зеркало из https://github.com/microsoft/pai.git
fix grammar issues in cluster-user manual (#5287)
This commit is contained in:
Родитель
b8fa58782a
Коммит
be386f0a8c
|
|
@ -4,20 +4,20 @@
|
|||
<img src="./images/dbc_structure.png" width="100%">
|
||||
</center>
|
||||
|
||||
Database Controller is designed to manage job status in database and API server. To be brief, we treat records in database as the ground truth, and synchronize them to the API server.
|
||||
Database Controller is designed to manage job status in database and API server. To be brief, we treat records in the database as the ground truth and synchronize them to the API server.
|
||||
|
||||
Database Controller contains 3 main components: write merger, poller and watcher. Here is an example of job lifetime controlled by these 3 components:
|
||||
Database Controller contains 3 main components: write merger, poller, and watcher. Here is an example of a job lifetime controlled by these 3 components:
|
||||
|
||||
1. User submits framework request to rest-server.
|
||||
2. Rest-server forwards the request to write merger.
|
||||
3. Write merger saves it to database, mark `synced=false`, and return.
|
||||
3. Write merger saves it to the database, mark `synced=false`, and return.
|
||||
4. User is notified the framework request is successfully created.
|
||||
5. Poller finds the `synced=false` request, and synchronize it to the API server.
|
||||
6. Now watcher finds the framework is created in API server. So it sends the event to write merger.
|
||||
5. Poller finds the `synced=false` request and synchronizes it to the API server.
|
||||
6. Now watcher finds the framework is created in the API server. So it sends the event to write merger.
|
||||
7. Write merger receives the watched event, mark `synced=true`, and update job status according to the event.
|
||||
8. The job finishes. Watcher sends this event to write merger.
|
||||
9. Write merger receives the watched event, mark `completed=true`, and update job status according to the event.
|
||||
10. Poller finds the `completed=true` request, delete it from API server.
|
||||
10. Poller finds the `completed=true` request, deletes it from the API server.
|
||||
11. Watcher sends the delete event to write merger.
|
||||
12. Write merger receives the watched event, mark `deleted=true`.
|
||||
|
||||
|
|
|
|||
|
|
@ -6,14 +6,14 @@
|
|||
|
||||
[中文版请点击这里](https://openpai.readthedocs.io/zh_CN/latest/)
|
||||
|
||||
OpenPAI is an open source platform that provides complete AI model training and resource management capabilities, it is easy to extend and supports on-premise, cloud and hybrid environments in various scale.
|
||||
OpenPAI is an open-source platform that provides complete AI model training and resource management capabilities, it is easy to extend and supports on-premise, cloud, and hybrid environments on various scales.
|
||||
|
||||
This handbook is based on OpenPAI >= v1.0.0, and it contains two parts: [User Manual](./manual/cluster-user/README.md) and [Admin Manual](./manual/cluster-admin/README.md).
|
||||
|
||||
To learn how to submit job, debug job, manage data, use Marketplace and VSCode extension on OpenPAI, please follow our [User Manual](./manual/cluster-user/README.md).
|
||||
To learn how to submit jobs, debug jobs, manage data, use Marketplace and VSCode extensions on OpenPAI, please follow our [User Manual](./manual/cluster-user/README.md).
|
||||
|
||||
To set up a new cluster, learn how to manage cluster on OpenPAI, please follow [Admin Manual](./manual/cluster-admin/README.md).
|
||||
|
||||
To view a general introduction of OpenPAI, please refer to the [Github Readme](https://github.com/microsoft/pai/blob/master/README.md).
|
||||
|
||||
For any issue/bug/feature request, please submit it to [GitHub](https://github.com/microsoft/pai).
|
||||
For any issue/bug feedback or feature pull request, please submit it to [GitHub](https://github.com/microsoft/pai).
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ Apart from it, OpenPAI provides many out-of-the-box images for different deep le
|
|||
| openpai/standard | python_3.6-mxnet_1.5.1-cpu | - | - |
|
||||
| openpai/standard | python_3.6-cntk_2.7-cpu | - | - |
|
||||
|
||||
The tag of these images indicates the version of the built-in deep learning framework and whether it supports GPU. Some GPU-supported dockers require a high version of your NVIDIA driver, because of the requirement of CUDA. If you are not sure about the driver version of the cluster, please ask your administrator.
|
||||
The tag of these images indicates the version of the built-in deep learning framework and whether it supports GPU. According to the requirement of CUDA, some GPU-supported dockers require a high version of the NVIDIA driver. If you are not sure about the driver version of the cluster, please ask your administrator.
|
||||
|
||||
## Job Examples based on Pre-built Images
|
||||
|
||||
|
|
@ -43,14 +43,14 @@ The tag of these images indicates the version of the built-in deep learning fram
|
|||
|
||||
There are also CPU/GPU/Multi-GPU/Horovod job examples for TensorFlow. Please check [tensorflow_cifar10](https://github.com/microsoft/pai/blob/pai-for-edu/contrib/edu-examples/tensorflow_cifar10) for details.
|
||||
|
||||
## Use Your Own Custom Image
|
||||
## Use Your Custom Image
|
||||
|
||||
If you want to build your own custom image instead of pre-built images, it is recommended to build it basing on ubuntu system, which includes bash, apt and other required dependency. Then you could add any requirements your job needs in the docker image, for example, python, pip and tensorflow etc. Please take care of potential conflicts when adding additional dependencies.
|
||||
If you want to build your custom image instead of pre-built images, it is recommended to build it basing on the Ubuntu system, which includes bash, apt, and other required dependencies. Then you could add any requirements your job needs in the docker image, such as python, pip, and TensorFlow. Please take care of potential conflicts when adding additional dependencies.
|
||||
|
||||
## How to use Images from Private Registry
|
||||
|
||||
By default, OpenPAI will pull images from the [official Docker Hub](https://hub.docker.com/), which is a public docker registry. The pre-built images are all available in this public registry.
|
||||
By default, OpenPAI will pull images from the [official Docker Hub](https://hub.docker.com/), which is a public Docker registry. The pre-built images are all available in this public registry.
|
||||
|
||||
If you want to use a private registry, please toggle the `Custom` botton, then click the `Auth` button, and fill in the required information. If your authorization information is invalid, OpenPAI will inform you of an authorization failure after job submission.
|
||||
If you want to use a private registry, please toggle the `Custom` button, then click the `Auth` button, and fill in the required information. If your authorization information is invalid, OpenPAI will inform you of an authorization failure after job submission.
|
||||
|
||||
<img src="./imgs/docker-image-auth.png" width="60%" height="60%" />
|
||||
|
|
@ -2,6 +2,6 @@
|
|||
|
||||
## Why my job has an unexpected retry number?
|
||||
|
||||
Generally speaking, there are 3 types of error in OpenPAI: transient error, permanent error, and unknown error. In jobs, transient error will be always retried, and permanent error will never be retried. If unknown error happens, PAI will retry the job according to the [retry policy](./how-to-use-advanced-job-settings.md#job-exit-spec-retry-policy-and-completion-policy) of the job, which is set by user.
|
||||
Generally speaking, there are 3 types of error in OpenPAI: transient error, permanent error, and unknown error. In jobs, transient errors will be always retried, and permanent errors will never be retried. If an unknown error happens, PAI will retry the job according to the [retry policy](./how-to-use-advanced-job-settings.md#job-exit-spec-retry-policy-and-completion-policy) of the job, which is set by the user.
|
||||
|
||||
If you don't set any [retry policy](./how-to-use-advanced-job-settings.md#job-exit-spec-retry-policy-and-completion-policy) but find the job has an unexpected retry number, it can be caused by some transient error, e.g. memory issues, disk pressure, or power failure of the node. Another kind of transient error is preemption. Jobs with higher priority can preempt jobs with lower priority. In OpenPAI's [job protocol](https://github.com/microsoft/openpai-protocol/blob/master/schemas/v2/schema.yaml), you can find a field named `jobPriorityClass`. It defines the priority of a job.
|
||||
|
|
@ -1,12 +1,12 @@
|
|||
# How to Debug Jobs
|
||||
|
||||
This document describes how to use SSH and TensorBoard plugin to debug job.
|
||||
This document describes how to use SSH and TensorBoard plugin to debug jobs.
|
||||
|
||||
**Note:** These two plugins only work when the IP address is accessible from customer environment (not cluster internal IP). So if PAI deployed in some cloud environment such as Azure, these two plugins will not work.
|
||||
**Note:** These two plugins only work when the IP address is accessible from the customer environment (not cluster internal IP). So if PAI is deployed in some cloud environment such as Azure, these two plugins will not work.
|
||||
|
||||
## How to use SSH
|
||||
|
||||
OpenPAI provides SSH plugin for you to connect to job containers. To use SSH, you can either create an SSH key pair, or use your own pre-generated keys.
|
||||
OpenPAI provides an SSH plugin for you to connect to job containers. To use SSH, you can either create an SSH key pair or use your pre-generated keys.
|
||||
|
||||
**Option 1. Create an SSH Key Pair**
|
||||
|
||||
|
|
@ -14,12 +14,12 @@ It is feasible to create a new SSH key pair when you submit the job. First, open
|
|||
|
||||
<img src="./imgs/ssh-click-generator.png" width="60%" height="60%" />
|
||||
|
||||
The generator will generate one public key and one private key for you. Please download SSH private key, then click `Use Public Key` button to use this key pair in your job.
|
||||
The generator will generate one public key and one private key for you. Please download SSH private key, then click the `Use Public Key` button to use this key pair in your job.
|
||||
|
||||
|
||||
<img src="./imgs/ssh-generator.png" width="60%" height="60%" />
|
||||
|
||||
After job submission, you can ssh to job containers as user root with the downloaded private key through container ip and ssh port. The `View SSH Info` button will give you the corresponding command:
|
||||
After job submission, you can ssh to job containers as user root with the downloaded private key through container IP and SSH port. The `View SSH Info` button will give you the corresponding command:
|
||||
|
||||
|
||||
<img src="./imgs/view-ssh-info.png" width="100%" height="100%" />
|
||||
|
|
@ -38,9 +38,9 @@ chmod 400 <your-private-key-file-path> && ssh -p <ssh-port> -i <your-private-key
|
|||
|
||||
**Option 2. Use your Own Keys**
|
||||
|
||||
If you are familiar with SSH key authentication, you would probably have generated a public key and a private key already, in the folder `C:\Users\<your-user-name>\.ssh` (it is `~/.ssh/` on a Unix-like system). There is an `id_rsa.pub` file and an `id_rsa` file in such folder, which are the public key and the private key, respectively.
|
||||
If you are familiar with SSH key authentication, you would probably have generated a public key and a private key already, in the `.ssh` subfolder under your user folder (`C:\Users\<your-user-name>` on Windows and `~` on a Unix-like system). There are an `id_rsa.pub` file and an `id_rsa` file in such a folder, which contains the public key and the private key, respectively.
|
||||
|
||||
To use them, open the `id_rsa.pub` and copy its content to the SSH plugin, then submit the job. Do not use the key generator.
|
||||
To use them, open the `id_rsa.pub` and copy its content to the SSH plugin, then submit the job. There is no need to use the key generator.
|
||||
|
||||
<img src="./imgs/copy-ssh-public-key.png" width="60%" height="60%" />
|
||||
|
||||
|
|
@ -69,12 +69,12 @@ After submission, you will see a `Go to TensorBoard Page` button on the job deta
|
|||
|
||||
<img src="./imgs/go-to-tensorboard-page.png" width="100%" height="100%" />
|
||||
|
||||
The button will bring you to the TensorBoard page. You might wait a few minutes until the log is ready:
|
||||
The button will bring you to the TensorBoard page. You might wait for a few minutes until the log is ready:
|
||||
|
||||
<img src="./imgs/tensorboard-ok.png" width="100%" height="100%" />
|
||||
|
||||
Generally speaking, to use the TensorBoard plugin, you should:
|
||||
|
||||
1. Save your TensorFlow summary logs to `/mnt/tensorboard`
|
||||
1. Save your TensorFlow summary logs to `/mnt/tensorboard`.
|
||||
2. Make sure `tensorboard` is installed in the docker image you use.
|
||||
3. Use the `sleep` command to extend the job lifetime, if you want TensorBoard available after job completes.
|
||||
3. Use the `sleep` command to extend the job lifetime, if you want TensorBoard available after the job completes.
|
||||
|
|
|
|||
|
|
@ -6,28 +6,28 @@ You should first have at least one permitted storage to manage data in OpenPAI.
|
|||
|
||||

|
||||
|
||||
Then all storages you have access to will be shown:
|
||||
Then all storages you have access to will be displayed:
|
||||
|
||||

|
||||
|
||||
If you don't find any storage, please contact the cluster administrator.
|
||||
If the display list is empty, please contact the cluster administrator.
|
||||
|
||||
## Upload data
|
||||
|
||||
There are multiple types of storage. We introduce how to upload data to `NFS`, `AzureBlob` and `AzureFile` storage as examples.
|
||||
There are multiple types of storage. We will introduce how to upload data to `NFS`, `AzureBlob`, and `AzureFile` storage as examples.
|
||||
|
||||
### Upload data to NFS
|
||||
|
||||
#### Upload data to NFS server on Ubuntu (16.04 or above)
|
||||
|
||||
For Ubuntu users. To upload data to an `NFS` storage, please run following commands first to install nfs dependencies.
|
||||
For Ubuntu users. To upload data to an `NFS` storage, please run the following commands first to install NFS dependencies.
|
||||
|
||||
```bash
|
||||
sudo apt-get update
|
||||
sudo apt-get install --assume-yes nfs-common
|
||||
```
|
||||
|
||||
Then you can mount nfs into your machine:
|
||||
Then you can mount NFS into your machine:
|
||||
```bash
|
||||
sudo mkdir -p MOUNT_PATH
|
||||
sudo mount -t nfs4 NFS_SERVER:/NFS_PATH MOUNT_PATH
|
||||
|
|
@ -35,7 +35,7 @@ sudo mount -t nfs4 NFS_SERVER:/NFS_PATH MOUNT_PATH
|
|||
|
||||
Copy your data to the mount point will upload your data to `NFS`.
|
||||
|
||||
The `NFS_SERVER` and `NFS_PATH` can be found in the storage section on your profile page.
|
||||
The `NFS_SERVER` and `NFS_PATH` can be found in the `Storage` section on your profile page.
|
||||
|
||||
#### Upload data to NFS server in Windows
|
||||
|
||||
|
|
@ -46,9 +46,9 @@ You could access `NFS` data by `Windows File Explorer` directly if:
|
|||
|
||||
To access it, use the file location `\\NFS_SERVER_ADDRESS` in `Window File Explorer`. It will prompt you to type in a username and a password:
|
||||
|
||||
- If OpenPAI is in basic authentication mode (this mode means you use basic username/password to log in to OpenPAI webportal), you can access nfs data through its configured username and password. Please note it is different from the one you use to log in to OpenPAI. If the administrator uses `storage-manager`, the default username/password for NFS is `smbuser` and `smbpwd`.
|
||||
- If OpenPAI is in basic authentication mode (this mode means you use a basic username/password to log in to OpenPAI web portal), you can access NFS data through its configured username and password. Please note it is different from the one you use to log in to OpenPAI. If the administrator uses `storage-manager`, the default username/password for NFS is `smbuser` and `smbpwd`.
|
||||
|
||||
- If OpenPAI is in AAD authentication mode, you can access nfs data through user domain name and password.
|
||||
- If OpenPAI is in AAD authentication mode, you can access NFS data through the user domain name and password.
|
||||
|
||||
If it doesn't work, please make sure the `network discovery` is on, or contact your administrator for help.
|
||||
|
||||
|
|
@ -62,15 +62,15 @@ For Azure File, you can get the `storage account name` and `file share name` on
|
|||
|
||||
To upload data to Azure Blob or Azure File, please:
|
||||
|
||||
1. Download [Azure Storage Explorer](https://azure.microsoft.com/en-us/features/storage-explorer/)
|
||||
2. If you use AAD to login to PAI portal, the administrator should already grant you the permission to access storage. You can get the `storage account name`, `container name` and `file share name` on the profile page. Please use them to access storage in `Azure Storage Explorer`. For more details, please refer to [storage explore: add resource via azure ad](https://docs.microsoft.com/en-us/azure/vs-azure-tools-storage-manage-with-storage-explorer?tabs=windows#add-a-resource-via-azure-ad)
|
||||
3. If you use basic authentication (username/password) to login to PAI portal. Please ask your administrator for the storage `access key`. Then you can add the storage by `access key` and `storage account name`. For more details, please refer to: [storage explore: use name and key](https://docs.microsoft.com/en-us/azure/vs-azure-tools-storage-manage-with-storage-explorer?tabs=windows#use-a-name-and-key)
|
||||
1. Download and install [Azure Storage Explorer](https://azure.microsoft.com/en-us/features/storage-explorer/).
|
||||
2. If you use AAD to login into the PAI portal, the administrator should already permit you to access storage. You can get the `storage account name`, `container name`, and `file share name` on the profile page. Please use them to access storage in `Azure Storage Explorer`. For more details, please refer to [storage explore: add resource via azure ad](https://docs.microsoft.com/en-us/azure/vs-azure-tools-storage-manage-with-storage-explorer?tabs=windows#add-a-resource-via-azure-ad).
|
||||
3. If you use basic authentication (username/password) to login into the PAI portal, please ask your administrator for the storage `access key`. Then you can add the storage by `access key` and `storage account name`. For more details, please refer to [storage explore: use name and key](https://docs.microsoft.com/en-us/azure/vs-azure-tools-storage-manage-with-storage-explorer?tabs=windows#use-a-name-and-key).
|
||||
|
||||
## Use Storage in Jobs
|
||||
|
||||
### Use Data Section UI
|
||||
|
||||
You can use the `Data` Section on the job submission page to select desired storage:
|
||||
You can select desired storage in the `Data` section on the job submission page:
|
||||
|
||||

|
||||
|
||||
|
|
@ -90,9 +90,9 @@ extras:
|
|||
|
||||
There are two fields for each storage, `name` and `mountPath`. `name` refers to storage name while `mountPath` is the mount path inside job container. `mountPath` has default value `/mnt/${name}` and is optional.
|
||||
|
||||
Set it to an empty list (as follows) will mount default storage for the current user in the job.
|
||||
|
||||
```yaml
|
||||
extras:
|
||||
storages: []
|
||||
```
|
||||
|
||||
Set it to an empty list will mount default storage for current user in the job.
|
||||
|
|
|
|||
|
|
@ -1,12 +1,12 @@
|
|||
## How OpenPAI Deploy Distributed Jobs
|
||||
### Taskrole and Instance
|
||||
When we execute distributed programs on PAI, we can add different task roles for our job. For single server jobs, there is only one task role. For distributed jobs, there may be multiple task roles. For example, when TensorFlow is used to running distributed jobs, it has two roles, including the parameter server and the worker. In distributed jobs, each role may have one or more instances. For example, if it's 8 instances in a worker role of TensorFlow. It means there should be 8 Docker containers for the worker role. Please visit [here](./how-to-use-advanced-job-settings.md#multiple-task-roles) for specific operations.
|
||||
When we execute distributed programs on PAI, we can add different task roles for our job. For single server jobs, there is only one task role. For distributed jobs, there may be multiple task roles. For example, when TensorFlow is used to running distributed jobs, it has two roles, including the parameter server and the worker. In distributed jobs, each role may have one or more instances. For example, if it's 8 instances in a worker role of TensorFlow, it means there should be 8 Docker containers for the worker role. Please visit [here](./how-to-use-advanced-job-settings.md#multiple-task-roles) for specific operations.
|
||||
|
||||
### Environmental variables
|
||||
In a distributed job, one task might communicate with others (When we say task, we mean a single instance of a task role). So a task need to be aware of other tasks' runtime information such as IP, port, etc. The system exposes such runtime information as environment variables to each task's Docker container. For mutual communication, users can write code in the container to access those runtime environment variables. Please visit [here](./how-to-use-advanced-job-settings.md#environmental-variables-and-port-reservation) for specific operations.
|
||||
In a distributed job, one task might communicate with others (When we say task, we mean a single instance of a task role). So a task needs to be aware of other tasks' runtime information such as IP, port, etc. The system exposes such runtime information as environment variables to each task's Docker container. For mutual communication, users can write code in the container to access those runtime environment variables. Please visit [here](./how-to-use-advanced-job-settings.md#environmental-variables-and-port-reservation) for specific operations.
|
||||
|
||||
### Retry policy and Completion policy
|
||||
If unknown error happens, PAI will retry the job according to user settings. To set a retry policy and completion policy for user's job,PAI asks user to switch to Advanced mode. Please visit [here](./how-to-use-advanced-job-settings.md#job-exit-spec-retry-policy-and-completion-policy) for specific operations.
|
||||
If an unknown error happens, PAI will retry the job according to user settings. To set a retry policy and completion policy for the user's job,PAI asks the user to switch to Advanced mode. Please visit [here](./how-to-use-advanced-job-settings.md#job-exit-spec-retry-policy-and-completion-policy) for specific operations.
|
||||
### Run PyTorch Distributed Jobs in OpenPAI
|
||||
Example Name | Multi-GPU | Multi-Node | Backend |Apex| Job protocol |
|
||||
---|---|---|---|---|---|
|
||||
|
|
@ -18,16 +18,16 @@ cifar10-single-mul-DDP-nccl-Apex-mixed | ✓| ✓ | nccl| ✓ | [cifar10-singl
|
|||
imagenet-single-mul-DDP-gloo | ✓| ✓| gloo|-| [imagenet-single-mul-DDP-gloo.yaml](https://github.com/microsoft/pai/tree/master/examples/Distributed-example/Lite-imagenet-single-mul-DDP-gloo.yaml)|
|
||||
|
||||
## DataParallel
|
||||
The single node program is simple. The program executed in PAI is exactly the same as the program in our machine. It should be noted that an Worker can be applied in PAI and a Instance can be applied in Worker. In a worker, we can apply for GPUs that we need. We provide an [example](../../../examples/Distributed-example/cifar10-single-node-gpus-cpu-DP.py) of DP.
|
||||
The single-node program is simple. It mainly uses the DataParallel (DP) provided by PyTorch to realize multi-GPU training. The program executed in PAI is the same as the program in our machine. It should be noted that a `worker` can be applied in PAI and an `instance` can be applied in the `worker`. In a worker, we can apply for GPUs that we need. We provide an [example](../../../examples/Distributed-example/cifar10-single-node-gpus-cpu-DP.py) of DP.
|
||||
|
||||
## DistributedDataParallel
|
||||
DDP requires users set a master node ip and port for synchronization in PyTorch. For the port, you can simply set one certain port, such as `5000` as your master port. However, this port may conflict with others. To prevent port conflict, you can reserve a port in OpenPAI, as we mentioned [here](./how-to-use-advanced-job-settings.md#environmental-variables-and-port-reservation). The port you reserved is available in environmental variables like `PAI_PORT_LIST_$taskRole_$taskIndex_$portLabel`, where `$taskIndex` means the instance index of that task role. For example, if your task role name is `work` and port label is `SyncPort`, you can add the following code in your PyTorch DDP program:
|
||||
DDP requires users to set a master node IP and port for synchronization in PyTorch. For the port, you can simply set one certain port, such as `5000` as your master port. However, this port may conflict with others. To prevent port conflict, you can reserve a port in OpenPAI, as we mentioned [here](./how-to-use-advanced-job-settings.md#environmental-variables-and-port-reservation). The port you reserved is available in environmental variables like `PAI_PORT_LIST_$taskRole_$taskIndex_$portLabel`, where `$taskIndex` means the instance index of that task role. For example, if your task role name is `work` and the port label is `SyncPort`, you can add the following code in your PyTorch DDP program:
|
||||
|
||||
```
|
||||
os.environ['MASTER_ADDR'] = os.environ['PAI_HOST_IP_worker_0']
|
||||
os.environ['MASTER_PORT'] = os.environ['PAI_worker_0_SynPort_PORT']
|
||||
```
|
||||
If you are using `gloo` as your DDP communication backend, please set correct network interface such as `export GLOO_SOCKET_IFNAME=eth0`.
|
||||
If you are using `gloo` as your DDP communication backend, please set the correct network interface such as `export GLOO_SOCKET_IFNAME=eth0`.
|
||||
|
||||
|
||||
We provide examples with [gloo](https://github.com/microsoft/pai/tree/master/examples/Distributed-example/cifar10-single-mul-DDP-gloo.yaml) and [nccl](https://github.com/microsoft/pai/tree/master/examples/Distributed-example/cifar10-single-mul-DDP-nccl.yaml) as backend.
|
||||
|
|
|
|||
|
|
@ -2,13 +2,13 @@
|
|||
|
||||
## Parameters and Secrets
|
||||
|
||||
It is common to train models with different parameters. OpenPAI supports parameter definition and reference, which provides a flexible way of training and comparing models. You can define your parameters in `Parameters` section and reference them by using `<% $parameters.paramKey %>` in your commands. For example, the following picture shows how to define the [Quick Start](./quick-start.md) job using a `stepNum` parameter.
|
||||
It is common to train models with different parameters. OpenPAI supports parameter definition and reference, which provides a flexible way of training and comparing models. You can define your parameters in the `Parameters` section and reference them by using `<% $parameters.paramKey %>` in your commands. For example, the following picture shows how to define the [Quick Start](./quick-start.md) job using a `stepNum` parameter.
|
||||
|
||||
<img src="./imgs/use-parameters.png" width="100%" height="100%" />
|
||||
|
||||
You can define batch size, learning rate, or whatever you want as parameters to accelerate your job submission.
|
||||
|
||||
In some cases, it is desired to define some secret messages such as password, token, etc. You can use the `Secrets` section for the information. The usage is the same as parameters except that secrets will not be displayed or recorded.
|
||||
In some cases, it is desired to define some secret messages such as passwords, tokens, etc. You can use the `Secrets` section for the definition. The usage is the same as parameters except that secrets will not be displayed or recorded.
|
||||
|
||||
## Multiple Task Roles
|
||||
|
||||
|
|
@ -16,15 +16,15 @@ If you use the `Distributed` button to submit jobs, then you can add different t
|
|||
|
||||
<img src="./imgs/distributed-job.png" width="60%" height="60%" />
|
||||
|
||||
What is task role? For single server jobs, there is only one task role. For distributed jobs, there may be multiple task roles. For example, when TensorFlow is used to running distributed jobs, it has two roles, including the parameter server and the worker.
|
||||
What is a task role? For single server jobs, there is only one task role. For distributed jobs, there may be multiple task roles. For example, when TensorFlow is used to run distributed jobs, it has two roles, including the parameter server and the worker.
|
||||
|
||||
`Instances` in the following picture is the number of instances of certain task role. In distributed jobs, it depends on how many instances are needed for a task role. For example, if it's 8 in a worker role of TensorFlow. It means there should be 8 Docker containers for the worker role.
|
||||
`Instances` in the following picture is the number of instances of certain task roles. In distributed jobs, it depends on how many instances are needed for a task role. For example, if you set instances to 8 for a TensorFlow worker task role, it means there should be 8 Docker containers for the worker role.
|
||||
|
||||
<img src="./imgs/taskrole-and-instance.png" width="100%" height="100%" />
|
||||
|
||||
### Environmental Variables and Port Reservation
|
||||
|
||||
In a distributed job, one task might communicate with others (When we say task, we mean a single instance of a task role). So a task need to be aware of other tasks' runtime information such as IP, port, etc. The system exposes such runtime information as environment variables to each task's Docker container. For mutual communication, users can write code in the container to access those runtime environment variables.
|
||||
In a distributed job, one task might communicate with others (When we say task, we mean a single instance of a task role). So a task needs to be aware of other tasks' runtime information such as IP, port, etc. The system exposes such runtime information as environment variables to each task's Docker container. For mutual communication, users can write code in the container to access those runtime environment variables.
|
||||
|
||||
Below we show a complete list of environment variables accessible in a Docker container:
|
||||
|
||||
|
|
@ -50,7 +50,7 @@ Some environmental variables are in association with ports. In OpenPAI, you can
|
|||
|
||||
The ports you reserved are available in environmental variables like `PAI_PORT_LIST_$taskRole_$taskIndex_$portLabel`, where `$taskIndex` means the instance index of that task role.
|
||||
|
||||
For a detailed summary, there are two ways to reference a declared port (list)
|
||||
For a detailed summary, there are two ways to reference a declared port (list):
|
||||
|
||||
- use [Indirection](https://stackoverflow.com/a/16553351/1012014) supported by `bash` as below
|
||||
```bash
|
||||
|
|
@ -58,7 +58,7 @@ MY_PORT="PAI_PORT_LIST_${PAI_CURRENT_TASK_ROLE_NAME}_${PAI_CURRENT_TASK_ROLE_CUR
|
|||
PORT=${!MY_PORT}
|
||||
```
|
||||
|
||||
*Note that you need use `$PAI_CURRENT_TASK_ROLE_NAME` and `$PAI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX`*
|
||||
*Note that you need to use `$PAI_CURRENT_TASK_ROLE_NAME` and `$PAI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX`*
|
||||
|
||||
- use a **to-be-deprecated** environmental variable to get port (list) in current container like
|
||||
```bash
|
||||
|
|
@ -70,23 +70,23 @@ PAI_CONTAINER_HOST_<port-label>_PORT_LIST
|
|||
|
||||
There are always different kinds of errors in jobs. In OpenPAI, errors are classified into 3 categories automatically:
|
||||
|
||||
1. Transient Error: This kind of error is considered transient. There is high chance to bypass it through a retry.
|
||||
1. Transient Error: This kind of error is considered transient. There is a high chance to bypass it through a retry.
|
||||
2. Permanent Error: This kind of error is considered permanent. Retries may not help.
|
||||
3. Unknown Error: Errors besides transient error and permanent error.
|
||||
|
||||
In jobs, transient error will be always retried, and permanent error will never be retried. If unknown error happens, PAI will retry the job according to user settings. To set a retry policy and completion policy for your job, please toggle the `Advanced` mode, as shown in the following image:
|
||||
In jobs, transient errors will be always retried, and permanent errors will never be retried. If an unknown error happens, PAI will retry the job according to user settings. To set a retry policy and completion policy for your job, please toggle the `Advanced` mode, as shown in the following image:
|
||||
|
||||
<img src="./imgs/advanced-and-retry.png" width="100%" height="100%" />
|
||||
|
||||
Here we have 3 settings: `Retry count`, `Task retry count`, and `Completion policy`. To explain them, we should be aware that a job is made up by multiple tasks. One task stands for a single instance in a task role. `Task retry count` is used for task-level retry. `Retry count` and `Completion policy` are used for job-level retry.
|
||||
Here we have 3 settings: `Retry count`, `Task retry count`, and `Completion policy`. To explain them, we should be aware that a job is made up of multiple tasks. One task stands for a single instance in a task role. `Task retry count` is used for task-level retry. `Retry count` and `Completion policy` are used for job-level retry.
|
||||
|
||||
Firstly, let's look at `Retry count` and `Completion policy`.
|
||||
|
||||
In `Completion policy`, there are settings for `Min Failed Instances` and `Min Succeed Instances`. `Min Failed Instances` means the number of failed tasks to fail the entire job. It should be -1 or no less than 1. If it is set to -1, the job will always succeed regardless of any task failure. Default value is 1, which means 1 failed task will cause an entire job failure. `Min Succeed Instances` means the number of succeeded tasks to succeed the entire job. It should be -1 or no less than 1. If it is set to -1, the job will only succeed until all tasks are completed and `Min Failed Instances` is not triggered. Default value is -1.
|
||||
In `Completion policy`, there are settings for `Min Failed Instances` and `Min Succeed Instances`. `Min Failed Instances` means the number of failed tasks to fail the entire job. It should be -1 or no less than 1. If it is set to -1, the job will always succeed regardless of any task failure. The default value is 1, which means 1 failed task will cause an entire job failure. `Min Succeed Instances` means the number of succeeded tasks to succeed the entire job. It should be -1 or no less than 1. If it is set to -1, the job will only succeed until all tasks are completed and `Min Failed Instances` is not triggered. The default value is -1.
|
||||
|
||||
If a job doesn't succeed after it satisfies `Completion policy`, the failure is caused by an unknown error, and `Retry count` is larger than 0, the whole job will be retried. Set `Retry count` to a larger number if you need more retries.
|
||||
If a job: 1. doesn't succeed after it satisfies `Completion policy`, 2. fails with an unknown error, and 3. has a `Retry count` larger than 0, the whole job will be retried. Set `Retry count` to a larger number if you need more retries.
|
||||
|
||||
Finally, for `Task retry count`, it is the maximum retry number for a single task. A special notice is that, this setting won't work unless you set `extras.gangAllocation` to `false` in the [job protocol](#job-protocol-export-and-import-jobs).
|
||||
Finally, for `Task retry count`, it is the maximum retry number for a single task. A special notice is that this setting won't work unless you set `extras.gangAllocation` to `false` in the [job protocol](#job-protocol-export-and-import-jobs).
|
||||
|
||||
## Job Protocol, Export and Import Jobs
|
||||
|
||||
|
|
@ -98,7 +98,7 @@ Use the `Save` button to apply any changes:
|
|||
|
||||
<img src="./imgs/click-save-yaml.png" width="100%" height="100%" />
|
||||
|
||||
You can also export and import YAML files using the `Export` and `Import` button.
|
||||
You can also export and import YAML files using the `Export` and `Import` buttons.
|
||||
|
||||
<img src="./imgs/export-and-import.png" width="100%" height="100%" />
|
||||
|
||||
|
|
@ -116,7 +116,7 @@ This example, [horovod-pytorch-synthetic-benchmark.yaml](https://github.com/micr
|
|||
|
||||
## InfiniBand Jobs
|
||||
|
||||
Here's an example for InfiniBand job:
|
||||
Here's an example for an InfiniBand job:
|
||||
|
||||
```yaml
|
||||
protocolVersion: 2
|
||||
|
|
@ -125,7 +125,7 @@ type: job
|
|||
version: horovod0.16.4-tf1.12.0-torch1.1.0-mxnet1.4.1-py3.5
|
||||
contributor: OpenPAI
|
||||
description: |
|
||||
This is a distributed synthetic benchmark for Horovod with PyTorch backend running on OpenPAI.
|
||||
This is a distributed synthetic benchmark for Horovod with the PyTorch backend running on OpenPAI.
|
||||
It runs [Horovod with Open MPI](https://github.com/horovod/horovod/blob/master/docs/mpirun.rst).
|
||||
parameters:
|
||||
model: resnet50
|
||||
|
|
|
|||
|
|
@ -14,17 +14,17 @@ Now your first OpenPAI job has been kicked off!
|
|||
|
||||
## Browse Stdout, Stderr, Full logs, and Metrics
|
||||
|
||||
The hello world job is implemented by TensorFlow. It trains a simple model on CIFAR-10 dataset for 1,000 steps with downloaded data. You can monitor the job by checking its logs and running metrics on webportal.
|
||||
The hello world job is implemented by TensorFlow. It trains a simple model on the CIFAR-10 dataset for 1,000 steps with downloaded data. You can monitor the job by checking its logs and running metrics on the web portal.
|
||||
|
||||
Click `Stdout` and `Stderr` button to see the stdout and stderr logs for a job on the job detail page. If you want to see a merged log, you can click `...` on the right and then select `Stdout + Stderr`.
|
||||
Click the `Stdout` and `Stderr` buttons to see the stdout and stderr logs for a job on the job detail page. If you want to see a merged log, you can click `...` on the right and then select `Stdout + Stderr`.
|
||||
|
||||
<img src="./imgs/view-logs.png" width="90%" height="90%" />
|
||||
|
||||
As shown in the following picture, we will only show last 16KB logs in the dialog. Click `View Full Log` for a full log.
|
||||
As shown in the following screenshot, we will only show the last 16KB logs in the dialog. Click `View Full Log` for a full log.
|
||||
|
||||
<img src="./imgs/view-stderr.png" width="90%" height="90%" />
|
||||
|
||||
On the job detail page, you can also see metrics by clicking `Go to Job Metrics Page`. Then the CPU/GPU utilization and network will be shown in a new window:
|
||||
On the job detail page, you can also see metrics by clicking `Go to Job Metrics Page`. Then the data (including CPU / GPU utilization, network usage, etc.) will be displayed in a new window:
|
||||
|
||||
<img src="./imgs/view-metrics.gif" width="90%" height="90%" />
|
||||
|
||||
|
|
@ -49,13 +49,13 @@ python download_and_convert_data.py --dataset_name=cifar10 --dataset_dir=/tmp/da
|
|||
python train_image_classifier.py --dataset_name=cifar10 --dataset_dir=/tmp/data --max_number_of_steps=1000
|
||||
```
|
||||
|
||||
Note: Please **Do Not** use `#` for comments or use `\` for line continuation in the command box. These symbols may break the syntax and will be supported in the future.
|
||||
Note: Please **DO NOT** use `#` for comments or use `\` for line continuation in the command box. These symbols may break the syntax and will be supported in the future.
|
||||
|
||||
<img src="./imgs/input-command.png" width="90%" height="90%" />
|
||||
|
||||
**Step 4.** Specify the resources you need. OpenPAI uses **resource SKU** to quantify the resource in one instance. For example, here 1 `DT` SKU means 1 GPU, 5 CPUs, and 53914 MB memory. If you specify one `DT` SKU, you will get a container with 1 GPU, 5 CPUs, and 53914 MB memory. If you specify two `DT` SKUs, you will get a container with 2 GPUs, 10 CPUs, and 107828 MB memory.
|
||||
|
||||
**Step 5.** Specify the docker image. You can either use the listed docker images or take advantage of your own one. Here we select `TensorFlow 1.15.0 + Python 3.6 with GPU, CUDA 10.0`, which is a pre-built image. We will introduce more about docker images in [Docker Images and Job Examples](./docker-images-and-job-examples.md).
|
||||
**Step 5.** Specify the Docker image. You can either use the listed docker images or take advantage of your own. Here we select `TensorFlow 1.15.0 + Python 3.6 with GPU, CUDA 10.0`, which is a pre-built image. We will introduce more about docker images in [Docker Images and Job Examples](./docker-images-and-job-examples.md).
|
||||
|
||||
<img src="./imgs/input-docker.png" width="90%" height="90%" />
|
||||
|
||||
|
|
@ -65,10 +65,10 @@ Note: Please **Do Not** use `#` for comments or use `\` for line continuation in
|
|||
|
||||
Here are some detailed explanations about configurations on the submission page:
|
||||
|
||||
- **Job name** is the name of current job. It must be unique in each user account. A meaningful name helps manage jobs well.
|
||||
- **Job name** is the name of the current job. It must be unique within all jobs of the same user account. A meaningful name helps manage jobs well.
|
||||
|
||||
- **Command** is the commands to run in this task role. It can be multiple lines. For example, in the hello-world job, the command clones code from GitHub, downloads data and then executes the training progress. If one command fails (exits with a nonzero code), the following commands will not be executed. This behavior may be changed in the future.
|
||||
- **Command** is the commands to run in this task role. It can be multiple lines. For example, in the hello-world job, the command clones code from GitHub, downloads data, and then executes the training progress. If one command fails (exits with a nonzero code), the following commands will not be executed. This behavior may be changed in the future.
|
||||
|
||||
- **GPU count**, **CPU vcore count**, **Memory (MB)** are easy to understand. They specify corresponding hardware resources including the number of GPUs, the number of CPU cores, and MB of memory.
|
||||
- **GPU count**, **CPU vcore count**, **Memory (MB)** are easy to understand. They specify corresponding hardware resources including the number of GPUs, the number of CPU cores, and the amount of memory in MB.
|
||||
|
||||
We will introduce more details about the job configuration in [`How to Use Advanced Job Settings`](./how-to-use-advanced-job-settings.md).
|
||||
|
|
@ -1,3 +1,3 @@
|
|||
# Use Jupyter Notebook Extension
|
||||
|
||||
Jupyter Notebook Extension is under development to fix compatibility issues with new version of PAI.
|
||||
Jupyter Notebook Extension is under development to fix compatibility issues with a new version of PAI.
|
||||
|
|
|
|||
|
|
@ -1,23 +1,25 @@
|
|||
# Use Marketplace
|
||||
|
||||
[OpenPAI Marketplace](https://github.com/microsoft/openpaimarketplace) can store job examples and templates. You can use marketplace to run-and-learn others' sharing jobs or share your own jobs.
|
||||
[OpenPAI Marketplace](https://github.com/microsoft/openpaimarketplace) can store job examples and templates. You can use Marketplace to run-and-learn others' sharing jobs or share your jobs.
|
||||
|
||||
## Entrance
|
||||
|
||||
If your administrator enables marketplace plugin, you will find a link in the `Plugin` section on webportal, like:
|
||||
If your administrator enables marketplace plugin, you will find a link in the `Plugin` section on the web portal, like:
|
||||
|
||||
> If you are pai admin, you could check [deployment doc](https://github.com/microsoft/openpaimarketplace/blob/master/docs/deployment.md) to see how to deploy and enable marketplace plugin.
|
||||
> If you are PAI admin, you could check [deployment doc](https://github.com/microsoft/openpaimarketplace/blob/master/docs/deployment.md) to see how to deploy and enable marketplace plugin.
|
||||
|
||||

|
||||
|
||||
## Use Templates on Marketplace
|
||||
|
||||
The marketplace plugin has some official templates in market list by default, to use the templates on marketplace, you can click `Submit` directly, and it will bring you to the job submission page. Or you could click view button to view the information about this template.
|
||||
The marketplace plugin has some official templates in the market list by default, to use the templates on Marketplace, you can click `Submit` directly, and it will bring you to the job submission page. Or you could click the `View` button to view the information about this template.
|
||||
|
||||

|
||||
|
||||
## Create your Own Templates
|
||||
## Create your Templates
|
||||
|
||||
To create a marketplace template, click the `Create` button on the page. As shown in the following picture, you could create the template from scratch with a config yaml file. You should fill in some necessary info like `name`, `introduction` and `description` etc. Another approach is creating from your existing job in pai platform. You can only create marketplace template from one `Succeeded` job. After creating, your templates will be awaiting for review by platform admin before you could see them in market list.
|
||||
To create a marketplace template, click the `Create` button on the page. As shown in the following picture, you could create the template from scratch with a config YAML file. You should fill in some necessary info like `name`, `introduction` and `description` etc.
|
||||
|
||||
Another approach is creating from your existing job in the PAI platform. You can only create a Marketplace template from one `Succeeded` job. After creating, your templates will be awaiting review by the platform admin before you could see them in the market list.
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
## Connect to an OpenPAI cluster
|
||||
|
||||
Before using OpenPAI VS Code Client, follow below steps connecting to an OpenPAI cluster. If you are using username and password to login to the cluster, then you should follow `Basic login`. If you are using AAD to login to the cluster, please follow `AAD login`.
|
||||
Before using OpenPAI VS Code Client, follow these steps to connect to an OpenPAI cluster. If you are using a username and password to login into the cluster, then you should follow `Basic login`. If you are using AAD to login to the cluster, please follow `AAD login`.
|
||||
|
||||
### Basic login
|
||||
|
||||
|
|
@ -17,11 +17,11 @@ Before using OpenPAI VS Code Client, follow below steps connecting to an OpenPAI
|
|||
|
||||

|
||||
|
||||
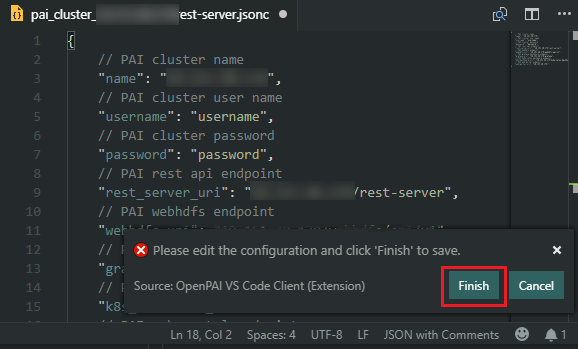
4. A configuration file is opened, and username and password fields are needed at least. Once it completes, click *Finish* button at right bottom corner. Notice, it won't be effect, if you save and close the file directly.
|
||||
4. A configuration file is opened, and the username and password fields are needed at least. Once it completes, click the *Finish* button at the bottom right corner. Notice, the settings will not take effect if you save and close the file directly.
|
||||
|
||||
|
||||
|
||||
If there are multiple OpenPAI clusters, you can follow above steps again to connect with them.
|
||||
If there are multiple OpenPAI clusters, you can follow the above steps again to connect with them.
|
||||
|
||||
### AAD login
|
||||
|
||||
|
|
@ -34,30 +34,30 @@ If there are multiple OpenPAI clusters, you can follow above steps again to conn
|
|||
|
||||

|
||||
|
||||
4. If the `authn_type` of the cluster is `OIDC`, a webside will be open and ask you to login, after that a configuration file is opened, and if your login was successful the username and token fields are auto filled, you can change it if needed. Once it completes, click *Finish* button at right bottom corner. Notice, it won't be effect, if you save and close the file directly.
|
||||
4. If the `authn_type` of the cluster is `OIDC`, a website will be open and ask you to log in. If your login was successful, the username and token fields are auto-filled, and you can change them if needed. Once it completes, click the *Finish* button at the bottom right corner. Notice, the settings will not take effect if you save and close the file directly.
|
||||
|
||||
|
||||
|
||||
If there are multiple OpenPAI clusters, you can follow above steps again to connect with them.
|
||||
If there are multiple OpenPAI clusters, you can follow the above steps again to connect with them.
|
||||
|
||||
## Submit job
|
||||
## Submit jobs
|
||||
|
||||
After added a cluster configuration, you can find the cluster in *PAI CLUSTER EXPLORER* pane as below.
|
||||
After added a cluster configuration, you can find the cluster in the *PAI CLUSTER EXPLORER* pane as below.
|
||||
|
||||
|
||||
|
||||
To submit a job yaml, please follow the steps below:
|
||||
To submit a job config YAML file, please follow the steps below:
|
||||
|
||||
1. Double click `Create Job Config...` in OpenPAI cluster Explorer, and then specify file name and location to create a job configuration file.
|
||||
1. Double-click `Create Job Config...` in OpenPAI cluster Explorer, and then specify file name and location to create a job configuration file.
|
||||
2. Update job configuration as needed.
|
||||
3. Right click on the created job configuration file, then click on `Submit Job to PAI Cluster`. The client will upload files to OpenPAI and create a job. Once it's done, there is a notification at right bottom corner, you can click to open the job detail page.
|
||||
3. Right-click on the created job configuration file, then click on `Submit Job to PAI Cluster`. The client will then upload files to OpenPAI and create a job. Once it's done, there is a notification at the bottom right corner, you can click to open the job detail page.
|
||||
|
||||
If there are multiple OpenPAI clusters, you need to choose one.
|
||||
|
||||
This animation shows above steps.
|
||||
This animation shows the above steps.
|
||||
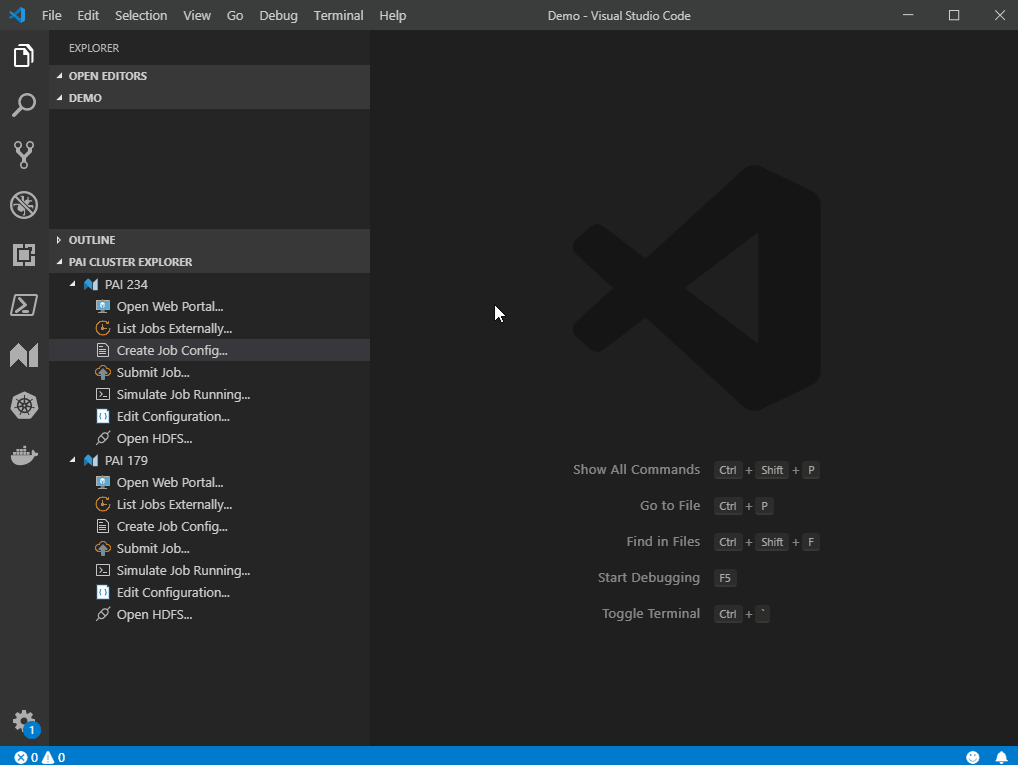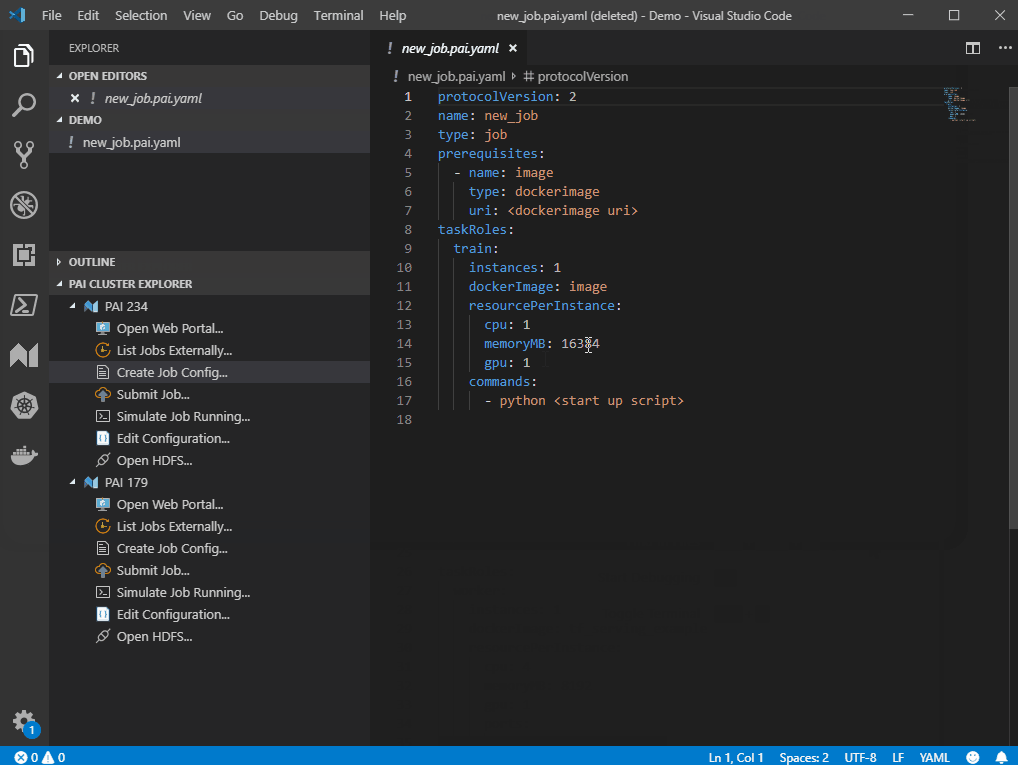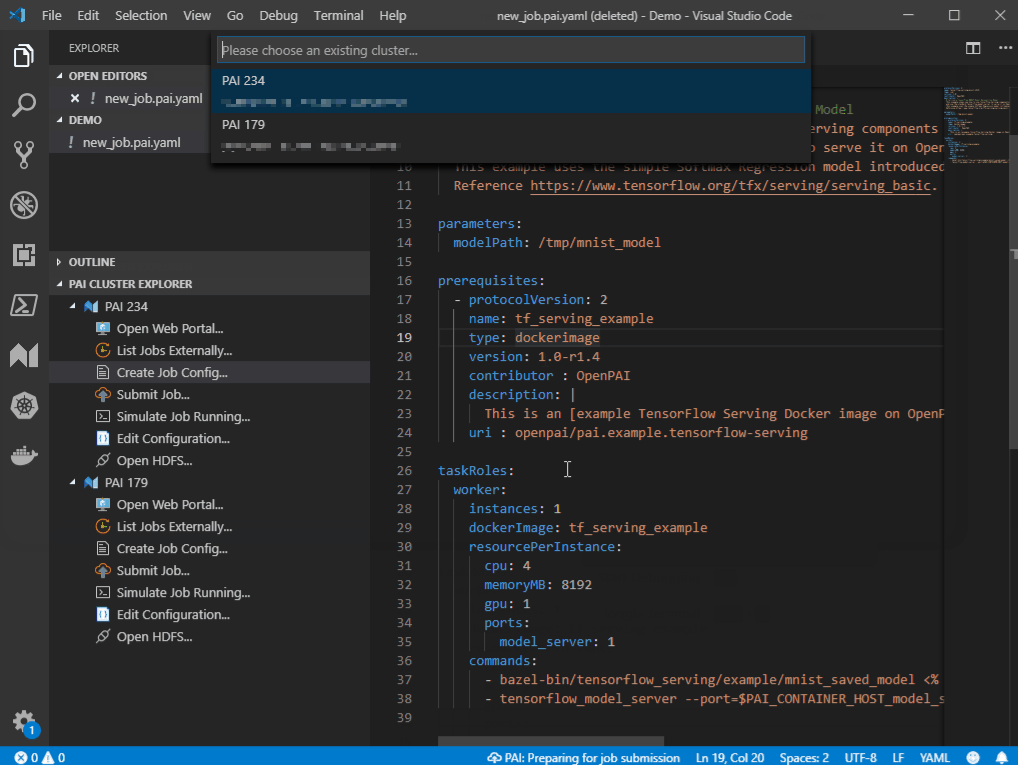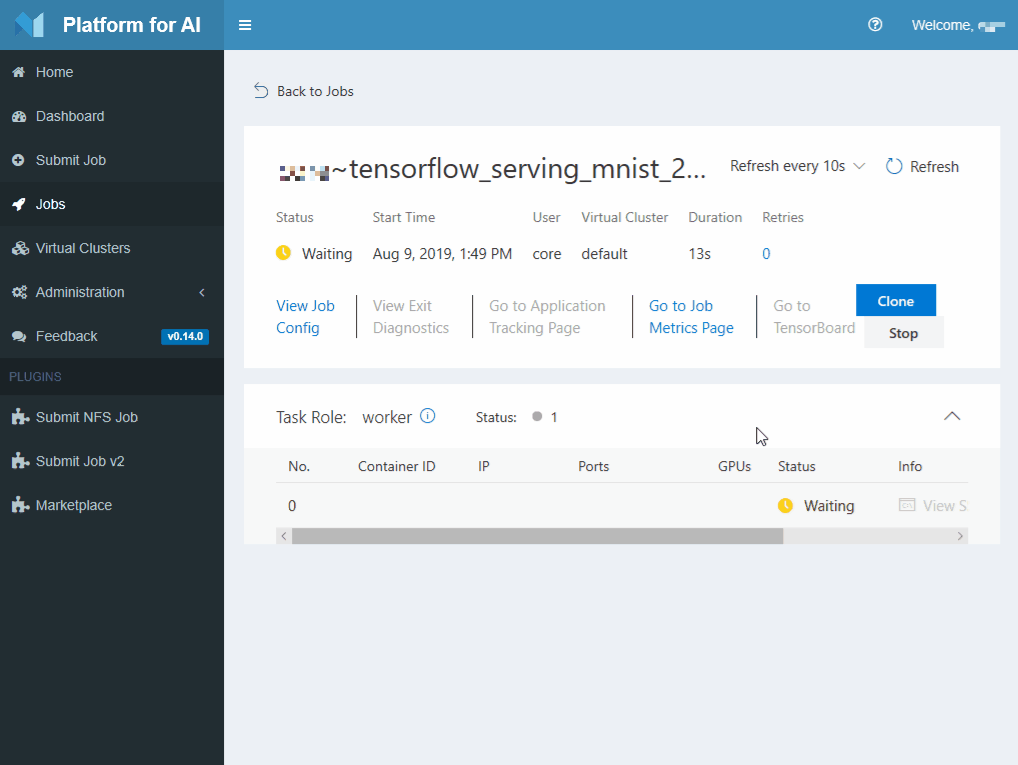
|
||||
|
||||
|
||||
## Reference
|
||||
|
||||
- [Full documentation of VSCode Extension](https://github.com/microsoft/openpaivscode/blob/master/README.md): Please note two kinds of jobs are mentioned in this full documentation: V1 and V2 job. You can safely skip contents about V1 job since it is deprecated.
|
||||
- [Full documentation of VSCode Extension](https://github.com/microsoft/openpaivscode/blob/master/README.md): Please note two kinds of jobs are mentioned in this full documentation: V1 and V2 job. You can safely skip contents about the V1 job since it is deprecated.
|
||||
|
|
|
|||
|
|
@ -1,12 +1,12 @@
|
|||
## An Open AI Platform for R&D and Education
|
||||
One key purpose of PAI is to support the highly diversified requirements from academia and industry. PAI is completely open: it is under the MIT license. PAI is architected in a modular way: different module can be plugged in as appropriate. This makes PAI particularly attractive to evaluate various research ideas, which include but not limited to the following components:
|
||||
One key purpose of PAI is to support the highly diversified requirements from academia and industry. PAI is completely open: it is under the MIT license. PAI is architected in a modular way: different modules can be plugged in as appropriate. This makes PAI particularly attractive to evaluate various research ideas, which include but not limited to the following components:
|
||||
|
||||
* Scheduling mechanism for deep learning workload
|
||||
* Deep neural network application that requires evaluation under realistic platform environment
|
||||
* Deep neural network application that requires evaluation under a realistic platform environment
|
||||
* New deep learning framework
|
||||
* AutoML
|
||||
* Compiler technique for AI
|
||||
* High performance networking for AI
|
||||
* High-performance networking for AI
|
||||
* Profiling tool, including network, platform, and AI job profiling
|
||||
* AI Benchmark suite
|
||||
* New hardware for AI, including FPGA, ASIC, Neural Processor
|
||||
|
|
|
|||
|
|
@ -2,17 +2,17 @@
|
|||
|
||||
## Search existing questions
|
||||
|
||||
We recommend searching before asking. In case someone met the similar problem, it may save your time. [click here](https://stackoverflow.com/questions/tagged/openpai) to find related questions.
|
||||
We recommend searching before asking. In case someone met a similar problem, it may save your time. [click here](https://stackoverflow.com/questions/tagged/openpai) to find related questions.
|
||||
|
||||
## Ask a question about OpenPAI
|
||||
|
||||
1. Click [the link](https://stackoverflow.com/questions/ask?tags=openpai) with 'openpai' tag.
|
||||
|
||||
You need to sign up at first use. Go ahead, Stack Overflow is a trustworthy web site. Or you can ask question on [github](https://github.com/Microsoft/pai/issues/new/choose) directly.
|
||||
You need to sign up at first use. Go ahead, Stack Overflow is a trustworthy website. Or you can ask the question on [github](https://github.com/Microsoft/pai/issues/new/choose) directly.
|
||||
|
||||
1. Read the advice and proceed.
|
||||
1. Read the advice and proceed with your question.
|
||||
|
||||
You can read advice or search related topic again. If you still want to post a new question, choose the checkbox below, and click 'proceed'.
|
||||
You can read advice or search-related topic again. If you still want to post a new question, choose the checkbox below, and click 'proceed'.
|
||||
|
||||

|
||||
|
||||
|
|
@ -22,7 +22,7 @@ We recommend searching before asking. In case someone met the similar problem, i
|
|||
|
||||
1. Add any relevant tags.
|
||||
|
||||
In the tags field, when you begin typing, the Stack Overflow system will automatically suggest likely tags to help you with this process. We already choose 'opanpai' tag for you.
|
||||
In the tags field, when you begin typing, the Stack Overflow system will automatically suggest likely tags to help you with this process. We already choose the 'opanpai' tag for you.
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -16,12 +16,12 @@ The hardware and software requirements include GPU/CPU/Memory resource requireme
|
|||
OpenPAI protocol facilitates platform interoperability and job portability, a job described by the protocol can run on different clusters managed by OpenPAI, as long as the clusters can meet the specification.
|
||||
The OpenPAI protocol also enables great flexibility, any AI workload, being it Tensorflow, PyTorch, or your proprietary deep learning workload, can be described by the protocol.
|
||||
|
||||
Job orchestrator and OpenPAI runtime are two key components that understand and execute the workload specified by the OpenPAI protocol. Job orechestrator is implemented by leveraging [FrameworkController](https://github.com/Microsoft/frameworkcontroller), a general purpose k8s controller that orchestrates k8s Pods supporting all kinds of AI workloads. The [OpenPAI runtime](https://github.com/microsoft/openpai-runtime) provides runtime support to the workload and implement [OpenPAI runtime parameters/variables](https://openpai.readthedocs.io/en/latest/manual/cluster-user/advanced-jobs.html) that are necessary to support the OpenPAI protocol.
|
||||
OpenPAI runtime also prebuilds with [failure analysis](../src/k8s-job-exit-spec/config/user-manual.md) rules that can detect typical runtime failure patterns. OpenPAI might take some actions against the detected failure pattens. For example, if OpenPAI finds the job failure is due to Python syntax error, it will not retry the job regardless of the job retry behavior specified by user to prevent from unnecessary retry and the corresponding waste of cluster resource.
|
||||
The failure rules can be updated on-the-fly by the cluster operaters. Wheneven new failure patterns discovered, the cluster operator can build them into the OpenPAI runtime.
|
||||
Job orchestrator and OpenPAI runtime are two key components that understand and execute the workload specified by the OpenPAI protocol. Job orchestrator is implemented by leveraging [FrameworkController](https://github.com/Microsoft/frameworkcontroller), a general-purpose k8s controller that orchestrates k8s Pods supporting all kinds of AI workloads. The [OpenPAI runtime](https://github.com/microsoft/openpai-runtime) provides runtime support to the workload and implement [OpenPAI runtime parameters/variables](https://openpai.readthedocs.io/en/latest/manual/cluster-user/advanced-jobs.html) that are necessary to support the OpenPAI protocol.
|
||||
OpenPAI runtime also prebuilds with [failure analysis](../src/k8s-job-exit-spec/config/user-manual.md) rules that can detect typical runtime failure patterns. OpenPAI might take some actions against the detected failure pattens. For example, if OpenPAI finds the job failure is due to a Python syntax error, it will not retry the job regardless of the job retry behavior specified by the user to prevent unnecessary retry and the corresponding waste of cluster resources.
|
||||
The failure rules can be updated on-the-fly by the cluster operators. Whenever new failure patterns are discovered the cluster operator can build them into the OpenPAI runtime.
|
||||
|
||||
OpenPAI provides comprehensive monitoring tools to users and cluster admins for job and cluster monitoring. OpenPAI also monitors the status of key OpenPAI components in the cluster and is able to send alerts (e.g., as in email) if pre-configed conditions have been triggered.
|
||||
OpenPAI provides comprehensive monitoring tools to users and cluster admins for the job and cluster monitoring. OpenPAI also monitors the status of key OpenPAI components in the cluster and can send alerts (e.g., as in email) if pre-confined conditions have been triggered.
|
||||
|
||||
OpenPAI is a modular platform, which is designed to enable various innovations. With the standard k8s scheduling API, OpenPAI introduces [HiveD](https://github.com/microsoft/hivedscheduler), an optional but recommended scheduler designed for deep learning workloads in a multi-tenant GPU cluster. HiveD provides various advantages over standard k8s scheduler. For example, it introduces a notion of "virtual cluster", which allows a team of users to run workload in the virtual cluster as if they reserve a private, dedicated (smaller) GPU cluster.
|
||||
HiveD's virtual cluster reserves GPU resource not only in terms of quota (i.e., number of GPU), but also in terms of **topology**. For example, with HiveD a virtual cluster can reserve a GPU node, or a rack of GPU nodes within the same InfiniBand domain, instead of a set of GPUs randomly scatters across the cluster. This is important to preserve the training speed for jobs within the virtual cluster.
|
||||
OpenPAI is a modular platform, which is designed to enable various innovations. With the standard k8s scheduling API, OpenPAI introduces [HiveD](https://github.com/microsoft/hivedscheduler), an optional but recommended scheduler designed for deep learning workloads in a multi-tenant GPU cluster. HiveD provides various advantages over the standard k8s scheduler. For example, it introduces a notion of a "virtual cluster", which allows a team of users to run a workload in the virtual cluster as if they reserve a private, dedicated (smaller) GPU cluster.
|
||||
HiveD's virtual cluster reserves GPU resources not only in terms of quota (i.e., number of GPU) but also in terms of **topology**. For example, with HiveD a virtual cluster can reserve a GPU node, or a rack of GPU nodes within the same InfiniBand domain, instead of a set of GPUs randomly scatters across the cluster. This is important to preserve the training speed for jobs within the virtual cluster.
|
||||
With HiveD, OpenPAI also provides better topology-aware gang scheduling with no [resource starvation](https://en.wikipedia.org/wiki/Starvation_(computer_science)). HiveD also supports multi-priority jobs and job preemption.
|
||||
|
|
|
|||
|
|
@ -14,4 +14,4 @@ OpenPAI是一个提供完整的人工智能模型训练和资源管理能力开
|
|||
|
||||
如果您想阅读关于OpenPAI的简单介绍,请访问[Github](https://github.com/microsoft/pai/blob/master/README.md)。
|
||||
|
||||
如果您想反馈问题/Bug/要求新Feature,请提交至[GitHub](https://github.com/microsoft/pai)。
|
||||
如果您想反馈问题/Bug或提供新Feature,请提交至[GitHub](https://github.com/microsoft/pai)。
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Docker镜像和任务示例
|
||||
|
||||
OpenPAI使用[Docker](https://www.docker.com/why-docker)提供一致且独立的环境。利用Docker,OpenPAI可以在同一服务器上处理多个任务请求。任务环境很大程度上依赖您选择的Docker镜像。
|
||||
OpenPAI使用[Docker](https://www.docker.com/why-docker)提供一致且独立的环境。基于Docker,OpenPAI可以在同一服务器上处理多个任务请求。任务环境很大程度上依赖您选择的Docker镜像。
|
||||
|
||||
## 预构建的Docker镜像介绍
|
||||
|
||||
|
|
@ -44,7 +44,7 @@ OpenPAI使用[Docker](https://www.docker.com/why-docker)提供一致且独立的
|
|||
|
||||
## 使用您自己的镜像
|
||||
|
||||
如果不使用预构建镜像,想要构建自己的自定义镜像,建议基于Ubuntu系统构建,Ubuntu中包含bash、apt和其他必须的依赖项。然后,您可以在docker镜像中添加任务需要的其他依赖包,例如python、pip和TensorFlow等,添加时请注意潜在的冲突。
|
||||
如果不使用预构建镜像,想要构建自己的自定义镜像,建议基于Ubuntu系统构建,因为Ubuntu中包含bash、apt和其他必须的依赖项。然后,您可以在docker镜像中添加任务需要的其他依赖包,例如python、pip和TensorFlow等,添加时请注意潜在的冲突。
|
||||
|
||||
## 如何使用私有Registry的镜像
|
||||
|
||||
|
|
|
|||
|
|
@ -2,6 +2,6 @@
|
|||
|
||||
## 为何我的任务会自动重试?
|
||||
|
||||
一般来说,OpenPAI中存在三种错误类型:瞬时错误,永久错误和未知错误。在任务中,瞬时错误将一直重试,而永久错误永远不会重试。如果发生未知错误,PAI将会根据任务的[重试策略](./how-to-use-advanced-job-settings.md#job-exit-spec-retry-policy-and-completion-policy)重试该任务,此策略由用户设置。
|
||||
一般来说,OpenPAI中存在三种错误类型:瞬时错误,永久错误和未知错误。在任务中,将一直重试瞬时错误,而永远不会重试永久错误。如果发生未知错误,PAI将会根据任务的[重试策略](./how-to-use-advanced-job-settings.md#job-exit-spec-retry-policy-and-completion-policy)重试该任务,此策略由用户设置。
|
||||
|
||||
如果您未设置任何[重试策略](./how-to-use-advanced-job-settings.md#job-exit-spec-retry-policy-and-completion-policy)却发现任务有意外的重试编号,可能是一些瞬时错误引起的,例如内存问题,磁盘压力或节点电源故障。另一种瞬时错误是抢占。优先级较高的任务可以抢占优先级较低的任务。在OpenPAI的[任务协议](https://github.com/microsoft/openpai-protocol/blob/master/schemas/v2/schema.yaml)中,您可以找到一个名为 `jobPriorityClass` 的字段,它定义了任务的优先级。
|
||||
|
|
@ -24,7 +24,7 @@ OpenPAI提供SSH插件来帮助您连接到任务容器。 要使用SSH,您可
|
|||
|
||||
<img src="./imgs/view-ssh-info.png" width="100%" height="100%" />
|
||||
|
||||
在SSH Info中,您应该参考`Use a pre-downloaded SSH private key`部分。如果您使用的是Windows,则以下命令适用于您:
|
||||
在SSH Info中,您应该参考`Use a pre-downloaded SSH private key`部分。如果您使用的是Windows,则可使用以下命令:
|
||||
|
||||
```bash
|
||||
ssh -p <ssh-port> -i <your-private-key-file-path> root@<container-ip>
|
||||
|
|
@ -38,9 +38,9 @@ chmod 400 <your-private-key-file-path> && ssh -p <ssh-port> -i <your-private-key
|
|||
|
||||
**选项2.使用您自己的密钥**
|
||||
|
||||
如果您熟悉SSH身份验证机制,那么您可能已经在文件夹`C:\Users\<your-user-name>\.ssh`中生成了一个公共密钥和一个私有密钥(在类Unix的系统上,对应的文件夹是`~/.ssh/`)。该文件夹中有一个id_rsa.pub文件和一个id_rsa文件,分别是公钥和私钥。
|
||||
如果您熟悉SSH身份验证机制,那么您可能已经在个人文件夹(Windows系统中为`C:\Users\<your-user-name>`,类Unix的系统中为`~`)下的`.ssh`子文件夹中生成了一个公共密钥和一个私有密钥。该文件夹中有一个id_rsa.pub文件和一个id_rsa文件,分别包含公钥和私钥。
|
||||
|
||||
要使用它们,请打开 `id_rsa.pub`并将其内容复制到SSH插件,然后提交任务。不要使用上述密钥生成器。
|
||||
要使用它们,请打开 `id_rsa.pub`并将其内容复制到SSH插件,然后提交任务。无需使用上述密钥生成器。
|
||||
|
||||
<img src="./imgs/copy-ssh-public-key.png" width="60%" height="60%" />
|
||||
|
||||
|
|
@ -65,11 +65,11 @@ sleep 30m
|
|||
|
||||
<img src="./imgs/enable-tensorboard.png" width="100%" height="100%" />
|
||||
|
||||
提交后,您将在任务页面上看到一个`Go To TensorBoard Page`按钮。
|
||||
提交后,您将在任务详情页面上看到一个`Go To TensorBoard Page`按钮。
|
||||
|
||||
<img src="./imgs/go-to-tensorboard-page.png" width="100%" height="100%" />
|
||||
|
||||
点击该按钮可转到TensorBoard页面。 您可能需要等待几分钟,直到日志准备就绪:
|
||||
点击该按钮可转到TensorBoard页面。 在日志准备就绪前,您可能需要等待几分钟。
|
||||
|
||||
<img src="./imgs/tensorboard-ok.png" width="100%" height="100%" />
|
||||
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@
|
|||
然后所有您有权限访问的空间将被显示为:
|
||||
|
||||

|
||||
如果您没有发现任何存储,请联系集群的管理员。
|
||||
如果显示列表为空,请联系集群的管理员。
|
||||
|
||||
## 上传数据
|
||||
|
||||
|
|
@ -26,13 +26,13 @@ sudo apt-get update
|
|||
sudo apt-get install --assume-yes nfs-common
|
||||
```
|
||||
|
||||
然后您可以将nfs mount到您的机器中:
|
||||
然后您可以将nfs挂载到您的机器中:
|
||||
```bash
|
||||
sudo mkdir -p MOUNT_PATH
|
||||
sudo mount -t nfs4 NFS_SERVER:/NFS_PATH MOUNT_PATH
|
||||
```
|
||||
|
||||
`NFS_SERVER`和`NFS_PATH`可以在个人信息页面的存储部分中找到。
|
||||
`NFS_SERVER`和`NFS_PATH`可以在个人信息页面的`Storage`部分中找到。
|
||||
|
||||
您可以将数据复制到`MOUNT_PATH`,这样数据就被上传到`NFS`服务器了。
|
||||
|
||||
|
|
@ -60,15 +60,15 @@ sudo mount -t nfs4 NFS_SERVER:/NFS_PATH MOUNT_PATH
|
|||
|
||||
要将数据上传到Azure Blob或Azure File,请执行以下操作:
|
||||
|
||||
1. 下载 [Azure Storage Explorer](https://azure.microsoft.com/en-us/features/storage-explorer/)
|
||||
1. 下载安装 [Azure Storage Explorer](https://azure.microsoft.com/en-us/features/storage-explorer/)。
|
||||
2. 如果您使用AAD登录到PAI,则管理员应该已经向您授予访问存储空间的权限。 您可以在个人信息页面上获取存储帐户名称,容器名称和文件共享名称。 请使用它们访问Azure存储资源管理器中的存储空间。 有关更多详细信息,请参阅[这里](https://docs.microsoft.com/en-us/azure/vs-azure-tools-storage-manage-with-storage-explorer?tabs=windows#add-a-resource-via-azure-ad)。
|
||||
3. 如果您使用基本身份验证(用户名/密码)登录到PAI门户。 请向管理员询问存储空间的`访问密钥`。 然后,您可以通过`访问密钥`和`存储帐户名`添加存储。 有关更多详细信息,请参阅[这里](https://docs.microsoft.com/en-us/azure/vs-azure-tools-storage-manage-with-storage-explorer?tabs=windows#use-a-name-and-key)。
|
||||
3. 如果您使用基本身份验证(用户名/密码)登录到PAI门户,请向管理员询问存储空间的`访问密钥`。 然后,您可以通过`访问密钥`和`存储帐户名`添加存储。 有关更多详细信息,请参阅[这里](https://docs.microsoft.com/en-us/azure/vs-azure-tools-storage-manage-with-storage-explorer?tabs=windows#use-a-name-and-key)。
|
||||
|
||||
## 在任务中使用数据
|
||||
|
||||
### 通过Data的UI界面
|
||||
|
||||
您可以使用任务提交页面上的`Data`部分来选择所需的存储:
|
||||
您可以在任务提交页面上的`Data`部分来选择所需的存储:
|
||||
|
||||

|
||||
|
||||
|
|
@ -76,7 +76,7 @@ sudo mount -t nfs4 NFS_SERVER:/NFS_PATH MOUNT_PATH
|
|||
|
||||
### 通过任务配置
|
||||
|
||||
您也可以在[任务配置文件](./how-to-use-advanced-job-settings.md#job-protocol-export-and-import-jobs)中的`extras.storages`部分中指定存储名称,以下为相应部分:
|
||||
您也可以在[任务配置文件](./how-to-use-advanced-job-settings.md#job-protocol-export-and-import-jobs)中的`extras.storages`部分中指定存储名称:
|
||||
|
||||
```yaml
|
||||
extras:
|
||||
|
|
@ -86,13 +86,11 @@ extras:
|
|||
- name: azure-file-storage
|
||||
```
|
||||
|
||||
每个存储都有两个字段,`name`和`mountPath`。 `name`是指存储名称,而`mountPath`是任务容器内的mount路径。 `mountPath`的默认值为`/mnt/${name}`。
|
||||
每个存储都有两个字段,`name`和`mountPath`。 `name`是指存储名称,而`mountPath`是任务容器内的mount路径。 `mountPath`不是必须项,其默认值为`/mnt/${name}`。
|
||||
|
||||
如果`storages`设置为空(如下),将使用当前用户的默认存储。
|
||||
如果`storages`设置为空列表(如下),将使用当前用户的默认存储。
|
||||
|
||||
```yaml
|
||||
extras:
|
||||
storages: []
|
||||
```
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@
|
|||
|
||||
在分布式任务中,一个 task 可能和其他 task 通信(这里 task 指一个 task role 里的单个instance)。因此,一个 task 需要知道其他 task 的运行时信息,例如IP、端口等。系统将这些运行时信息作为环境变量公开给每个 task 的 Docker 容器。用户可以在容器中编写代码访问运行时环境变量来相互通信。
|
||||
|
||||
下表展示了可以在Docker容器中访问的环境变量的完整列表:
|
||||
下面是可以在Docker容器中访问的环境变量的完整列表:
|
||||
|
||||
| 类别 | 环境变量名 | 描述 |
|
||||
| :---------------- | :---------------------------------------------------- | :--------------------------------------------------------------------------------- |
|
||||
|
|
@ -74,7 +74,7 @@ PAI_CONTAINER_HOST_<port-label>_PORT_LIST
|
|||
2. 永久错误:这种错误被认为是永久的,重试可能没有帮助。
|
||||
3. 未知错误:除了瞬时错误和永久错误之外的错误。
|
||||
|
||||
在任务中,瞬时错误将会被一直重试,永久错误永远不会重试。如果发生未知错误,PAI 将根据用户设置来重试任务。要为任务设置重试策略和完成策略,请切换至 `Advanced` 模式,如下图所示:
|
||||
在任务中,发生瞬时错误将一直重试,发生永久错误则永远不会重试。如果发生未知错误,PAI 将根据用户设置来重试任务。要为任务设置重试策略和完成策略,请切换至 `Advanced` 模式,如下图所示:
|
||||
|
||||
<img src="./imgs/advanced-and-retry.png" width="100%" height="100%" />
|
||||
|
||||
|
|
@ -188,7 +188,7 @@ extras:
|
|||
sshbarrier: true
|
||||
```
|
||||
|
||||
请确保已经在 worker 节点上安装了 InfiniBand 驱动程序,HCA名称和网络接口名称已正确设置。
|
||||
请确保已经在 worker 节点上安装了 InfiniBand 驱动程序,并且HCA名称和网络接口名称已正确设置。
|
||||
|
||||
## 参考
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
OpenPAI的 **任务** 定义了一个特定环境下执行的代码和命令。它可以在单个节点上运行,也可以分布式运行。
|
||||
|
||||
作为快速入门,请先下载[`hello-world-job.yaml`](./examples/hello-world-job.yaml)。
|
||||
·
|
||||
|
||||
然后登录到OpenPAI的网页端,点击`Submit Job` -> `Import Config`,选择刚刚下载好的`hello-world-job.yaml`文件,提交任务:
|
||||
<img src="./imgs/import-config-submit.gif" width="90%" height="90%" >
|
||||
|
||||
|
|
@ -13,7 +13,7 @@ OpenPAI的 **任务** 定义了一个特定环境下执行的代码和命令。
|
|||
|
||||
## 查看Stdout、Stderr、所有日志和运行指标
|
||||
|
||||
上述Hello World任务基于TensorFlow实现。这个任务在CIFAR-10数据集上训练了1000步,生成了一个简单的模型。您可以检查运行日志,或在网页端查看监控指标。
|
||||
上述Hello World任务基于TensorFlow实现。这个任务在CIFAR-10数据集上训练了1000步,生成了一个简单的模型。您可以通过检查运行日志或在网页端查看指标以监控该任务。
|
||||
|
||||
点击 `Stdout` 和 `Stderr` 按钮,可以在任务详细信息页面上看到这个任务的标准输出和标准错误日志。如果要查看合并的日志,可以点击右侧的 `...` ,选择 `Stdout + Stderr`。
|
||||
|
||||
|
|
@ -64,7 +64,7 @@ python train_image_classifier.py --dataset_name=cifar10 --dataset_dir=/tmp/data
|
|||
|
||||
以下是提交页面上配置信息的一些详细说明:
|
||||
|
||||
- **Job name** 是当前任务的名字。在每个用户账户中,它必须是唯一的。有意义的名字有助于良好地管理任务。
|
||||
- **Job name** 是当前任务的名字。在同一个用户帐户的所有任务中,它必须是唯一的。有意义的名字有助于良好地管理任务。
|
||||
|
||||
- **Command** 是在此任务角色中运行的命令,它可以是多行的。例如,在 Hello World 任务中,命令从Github克隆代码、下载数据,然后执行训练过程。如果一个命令失败了(退出时返回非零),接下来的命令将不继续执行。这个行为未来可能会改变。
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
|
||||
如果您的管理员启用了`Marketplace`插件,您将在Webportal的`Plugin`部分中找到一个链接,例如:
|
||||
|
||||
> 如果您是Pai管理员,则可以查看 [部署文件](https://github.com/microsoft/openpaimarketplace/blob/master/docs/deployment.md) 了解如何部署和启用`Marketplace`插件。
|
||||
> 如果您是PAI管理员,则可以查看 [部署文件](https://github.com/microsoft/openpaimarketplace/blob/master/docs/deployment.md) 了解如何部署和启用`Marketplace`插件。
|
||||
|
||||

|
||||
|
||||
|
|
@ -17,6 +17,8 @@
|
|||
|
||||
## 创建模板
|
||||
|
||||
要创建`Marketplace`模板,请单击页面上的`Create`按钮。如下图所示,您可以点击`Upload yaml file`上传配置文件并创建模板。在创建时,您应该填写一些必要的信息,例如`name`, `introduction` 和`description`等。另一种方法是从PAI平台中的现有任务中创建。您只能使用`Succeeded`的任务创建模板。创建后,您的模板将等待平台管理员进行审核,审核通过后,您才能在`Marketplace`列表中看到它们。
|
||||
要创建`Marketplace`模板,请单击页面上的`Create`按钮。如下图所示,您可以点击`Upload yaml file`上传配置文件并创建模板。在创建时,您应该填写一些必要的信息,例如`name`, `introduction` 和`description`等。
|
||||
|
||||
另一种方法是从PAI平台中的现有任务中创建。您只能使用`Succeeded`的任务创建模板。创建后,您的模板将等待平台管理员进行审核,审核通过后,您才能在`Marketplace`列表中看到它们。
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# 使用VSCode扩展
|
||||
|
||||
[OpenPAI VS Code Client](https://github.com/microsoft/openpaivscode) 是一个VSCode扩展,用于连接OpenPAI集群、提交任务、本地模拟任务、管理文件等。请使用[这个页面上](https://github.com/microsoft/openpaivscode/releases) 发布的vsix文件来安装它。
|
||||
[OpenPAI VS Code Client](https://github.com/microsoft/openpaivscode) 是一个VSCode扩展,用于连接OpenPAI集群、提交任务、本地模拟任务、管理文件等。请使用 [这个页面上](https://github.com/microsoft/openpaivscode/releases) 发布的vsix文件来安装它。
|
||||
|
||||
## 连接OpenPAI集群
|
||||
|
||||
|
|
@ -13,7 +13,7 @@
|
|||
|
||||

|
||||
|
||||
3. 按 <kbd>Enter</kbd>, 然后输入OpenPAI集群的主机地址。 它可以是域名或IP地址。 之后,再次按 <kbd>Enter</kbd>。
|
||||
3. 按 <kbd>Enter</kbd>, 然后输入OpenPAI集群的主机地址(可以是域名或IP地址)。 之后,再次按 <kbd>Enter</kbd>。
|
||||
|
||||

|
||||
|
||||
|
|
@ -30,11 +30,11 @@
|
|||
|
||||

|
||||
|
||||
3. 按 <kbd>Enter</kbd>,然后输入OpenPAI集群的主机。它可以是域名或IP地址。之后,再次按 <kbd>Enter</kbd> 。
|
||||
3. 按 <kbd>Enter</kbd>,然后输入OpenPAI集群的主机地址(可以是域名或IP地址)。之后,再次按 <kbd>Enter</kbd> 。
|
||||
|
||||

|
||||
|
||||
4. 程序会打开一个网站,并要求您登录。如果登录成功,程序会自动填充用户名和token字段。完成后,单击右下角的*Finish*按钮。请注意,如果直接保存并关闭文件,设置将不会生效。
|
||||
4. 程序会打开一个网站,并要求您登录。如果登录成功,程序会自动填充用户名和token字段(可以手动更改)。完成后,单击右下角的*Finish*按钮。请注意,如果直接保存并关闭文件,设置将不会生效。
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
Загрузка…
Ссылка в новой задаче