.explode("output"))
|
||||
.join(df, df["id"] == F.col("match.value"))
|
||||
.select("query", F.col("combined"), "match.distance")
|
||||
)
|
||||
|
||||
display(df_result)
|
||||
```
|
||||
|
|
@ -0,0 +1,291 @@
|
|||
---
|
||||
title: CognitiveServices - OpenAI
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Azure OpenAI for Big Data
|
||||
|
||||
The Azure OpenAI service can be used to solve a large number of natural language tasks through prompting the completion API. To make it easier to scale your prompting workflows from a few examples to large datasets of examples, we have integrated the Azure OpenAI service with the distributed machine learning library [SynapseML](https://www.microsoft.com/en-us/research/blog/synapseml-a-simple-multilingual-and-massively-parallel-machine-learning-library/). This integration makes it easy to use the [Apache Spark](https://spark.apache.org/) distributed computing framework to process millions of prompts with the OpenAI service. This tutorial shows how to apply large language models at a distributed scale using Azure Open AI and Azure Synapse Analytics.
|
||||
|
||||
## Step 1: Prerequisites
|
||||
|
||||
The key prerequisites for this quickstart include a working Azure OpenAI resource, and an Apache Spark cluster with SynapseML installed. We suggest creating a Synapse workspace, but an Azure Databricks, HDInsight, or Spark on Kubernetes, or even a python environment with the `pyspark` package will work.
|
||||
|
||||
1. An Azure OpenAI resource – request access [here](https://customervoice.microsoft.com/Pages/ResponsePage.aspx?id=v4j5cvGGr0GRqy180BHbR7en2Ais5pxKtso_Pz4b1_xUOFA5Qk1UWDRBMjg0WFhPMkIzTzhKQ1dWNyQlQCN0PWcu) before [creating a resource](https://docs.microsoft.com/en-us/azure/cognitive-services/openai/how-to/create-resource?pivots=web-portal#create-a-resource)
|
||||
1. [Create a Synapse workspace](https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started-create-workspace)
|
||||
1. [Create a serverless Apache Spark pool](https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started-analyze-spark#create-a-serverless-apache-spark-pool)
|
||||
|
||||
|
||||
## Step 2: Import this guide as a notebook
|
||||
|
||||
The next step is to add this code into your Spark cluster. You can either create a notebook in your Spark platform and copy the code into this notebook to run the demo. Or download the notebook and import it into Synapse Analytics
|
||||
|
||||
1. [Download this demo as a notebook](https://github.com/microsoft/SynapseML/blob/master/notebooks/features/cognitive_services/CognitiveServices%20-%20OpenAI.ipynb) (click Raw, then save the file)
|
||||
1. Import the notebook [into the Synapse Workspace](https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-development-using-notebooks#create-a-notebook) or if using Databricks [import into the Databricks Workspace](https://docs.microsoft.com/en-us/azure/databricks/notebooks/notebooks-manage#create-a-notebook). If using Fabric [import into the Fabric Workspace](https://learn.microsoft.com/en-us/fabric/data-engineering/how-to-use-notebook)
|
||||
1. Install SynapseML on your cluster. Please see the installation instructions for Synapse at the bottom of [the SynapseML website](https://microsoft.github.io/SynapseML/). If using Fabric, please check [Installation Guide](https://learn.microsoft.com/en-us/fabric/data-science/install-synapseml). This requires pasting an extra cell at the top of the notebook you imported.
|
||||
1. Connect your notebook to a cluster and follow along, editing and running the cells.
|
||||
|
||||
## Step 3: Fill in your service information
|
||||
|
||||
Next, edit the cell in the notebook to point to your service. In particular set the `service_name`, `deployment_name`, `location`, and `key` variables to match those for your OpenAI service:
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import running_on_synapse, find_secret
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
if running_on_synapse():
|
||||
from notebookutils.visualization import display
|
||||
|
||||
# Fill in the following lines with your service information
|
||||
# Learn more about selecting which embedding model to choose: https://openai.com/blog/new-and-improved-embedding-model
|
||||
service_name = "synapseml-openai"
|
||||
deployment_name = "gpt-35-turbo"
|
||||
deployment_name_embeddings = "text-embedding-ada-002"
|
||||
|
||||
key = find_secret(
|
||||
"openai-api-key"
|
||||
) # please replace this line with your key as a string
|
||||
|
||||
assert key is not None and service_name is not None
|
||||
```
|
||||
|
||||
## Step 4: Create a dataset of prompts
|
||||
|
||||
Next, create a dataframe consisting of a series of rows, with one prompt per row.
|
||||
|
||||
You can also load data directly from ADLS or other databases. For more information on loading and preparing Spark dataframes, see the [Apache Spark data loading guide](https://spark.apache.org/docs/latest/sql-data-sources.html).
|
||||
|
||||
|
||||
```python
|
||||
df = spark.createDataFrame(
|
||||
[
|
||||
("Hello my name is",),
|
||||
("The best code is code thats",),
|
||||
("SynapseML is ",),
|
||||
]
|
||||
).toDF("prompt")
|
||||
```
|
||||
|
||||
## Step 5: Create the OpenAICompletion Apache Spark Client
|
||||
|
||||
To apply the OpenAI Completion service to your dataframe you created, create an OpenAICompletion object, which serves as a distributed client. Parameters of the service can be set either with a single value, or by a column of the dataframe with the appropriate setters on the `OpenAICompletion` object. Here we're setting `maxTokens` to 200. A token is around four characters, and this limit applies to the sum of the prompt and the result. We're also setting the `promptCol` parameter with the name of the prompt column in the dataframe.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import OpenAICompletion
|
||||
|
||||
completion = (
|
||||
OpenAICompletion()
|
||||
.setSubscriptionKey(key)
|
||||
.setDeploymentName(deployment_name)
|
||||
.setCustomServiceName(service_name)
|
||||
.setMaxTokens(200)
|
||||
.setPromptCol("prompt")
|
||||
.setErrorCol("error")
|
||||
.setOutputCol("completions")
|
||||
)
|
||||
```
|
||||
|
||||
## Step 6: Transform the dataframe with the OpenAICompletion Client
|
||||
|
||||
Now that you have the dataframe and the completion client, you can transform your input dataset and add a column called `completions` with all of the information the service adds. We'll select out just the text for simplicity.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import col
|
||||
|
||||
completed_df = completion.transform(df).cache()
|
||||
display(
|
||||
completed_df.select(
|
||||
col("prompt"),
|
||||
col("error"),
|
||||
col("completions.choices.text").getItem(0).alias("text"),
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
Your output should look something like this. Please note completion text will be different
|
||||
|
||||
| **prompt** | **error** | **text** |
|
||||
|:----------------------------: |:----------: |:-------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
| Hello my name is | null | Makaveli I'm eighteen years old and I want to be a rapper when I grow up I love writing and making music I'm from Los Angeles, CA |
|
||||
| The best code is code thats | null | understandable This is a subjective statement, and there is no definitive answer. |
|
||||
| SynapseML is | null | A machine learning algorithm that is able to learn how to predict the future outcome of events. |
|
||||
|
||||
## Additional Usage Examples
|
||||
|
||||
### Generating Text Embeddings
|
||||
|
||||
In addition to completing text, we can also embed text for use in downstream algorithms or vector retrieval architectures. Creating embeddings allows you to search and retrieve documents from large collections and can be used when prompt engineering isn't sufficient for the task. For more information on using `OpenAIEmbedding`, see our [embedding guide](https://microsoft.github.io/SynapseML/docs/features/cognitive_services/CognitiveServices%20-%20OpenAI%20Embedding/).
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import OpenAIEmbedding
|
||||
|
||||
embedding = (
|
||||
OpenAIEmbedding()
|
||||
.setSubscriptionKey(key)
|
||||
.setDeploymentName(deployment_name_embeddings)
|
||||
.setCustomServiceName(service_name)
|
||||
.setTextCol("prompt")
|
||||
.setErrorCol("error")
|
||||
.setOutputCol("embeddings")
|
||||
)
|
||||
|
||||
display(embedding.transform(df))
|
||||
```
|
||||
|
||||
### Chat Completion
|
||||
|
||||
Models such as ChatGPT and GPT-4 are capable of understanding chats instead of single prompts. The `OpenAIChatCompletion` transformer exposes this functionality at scale.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import OpenAIChatCompletion
|
||||
from pyspark.sql import Row
|
||||
from pyspark.sql.types import *
|
||||
|
||||
|
||||
def make_message(role, content):
|
||||
return Row(role=role, content=content, name=role)
|
||||
|
||||
|
||||
chat_df = spark.createDataFrame(
|
||||
[
|
||||
(
|
||||
[
|
||||
make_message(
|
||||
"system", "You are an AI chatbot with red as your favorite color"
|
||||
),
|
||||
make_message("user", "Whats your favorite color"),
|
||||
],
|
||||
),
|
||||
(
|
||||
[
|
||||
make_message("system", "You are very excited"),
|
||||
make_message("user", "How are you today"),
|
||||
],
|
||||
),
|
||||
]
|
||||
).toDF("messages")
|
||||
|
||||
|
||||
chat_completion = (
|
||||
OpenAIChatCompletion()
|
||||
.setSubscriptionKey(key)
|
||||
.setDeploymentName(deployment_name)
|
||||
.setCustomServiceName(service_name)
|
||||
.setMessagesCol("messages")
|
||||
.setErrorCol("error")
|
||||
.setOutputCol("chat_completions")
|
||||
)
|
||||
|
||||
display(
|
||||
chat_completion.transform(chat_df).select(
|
||||
"messages", "chat_completions.choices.message.content"
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
### Improve throughput with request batching
|
||||
|
||||
The example makes several requests to the service, one for each prompt. To complete multiple prompts in a single request, use batch mode. First, in the OpenAICompletion object, instead of setting the Prompt column to "Prompt", specify "batchPrompt" for the BatchPrompt column.
|
||||
To do so, create a dataframe with a list of prompts per row.
|
||||
|
||||
**Note** that as of this writing there is currently a limit of 20 prompts in a single request, and a hard limit of 2048 "tokens", or approximately 1500 words.
|
||||
|
||||
|
||||
```python
|
||||
batch_df = spark.createDataFrame(
|
||||
[
|
||||
(["The time has come", "Pleased to", "Today stocks", "Here's to"],),
|
||||
(["The only thing", "Ask not what", "Every litter", "I am"],),
|
||||
]
|
||||
).toDF("batchPrompt")
|
||||
```
|
||||
|
||||
Next we create the OpenAICompletion object. Rather than setting the prompt column, set the batchPrompt column if your column is of type `Array[String]`.
|
||||
|
||||
|
||||
```python
|
||||
batch_completion = (
|
||||
OpenAICompletion()
|
||||
.setSubscriptionKey(key)
|
||||
.setDeploymentName(deployment_name)
|
||||
.setCustomServiceName(service_name)
|
||||
.setMaxTokens(200)
|
||||
.setBatchPromptCol("batchPrompt")
|
||||
.setErrorCol("error")
|
||||
.setOutputCol("completions")
|
||||
)
|
||||
```
|
||||
|
||||
In the call to transform a request will then be made per row. Since there are multiple prompts in a single row, each is sent with all prompts in that row. The results contain a row for each row in the request.
|
||||
|
||||
|
||||
```python
|
||||
completed_batch_df = batch_completion.transform(batch_df).cache()
|
||||
display(completed_batch_df)
|
||||
```
|
||||
|
||||
### Using an automatic minibatcher
|
||||
|
||||
If your data is in column format, you can transpose it to row format using SynapseML's `FixedMiniBatcherTransformer`.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.types import StringType
|
||||
from synapse.ml.stages import FixedMiniBatchTransformer
|
||||
from synapse.ml.core.spark import FluentAPI
|
||||
|
||||
completed_autobatch_df = (
|
||||
df.coalesce(
|
||||
1
|
||||
) # Force a single partition so that our little 4-row dataframe makes a batch of size 4, you can remove this step for large datasets
|
||||
.mlTransform(FixedMiniBatchTransformer(batchSize=4))
|
||||
.withColumnRenamed("prompt", "batchPrompt")
|
||||
.mlTransform(batch_completion)
|
||||
)
|
||||
|
||||
display(completed_autobatch_df)
|
||||
```
|
||||
|
||||
### Prompt engineering for translation
|
||||
|
||||
The Azure OpenAI service can solve many different natural language tasks through [prompt engineering](https://docs.microsoft.com/en-us/azure/cognitive-services/openai/how-to/completions). Here we show an example of prompting for language translation:
|
||||
|
||||
|
||||
```python
|
||||
translate_df = spark.createDataFrame(
|
||||
[
|
||||
("Japanese: Ookina hako \nEnglish: Big box \nJapanese: Midori tako\nEnglish:",),
|
||||
(
|
||||
"French: Quel heure et il au Montreal? \nEnglish: What time is it in Montreal? \nFrench: Ou est le poulet? \nEnglish:",
|
||||
),
|
||||
]
|
||||
).toDF("prompt")
|
||||
|
||||
display(completion.transform(translate_df))
|
||||
```
|
||||
|
||||
### Prompt for question answering
|
||||
|
||||
Here, we prompt GPT-3 for general-knowledge question answering:
|
||||
|
||||
|
||||
```python
|
||||
qa_df = spark.createDataFrame(
|
||||
[
|
||||
(
|
||||
"Q: Where is the Grand Canyon?\nA: The Grand Canyon is in Arizona.\n\nQ: What is the weight of the Burj Khalifa in kilograms?\nA:",
|
||||
)
|
||||
]
|
||||
).toDF("prompt")
|
||||
|
||||
display(completion.transform(qa_df))
|
||||
```
|
||||
|
|
@ -0,0 +1,535 @@
|
|||
---
|
||||
title: CognitiveServices - Overview
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Cognitive Services
|
||||
|
||||
<image width="200" alt-text="icon" src="https://mmlspark.blob.core.windows.net/graphics/Readme/cog_services_on_spark_2.svg" />
|
||||
|
||||
[Azure Cognitive Services](https://azure.microsoft.com/services/cognitive-services/) are a suite of APIs, SDKs, and services available to help developers build intelligent applications without having direct AI or data science skills or knowledge by enabling developers to easily add cognitive features into their applications. The goal of Azure Cognitive Services is to help developers create applications that can see, hear, speak, understand, and even begin to reason. The catalog of services within Azure Cognitive Services can be categorized into five main pillars - Vision, Speech, Language, Web Search, and Decision.
|
||||
|
||||
## Usage
|
||||
|
||||
### Vision
|
||||
[**Computer Vision**](https://azure.microsoft.com/services/cognitive-services/computer-vision/)
|
||||
- Describe: provides description of an image in human readable language ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/DescribeImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.DescribeImage))
|
||||
- Analyze (color, image type, face, adult/racy content): analyzes visual features of an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/AnalyzeImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.AnalyzeImage))
|
||||
- OCR: reads text from an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/OCR.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.OCR))
|
||||
- Recognize Text: reads text from an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/RecognizeText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.RecognizeText))
|
||||
- Thumbnail: generates a thumbnail of user-specified size from the image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/GenerateThumbnails.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.GenerateThumbnails))
|
||||
- Recognize domain-specific content: recognizes domain-specific content (celebrity, landmark) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/RecognizeDomainSpecificContent.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.RecognizeDomainSpecificContent))
|
||||
- Tag: identifies list of words that are relevant to the input image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/vision/TagImage.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.vision.html#module-synapse.ml.cognitive.vision.TagImage))
|
||||
|
||||
[**Face**](https://azure.microsoft.com/services/cognitive-services/face/)
|
||||
- Detect: detects human faces in an image ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/DetectFace.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.DetectFace))
|
||||
- Verify: verifies whether two faces belong to a same person, or a face belongs to a person ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/VerifyFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.VerifyFaces))
|
||||
- Identify: finds the closest matches of the specific query person face from a person group ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/IdentifyFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.IdentifyFaces))
|
||||
- Find similar: finds similar faces to the query face in a face list ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/FindSimilarFace.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.FindSimilarFace))
|
||||
- Group: divides a group of faces into disjoint groups based on similarity ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/face/GroupFaces.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.face.html#module-synapse.ml.cognitive.face.GroupFaces))
|
||||
|
||||
### Speech
|
||||
[**Speech Services**](https://azure.microsoft.com/services/cognitive-services/speech-services/)
|
||||
- Speech-to-text: transcribes audio streams ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/speech/SpeechToText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.SpeechToText))
|
||||
- Conversation Transcription: transcribes audio streams into live transcripts with identified speakers. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/speech/ConversationTranscription.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.ConversationTranscription))
|
||||
- Text to Speech: Converts text to realistic audio ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/speech/TextToSpeech.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.speech.html#module-synapse.ml.cognitive.speech.TextToSpeech))
|
||||
|
||||
|
||||
### Language
|
||||
[**Text Analytics**](https://azure.microsoft.com/services/cognitive-services/text-analytics/)
|
||||
- Language detection: detects language of the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/LanguageDetector.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.LanguageDetector))
|
||||
- Key phrase extraction: identifies the key talking points in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/KeyPhraseExtractor.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.KeyPhraseExtractor))
|
||||
- Named entity recognition: identifies known entities and general named entities in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/NER.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.NER))
|
||||
- Sentiment analysis: returns a score between 0 and 1 indicating the sentiment in the input text ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/TextSentiment.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.TextSentiment))
|
||||
- Healthcare Entity Extraction: Extracts medical entities and relationships from text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/text/AnalyzeHealthText.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.text.html#module-synapse.ml.cognitive.text.AnalyzeHealthText))
|
||||
|
||||
|
||||
### Translation
|
||||
[**Translator**](https://azure.microsoft.com/services/cognitive-services/translator/)
|
||||
- Translate: Translates text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Translate.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Translate))
|
||||
- Transliterate: Converts text in one language from one script to another script. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Transliterate.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Transliterate))
|
||||
- Detect: Identifies the language of a piece of text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/Detect.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.Detect))
|
||||
- BreakSentence: Identifies the positioning of sentence boundaries in a piece of text. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/BreakSentence.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.BreakSentence))
|
||||
- Dictionary Lookup: Provides alternative translations for a word and a small number of idiomatic phrases. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DictionaryLookup.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DictionaryLookup))
|
||||
- Dictionary Examples: Provides examples that show how terms in the dictionary are used in context. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DictionaryExamples.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DictionaryExamples))
|
||||
- Document Translation: Translates documents across all supported languages and dialects while preserving document structure and data format. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/translate/DocumentTranslator.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.translate.html#module-synapse.ml.cognitive.translate.DocumentTranslator))
|
||||
|
||||
### Form Recognizer
|
||||
[**Form Recognizer**](https://azure.microsoft.com/services/form-recognizer/)
|
||||
- Analyze Layout: Extract text and layout information from a given document. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeLayout.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeLayout))
|
||||
- Analyze Receipts: Detects and extracts data from receipts using optical character recognition (OCR) and our receipt model, enabling you to easily extract structured data from receipts such as merchant name, merchant phone number, transaction date, transaction total, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeReceipts.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeReceipts))
|
||||
- Analyze Business Cards: Detects and extracts data from business cards using optical character recognition (OCR) and our business card model, enabling you to easily extract structured data from business cards such as contact names, company names, phone numbers, emails, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeBusinessCards.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeBusinessCards))
|
||||
- Analyze Invoices: Detects and extracts data from invoices using optical character recognition (OCR) and our invoice understanding deep learning models, enabling you to easily extract structured data from invoices such as customer, vendor, invoice ID, invoice due date, total, invoice amount due, tax amount, ship to, bill to, line items and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeInvoices.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeInvoices))
|
||||
- Analyze ID Documents: Detects and extracts data from identification documents using optical character recognition (OCR) and our ID document model, enabling you to easily extract structured data from ID documents such as first name, last name, date of birth, document number, and more. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeIDDocuments.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeIDDocuments))
|
||||
- Analyze Custom Form: Extracts information from forms (PDFs and images) into structured data based on a model created from a set of representative training forms. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/AnalyzeCustomModel.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.AnalyzeCustomModel))
|
||||
- Get Custom Model: Get detailed information about a custom model. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/GetCustomModel.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/ListCustomModels.html))
|
||||
- List Custom Models: Get information about all custom models. ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/form/ListCustomModels.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.form.html#module-synapse.ml.cognitive.form.ListCustomModels))
|
||||
|
||||
### Decision
|
||||
[**Anomaly Detector**](https://azure.microsoft.com/services/cognitive-services/anomaly-detector/)
|
||||
- Anomaly status of latest point: generates a model using preceding points and determines whether the latest point is anomalous ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/anomaly/DetectLastAnomaly.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.anomaly.html#module-synapse.ml.cognitive.anomaly.DetectLastAnomaly))
|
||||
- Find anomalies: generates a model using an entire series and finds anomalies in the series ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/anomaly/DetectAnomalies.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.anomaly.html#module-synapse.ml.cognitive.anomaly.DetectAnomalies))
|
||||
|
||||
### Search
|
||||
- [Bing Image search](https://azure.microsoft.com/services/cognitive-services/bing-image-search-api/) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/bing/BingImageSearch.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.bing.html#module-synapse.ml.cognitive.bing.BingImageSearch))
|
||||
- [Azure Cognitive search](https://docs.microsoft.com/azure/search/search-what-is-azure-search) ([Scala](https://mmlspark.blob.core.windows.net/docs/0.11.2/scala/com/microsoft/azure/synapse/ml/cognitive/search/AzureSearchWriter$.html), [Python](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.cognitive.search.html#module-synapse.ml.cognitive.search.AzureSearchWriter))
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Follow the steps in [Getting started](https://docs.microsoft.com/en-us/azure/cognitive-services/big-data/getting-started) to set up your Azure Databricks and Cognitive Services environment. This tutorial shows you how to install SynapseML and how to create your Spark cluster in Databricks.
|
||||
1. After you create a new notebook in Azure Databricks, copy the **Shared code** below and paste into a new cell in your notebook.
|
||||
1. Choose a service sample, below, and copy paste it into a second new cell in your notebook.
|
||||
1. Replace any of the service subscription key placeholders with your own key.
|
||||
1. Choose the run button (triangle icon) in the upper right corner of the cell, then select **Run Cell**.
|
||||
1. View results in a table below the cell.
|
||||
|
||||
## Shared code
|
||||
|
||||
To get started, we'll need to add this code to the project:
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import udf, col
|
||||
from synapse.ml.io.http import HTTPTransformer, http_udf
|
||||
from requests import Request
|
||||
from pyspark.sql.functions import lit
|
||||
from pyspark.ml import PipelineModel
|
||||
from pyspark.sql.functions import col
|
||||
import os
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
|
||||
# A general Cognitive Services key for Text Analytics, Computer Vision and Form Recognizer (or use separate keys that belong to each service)
|
||||
service_key = find_secret("cognitive-api-key")
|
||||
service_loc = "eastus"
|
||||
|
||||
# A Bing Search v7 subscription key
|
||||
bing_search_key = find_secret("bing-search-key")
|
||||
|
||||
# An Anomaly Dectector subscription key
|
||||
anomaly_key = find_secret("anomaly-api-key")
|
||||
anomaly_loc = "westus2"
|
||||
|
||||
# A Translator subscription key
|
||||
translator_key = find_secret("translator-key")
|
||||
translator_loc = "eastus"
|
||||
|
||||
# An Azure search key
|
||||
search_key = find_secret("azure-search-key")
|
||||
```
|
||||
|
||||
## Text Analytics sample
|
||||
|
||||
The [Text Analytics](https://azure.microsoft.com/en-us/services/cognitive-services/text-analytics/) service provides several algorithms for extracting intelligent insights from text. For example, we can find the sentiment of given input text. The service will return a score between 0.0 and 1.0 where low scores indicate negative sentiment and high score indicates positive sentiment. This sample uses three simple sentences and returns the sentiment for each.
|
||||
|
||||
|
||||
```python
|
||||
# Create a dataframe that's tied to it's column names
|
||||
df = spark.createDataFrame(
|
||||
[
|
||||
("I am so happy today, its sunny!", "en-US"),
|
||||
("I am frustrated by this rush hour traffic", "en-US"),
|
||||
("The cognitive services on spark aint bad", "en-US"),
|
||||
],
|
||||
["text", "language"],
|
||||
)
|
||||
|
||||
# Run the Text Analytics service with options
|
||||
sentiment = (
|
||||
TextSentiment()
|
||||
.setTextCol("text")
|
||||
.setLocation(service_loc)
|
||||
.setSubscriptionKey(service_key)
|
||||
.setOutputCol("sentiment")
|
||||
.setErrorCol("error")
|
||||
.setLanguageCol("language")
|
||||
)
|
||||
|
||||
# Show the results of your text query in a table format
|
||||
display(
|
||||
sentiment.transform(df).select(
|
||||
"text", col("sentiment.document.sentiment").alias("sentiment")
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
## Text Analytics for Health Sample
|
||||
|
||||
The [Text Analytics for Health Service](https://docs.microsoft.com/en-us/azure/cognitive-services/language-service/text-analytics-for-health/overview?tabs=ner) extracts and labels relevant medical information from unstructured texts such as doctor's notes, discharge summaries, clinical documents, and electronic health records.
|
||||
|
||||
|
||||
```python
|
||||
df = spark.createDataFrame(
|
||||
[
|
||||
("20mg of ibuprofen twice a day",),
|
||||
("1tsp of Tylenol every 4 hours",),
|
||||
("6-drops of Vitamin B-12 every evening",),
|
||||
],
|
||||
["text"],
|
||||
)
|
||||
|
||||
healthcare = (
|
||||
AnalyzeHealthText()
|
||||
.setSubscriptionKey(service_key)
|
||||
.setLocation(service_loc)
|
||||
.setLanguage("en")
|
||||
.setOutputCol("response")
|
||||
)
|
||||
|
||||
display(healthcare.transform(df))
|
||||
```
|
||||
|
||||
## Translator sample
|
||||
[Translator](https://azure.microsoft.com/en-us/services/cognitive-services/translator/) is a cloud-based machine translation service and is part of the Azure Cognitive Services family of cognitive APIs used to build intelligent apps. Translator is easy to integrate in your applications, websites, tools, and solutions. It allows you to add multi-language user experiences in 90 languages and dialects and can be used for text translation with any operating system. In this sample, we do a simple text translation by providing the sentences you want to translate and target languages you want to translate to.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import col, flatten
|
||||
|
||||
# Create a dataframe including sentences you want to translate
|
||||
df = spark.createDataFrame(
|
||||
[(["Hello, what is your name?", "Bye"],)],
|
||||
[
|
||||
"text",
|
||||
],
|
||||
)
|
||||
|
||||
# Run the Translator service with options
|
||||
translate = (
|
||||
Translate()
|
||||
.setSubscriptionKey(translator_key)
|
||||
.setLocation(translator_loc)
|
||||
.setTextCol("text")
|
||||
.setToLanguage(["zh-Hans"])
|
||||
.setOutputCol("translation")
|
||||
)
|
||||
|
||||
# Show the results of the translation.
|
||||
display(
|
||||
translate.transform(df)
|
||||
.withColumn("translation", flatten(col("translation.translations")))
|
||||
.withColumn("translation", col("translation.text"))
|
||||
.select("translation")
|
||||
)
|
||||
```
|
||||
|
||||
## Form Recognizer sample
|
||||
[Form Recognizer](https://azure.microsoft.com/en-us/services/form-recognizer/) is a part of Azure Applied AI Services that lets you build automated data processing software using machine learning technology. Identify and extract text, key/value pairs, selection marks, tables, and structure from your documents—the service outputs structured data that includes the relationships in the original file, bounding boxes, confidence and more. In this sample, we analyze a business card image and extract its information into structured data.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import col, explode
|
||||
|
||||
# Create a dataframe containing the source files
|
||||
imageDf = spark.createDataFrame(
|
||||
[
|
||||
(
|
||||
"https://mmlspark.blob.core.windows.net/datasets/FormRecognizer/business_card.jpg",
|
||||
)
|
||||
],
|
||||
[
|
||||
"source",
|
||||
],
|
||||
)
|
||||
|
||||
# Run the Form Recognizer service
|
||||
analyzeBusinessCards = (
|
||||
AnalyzeBusinessCards()
|
||||
.setSubscriptionKey(service_key)
|
||||
.setLocation(service_loc)
|
||||
.setImageUrlCol("source")
|
||||
.setOutputCol("businessCards")
|
||||
)
|
||||
|
||||
# Show the results of recognition.
|
||||
display(
|
||||
analyzeBusinessCards.transform(imageDf)
|
||||
.withColumn(
|
||||
"documents", explode(col("businessCards.analyzeResult.documentResults.fields"))
|
||||
)
|
||||
.select("source", "documents")
|
||||
)
|
||||
```
|
||||
|
||||
## Computer Vision sample
|
||||
|
||||
[Computer Vision](https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/) analyzes images to identify structure such as faces, objects, and natural-language descriptions. In this sample, we tag a list of images. Tags are one-word descriptions of things in the image like recognizable objects, people, scenery, and actions.
|
||||
|
||||
|
||||
```python
|
||||
# Create a dataframe with the image URLs
|
||||
base_url = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-sample-data-files/master/ComputerVision/Images/"
|
||||
df = spark.createDataFrame(
|
||||
[
|
||||
(base_url + "objects.jpg",),
|
||||
(base_url + "dog.jpg",),
|
||||
(base_url + "house.jpg",),
|
||||
],
|
||||
[
|
||||
"image",
|
||||
],
|
||||
)
|
||||
|
||||
# Run the Computer Vision service. Analyze Image extracts infortmation from/about the images.
|
||||
analysis = (
|
||||
AnalyzeImage()
|
||||
.setLocation(service_loc)
|
||||
.setSubscriptionKey(service_key)
|
||||
.setVisualFeatures(
|
||||
["Categories", "Color", "Description", "Faces", "Objects", "Tags"]
|
||||
)
|
||||
.setOutputCol("analysis_results")
|
||||
.setImageUrlCol("image")
|
||||
.setErrorCol("error")
|
||||
)
|
||||
|
||||
# Show the results of what you wanted to pull out of the images.
|
||||
display(analysis.transform(df).select("image", "analysis_results.description.tags"))
|
||||
```
|
||||
|
||||
## Bing Image Search sample
|
||||
|
||||
[Bing Image Search](https://azure.microsoft.com/en-us/services/cognitive-services/bing-image-search-api/) searches the web to retrieve images related to a user's natural language query. In this sample, we use a text query that looks for images with quotes. It returns a list of image URLs that contain photos related to our query.
|
||||
|
||||
|
||||
```python
|
||||
# Number of images Bing will return per query
|
||||
imgsPerBatch = 10
|
||||
# A list of offsets, used to page into the search results
|
||||
offsets = [(i * imgsPerBatch,) for i in range(100)]
|
||||
# Since web content is our data, we create a dataframe with options on that data: offsets
|
||||
bingParameters = spark.createDataFrame(offsets, ["offset"])
|
||||
|
||||
# Run the Bing Image Search service with our text query
|
||||
bingSearch = (
|
||||
BingImageSearch()
|
||||
.setSubscriptionKey(bing_search_key)
|
||||
.setOffsetCol("offset")
|
||||
.setQuery("Martin Luther King Jr. quotes")
|
||||
.setCount(imgsPerBatch)
|
||||
.setOutputCol("images")
|
||||
)
|
||||
|
||||
# Transformer that extracts and flattens the richly structured output of Bing Image Search into a simple URL column
|
||||
getUrls = BingImageSearch.getUrlTransformer("images", "url")
|
||||
|
||||
# This displays the full results returned, uncomment to use
|
||||
# display(bingSearch.transform(bingParameters))
|
||||
|
||||
# Since we have two services, they are put into a pipeline
|
||||
pipeline = PipelineModel(stages=[bingSearch, getUrls])
|
||||
|
||||
# Show the results of your search: image URLs
|
||||
display(pipeline.transform(bingParameters))
|
||||
```
|
||||
|
||||
## Speech-to-Text sample
|
||||
The [Speech-to-text](https://azure.microsoft.com/en-us/services/cognitive-services/speech-services/) service converts streams or files of spoken audio to text. In this sample, we transcribe one audio file.
|
||||
|
||||
|
||||
```python
|
||||
# Create a dataframe with our audio URLs, tied to the column called "url"
|
||||
df = spark.createDataFrame(
|
||||
[("https://mmlspark.blob.core.windows.net/datasets/Speech/audio2.wav",)], ["url"]
|
||||
)
|
||||
|
||||
# Run the Speech-to-text service to translate the audio into text
|
||||
speech_to_text = (
|
||||
SpeechToTextSDK()
|
||||
.setSubscriptionKey(service_key)
|
||||
.setLocation(service_loc)
|
||||
.setOutputCol("text")
|
||||
.setAudioDataCol("url")
|
||||
.setLanguage("en-US")
|
||||
.setProfanity("Masked")
|
||||
)
|
||||
|
||||
# Show the results of the translation
|
||||
display(speech_to_text.transform(df).select("url", "text.DisplayText"))
|
||||
```
|
||||
|
||||
## Text-to-Speech sample
|
||||
[Text to speech](https://azure.microsoft.com/en-us/services/cognitive-services/text-to-speech/#overview) is a service that allows one to build apps and services that speak naturally, choosing from more than 270 neural voices across 119 languages and variants.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import TextToSpeech
|
||||
|
||||
fs = ""
|
||||
if running_on_databricks():
|
||||
fs = "dbfs:"
|
||||
elif running_on_synapse_internal():
|
||||
fs = "Files"
|
||||
|
||||
# Create a dataframe with text and an output file location
|
||||
df = spark.createDataFrame(
|
||||
[
|
||||
(
|
||||
"Reading out loud is fun! Check out aka.ms/spark for more information",
|
||||
fs + "/output.mp3",
|
||||
)
|
||||
],
|
||||
["text", "output_file"],
|
||||
)
|
||||
|
||||
tts = (
|
||||
TextToSpeech()
|
||||
.setSubscriptionKey(service_key)
|
||||
.setTextCol("text")
|
||||
.setLocation(service_loc)
|
||||
.setVoiceName("en-US-JennyNeural")
|
||||
.setOutputFileCol("output_file")
|
||||
)
|
||||
|
||||
# Check to make sure there were no errors during audio creation
|
||||
display(tts.transform(df))
|
||||
```
|
||||
|
||||
## Anomaly Detector sample
|
||||
|
||||
[Anomaly Detector](https://azure.microsoft.com/en-us/services/cognitive-services/anomaly-detector/) is great for detecting irregularities in your time series data. In this sample, we use the service to find anomalies in the entire time series.
|
||||
|
||||
|
||||
```python
|
||||
# Create a dataframe with the point data that Anomaly Detector requires
|
||||
df = spark.createDataFrame(
|
||||
[
|
||||
("1972-01-01T00:00:00Z", 826.0),
|
||||
("1972-02-01T00:00:00Z", 799.0),
|
||||
("1972-03-01T00:00:00Z", 890.0),
|
||||
("1972-04-01T00:00:00Z", 900.0),
|
||||
("1972-05-01T00:00:00Z", 766.0),
|
||||
("1972-06-01T00:00:00Z", 805.0),
|
||||
("1972-07-01T00:00:00Z", 821.0),
|
||||
("1972-08-01T00:00:00Z", 20000.0),
|
||||
("1972-09-01T00:00:00Z", 883.0),
|
||||
("1972-10-01T00:00:00Z", 898.0),
|
||||
("1972-11-01T00:00:00Z", 957.0),
|
||||
("1972-12-01T00:00:00Z", 924.0),
|
||||
("1973-01-01T00:00:00Z", 881.0),
|
||||
("1973-02-01T00:00:00Z", 837.0),
|
||||
("1973-03-01T00:00:00Z", 9000.0),
|
||||
],
|
||||
["timestamp", "value"],
|
||||
).withColumn("group", lit("series1"))
|
||||
|
||||
# Run the Anomaly Detector service to look for irregular data
|
||||
anamoly_detector = (
|
||||
SimpleDetectAnomalies()
|
||||
.setSubscriptionKey(anomaly_key)
|
||||
.setLocation(anomaly_loc)
|
||||
.setTimestampCol("timestamp")
|
||||
.setValueCol("value")
|
||||
.setOutputCol("anomalies")
|
||||
.setGroupbyCol("group")
|
||||
.setGranularity("monthly")
|
||||
)
|
||||
|
||||
# Show the full results of the analysis with the anomalies marked as "True"
|
||||
display(
|
||||
anamoly_detector.transform(df).select("timestamp", "value", "anomalies.isAnomaly")
|
||||
)
|
||||
```
|
||||
|
||||
## Arbitrary web APIs
|
||||
|
||||
With HTTP on Spark, any web service can be used in your big data pipeline. In this example, we use the [World Bank API](http://api.worldbank.org/v2/country/) to get information about various countries around the world.
|
||||
|
||||
|
||||
```python
|
||||
# Use any requests from the python requests library
|
||||
|
||||
|
||||
def world_bank_request(country):
|
||||
return Request(
|
||||
"GET", "http://api.worldbank.org/v2/country/{}?format=json".format(country)
|
||||
)
|
||||
|
||||
|
||||
# Create a dataframe with spcificies which countries we want data on
|
||||
df = spark.createDataFrame([("br",), ("usa",)], ["country"]).withColumn(
|
||||
"request", http_udf(world_bank_request)(col("country"))
|
||||
)
|
||||
|
||||
# Much faster for big data because of the concurrency :)
|
||||
client = (
|
||||
HTTPTransformer().setConcurrency(3).setInputCol("request").setOutputCol("response")
|
||||
)
|
||||
|
||||
# Get the body of the response
|
||||
|
||||
|
||||
def get_response_body(resp):
|
||||
return resp.entity.content.decode()
|
||||
|
||||
|
||||
# Show the details of the country data returned
|
||||
display(
|
||||
client.transform(df).select(
|
||||
"country", udf(get_response_body)(col("response")).alias("response")
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
## Azure Cognitive search sample
|
||||
|
||||
In this example, we show how you can enrich data using Cognitive Skills and write to an Azure Search Index using SynapseML.
|
||||
|
||||
|
||||
```python
|
||||
search_service = "mmlspark-azure-search"
|
||||
search_index = "test-33467690"
|
||||
|
||||
df = spark.createDataFrame(
|
||||
[
|
||||
(
|
||||
"upload",
|
||||
"0",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test1.jpg",
|
||||
),
|
||||
(
|
||||
"upload",
|
||||
"1",
|
||||
"https://mmlspark.blob.core.windows.net/datasets/DSIR/test2.jpg",
|
||||
),
|
||||
],
|
||||
["searchAction", "id", "url"],
|
||||
)
|
||||
|
||||
tdf = (
|
||||
AnalyzeImage()
|
||||
.setSubscriptionKey(service_key)
|
||||
.setLocation(service_loc)
|
||||
.setImageUrlCol("url")
|
||||
.setOutputCol("analyzed")
|
||||
.setErrorCol("errors")
|
||||
.setVisualFeatures(
|
||||
["Categories", "Tags", "Description", "Faces", "ImageType", "Color", "Adult"]
|
||||
)
|
||||
.transform(df)
|
||||
.select("*", "analyzed.*")
|
||||
.drop("errors", "analyzed")
|
||||
)
|
||||
|
||||
tdf.writeToAzureSearch(
|
||||
subscriptionKey=search_key,
|
||||
actionCol="searchAction",
|
||||
serviceName=search_service,
|
||||
indexName=search_index,
|
||||
keyCol="id",
|
||||
)
|
||||
```
|
||||
|
|
@ -0,0 +1,186 @@
|
|||
---
|
||||
title: CognitiveServices - Predictive Maintenance
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Recipe: Predictive maintenance with the Cognitive Services for Big Data
|
||||
|
||||
This recipe shows how you can use Azure Synapse Analytics and Cognitive Services on Apache Spark for predictive maintenance of IoT devices. We'll follow along with the [CosmosDB and Synapse Link](https://github.com/Azure-Samples/cosmosdb-synapse-link-samples) sample. To keep things simple, in this recipe we'll read the data straight from a CSV file rather than getting streamed data through CosmosDB and Synapse Link. We strongly encourage you to look over the Synapse Link sample.
|
||||
|
||||
## Hypothetical scenario
|
||||
|
||||
The hypothetical scenario is a Power Plant, where IoT devices are monitoring [steam turbines](https://en.wikipedia.org/wiki/Steam_turbine). The IoTSignals collection has Revolutions per minute (RPM) and Megawatts (MW) data for each turbine. Signals from steam turbines are being analyzed and anomalous signals are detected.
|
||||
|
||||
There could be outliers in the data in random frequency. In those situations, RPM values will go up and MW output will go down, for circuit protection. The idea is to see the data varying at the same time, but with different signals.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* An Azure subscription - [Create one for free](https://azure.microsoft.com/en-us/free/)
|
||||
* [Azure Synapse workspace](https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started-create-workspace) configured with a [serverless Apache Spark pool](https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started-analyze-spark)
|
||||
|
||||
## Setup
|
||||
|
||||
### Create an Anomaly Detector resource
|
||||
|
||||
Azure Cognitive Services are represented by Azure resources that you subscribe to. Create a resource for Translator using the [Azure portal](https://docs.microsoft.com/en-us/azure/cognitive-services/cognitive-services-apis-create-account?tabs=multiservice%2Clinux) or [Azure CLI](https://docs.microsoft.com/en-us/azure/cognitive-services/cognitive-services-apis-create-account-cli?tabs=linux). You can also:
|
||||
|
||||
- View an existing resource in the [Azure portal](https://portal.azure.com/).
|
||||
|
||||
Make note of the endpoint and the key for this resource, you'll need it in this guide.
|
||||
|
||||
## Enter your service keys
|
||||
|
||||
Let's start by adding your key and location.
|
||||
|
||||
|
||||
```
|
||||
import os
|
||||
from synapse.ml.core.platform import find_secret
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
service_key = find_secret("anomaly-api-key") # Paste your anomaly detector key here
|
||||
location = "westus2" # Paste your anomaly detector location here
|
||||
```
|
||||
|
||||
## Read data into a DataFrame
|
||||
|
||||
Next, let's read the IoTSignals file into a DataFrame. Open a new notebook in your Synapse workspace and create a DataFrame from the file.
|
||||
|
||||
|
||||
```
|
||||
df_signals = spark.read.csv(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/iot/IoTSignals.csv",
|
||||
header=True,
|
||||
inferSchema=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Run anomaly detection using Cognitive Services on Spark
|
||||
|
||||
The goal is to find instances where the signals from the IoT devices were outputting anomalous values so that we can see when something is going wrong and do predictive maintenance. To do that, let's use Anomaly Detector on Spark:
|
||||
|
||||
|
||||
```
|
||||
from pyspark.sql.functions import col, struct
|
||||
from synapse.ml.cognitive import SimpleDetectAnomalies
|
||||
from synapse.ml.core.spark import FluentAPI
|
||||
|
||||
detector = (
|
||||
SimpleDetectAnomalies()
|
||||
.setSubscriptionKey(service_key)
|
||||
.setLocation(location)
|
||||
.setOutputCol("anomalies")
|
||||
.setGroupbyCol("grouping")
|
||||
.setSensitivity(95)
|
||||
.setGranularity("secondly")
|
||||
)
|
||||
|
||||
df_anomaly = (
|
||||
df_signals.where(col("unitSymbol") == "RPM")
|
||||
.withColumn("timestamp", col("dateTime").cast("string"))
|
||||
.withColumn("value", col("measureValue").cast("double"))
|
||||
.withColumn("grouping", struct("deviceId"))
|
||||
.mlTransform(detector)
|
||||
).cache()
|
||||
|
||||
df_anomaly.createOrReplaceTempView("df_anomaly")
|
||||
```
|
||||
|
||||
Let's take a look at the data:
|
||||
|
||||
|
||||
```
|
||||
df_anomaly.select("timestamp", "value", "deviceId", "anomalies.isAnomaly").show(3)
|
||||
```
|
||||
|
||||
This cell should yield a result that looks like:
|
||||
|
||||
| timestamp | value | deviceId | isAnomaly |
|
||||
|:--------------------|--------:|:-----------|:------------|
|
||||
| 2020-05-01 18:33:51 | 3174 | dev-7 | False |
|
||||
| 2020-05-01 18:33:52 | 2976 | dev-7 | False |
|
||||
| 2020-05-01 18:33:53 | 2714 | dev-7 | False |
|
||||
|
||||
## Visualize anomalies for one of the devices
|
||||
|
||||
IoTSignals.csv has signals from multiple IoT devices. We'll focus on a specific device and visualize anomalous outputs from the device.
|
||||
|
||||
|
||||
```
|
||||
df_anomaly_single_device = spark.sql(
|
||||
"""
|
||||
select
|
||||
timestamp,
|
||||
measureValue,
|
||||
anomalies.expectedValue,
|
||||
anomalies.expectedValue + anomalies.upperMargin as expectedUpperValue,
|
||||
anomalies.expectedValue - anomalies.lowerMargin as expectedLowerValue,
|
||||
case when anomalies.isAnomaly=true then 1 else 0 end as isAnomaly
|
||||
from
|
||||
df_anomaly
|
||||
where deviceid = 'dev-1' and timestamp < '2020-04-29'
|
||||
order by timestamp
|
||||
limit 200"""
|
||||
)
|
||||
```
|
||||
|
||||
Now that we have created a dataframe that represents the anomalies for a particular device, we can visualize these anomalies:
|
||||
|
||||
|
||||
```
|
||||
import matplotlib.pyplot as plt
|
||||
from pyspark.sql.functions import col
|
||||
|
||||
adf = df_anomaly_single_device.toPandas()
|
||||
adf_subset = df_anomaly_single_device.where(col("isAnomaly") == 1).toPandas()
|
||||
|
||||
plt.figure(figsize=(23, 8))
|
||||
plt.plot(
|
||||
adf["timestamp"],
|
||||
adf["expectedUpperValue"],
|
||||
color="darkred",
|
||||
line,
|
||||
linewidth=0.25,
|
||||
label="UpperMargin",
|
||||
)
|
||||
plt.plot(
|
||||
adf["timestamp"],
|
||||
adf["expectedValue"],
|
||||
color="darkgreen",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="Expected Value",
|
||||
)
|
||||
plt.plot(
|
||||
adf["timestamp"],
|
||||
adf["measureValue"],
|
||||
"b",
|
||||
color="royalblue",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="Actual",
|
||||
)
|
||||
plt.plot(
|
||||
adf["timestamp"],
|
||||
adf["expectedLowerValue"],
|
||||
color="black",
|
||||
line,
|
||||
linewidth=0.25,
|
||||
label="Lower Margin",
|
||||
)
|
||||
plt.plot(adf_subset["timestamp"], adf_subset["measureValue"], "ro", label="Anomaly")
|
||||
plt.legend()
|
||||
plt.title("RPM Anomalies with Confidence Intervals")
|
||||
plt.show()
|
||||
```
|
||||
|
||||
If successful, your output will look like this:
|
||||
|
||||

|
||||
|
||||
## Next steps
|
||||
|
||||
Learn how to do predictive maintenance at scale with Azure Cognitive Services, Azure Synapse Analytics, and Azure CosmosDB. For more information, see the full sample on [GitHub](https://github.com/Azure-Samples/cosmosdb-synapse-link-samples).
|
||||
|
|
@ -0,0 +1,199 @@
|
|||
---
|
||||
title: GeospatialServices - Flooding Risk
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Visualizing Customer addresses on a flood plane
|
||||
|
||||
King County (WA) publishes flood plain data as well as tax parcel data. We can use the addresses in the tax parcel data and use the geocoder to calculate coordinates. Using this coordinates and the flood plain data we can enrich out dataset with a flag indicating whether the house is in a flood zone or not.
|
||||
|
||||
The following data has been sourced from King County's Open data portal. [_Link_](https://data.kingcounty.gov/)
|
||||
1. [Address Data](https://mmlspark.blob.core.windows.net/publicwasb/maps/KingCountyAddress.csv)
|
||||
1. [Flood plains](https://mmlspark.blob.core.windows.net/publicwasb/maps/KingCountyFloodPlains.geojson)
|
||||
|
||||
For this demonstration, please follow the instructions on setting up your azure maps account from the overview notebook.
|
||||
|
||||
## Prerequisites
|
||||
1. Upload the flood plains data as map data to your creator resource
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
import json
|
||||
import time
|
||||
import requests
|
||||
from requests.adapters import HTTPAdapter
|
||||
from requests.packages.urllib3.util.retry import Retry
|
||||
|
||||
# Configure more resiliant requests to stop flakiness
|
||||
retry_strategy = Retry(
|
||||
total=3,
|
||||
status_forcelist=[429, 500, 502, 503, 504],
|
||||
allowed_methods=["HEAD", "GET", "PUT", "DELETE", "OPTIONS", "TRACE"],
|
||||
)
|
||||
adapter = HTTPAdapter(max_retries=retry_strategy)
|
||||
http = requests.Session()
|
||||
http.mount("https://", adapter)
|
||||
http.mount("http://", adapter)
|
||||
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Azure Maps account key
|
||||
maps_key = find_secret("azuremaps-api-key") # Replace this with your azure maps key
|
||||
|
||||
# Creator Geo prefix
|
||||
# for this example, assuming that the creator resource is created in `EAST US 2`.
|
||||
atlas_geo_prefix = "us"
|
||||
|
||||
# Load flood plains data
|
||||
flood_plain_geojson = http.get(
|
||||
"https://mmlspark.blob.core.windows.net/publicwasb/maps/KingCountyFloodPlains.geojson"
|
||||
).content
|
||||
|
||||
# Upload this flood plains data to your maps/creator account. This is a Long-Running async operation and takes approximately 15~30 seconds to complete
|
||||
r = http.post(
|
||||
f"https://{atlas_geo_prefix}.atlas.microsoft.com/mapData/upload?api-version=1.0&dataFormat=geojson&subscription-key={maps_key}",
|
||||
json=json.loads(flood_plain_geojson),
|
||||
)
|
||||
|
||||
# Poll for resource upload completion
|
||||
resource_location = r.headers.get("location")
|
||||
for _ in range(20):
|
||||
resource = json.loads(
|
||||
http.get(f"{resource_location}&subscription-key={maps_key}").content
|
||||
)
|
||||
status = resource["status"].lower()
|
||||
if status == "running":
|
||||
time.sleep(5) # wait in a polling loop
|
||||
elif status == "succeeded":
|
||||
break
|
||||
else:
|
||||
raise ValueError("Unknown status {}".format(status))
|
||||
|
||||
# Once the above operation returns a HTTP 201, get the user_data_id of the flood plains data, you uploaded to your map account.
|
||||
user_data_id_resource_url = resource["resourceLocation"]
|
||||
user_data_id = json.loads(
|
||||
http.get(f"{user_data_id_resource_url}&subscription-key={maps_key}").content
|
||||
)["udid"]
|
||||
```
|
||||
|
||||
Now that we have the flood plains data setup in our maps account, we can use the `CheckPointInPolygon` function to check if a location `(lat,lon)` coordinate is in a flood zone.
|
||||
|
||||
### Load address data:
|
||||
|
||||
|
||||
```python
|
||||
data = spark.read.option("header", "true").csv(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/maps/KingCountyAddress.csv"
|
||||
)
|
||||
|
||||
# Visualize incoming schema
|
||||
print("Schema:")
|
||||
data.printSchema()
|
||||
|
||||
# Choose a subset of the data for this example
|
||||
subset_data = data.limit(50)
|
||||
display(subset_data)
|
||||
```
|
||||
|
||||
### Wire-up the Address Geocoder
|
||||
|
||||
We will use the address geocoder to enrich the dataset with location coordinates of the addresses.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import col
|
||||
from synapse.ml.cognitive import *
|
||||
from synapse.ml.stages import FixedMiniBatchTransformer, FlattenBatch
|
||||
from synapse.ml.geospatial import *
|
||||
|
||||
|
||||
def extract_location_fields(df):
|
||||
# Use this function to select only lat/lon columns into the dataframe
|
||||
return df.select(
|
||||
col("*"),
|
||||
col("output.response.results")
|
||||
.getItem(0)
|
||||
.getField("position")
|
||||
.getField("lat")
|
||||
.alias("Latitude"),
|
||||
col("output.response.results")
|
||||
.getItem(0)
|
||||
.getField("position")
|
||||
.getField("lon")
|
||||
.alias("Longitude"),
|
||||
).drop("output")
|
||||
|
||||
|
||||
# Azure Maps geocoder to enhance the dataframe with location data
|
||||
geocoder = (
|
||||
AddressGeocoder()
|
||||
.setSubscriptionKey(maps_key)
|
||||
.setAddressCol("FullAddress")
|
||||
.setOutputCol("output")
|
||||
)
|
||||
|
||||
# Set up a fixed mini batch transformer to geocode addresses
|
||||
batched_dataframe = geocoder.transform(
|
||||
FixedMiniBatchTransformer().setBatchSize(10).transform(subset_data.coalesce(1))
|
||||
)
|
||||
geocoded_addresses = extract_location_fields(
|
||||
FlattenBatch().transform(batched_dataframe)
|
||||
)
|
||||
|
||||
# Display the results
|
||||
display(geocoded_addresses)
|
||||
```
|
||||
|
||||
Now that we have geocoded the addresses, we can now use the `CheckPointInPolygon` function to check if a property is in a flood zone or not.
|
||||
|
||||
### Setup Check Point In Polygon
|
||||
|
||||
|
||||
```python
|
||||
def extract_point_in_polygon_result_fields(df):
|
||||
# Use this function to select only lat/lon columns into the dataframe
|
||||
return df.select(
|
||||
col("*"),
|
||||
col("output.result.pointInPolygons").alias("In Polygon"),
|
||||
col("output.result.intersectingGeometries").alias("Intersecting Polygons"),
|
||||
).drop("output")
|
||||
|
||||
|
||||
check_point_in_polygon = (
|
||||
CheckPointInPolygon()
|
||||
.setSubscriptionKey(maps_key)
|
||||
.setGeography(atlas_geo_prefix)
|
||||
.setUserDataIdentifier(user_data_id)
|
||||
.setLatitudeCol("Latitude")
|
||||
.setLongitudeCol("Longitude")
|
||||
.setOutputCol("output")
|
||||
)
|
||||
|
||||
|
||||
flood_plain_addresses = extract_point_in_polygon_result_fields(
|
||||
check_point_in_polygon.transform(geocoded_addresses)
|
||||
)
|
||||
|
||||
# Display the results
|
||||
display(flood_plain_addresses)
|
||||
```
|
||||
|
||||
### Cleanup Uploaded User Data (Optional)
|
||||
You can (optionally) delete the uploaded geojson polygon.
|
||||
|
||||
|
||||
```python
|
||||
res = http.delete(
|
||||
f"https://{atlas_geo_prefix}.atlas.microsoft.com/mapData/{user_data_id}?api-version=1.0&subscription-key={maps_key}"
|
||||
)
|
||||
```
|
||||
|
|
@ -0,0 +1,290 @@
|
|||
---
|
||||
title: GeospatialServices - Overview
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
<img width="500" src="https://azurecomcdn.azureedge.net/cvt-18f087887a905ed3ae5310bee894aa53fc03cfffadc5dc9902bfe3469d832fec/less/images/section/azure-maps.png" />
|
||||
|
||||
# Azure Maps Geospatial Services
|
||||
|
||||
[Microsoft Azure Maps ](https://azure.microsoft.com/en-us/services/azure-maps/) provides developers from all industries with powerful geospatial capabilities. Those geospatial capabilities are packed with the freshest mapping data. Azure Maps is available for web, mobile (iOS and Android), Microsoft Power BI, Microsoft Power Apps and Microsoft Synapse. Azure Maps is an Open API compliant set of REST APIs. The following are only a high-level overview of the services which Azure Maps offers - Maps, Search, Routing, Traffic, Weather, Time Zones, Geolocation, Geofencing, Map Data, Creator, and Spatial Operations.
|
||||
|
||||
## Usage
|
||||
|
||||
### Geocode addresses
|
||||
[**Address Geocoding**](https://docs.microsoft.com/en-us/rest/api/maps/search/post-search-address-batch) The Search Address Batch API sends batches of queries to Search Address API using just a single API call. This API geocodes text addresses or partial addresses and the geocoding search index will be queried for everything above the street level data. **Note** that the geocoder is very tolerant of typos and incomplete addresses. It will also handle everything from exact street addresses or street or intersections as well as higher level geographies such as city centers, counties, states etc.
|
||||
|
||||
### Reverse Geocode Coordinates
|
||||
[**Reverse Geocoding**](https://docs.microsoft.com/en-us/rest/api/maps/search/post-search-address-reverse-batch) The Search Address Reverse Batch API sends batches of queries to Search Address Reverse API using just a single API call. This API takes in location coordinates and translates them into human readable street addresses. Most often this is needed in tracking applications where you receive a GPS feed from the device or asset and wish to know what address where the coordinate is located.
|
||||
|
||||
### Get Point In Polygon
|
||||
[**Get Point in Polygon**](https://docs.microsoft.com/en-us/rest/api/maps/spatial/get-point-in-polygon) This API returns a boolean value indicating whether a point is inside a set of polygons. The set of polygons can we pre-created by using the [**Data Upload API**](https://docs.microsoft.com/en-us/rest/api/maps/data/upload-preview) referenced by a unique udid.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Sign into the [Azure Portal](https://portal.azure.com) and create an Azure Maps account by following these [instructions](https://docs.microsoft.com/en-us/azure/azure-maps/how-to-manage-account-keys#create-a-new-account).
|
||||
1. Once the Maps account is created, provision a Maps Creator Resource by following these [instructions](https://docs.microsoft.com/en-us/azure/azure-maps/how-to-manage-creator#create-creator-resource). Creator is a [geographically scoped service](https://docs.microsoft.com/en-us/azure/azure-maps/creator-geographic-scope). Pick appropriate location while provisioning the creator resource.
|
||||
1. Follow these [instructions](https://docs.microsoft.com/en-us/azure/cognitive-services/big-data/getting-started#create-an-apache-spark-cluster) to set up your Azure Databricks environment and install SynapseML.
|
||||
1. After you create a new notebook in Azure Databricks, copy the **Shared code** below and paste into a new cell in your notebook.
|
||||
1. Choose a service sample, below, and copy paste it into a second new cell in your notebook.
|
||||
1. Replace the `AZUREMAPS_API_KEY` placeholders with your own [Maps account key](https://docs.microsoft.com/en-us/azure/azure-maps/how-to-manage-authentication#view-authentication-details).
|
||||
1. Choose the run button (triangle icon) in the upper right corner of the cell, then select **Run Cell**.
|
||||
1. View results in a table below the cell.
|
||||
|
||||
## Shared code
|
||||
|
||||
To get started, we'll need to add this code to the project:
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import udf, col
|
||||
from pyspark.sql.types import StructType, StructField, DoubleType
|
||||
from pyspark.sql.functions import lit
|
||||
from pyspark.ml import PipelineModel
|
||||
from pyspark.sql.functions import col
|
||||
import os
|
||||
import requests
|
||||
from requests.adapters import HTTPAdapter
|
||||
from requests.packages.urllib3.util.retry import Retry
|
||||
|
||||
# Configure more resiliant requests to stop flakiness
|
||||
retry_strategy = Retry(
|
||||
total=3,
|
||||
status_forcelist=[429, 500, 502, 503, 504],
|
||||
allowed_methods=["HEAD", "GET", "PUT", "DELETE", "OPTIONS", "TRACE"],
|
||||
)
|
||||
adapter = HTTPAdapter(max_retries=retry_strategy)
|
||||
http = requests.Session()
|
||||
http.mount("https://", adapter)
|
||||
http.mount("http://", adapter)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.cognitive import *
|
||||
from synapse.ml.geospatial import *
|
||||
|
||||
# An Azure Maps account key
|
||||
maps_key = find_secret("azuremaps-api-key")
|
||||
```
|
||||
|
||||
## Geocoding sample
|
||||
|
||||
The azure maps geocoder sends batches of queries to the [Search Address API](https://docs.microsoft.com/en-us/rest/api/maps/search/getsearchaddress). The API limits the batch size to 10000 queries per request.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.stages import FixedMiniBatchTransformer, FlattenBatch
|
||||
|
||||
df = spark.createDataFrame(
|
||||
[
|
||||
("One, Microsoft Way, Redmond",),
|
||||
("400 Broad St, Seattle",),
|
||||
("350 5th Ave, New York",),
|
||||
("Pike Pl, Seattle",),
|
||||
("Champ de Mars, 5 Avenue Anatole France, 75007 Paris",),
|
||||
],
|
||||
[
|
||||
"address",
|
||||
],
|
||||
)
|
||||
|
||||
|
||||
def extract_location_fields(df):
|
||||
# Use this function to select only lat/lon columns into the dataframe
|
||||
return df.select(
|
||||
col("*"),
|
||||
col("output.response.results")
|
||||
.getItem(0)
|
||||
.getField("position")
|
||||
.getField("lat")
|
||||
.alias("Latitude"),
|
||||
col("output.response.results")
|
||||
.getItem(0)
|
||||
.getField("position")
|
||||
.getField("lon")
|
||||
.alias("Longitude"),
|
||||
).drop("output")
|
||||
|
||||
|
||||
# Run the Azure Maps geocoder to enhance the data with location data
|
||||
geocoder = (
|
||||
AddressGeocoder()
|
||||
.setSubscriptionKey(maps_key)
|
||||
.setAddressCol("address")
|
||||
.setOutputCol("output")
|
||||
)
|
||||
|
||||
# Show the results of your text query in a table format
|
||||
display(
|
||||
extract_location_fields(
|
||||
geocoder.transform(FixedMiniBatchTransformer().setBatchSize(10).transform(df))
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
## Reverse Geocoding sample
|
||||
|
||||
The azure maps reverse geocoder sends batches of queries to the [Search Address Reverse API](https://docs.microsoft.com/en-us/rest/api/maps/search/get-search-address-reverse) using just a single API call. The API allows caller to batch up to 10,000 queries per request
|
||||
|
||||
|
||||
```python
|
||||
# Create a dataframe that's tied to it's column names
|
||||
df = spark.createDataFrame(
|
||||
(
|
||||
(
|
||||
(48.858561, 2.294911),
|
||||
(47.639765, -122.127896),
|
||||
(47.621028, -122.348170),
|
||||
(47.734012, -122.102737),
|
||||
)
|
||||
),
|
||||
StructType([StructField("lat", DoubleType()), StructField("lon", DoubleType())]),
|
||||
)
|
||||
|
||||
# Run the Azure Maps geocoder to enhance the data with location data
|
||||
rev_geocoder = (
|
||||
ReverseAddressGeocoder()
|
||||
.setSubscriptionKey(maps_key)
|
||||
.setLatitudeCol("lat")
|
||||
.setLongitudeCol("lon")
|
||||
.setOutputCol("output")
|
||||
)
|
||||
|
||||
# Show the results of your text query in a table format
|
||||
|
||||
display(
|
||||
rev_geocoder.transform(FixedMiniBatchTransformer().setBatchSize(10).transform(df))
|
||||
.select(
|
||||
col("*"),
|
||||
col("output.response.addresses")
|
||||
.getItem(0)
|
||||
.getField("address")
|
||||
.getField("freeformAddress")
|
||||
.alias("In Polygon"),
|
||||
col("output.response.addresses")
|
||||
.getItem(0)
|
||||
.getField("address")
|
||||
.getField("country")
|
||||
.alias("Intersecting Polygons"),
|
||||
)
|
||||
.drop("output")
|
||||
)
|
||||
```
|
||||
|
||||
## Check Point In Polygon sample
|
||||
|
||||
This API returns a boolean value indicating whether a point is inside a set of polygons. The polygon can be added to your creator account using the [**Data Upload API**](https://docs.microsoft.com/en-us/rest/api/maps/data/upload-preview). The API then returns a unique udid to reference the polygon.
|
||||
|
||||
### Set up geojson Polygons in your azure maps creator account
|
||||
|
||||
Based on where the creator resource was provisioned, we need to prefix the appropriate geography code to the azure maps URL. In this example, the assumption is that the creator resource was provisioned in `East US 2` Location and hence we pick `us` as our geo prefix.
|
||||
|
||||
|
||||
```python
|
||||
import time
|
||||
import json
|
||||
|
||||
# Choose a geography, you want your data to reside in.
|
||||
# Allowed values
|
||||
# us => North American datacenters
|
||||
# eu -> European datacenters
|
||||
url_geo_prefix = "us"
|
||||
|
||||
# Upload a geojson with polygons in them
|
||||
r = http.post(
|
||||
f"https://{url_geo_prefix}.atlas.microsoft.com/mapData/upload?api-version=1.0&dataFormat=geojson&subscription-key={maps_key}",
|
||||
json={
|
||||
"type": "FeatureCollection",
|
||||
"features": [
|
||||
{
|
||||
"type": "Feature",
|
||||
"properties": {"geometryId": "test_geometry"},
|
||||
"geometry": {
|
||||
"type": "Polygon",
|
||||
"coordinates": [
|
||||
[
|
||||
[-122.14290618896484, 47.67856488312544],
|
||||
[-122.03956604003906, 47.67856488312544],
|
||||
[-122.03956604003906, 47.7483271435476],
|
||||
[-122.14290618896484, 47.7483271435476],
|
||||
[-122.14290618896484, 47.67856488312544],
|
||||
]
|
||||
],
|
||||
},
|
||||
}
|
||||
],
|
||||
},
|
||||
)
|
||||
|
||||
long_running_operation = r.headers.get("location")
|
||||
time.sleep(30) # Sometimes this may take upto 30 seconds
|
||||
print(f"Status Code: {r.status_code}, Long Running Operation: {long_running_operation}")
|
||||
# This Operation completes in approximately 5 ~ 15 seconds
|
||||
user_data_id_resource_url = json.loads(
|
||||
http.get(f"{long_running_operation}&subscription-key={maps_key}").content
|
||||
)["resourceLocation"]
|
||||
user_data_id = json.loads(
|
||||
http.get(f"{user_data_id_resource_url}&subscription-key={maps_key}").content
|
||||
)["udid"]
|
||||
```
|
||||
|
||||
### Use the function to check if point is in polygon
|
||||
|
||||
|
||||
```python
|
||||
# Create a dataframe that's tied to it's column names
|
||||
df = spark.createDataFrame(
|
||||
(
|
||||
(
|
||||
(48.858561, 2.294911),
|
||||
(47.639765, -122.127896),
|
||||
(47.621028, -122.348170),
|
||||
(47.734012, -122.102737),
|
||||
)
|
||||
),
|
||||
StructType([StructField("lat", DoubleType()), StructField("lon", DoubleType())]),
|
||||
)
|
||||
|
||||
# Run the Azure Maps geocoder to enhance the data with location data
|
||||
check_point_in_polygon = (
|
||||
CheckPointInPolygon()
|
||||
.setSubscriptionKey(maps_key)
|
||||
.setGeography(url_geo_prefix)
|
||||
.setUserDataIdentifier(user_data_id)
|
||||
.setLatitudeCol("lat")
|
||||
.setLongitudeCol("lon")
|
||||
.setOutputCol("output")
|
||||
)
|
||||
|
||||
# Show the results of your text query in a table format
|
||||
display(
|
||||
check_point_in_polygon.transform(df)
|
||||
.select(
|
||||
col("*"),
|
||||
col("output.result.pointInPolygons").alias("In Polygon"),
|
||||
col("output.result.intersectingGeometries").alias("Intersecting Polygons"),
|
||||
)
|
||||
.drop("output")
|
||||
)
|
||||
```
|
||||
|
||||
### Cleanup
|
||||
|
||||
|
||||
```python
|
||||
res = http.delete(
|
||||
f"https://{url_geo_prefix}.atlas.microsoft.com/mapData/{user_data_id}?api-version=1.0&subscription-key={maps_key}"
|
||||
)
|
||||
```
|
||||
|
|
@ -0,0 +1,346 @@
|
|||
---
|
||||
title: HyperOpt-SynapseML
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Hyperparameter tuning: SynapseML with Hyperopt
|
||||
|
||||
[SynapseML](https://github.com/microsoft/SynapseML) is an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. SynapseML provides simple, composable, and distributed APIs for a wide variety of different machine learning tasks such as text analytics, vision, anomaly detection, and many others.
|
||||
|
||||
[Hyperopt](https://github.com/hyperopt/hyperopt), on the other hand, is a Python library for serial and parallel optimization over complex search spaces, including real-valued, discrete, and conditional dimensions.
|
||||
|
||||
This guide showcases the process of tuning a distributed algorithm in Spark with SynapseML and Hyperopt.
|
||||
|
||||
The use case of this guide is for distributed machine learning in Python that requires hyperparameter tuning. It provides a demo on how to tune hyperparameters for a machine learning workflow in SynapseML and can be used as a reference to tune other distributed machine learning algorithms from Spark MLlib or other libraries.
|
||||
|
||||
The guide includes two sections:
|
||||
* Running distributed training with SynapseML without hyperparameter tuning.
|
||||
* Using Hyperopt to tune hyperparameters in the distributed training workflow.
|
||||
## Prerequisites
|
||||
- If you are running it on Synapse, you'll need to [create an AML workspace and set up linked Service](https://microsoft.github.io/SynapseML/docs/next/mlflow/installation/).
|
||||
|
||||
## Requirements
|
||||
- Install HyperOpt
|
||||
|
||||
|
||||
```python
|
||||
# %pip install hyperopt
|
||||
import os
|
||||
|
||||
os.system("pip install hyperopt")
|
||||
```
|
||||
|
||||
## MLflow autologging
|
||||
|
||||
To track model training and tuning with MLflow, you could enable MLflow autologging by running `mlflow.pyspark.ml.autolog()`.
|
||||
|
||||
|
||||
```python
|
||||
# version >= 1.28.0 supports reading logModelAllowlistFile from url
|
||||
# %pip install mlflow==1.29.0
|
||||
os.system("pip install mlflow==1.29.0")
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.core.platform import *
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
if running_on_synapse_internal():
|
||||
experiment_name = "hyperopt-synapseml"
|
||||
elif running_on_synapse():
|
||||
experiment_name = "hyperopt-synapseml"
|
||||
# from notebookutils.visualization import display # use this display on interactive notebook
|
||||
from synapse.ml.core.platform import (
|
||||
materializing_display as display,
|
||||
) # display for pipeline testing
|
||||
else:
|
||||
experiment_name = "/Shared/hyperopt-synapseml"
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
import mlflow
|
||||
|
||||
mlflow.__version__
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Set pyspark autologging logModelAllowlist to include SynapseML models
|
||||
spark.sparkContext._conf.set(
|
||||
"spark.mlflow.pysparkml.autolog.logModelAllowlistFile",
|
||||
"https://mmlspark.blob.core.windows.net/publicwasb/log_model_allowlist.txt",
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# enable autologging
|
||||
mlflow.pyspark.ml.autolog()
|
||||
```
|
||||
|
||||
### Set experiment name for tracking
|
||||
|
||||
|
||||
```python
|
||||
# Set MLflow experiment.
|
||||
|
||||
if running_on_synapse():
|
||||
from notebookutils.mssparkutils import azureML
|
||||
|
||||
linked_service = "AzureMLService1" # use your linked service name
|
||||
ws = azureML.getWorkspace(linked_service)
|
||||
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
|
||||
mlflow.set_experiment(experiment_name)
|
||||
```
|
||||
|
||||
## Part 1. Run distributed training using MLlib
|
||||
|
||||
This section shows a simple example of distributed training using SynapseML. For more information and examples, visit the official [website](https://microsoft.github.io/SynapseML/)
|
||||
|
||||
## Prepare Dataset
|
||||
We use [*California Housing* dataset](https://scikit-learn.org/stable/datasets/real_world.html#california-housing-dataset).
|
||||
The data was derived from the 1990 U.S. census. It consists of 20640 entries with 8 features.
|
||||
We use `sklearn.datasets` module to download it easily, then split the set into training and testing by 75/25.
|
||||
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
from sklearn.datasets import fetch_california_housing
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
california = fetch_california_housing()
|
||||
|
||||
feature_cols = ["f" + str(i) for i in range(california.data.shape[1])]
|
||||
header = ["target"] + feature_cols
|
||||
df = spark.createDataFrame(
|
||||
pd.DataFrame(
|
||||
data=np.column_stack((california.target, california.data)), columns=header
|
||||
)
|
||||
).repartition(1)
|
||||
|
||||
print("Dataframe has {} rows".format(df.count()))
|
||||
display(df)
|
||||
```
|
||||
|
||||
Following is the summary of the data set.
|
||||
|
||||
|
||||
```python
|
||||
display(df.summary().toPandas())
|
||||
```
|
||||
|
||||
### Create a function to train a model
|
||||
|
||||
In this section, you define a function to train a gradient boosting model with SynapseML LightgbmRegressor. Wrapping the training code in a function is important for passing the function to Hyperopt for tuning later.
|
||||
|
||||
We evaluate the prediction result by using `synapse.ml.train.ComputeModelStatistics` which returns four metrics:
|
||||
* [MSE (Mean Squared Error)](https://en.wikipedia.org/wiki/Mean_squared_error)
|
||||
* [RMSE (Root Mean Squared Error)](https://en.wikipedia.org/wiki/Root-mean-square_deviation) = sqrt(MSE)
|
||||
* [R Squared](https://en.wikipedia.org/wiki/Coefficient_of_determination)
|
||||
* [MAE (Mean Absolute Error)](https://en.wikipedia.org/wiki/Mean_absolute_error)
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml.feature import VectorAssembler
|
||||
|
||||
# Convert features into a single vector column
|
||||
featurizer = VectorAssembler(inputCols=feature_cols, outputCol="features")
|
||||
data = featurizer.transform(df)["target", "features"]
|
||||
|
||||
train_data, test_data = data.randomSplit([0.75, 0.25], seed=42)
|
||||
train_data, validation_data = train_data.randomSplit([0.85, 0.15], seed=42)
|
||||
|
||||
display(train_data)
|
||||
|
||||
# Using one partition since the training dataset is very small
|
||||
repartitioned_data = train_data.repartition(1).cache()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMRegressor
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
|
||||
|
||||
def train_tree(alpha, learningRate, numLeaves, numIterations):
|
||||
"""
|
||||
This train() function:
|
||||
- takes hyperparameters as inputs (for tuning later)
|
||||
- returns the F1 score on the validation dataset
|
||||
|
||||
Wrapping code as a function makes it easier to reuse the code later with Hyperopt.
|
||||
"""
|
||||
# Use MLflow to track training.
|
||||
# Specify "nested=True" since this single model will be logged as a child run of Hyperopt's run.
|
||||
with mlflow.start_run(nested=True):
|
||||
|
||||
lgr = LightGBMRegressor(
|
||||
objective="quantile",
|
||||
alpha=alpha,
|
||||
learningRate=learningRate,
|
||||
numLeaves=numLeaves,
|
||||
labelCol="target",
|
||||
numIterations=numIterations,
|
||||
)
|
||||
|
||||
model = lgr.fit(repartitioned_data)
|
||||
|
||||
cms = ComputeModelStatistics(
|
||||
evaluationMetric="regression", labelCol="target", scoresCol="prediction"
|
||||
)
|
||||
|
||||
# Define an evaluation metric and evaluate the model on the test dataset.
|
||||
predictions = model.transform(test_data)
|
||||
metrics = cms.transform(predictions).collect()[0].asDict()
|
||||
|
||||
# log metrics with mlflow
|
||||
mlflow.log_metric("MSE", metrics["mean_squared_error"])
|
||||
mlflow.log_metric("RMSE", metrics["root_mean_squared_error"])
|
||||
mlflow.log_metric("R^2", metrics["R^2"])
|
||||
mlflow.log_metric("MAE", metrics["mean_absolute_error"])
|
||||
|
||||
return model, metrics["R^2"]
|
||||
```
|
||||
|
||||
Run the training function to make sure it works.
|
||||
It's a good idea to make sure training code runs before adding in tuning.
|
||||
|
||||
|
||||
```python
|
||||
initial_model, val_metric = train_tree(
|
||||
alpha=0.2, learningRate=0.3, numLeaves=31, numIterations=100
|
||||
)
|
||||
print(
|
||||
f"The trained decision tree achieved a R^2 of {val_metric} on the validation data"
|
||||
)
|
||||
```
|
||||
|
||||
## Part 2. Use Hyperopt to tune hyperparameters
|
||||
|
||||
In the second section, the Hyperopt workflow is created by:
|
||||
* Define a function to minimize
|
||||
* Define a search space over hyperparameters
|
||||
* Specifying the search algorithm and using `fmin()` for tuning the model.
|
||||
|
||||
For more information about the Hyperopt APIs, see the [Hyperopt documentation](http://hyperopt.github.io/hyperopt/).
|
||||
|
||||
### Define a function to minimize
|
||||
|
||||
* Input: hyperparameters
|
||||
* Internally: Reuse the training function defined above.
|
||||
* Output: loss
|
||||
|
||||
|
||||
```python
|
||||
from hyperopt import fmin, tpe, hp, Trials, STATUS_OK
|
||||
|
||||
|
||||
def train_with_hyperopt(params):
|
||||
"""
|
||||
An example train method that calls into MLlib.
|
||||
This method is passed to hyperopt.fmin().
|
||||
|
||||
:param params: hyperparameters as a dict. Its structure is consistent with how search space is defined. See below.
|
||||
:return: dict with fields 'loss' (scalar loss) and 'status' (success/failure status of run)
|
||||
"""
|
||||
# For integer parameters, make sure to convert them to int type if Hyperopt is searching over a continuous range of values.
|
||||
alpha = params["alpha"]
|
||||
learningRate = params["learningRate"]
|
||||
numLeaves = int(params["numLeaves"])
|
||||
numIterations = int(params["numIterations"])
|
||||
|
||||
model, r_squared = train_tree(alpha, learningRate, numLeaves, numIterations)
|
||||
|
||||
# Hyperopt expects you to return a loss (for which lower is better), so take the negative of the R^2 (for which higher is better).
|
||||
loss = -r_squared
|
||||
|
||||
return {"loss": loss, "status": STATUS_OK}
|
||||
```
|
||||
|
||||
### Define the search space over hyperparameters
|
||||
|
||||
This example tunes four hyperparameters: `alpha`, `learningRate`, `numLeaves` and `numIterations`. See the [Hyperopt documentation](https://github.com/hyperopt/hyperopt/wiki/FMin#21-parameter-expressions) for details on defining a search space and parameter expressions.
|
||||
|
||||
|
||||
```python
|
||||
space = {
|
||||
"alpha": hp.uniform("alpha", 0, 1),
|
||||
"learningRate": hp.uniform("learningRate", 0, 1),
|
||||
"numLeaves": hp.uniformint("numLeaves", 30, 50),
|
||||
"numIterations": hp.uniformint("numIterations", 100, 300),
|
||||
}
|
||||
```
|
||||
|
||||
### Tune the model using Hyperopt `fmin()`
|
||||
|
||||
For tuning the model with Hyperopt's `fmin()`, the following steps are taken:
|
||||
- Setting `max_evals` to the maximum number of points in the hyperparameter space to be tested.
|
||||
- Specifying the search algorithm, either `hyperopt.tpe.suggest` or `hyperopt.rand.suggest`.
|
||||
- `hyperopt.tpe.suggest`: Tree of Parzen Estimators, a Bayesian approach which iteratively and adaptively selects new hyperparameter settings to explore based on previous results
|
||||
- `hyperopt.rand.suggest`: Random search, a non-adaptive approach that randomly samples the search space
|
||||
|
||||
**Important:**
|
||||
When using Hyperopt with SynapseML and other distributed training algorithms, do not pass a `trials` argument to `fmin()`. When you do not include the `trials` argument, Hyperopt uses the default `Trials` class, which runs on the cluster driver. Hyperopt needs to evaluate each trial on the driver node so that each trial can initiate distributed training jobs.
|
||||
|
||||
Do not use the `SparkTrials` class with SynapseML. `SparkTrials` is designed to distribute trials for algorithms that are not themselves distributed. SynapseML uses distributed computing already and is not compatible with `SparkTrials`.
|
||||
|
||||
|
||||
```python
|
||||
algo = tpe.suggest
|
||||
|
||||
with mlflow.start_run():
|
||||
best_params = fmin(fn=train_with_hyperopt, space=space, algo=algo, max_evals=8)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Print out the parameters that produced the best model
|
||||
best_params
|
||||
```
|
||||
|
||||
### Retrain the model on the full training dataset
|
||||
|
||||
For tuning, this workflow split the training dataset into training and validation subsets. Now, retrain the model using the "best" hyperparameters on the full training dataset.
|
||||
|
||||
|
||||
```python
|
||||
best_alpha = best_params["alpha"]
|
||||
best_learningRate = best_params["learningRate"]
|
||||
best_numIterations = int(best_params["numIterations"])
|
||||
best_numLeaves = int(best_params["numLeaves"])
|
||||
|
||||
final_model, val_r_squared = train_tree(
|
||||
best_alpha, best_learningRate, best_numIterations, best_numLeaves
|
||||
)
|
||||
```
|
||||
|
||||
Use the test dataset to compare evaluation metrics for the initial and "best" models.
|
||||
|
||||
|
||||
```python
|
||||
# Define an evaluation metric and evaluate the model on the test dataset.
|
||||
cms = ComputeModelStatistics(
|
||||
evaluationMetric="regression", labelCol="target", scoresCol="prediction"
|
||||
)
|
||||
|
||||
initial_model_predictions = initial_model.transform(test_data)
|
||||
initial_model_test_metric = (
|
||||
cms.transform(initial_model_predictions).collect()[0].asDict()["R^2"]
|
||||
)
|
||||
|
||||
final_model_predictions = final_model.transform(test_data)
|
||||
final_model_test_metric = (
|
||||
cms.transform(final_model_predictions).collect()[0].asDict()["R^2"]
|
||||
)
|
||||
|
||||
print(
|
||||
f"On the test data, the initial (untuned) model achieved R^2 {initial_model_test_metric}, and the final (tuned) model achieved {final_model_test_metric}."
|
||||
)
|
||||
```
|
||||
|
|
@ -0,0 +1,498 @@
|
|||
---
|
||||
title: IsolationForest - Multivariate Anomaly Detection
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Recipe: Multivariate Anomaly Detection with Isolation Forest
|
||||
This recipe shows how you can use SynapseML on Apache Spark for multivariate anomaly detection. Multivariate anomaly detection allows for the detection of anomalies among many variables or time series, taking into account all the inter-correlations and dependencies between the different variables. In this scenario, we use SynapseML to train an Isolation Forest model for multivariate anomaly detection, and we then use to the trained model to infer multivariate anomalies within a dataset containing synthetic measurements from three IoT sensors.
|
||||
|
||||
To learn more about the Isolation Forest model please refer to the original paper by [Liu _et al._](https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf?q=isolation-forest).
|
||||
|
||||
## Prerequisites
|
||||
- If you are running it on Synapse, you'll need to [create an AML workspace and set up linked Service](https://microsoft.github.io/SynapseML/docs/next/mlflow/installation/).
|
||||
|
||||
|
||||
|
||||
```python
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
for package in ["sqlparse", "raiwidgets", "interpret-community"]:
|
||||
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
|
||||
```
|
||||
|
||||
## Library imports
|
||||
|
||||
|
||||
```python
|
||||
import uuid
|
||||
import mlflow
|
||||
|
||||
from pyspark.sql import functions as F
|
||||
from pyspark.sql import SparkSession
|
||||
from pyspark.ml.feature import VectorAssembler
|
||||
from pyspark.sql.types import *
|
||||
from pyspark.ml import Pipeline
|
||||
|
||||
from synapse.ml.isolationforest import *
|
||||
from synapse.ml.explainers import *
|
||||
from synapse.ml.core.platform import *
|
||||
from synapse.ml.isolationforest import *
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# %matplotlib inline
|
||||
```
|
||||
|
||||
## Input data
|
||||
|
||||
|
||||
```python
|
||||
# Table inputs
|
||||
timestampColumn = "timestamp" # str: the name of the timestamp column in the table
|
||||
inputCols = [
|
||||
"sensor_1",
|
||||
"sensor_2",
|
||||
"sensor_3",
|
||||
] # list(str): the names of the input variables
|
||||
|
||||
# Training Start time, and number of days to use for training:
|
||||
trainingStartTime = (
|
||||
"2022-02-24T06:00:00Z" # datetime: datetime for when to start the training
|
||||
)
|
||||
trainingEndTime = (
|
||||
"2022-03-08T23:55:00Z" # datetime: datetime for when to end the training
|
||||
)
|
||||
inferenceStartTime = (
|
||||
"2022-03-09T09:30:00Z" # datetime: datetime for when to start the training
|
||||
)
|
||||
inferenceEndTime = (
|
||||
"2022-03-20T23:55:00Z" # datetime: datetime for when to end the training
|
||||
)
|
||||
|
||||
# Isolation Forest parameters
|
||||
contamination = 0.021
|
||||
num_estimators = 100
|
||||
max_samples = 256
|
||||
max_features = 1.0
|
||||
|
||||
# MLFlow experiment
|
||||
artifact_path = "isolationforest"
|
||||
experiment_name = f"/Shared/isolation_forest_experiment-{str(uuid.uuid1())}/"
|
||||
model_name = f"isolation-forest-model"
|
||||
if running_on_synapse():
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
|
||||
# use regular display when running on interactive notebook
|
||||
# from notebookutils.visualization import display
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
## Read data
|
||||
|
||||
|
||||
```python
|
||||
df = (
|
||||
spark.read.format("csv")
|
||||
.option("header", "true")
|
||||
.load(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/generated_sample_mvad_data.csv"
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
cast columns to appropriate data types
|
||||
|
||||
|
||||
```python
|
||||
df = (
|
||||
df.orderBy(timestampColumn)
|
||||
.withColumn("timestamp", F.date_format(timestampColumn, "yyyy-MM-dd'T'HH:mm:ss'Z'"))
|
||||
.withColumn("sensor_1", F.col("sensor_1").cast(DoubleType()))
|
||||
.withColumn("sensor_2", F.col("sensor_2").cast(DoubleType()))
|
||||
.withColumn("sensor_3", F.col("sensor_3").cast(DoubleType()))
|
||||
.drop("_c5")
|
||||
)
|
||||
|
||||
display(df)
|
||||
```
|
||||
|
||||
## Training data preparation
|
||||
|
||||
|
||||
```python
|
||||
# filter to data with timestamps within the training window
|
||||
df_train = df.filter(
|
||||
(F.col(timestampColumn) >= trainingStartTime)
|
||||
& (F.col(timestampColumn) <= trainingEndTime)
|
||||
)
|
||||
display(df_train.limit(5))
|
||||
```
|
||||
|
||||
## Test data preparation
|
||||
|
||||
|
||||
```python
|
||||
# filter to data with timestamps within the inference window
|
||||
df_test = df.filter(
|
||||
(F.col(timestampColumn) >= inferenceStartTime)
|
||||
& (F.col(timestampColumn) <= inferenceEndTime)
|
||||
)
|
||||
display(df_test.limit(5))
|
||||
```
|
||||
|
||||
## Train Isolation Forest model
|
||||
|
||||
|
||||
```python
|
||||
isolationForest = (
|
||||
IsolationForest()
|
||||
.setNumEstimators(num_estimators)
|
||||
.setBootstrap(False)
|
||||
.setMaxSamples(max_samples)
|
||||
.setMaxFeatures(max_features)
|
||||
.setFeaturesCol("features")
|
||||
.setPredictionCol("predictedLabel")
|
||||
.setScoreCol("outlierScore")
|
||||
.setContamination(contamination)
|
||||
.setContaminationError(0.01 * contamination)
|
||||
.setRandomSeed(1)
|
||||
)
|
||||
```
|
||||
|
||||
Next, we create an ML pipeline to train the Isolation Forest model. We also demonstrate how to create an MLFlow experiment and register the trained model.
|
||||
|
||||
Note that MLFlow model registration is strictly only required if accessing the trained model at a later time. For training the model, and performing inferencing in the same notebook, the model object model is sufficient.
|
||||
|
||||
|
||||
```python
|
||||
if running_on_synapse():
|
||||
from synapse.ml.core.platform import find_secret
|
||||
|
||||
tracking_url = find_secret(
|
||||
"aml-mlflow-tracking-url"
|
||||
) # check link in prerequisites for more information on mlflow tracking url
|
||||
mlflow.set_tracking_uri(tracking_url)
|
||||
experiment_name = f"isolation_forest_experiment"
|
||||
model_name = "isolation-forest"
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
mlflow.set_experiment(experiment_name)
|
||||
with mlflow.start_run():
|
||||
va = VectorAssembler(inputCols=inputCols, outputCol="features")
|
||||
pipeline = Pipeline(stages=[va, isolationForest])
|
||||
model = pipeline.fit(df_train)
|
||||
mlflow.spark.log_model(
|
||||
model, artifact_path=artifact_path, registered_model_name=model_name
|
||||
)
|
||||
```
|
||||
|
||||
## Perform inferencing
|
||||
|
||||
Load the trained Isolation Forest Model
|
||||
|
||||
|
||||
```python
|
||||
# model_version = 1
|
||||
# model_uri = f"models:/{model_name}/{model_version}"
|
||||
# model = mlflow.spark.load_model(model_uri)
|
||||
```
|
||||
|
||||
Perform inferencing
|
||||
|
||||
|
||||
```python
|
||||
df_test_pred = model.transform(df_test)
|
||||
display(df_test_pred.limit(5))
|
||||
```
|
||||
|
||||
## ML interpretability
|
||||
In this section, we use ML interpretability tools to help unpack the contribution of each sensor to the detected anomalies at any point in time.
|
||||
|
||||
|
||||
```python
|
||||
# Here, we create a TabularSHAP explainer, set the input columns to all the features the model takes, specify the model and the target output column
|
||||
# we are trying to explain. In this case, we are trying to explain the "outlierScore" output.
|
||||
shap = TabularSHAP(
|
||||
inputCols=inputCols,
|
||||
outputCol="shapValues",
|
||||
model=model,
|
||||
targetCol="outlierScore",
|
||||
backgroundData=F.broadcast(df_test),
|
||||
)
|
||||
```
|
||||
|
||||
Display the dataframe with `shapValues` column
|
||||
|
||||
|
||||
```python
|
||||
shap_df = shap.transform(df_test_pred)
|
||||
display(shap_df.limit(5))
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Define UDF
|
||||
vec2array = F.udf(lambda vec: vec.toArray().tolist(), ArrayType(FloatType()))
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Here, we extract the SHAP values, the original features and the outlier score column. Then we convert it to a Pandas DataFrame for visualization.
|
||||
# For each observation, the first element in the SHAP values vector is the base value (the mean output of the background dataset),
|
||||
# and each of the following elements represents the SHAP values for each feature
|
||||
shaps = (
|
||||
shap_df.withColumn("shapValues", vec2array(F.col("shapValues").getItem(0)))
|
||||
.select(
|
||||
["shapValues", "outlierScore"] + inputCols + [timestampColumn, "predictedLabel"]
|
||||
)
|
||||
.withColumn("sensor_1_localimp", F.col("shapValues")[1])
|
||||
.withColumn("sensor_2_localimp", F.col("shapValues")[2])
|
||||
.withColumn("sensor_3_localimp", F.col("shapValues")[3])
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
shaps_local = shaps.toPandas()
|
||||
shaps_local
|
||||
```
|
||||
|
||||
Retrieve local feature importances
|
||||
|
||||
|
||||
```python
|
||||
local_importance_values = shaps_local[["shapValues"]]
|
||||
eval_data = shaps_local[inputCols]
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Removing the first element in the list of local importance values (this is the base value or mean output of the background dataset)
|
||||
list_local_importance_values = local_importance_values.values.tolist()
|
||||
converted_importance_values = []
|
||||
bias = []
|
||||
for classarray in list_local_importance_values:
|
||||
for rowarray in classarray:
|
||||
converted_list = rowarray.tolist()
|
||||
bias.append(converted_list[0])
|
||||
# remove the bias from local importance values
|
||||
del converted_list[0]
|
||||
converted_importance_values.append(converted_list)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from interpret_community.adapter import ExplanationAdapter
|
||||
|
||||
adapter = ExplanationAdapter(inputCols, classification=False)
|
||||
global_explanation = adapter.create_global(
|
||||
converted_importance_values, eval_data, expected_values=bias
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# view the global importance values
|
||||
global_explanation.global_importance_values
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# view the local importance values
|
||||
global_explanation.local_importance_values
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Defining a wrapper class with predict method for creating the Explanation Dashboard
|
||||
|
||||
|
||||
class wrapper(object):
|
||||
def __init__(self, model):
|
||||
self.model = model
|
||||
|
||||
def predict(self, data):
|
||||
sparkdata = spark.createDataFrame(data)
|
||||
return (
|
||||
model.transform(sparkdata)
|
||||
.select("outlierScore")
|
||||
.toPandas()
|
||||
.values.flatten()
|
||||
.tolist()
|
||||
)
|
||||
```
|
||||
|
||||
## Visualize results
|
||||
|
||||
Visualize anomaly results and feature contribution scores (derived from local feature importance)
|
||||
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
|
||||
def visualize(rdf):
|
||||
anoms = list(rdf["predictedLabel"] == 1)
|
||||
|
||||
fig = plt.figure(figsize=(26, 12))
|
||||
|
||||
ax = fig.add_subplot(611)
|
||||
ax.title.set_text(f"Multivariate Anomaly Detection Results")
|
||||
ax.plot(
|
||||
rdf[timestampColumn],
|
||||
rdf["sensor_1"],
|
||||
color="tab:orange",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="sensor_1",
|
||||
)
|
||||
ax.grid(axis="y")
|
||||
_, _, ymin, ymax = plt.axis()
|
||||
ax.vlines(
|
||||
rdf[timestampColumn][anoms],
|
||||
ymin=ymin,
|
||||
ymax=ymax,
|
||||
color="tab:red",
|
||||
alpha=0.2,
|
||||
linewidth=6,
|
||||
)
|
||||
ax.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
|
||||
ax.set_ylabel("sensor1_value")
|
||||
ax.legend()
|
||||
|
||||
ax = fig.add_subplot(612, sharex=ax)
|
||||
ax.plot(
|
||||
rdf[timestampColumn],
|
||||
rdf["sensor_2"],
|
||||
color="tab:green",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="sensor_2",
|
||||
)
|
||||
ax.grid(axis="y")
|
||||
_, _, ymin, ymax = plt.axis()
|
||||
ax.vlines(
|
||||
rdf[timestampColumn][anoms],
|
||||
ymin=ymin,
|
||||
ymax=ymax,
|
||||
color="tab:red",
|
||||
alpha=0.2,
|
||||
linewidth=6,
|
||||
)
|
||||
ax.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
|
||||
ax.set_ylabel("sensor2_value")
|
||||
ax.legend()
|
||||
|
||||
ax = fig.add_subplot(613, sharex=ax)
|
||||
ax.plot(
|
||||
rdf[timestampColumn],
|
||||
rdf["sensor_3"],
|
||||
color="tab:purple",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="sensor_3",
|
||||
)
|
||||
ax.grid(axis="y")
|
||||
_, _, ymin, ymax = plt.axis()
|
||||
ax.vlines(
|
||||
rdf[timestampColumn][anoms],
|
||||
ymin=ymin,
|
||||
ymax=ymax,
|
||||
color="tab:red",
|
||||
alpha=0.2,
|
||||
linewidth=6,
|
||||
)
|
||||
ax.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
|
||||
ax.set_ylabel("sensor3_value")
|
||||
ax.legend()
|
||||
|
||||
ax = fig.add_subplot(614, sharex=ax)
|
||||
ax.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
|
||||
ax.plot(
|
||||
rdf[timestampColumn],
|
||||
rdf["outlierScore"],
|
||||
color="black",
|
||||
line,
|
||||
linewidth=2,
|
||||
label="Outlier score",
|
||||
)
|
||||
ax.set_ylabel("outlier score")
|
||||
ax.grid(axis="y")
|
||||
ax.legend()
|
||||
|
||||
ax = fig.add_subplot(615, sharex=ax)
|
||||
ax.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
|
||||
ax.bar(
|
||||
rdf[timestampColumn],
|
||||
rdf["sensor_1_localimp"].abs(),
|
||||
width=2,
|
||||
color="tab:orange",
|
||||
label="sensor_1",
|
||||
)
|
||||
ax.bar(
|
||||
rdf[timestampColumn],
|
||||
rdf["sensor_2_localimp"].abs(),
|
||||
width=2,
|
||||
color="tab:green",
|
||||
label="sensor_2",
|
||||
bottom=rdf["sensor_1_localimp"].abs(),
|
||||
)
|
||||
ax.bar(
|
||||
rdf[timestampColumn],
|
||||
rdf["sensor_3_localimp"].abs(),
|
||||
width=2,
|
||||
color="tab:purple",
|
||||
label="sensor_3",
|
||||
bottom=rdf["sensor_1_localimp"].abs() + rdf["sensor_2_localimp"].abs(),
|
||||
)
|
||||
ax.set_ylabel("Contribution scores")
|
||||
ax.grid(axis="y")
|
||||
ax.legend()
|
||||
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
visualize(shaps_local)
|
||||
```
|
||||
|
||||
When you run the cell above, you will see the following plots:
|
||||
|
||||
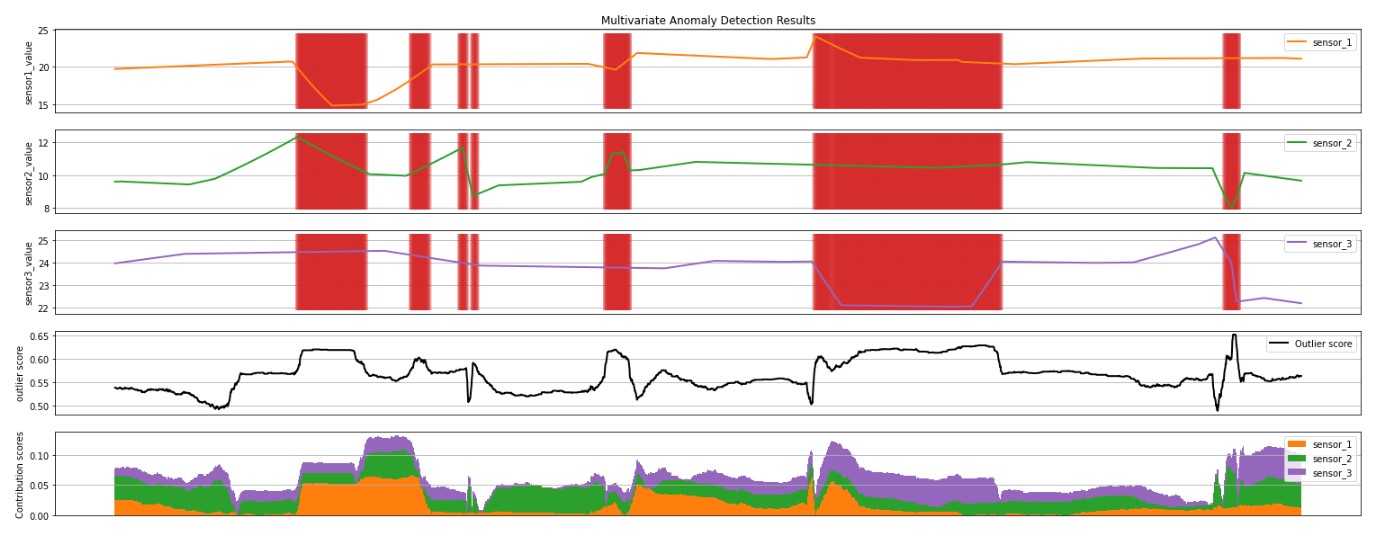
|
||||
|
||||
- The first 3 plots above show the sensor time series data in the inference window, in orange, green, purple and blue. The red vertical lines show the detected anomalies (`prediction` = 1).
|
||||
- The fourth plot shows the outlierScore of all the points, with the `minOutlierScore` threshold shown by the dotted red horizontal line.
|
||||
- The last plot shows the contribution scores of each sensor to the `outlierScore` for that point.
|
||||
|
||||
Plot aggregate feature importance
|
||||
|
||||
|
||||
```python
|
||||
plt.figure(figsize=(10, 7))
|
||||
plt.bar(inputCols, global_explanation.global_importance_values)
|
||||
plt.ylabel("global importance values")
|
||||
```
|
||||
|
||||
When you run the cell above, you will see the following global feature importance plot:
|
||||
|
||||
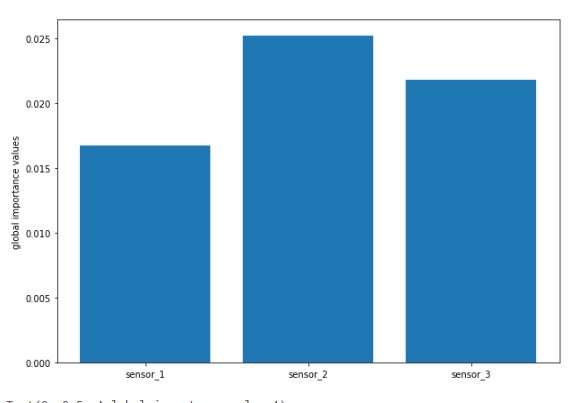
|
||||
|
||||
Visualize the explanation in the ExplanationDashboard from https://github.com/microsoft/responsible-ai-widgets.
|
||||
|
||||
|
||||
```python
|
||||
# View the model explanation in the ExplanationDashboard
|
||||
from raiwidgets import ExplanationDashboard
|
||||
|
||||
ExplanationDashboard(global_explanation, wrapper(model), dataset=eval_data)
|
||||
```
|
||||
|
|
@ -0,0 +1,311 @@
|
|||
---
|
||||
title: LightGBM - Overview
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# LightGBM
|
||||
|
||||
[LightGBM](https://github.com/Microsoft/LightGBM) is an open-source,
|
||||
distributed, high-performance gradient boosting (GBDT, GBRT, GBM, or
|
||||
MART) framework. This framework specializes in creating high-quality and
|
||||
GPU enabled decision tree algorithms for ranking, classification, and
|
||||
many other machine learning tasks. LightGBM is part of Microsoft's
|
||||
[DMTK](http://github.com/microsoft/dmtk) project.
|
||||
|
||||
### Advantages of LightGBM
|
||||
|
||||
- **Composability**: LightGBM models can be incorporated into existing
|
||||
SparkML Pipelines, and used for batch, streaming, and serving
|
||||
workloads.
|
||||
- **Performance**: LightGBM on Spark is 10-30% faster than SparkML on
|
||||
the Higgs dataset, and achieves a 15% increase in AUC. [Parallel
|
||||
experiments](https://github.com/Microsoft/LightGBM/blob/master/docs/Experiments.rst#parallel-experiment)
|
||||
have verified that LightGBM can achieve a linear speed-up by using
|
||||
multiple machines for training in specific settings.
|
||||
- **Functionality**: LightGBM offers a wide array of [tunable
|
||||
parameters](https://github.com/Microsoft/LightGBM/blob/master/docs/Parameters.rst),
|
||||
that one can use to customize their decision tree system. LightGBM on
|
||||
Spark also supports new types of problems such as quantile regression.
|
||||
- **Cross platform** LightGBM on Spark is available on Spark, PySpark, and SparklyR
|
||||
|
||||
### LightGBM Usage:
|
||||
|
||||
- LightGBMClassifier: used for building classification models. For example, to predict whether a company will bankrupt or not, we could build a binary classification model with LightGBMClassifier.
|
||||
- LightGBMRegressor: used for building regression models. For example, to predict the house price, we could build a regression model with LightGBMRegressor.
|
||||
- LightGBMRanker: used for building ranking models. For example, to predict website searching result relevance, we could build a ranking model with LightGBMRanker.
|
||||
|
||||
## Bankruptcy Prediction with LightGBM Classifier
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Documentation/bankruptcy image.png" width="800" />
|
||||
|
||||
In this example, we use LightGBM to build a classification model in order to predict bankruptcy.
|
||||
|
||||
#### Read dataset
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
df = (
|
||||
spark.read.format("csv")
|
||||
.option("header", True)
|
||||
.option("inferSchema", True)
|
||||
.load(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/company_bankruptcy_prediction_data.csv"
|
||||
)
|
||||
)
|
||||
# print dataset size
|
||||
print("records read: " + str(df.count()))
|
||||
print("Schema: ")
|
||||
df.printSchema()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
display(df)
|
||||
```
|
||||
|
||||
#### Split the dataset into train and test
|
||||
|
||||
|
||||
```python
|
||||
train, test = df.randomSplit([0.85, 0.15], seed=1)
|
||||
```
|
||||
|
||||
#### Add featurizer to convert features to vector
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml.feature import VectorAssembler
|
||||
|
||||
feature_cols = df.columns[1:]
|
||||
featurizer = VectorAssembler(inputCols=feature_cols, outputCol="features")
|
||||
train_data = featurizer.transform(train)["Bankrupt?", "features"]
|
||||
test_data = featurizer.transform(test)["Bankrupt?", "features"]
|
||||
```
|
||||
|
||||
#### Check if the data is unbalanced
|
||||
|
||||
|
||||
```python
|
||||
display(train_data.groupBy("Bankrupt?").count())
|
||||
```
|
||||
|
||||
#### Model Training
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMClassifier
|
||||
|
||||
model = LightGBMClassifier(
|
||||
objective="binary", featuresCol="features", labelCol="Bankrupt?", isUnbalance=True
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
model = model.fit(train_data)
|
||||
```
|
||||
|
||||
By calling "saveNativeModel", it allows you to extract the underlying lightGBM model for fast deployment after you train on Spark.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMClassificationModel
|
||||
|
||||
if running_on_synapse():
|
||||
model.saveNativeModel("/models/lgbmclassifier.model")
|
||||
model = LightGBMClassificationModel.loadNativeModelFromFile(
|
||||
"/models/lgbmclassifier.model"
|
||||
)
|
||||
if running_on_synapse_internal():
|
||||
model.saveNativeModel("Files/models/lgbmclassifier.model")
|
||||
model = LightGBMClassificationModel.loadNativeModelFromFile(
|
||||
"Files/models/lgbmclassifier.model"
|
||||
)
|
||||
else:
|
||||
model.saveNativeModel("/tmp/lgbmclassifier.model")
|
||||
model = LightGBMClassificationModel.loadNativeModelFromFile(
|
||||
"/tmp/lgbmclassifier.model"
|
||||
)
|
||||
```
|
||||
|
||||
#### Feature Importances Visualization
|
||||
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
feature_importances = model.getFeatureImportances()
|
||||
fi = pd.Series(feature_importances, index=feature_cols)
|
||||
fi = fi.sort_values(ascending=True)
|
||||
f_index = fi.index
|
||||
f_values = fi.values
|
||||
|
||||
# print feature importances
|
||||
print("f_index:", f_index)
|
||||
print("f_values:", f_values)
|
||||
|
||||
# plot
|
||||
x_index = list(range(len(fi)))
|
||||
x_index = [x / len(fi) for x in x_index]
|
||||
plt.rcParams["figure.figsize"] = (20, 20)
|
||||
plt.barh(
|
||||
x_index, f_values, height=0.028, align="center", color="tan", tick_label=f_index
|
||||
)
|
||||
plt.xlabel("importances")
|
||||
plt.ylabel("features")
|
||||
plt.show()
|
||||
```
|
||||
|
||||
#### Model Prediction
|
||||
|
||||
|
||||
```python
|
||||
predictions = model.transform(test_data)
|
||||
predictions.limit(10).toPandas()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
|
||||
metrics = ComputeModelStatistics(
|
||||
evaluationMetric="classification",
|
||||
labelCol="Bankrupt?",
|
||||
scoredLabelsCol="prediction",
|
||||
).transform(predictions)
|
||||
display(metrics)
|
||||
```
|
||||
|
||||
## Quantile Regression for Drug Discovery with LightGBMRegressor
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/Documentation/drug.png" width="800" />
|
||||
|
||||
In this example, we show how to use LightGBM to build a simple regression model.
|
||||
|
||||
#### Read dataset
|
||||
|
||||
|
||||
```python
|
||||
triazines = spark.read.format("libsvm").load(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/triazines.scale.svmlight"
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# print some basic info
|
||||
print("records read: " + str(triazines.count()))
|
||||
print("Schema: ")
|
||||
triazines.printSchema()
|
||||
display(triazines.limit(10))
|
||||
```
|
||||
|
||||
#### Split dataset into train and test
|
||||
|
||||
|
||||
```python
|
||||
train, test = triazines.randomSplit([0.85, 0.15], seed=1)
|
||||
```
|
||||
|
||||
#### Model Training
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMRegressor
|
||||
|
||||
model = LightGBMRegressor(
|
||||
objective="quantile", alpha=0.2, learningRate=0.3, numLeaves=31
|
||||
).fit(train)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
print(model.getFeatureImportances())
|
||||
```
|
||||
|
||||
#### Model Prediction
|
||||
|
||||
|
||||
```python
|
||||
scoredData = model.transform(test)
|
||||
display(scoredData)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
|
||||
metrics = ComputeModelStatistics(
|
||||
evaluationMetric="regression", labelCol="label", scoresCol="prediction"
|
||||
).transform(scoredData)
|
||||
display(metrics)
|
||||
```
|
||||
|
||||
## LightGBM Ranker
|
||||
|
||||
#### Read dataset
|
||||
|
||||
|
||||
```python
|
||||
df = spark.read.format("parquet").load(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/lightGBMRanker_train.parquet"
|
||||
)
|
||||
# print some basic info
|
||||
print("records read: " + str(df.count()))
|
||||
print("Schema: ")
|
||||
df.printSchema()
|
||||
display(df.limit(10))
|
||||
```
|
||||
|
||||
#### Model Training
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMRanker
|
||||
|
||||
features_col = "features"
|
||||
query_col = "query"
|
||||
label_col = "labels"
|
||||
lgbm_ranker = LightGBMRanker(
|
||||
labelCol=label_col,
|
||||
featuresCol=features_col,
|
||||
groupCol=query_col,
|
||||
predictionCol="preds",
|
||||
leafPredictionCol="leafPreds",
|
||||
featuresShapCol="importances",
|
||||
repartitionByGroupingColumn=True,
|
||||
numLeaves=32,
|
||||
numIterations=200,
|
||||
evalAt=[1, 3, 5],
|
||||
metric="ndcg",
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
lgbm_ranker_model = lgbm_ranker.fit(df)
|
||||
```
|
||||
|
||||
#### Model Prediction
|
||||
|
||||
|
||||
```python
|
||||
dt = spark.read.format("parquet").load(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/lightGBMRanker_test.parquet"
|
||||
)
|
||||
predictions = lgbm_ranker_model.transform(dt)
|
||||
predictions.limit(10).toPandas()
|
||||
```
|
||||
|
|
@ -0,0 +1,262 @@
|
|||
---
|
||||
title: LightGBM
|
||||
hide_title: true
|
||||
sidebar_label: About
|
||||
---
|
||||
|
||||
# LightGBM on Apache Spark
|
||||
|
||||
### LightGBM
|
||||
|
||||
[LightGBM](https://github.com/Microsoft/LightGBM) is an open-source,
|
||||
distributed, high-performance gradient boosting (GBDT, GBRT, GBM, or
|
||||
MART) framework. This framework specializes in creating high-quality and
|
||||
GPU enabled decision tree algorithms for ranking, classification, and
|
||||
many other machine learning tasks. LightGBM is part of Microsoft's
|
||||
[DMTK](http://github.com/microsoft/dmtk) project.
|
||||
|
||||
### Advantages of LightGBM through SynapseML
|
||||
|
||||
- **Composability**: LightGBM models can be incorporated into existing
|
||||
SparkML Pipelines, and used for batch, streaming, and serving
|
||||
workloads.
|
||||
- **Performance**: LightGBM on Spark is 10-30% faster than SparkML on
|
||||
the Higgs dataset, and achieves a 15% increase in AUC. [Parallel
|
||||
experiments](https://github.com/Microsoft/LightGBM/blob/master/docs/Experiments.rst#parallel-experiment)
|
||||
have verified that LightGBM can achieve a linear speed-up by using
|
||||
multiple machines for training in specific settings.
|
||||
- **Functionality**: LightGBM offers a wide array of [tunable
|
||||
parameters](https://github.com/Microsoft/LightGBM/blob/master/docs/Parameters.rst),
|
||||
that one can use to customize their decision tree system. LightGBM on
|
||||
Spark also supports new types of problems such as quantile regression.
|
||||
- **Cross platform** LightGBM on Spark is available on Spark, PySpark, and SparklyR
|
||||
|
||||
### Usage
|
||||
|
||||
In PySpark, you can run the `LightGBMClassifier` via:
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMClassifier
|
||||
model = LightGBMClassifier(learningRate=0.3,
|
||||
numIterations=100,
|
||||
numLeaves=31).fit(train)
|
||||
```
|
||||
|
||||
Similarly, you can run the `LightGBMRegressor` by setting the
|
||||
`application` and `alpha` parameters:
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMRegressor
|
||||
model = LightGBMRegressor(application='quantile',
|
||||
alpha=0.3,
|
||||
learningRate=0.3,
|
||||
numIterations=100,
|
||||
numLeaves=31).fit(train)
|
||||
```
|
||||
|
||||
For an end to end application, check out the LightGBM [notebook
|
||||
example](../LightGBM%20-%20Overview).
|
||||
|
||||
### Arguments/Parameters
|
||||
|
||||
SynapseML exposes getters/setters for many common LightGBM parameters.
|
||||
In python, you can use property-value pairs, or in Scala use
|
||||
fluent setters. Examples of both are shown in this section.
|
||||
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.lightgbm.LightGBMClassifier
|
||||
val classifier = new LightGBMClassifier()
|
||||
.setLearningRate(0.2)
|
||||
.setNumLeaves(50)
|
||||
```
|
||||
|
||||
LightGBM has far more parameters than SynapseML exposes. For cases where you
|
||||
need to set some parameters that SynapseML doesn't expose a setter for, use
|
||||
passThroughArgs. This argument is just a free string that you can use to add extra parameters
|
||||
to the command SynapseML sends to configure LightGBM.
|
||||
|
||||
In python:
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMClassifier
|
||||
model = LightGBMClassifier(passThroughArgs="force_row_wise=true min_sum_hessian_in_leaf=2e-3",
|
||||
numIterations=100,
|
||||
numLeaves=31).fit(train)
|
||||
```
|
||||
|
||||
In Scala:
|
||||
```scala
|
||||
import com.microsoft.azure.synapse.ml.lightgbm.LightGBMClassifier
|
||||
val classifier = new LightGBMClassifier()
|
||||
.setPassThroughArgs("force_row_wise=true min_sum_hessian_in_leaf=2e-3")
|
||||
.setLearningRate(0.2)
|
||||
.setNumLeaves(50)
|
||||
```
|
||||
|
||||
For formatting options and specific argument documentation, see
|
||||
[LightGBM docs](https://lightgbm.readthedocs.io/en/v3.3.2/Parameters.html). SynapseML sets some
|
||||
parameters specifically for the Spark distributed environment and
|
||||
shouldn't be changed. Some parameters are for CLI mode only, and don't work within
|
||||
Spark.
|
||||
|
||||
You can mix *passThroughArgs* and explicit args, as shown in the example. SynapseML
|
||||
merges them to create one argument string to send to LightGBM. If you set a parameter in
|
||||
both places, *passThroughArgs* takes precedence.
|
||||
|
||||
### Architecture
|
||||
|
||||
LightGBM on Spark uses the Simple Wrapper and Interface Generator (SWIG)
|
||||
to add Java support for LightGBM. These Java Binding use the Java Native
|
||||
Interface call into the [distributed C++
|
||||
API](https://github.com/Microsoft/LightGBM/blob/master/include/LightGBM/c_api.h).
|
||||
|
||||
We initialize LightGBM by calling
|
||||
[`LGBM_NetworkInit`](https://github.com/Microsoft/LightGBM/blob/master/include/LightGBM/c_api.h)
|
||||
with the Spark executors within a MapPartitions call. We then pass each
|
||||
workers partitions into LightGBM to create the in-memory distributed
|
||||
dataset for LightGBM. We can then train LightGBM to produce a model
|
||||
that can then be used for inference.
|
||||
|
||||
The `LightGBMClassifier` and `LightGBMRegressor` use the SparkML API,
|
||||
inherit from the same base classes, integrate with SparkML pipelines,
|
||||
and can be tuned with [SparkML's cross
|
||||
validators](https://spark.apache.org/docs/latest/ml-tuning.html).
|
||||
|
||||
Models built can be saved as SparkML pipeline with native LightGBM model
|
||||
using `saveNativeModel()`. Additionally, they're fully compatible with [PMML](https://en.wikipedia.org/wiki/Predictive_Model_Markup_Language) and
|
||||
can be converted to PMML format through the
|
||||
[JPMML-SparkML-LightGBM](https://github.com/alipay/jpmml-sparkml-lightgbm) plugin.
|
||||
|
||||
#### Dynamic Allocation Limitations
|
||||
The native LightGBM library has a *distributed mode* that allows the algorithm to work over multiple *machines*. SynapseML
|
||||
uses this mode to call LightGBM from Spark. SynapseML first gathers all the Spark executor networking information, passes that to LightGBM, and then
|
||||
waits for LightGBM to complete its work. However, the native LightGBM algorithm implementation assumes all networking is constant over the time period of a single
|
||||
training or scoring session. The native LightGBM distributed mode was designed this way and isn't a limitation of SynapseML by itself.
|
||||
|
||||
Dynamic compute changes can cause LightGBM problems if the Spark executors change during data processing. Spark can naturally
|
||||
take advantage of cluster autoscaling and can also dynamically replace any failed executor with another, but LightGBM can't
|
||||
handle these networking changes. Large datasets are affected in particular since they're more likely to cause executor scaling
|
||||
or have a single executor fail during a single processing pass.
|
||||
|
||||
If you're experiencing problems with LightGBM as exposed through SynapseML due to executor changes (for example, occasional Task failures or networking hangs),
|
||||
there are several options.
|
||||
1. In the Spark platform, turn off any autoscaling on the cluster you have provisioned.
|
||||
2. Set *numTasks* manually to be smaller so that fewer executors are used (reducing probability of single executor failure).
|
||||
3. Turn off dynamic executor scaling with configuration in a notebook cell. In Synapse and Fabric, you can use:
|
||||
|
||||
```python
|
||||
%%configure
|
||||
{
|
||||
"conf":
|
||||
{
|
||||
"spark.dynamicAllocation.enabled": "false"
|
||||
}
|
||||
}
|
||||
```
|
||||
Note: setting any custom configuration can affect cluster startup time if your compute platform takes advantage of "live pools"
|
||||
to improve notebook performance.
|
||||
|
||||
If you still have problems, you can consider splitting your data into smaller segments using *numBatches*. Splitting into multiple
|
||||
batches increases total processing time, but can potentially be used to increase reliability.
|
||||
|
||||
### Data Transfer Mode
|
||||
|
||||
SynapseML must pass data from Spark partitions to LightGBM native Datasets before turning over control to
|
||||
the actual LightGBM execution code for training and inference. SynapseML has two modes
|
||||
that control how this data is transferred: *streaming* and *bulk*.
|
||||
This mode doesn't affect training but can affect memory usage and overall fit/transform time.
|
||||
|
||||
#### Bulk Execution mode
|
||||
The "Bulk" mode is older and requires accumulating all data in executor memory before creating Datasets. This mode can cause
|
||||
OOM errors for large data, especially since the data must be accumulated in its original uncompressed double-format size.
|
||||
For now, "bulk" mode is the default since "streaming" is new, but SynapseML will eventually make streaming the default.
|
||||
|
||||
For bulk mode, native LightGBM Datasets can either be created per partition (useSingleDatasetMode=false), or
|
||||
per executor (useSingleDatasetMode=true). Generally, one Dataset per executor is more efficient since it reduces LightGBM network size and complexity during training or fitting. It also avoids using slow network protocols on partitions
|
||||
that are actually on the same executor node.
|
||||
|
||||
#### Streaming Execution Mode
|
||||
The "streaming" execution mode uses new native LightGBM APIs created just for SynapseML that don't require loading extra copies of the data into memory. In particular, data is passed directly
|
||||
from partitions to Datasets in small "micro-batches", similar to Spark streaming. The `microBatchSize` parameter controls the size of these micro-batches.
|
||||
Smaller micro-batch sizes reduce memory overhead, but larger sizes avoid overhead from repeatedly transferring data to the native layer. The default
|
||||
100, uses far less memory than bulk mode since only 100 rows of data will be loaded at a time. If your dataset has
|
||||
few columns, you can increase the batch size. Alternatively, if
|
||||
your dataset has a large number of columns you can decrease the micro-batch size to avoid OOM issues.
|
||||
|
||||
These new streaming APIs in LightGBM are thread-safe, and allow all partitions in the same executor
|
||||
to push data into a shared Dataset in parallel. Because of this, streaming mode always uses the more efficient
|
||||
"useSingleDatasetMode=true", creating only one Dataset per executor.
|
||||
|
||||
You can explicitly specify Execution Mode and MicroBatch size as parameters.
|
||||
|
||||
val lgbm = new LightGBMClassifier()
|
||||
.setExecutionMode("streaming")
|
||||
.setMicroBatchSize(100)
|
||||
.setLabelCol(labelColumn)
|
||||
.setObjective("binary")
|
||||
...
|
||||
<train classifier>
|
||||
|
||||
For streaming mode, only one Dataset is created per partition, so *useSingleDataMode* has no effect. It's effectively always true.
|
||||
|
||||
### Data Sampling
|
||||
|
||||
In order for LightGBM algorithm to work, it must first create a set of bin boundaries for optimization. It does this calculation by
|
||||
first sampling the data before any training or inferencing starts. ([LightGBM docs](https://github.com/Microsoft/LightGBM)). The number of
|
||||
samples to use is set using *binSampleCount*, which must be a minimal percent of the data or LightGBM rejects it.
|
||||
|
||||
For *bulk* mode, this sampling is automatically done over the entire data, and each executor uses its own partitions to calculate samples for only
|
||||
a subset of the features. This distributed sampling can have subtle effects since partitioning can affect the calculated bins.
|
||||
Also, all data is sampled no matter what.
|
||||
|
||||
For *streaming* mode, there are more explicit user controls for this sampling, and it's all done from the driver.
|
||||
The *samplingMode* property controls the behavior. The efficiency of these methods increases from first to last.
|
||||
- *global* - Like bulk mode, the random sample is calculated by iterating over entire data (hence data is traversed twice)
|
||||
- *subset* - (default) Samples only from the first *samplingSubsetSize* elements. Assumes this subset is representative.
|
||||
- *fixed* - There's no random sample. The first *binSampleSize* rows are used. Assumes randomized data.
|
||||
For large row counts, *subset* and *fixed* modes can save a first iteration over the entire data.
|
||||
|
||||
#### Reference Dataset
|
||||
The sampling of the data to calculate bin boundaries happens every *fit* call.
|
||||
If repeating a fit many times (for example, hyperparameter tuning), this calculation is duplicated effort.
|
||||
|
||||
For *streaming* mode, there's an optimization that a client can set to use the previously calculated bin boundaries. The
|
||||
sampling calculation results in a *reference dataset*, which can be reused. After a fit, there will be a *referenceDataset* property
|
||||
on the estimator that was calculated and used for that fit. If that is set on the next estimator (or you reuse the same one),
|
||||
it will use that instead of resampling the data.
|
||||
|
||||
```python
|
||||
from synapse.ml.lightgbm import LightGBMClassifier
|
||||
classifier = LightGBMClassifier(learningRate=0.3,
|
||||
numIterations=100,
|
||||
numLeaves=31)
|
||||
model1 = classifier.fit(train)
|
||||
|
||||
classifier.learningRate = 0.4
|
||||
model2 = classifier.fit(train)
|
||||
```
|
||||
The 'model2' call to 'fit' doesn't resample the data and uses the same bin boundaries as 'model1'.
|
||||
|
||||
*Caution*: Some parameters actually affect the bin boundary calculation and require the use of a new reference dataset every time.
|
||||
These parameters include *isEnableSparse*, *useMissing*, and *zeroAsMissing* that you can set from SynapseML. If you manually set
|
||||
some parameters with *passThroughArgs*, you should look at LightGBM docs to see if they affect bin boundaries. If you're setting
|
||||
any parameter that affects bin boundaries and reusing the same estimator, you should set referenceDataset to an empty array between calls.
|
||||
|
||||
### Barrier Execution Mode
|
||||
|
||||
By default LightGBM uses the regular spark paradigm for launching tasks and communicates with the driver to coordinate task execution.
|
||||
The driver thread aggregates all task host:port information and then communicates the full list back to the workers in order for NetworkInit to be called.
|
||||
This procedure requires the driver to know how many tasks there are, and a mismatch between the expected number of tasks and the actual number causes
|
||||
the initialization to deadlock.
|
||||
|
||||
If you're experiencing network issues, you can try using Spark's *barrier* execution mode. SynapseML provides a `UseBarrierExecutionMode` flag,
|
||||
to use Apache Spark's `barrier()` stage to ensure all tasks execute at the same time.
|
||||
Barrier execution mode changes the logic to aggregate `host:port` information across all tasks in a synchronized way.
|
||||
To use it in scala, you can call setUseBarrierExecutionMode(true), for example:
|
||||
|
||||
val lgbm = new LightGBMClassifier()
|
||||
.setLabelCol(labelColumn)
|
||||
.setObjective(binaryObjective)
|
||||
.setUseBarrierExecutionMode(true)
|
||||
...
|
||||
<train classifier>
|
||||
Note: barrier execution mode can also cause complicated issues, so use it only if needed.
|
||||
|
|
@ -0,0 +1,155 @@
|
|||
---
|
||||
title: ONNX - Inference on Spark
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## ONNX Inference on Spark
|
||||
|
||||
In this example, we will train a LightGBM model, convert the model to ONNX format and use the converted model to infer some testing data on Spark.
|
||||
|
||||
Python dependencies:
|
||||
|
||||
- onnxmltools==1.7.0
|
||||
- lightgbm==3.2.1
|
||||
|
||||
|
||||
Load training data
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
df = (
|
||||
spark.read.format("csv")
|
||||
.option("header", True)
|
||||
.option("inferSchema", True)
|
||||
.load(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/company_bankruptcy_prediction_data.csv"
|
||||
)
|
||||
)
|
||||
|
||||
display(df)
|
||||
```
|
||||
|
||||
Use LightGBM to train a model
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml.feature import VectorAssembler
|
||||
from synapse.ml.lightgbm import LightGBMClassifier
|
||||
|
||||
feature_cols = df.columns[1:]
|
||||
featurizer = VectorAssembler(inputCols=feature_cols, outputCol="features")
|
||||
|
||||
train_data = featurizer.transform(df)["Bankrupt?", "features"]
|
||||
|
||||
model = (
|
||||
LightGBMClassifier(featuresCol="features", labelCol="Bankrupt?")
|
||||
.setEarlyStoppingRound(300)
|
||||
.setLambdaL1(0.5)
|
||||
.setNumIterations(1000)
|
||||
.setNumThreads(-1)
|
||||
.setMaxDeltaStep(0.5)
|
||||
.setNumLeaves(31)
|
||||
.setMaxDepth(-1)
|
||||
.setBaggingFraction(0.7)
|
||||
.setFeatureFraction(0.7)
|
||||
.setBaggingFreq(2)
|
||||
.setObjective("binary")
|
||||
.setIsUnbalance(True)
|
||||
.setMinSumHessianInLeaf(20)
|
||||
.setMinGainToSplit(0.01)
|
||||
)
|
||||
|
||||
model = model.fit(train_data)
|
||||
```
|
||||
|
||||
Export the trained model to a LightGBM booster, convert it to ONNX format.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.core.platform import running_on_binder
|
||||
|
||||
if running_on_binder():
|
||||
!pip install lightgbm==3.2.1
|
||||
from IPython import get_ipython
|
||||
import lightgbm as lgb
|
||||
from lightgbm import Booster, LGBMClassifier
|
||||
|
||||
|
||||
def convertModel(lgbm_model: LGBMClassifier or Booster, input_size: int) -> bytes:
|
||||
from onnxmltools.convert import convert_lightgbm
|
||||
from onnxconverter_common.data_types import FloatTensorType
|
||||
|
||||
initial_types = [("input", FloatTensorType([-1, input_size]))]
|
||||
onnx_model = convert_lightgbm(
|
||||
lgbm_model, initial_types=initial_types, target_opset=9
|
||||
)
|
||||
return onnx_model.SerializeToString()
|
||||
|
||||
|
||||
booster_model_str = model.getLightGBMBooster().modelStr().get()
|
||||
booster = lgb.Booster(model_str=booster_model_str)
|
||||
model_payload_ml = convertModel(booster, len(feature_cols))
|
||||
```
|
||||
|
||||
Load the ONNX payload into an `ONNXModel`, and inspect the model inputs and outputs.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.onnx import ONNXModel
|
||||
|
||||
onnx_ml = ONNXModel().setModelPayload(model_payload_ml)
|
||||
|
||||
print("Model inputs:" + str(onnx_ml.getModelInputs()))
|
||||
print("Model outputs:" + str(onnx_ml.getModelOutputs()))
|
||||
```
|
||||
|
||||
Map the model input to the input dataframe's column name (FeedDict), and map the output dataframe's column names to the model outputs (FetchDict).
|
||||
|
||||
|
||||
```python
|
||||
onnx_ml = (
|
||||
onnx_ml.setDeviceType("CPU")
|
||||
.setFeedDict({"input": "features"})
|
||||
.setFetchDict({"probability": "probabilities", "prediction": "label"})
|
||||
.setMiniBatchSize(5000)
|
||||
)
|
||||
```
|
||||
|
||||
Create some testing data and transform the data through the ONNX model.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml.feature import VectorAssembler
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
|
||||
n = 1000 * 1000
|
||||
m = 95
|
||||
test = np.random.rand(n, m)
|
||||
testPdf = pd.DataFrame(test)
|
||||
cols = list(map(str, testPdf.columns))
|
||||
testDf = spark.createDataFrame(testPdf)
|
||||
testDf = testDf.union(testDf).repartition(200)
|
||||
testDf = (
|
||||
VectorAssembler()
|
||||
.setInputCols(cols)
|
||||
.setOutputCol("features")
|
||||
.transform(testDf)
|
||||
.drop(*cols)
|
||||
.cache()
|
||||
)
|
||||
|
||||
display(onnx_ml.transform(testDf))
|
||||
```
|
||||
|
|
@ -0,0 +1,108 @@
|
|||
---
|
||||
title: ONNX model inferencing on Spark
|
||||
hide_title: true
|
||||
sidebar_label: About
|
||||
description: Learn how to use the ONNX model transformer to run inference for an ONNX model on Spark.
|
||||
---
|
||||
|
||||
# ONNX model inferencing on Spark
|
||||
|
||||
## ONNX
|
||||
|
||||
[ONNX](https://onnx.ai/) is an open format to represent both deep learning and traditional machine learning models. With ONNX, AI developers can more easily move models between state-of-the-art tools and choose the combination that is best for them.
|
||||
|
||||
SynapseML now includes a Spark transformer to bring a trained ONNX model to Apache Spark, so you can run inference on your data with Spark's large-scale data processing power.
|
||||
|
||||
## ONNXHub
|
||||
Although you can use your own local model, many popular existing models are provided through the ONNXHub. You can use
|
||||
a model's ONNXHub name (for example "MNIST") and download the bytes of the model, and some metadata about the model. You can also list
|
||||
available models, optionally filtering by name or tags.
|
||||
|
||||
```scala
|
||||
// List models
|
||||
val hub = new ONNXHub()
|
||||
val models = hub.listModels(model = Some("mnist"), tags = Some(Seq("vision")))
|
||||
|
||||
// Retrieve and transform with a model
|
||||
val info = hub.getModelInfo("resnet50")
|
||||
val bytes = hub.load(name)
|
||||
val model = new ONNXModel()
|
||||
.setModelPayload(bytes)
|
||||
.setFeedDict(Map("data" -> "features"))
|
||||
.setFetchDict(Map("rawPrediction" -> "resnetv24_dense0_fwd"))
|
||||
.setSoftMaxDict(Map("rawPrediction" -> "probability"))
|
||||
.setArgMaxDict(Map("rawPrediction" -> "prediction"))
|
||||
.setMiniBatchSize(1)
|
||||
|
||||
val (probability, _) = model.transform({YOUR_DATAFRAME})
|
||||
.select("probability", "prediction")
|
||||
.as[(Vector, Double)]
|
||||
.head
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
1. Create a `com.microsoft.azure.synapse.ml.onnx.ONNXModel` object and use `setModelLocation` or `setModelPayload` to load the ONNX model.
|
||||
|
||||
For example:
|
||||
|
||||
```scala
|
||||
val onnx = new ONNXModel().setModelLocation("/path/to/model.onnx")
|
||||
```
|
||||
|
||||
Optionally, create the model from the ONNXHub.
|
||||
|
||||
```scala
|
||||
val onnx = new ONNXModel().setModelPayload(hub.load("MNIST"))
|
||||
```
|
||||
2. Use ONNX visualization tool (for example, [Netron](https://netron.app/)) to inspect the ONNX model's input and output nodes.
|
||||
|
||||
|
||||
|
||||
3. Set the parameters properly to the `ONNXModel` object.
|
||||
|
||||
The `com.microsoft.azure.synapse.ml.onnx.ONNXModel` class provides a set of parameters to control the behavior of the inference.
|
||||
|
||||
| Parameter | Description | Default Value |
|
||||
|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------|
|
||||
| feedDict | Map the ONNX model's expected input node names to the input DataFrame's column names. Make sure the input DataFrame's column schema matches with the corresponding input's shape of the ONNX model. For example, an image classification model may have an input node of shape `[1, 3, 224, 224]` with type Float. It's assumed that the first dimension (1) is the batch size. Then the input DataFrame's corresponding column's type should be `ArrayType(ArrayType(ArrayType(FloatType)))`. | None |
|
||||
| fetchDict | Map the output DataFrame's column names to the ONNX model's output node names. NOTE: If you put outputs that are intermediate in the model, transform will automatically slice at those outputs. See the section on [Slicing](#slicing). | None |
|
||||
| miniBatcher | Specify the MiniBatcher to use. | `FixedMiniBatchTransformer` with batch size 10 |
|
||||
| softMaxDict | A map between output DataFrame columns, where the value column will be computed from taking the softmax of the key column. If the 'rawPrediction' column contains logits outputs, then one can set softMaxDict to `Map("rawPrediction" -> "probability")` to obtain the probability outputs. | None |
|
||||
| argMaxDict | A map between output DataFrame columns, where the value column will be computed from taking the argmax of the key column. This parameter can be used to convert probability or logits output to the predicted label. | None |
|
||||
| deviceType | Specify a device type the model inference runs on. Supported types are: CPU or CUDA. If not specified, auto detection will be used. | None |
|
||||
| optimizationLevel | Specify the [optimization level](https://onnxruntime.ai/docs/resources/graph-optimizations.html#graph-optimization-levels) for the ONNX graph optimizations. Supported values are: `NO_OPT`, `BASIC_OPT`, `EXTENDED_OPT`, `ALL_OPT`. | `ALL_OPT` |
|
||||
|
||||
4. Call `transform` method to run inference on the input DataFrame.
|
||||
|
||||
## <a name="slicing"></a>Model Slicing
|
||||
By default, an ONNX model is treated as a black box with inputs and outputs.
|
||||
If you want to use intermediate nodes of a model, you can slice the model at particular nodes. Slicing will create a new model,
|
||||
keeping only parts of the model that are needed for those nodes. This new model's outputs will be the outputs from
|
||||
the intermediate nodes. You can save the sliced model and use it to transform just like any other ONNXModel.
|
||||
|
||||
This slicing feature is used implicitly by the ImageFeaturizer, which uses ONNX models. The OnnxHub manifest entry for each model
|
||||
includes which intermediate node outputs should be used for featurization, so the ImageFeaturizer will automatically slice at the correct nodes.
|
||||
|
||||
The below example shows how to perform the slicing manually with a direct ONNXModel.
|
||||
|
||||
```scala
|
||||
// create a df: Dataframe with image data
|
||||
val hub = new ONNXHub()
|
||||
val info = hub.getModelInfo("resnet50")
|
||||
val bytes = hub.load(name)
|
||||
val intermediateOutputName = "resnetv24_pool1_fwd"
|
||||
val slicedModel = new ONNXModel()
|
||||
.setModelPayload(bytes)
|
||||
.setFeedDict(Map("data" -> "features"))
|
||||
.setFetchDict(Map("rawFeatures" -> intermediateOutputName)) // automatic slicing based on fetch dictionary
|
||||
// -- or --
|
||||
// .sliceAtOutput(intermediateOutputName) // manual slicing
|
||||
|
||||
val slicedModelDf = slicedModel.transform(df)
|
||||
```
|
||||
|
||||
## Example
|
||||
|
||||
- [Interpretability - Image Explainers](../../responsible_ai/Interpretability%20-%20Image%20Explainers)
|
||||
- [ONNX - Inference on Spark](../ONNX%20-%20Inference%20on%20Spark)
|
||||
|
|
@ -0,0 +1,170 @@
|
|||
---
|
||||
title: OpenCV - Pipeline Image Transformations
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## OpenCV - Pipeline Image Transformations
|
||||
|
||||
This example shows how to manipulate the collection of images.
|
||||
First, the images are downloaded to the local directory.
|
||||
Second, they are copied to your cluster's attached HDFS.
|
||||
|
||||
The images are loaded from the directory (for fast prototyping, consider loading a fraction of
|
||||
images). Inside the dataframe, each image is a single field in the image column. The image has
|
||||
sub-fields (path, height, width, OpenCV type and OpenCV bytes).
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import running_on_synapse
|
||||
|
||||
if running_on_synapse():
|
||||
from notebookutils.visualization import display
|
||||
|
||||
import synapse.ml
|
||||
import numpy as np
|
||||
from synapse.ml.opencv import toNDArray
|
||||
from synapse.ml.io import *
|
||||
|
||||
imageDir = "wasbs://publicwasb@mmlspark.blob.core.windows.net/sampleImages"
|
||||
images = spark.read.image().load(imageDir).cache()
|
||||
images.printSchema()
|
||||
print(images.count())
|
||||
```
|
||||
|
||||
We can also alternatively stream the images with a similar api.
|
||||
Check the [Structured Streaming Programming Guide](https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html)
|
||||
for more details on streaming.
|
||||
|
||||
|
||||
```python
|
||||
import time
|
||||
|
||||
imageStream = spark.readStream.image().load(imageDir)
|
||||
query = (
|
||||
imageStream.select("image.height")
|
||||
.writeStream.format("memory")
|
||||
.queryName("heights")
|
||||
.start()
|
||||
)
|
||||
time.sleep(3)
|
||||
print("Streaming query activity: {}".format(query.isActive))
|
||||
```
|
||||
|
||||
Wait a few seconds and then try querying for the images below.
|
||||
Note that when streaming a directory of images that already exists it will
|
||||
consume all images in a single batch. If one were to move images into the
|
||||
directory, the streaming engine would pick up on them and send them as
|
||||
another batch.
|
||||
|
||||
|
||||
```python
|
||||
heights = spark.sql("select * from heights")
|
||||
print("Streamed {} heights".format(heights.count()))
|
||||
```
|
||||
|
||||
After we have streamed the images we can stop the query:
|
||||
|
||||
|
||||
```python
|
||||
from py4j.protocol import Py4JJavaError
|
||||
|
||||
try:
|
||||
query.stop()
|
||||
except Py4JJavaError as e:
|
||||
print(e)
|
||||
```
|
||||
|
||||
When collected from the *DataFrame*, the image data are stored in a *Row*, which is Spark's way
|
||||
to represent structures (in the current example, each dataframe row has a single Image, which
|
||||
itself is a Row). It is possible to address image fields by name and use `toNDArray()` helper
|
||||
function to convert the image into numpy array for further manipulations.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.core.platform import running_on_binder
|
||||
|
||||
if running_on_binder():
|
||||
from IPython import get_ipython
|
||||
from PIL import Image
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
data = images.take(3) # take first three rows of the dataframe
|
||||
im = data[2][0] # the image is in the first column of a given row
|
||||
|
||||
print("image type: {}, number of fields: {}".format(type(im), len(im)))
|
||||
print("image path: {}".format(im.origin))
|
||||
print("height: {}, width: {}, OpenCV type: {}".format(im.height, im.width, im.mode))
|
||||
|
||||
arr = toNDArray(im) # convert to numpy array
|
||||
print(images.count())
|
||||
plt.imshow(Image.fromarray(arr, "RGB")) # display the image inside notebook
|
||||
```
|
||||
|
||||
Use `ImageTransformer` for the basic image manipulation: resizing, cropping, etc.
|
||||
Internally, operations are pipelined and backed by OpenCV implementation.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.opencv import ImageTransformer
|
||||
|
||||
tr = (
|
||||
ImageTransformer() # images are resized and then cropped
|
||||
.setOutputCol("transformed")
|
||||
.resize(size=(200, 200))
|
||||
.crop(0, 0, height=180, width=180)
|
||||
)
|
||||
|
||||
small = tr.transform(images).select("transformed")
|
||||
|
||||
im = small.take(3)[2][0] # take third image
|
||||
plt.imshow(Image.fromarray(toNDArray(im), "RGB")) # display the image inside notebook
|
||||
```
|
||||
|
||||
For the advanced image manipulations, use Spark UDFs.
|
||||
The SynapseML package provides conversion function between *Spark Row* and
|
||||
*ndarray* image representations.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.functions import udf
|
||||
from synapse.ml.opencv import ImageSchema, toNDArray, toImage
|
||||
|
||||
|
||||
def u(row):
|
||||
array = toNDArray(row) # convert Image to numpy ndarray[height, width, 3]
|
||||
array[:, :, 2] = 0
|
||||
return toImage(array) # numpy array back to Spark Row structure
|
||||
|
||||
|
||||
noBlueUDF = udf(u, ImageSchema)
|
||||
|
||||
noblue = small.withColumn("noblue", noBlueUDF(small["transformed"])).select("noblue")
|
||||
|
||||
im = noblue.take(3)[2][0] # take second image
|
||||
plt.imshow(Image.fromarray(toNDArray(im), "RGB")) # display the image inside notebook
|
||||
```
|
||||
|
||||
Images could be unrolled into the dense 1D vectors suitable for CNTK evaluation.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.image import UnrollImage
|
||||
|
||||
unroller = UnrollImage().setInputCol("noblue").setOutputCol("unrolled")
|
||||
|
||||
unrolled = unroller.transform(noblue).select("unrolled")
|
||||
|
||||
vector = unrolled.take(1)[0][0]
|
||||
print(type(vector))
|
||||
len(vector.toArray())
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,237 @@
|
|||
---
|
||||
title: ConditionalKNN - Exploring Art Across Cultures
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# Exploring Art across Culture and Medium with Fast, Conditional, k-Nearest Neighbors
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/art/cross_cultural_matches.jpg" width="600"/>
|
||||
|
||||
This notebook serves as a guideline for match-finding via k-nearest-neighbors. In the code below, we will set up code that allows queries involving cultures and mediums of art amassed from the Metropolitan Museum of Art in NYC and the Rijksmuseum in Amsterdam.
|
||||
|
||||
### Overview of the BallTree
|
||||
The structure functioning behind the kNN model is a BallTree, which is a recursive binary tree where each node (or "ball") contains a partition of the points of data to be queried. Building a BallTree involves assigning data points to the "ball" whose center they are closest to (with respect to a certain specified feature), resulting in a structure that allows binary-tree-like traversal and lends itself to finding k-nearest neighbors at a BallTree leaf.
|
||||
|
||||
#### Setup
|
||||
Import necessary Python libraries and prepare dataset.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
if running_on_binder():
|
||||
from IPython import get_ipython
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql.types import BooleanType
|
||||
from pyspark.sql.types import *
|
||||
from pyspark.ml.feature import Normalizer
|
||||
from pyspark.sql.functions import lit, array, array_contains, udf, col, struct
|
||||
from synapse.ml.nn import ConditionalKNN, ConditionalKNNModel
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
|
||||
import requests
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
Our dataset comes from a table containing artwork information from both the Met and Rijks museums. The schema is as follows:
|
||||
|
||||
- **id**: A unique identifier for a piece of art
|
||||
- Sample Met id: *388395*
|
||||
- Sample Rijks id: *SK-A-2344*
|
||||
- **Title**: Art piece title, as written in the museum's database
|
||||
- **Artist**: Art piece artist, as written in the museum's database
|
||||
- **Thumbnail_Url**: Location of a JPEG thumbnail of the art piece
|
||||
- **Image_Url** Location of an image of the art piece hosted on the Met/Rijks website
|
||||
- **Culture**: Category of culture that the art piece falls under
|
||||
- Sample culture categories: *latin american*, *egyptian*, etc.
|
||||
- **Classification**: Category of medium that the art piece falls under
|
||||
- Sample medium categories: *woodwork*, *paintings*, etc.
|
||||
- **Museum_Page**: Link to the work of art on the Met/Rijks website
|
||||
- **Norm_Features**: Embedding of the art piece image
|
||||
- **Museum**: Specifies which museum the piece originated from
|
||||
|
||||
|
||||
```python
|
||||
# loads the dataset and the two trained CKNN models for querying by medium and culture
|
||||
df = spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/met_and_rijks.parquet"
|
||||
)
|
||||
display(df.drop("Norm_Features"))
|
||||
```
|
||||
|
||||
#### Define categories to be queried on
|
||||
We will be using two kNN models: one for culture, and one for medium. The categories for each grouping are defined below.
|
||||
|
||||
|
||||
```python
|
||||
# mediums = ['prints', 'drawings', 'ceramics', 'textiles', 'paintings', "musical instruments","glass", 'accessories', 'photographs', "metalwork",
|
||||
# "sculptures", "weapons", "stone", "precious", "paper", "woodwork", "leatherwork", "uncategorized"]
|
||||
|
||||
mediums = ["paintings", "glass", "ceramics"]
|
||||
|
||||
# cultures = ['african (general)', 'american', 'ancient american', 'ancient asian', 'ancient european', 'ancient middle-eastern', 'asian (general)',
|
||||
# 'austrian', 'belgian', 'british', 'chinese', 'czech', 'dutch', 'egyptian']#, 'european (general)', 'french', 'german', 'greek',
|
||||
# 'iranian', 'italian', 'japanese', 'latin american', 'middle eastern', 'roman', 'russian', 'south asian', 'southeast asian',
|
||||
# 'spanish', 'swiss', 'various']
|
||||
|
||||
cultures = ["japanese", "american", "african (general)"]
|
||||
|
||||
# Uncomment the above for more robust and large scale searches!
|
||||
|
||||
classes = cultures + mediums
|
||||
|
||||
medium_set = set(mediums)
|
||||
culture_set = set(cultures)
|
||||
selected_ids = {"AK-RBK-17525-2", "AK-MAK-1204", "AK-RAK-2015-2-9"}
|
||||
|
||||
small_df = df.where(
|
||||
udf(
|
||||
lambda medium, culture, id_val: (medium in medium_set)
|
||||
or (culture in culture_set)
|
||||
or (id_val in selected_ids),
|
||||
BooleanType(),
|
||||
)("Classification", "Culture", "id")
|
||||
)
|
||||
|
||||
small_df.count()
|
||||
```
|
||||
|
||||
### Define and fit ConditionalKNN models
|
||||
Below, we create ConditionalKNN models for both the medium and culture columns; each model takes in an output column, features column (feature vector), values column (cell values under the output column), and label column (the quality that the respective KNN is conditioned on).
|
||||
|
||||
|
||||
```python
|
||||
medium_cknn = (
|
||||
ConditionalKNN()
|
||||
.setOutputCol("Matches")
|
||||
.setFeaturesCol("Norm_Features")
|
||||
.setValuesCol("Thumbnail_Url")
|
||||
.setLabelCol("Classification")
|
||||
.fit(small_df)
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
culture_cknn = (
|
||||
ConditionalKNN()
|
||||
.setOutputCol("Matches")
|
||||
.setFeaturesCol("Norm_Features")
|
||||
.setValuesCol("Thumbnail_Url")
|
||||
.setLabelCol("Culture")
|
||||
.fit(small_df)
|
||||
)
|
||||
```
|
||||
|
||||
#### Define matching and visualizing methods
|
||||
|
||||
After the initial dataset and category setup, we prepare methods that will query and visualize the conditional kNN's results.
|
||||
|
||||
`addMatches()` will create a Dataframe with a handful of matches per category.
|
||||
|
||||
|
||||
```python
|
||||
def add_matches(classes, cknn, df):
|
||||
results = df
|
||||
for label in classes:
|
||||
results = cknn.transform(
|
||||
results.withColumn("conditioner", array(lit(label)))
|
||||
).withColumnRenamed("Matches", "Matches_{}".format(label))
|
||||
return results
|
||||
```
|
||||
|
||||
`plot_urls()` calls `plot_img` to visualize top matches for each category into a grid.
|
||||
|
||||
|
||||
```python
|
||||
def plot_img(axis, url, title):
|
||||
try:
|
||||
response = requests.get(url)
|
||||
img = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
axis.imshow(img, aspect="equal")
|
||||
except:
|
||||
pass
|
||||
if title is not None:
|
||||
axis.set_title(title, fontsize=4)
|
||||
axis.axis("off")
|
||||
|
||||
|
||||
def plot_urls(url_arr, titles, filename):
|
||||
nx, ny = url_arr.shape
|
||||
|
||||
plt.figure(figsize=(nx * 5, ny * 5), dpi=1600)
|
||||
fig, axes = plt.subplots(ny, nx)
|
||||
|
||||
# reshape required in the case of 1 image query
|
||||
if len(axes.shape) == 1:
|
||||
axes = axes.reshape(1, -1)
|
||||
|
||||
for i in range(nx):
|
||||
for j in range(ny):
|
||||
if j == 0:
|
||||
plot_img(axes[j, i], url_arr[i, j], titles[i])
|
||||
else:
|
||||
plot_img(axes[j, i], url_arr[i, j], None)
|
||||
|
||||
plt.savefig(filename, dpi=1600) # saves the results as a PNG
|
||||
|
||||
display(plt.show())
|
||||
```
|
||||
|
||||
### Putting it all together
|
||||
Below, we define `test_all()` to take in the data, CKNN models, the art id values to query on, and the file path to save the output visualization to. The medium and culture models were previously trained and loaded.
|
||||
|
||||
|
||||
```python
|
||||
# main method to test a particular dataset with two CKNN models and a set of art IDs, saving the result to filename.png
|
||||
|
||||
|
||||
def test_all(data, cknn_medium, cknn_culture, test_ids, root):
|
||||
is_nice_obj = udf(lambda obj: obj in test_ids, BooleanType())
|
||||
test_df = data.where(is_nice_obj("id"))
|
||||
|
||||
results_df_medium = add_matches(mediums, cknn_medium, test_df)
|
||||
results_df_culture = add_matches(cultures, cknn_culture, results_df_medium)
|
||||
|
||||
results = results_df_culture.collect()
|
||||
|
||||
original_urls = [row["Thumbnail_Url"] for row in results]
|
||||
|
||||
culture_urls = [
|
||||
[row["Matches_{}".format(label)][0]["value"] for row in results]
|
||||
for label in cultures
|
||||
]
|
||||
culture_url_arr = np.array([original_urls] + culture_urls)[:, :]
|
||||
plot_urls(culture_url_arr, ["Original"] + cultures, root + "matches_by_culture.png")
|
||||
|
||||
medium_urls = [
|
||||
[row["Matches_{}".format(label)][0]["value"] for row in results]
|
||||
for label in mediums
|
||||
]
|
||||
medium_url_arr = np.array([original_urls] + medium_urls)[:, :]
|
||||
plot_urls(medium_url_arr, ["Original"] + mediums, root + "matches_by_medium.png")
|
||||
|
||||
return results_df_culture
|
||||
```
|
||||
|
||||
### Demo
|
||||
The following cell performs batched queries given desired image IDs and a filename to save the visualization.
|
||||
|
||||
|
||||
<img src="https://mmlspark.blob.core.windows.net/graphics/art/cross_cultural_matches.jpg" width="600"/>
|
||||
|
||||
|
||||
```python
|
||||
# sample query
|
||||
result_df = test_all(small_df, medium_cknn, culture_cknn, selected_ids, root=".")
|
||||
```
|
||||
|
|
@ -0,0 +1,362 @@
|
|||
---
|
||||
title: CyberML - Anomalous Access Detection
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
# CyberML - Anomalous Access Detection
|
||||
|
||||
Here we demonstrate a novel CyberML model which can learn user access patterns and then automatically detect anomalous user access based on learned behavior.
|
||||
The model internally uses Collaborative Filtering for Implicit Feedback as published here: http://yifanhu.net/PUB/cf.pdf
|
||||
and is based on Apache Spark's implementation of this: https://spark.apache.org/docs/2.2.0/ml-collaborative-filtering.html.
|
||||
|
||||
This notebook demonstrates a usage example of Anomalous Resource Access model.
|
||||
All the model requires is a dataset in which there are 'users' which access 'resources'.
|
||||
The model is based on Collaborative Filtering and it uses Machine Learning to learn access patterns of users and resources.
|
||||
When a user accesses a resource which is outside of the user's learned profile then this access receives a high anomaly score.
|
||||
|
||||
In this notebook we provide a usage example and a synthetic dataset in which there are 3 departments:
|
||||
(1) Finance, (2) HR and (3) Engineering.
|
||||
In the training data users access only a subset of resources from their own departments.
|
||||
To evaluate the model we use two datasets.
|
||||
The first contains access patterns unseen during training in which users access resources within their departments (again, resources they didn't access during training but within their department).
|
||||
The latter contains users accessing resources from outside their department.
|
||||
We then use the model to assign anomaly scores expecting that the first get low anomaly scores and the latter receive high anomaly scores.
|
||||
This is what this example demonstrates.
|
||||
|
||||
Note: the data does NOT contain information about departments, this information is implicitly learned by the model by analyzing the access patterns.
|
||||
|
||||
# Create an Azure Databricks cluster and install the following libs
|
||||
|
||||
1. In Cluster Libraries install from library source Maven:
|
||||
Coordinates: com.microsoft.azure:synapseml_2.12:0.11.2
|
||||
Repository: https://mmlspark.azureedge.net/maven
|
||||
|
||||
2. In Cluster Libraries install from PyPI the library called plotly
|
||||
|
||||
# Setup & Initialization
|
||||
|
||||
|
||||
```python
|
||||
# this is used to produce the synthetic dataset for this test
|
||||
from synapse.ml.cyber.dataset import DataFactory
|
||||
|
||||
# the access anomalies model generator
|
||||
from synapse.ml.cyber.anomaly.collaborative_filtering import AccessAnomaly
|
||||
|
||||
from pyspark.sql import functions as f, types as t
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
# Load up datasets
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.core.platform import running_on_databricks, running_on_synapse
|
||||
|
||||
if running_on_databricks():
|
||||
spark.sparkContext.setCheckpointDir("dbfs:/checkpoint_path/")
|
||||
else:
|
||||
spark.sparkContext.setCheckpointDir("./tmp/checkpoint_path/")
|
||||
|
||||
if running_on_synapse():
|
||||
from notebookutils.visualization import display
|
||||
|
||||
factory = DataFactory(
|
||||
num_hr_users=25,
|
||||
num_hr_resources=50,
|
||||
num_fin_users=35,
|
||||
num_fin_resources=75,
|
||||
num_eng_users=15,
|
||||
num_eng_resources=25,
|
||||
single_component=True,
|
||||
)
|
||||
|
||||
training_pdf = factory.create_clustered_training_data(ratio=0.4)
|
||||
|
||||
# a tenant id is used when independent datasets originate from different tenants, in this example we set all tenants-ids to the same value
|
||||
training_df = spark.createDataFrame(training_pdf).withColumn("tenant_id", f.lit(0))
|
||||
ingroup_df = spark.createDataFrame(
|
||||
factory.create_clustered_intra_test_data(training_pdf)
|
||||
).withColumn("tenant_id", f.lit(0))
|
||||
outgroup_df = spark.createDataFrame(
|
||||
factory.create_clustered_inter_test_data()
|
||||
).withColumn("tenant_id", f.lit(0))
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
training_df.show()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
print(training_df.count())
|
||||
print(ingroup_df.count())
|
||||
print(outgroup_df.count())
|
||||
```
|
||||
|
||||
# Model setup & training
|
||||
|
||||
|
||||
```python
|
||||
access_anomaly = AccessAnomaly(
|
||||
tenantCol="tenant_id",
|
||||
userCol="user",
|
||||
resCol="res",
|
||||
likelihoodCol="likelihood",
|
||||
maxIter=1000,
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
model = access_anomaly.fit(training_df)
|
||||
```
|
||||
|
||||
# Apply model & show result stats
|
||||
|
||||
|
||||
```python
|
||||
ingroup_scored_df = model.transform(ingroup_df)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
ingroup_scored_df.agg(
|
||||
f.min("anomaly_score").alias("min_anomaly_score"),
|
||||
f.max("anomaly_score").alias("max_anomaly_score"),
|
||||
f.mean("anomaly_score").alias("mean_anomaly_score"),
|
||||
f.stddev("anomaly_score").alias("stddev_anomaly_score"),
|
||||
).show()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
outgroup_scored_df = model.transform(outgroup_df)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
outgroup_scored_df.agg(
|
||||
f.min("anomaly_score").alias("min_anomaly_score"),
|
||||
f.max("anomaly_score").alias("max_anomaly_score"),
|
||||
f.mean("anomaly_score").alias("mean_anomaly_score"),
|
||||
f.stddev("anomaly_score").alias("stddev_anomaly_score"),
|
||||
).show()
|
||||
```
|
||||
|
||||
# Examine results
|
||||
|
||||
|
||||
```python
|
||||
#
|
||||
# Select a subset of results to send to Log Analytics
|
||||
#
|
||||
|
||||
full_res_df = outgroup_scored_df.orderBy(f.desc("anomaly_score")).cache()
|
||||
|
||||
from pyspark.sql.window import Window
|
||||
|
||||
w = Window.partitionBy("tenant_id", "user", "res").orderBy(f.desc("anomaly_score"))
|
||||
|
||||
# select values above threshold
|
||||
results_above_threshold = full_res_df.filter(full_res_df.anomaly_score > 1.0)
|
||||
|
||||
# get distinct resource/user and corresponding timestamp and highest score
|
||||
results_to_la = (
|
||||
results_above_threshold.withColumn("index", f.row_number().over(w))
|
||||
.orderBy(f.desc("anomaly_score"))
|
||||
.select("tenant_id", f.col("user"), f.col("res"), "anomaly_score")
|
||||
.where("index == 1")
|
||||
.limit(100)
|
||||
.cache()
|
||||
)
|
||||
|
||||
# add a fake timestamp to the results
|
||||
results_to_la = results_to_la.withColumn("timestamp", f.current_timestamp())
|
||||
|
||||
display(results_to_la)
|
||||
```
|
||||
|
||||
# Display all resource accesses by users with highest anomalous score
|
||||
|
||||
|
||||
```python
|
||||
# !pip install plotly
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
from plotly import __version__
|
||||
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot, offline
|
||||
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
print(__version__) # requires version >= 1.9.0
|
||||
|
||||
# run plotly in offline mode
|
||||
offline.init_notebook_mode()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Find all server accesses of users with high predicted scores
|
||||
# For display, limit to top 25 results
|
||||
results_to_display = results_to_la.orderBy(f.desc("anomaly_score")).limit(25).cache()
|
||||
interesting_records = full_res_df.join(results_to_display, ["user"], "left_semi")
|
||||
non_anomalous_records = interesting_records.join(
|
||||
results_to_display, ["user", "res"], "left_anti"
|
||||
)
|
||||
|
||||
top_non_anomalous_records = (
|
||||
non_anomalous_records.groupBy("tenant_id", "user", "res")
|
||||
.agg(
|
||||
f.count("*").alias("count"),
|
||||
)
|
||||
.select(f.col("tenant_id"), f.col("user"), f.col("res"), "count")
|
||||
)
|
||||
|
||||
# pick only a subset of non-anomalous record for UI
|
||||
w = Window.partitionBy(
|
||||
"tenant_id",
|
||||
"user",
|
||||
).orderBy(f.desc("count"))
|
||||
|
||||
# pick top non-anomalous set
|
||||
top_non_anomalous_accesses = (
|
||||
top_non_anomalous_records.withColumn("index", f.row_number().over(w))
|
||||
.orderBy(f.desc("count"))
|
||||
.select("tenant_id", f.col("user"), f.col("res"), f.col("count"))
|
||||
.where("index in (1,2,3,4,5)")
|
||||
.limit(25)
|
||||
)
|
||||
|
||||
# add back anomalous record
|
||||
fileShare_accesses = (
|
||||
top_non_anomalous_accesses.select("user", "res", "count")
|
||||
.union(results_to_display.select("user", "res", f.lit(1).alias("count")))
|
||||
.cache()
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# get unique users and file shares
|
||||
high_scores_df = fileShare_accesses.toPandas()
|
||||
unique_arr = np.append(high_scores_df.user.unique(), high_scores_df.res.unique())
|
||||
|
||||
unique_df = pd.DataFrame(data=unique_arr, columns=["name"])
|
||||
unique_df["index"] = range(0, len(unique_df.index))
|
||||
|
||||
# create index for source & target and color for the normal accesses
|
||||
normal_line_color = "rgba(211, 211, 211, 0.8)"
|
||||
anomolous_color = "red"
|
||||
x = (
|
||||
pd.merge(high_scores_df, unique_df, how="left", left_on="user", right_on="name")
|
||||
.drop(["name"], axis=1)
|
||||
.rename(columns={"index": "userIndex"})
|
||||
)
|
||||
all_access_index_df = (
|
||||
pd.merge(x, unique_df, how="left", left_on="res", right_on="name")
|
||||
.drop(["name"], axis=1)
|
||||
.rename(columns={"index": "resIndex"})
|
||||
)
|
||||
all_access_index_df["color"] = normal_line_color
|
||||
|
||||
# results_to_display index, color and
|
||||
y = results_to_display.toPandas().drop(
|
||||
["tenant_id", "timestamp", "anomaly_score"], axis=1
|
||||
)
|
||||
y = (
|
||||
pd.merge(y, unique_df, how="left", left_on="user", right_on="name")
|
||||
.drop(["name"], axis=1)
|
||||
.rename(columns={"index": "userIndex"})
|
||||
)
|
||||
high_scores_index_df = (
|
||||
pd.merge(y, unique_df, how="left", left_on="res", right_on="name")
|
||||
.drop(["name"], axis=1)
|
||||
.rename(columns={"index": "resIndex"})
|
||||
)
|
||||
high_scores_index_df["count"] = 1
|
||||
high_scores_index_df["color"] = anomolous_color
|
||||
|
||||
# subtract 1 for the red entries in all_access df
|
||||
hsi_df = high_scores_index_df[["user", "res", "count"]].rename(
|
||||
columns={"count": "hsiCount"}
|
||||
)
|
||||
all_access_updated_count_df = pd.merge(
|
||||
all_access_index_df,
|
||||
hsi_df,
|
||||
how="left",
|
||||
left_on=["user", "res"],
|
||||
right_on=["user", "res"],
|
||||
)
|
||||
all_access_updated_count_df["count"] = np.where(
|
||||
all_access_updated_count_df["hsiCount"] == 1,
|
||||
all_access_updated_count_df["count"] - 1,
|
||||
all_access_updated_count_df["count"],
|
||||
)
|
||||
all_access_updated_count_df = all_access_updated_count_df.loc[
|
||||
all_access_updated_count_df["count"] > 0
|
||||
]
|
||||
all_access_updated_count_df = all_access_updated_count_df[
|
||||
["user", "res", "count", "userIndex", "resIndex", "color"]
|
||||
]
|
||||
|
||||
# combine the two tables
|
||||
frames = [all_access_updated_count_df, high_scores_index_df]
|
||||
display_df = pd.concat(frames, sort=True)
|
||||
# display_df.head()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
data_trace = dict(
|
||||
type="sankey",
|
||||
domain=dict(x=[0, 1], y=[0, 1]),
|
||||
orientation="h",
|
||||
valueformat=".0f",
|
||||
node=dict(
|
||||
pad=10,
|
||||
thickness=30,
|
||||
line=dict(color="black", width=0),
|
||||
label=unique_df["name"].dropna(axis=0, how="any"),
|
||||
),
|
||||
link=dict(
|
||||
source=display_df["userIndex"].dropna(axis=0, how="any"),
|
||||
target=display_df["resIndex"].dropna(axis=0, how="any"),
|
||||
value=display_df["count"].dropna(axis=0, how="any"),
|
||||
color=display_df["color"].dropna(axis=0, how="any"),
|
||||
),
|
||||
)
|
||||
|
||||
layout = dict(
|
||||
title="All resources accessed by users with highest anomalous scores",
|
||||
height=772,
|
||||
font=dict(size=10),
|
||||
)
|
||||
|
||||
fig = dict(data=[data_trace], layout=layout)
|
||||
|
||||
p = plot(fig, output_type="div")
|
||||
|
||||
if running_on_databricks():
|
||||
displayHTML(p)
|
||||
else:
|
||||
import IPython
|
||||
|
||||
IPython.display.HTML(p)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,147 @@
|
|||
---
|
||||
title: DeepLearning - Flower Image Classification
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## Deep Learning - Flower Image Classification
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.ml import Transformer, Estimator, Pipeline
|
||||
from pyspark.ml.classification import LogisticRegression
|
||||
import sys, time
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
|
||||
from synapse.ml.core.platform import running_on_synapse, running_on_databricks
|
||||
|
||||
from synapse.ml.core.platform import materializing_display as display
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# Load the images
|
||||
# use flowers_and_labels.parquet on larger cluster in order to get better results
|
||||
imagesWithLabels = (
|
||||
spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/flowers_and_labels2.parquet"
|
||||
)
|
||||
.withColumnRenamed("bytes", "image")
|
||||
.sample(0.1)
|
||||
)
|
||||
|
||||
imagesWithLabels.printSchema()
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.opencv import ImageTransformer
|
||||
from synapse.ml.image import UnrollImage
|
||||
from synapse.ml.onnx import ImageFeaturizer
|
||||
from synapse.ml.stages import *
|
||||
|
||||
# Make some featurizers
|
||||
it = ImageTransformer().setOutputCol("scaled").resize(size=(60, 60))
|
||||
|
||||
ur = UnrollImage().setInputCol("scaled").setOutputCol("features")
|
||||
|
||||
dc1 = DropColumns().setCols(["scaled", "image"])
|
||||
|
||||
lr1 = (
|
||||
LogisticRegression().setMaxIter(8).setFeaturesCol("features").setLabelCol("labels")
|
||||
)
|
||||
|
||||
dc2 = DropColumns().setCols(["features"])
|
||||
|
||||
basicModel = Pipeline(stages=[it, ur, dc1, lr1, dc2])
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
resnet = (
|
||||
ImageFeaturizer().setInputCol("image").setOutputCol("features").setModel("ResNet50")
|
||||
)
|
||||
|
||||
dc3 = DropColumns().setCols(["image"])
|
||||
|
||||
lr2 = (
|
||||
LogisticRegression().setMaxIter(8).setFeaturesCol("features").setLabelCol("labels")
|
||||
)
|
||||
|
||||
dc4 = DropColumns().setCols(["features"])
|
||||
|
||||
deepModel = Pipeline(stages=[resnet, dc3, lr2, dc4])
|
||||
```
|
||||
|
||||
|
||||
|
||||
### How does it work?
|
||||
|
||||

|
||||
|
||||
### Run the experiment
|
||||
|
||||
|
||||
```python
|
||||
def timedExperiment(model, train, test):
|
||||
start = time.time()
|
||||
result = model.fit(train).transform(test).toPandas()
|
||||
print("Experiment took {}s".format(time.time() - start))
|
||||
return result
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
train, test = imagesWithLabels.randomSplit([0.8, 0.2])
|
||||
train.count(), test.count()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
basicResults = timedExperiment(basicModel, train, test)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
deepResults = timedExperiment(deepModel, train, test)
|
||||
```
|
||||
|
||||
### Plot confusion matrix.
|
||||
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
from sklearn.metrics import confusion_matrix
|
||||
import numpy as np
|
||||
|
||||
|
||||
def evaluate(results, name):
|
||||
y, y_hat = results["labels"], results["prediction"]
|
||||
y = [int(l) for l in y]
|
||||
|
||||
accuracy = np.mean([1.0 if pred == true else 0.0 for (pred, true) in zip(y_hat, y)])
|
||||
cm = confusion_matrix(y, y_hat)
|
||||
cm = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis]
|
||||
|
||||
plt.text(
|
||||
40, 10, "$Accuracy$ $=$ ${}\%$".format(round(accuracy * 100, 1)), fontsize=14
|
||||
)
|
||||
plt.imshow(cm, interpolation="nearest", cmap=plt.cm.Blues)
|
||||
plt.colorbar()
|
||||
plt.xlabel("$Predicted$ $label$", fontsize=18)
|
||||
plt.ylabel("$True$ $Label$", fontsize=18)
|
||||
plt.title("$Normalized$ $CM$ $for$ ${}$".format(name))
|
||||
|
||||
|
||||
plt.figure(figsize=(12, 5))
|
||||
plt.subplot(1, 2, 1)
|
||||
evaluate(deepResults, "CNTKModel + LR")
|
||||
plt.subplot(1, 2, 2)
|
||||
evaluate(basicResults, "LR")
|
||||
# Note that on the larger dataset the accuracy will bump up from 44% to >90%
|
||||
display(plt.show())
|
||||
```
|
||||
|
|
@ -0,0 +1,105 @@
|
|||
---
|
||||
title: HyperParameterTuning - Fighting Breast Cancer
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## HyperParameterTuning - Fighting Breast Cancer
|
||||
|
||||
We can do distributed randomized grid search hyperparameter tuning with SynapseML.
|
||||
|
||||
First, we import the packages
|
||||
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
Now let's read the data and split it to tuning and test sets:
|
||||
|
||||
|
||||
```python
|
||||
data = spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/BreastCancer.parquet"
|
||||
).cache()
|
||||
tune, test = data.randomSplit([0.80, 0.20])
|
||||
tune.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Next, define the models that will be tuned:
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.automl import TuneHyperparameters
|
||||
from synapse.ml.train import TrainClassifier
|
||||
from pyspark.ml.classification import (
|
||||
LogisticRegression,
|
||||
RandomForestClassifier,
|
||||
GBTClassifier,
|
||||
)
|
||||
|
||||
logReg = LogisticRegression()
|
||||
randForest = RandomForestClassifier()
|
||||
gbt = GBTClassifier()
|
||||
smlmodels = [logReg, randForest, gbt]
|
||||
mmlmodels = [TrainClassifier(model=model, labelCol="Label") for model in smlmodels]
|
||||
```
|
||||
|
||||
We can specify the hyperparameters using the HyperparamBuilder.
|
||||
We can add either DiscreteHyperParam or RangeHyperParam hyperparameters.
|
||||
TuneHyperparameters will randomly choose values from a uniform distribution.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.automl import *
|
||||
|
||||
paramBuilder = (
|
||||
HyperparamBuilder()
|
||||
.addHyperparam(logReg, logReg.regParam, RangeHyperParam(0.1, 0.3))
|
||||
.addHyperparam(randForest, randForest.numTrees, DiscreteHyperParam([5, 10]))
|
||||
.addHyperparam(randForest, randForest.maxDepth, DiscreteHyperParam([3, 5]))
|
||||
.addHyperparam(gbt, gbt.maxBins, RangeHyperParam(8, 16))
|
||||
.addHyperparam(gbt, gbt.maxDepth, DiscreteHyperParam([3, 5]))
|
||||
)
|
||||
searchSpace = paramBuilder.build()
|
||||
# The search space is a list of params to tuples of estimator and hyperparam
|
||||
print(searchSpace)
|
||||
randomSpace = RandomSpace(searchSpace)
|
||||
```
|
||||
|
||||
Next, run TuneHyperparameters to get the best model.
|
||||
|
||||
|
||||
```python
|
||||
bestModel = TuneHyperparameters(
|
||||
evaluationMetric="accuracy",
|
||||
models=mmlmodels,
|
||||
numFolds=2,
|
||||
numRuns=len(mmlmodels) * 2,
|
||||
parallelism=1,
|
||||
paramSpace=randomSpace.space(),
|
||||
seed=0,
|
||||
).fit(tune)
|
||||
```
|
||||
|
||||
We can view the best model's parameters and retrieve the underlying best model pipeline
|
||||
|
||||
|
||||
```python
|
||||
print(bestModel.getBestModelInfo())
|
||||
print(bestModel.getBestModel())
|
||||
```
|
||||
|
||||
We can score against the test set and view metrics.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
|
||||
prediction = bestModel.transform(test)
|
||||
metrics = ComputeModelStatistics().transform(prediction)
|
||||
metrics.limit(10).toPandas()
|
||||
```
|
||||
|
|
@ -0,0 +1,228 @@
|
|||
---
|
||||
title: Regression - Auto Imports
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## Regression - Auto Imports
|
||||
|
||||
This sample notebook is based on the Gallery [Sample 6: Train, Test, Evaluate
|
||||
for Regression: Auto Imports
|
||||
Dataset](https://gallery.cortanaintelligence.com/Experiment/670fbfc40c4f44438bfe72e47432ae7a)
|
||||
for AzureML Studio. This experiment demonstrates how to build a regression
|
||||
model to predict the automobile's price. The process includes training, testing,
|
||||
and evaluating the model on the Automobile Imports data set.
|
||||
|
||||
This sample demonstrates the use of several members of the synapseml library:
|
||||
- [`TrainRegressor`
|
||||
](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.train.html?#module-synapse.ml.train.TrainRegressor)
|
||||
- [`SummarizeData`
|
||||
](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.stages.html?#module-synapse.ml.stages.SummarizeData)
|
||||
- [`CleanMissingData`
|
||||
](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.featurize.html?#module-synapse.ml.featurize.CleanMissingData)
|
||||
- [`ComputeModelStatistics`
|
||||
](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.train.html?#module-synapse.ml.train.ComputeModelStatistics)
|
||||
- [`FindBestModel`
|
||||
](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.automl.html?#module-synapse.ml.automl.FindBestModel)
|
||||
|
||||
First, import the pandas package so that we can read and parse the datafile
|
||||
using `pandas.read_csv()`
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
data = spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/AutomobilePriceRaw.parquet"
|
||||
)
|
||||
```
|
||||
|
||||
To learn more about the data that was just read into the DataFrame,
|
||||
summarize the data using `SummarizeData` and print the summary. For each
|
||||
column of the DataFrame, `SummarizeData` will report the summary statistics
|
||||
in the following subcategories for each column:
|
||||
* Feature name
|
||||
* Counts
|
||||
- Count
|
||||
- Unique Value Count
|
||||
- Missing Value Count
|
||||
* Quantiles
|
||||
- Min
|
||||
- 1st Quartile
|
||||
- Median
|
||||
- 3rd Quartile
|
||||
- Max
|
||||
* Sample Statistics
|
||||
- Sample Variance
|
||||
- Sample Standard Deviation
|
||||
- Sample Skewness
|
||||
- Sample Kurtosis
|
||||
* Percentiles
|
||||
- P0.5
|
||||
- P1
|
||||
- P5
|
||||
- P95
|
||||
- P99
|
||||
- P99.5
|
||||
|
||||
Note that several columns have missing values (`normalized-losses`, `bore`,
|
||||
`stroke`, `horsepower`, `peak-rpm`, `price`). This summary can be very
|
||||
useful during the initial phases of data discovery and characterization.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.stages import SummarizeData
|
||||
|
||||
summary = SummarizeData().transform(data)
|
||||
summary.toPandas()
|
||||
```
|
||||
|
||||
Split the dataset into train and test datasets.
|
||||
|
||||
|
||||
```python
|
||||
# split the data into training and testing datasets
|
||||
train, test = data.randomSplit([0.6, 0.4], seed=123)
|
||||
train.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Now use the `CleanMissingData` API to replace the missing values in the
|
||||
dataset with something more useful or meaningful. Specify a list of columns
|
||||
to be cleaned, and specify the corresponding output column names, which are
|
||||
not required to be the same as the input column names. `CleanMissiongData`
|
||||
offers the options of "Mean", "Median", or "Custom" for the replacement
|
||||
value. In the case of "Custom" value, the user also specifies the value to
|
||||
use via the "customValue" parameter. In this example, we will replace
|
||||
missing values in numeric columns with the median value for the column. We
|
||||
will define the model here, then use it as a Pipeline stage when we train our
|
||||
regression models and make our predictions in the following steps.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize import CleanMissingData
|
||||
|
||||
cols = ["normalized-losses", "stroke", "bore", "horsepower", "peak-rpm", "price"]
|
||||
cleanModel = (
|
||||
CleanMissingData().setCleaningMode("Median").setInputCols(cols).setOutputCols(cols)
|
||||
)
|
||||
```
|
||||
|
||||
Now we will create two Regressor models for comparison: Poisson Regression
|
||||
and Random Forest. PySpark has several regressors implemented:
|
||||
* `LinearRegression`
|
||||
* `IsotonicRegression`
|
||||
* `DecisionTreeRegressor`
|
||||
* `RandomForestRegressor`
|
||||
* `GBTRegressor` (Gradient-Boosted Trees)
|
||||
* `AFTSurvivalRegression` (Accelerated Failure Time Model Survival)
|
||||
* `GeneralizedLinearRegression` -- fit a generalized model by giving symbolic
|
||||
description of the linear predictor (link function) and a description of the
|
||||
error distribution (family). The following families are supported:
|
||||
- `Gaussian`
|
||||
- `Binomial`
|
||||
- `Poisson`
|
||||
- `Gamma`
|
||||
- `Tweedie` -- power link function specified through `linkPower`
|
||||
Refer to the
|
||||
[Pyspark API Documentation](http://spark.apache.org/docs/latest/api/python/)
|
||||
for more details.
|
||||
|
||||
`TrainRegressor` creates a model based on the regressor and other parameters
|
||||
that are supplied to it, then trains data on the model.
|
||||
|
||||
In this next step, Create a Poisson Regression model using the
|
||||
`GeneralizedLinearRegressor` API from Spark and create a Pipeline using the
|
||||
`CleanMissingData` and `TrainRegressor` as pipeline stages to create and
|
||||
train the model. Note that because `TrainRegressor` expects a `labelCol` to
|
||||
be set, there is no need to set `linkPredictionCol` when setting up the
|
||||
`GeneralizedLinearRegressor`. Fitting the pipe on the training dataset will
|
||||
train the model. Applying the `transform()` of the pipe to the test dataset
|
||||
creates the predictions.
|
||||
|
||||
|
||||
```python
|
||||
# train Poisson Regression Model
|
||||
from pyspark.ml.regression import GeneralizedLinearRegression
|
||||
from pyspark.ml import Pipeline
|
||||
from synapse.ml.train import TrainRegressor
|
||||
|
||||
glr = GeneralizedLinearRegression(family="poisson", link="log")
|
||||
poissonModel = TrainRegressor().setModel(glr).setLabelCol("price").setNumFeatures(256)
|
||||
poissonPipe = Pipeline(stages=[cleanModel, poissonModel]).fit(train)
|
||||
poissonPrediction = poissonPipe.transform(test)
|
||||
```
|
||||
|
||||
Next, repeat these steps to create a Random Forest Regression model using the
|
||||
`RandomRorestRegressor` API from Spark.
|
||||
|
||||
|
||||
```python
|
||||
# train Random Forest regression on the same training data:
|
||||
from pyspark.ml.regression import RandomForestRegressor
|
||||
|
||||
rfr = RandomForestRegressor(maxDepth=30, maxBins=128, numTrees=8, minInstancesPerNode=1)
|
||||
randomForestModel = TrainRegressor(model=rfr, labelCol="price", numFeatures=256).fit(
|
||||
train
|
||||
)
|
||||
randomForestPipe = Pipeline(stages=[cleanModel, randomForestModel]).fit(train)
|
||||
randomForestPrediction = randomForestPipe.transform(test)
|
||||
```
|
||||
|
||||
After the models have been trained and scored, compute some basic statistics
|
||||
to evaluate the predictions. The following statistics are calculated for
|
||||
regression models to evaluate:
|
||||
* Mean squared error
|
||||
* Root mean squared error
|
||||
* R^2
|
||||
* Mean absolute error
|
||||
|
||||
Use the `ComputeModelStatistics` API to compute basic statistics for
|
||||
the Poisson and the Random Forest models.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
|
||||
poissonMetrics = ComputeModelStatistics().transform(poissonPrediction)
|
||||
print("Poisson Metrics")
|
||||
poissonMetrics.toPandas()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
randomForestMetrics = ComputeModelStatistics().transform(randomForestPrediction)
|
||||
print("Random Forest Metrics")
|
||||
randomForestMetrics.toPandas()
|
||||
```
|
||||
|
||||
We can also compute per instance statistics for `poissonPrediction`:
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputePerInstanceStatistics
|
||||
|
||||
|
||||
def demonstrateEvalPerInstance(pred):
|
||||
return (
|
||||
ComputePerInstanceStatistics()
|
||||
.transform(pred)
|
||||
.select("price", "prediction", "L1_loss", "L2_loss")
|
||||
.limit(10)
|
||||
.toPandas()
|
||||
)
|
||||
|
||||
|
||||
demonstrateEvalPerInstance(poissonPrediction)
|
||||
```
|
||||
|
||||
and with `randomForestPrediction`:
|
||||
|
||||
|
||||
```python
|
||||
demonstrateEvalPerInstance(randomForestPrediction)
|
||||
```
|
||||
|
|
@ -0,0 +1,166 @@
|
|||
---
|
||||
title: Regression - Flight Delays with DataCleaning
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## Regression - Flight Delays with DataCleaning
|
||||
|
||||
This example notebook is similar to
|
||||
[Regression - Flight Delays](https://github.com/microsoft/SynapseML/blob/master/notebooks/Regression%20-%20Flight%20Delays.ipynb).
|
||||
In this example, we will demonstrate the use of `DataConversion()` in two
|
||||
ways. First, to convert the data type of several columns after the dataset
|
||||
has been read in to the Spark DataFrame instead of specifying the data types
|
||||
as the file is read in. Second, to convert columns to categorical columns
|
||||
instead of iterating over the columns and applying the `StringIndexer`.
|
||||
|
||||
This sample demonstrates how to use the following APIs:
|
||||
- [`TrainRegressor`
|
||||
](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.train.html?#module-synapse.ml.train.TrainRegressor)
|
||||
- [`ComputePerInstanceStatistics`
|
||||
](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.train.html?#module-synapse.ml.train.ComputePerInstanceStatistics)
|
||||
- [`DataConversion`
|
||||
](https://mmlspark.blob.core.windows.net/docs/0.11.2/pyspark/synapse.ml.featurize.html?#module-synapse.ml.featurize.DataConversion)
|
||||
|
||||
First, import the pandas package
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
```
|
||||
|
||||
Next, import the CSV dataset: retrieve the file if needed, save it locally,
|
||||
read the data into a pandas dataframe via `read_csv()`, then convert it to
|
||||
a Spark dataframe.
|
||||
|
||||
Print the schema of the dataframe, and note the columns that are `long`.
|
||||
|
||||
|
||||
```python
|
||||
flightDelay = spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/On_Time_Performance_2012_9.parquet"
|
||||
)
|
||||
# print some basic info
|
||||
print("records read: " + str(flightDelay.count()))
|
||||
print("Schema: ")
|
||||
flightDelay.printSchema()
|
||||
flightDelay.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Use the `DataConversion` transform API to convert the columns listed to
|
||||
double.
|
||||
|
||||
The `DataConversion` API accepts the following types for the `convertTo`
|
||||
parameter:
|
||||
* `boolean`
|
||||
* `byte`
|
||||
* `short`
|
||||
* `integer`
|
||||
* `long`
|
||||
* `float`
|
||||
* `double`
|
||||
* `string`
|
||||
* `toCategorical`
|
||||
* `clearCategorical`
|
||||
* `date` -- converts a string or long to a date of the format
|
||||
"yyyy-MM-dd HH:mm:ss" unless another format is specified by
|
||||
the `dateTimeFormat` parameter.
|
||||
|
||||
Again, print the schema and note that the columns are now `double`
|
||||
instead of long.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.featurize import DataConversion
|
||||
|
||||
flightDelay = DataConversion(
|
||||
cols=[
|
||||
"Quarter",
|
||||
"Month",
|
||||
"DayofMonth",
|
||||
"DayOfWeek",
|
||||
"OriginAirportID",
|
||||
"DestAirportID",
|
||||
"CRSDepTime",
|
||||
"CRSArrTime",
|
||||
],
|
||||
convertTo="double",
|
||||
).transform(flightDelay)
|
||||
flightDelay.printSchema()
|
||||
flightDelay.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Split the dataset into train and test sets.
|
||||
|
||||
|
||||
```python
|
||||
train, test = flightDelay.randomSplit([0.75, 0.25])
|
||||
```
|
||||
|
||||
Create a regressor model and train it on the dataset.
|
||||
|
||||
First, use `DataConversion` to convert the columns `Carrier`, `DepTimeBlk`,
|
||||
and `ArrTimeBlk` to categorical data. Recall that in Notebook 102, this
|
||||
was accomplished by iterating over the columns and converting the strings
|
||||
to index values using the `StringIndexer` API. The `DataConversion` API
|
||||
simplifies the task by allowing you to specify all columns that will have
|
||||
the same end type in a single command.
|
||||
|
||||
Create a LinearRegression model using the Limited-memory BFGS solver
|
||||
(`l-bfgs`), an `ElasticNet` mixing parameter of `0.3`, and a `Regularization`
|
||||
of `0.1`.
|
||||
|
||||
Train the model with the `TrainRegressor` API fit on the training dataset.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import TrainRegressor, TrainedRegressorModel
|
||||
from pyspark.ml.regression import LinearRegression
|
||||
|
||||
trainCat = DataConversion(
|
||||
cols=["Carrier", "DepTimeBlk", "ArrTimeBlk"], convertTo="toCategorical"
|
||||
).transform(train)
|
||||
testCat = DataConversion(
|
||||
cols=["Carrier", "DepTimeBlk", "ArrTimeBlk"], convertTo="toCategorical"
|
||||
).transform(test)
|
||||
lr = LinearRegression().setRegParam(0.1).setElasticNetParam(0.3)
|
||||
model = TrainRegressor(model=lr, labelCol="ArrDelay").fit(trainCat)
|
||||
```
|
||||
|
||||
Score the regressor on the test data.
|
||||
|
||||
|
||||
```python
|
||||
scoredData = model.transform(testCat)
|
||||
scoredData.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Compute model metrics against the entire scored dataset
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
|
||||
metrics = ComputeModelStatistics().transform(scoredData)
|
||||
metrics.toPandas()
|
||||
```
|
||||
|
||||
Finally, compute and show statistics on individual predictions in the test
|
||||
dataset, demonstrating the usage of `ComputePerInstanceStatistics`
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputePerInstanceStatistics
|
||||
|
||||
evalPerInstance = ComputePerInstanceStatistics().transform(scoredData)
|
||||
evalPerInstance.select("ArrDelay", "prediction", "L1_loss", "L2_loss").limit(
|
||||
10
|
||||
).toPandas()
|
||||
```
|
||||
|
|
@ -0,0 +1,121 @@
|
|||
---
|
||||
title: Regression - Flight Delays
|
||||
hide_title: true
|
||||
status: stable
|
||||
---
|
||||
## Regression - Flight Delays
|
||||
|
||||
In this example, we run a linear regression on the *Flight Delay* dataset to predict the delay times.
|
||||
|
||||
We demonstrate how to use the `TrainRegressor` and the `ComputePerInstanceStatistics` APIs.
|
||||
|
||||
First, import the packages.
|
||||
|
||||
|
||||
```python
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
# Bootstrap Spark Session
|
||||
spark = SparkSession.builder.getOrCreate()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
import synapse.ml
|
||||
```
|
||||
|
||||
Next, import the CSV dataset.
|
||||
|
||||
|
||||
```python
|
||||
flightDelay = spark.read.parquet(
|
||||
"wasbs://publicwasb@mmlspark.blob.core.windows.net/On_Time_Performance_2012_9.parquet"
|
||||
)
|
||||
# print some basic info
|
||||
print("records read: " + str(flightDelay.count()))
|
||||
print("Schema: ")
|
||||
flightDelay.printSchema()
|
||||
flightDelay.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Split the dataset into train and test sets.
|
||||
|
||||
|
||||
```python
|
||||
train, test = flightDelay.randomSplit([0.75, 0.25])
|
||||
```
|
||||
|
||||
Train a regressor on dataset with `l-bfgs`.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import TrainRegressor, TrainedRegressorModel
|
||||
from pyspark.ml.regression import LinearRegression
|
||||
from pyspark.ml.feature import StringIndexer
|
||||
|
||||
# Convert columns to categorical
|
||||
catCols = ["Carrier", "DepTimeBlk", "ArrTimeBlk"]
|
||||
trainCat = train
|
||||
testCat = test
|
||||
for catCol in catCols:
|
||||
simodel = StringIndexer(inputCol=catCol, outputCol=catCol + "Tmp").fit(train)
|
||||
trainCat = (
|
||||
simodel.transform(trainCat)
|
||||
.drop(catCol)
|
||||
.withColumnRenamed(catCol + "Tmp", catCol)
|
||||
)
|
||||
testCat = (
|
||||
simodel.transform(testCat)
|
||||
.drop(catCol)
|
||||
.withColumnRenamed(catCol + "Tmp", catCol)
|
||||
)
|
||||
lr = LinearRegression().setRegParam(0.1).setElasticNetParam(0.3)
|
||||
model = TrainRegressor(model=lr, labelCol="ArrDelay").fit(trainCat)
|
||||
```
|
||||
|
||||
Save, load, or Score the regressor on the test data.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.core.platform import *
|
||||
|
||||
if running_on_synapse():
|
||||
model_name = "/models/flightDelayModel.mml"
|
||||
elif running_on_synapse_internal():
|
||||
model_name = "Files/models/flightDelayModel.mml"
|
||||
elif running_on_databricks():
|
||||
model_name = "dbfs:/flightDelayModel.mml"
|
||||
else:
|
||||
model_name = "/tmp/flightDelayModel.mml"
|
||||
|
||||
model.write().overwrite().save(model_name)
|
||||
flightDelayModel = TrainedRegressorModel.load(model_name)
|
||||
|
||||
scoredData = flightDelayModel.transform(testCat)
|
||||
scoredData.limit(10).toPandas()
|
||||
```
|
||||
|
||||
Compute model metrics against the entire scored dataset
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputeModelStatistics
|
||||
|
||||
metrics = ComputeModelStatistics().transform(scoredData)
|
||||
metrics.toPandas()
|
||||
```
|
||||
|
||||
Finally, compute and show per-instance statistics, demonstrating the usage
|
||||
of `ComputePerInstanceStatistics`.
|
||||
|
||||
|
||||
```python
|
||||
from synapse.ml.train import ComputePerInstanceStatistics
|
||||
|
||||
evalPerInstance = ComputePerInstanceStatistics().transform(scoredData)
|
||||
evalPerInstance.select("ArrDelay", "prediction", "L1_loss", "L2_loss").limit(
|
||||
10
|
||||
).toPandas()
|
||||
```
|
||||
Некоторые файлы не были показаны из-за слишком большого количества измененных файлов Показать больше
Загрузка…
Ссылка в новой задаче