|
|
||
|---|---|---|
| Notebooks | ||
| benchmarking | ||
| dataset | ||
| demo | ||
| docs | ||
| fpga/vstream | ||
| ingestion | ||
| magenta/pipeline | ||
| tools | ||
| .gitignore | ||
| CODE_OF_CONDUCT.md | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
README.md
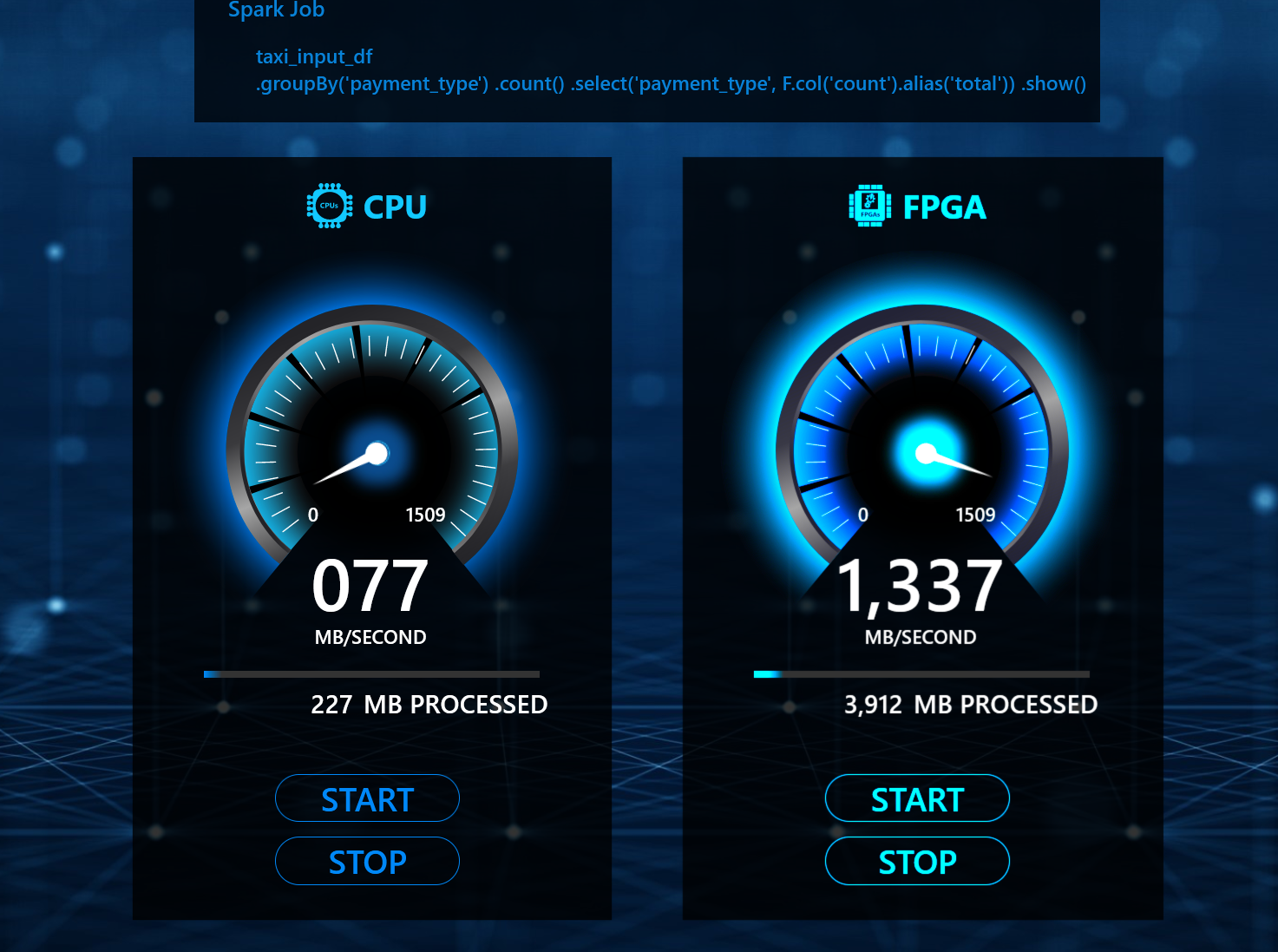
Asessing CPU vs FPGA Performance Using Spark
We benchmark performance of a simple query using NYC Taxi Dataset.
Downloading and Normalizing Data
We use a subset of the Yellow Trip Data consisting of files with 18 columns. We further normalize the data in these files to conform to the schema published on the NYC Taxi Dataset site for Yellow Taxi trips.
To download the data locally:
- Clone this repo
- Clone nyc-taxi-data git repo
- Edit
download_raw_data.shin the root ofnyc-taxi-datarepo replacing the defaultsetup_files/raw_data_urls.txtwith<this_repo>/dataset/yellow_taxi_files.csv - Run
./download_raw_data.shto download the dataset. - Normalize the downloaded dataset by going through the
Notebooks/Standardize Schema.ipynbin this repo. Theclean_schemafunction is what does normalization.
Our dataset is 100 GB in size split into 82 files.
Collecting Performance Data
We use local Spark configured with local[*] (default) and structured streaming to measure and aggregate performance on our dataset. Each streaming batch consists of a single CSV file. The profiled query is:
select payment_type, count(*) as total from nyctaxidata group by payment_type
As configured above, all local CPU cores are utilized for the query.
CPU
- Install Apache Spark.
- In
<repo_root>/benchmarking/queries/benchmark_taxi.scala, modify the following values as appropriate:
val rootPath = s"~/data/taxi_data_cleaned_18_standard" //root of the dataset
val magentaOutDir = s"~/data/queries_e8/$queryName/processed/results" // query results
val checkpointLoc = s"~/data/queries_e8/$queryName/checkpoint" // checkpoint files
val logDir = s"~/data/queries_e8/$queryName/monitor/results" // profiling results
- Launch spark-shell with enough memory to stream the data:
From the root of this repo:
$ cd benchmarking/queries
$ spark-shell --driver-memory 50G
- Load the relevant file and launch Spark processing
scala> :load benchmark_taxi.scala
scala> Benchmark.main(1)
Benchmarking results will be placed in the directories prefixed with logDir, so in the example above these will be:
~/data/queries_e8/q1/monitor/results_0
~/data/queries_e8/q1/monitor/results_1
~/data/queries_e8/q1/monitor/results_2
etc
- Collect the results:
$ cat ~/data/queries_e8/q1/monitor/results_*/*.csv > taxi_q1_profile.csv
FPGA
Provisioning an NP-10 machine in Azure and going through the above steps should yield the benchmarks for FPGA. For the demo we used a custom "one-off" implementation of this query to assess FPGA performance.
Web UI
See this README for instruction on how to visualize performance data in Web UI. Here is the finished app