|
|
||
|---|---|---|
| .. | ||
| assets | ||
| models | ||
| README.md | ||
| generate_text.py | ||
| search.py | ||
| train.py | ||
README.md
Text Generation
At Archai, we recognize the significance of discovering the optimal neural architecture to attain the highest performance in text generation. For this purpose, we have created an advanced neural architecture search method known as the Lightweight Transformer Search (LTS). This innovative method enables us to identify the most optimal architectures that exist on the Pareto Frontier, where trade-offs are made between several objectives, such as latency and memory usage.
Model Gallery
We utilized GPT-2 as our base model and applied LTS on top of it to find the best performing architectures given a set of constraints. The following table showcases the results of our search:
For a straightforward usage with the transformers package, please refer to microsoft/lts-gpt2-sm on the Hugging Face Hub.
Searching for Pareto-optimal Architectures
We ran LTS for a total of 10 generations and discovered multiple architectures that perform well with regards to non-embedding parameters, latency, and memory. To reproduce the search, the following command can be used:
python search.py -h
The default arguments provided by the script were used in this task.
Results
The best-performing architectures with respect to non-embedding parameters and ONNX-based latency are depicted by the points in the bottom-left corner of the plot:

The best-performing architectures with respect to non-embedding parameters and ONNX-based memory are shown by the points in the bottom-left corner of the plot:

Training the Architectures
Once the Pareto-optimal architectures have been found (located in the models folder), they can be trained using the following script:
python train.py -h
The default arguments provided by the script were used in this task. The training dataset consisted of 7.8 billion tokens from a pre-encoded version of ThePile.
Results
After pre-training the architectures, we performed a zero-shot evaluation over 16 tasks, and created two Pareto frontiers between the average performance (across all tasks) and ONNX-based metrics (latency and memory).
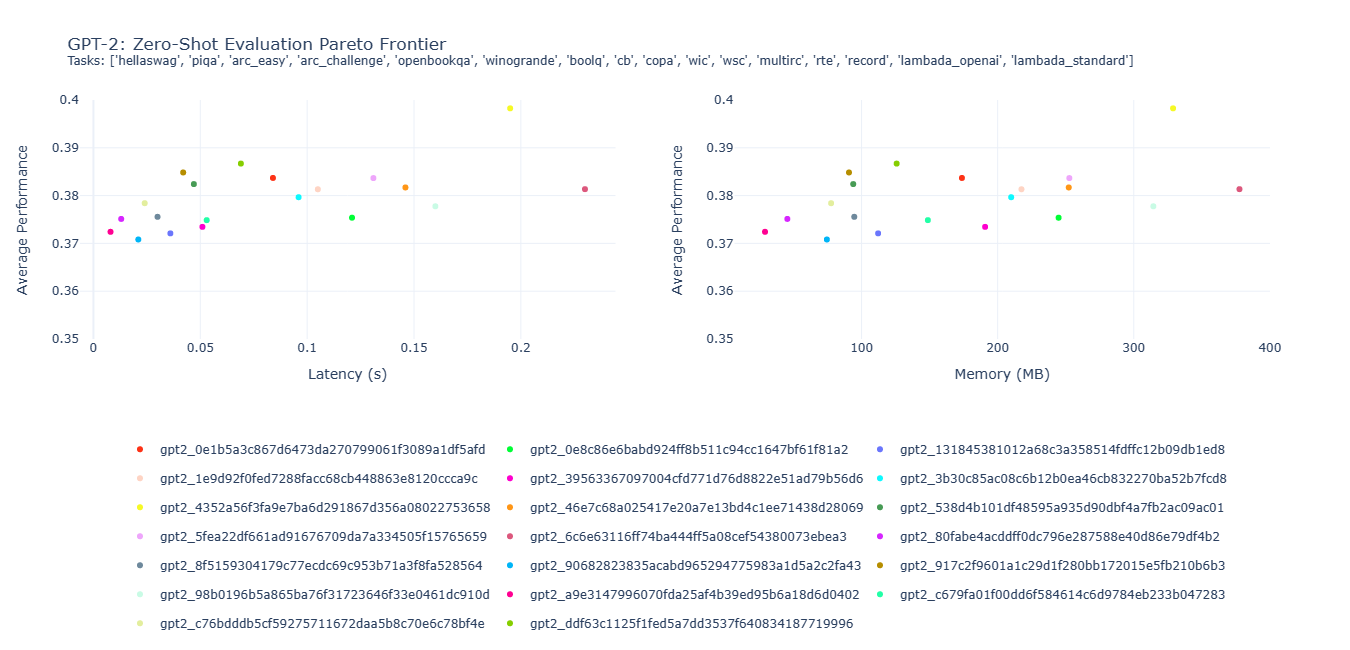
It is worth noting that the model labeled gpt2_4352a56f3fa9e7ba6d291867d356a08022753658 (represented by the "yellow" dot) achieved the highest average performance with lower latency and memory usage than gpt2_6c6e63116ff74ba444ff5a08cef54380073ebea3, despite having 20% less parameters.
Furthermore, gpt2_ddf63c1125f1fed5a7dd3537f640834187719996 (represented by the "medium green" dot) used only 13.32M non-embedding parameters, 0.069s of latency, and 125.78MB of memory, yet it attained an average performance of 0.3867. This level of performance was only 2.89% lower than that of the highest-performing model ("yellow" dot), but it utilized roughly one-third of the non-embedding parameters, latency, and memory.
Generating Text with Pre-Trained Architectures
With our pre-trained architectures, text can be generated with ease using just a few lines of code. Simply use one of the models from our Model Gallery and start generating text:
python generate_text.py "microsoft/lts-gpt2-sm" "# Halo Infinite Review" --pre_trained_model_subfolder "gpt2_ddf63c1125f1fed5a7dd3537f640834187719996"