зеркало из https://github.com/microsoft/UniSpeech.git
|
|
||
|---|---|---|
| .. | ||
| config | ||
| examples | ||
| fairseq | ||
| fairseq_cli | ||
| scripts | ||
| CODE_OF_CONDUCT.md | ||
| CONTRIBUTING.md | ||
| LICENSE | ||
| README.md | ||
| SUPERB_Results.png | ||
| hubconf.py | ||
| preprocess.py | ||
| pyproject.toml | ||
| setup.py | ||
| train.py | ||
{kind=link}
README.md
UniSpeech-SAT
This is the official implementation of paper "UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware Pre-Training"(ICASSP 2022 Submission). The implementation mainly based on fairseq codebase.
Requirements and Installation
- Pytorch >= 1.6.0
- python version >= 3.7
cd UniSpeech/UniSpeech-SAT
pip install --editable ./ --user
Pre-trained models
| Model | Dataset | Model |
|---|---|---|
| UniSpeech-SAT Base | 960 hrs LibriSpeech | download |
| UniSpeech-SAT Base+ | 60k hrs Libri-Light + 10k hrs GigaSpeech + 24k hrs VoxPopuli | download |
| UniSpeech-SAT Large | 60k hrs Libri-Light + 10k hrs GigaSpeech + 24k hrs VoxPopuli | download |
Load pretrained model
Example usage:
import torch
import fairseq
cp_path = '/path/to/wav2vec.pt'
model, cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task([cp_path])
model = model[0]
model.remove_pretraining_modules()
model.eval()
wav_input_16khz = torch.randn(1,10000)
f = model.feature_extractor(wav_input_16khz)
Results on SUPERB
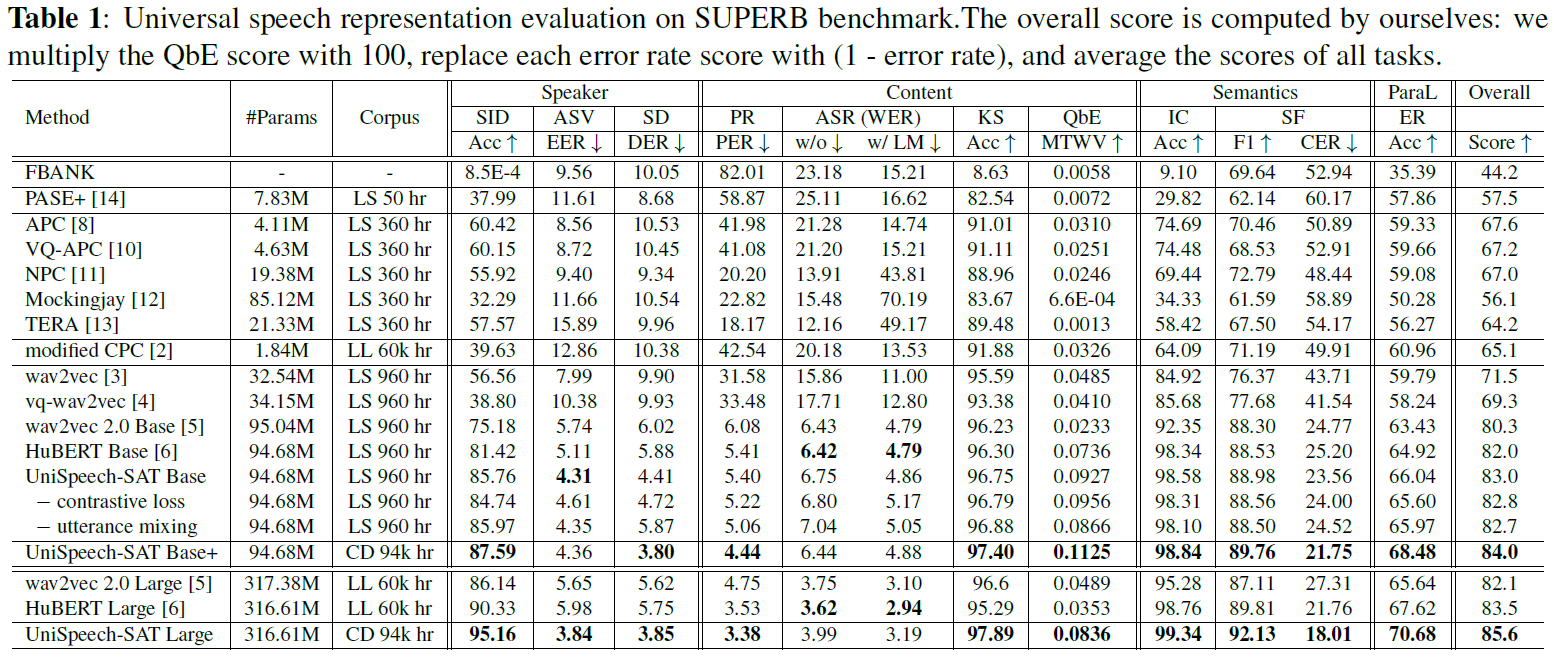
Citation
If you find our work useful, please cite our paper.