6.8 KiB
QnA Matching Data Science Scenario
Overview
Question answering systems of specific topics are highly demanded but are not quite available yet. The common use cases we see in this type of scenario include but are not limited to:
- Live chat support
- Chat bot
- Document match - find a subcategory of financial/legal/.. documents that answers a particular question
Therefore, we have provided a series of 7 Notebooks with step-by-step descriptions of how to create various training methods to match the correct answer to a given question.
Goal
- Provide our feedback to the product/engineering team about how a data scientist would solve the question answering problem.
- Reveal the journey and steps in details.
- Reveal the reasons and results of different training methods.
- Provide working code for testing new products.
Data
We use three sets of data in this series of notebooks. We collect the raw data from the Stack Overflow Database and extract all question-answer pairs related to the "JavaScript" tag. For the question-answer pairs, we consider the following scenarios.
- Original Questions (Q): These questions have been asked and answered on the Stack Overflow.
- Duplications (D): There is a linkage among the questions. Some questions that have already been asked by others are linked to the previous/original questions as Duplications. In the Stack Overflow Database, this kind of linkage is determined by "LINK_TYPE_DUPE = 3". Each original question could have 0 to many duplications, which are considered as semantically equivalent to the original question.
- Answers (A): For each Original question and its Duplications, we have found more than one answers have solved that question. In our analysis, we only select the Accepted answer or the answer with the highest score that solved the Original question. Therefore, it's 1-to-1 mapping between Original questions and Answers and many-to-1 mapping between Duplications and Original questions. Each Original question and its Duplications have an unique AnswerId.
- Function Words: we consider a list of words that can only be used in between content words in the creation of phrases. This list of words, stored as a .txt file, is also used as Stop Words.
See the below Data Diagram to illustrate the relationship among Original Questions (Q), Duplications (D) and Answers (A):
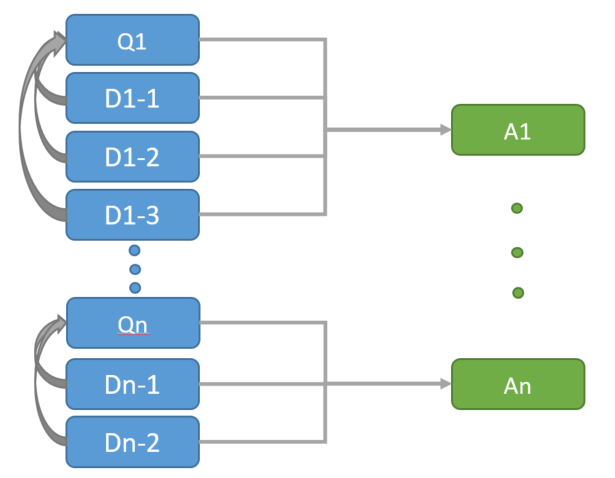
The data schema and download links are available as below:
| Dataset | Column Name | Description |
|---|---|---|
| questions | Id | the unique question ID (primary key) |
| AnswerId | the unique answer ID per question | |
| Text0 | the raw text data including the question's title and body | |
| CreationDate | the timestamp of when the question has been asked | |
| dupes | Id | the unique duplication ID (primary key) |
| AnswerId | the answer ID associated with the duplication | |
| Text0 | the raw text data including the duplication's title and body | |
| CreationDate | the timestamp of when the duplication has been asked | |
| answers | Id | the unique answer ID (primary key) |
| text0 | the raw text data of the answer |
To retrieve the data in Python, please find the code in the section Access sample data of the Part 1 notebook.
Description
The series include 7 notebooks, which provide working code for each step of our Data Science process.
Part 1 of the series shows how to pre-process the text data, learn the most salient phrases present in a large collection of documents and save cleaned text data in the Azure Blob Storage. These phrases can be treated as single compound word units in down-stream processes such as discriminative training. To learn the phrases, we have implemented the basic framework that combines key phrase learning and latent topic modeling as described in the paper entitled "Modeling Multiword Phrases with Constrained Phrases Tree for Improved Topic Modeling of Conversational Speech" which was originally presented in the 2012 IEEE Workshop on Spoken Language Technology. Although the paper examines the use of the technology for analyzing human-to-human conversations, the techniques are quite general and can be applied to a wide range of natural language data including news stories, legal documents, research publications, social media forum discussions, customer feedback forms, product reviews, and many more.
Also, we have implemented several training methods in the notebooks titled Part 2 to Part 7.
- Part 2: Match Questions to Answers based on the Cosine Similarity of their Term Frequency-Inverse Document Frequency (TF-IDF) matrix.
- Part 3: Match Questions to previously seen Questions, which link to their corresponding Answers, based on the Cosine Similarity of the Questions' Term Frequency-Inverse Document Frequency (TF-IDF) matrix.
- Part 4: Match Questions to previously seen Questions based on learned scores from a Naive Bayes Classifier as described in the paper entitled "MCE Training Techniques for Topic Identification of Spoken Audio Documents".
- Part 5: Match Questions to previously seen Questions based on calibrated probabilities from a One-vs-rest Support Vector Machine (SVM) Classifier. The classifier has been built using the scores learned from the Naive Bayes Classifier in Part 4 as the feature vectors. Two feature vectors sets have been used to build the SVM classifier: the scores learned on unigrams and the concatenation of scores learned on unigrams and scores learned on bigrams.
- Part 6: Similar to the Part 5, we have built a One-vs-rest SVM Classifier using the feature embeddings extracted from a Deep Structured Semantic Model (DSSM) Transformer. The transform uses pre-trained DSSM models to feature the text into either a semantic embedding vector, or, given two strings, output a similarity score between them.
- Part 7: Match Questions to previously seen Questions based on a weighted average of 5 base classifiers learned in the previous Parts.
Note: This notebook series are built under Python 3.5 and NLTK 3.2.2.
Contact
Please feel free to contact Katherine Zhao (mez@microsoft.com) and T.J. Hazen (TJ.Hazen@microsoft.com) with any question or comment.