Bumps [numpy](https://github.com/numpy/numpy) from 1.19.3 to 1.22.0. - [Release notes](https://github.com/numpy/numpy/releases) - [Changelog](https://github.com/numpy/numpy/blob/main/doc/HOWTO_RELEASE.rst) - [Commits](https://github.com/numpy/numpy/compare/v1.19.3...v1.22.0) --- updated-dependencies: - dependency-name: numpy dependency-type: direct:production ... Signed-off-by: dependabot[bot] <support@github.com> |
||
|---|---|---|
| config | ||
| datasets | ||
| experiments/imagenet | ||
| layers | ||
| models | ||
| plot | ||
| scripts/scripts_local | ||
| .gitignore | ||
| CODE_OF_CONDUCT.md | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
| SUPPORT.md | ||
| analyze_models.py | ||
| cgmanifest.json | ||
| eval_knn.py | ||
| eval_linear.py | ||
| main_esvit.py | ||
| main_esvit_mnodes.py | ||
| requirements.txt | ||
| utils.py | ||
README.md
Efficient Self-Supervised Vision Transformers (EsViT)
![]()
PyTorch implementation for EsViT (accepted in ICLR, 2022), built with two techniques:
- A multi-stage Transformer architecture. Three multi-stage Transformer variants are implemented under the folder
models. - A non-contrastive region-level matching pre-train task. The region-level matching task is implemented in function
DDINOLoss(nn.Module)(Line 648) inmain_esvit.py. Please use--use_dense_prediction True, otherwise only the view-level task is used.
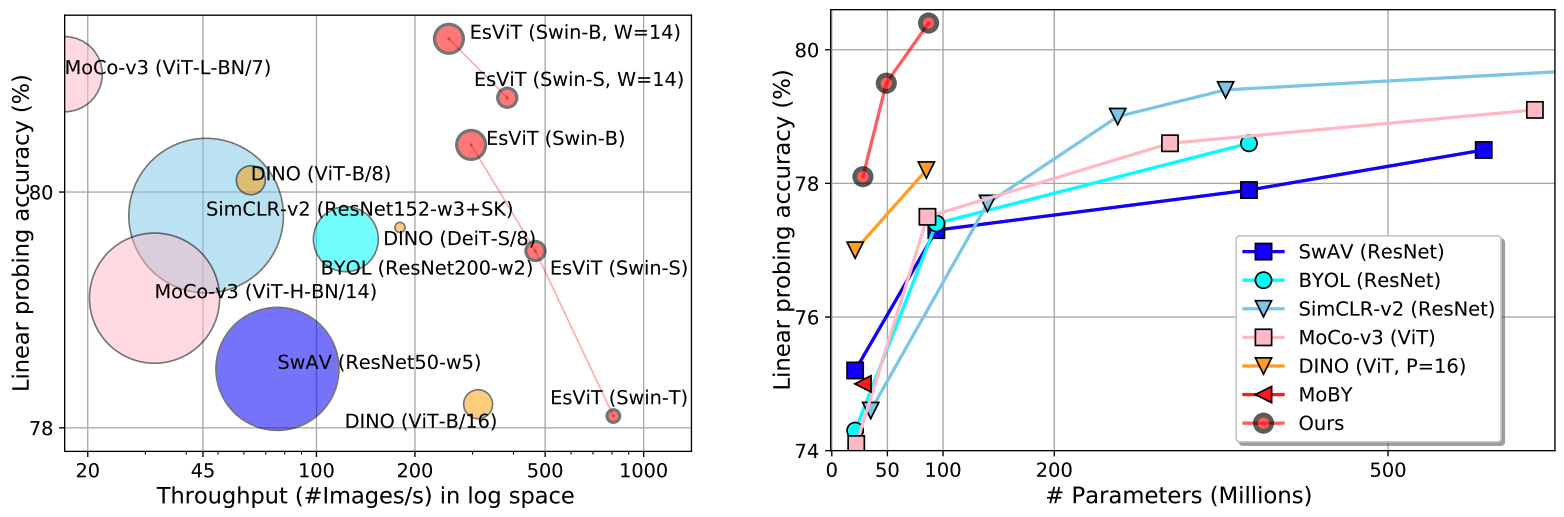
Pretrained models
You can download the full checkpoint (trained with both view-level and region-level tasks, batch size=512 and ImageNet-1K.), which contains backbone and projection head weights for both student and teacher networks.
- EsViT (Swin) with network configurations of increased model capacities, pre-trained with both view-level and region-level tasks. ResNet-50 trained with both tasks is shown as a reference.
| arch | params | tasks | linear | k-nn | download | logs | ||
|---|---|---|---|---|---|---|---|---|
| ResNet-50 | 23M | V+R | 75.7% | 71.3% | full ckpt | train | linear | knn |
| EsViT (Swin-T, W=7) | 28M | V+R | 78.0% | 75.7% | full ckpt | train | linear | knn |
| EsViT (Swin-S, W=7) | 49M | V+R | 79.5% | 77.7% | full ckpt | train | linear | knn |
| EsViT (Swin-B, W=7) | 87M | V+R | 80.4% | 78.9% | full ckpt | train | linear | knn |
| EsViT (Swin-T, W=14) | 28M | V+R | 78.7% | 77.0% | full ckpt | train | linear | knn |
| EsViT (Swin-S, W=14) | 49M | V+R | 80.8% | 79.1% | full ckpt | train | linear | knn |
| EsViT (Swin-B, W=14) | 87M | V+R | 81.3% | 79.3% | full ckpt | train | linear | knn |
- EsViT with view-level task only
| arch | params | tasks | linear | k-nn | download | logs | ||
|---|---|---|---|---|---|---|---|---|
| ResNet-50 | 23M | V | 75.0% | 69.1% | full ckpt | train | linear | knn |
| EsViT (Swin-T, W=7) | 28M | V | 77.0% | 74.2% | full ckpt | train | linear | knn |
| EsViT (Swin-S, W=7) | 49M | V | 79.2% | 76.9% | full ckpt | train | linear | knn |
| EsViT (Swin-B, W=7) | 87M | V | 79.6% | 77.7% | full ckpt | train | linear | knn |
- EsViT (Swin-T, W=7) with different pre-train datasets (view-level task only)
| arch | params | batch size | pre-train dataset | linear | k-nn | download | logs | ||
|---|---|---|---|---|---|---|---|---|---|
| EsViT | 28M | 1024 | ImageNet-1K | 77.1% | 73.7% | full ckpt | train | linear | knn |
| EsViT | 28M | 1024 | WebVision-v1 | 75.4% | 69.4% | full ckpt | train | linear | knn |
| EsViT | 28M | 1024 | OpenImages-v4 | 69.6% | 60.3% | full ckpt | train | linear | knn |
| EsViT | 28M | 1024 | ImageNet-22K | 73.5% | 66.1% | full ckpt | train | linear | knn |
- EsViT with more multi-stage vision Transformer architectures, pre-trained with View-level and Region-level tasks.
| arch | params | pre-train task | linear | k-nn | download | logs | ||
|---|---|---|---|---|---|---|---|---|
| EsViT (ViL, W=7) | 28M | V | 77.3% | 73.9% | full ckpt | train | linear | knn |
| EsViT (ViL, W=7) | 28M | V+R | 77.5% | 74.5% | full ckpt | train | linear | knn |
| EsViT (CvT, W=7) | 29M | V | 77.6% | 74.8% | full ckpt | train | linear | knn |
| EsViT (CvT, W=7) | 29M | V+R | 78.5% | 76.7% | full ckpt | train | linear | knn |
Pre-training
One-node training
To train on 1 node with 16 GPUs for Swin-T model size:
PROJ_PATH=your_esvit_project_path
DATA_PATH=$PROJ_PATH/project/data/imagenet
OUT_PATH=$PROJ_PATH/output/esvit_exp/ssl/swin_tiny_imagenet/
python -m torch.distributed.launch --nproc_per_node=16 main_esvit.py --arch swin_tiny --data_path $DATA_PATH/train --output_dir $OUT_PATH --batch_size_per_gpu 32 --epochs 300 --teacher_temp 0.07 --warmup_epochs 10 --warmup_teacher_temp_epochs 30 --norm_last_layer false --use_dense_prediction True --cfg experiments/imagenet/swin/swin_tiny_patch4_window7_224.yaml
The main training script is main_esvit.py and conducts the training loop, taking the following options (among others) as arguments:
--use_dense_prediction: whether or not to use the region matching task in pre-training--arch: switch between different sparse self-attention in the multi-stage Transformer architecture. Example architecture choices for EsViT training include [swin_tiny,swin_small,swin_base,swin_large,cvt_tiny,vil_2262]. The configuration files should be adjusted accrodingly, we provide example below. One may specify the network configuration by editing theYAMLfile underexperiments/imagenet/*/*.yaml. The default window size=7; To consider a multi-stage architecture with window size=14, please choose yaml files withwindow14in filenames.
To train on 1 node with 16 GPUs for Convolutional vision Transformer (CvT) models:
python -m torch.distributed.launch --nproc_per_node=16 main_evsit.py --arch cvt_tiny --data_path $DATA_PATH/train --output_dir $OUT_PATH --batch_size_per_gpu 32 --epochs 300 --teacher_temp 0.07 --warmup_epochs 10 --warmup_teacher_temp_epochs 30 --norm_last_layer false --use_dense_prediction True --aug-opt dino_aug --cfg experiments/imagenet/cvt_v4/s1.yaml
To train on 1 node with 16 GPUs for Vision Longformer (ViL) models:
python -m torch.distributed.launch --nproc_per_node=16 main_evsit.py --arch vil_2262 --data_path $DATA_PATH/train --output_dir $OUT_PATH --batch_size_per_gpu 32 --epochs 300 --teacher_temp 0.07 --warmup_epochs 10 --warmup_teacher_temp_epochs 30 --norm_last_layer false --use_dense_prediction True --aug-opt dino_aug --cfg experiments/imagenet/vil/vil_small/base.yaml MODEL.SPEC.MSVIT.ARCH 'l1,h3,d96,n2,s1,g1,p4,f7,a0_l2,h6,d192,n2,s1,g1,p2,f7,a0_l3,h12,d384,n6,s0,g1,p2,f7,a0_l4,h24,d768,n2,s0,g0,p2,f7,a0' MODEL.SPEC.MSVIT.MODE 1 MODEL.SPEC.MSVIT.VIL_MODE_SWITCH 0.75
Multi-node training
To train on 2 nodes with 16 GPUs each (total 32 GPUs) for Swin-Small model size:
OUT_PATH=$PROJ_PATH/exp_output/esvit_exp/swin/swin_small/bl_lr0.0005_gpu16_bs16_multicrop_epoch300_dino_aug_window14
python main_evsit_mnodes.py --num_nodes 2 --num_gpus_per_node 16 --data_path $DATA_PATH/train --output_dir $OUT_PATH/continued_from0200_dense --batch_size_per_gpu 16 --arch swin_small --zip_mode True --epochs 300 --teacher_temp 0.07 --warmup_epochs 10 --warmup_teacher_temp_epochs 30 --norm_last_layer false --cfg experiments/imagenet/swin/swin_small_patch4_window14_224.yaml --use_dense_prediction True --pretrained_weights_ckpt $OUT_PATH/checkpoint0200.pth
Evaluation:
k-NN and Linear classification on ImageNet
To train a supervised linear classifier on frozen weights on a single node with 4 gpus, run eval_linear.py. To train a k-NN classifier on frozen weights on a single node with 4 gpus, run eval_knn.py. Please specify --arch, --cfg and --pretrained_weights to choose a pre-trained checkpoint. If you want to evaluate the last checkpoint of EsViT with Swin-T, you can run for example:
PROJ_PATH=your_esvit_project_path
DATA_PATH=$PROJ_PATH/project/data/imagenet
OUT_PATH=$PROJ_PATH/exp_output/esvit_exp/swin/swin_tiny/bl_lr0.0005_gpu16_bs32_dense_multicrop_epoch300
CKPT_PATH=$PROJ_PATH/exp_output/esvit_exp/swin/swin_tiny/bl_lr0.0005_gpu16_bs32_dense_multicrop_epoch300/checkpoint.pth
python -m torch.distributed.launch --nproc_per_node=4 eval_linear.py --data_path $DATA_PATH --output_dir $OUT_PATH/lincls/epoch0300 --pretrained_weights $CKPT_PATH --checkpoint_key teacher --batch_size_per_gpu 256 --arch swin_tiny --cfg experiments/imagenet/swin/swin_tiny_patch4_window7_224.yaml --n_last_blocks 4 --num_labels 1000 MODEL.NUM_CLASSES 0
python -m torch.distributed.launch --nproc_per_node=4 eval_knn.py --data_path $DATA_PATH --dump_features $OUT_PATH/features/epoch0300 --pretrained_weights $CKPT_PATH --checkpoint_key teacher --batch_size_per_gpu 256 --arch swin_tiny --cfg experiments/imagenet/swin/swin_tiny_patch4_window7_224.yaml MODEL.NUM_CLASSES 0
Analysis/Visualization of correspondence and attention maps
You can analyze the learned models by running python run_analysis.py. One example to analyze EsViT (Swin-T) is shown.
For an invidiual image (with path --image_path $IMG_PATH), we visualize the attention maps and correspondence of the last layer:
python run_analysis.py --arch swin_tiny --image_path $IMG_PATH --output_dir $OUT_PATH --pretrained_weights $CKPT_PATH --learning ssl --seed $SEED --cfg experiments/imagenet/swin/swin_tiny_patch4_window7_224.yaml --vis_attention True --vis_correspondence True MODEL.NUM_CLASSES 0
For an image dataset (with path --data_path $DATA_PATH), we quantatively measure the correspondence:
python run_analysis.py --arch swin_tiny --data_path $DATA_PATH --output_dir $OUT_PATH --pretrained_weights $CKPT_PATH --learning ssl --seed $SEED --cfg experiments/imagenet/swin/swin_tiny_patch4_window7_224.yaml --measure_correspondence True MODEL.NUM_CLASSES 0
For more examples, please see scripts/scripts_local/run_analysis.sh.
Citation
If you find this repository useful, please consider giving a star ⭐ and citation 🍺:
@article{li2021esvit,
title={Efficient Self-supervised Vision Transformers for Representation Learning},
author={Li, Chunyuan and Yang, Jianwei and Zhang, Pengchuan and Gao, Mei and Xiao, Bin and Dai, Xiyang and Yuan, Lu and Gao, Jianfeng},
journal={International Conference on Learning Representations (ICLR)},
year={2022}
}
Related Projects/Codebase
[Swin Transformers] [Vision Longformer] [Convolutional vision Transformers (CvT)] [Focal Transformers]
Acknowledgement
Our implementation is built partly upon packages: [Dino] [Timm]
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.