18 KiB
How to Avoid the ReceiverDisconnectedException
In version 2.3.2 and above, the connector by default uses epoch receivers from the Event Hubs Java client.
The epoch receiver allows only one receiver to be open per consumer group-partition combo for an Event Hubs instance.
Let's say we have receiverA with an epoch of 0 which is open within the consumer group foo on partition 0.
Now, if we open a new receiver, receiverB, for the same consumer group and partition with an epoch of
0 (or higher), then receiverA will be disconnected and get the ReceiverDisconnectedException.
There are several scenarios in which the connector tries to open more than one epoch receiver for a particular <Event Hubs instance, consumer group, partition> combination. In this document, we elaborate on some of those scenarios and discuss how you can avoid them.
One scenario which causes this exception is when your code generates multiple concurrent tasks that read events from a particular partition in an Event Hubs instance using the same consumer group. This situation happens if you define multiple streams reading from an Event Hubs instance using the same consumer group. Since each stream generates a set of tasks to read events from each partition, if you use the same consumer group in more than one stream it results in having multiple tasks that use the same <Event Hubs instance, consumer group, partition> combination. You can avoid this situation by using a unique consumer group for each stream you create on an Event Hubs instance.
Your code may also generate multiple concurrent tasks using the same <Event Hubs instance, consumer group, partition> combination for a single stream. This situation happens if the code execution results in re-computing the input stream from the Event Hubs instance. The Stream Recomputation section below explains what may cause stream re-computation in more detail and proposes ways to avoid such cases.
Another situation that could result in seeing the ReceiverDisconnectedException is when batches dispatch
receiving tasks for the same <Event Hubs instance, consumer group, partition> combination to different executor nodes
in a cluster. The Receivers Move Between Executor Nodes section below
describes this situation and suggests how you can reduce the chance of being in such a situation.
Table of Contents
- Stream Recomputation
- Quick Check for Multiple Readers
- Examples of Having Multiple Readers Unintentionally
- Persist Data to Prevent Recomputation
- Receivers Move Between Executor Nodes
- Example of Receiver Recreation
- Reducing Receiver Movements
Stream Recomputation
Sometimes a Spark application recomputes a single input stream multiple times. If the stream source is an Event Hubs
instance, this recomputation can eventually cause opening multiple receivers per consumer group-partition combo and
result in getting the ReceiverDisconnectedException. Therefore, it is important to make sure that the application
that reads events from an Event Hubs instance does not recompute the input stream multiple times.
RDD Actions
In Spark, RDD operations are either Transformations or Actions. In abstract, transformations create a new dataset
and actions return a value. Spark has a lazy execution model for transformations, which means those operations are
being executed only when there is an action on the result dataset. Therefore, a transformed RDD may be recomputed
each time an action is being ran on it. However, you can avoid this recomputation by persisting an RDD in memory using
the persist or cache method. Please refer
to RDD Operations for more details.
Note that persisting an RDD in memory only helps if all actions are being executed on the same executor node.
Write to Multiple Data Sinks
You can write the output of a streaming query to multiple sinks by simply using the DataFrame/Dataset multiple times.
However, each write may cause the recomputation of the DataFrame/Dataset. In order to avoid this recomputation, similar
to the RDD case you can persist or cache the DataFrame/Dataset before writing it to multiple locations. Please refer to
Using Foreach and ForeachBatch
for more information.
Spark Speculation
One of Spark scheduling configuration options is spark.speculation.
Briefly, if speculation is enabled, Spark relaunches tasks that are running slower than other tasks in a stage. Therefore,
if you are defining a streaming query with an Event Hubs source while enabling the spark.speculation config, you may
end up in a situation where multiple tasks try to read events from the same <Event Hubs instance, consumer group, partition>
combination concurrently.
Quick Check for Multiple Readers
A quick way to check if your application uses multiple readers is to compare the rate of Incoming and Outgoing
messages to/from the underlying Event Hubs instance. You have access to both Messages and Throughput metrics in
the Overview page of the Event Hubs instance on Azure Portal.
Assume you have only Spark application (with a single stream reader) that reads events from an Event Hubs instance.
In this case, you should see the number(or total bytes) of Outgoing messages matching the number (or total bytes) of
Incoming messages. If you find out the rate of Outgoing messages is N times the rate of Incoming messages,
it indicates that your application is recomputing the input stream N times. This is a strong signal to
update the application code to eliminate input stream recomputations (usually by using persist or cache method).
Examples of Having Multiple Readers Unintentionally
Multiple Actions
The code below is an example where a single read stream is being used by multiple RDD actions without caching:
import org.apache.spark.eventhubs._
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.streaming.Trigger
// EventHubs connection string
val endpoint = "Endpoint=sb://SAMPLE;SharedAccessKeyName=KEY_NAME;SharedAccessKey=KEY;"
val eventHub = "EVENTHUBS_NAME"
val consumerGroup = "CONSUMER_GROUP"
val connectionString = ConnectionStringBuilder(endpoint)
.setEventHubName(eventHub)
.build
// Eventhubs configuration
val ehConf = EventHubsConf(connectionString)
.setStartingPosition(EventPosition.fromEndOfStream)
.setConsumerGroup(consumerGroup)
.setMaxEventsPerTrigger(500)
// read stream
val ehStream = spark.readStream
.format("eventhubs")
.options(ehConf.toMap)
.load
ehStream.writeStream
.trigger(Trigger.ProcessingTime("5 seconds"))
.foreachBatch { (ehStreamDF,_) =>
handleEhDataFrame(ehStreamDF)
}
.start
.awaitTermination
def handleEhDataFrame(ehStreamDF : DataFrame) : Unit = {
val totalSize = ehStreamDF.map(s => s.length).reduce((a, b) => a + b)
val eventCount = ehStreamDF.count
println("Batch contained " + eventCount + " events with total size of " + totalSize)
}
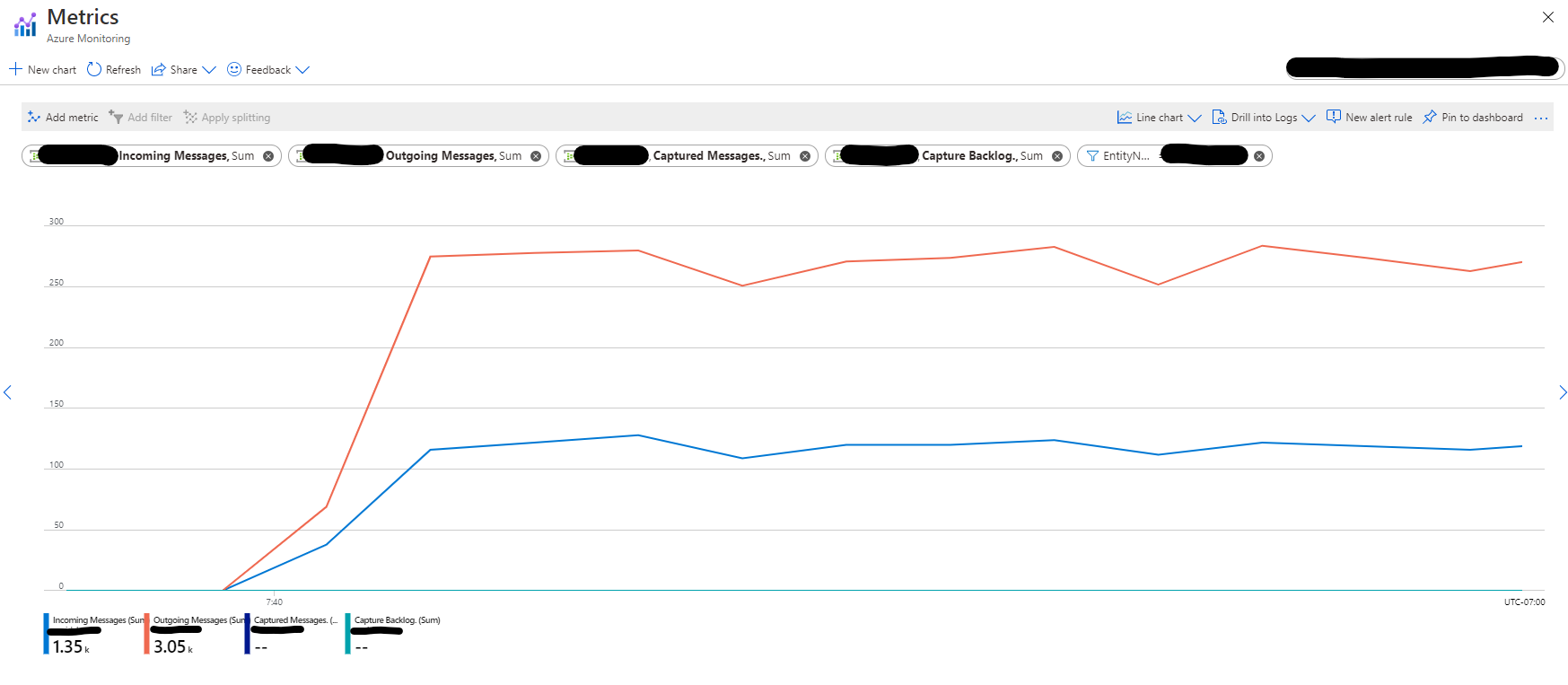
As you can see in the graph below which shows the rate of Incoming vs Outgoing messages in the
Event Hubs entity, the number of Outgoing messages is almost twice the number of Incoming messages.
This pattern indicates that the above code reads events from the Event Hubs entity twice: Once when
it computes the reduce action, and once when it computes the count action.
Multiple Sinks
The code below shows how writing the output of a streaming query to multiple sinks creates multiple readers:
import org.apache.spark.eventhubs._
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.streaming.Trigger
// EventHub connection string
val endpoint = "Endpoint=sb://SAMPLE;SharedAccessKeyName=KEY_NAME;SharedAccessKey=KEY;"
val src_eventHub = "SRC_EVENTHUBS_NAME"
val dst_eventHub = "DST_EVENTHUBS_NAME"
val consumerGroup = "CONSUMER_GROUP"
val src_connectionString = ConnectionStringBuilder(endpoint)
.setEventHubName(src_eventHub)
.build
val dst_connectionString = ConnectionStringBuilder(endpoint)
.setEventHubName(dst_eventHub)
.build
// Eventhub configuration
val src_ehConf = EventHubsConf(src_connectionString)
.setStartingPosition(EventPosition.fromEndOfStream)
.setConsumerGroup(consumerGroup)
.setMaxEventsPerTrigger(500)
val dst_ehConf = EventHubsConf(dst_connectionString)
// read stream
val ehStream = spark.readStream
.format("eventhubs")
.options(src_ehConf.toMap)
.load
.select($"body" cast "string")
// eventhub write stream
val wst1 = ehStream.writeStream
.format("org.apache.spark.sql.eventhubs.EventHubsSourceProvider")
.options(dst_ehConf.toMap)
.option("checkpointLocation", "/checkpointDir")
.trigger(Trigger.ProcessingTime("10 seconds"))
.start()
// console write stream
val wst2 = ehStream.writeStream
.outputMode("append")
.format("console")
.option("truncate", false)
.option("numRows",10)
.trigger(Trigger.ProcessingTime("10 seconds"))
.start()
wst1.awaitTermination()
wst2.awaitTermination()
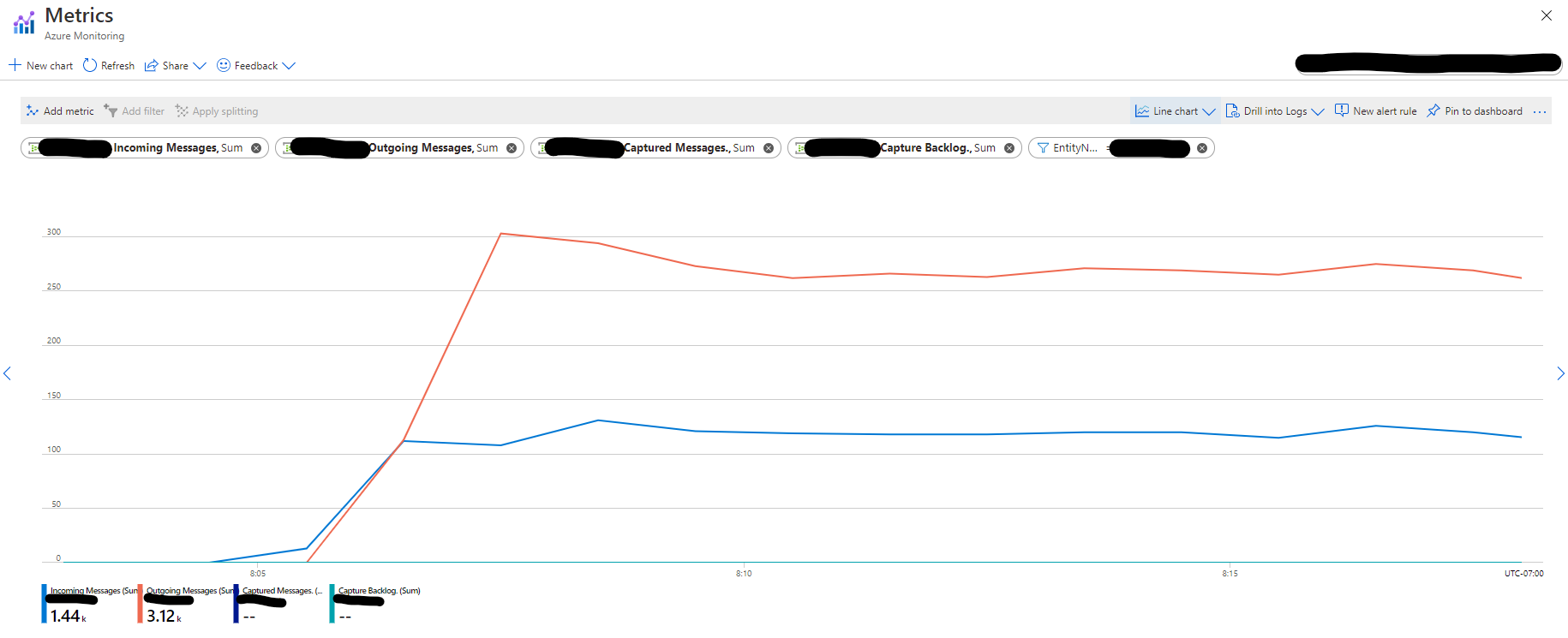
You can see in the graph below from the source Event Hubs entity that the number of Outgoing messages is almost twice the number of Incoming messages which indicates the existence of two separate readers in our application.
Persist Data to Prevent Recomputation
As we have mentioned before, one way to avoid recomputations is to persist (or cache) the generated DataFrame/Dataset from the input stream before performing your desired tasks and unpersist it afterward. Please remember this avoids recomputation only if all actions are being scheduled on the same executor node. The code below shows how you can run multiple actions on a DataFrame without recomputing the input stream:
import org.apache.spark.eventhubs._
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.streaming.Trigger
// EventHubs connection string
val endpoint = "Endpoint=sb://SAMPLE;SharedAccessKeyName=KEY_NAME;SharedAccessKey=KEY;"
val eventHub = "EVENTHUBS_NAME"
val consumerGroup = "CONSUMER_GROUP"
val connectionString = ConnectionStringBuilder(endpoint)
.setEventHubName(eventHub)
.build
// Eventhubs configuration
val ehConf = EventHubsConf(connectionString)
.setStartingPosition(EventPosition.fromEndOfStream)
.setConsumerGroup(consumerGroup)
.setMaxEventsPerTrigger(500)
// read stream
val ehStream = spark.readStream
.format("eventhubs")
.options(ehConf.toMap)
.load
ehStream.writeStream
.trigger(Trigger.ProcessingTime("5 seconds"))
.foreachBatch { (ehStreamDF,_) =>
handleEhDataFrame(ehStreamDF)
}
.start
.awaitTermination
def handleEhDataFrame(ehStreamDF : DataFrame) : Unit = {
ehStreamDF.persist
val totalSize = ehStreamDF.map(s => s.length).reduce((a, b) => a + b)
val eventCount = ehStreamDF.count
println("Batch contained " + eventCount + " events with total size of " + totalSize)
ehStreamDF.persist
}
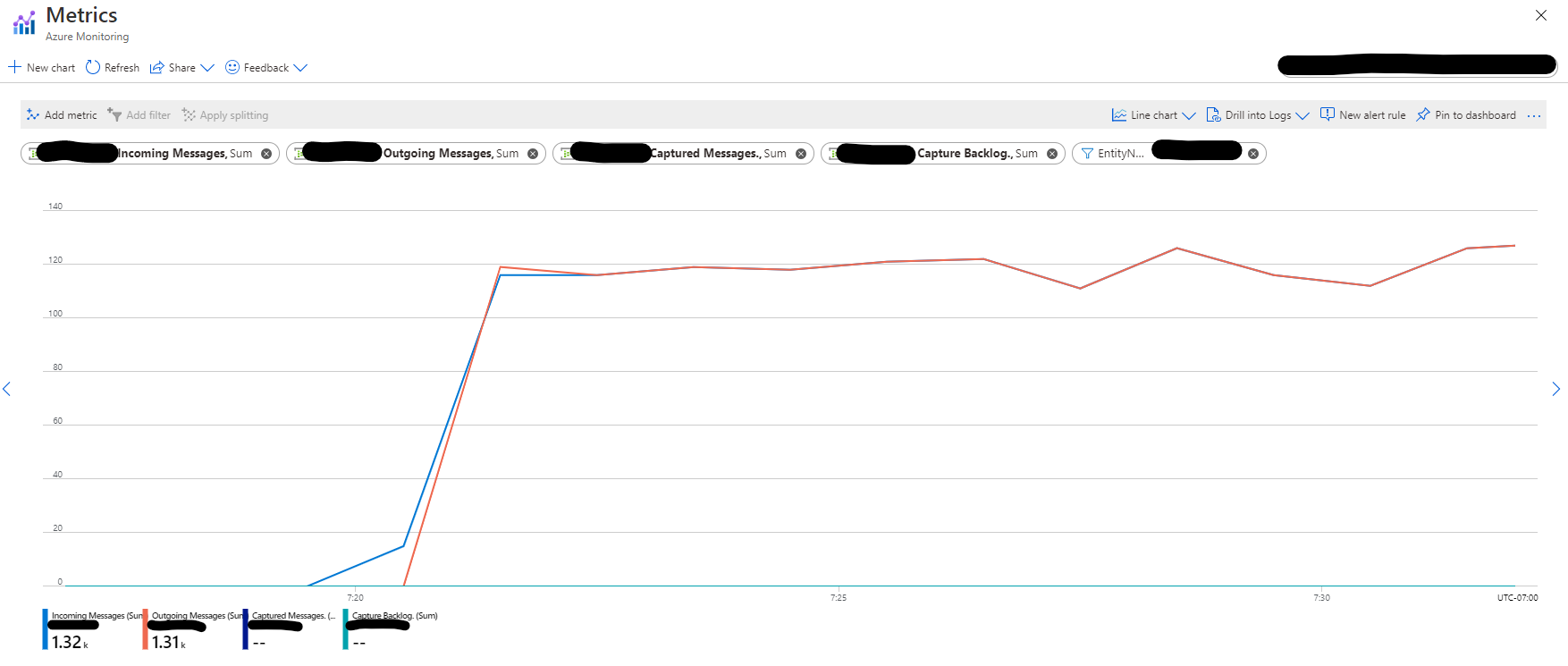
The graph below from the Event Hubs entity shows the number of Incoming and Outgoing messages are almost the same, which means the application reads events only once despite executing two actions on the generated DataFrame.
Receivers Move Between Executor Nodes
The Spark Event Hubs connector executes an input stream by dividing it into batches. Each batch generates a set of tasks where each task receives events from one partition. These tasks are being scheduled on the available executor nodes in the cluster.
The Spark Event Hubs connector creates and caches a receiver for each <Event Hubs instance, consumer group, partition> combination on the executor node that runs the task to read events from that specific combination. These receivers are epoch receivers by default. Whenever a task that is supposed to read events from a <Event Hubs instance, consumer group, partition> is being scheduled on an executor node, it first retrieves the corresponding receiver for the combination from the cache. Then, it checks if the receiver's cursor is at the right location (i.e. the latest event offset read by this receiver is exactly before the next offset requested to be read). If the receiver's cursor falls behind, it means that another node has created and used a receiver for the same <Event Hubs instance, consumer group, partition>, therefore the cached receiver on this node is disconnected (since it's an epoch receiver) and a new receiver must be recreated. This results in recreating the receiver and updating the cache on this node, which consequently disconnects the currently open receiver on the other node.
Example of Receiver Recreation
Let's consider the following example to elaborate on this scenario. Assume we have a stream that tries to read from an
Event Hubs instance with only 2 partitions (partitions 0 and 1) using the consumer group CG. This stream creates a
sequence of batches to read events from the Event Hubs instance and each batch creates 2 tasks, one per partition. For
simplicity, we name the task that is responsible to read events from partition k in batch i, task i.k, and assume
each task reads 10 events from its corresponding partition. We run this stream on a cluster with two executor nodes,
executor A and executor B. This cluster, for some unknown reason, schedules the tasks to read from partition 0 on
executor A for batches with odd number ids (1, 3, 5, ...) and schedules the tasks to read from partition 0 on
executor B for batches with even number ids (2, 4, 6, ...).
Now, we focus on tasks that read events from partition 0 (tasks i.0):
-
Batch 1 sends
task 1.0toexecutor Ato read events from offset 0 to 9. Theexecutor Acreates a receiver for the (CG, 0) combo and caches it locally. The receiver cursor is at offset 9. -
Batch 2 sends
task 2.0toexecutor Bto read events from offset 10 to 19. Theexecutor Bcreates a receiver for the (CG, 0) combo and caches it locally. The receiver cursor is at offset 19. Note that this new receiver creation results in disconnecting the existing receiver fromexecutor A. -
Batch 3 sends
task 3.0toexecutor Ato read events from offset 20 to 29. Theexecutor Aretrieves the receiver for the (CG, 0) combo from its cache. However, when it checks the receiver's cursor, it finds out the cursor (at offset 9) falls behind the offset for the current request (offset 20), which means the cached receiver has been disconnected by another receiver. Therefore, it recreates the receiver and updates its cache. Again, the receiver recreation onexecutor Adisconnects the other open receiver to the (CG, 0) combo fromexecutor B. -
Batch 4 sends
task 4.0toexecutor Bto read events from offset 30 to 39. Theexecutor Bretrieves the receiver for the (CG, 0) combo from its cache. However, when it checks the receiver's cursor, it finds out the cursor (at offset 19) falls behind the offset for the current request (offset 30), which means the cached receiver has been disconnected by another receiver. Therefore, it recreates the receiver and updates its cache. -
The same behavior goes on and on, ...
Reducing Receiver Movements
This situation would be avoided if all tasks that read events from the same <Event Hubs instance, consumer group, partition>
combination are being scheduled on the same executor node. In such a case, the executor node reuses the cached receiver,
and the connector doesn't have to recreate the receiver. Sparks scheduler decides where to schedule a task based on its
locality level. Generally speaking, Spark tries to schedule tasks locally as much as possible, but if the wait is getting
too long it schedules the tasks on nodes with less locality level. You can set "how long to wait to launch a data-local
task before giving up and launching it on a less-local node" by using the spark.locality.wait configuration option.
In this case, increasing the spark locality can help to reduce/avoid recreating receivers. The spark locality can be
increased by assigning a higher value to the spark.locality.wait property (for instance, increase the value to 15s
instead of the default value 3s). Please refer to
Spark Scheduling Configuration for more information.
Please note that increasing the locality level doesn't guarantee that all tasks being executed at the PROCESS_LOCAL level. This happens because based on the cluster workload some executor nodes might be busy and the scheduler couldn't send a task to those nodes even after an extended period of waiting. Therefore, another way to reduce the chance of receiver movement between different executor nodes is to increase the number of executor nodes on the cluster.
Finally, another option is to use non-epoch receivers instead of epoch receivers by setting the UseExclusiveReceiver
to false (you can do so by using the setUseExclusiveReceiver(b: Boolean) API in EventHubsConf). If you decide to
use the non-epoch receiver please be aware of its limitation of allowing up to 5 concurrent receivers (please refer to
Event Hubs quotas and limitations for more information).