update TableFT task experimental code and model weights.
This commit is contained in:
Родитель
c23dd46ed1
Коммит
d3737c9868
|
|
@ -4,7 +4,8 @@ The official repository which contains the code and pre-trained models for our p
|
|||
|
||||
# 🔥 Updates
|
||||
|
||||
- **2021-08-28**: We released the fine-tuned model weights on SQA and WikiTableQuestions!
|
||||
- **2021-10-01**: We released the code for TableFT and the fine-tuned model weights on TabFact!
|
||||
- **2021-08-28**: We released the fine-tuned model weights on WikiSQL, SQA and WikiTableQuestions!
|
||||
- **2021-08-27**: We released the code, the pre-training corpus, and the pre-trained TAPEX model weights. Thanks for your patience!
|
||||
- **2021-07-16**: We released our [paper](https://arxiv.org/pdf/2107.07653.pdf) and [home page](https://table-pretraining.github.io/). Check it out!
|
||||
|
||||
|
|
@ -126,6 +127,7 @@ Model | Dev Acc | Test Acc | Dataset | Download Data | Download Model
|
|||
`tapex.large.wtq` | 58.0 | 57.2 | WikiTableQuestions | [wtq.preprocessed.zip](https://github.com/microsoft/Table-Pretraining/releases/download/preprocessed-data/wtq.preprocessed.zip) | [tapex.large.wtq.tar.gz](https://github.com/microsoft/Table-Pretraining/releases/download/fine-tuned-model/tapex.large.wtq.tar.gz)
|
||||
`tapex.large.sqa` | 70.7 | 74.0 | SQA | [sqa.preprocessed.zip](https://github.com/microsoft/Table-Pretraining/releases/download/preprocessed-data/sqa.preprocessed.zip) | [tapex.large.sqa.tar.gz](https://github.com/microsoft/Table-Pretraining/releases/download/fine-tuned-model/tapex.large.sqa.tar.gz)
|
||||
`tapex.large.wikisql` | 89.3 | 89.2 | WikiSQL | [wikisql.preprocessed.zip](https://github.com/microsoft/Table-Pretraining/releases/download/preprocessed-data/wikisql.preprocessed.zip) | [tapex.large.wikisql.tar.gz](https://github.com/microsoft/Table-Pretraining/releases/download/fine-tuned-model/tapex.large.wikisql.tar.gz)
|
||||
`tapex.large.tabfact` | 84.2 | 84.0 | TabFact | [tabfact.preprocessed.zip](https://github.com/microsoft/Table-Pretraining/releases/download/preprocessed-data/tabfact.preprocessed.zip) | [tapex.large.tabfact.tar.gz](https://github.com/microsoft/Table-Pretraining/releases/download/fine-tuned-model/tapex.large.tabfact.tar.gz)
|
||||
|
||||
Given these fine-tuned model weights, you can play with them using the `predict` mode in `examples/tableqa/run_model.py`.
|
||||
|
||||
|
|
|
|||
|
|
@ -120,8 +120,86 @@ $ python run_model.py predict --resource-dir <resource_dir> --checkpoint-name <m
|
|||
```
|
||||
> Note that if <resource_dir> is under the current working directory, you should still specify a prefix `./` to make the path like a local path (e.g., ./tapex.base). Otherwise, fairseq will regard it as a model name.
|
||||
|
||||
## 🔎 Table Fact Verification (Released by Sep. 5)
|
||||
## 🔎 Table Fact Verification
|
||||
|
||||
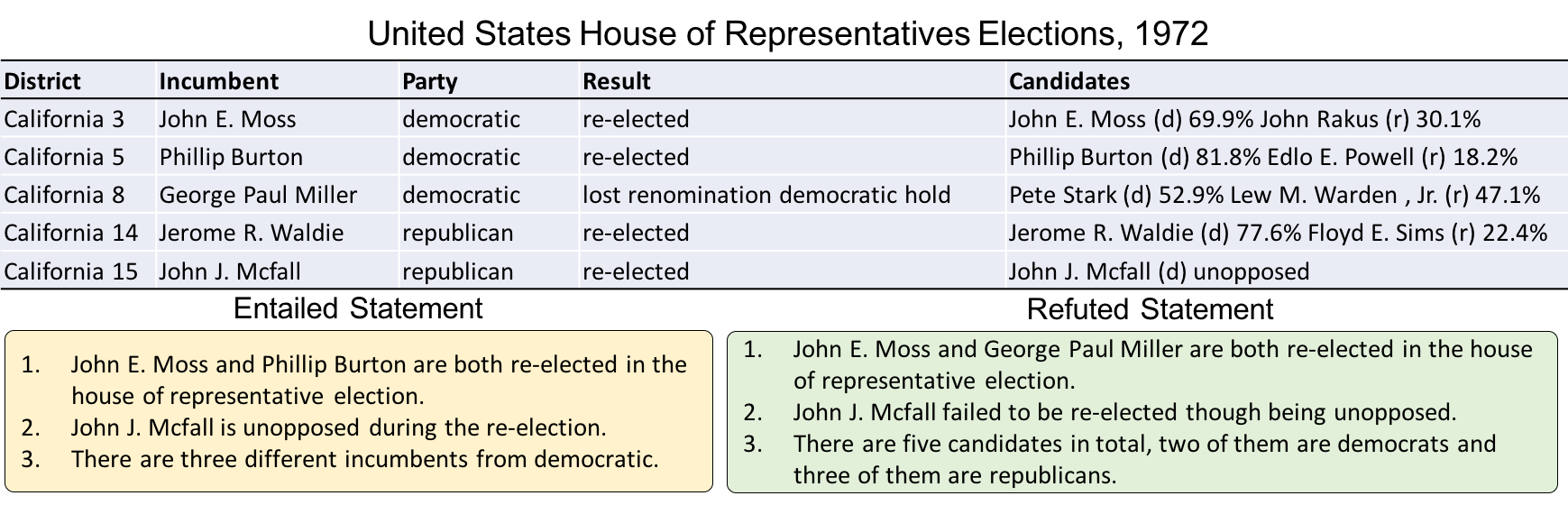
|
||||
|
||||
The preprocessing script of table fact verification is a little complicated, and we're still refactoring the code. Please stay tuned!
|
||||
### 🍲 Dataset
|
||||
|
||||
In this project, following the practise of BART on sequence classification tasks, we feed the same input to the encoder and the decoder of TAPEX, and build a binary classifier on top of the hidden state of the last token in the decoder to output `0` or `1`.
|
||||
Similar to the one in TableQA, the first step is to convert the original dataset into a compatiable format with fairseq.
|
||||
|
||||
Now we support the **one-stop services** for the following datasets, and you can simply run the linked script to accomplish the dataset preparation.
|
||||
- [TabFact (Chen et al., 2020)](tableft/process_tabfact_data.py)
|
||||
|
||||
Note that the one-stop service includes the procedure of downloading datasets and pretrained tapex models, truncating long inputs, converting to the fairseq sentence classification format, applying BPE tokenization and preprocessing for fairseq model training.
|
||||
|
||||
By default, these scripts will process data using the dictionary of `tapex.base`. If you want to switch pre-trained models, please change the variable `MODLE_NAME` at line 21.
|
||||
|
||||
After one dataset is prepared, you can run the `tableft/run_model.py` script to train your TableFT models.
|
||||
|
||||
### 🍳 Train
|
||||
|
||||
To train a model, you could simply run the following command, where:
|
||||
- `<dataset_dir>` refers to directory which contains a `input0` and a `label` folder such as `dataset/tabfact/tapex.base`
|
||||
- `<model_path>` refers to a pre-trained model path such as `tapex.base/model.pt`
|
||||
- `<model_arch>` is a pre-defined model architecture in fairseq such as `bart_base`.
|
||||
|
||||
**HINT**:
|
||||
- for `tapex.base` or `tapex.large`, `<model_arch>` should be `bart_base` or `bart_large` respectively.
|
||||
- the reported `accuracy` metric during training is the offcial binary classification accuracy defined in TabFact.
|
||||
|
||||
```shell
|
||||
$ python run_model.py train --dataset-dir <dataset_dir> --model-path <model_path> --model-arch <model_arch>
|
||||
```
|
||||
|
||||
A full list of training arguments can be seen as below:
|
||||
|
||||
```
|
||||
--dataset-dir DATASET_DIR
|
||||
dataset directory where train.src is located in
|
||||
--exp-dir EXP_DIR
|
||||
experiment directory which stores the checkpoint
|
||||
weights
|
||||
--model-path MODEL_PATH
|
||||
the directory of pre-trained model path
|
||||
--model-arch {bart_large,bart_base}
|
||||
tapex large should correspond to bart_large, and tapex base should be bart_base
|
||||
--max-tokens MAX_TOKENS
|
||||
if you train a large model on 16GB memory, max-tokens
|
||||
should be empirically set as 1536, and can be near-
|
||||
linearly increased according to your GPU memory.
|
||||
--gradient-accumulation GRADIENT_ACCUMULATION
|
||||
the accumulation steps to arrive a equal batch size,
|
||||
the default value can be usedto reproduce our results.
|
||||
And you can also reduce it to a proper value for you.
|
||||
--total-num-update TOTAL_NUM_UPDATE
|
||||
the total optimization training steps
|
||||
--learning-rate LEARNING_RATE
|
||||
the peak learning rate for model training
|
||||
```
|
||||
|
||||
### 🍪 Evaluate
|
||||
|
||||
Once the model is fine-tuned, we can evaluate it by running the following command, where:
|
||||
- `<dataset_dir>` refers to directory which contains a `.input0` and a `.label` file such as `dataset/tabfact`. **ATTENTION, THIS IS NOT THE SAME AS IN TABLEQA**.
|
||||
- `<model_dir>` refers to directory which contains a fine-tuned model as `model.pt` such as `checkpoints`.
|
||||
- `<sub_dir>` refers to `valid`, `test`, `test_simple`, `test_complex`, `test_small` for different testing.
|
||||
|
||||
```shell
|
||||
$ python run_model.py eval --dataset-dir <dataset_dir> --model-dir <model_dir> --sub-dir <sub_dir>
|
||||
```
|
||||
|
||||
A full list of evaluating arguments can be seen as below:
|
||||
|
||||
```
|
||||
--dataset-dir DATASET_DIR
|
||||
dataset directory where train.src is located in
|
||||
--model-dir MODEL_DIR
|
||||
the directory of fine-tuned model path such as
|
||||
wikisql.tapex.base
|
||||
--sub-dir {train,valid,test,test_complex,test_simple,test_small}
|
||||
the directory of pre-trained model path, and the
|
||||
default should be in{bart.base, bart.large,
|
||||
tapex.base, tapex.large}.
|
||||
```
|
||||
|
|
|
|||
|
|
@ -0,0 +1,128 @@
|
|||
# Copyright (c) Microsoft Corporation.
|
||||
# Licensed under the MIT license.
|
||||
|
||||
import os
|
||||
import shutil
|
||||
import zipfile
|
||||
import logging
|
||||
from tqdm import tqdm
|
||||
import json
|
||||
from tapex.common.download import download_file
|
||||
from tapex.processor import get_default_processor
|
||||
from tapex.data_utils.preprocess_bpe import fairseq_bpe_classification
|
||||
from tapex.data_utils.preprocess_binary import fairseq_binary_classification
|
||||
from typing import List
|
||||
|
||||
RAW_DATASET_FOLDER = "raw_dataset"
|
||||
PROCESSED_DATASET_FOLDER = "dataset"
|
||||
TABLE_PATH = os.path.join(RAW_DATASET_FOLDER, "tabfact")
|
||||
TABLE_PROCESSOR = get_default_processor(max_cell_length=15, max_input_length=1024)
|
||||
# Options: bart.base, bart.large, tapex.base, tapex.large
|
||||
MODEL_NAME = "tapex.base"
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def download_tabfact():
|
||||
"""
|
||||
Download WikiTableQuestion dataset and unzip the files
|
||||
"""
|
||||
tabfact_url = "https://github.com/microsoft/Table-Pretraining/"\
|
||||
"releases/download/origin-data/tabfact.zip"
|
||||
tabfact_raw_path = os.path.join(RAW_DATASET_FOLDER, "tabfact")
|
||||
tabfact_zip_file = download_file(tabfact_url)
|
||||
# unzip and move it into raw_dataset folder
|
||||
with zipfile.ZipFile(tabfact_zip_file) as zf:
|
||||
zf.extractall(RAW_DATASET_FOLDER)
|
||||
unzip_tabfact_path = os.path.join(RAW_DATASET_FOLDER, "TabFact")
|
||||
shutil.move(unzip_tabfact_path, tabfact_raw_path)
|
||||
# remove the original file
|
||||
os.remove(tabfact_zip_file)
|
||||
return tabfact_raw_path
|
||||
|
||||
|
||||
def split_fine_grained_test(data_dir):
|
||||
test_examples = [json.loads(line)
|
||||
for line in open(os.path.join(data_dir, "test.jsonl"), "r", encoding="utf8").readlines()]
|
||||
split_modes = ["complex", "simple", "small"]
|
||||
for split_mode in split_modes:
|
||||
valid_id_list = json.load(open(os.path.join(data_dir, split_mode + ".json"),
|
||||
"r", encoding="utf8"))
|
||||
valid_examples = [example for example in test_examples if example["table_id"] in valid_id_list]
|
||||
save_test_path = os.path.join(data_dir, "%s.jsonl" % ("test_" + split_mode))
|
||||
with open(save_test_path, "w", encoding="utf8") as save_f:
|
||||
for example in valid_examples:
|
||||
save_f.write(json.dumps(example) + "\n")
|
||||
|
||||
|
||||
def build_tabfact_fairseq_dataset(out_prefix, src_file, data_dir):
|
||||
if not os.path.exists(data_dir):
|
||||
os.makedirs(data_dir)
|
||||
|
||||
def _read_table(_tabfact_example: List):
|
||||
header = _tabfact_example[0]
|
||||
rows = _tabfact_example[1:]
|
||||
|
||||
return {
|
||||
"header": header,
|
||||
"rows": rows
|
||||
}
|
||||
|
||||
input_f = open("{}/{}.raw.input0".format(data_dir, out_prefix), "w", encoding="utf8")
|
||||
output_f = open("{}/{}.label".format(data_dir, out_prefix), "w", encoding="utf8")
|
||||
|
||||
lines = open(src_file, "r", encoding="utf8").readlines()
|
||||
for line in lines:
|
||||
line = line.strip()
|
||||
example = json.loads(line)
|
||||
sentence = example['statement'].lower()
|
||||
label = example['label']
|
||||
table_content = _read_table(example['table_text'])
|
||||
input_source = TABLE_PROCESSOR.process_input(table_content, sentence, []).lower()
|
||||
# Here we use the paradigm of BART to conduct classification on TabFact.
|
||||
# Therefore, the output should be a label rather than a text.
|
||||
output_target = str(label)
|
||||
input_f.write(input_source + "\n")
|
||||
output_f.write(output_target + "\n")
|
||||
|
||||
input_f.close()
|
||||
output_f.close()
|
||||
|
||||
|
||||
def preprocess_tabfact_dataset(processed_data_dir):
|
||||
fairseq_bpe_classification(processed_data_dir, resource_name=MODEL_NAME)
|
||||
fairseq_binary_classification(processed_data_dir, resource_name=MODEL_NAME)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
logger.info("You are using the setting of {}".format(MODEL_NAME))
|
||||
|
||||
logger.info("*" * 80)
|
||||
logger.info("Prepare to download preprocessed TabFact json line file from our released link...")
|
||||
tabfact_raw_data_dir = download_tabfact()
|
||||
|
||||
logger.info("Download finished! The original TabFact dataset is saved in {}".format(tabfact_raw_data_dir))
|
||||
processed_tabfact_data_dir = os.path.join(PROCESSED_DATASET_FOLDER, "tabfact")
|
||||
|
||||
split_fine_grained_test(tabfact_raw_data_dir)
|
||||
logger.info("*" * 80)
|
||||
logger.info("Process the dataset and save the processed dataset in {}".format(processed_tabfact_data_dir))
|
||||
build_tabfact_fairseq_dataset("train", os.path.join(tabfact_raw_data_dir, "train.jsonl"),
|
||||
processed_tabfact_data_dir)
|
||||
build_tabfact_fairseq_dataset("valid", os.path.join(tabfact_raw_data_dir, "valid.jsonl"),
|
||||
processed_tabfact_data_dir)
|
||||
build_tabfact_fairseq_dataset("test", os.path.join(tabfact_raw_data_dir, "test.jsonl"),
|
||||
processed_tabfact_data_dir)
|
||||
build_tabfact_fairseq_dataset("test_simple", os.path.join(tabfact_raw_data_dir, "test_simple.jsonl"),
|
||||
processed_tabfact_data_dir)
|
||||
build_tabfact_fairseq_dataset("test_complex", os.path.join(tabfact_raw_data_dir, "test_complex.jsonl"),
|
||||
processed_tabfact_data_dir)
|
||||
build_tabfact_fairseq_dataset("test_small", os.path.join(tabfact_raw_data_dir, "test_small.jsonl"),
|
||||
processed_tabfact_data_dir)
|
||||
|
||||
logger.info("*" * 80)
|
||||
logger.info("Begin to BPE and build the dataset binaries in {0}/input0 and {0}/label".format(processed_tabfact_data_dir))
|
||||
preprocess_tabfact_dataset(processed_tabfact_data_dir)
|
||||
|
||||
logger.info("*" * 80)
|
||||
logger.info("Now you can train models using {} as the <data_dir> argument. "
|
||||
"More details in `run_model.py`.".format(os.path.join(processed_tabfact_data_dir, MODEL_NAME)))
|
||||
|
|
@ -0,0 +1,157 @@
|
|||
# Copyright (c) Microsoft Corporation.
|
||||
# Licensed under the MIT license.
|
||||
import json
|
||||
import sys
|
||||
from argparse import ArgumentParser
|
||||
from fairseq_cli.train import cli_main as fairseq_train
|
||||
from fairseq_cli.generate import cli_main as fairseq_generate
|
||||
import logging
|
||||
import shlex
|
||||
import re
|
||||
from tapex.model_interface import TAPEXModelInterface
|
||||
from fairseq.models.bart import BARTModel
|
||||
from tapex.model_eval import evaluate_generate_file
|
||||
import os
|
||||
from tqdm import tqdm
|
||||
import torch
|
||||
import pathlib
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def set_train_parser(parser_group):
|
||||
train_parser = parser_group.add_parser("train")
|
||||
train_parser.add_argument("--dataset-dir", type=str, required=True, default="",
|
||||
help="dataset directory where train.src is located in")
|
||||
train_parser.add_argument("--exp-dir", type=str, default="checkpoints",
|
||||
help="experiment directory which stores the checkpoint weights")
|
||||
train_parser.add_argument("--model-path", type=str, default="tapex.base/model.pt",
|
||||
help="the directory of pre-trained model path")
|
||||
train_parser.add_argument("--model-arch", type=str, default="bart_base", choices=["bart_large", "bart_base"],
|
||||
help="tapex large should correspond to bart_large, and tapex base should be bart_base")
|
||||
train_parser.add_argument("--max-tokens", type=int, default=1800,
|
||||
help="if you train a large model on 16GB memory, max-tokens should be empirically "
|
||||
"set as 1536, and can be near-linearly increased according to your GPU memory.")
|
||||
train_parser.add_argument("--gradient-accumulation", type=int, default=8,
|
||||
help="the accumulation steps to arrive a equal batch size, the default value can be used"
|
||||
"to reproduce our results. And you can also reduce it to a proper value for you.")
|
||||
train_parser.add_argument("--total-num-update", type=int, default=20000,
|
||||
help="the total optimization training steps")
|
||||
train_parser.add_argument("--learning-rate", type=float, default=3e-5,
|
||||
help="the peak learning rate for model training")
|
||||
|
||||
|
||||
def set_eval_parser(parser_group):
|
||||
eval_parser = parser_group.add_parser("eval")
|
||||
eval_parser.add_argument("--dataset-dir", type=str, required=True, default="",
|
||||
help="dataset directory where train.src is located in")
|
||||
eval_parser.add_argument("--model-dir", type=str, default="tapex.base.tabfact",
|
||||
help="the directory of fine-tuned model path such as tapex.base.tabfact")
|
||||
eval_parser.add_argument("--sub-dir", type=str, default="valid", choices=["train", "valid", "test",
|
||||
"test_complex", "test_simple",
|
||||
"test_small"],
|
||||
help="the directory of pre-trained model path, and the default should be in"
|
||||
"{bart.base, bart.large, tapex.base, tapex.large}.")
|
||||
|
||||
|
||||
def train_fairseq_model(args):
|
||||
cmd = f"""
|
||||
fairseq-train {args.dataset_dir} \
|
||||
--save-dir {args.exp_dir} \
|
||||
--restore-file {args.model_path} \
|
||||
--arch {args.model_arch} \
|
||||
--memory-efficient-fp16 \
|
||||
--task sentence_prediction \
|
||||
--num-classes 2 \
|
||||
--add-prev-output-tokens \
|
||||
--criterion sentence_prediction \
|
||||
--find-unused-parameters \
|
||||
--init-token 0 \
|
||||
--best-checkpoint-metric accuracy \
|
||||
--maximize-best-checkpoint-metric \
|
||||
--max-tokens {args.max_tokens} \
|
||||
--update-freq {args.gradient_accumulation} \
|
||||
--max-update {args.total_num_update} \
|
||||
--required-batch-size-multiple 1 \
|
||||
--dropout 0.1 \
|
||||
--attention-dropout 0.1 \
|
||||
--relu-dropout 0.0 \
|
||||
--weight-decay 0.01 \
|
||||
--optimizer adam \
|
||||
--adam-eps 1e-08 \
|
||||
--clip-norm 0.1 \
|
||||
--lr-scheduler polynomial_decay \
|
||||
--lr {args.learning_rate} \
|
||||
--total-num-update {args.total_num_update} \
|
||||
--warmup-updates 5000 \
|
||||
--ddp-backend no_c10d \
|
||||
--num-workers 20 \
|
||||
--reset-meters \
|
||||
--reset-optimizer \
|
||||
--reset-dataloader \
|
||||
--share-all-embeddings \
|
||||
--layernorm-embedding \
|
||||
--share-decoder-input-output-embed \
|
||||
--skip-invalid-size-inputs-valid-test \
|
||||
--log-format json \
|
||||
--log-interval 10 \
|
||||
--save-interval-updates 100 \
|
||||
--validate-interval 50 \
|
||||
--save-interval 50 \
|
||||
--patience 200
|
||||
"""
|
||||
sys.argv = shlex.split(cmd)
|
||||
logger.info("Begin to train model for dataset {}".format(args.dataset_dir))
|
||||
logger.info("Running command {}".format(re.sub("\s+", " ", cmd.replace("\n", " "))))
|
||||
fairseq_train()
|
||||
|
||||
|
||||
def evaluate_fairseq_model(args):
|
||||
data_path = pathlib.Path(args.dataset_dir).parent
|
||||
bart = BARTModel.from_pretrained(
|
||||
args.model_dir,
|
||||
data_name_or_path=args.dataset_dir
|
||||
)
|
||||
bart.eval()
|
||||
|
||||
if torch.cuda.is_available():
|
||||
cuda_device = list(range(torch.cuda.device_count()))
|
||||
bart = bart.cuda(cuda_device[0])
|
||||
|
||||
call_back_label = lambda label: bart.task.label_dictionary.string(
|
||||
[label + bart.task.label_dictionary.nspecial]
|
||||
)
|
||||
split = args.sub_dir
|
||||
input_file, label_file = os.path.join(data_path, "%s.raw.input0" % split), \
|
||||
os.path.join(data_path, "%s.label" % split)
|
||||
with open(input_file, 'r', encoding="utf8") as f:
|
||||
inputs = f.readlines()
|
||||
with open(label_file, 'r', encoding="utf8") as f:
|
||||
labels = f.readlines()
|
||||
assert len(inputs) == len(labels)
|
||||
total, correct = 0, 0
|
||||
for input, gold_label in tqdm(zip(inputs, labels)):
|
||||
total += 1
|
||||
tokens = bart.encode(input)
|
||||
pred = call_back_label(bart.predict('sentence_classification_head', tokens).argmax().item())
|
||||
if pred == gold_label.strip():
|
||||
correct += 1
|
||||
logger.info("=" * 20 + "evaluate on {}".format(split) + "=" * 20)
|
||||
logger.info(json.dumps({
|
||||
"total": total,
|
||||
"correct": correct,
|
||||
"acc": correct / total
|
||||
}))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = ArgumentParser()
|
||||
subparsers = parser.add_subparsers(dest="subcommand")
|
||||
set_train_parser(subparsers)
|
||||
set_eval_parser(subparsers)
|
||||
|
||||
args = parser.parse_args()
|
||||
if args.subcommand == "train":
|
||||
train_fairseq_model(args)
|
||||
elif args.subcommand == "eval":
|
||||
evaluate_fairseq_model(args)
|
||||
Загрузка…
Ссылка в новой задаче