|
|
||
|---|---|---|
| assets | ||
| code | ||
| demo | ||
| deploy | ||
| notebook | ||
| pipeline | ||
| project | ||
| scraper | ||
| tests | ||
| .flake8 | ||
| .gitignore | ||
| CODE_OF_CONDUCT.md | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
| environment.yml | ||
README.md
![]()
NLP Toolkit
Supported Use cases
- Binary, multi-class & multi-label classification
- Named entity recognition
- Question answering
Live Demo
Deployment
-
Click on the button to start the resource deployment:

-
After the deployment has finished (~30min) as a workaround for now, add the function "default" host key as an environment variable named "FunctionHostKey" in the function (if the variable is already there, replace the value) and click "Save"
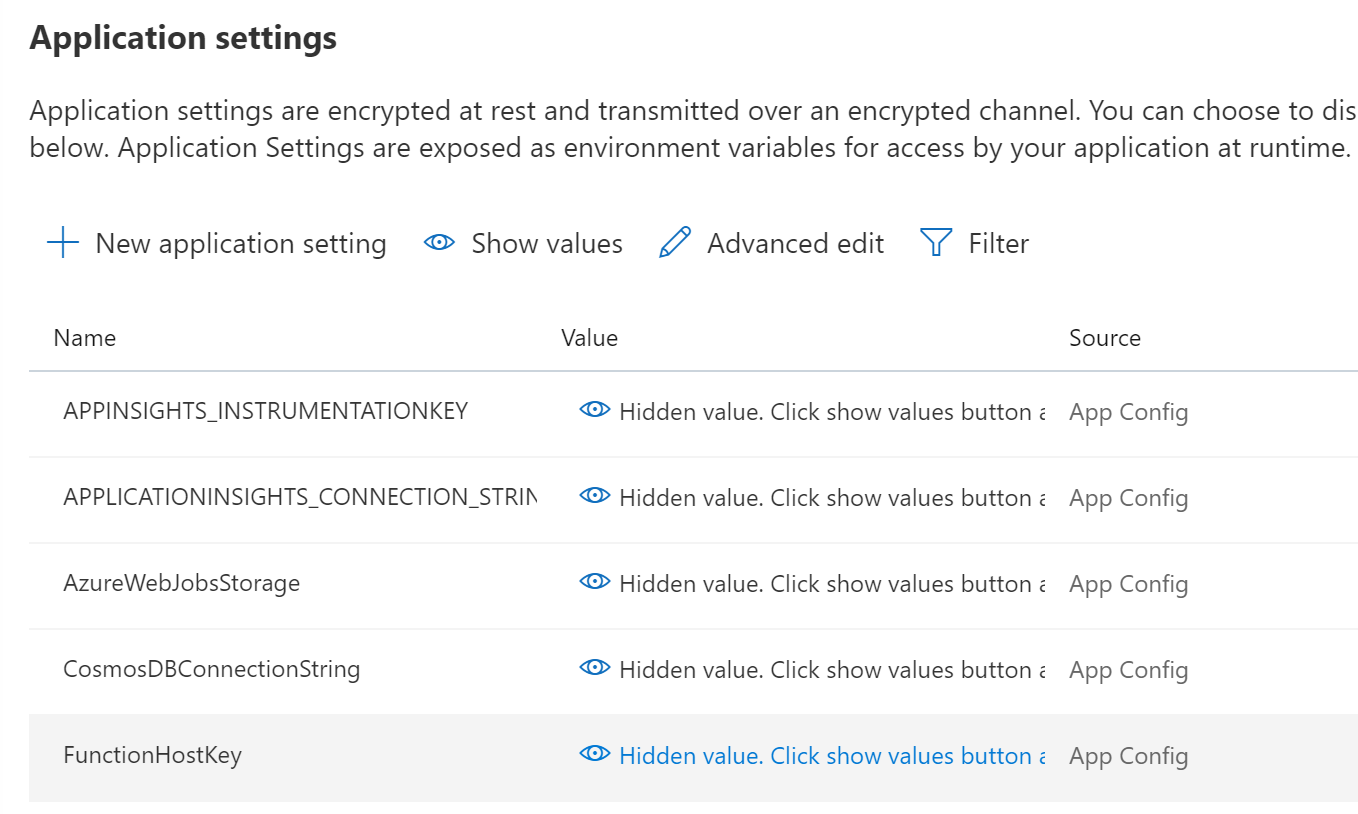
-
If you put files in the storage account "data" container, the files are processed and put in CosmosDB following the standardized output format.

Naming
Azure
nlp-<component>-<environment>
Assets
<project name>(-<task>)-<step>(-<environment>)
- where step in [source, train, deploy], for data assets.
- where task is an int, referring to the parameters, for models.
TODO
Project
- Overview architecture
- Detailed documentation
Prepare
- connect to CosmosDB (pipeline ready)
- (IP) document cracking to standardized format
Classification
- (IP) Multi label support
- integrate handling for larger documents
- dictionaries for business logic
- integrate handling for unbalanced datasets
- upload best model to AML Model
NER
- Improve duplicate handling
- basic custom NER
Rank
- (IP) Improve answer quality
Deployment
- Param script for deploy
- Deploy to Azure Function (without AzureML)
Notebooks
- review prepared data
- (IP) review model results (auto generate after each training step)
- review model bias (auto generate after each training step)
- available models benchmark (incl AutoML)
Tests
- (IP) integrate testing framework (pytest)
- automated benchmarks
New Features (TBD)
- Summarization
- Deployable feedback loop
- Integration with GitHub Actions
Acknowledgements
Verseagility is built in part using the following:
- Transformers by HuggingFace
- FARM by deepset ai
- spaCy by Explosion ai
- flair by Zalando Research
- gensim
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.