|
|
||
|---|---|---|
| assets | ||
| data | ||
| docs | ||
| src | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
README.md
Technical Guide to Create a Customer 360 Profile using Machine Learning
About this repository
- Maintainer: Emmanuel Awa (emmanuel.awa@microsoft.com)
- Project: Customer 360 Profile (Solution How-to Guide)
- Use case: Enabling Machine Learning to enrich customer profiles.. In this solution, we provide a model that uses enriched customer profiles to predict which product category a given customer is likely to purchase from. The model is trained using scaled out Gradient Boosted Machine (GBM) algorithm and runs on a Microsoft R Server. The model is trained using historic purchases, demographics, and customers’ browsing behavior data.
Table of Contents
- Scope
- Pre-requisites
- Customer 360 Profile
- Solution Building Blocks
- Solution Setup
- Usage
- Scaling
- Visualizations using Power BI Dashboard
- Exit and Clean up
- Copyright
- License
Scope
The Customer 360 Profile solution provides you a scalable way to build a customer profile enriched by machine learning. It also allows you to uniformly access and operate on data across disparate data sources (while minimizing raw data movement) and leverage the power of Microsoft R Server for scalable modelling and accurate predictions.
This technical guide walks you through the steps to implement a customer 360 profile solution using Cortana Intelligence Suite on Microsoft Azure. The solution involves:
-
Ingestion and Pre-processing: Ingest, prepare, and aggregate live user activity data.
-
Integration of Data Sources: Integrate and federate customer profile data that’s embedded across disparate data sources.
-
Feature engineering and ETL: Segment customers into RFM segments based on their browsing and purchase behavior.
-
Machine Learning (ML)): Build an ML model to predict how likely a customer will purchase in the next few days and from which product category. The ML model enriches existing customer profiles based on their most recent activities.
Pre-requisites
To deploy this solution you will need an active Azure subscription. In this solution, we will implement a number of Azure services described in the Solution Setup section of this document.
Tools and Azure Services
This solution includes a detailed guidance on architectural best practices and recommended big data tools and services. These tools and services are used to build a customer profile enrichment solution on Azure. This solution uses managed services on Azure namely, Microsoft R Server, Azure Data Warehouse, Azure HDInsight Cluster, Azure Storage Blob, Azure EventHub, Azure Stream Analytics, Azure Data Factory, Azure Functions, and PowerBI. It also uses industry standard open source tools commonly used by data scientists and engineers: Python, SparkSQL/PySpark, and Scalable R.
These tools and services make this solution easily adoptable by the IT department of any business.
Customer 360 Profile
1. Definition and Benefits
To improve market positioning and profitability, it is important to deeply understand the connection between customer interests and buying patterns. That’s where Customer 360 Profile comes in.
Customer 360 Profile is an advanced solution to enrich customer profiles using machine learning. A 360-degree enriched customer profile is key to derive actionable insights and smarter data-driven decisions.
Customer profile enrichment can be applied across multiple business use cases:
-
Design targeted sales events.
-
Personalize promotions and offers
-
Proactively reduce customer churn
-
Predict customer buying behavior
-
Forecast demands for better pricing and inventory
-
Gain actionable insights for better sales and opportunity leads
Some of the benefits of customer profile enrichment includes:
- A 360-degree representation of the customer.
- Holistic view of your ideal customers’ purchasing behaviors and patterns.
- Allows you to locate, understand and better connect to your ideal customers.
What is under the hood
Today businesses amass customer data through various channels, such as web browse patterns, purchase behaviors, demographic information, and other session-based web footprints. While some of the data is first party to the organization, others are derived from external sources, such as, public domain, partners, manufactures and so on.
In many cases, only basic customer information can be derived from first party data, while other valuable data remains embedded in different locations and schemas.
Traditionally most businesses leverage only a small set of this data. However, to boost ROI with enriched customer profile, you need to integrate relevant data from all sources, perform distributed ETL (Extract, Transform, Load) across data processing engines, and use predictive analytics and machine learning to enrich customer information.
An effective profile enrichment ML model must have access to large datasets even though those datasets are geographically dispersed and schematically heterogenous. Often, these data systems are resource constrained as these are used by multiple main-stream applications and processes simultaneously.
That's why to prepare the data for ML, the feature engineering and ETL processes need to be off-loaded to more powerful computational systems, without having to move raw data physically.
Physically moving raw data to compute not only adds to the cost of the solution but also adds network latency and reduces throughput.
In this technical guide, we will walk you through the steps to create a customer 360 profile by uniformly accessing data from a variety of data sources (both on-prem and in-cloud) while minimizing data movement and system complexity to boost performance.
2. Architecture
An effective profile enrichment ML model creates a holistic customer profile utilizing large datasets from disparate sources. These sources individually hold partial information directly or indirectly about the customer. The data, usually accumulated over time, needs to be prepared for the ML. Most of the data needed for enrichment reside on various heterogeneous, shared, and resource constrained systems which are used by multiple main-stream applications and processes.
Thus, the feature engineering and ETL processes need to be off-loaded to more powerful computation systems without having to physically move the data. Physically moving the data to compute not only adds to the cost of the solution but also adds to network latency and reduces throughput.
Cross system query execution described in this guide provide ways to minimize data movement, incorporate data from heterogenous data sources (both on-prem and in-cloud), reduce system complexities and improve performance.
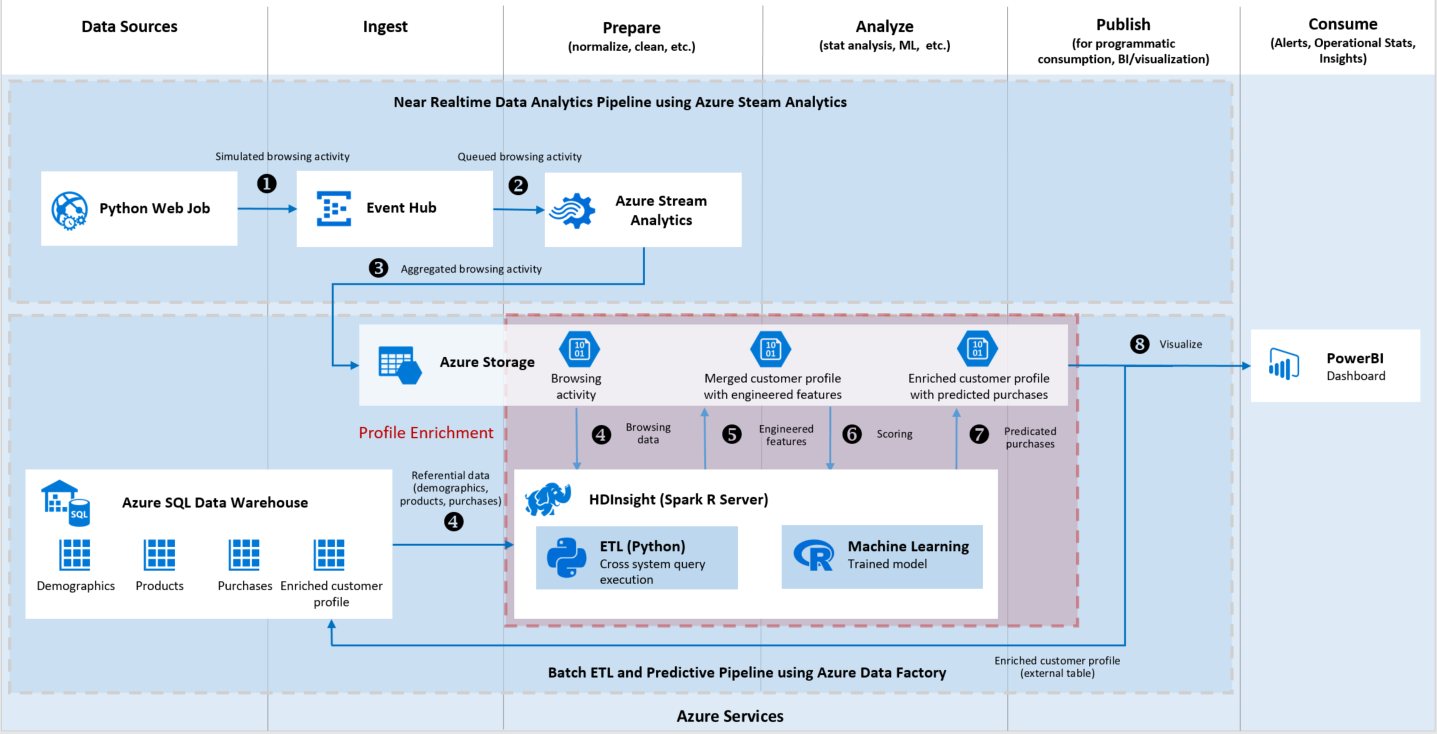
Figure 1: End to End Architecture to create a Customer 360 Profile.
In figure 1, the end to end pipeline is based on a hypothetical scenario that represents a retail company.
Customers are assumed to browse through three online product categories, namely, Technology, Apparel and Cosmetics.
These categories and timestamp of simulated user actions are generated and streamed to the EventHub.
Aggregation of total time spent on each category is done by Azure Stream Analytics and the aggregated data is then stored in Azure Storage blobs.
Using SparkSQL on Azure HDInsight the solution can perform feature engineering related steps like data wrangling, cross system query execution to bring in the referential data, and perform ETL to build a consolidated dataset. This consolidated dataset is then stored in the underlying Azure Storage (via a WASB connection) of the cluster, in preparation for ML.
A pre-trained ML model is invoked into a Microsoft R Server instance which is also on the same HDInsight cluster, to classify what category of product a user is likely to purchase from. Since Microsoft R Server runs on the HDI cluster, the movement of raw data is minimized.
NOTE: To learn how to retrain the model used please follow this short tutorial.
Solution Building Blocks
1. Cross System Query Execution
The feature engineering and ETL process relies heavily on accessing referential datasets (stored in Azure Data Warehouse) directly from Azure HDInsight (Hadoop based system).
Again, structured datasets (e.g. customer demographics and historic purchases) in Azure SQL Data Warehouse need to be joined with NoSQL streaming data on Azure storage blob.
Cross System Query Execution, uses JDBC, which allows the push of query to the SQL DW to access the views of the necessary referential data for ETL.
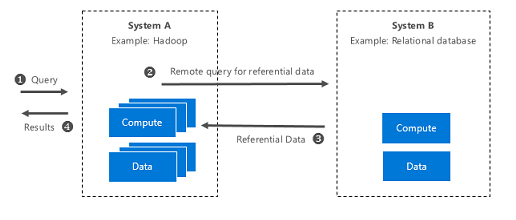
Figure 2: System-level overview of Cross System Query Execution.
Refer to this tutorial for details on Cross System Query Execution.
2. Machine Learning
The multi-class classifier Machine Learning model is built using an HDInsight cluster with Microsoft R Server (MRS) at scale. The power of R is leveraged using the MRS rxBTrees algorithm. rxBTrees scales the Gradient Boosting Machine (gbm()) that solves classification and regression problems. Its implementation is built upon rxDTree. It combines weak learners in an additive and iterative manner to produce accurate classifiers that are resistant to overfitting.
Learn more about rxBTress and Microsoft R Server.
3. Data Pipeline Triggering and Job Orchestration
The data pipeline for this solution is triggered by an Azure (Python) WebJob that generates the simulated user activity data stream.
The downstream orchestration, starting from the data preparation of data for ML and ending in the consumption of the final data, is done using Azure Data Factory. Synchronization between the webjob and the ADF pipelines is critical. Azure Data Factory is used to synchronize and orchestrate data movement, ETL and Customer Profile Enrichment activities.
Activities in ADF (Azure Data Factory) parlance are triggered at predefined intervals of time called time slices. In this solution, each time slice is fifteen (15) minutes wide. At every time slice, two pipelines activities are triggered. One for orchestrating the feature engineering and ETL process and a second for orchestrating the ML prediction process; these are fired sequentially.
4. ML Model Training
A predictive multi-class classifier is trained using rxBTrees. It enriches the existing profile for targeted insights and engagements, like personalized offers or targeted campaigns, via labels.
Each customer gets a label assigned based on a predicted (ML) category a customer is likely to purchase from. For example, ** a customer with predicted labels 1, 2, 3 are likely to buy from categories 1, 2 or 3 respectively and 0 is unlikely to buy anything**.
A short tutorial on how the model is trained can be found here
Solution Setup
If you have deployed the solution from the Cortana Intelligence gallery, you should have created the following resources in your Azure subscription.
-
Microsoft R Server - Highly scalable platform that extends the analytic capabilities of R.
-
Azure Data Warehouse - Store large and fast growing referential datasets.
-
Azure HDInsight Cluster - Perform distributed computations at massive scale.
-
Azure Storage Blob - Use HDFS compatible storage for HDInsight cluster.
-
Azure EventHub - Time-based event buffer for near real-time events.
-
Azure Stream Analytics - On demand real-time Advanced Analytics service.
-
Azure Data Factory - Data pipeline orchestrator, connects to both on-prem and in-cloud sources and allows data lineage visualizations.
-
Azure Functions/WebApp - Process events with serverless code.
-
PowerBI - Fully interactive data visualizations.
Otherwise follow this detailed tutorial that walks you through deploying all these resources using PowerShell and Azure Resource Manager (ARM) templates
Entire automated setup should have taken about 30 minutes.
Usage
1. Data Generation
Referential Data
The following referential tables are pre-generated and loaded into Azure SQL Data Warehouse.
The columns/featured used in this solution are outlined below each listed table.
-
6000 Customers
- Age
- Gender
- Income
- HeadofHousehold
- Number living in household
- Number of months living in current residence
-
8000 Purchase entries (multiple purchases per customer from each buying group)
- Date of Purchase
- Customer ID
- Product ID
- Amount Spent
-
3 Product categories - Technology, Cosmetics, Apparel
- Product ID
- Product Description
Browsing Data - NoSQL
Data generation is done in two stages:
- Generating data distribution for user behavior based on the logic described below.
- Streaming of the data downstream to EventHub.
In this tutorial, our focus will primary be three general product categories
| CATEGORY ID | CATEGORY DESCRIPTION |
|---|---|
| Technology | T1 |
| Cosmetics | T2 |
| Apparel | T3 |
The Python Data Generator synthesizes data based on the following hypothesis from two focus groups:
-
Group 1 - Customers between ages 25-60 and with Income greater than $50,000 spend more time browsing Technology (T1) and end up buying in T1.
-
Group 2 - Customers between 25-55 and with Income greater than $50,000 spend more time browsing cosmetics (T2) and apparel (T3) and end up buying from either both categories (T2 and T3)
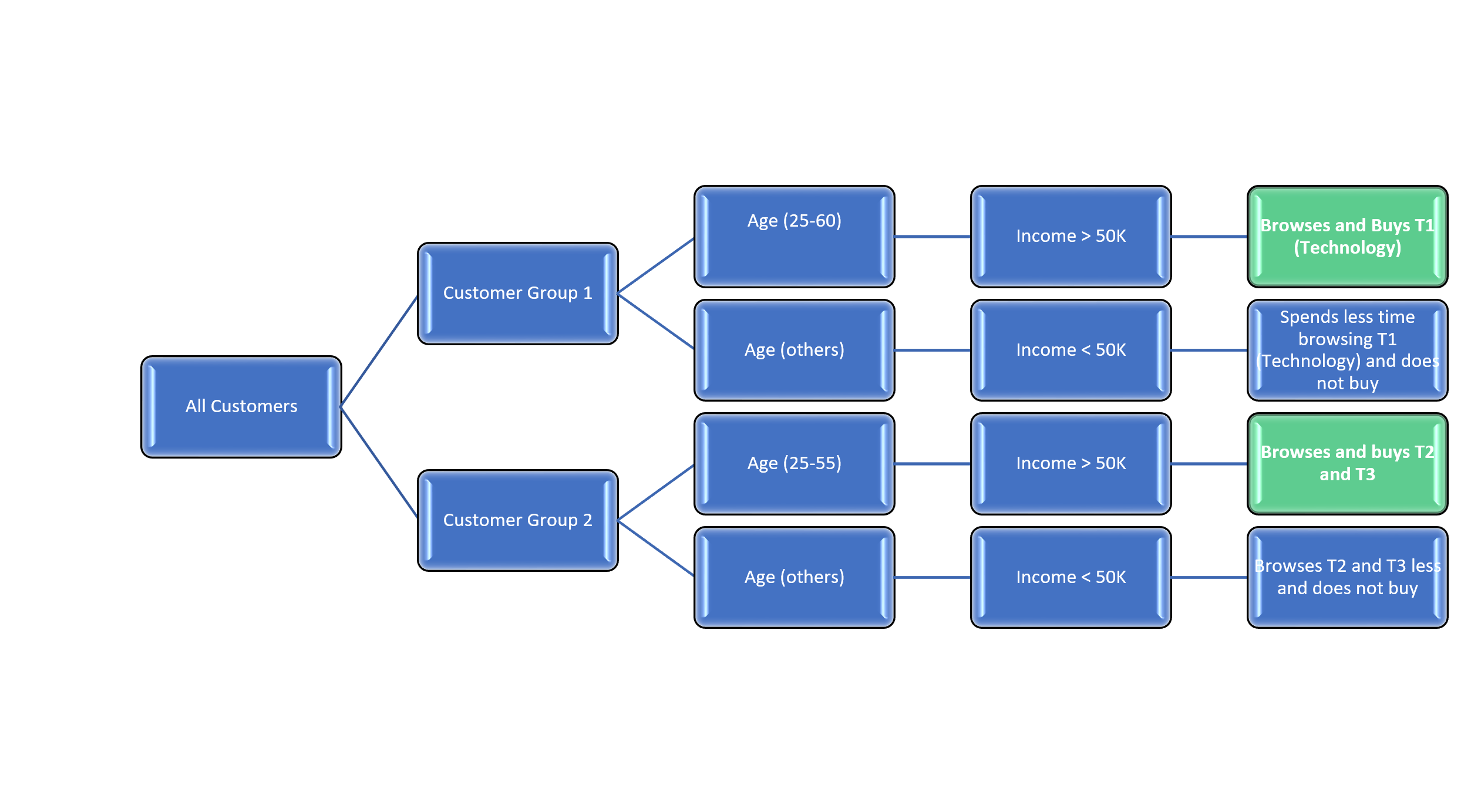
Figure 3: Graphical representation of the Data generation logic - user browsing data
The green boxes represent the actual buyers used to generate the Purchase table. At the end of data generation, the customer browsing data is then streamed through Azure EventHub to Azure Stream Analytics for aggregation. Total customers browsing times are calculated and saved to Azure Storage blob for archival and further processing.
2. Data Cleaning, Feature Engineering and ETL
This step requires joining NoSQL user browsing data stored on Azure Storage with referential data on Azure SQL Data Warehouse. Using Data Virtualization, the ETL queries are executed on an HDInsight Spark cluster, using jdbc push to materialize the SQL Customer and Purchase tables onto the HDInsight cluster.
First, set-up the environment and create a Hive context. Hive contexts allows you to run (SQL-Like) queries directly in Spark.
sc = SparkContext()
spark = HiveContext(sc)
Next create the JDBC connection to tables in Azure SQL Data Warehouse.
Recall the admin username and password created during resource deployment.
url = "jdbc:sqlserver://<sql_dw_name>.database.windows.net:1433;database=<databse_name>;user=<adminUsername>;password=<adminPassword>!"
# Read Puchase Table
dfPurchase = spark.read.jdbc(url=url,table="dbo.purchase")
# Read Customer Table
dfCustomer = spark.read.jdbc(url=url,table="dbo.customer")
Next remove unwanted columns (EventHub adds timestamp information) from userbrowsing data.
# Read Userbrowsing Data and drop Eventhub columns
dfBrowsingData = spark.read.csv('{}/{}'.format(str(wasb_dataset_path), '*.csv'), header=True)
dfBrowsingData = dfBrowsingData[dfBrowsingData.userdatetime, dfBrowsingData.customerid, dfBrowsingData.category_t1, dfBrowsingData.category_t2, dfBrowsingData.category_t3]
Missing values are replaced in Purchase table
create_hive_purchase_table = '''
CREATE TABLE IF NOT EXISTS Hive_Purchase
(
userDatetime STRING,
customerID VARCHAR(10),
ProductID VARCHAR(10),
T1_amount_spent DECIMAL(18, 2),
T2_amount_spent DECIMAL(18, 2),
T3_amount_spent DECIMAL(18, 2)
)
'''
spark.sql(create_hive_purchase_table)
# Replace Null values in Purchase table
insert_into_hive_purchase = '''
INSERT INTO Hive_Purchase
SELECT datetime, customerID, ProductID,
CASE WHEN ProductID = 'T1' THEN amount_spent ELSE 0 END AS T1_amount_spent,
CASE WHEN ProductID = 'T2' THEN amount_spent ELSE 0 END AS T2_amount_spent,
CASE WHEN ProductID = 'T3' THEN amount_spent ELSE 0 END AS T3_amount_spent
FROM Purchase
'''
spark.sql(insert_into_hive_purchase)
spark.sql('DROP TABLE IF EXISTS merge_temp')
Next find the historic purchase of every customer that has browsed and bought products. This is achieved by joining the cleansed Purchase and UserBrowsingTable.
insert_into_merge_purchase_browsing = '''
INSERT INTO merge_purchase_browsing
SELECT
b.userDatetime,
a.customerID,
a.category_T1,
a.category_T2,
a.category_T3,
CASE WHEN (b.T1_amount_spent IS NULL) THEN 0 ELSE b.T1_amount_spent END AS amount_spent_T1,
CASE WHEN (b.T2_amount_spent IS NULL) THEN 0 ELSE b.T2_amount_spent END AS amount_spent_T2,
CASE WHEN (b.T3_amount_spent IS NULL) THEN 0 ELSE b.T3_amount_spent END AS amount_spent_T3
FROM UserBrowsingTable a LEFT JOIN Hive_Purchase b
ON a.customerID = b.customerID
ORDER BY customerID ASC, a.userDatetime ASC
'''
spark.sql(merge_purchase_browsing)
Next from merge_purchase_browsing, find customers activity for the past 3, 10 and 30 days. This is used to create the RFM segments for our customers.
Customer activities in the past 3, 10 and 30 days are used to enrich already existing customer profiles. The consolidated Customer_Profile table is saved as csv to Azure Storage for further multi-class classification.
You can find the complete ETL Script here.
3. Profile Scoring and Enrichment
NOTE To explore how the Machine Learning model was trained, follow this tutorial.
First the pre-trained model is loaded from blob into R Server's local context.
# Copy model file locally after removing the existing file
# i.e. clean up existing objects in workspace
if (file.exists(localModelPath)==TRUE) {
file.remove(localModelPath)
}
dir.create(localModelFolder, showWarnings = FALSE)
rxHadoopCopyToLocal(modelFile, localModelPath) # copy the model to this location
load(localModelPath) # load the model into an object
Next the consolidated customer profile, from the feature engineering/etl stage is loaded onto the MRS head node.
customerprofileData <- RxTextData(file=inputFile, delimiter=",", fileSystem=hdfsFS)
XDF <- file.path(tempdir(), "customerprofile.xdf")
temp <- rxDataStep(customerprofileData, outFile = XDF, overwrite = TRUE,
colInfo = list( gender = list(type = "factor", levels = c("M", "F")),
income = list(type = "factor", levels = c("Less_than_10K","10K_50K","50K_100K","Greater_than_100K")),
label = list(type = "factor", levels = c("0","1","2","3"))))
DF <- rxImport(temp) # Import the file to the head node
Examine the metadata of the EXternal Data Frame (XDF). Validate the rxDataStep worked correctly by calling rxGetInfo.
rxGetInfo(temp, getVarInfo = TRUE) # show metadata about this XDF file
Next we call rxPredict to classifier our customer profile.
outputs = rxPredict(Tree1, DF, type = "prob")
Now using the outputs from the prior prediction step, update the customer profile xdf with the classifications.
# Updating the Customer profile with classification labels
enriched_profile_xdf <- transform(DF,
label = outputs$label_Pred,
prob_categoryT0 = outputs$X0_prob,
prob_categoryT1 = outputs$X1_prob,
prob_categoryT2 = outputs$X2_prob,
prob_categoryT3 = outputs$X3_prob )
The final enriched profile is written out as a csv file that maps to an external Data Warehouse table.
write.table(enriched_profile_xdf, file = localUpdatedCustomerProfileFile, row.names = FALSE, append = TRUE, col.names = FALSE, sep = ",")
For scalability, the scoring code must be parallel, modular and reuseable. The multi-class classification is invoked in batch mode using RevoScale R Revo64 CM BATCH Command. ADF orchestrates this parallel scoring using a MapReduce Activity on the HDInsight cluster. The following is the a sample command.
Revo64 CMD BATCH "--args <location_of_classifier_on_wasb> <path_to_data_slice> <name_of_output_file> <name_of_ouput_file>" <name_of_R_scoring_script> /dev/stdout
Following link for complete Scoring.R script
4. Final Results
The Azure Stream Analytics continuously aggregates the stream of user activity data sent to the EventHub by the data simulator. And for each ADF time slice (15 minutes), the aggregated data from ASA are piped to the ETL process and then classified using the pre-trained model (both running on an HDInsight cluster). The final enriched profiles are written out to a csv file that maps to an external table on Azure SQL Data Warehouse. For each orchestrated time slice, the Azure SQL DW table refreshes with new enriched customer profiles that reflect their most recent activities. Interactive visualizations, using PowerBI, can be extracted from the Azure SQL DW table to gain a deeper understanding of the customer.
Scaling
For a cost effective demonstration (i.e. end to end operation) of this solution, the data generator has been downscaled to produce approximately 7500 messages every 15 minutes to fit an ADF time slice. However, the batch size of the data generator can easily be tuned to scale up to 100 messages per second. The data generator batches events to EventHub and the batch size can be scaled up to even larger numbers. Each component in the architecture supports a separate level of scale. Each service can be scaled up to support a higher throughput or scaled out to spread throughput across multiple services. We observed a linear relationship between the number of EventHub Throughput Units and Azure Stream Analytics Stream Unit (SU).
| EventHub Throughput Unit (TU) | ASA Streaming Unit (SU) | Number of messages batched into EventHub | Number of messages reaching ASA from EventHub |
|---|---|---|---|
| 1 | 1 | 44.6k | 44.6k |
| 1 | 1 | 58k | 58k |
| 2 | 1 | 143k | 128k |
| 2 | 2 | 150k | 150k |
These numbers are variable based on the dataset used. If you would like to scale this architecture to higher throughput, then considerations must be given to the following components individually:
- Azure EventHubs
- Azure Streaming Analytics
- Azure HDInsight
1. Azure EventHub
Azure Eventhub ingresses events into a time-based buffer which is implemented based on a partition/consumer model. However, for scale, the consumer of these partitions will need to be intelligent enough to cordinate and load balance the reads. The tier you select affects the number of messages and connections you can make to an EventHub instance. Pricing and message tier information can be found here. Performance of EventHub is tied directly to the number of configured Throughput Units (TU). By default an EventHub is set to 1TU.
| Description | BASIC | STANDARD | DEDICATED |
|---|---|---|---|
| Ingress events | $0.028 per million events | $0.028 per million events | Included in dedicated pricing |
| Message size | 256KB | 256KB | 1MB |
| Consumer Group | 1 - Default | 20 | 20 |
This blog describes EventHub scaling in detail. If you interact with EventHub via code, separate modules can be added to your development that can handle auto-scaling, partition management and load balancing; for example - Event Processor Host nugget in C#. EventHubs also expose API and endpoints for batch messaging. We have leveraged this to send our payload from the data generator.
Follow this video for a detailed tutorial on scaling EventHub.
2. Azure Stream Analytics (ASA)
Azure Stream Analytics jobs are building blocks for increasing stream data processing throughput. An analytic job includes inputs, query, and output. Analytic computing power is controlled by Streaming Units (SU). Each streaming unit is approximately 1MB/second of throughput. Performance of the job depends on the number of SU, partition configuration of the inputes and the query of the job. ASA scales best if the data is perfectly partitionable and embarrasingly parallel. This tutorial describes more about ASA scaling fpr throughput. The end goal of a predictive pipeline is Machine Learning (ML). ASA requires special attention when scaling for Machine Learning functions and jobs. This tutorial discusses the best practices on how to achieve ASA ML scaling. Pricing details for Standard SU can be found below.
| USAGE | PRICE |
|---|---|
| Streaming Unit | $0.11/hr |
Learn more about ASA; documentation and pricing here
3. Azure HDInsight (HDI)
HDI can be scaled for General Availability and/or Compute Performance. Changing the number of nodes scales for performance and availability. HDI cluster lets you change the number of nodes without having to delete or re-create it. On Azure Portal, HDI has a Scaling Feature that allows you change the number of worker noders. When working with bigger datasets you may need to increase the number of your worker nodes in order to fit the end to end pipeline in the ADF fifteen (15) minutes time slice. Otherwise consider increase the time slice, in ADF, to allow the end to end pipeline to run completely.
Azure HDInsight pricing can be found here Learn more about Azure HDI manageability and scaling here
Visualizations using Power BI Dashboard
Use Power BI to gain powerful business insights by adding visualizations to the enriched customer profile data. Power BI can connect to a variety of data sources and in our solution, we will connect to the Azure Storage Blob which contains our enriched profile data. This section describes how to set up the sample Power BI dashboard to visualize the results of the end to end solution.
-
Get the Azure Storage Blob container Shared Access Signature (SAS) URL generated by the CIQS deployment.
- If you deployed this solution using CIQS, then one of the final steps outputs the SAS URL to the enriched customer profile blob. Please copy that URL for reference in Step 3 below.
-
Update the data source of the Power BI file.
-
Make sure you have the latest version of Power BI desktop installed.
-
Download the Power BI template for the solution and open it with Power BI Desktop.
-
The initial visualizations are based on sample data.
Note: If you see any error messages, please make sure you have the latest version of Power BI Desktop installed.
- On PowerBI Desktop, go to
Edit Queries->Data Source Settings->Change Source. Set the SAS URL to the path copied from step #1 above. This should look something likehttps://<storage_account_name>.blob.core.windows.net/<container_name>/xxx.csv?<query_parameters>If a new window pops up, click connect on this window.- If you did not use the automated deployment of the solution, you can create the SAS token by using Microsoft Azure Storage Explorer. Using the Storage Explorer navigate to the blob that contains your final enriched results. Right-click on it and select Get Shared Access Signature. On the window that appears, click Create and Copy the content of the URL – this is the SAS token of your blob.
NOTE: When new data is pulled into Power BI, you may see the WARNING
There are pending changes in your queries that haven’t been applied.-
If you see a WARNING or the data fails to load, hit Apply changes on the panel above.
-
Save the dashboard. Your Power BI file now has an established connection to the server.
- If your dashboards are empty, clear the stale visuals by selecting the visualizations and clicking the eraser icon on the upper right corner of the legends. Then use the refresh button to reflect new data on the visualizations.
- Alternatively, clicking on the yellow Fix this button might automatically resolve the issue.
-
-
Publish the dashboard to Power BI online (Optional).
Note that this step needs a Power BI account (or Office 365 account).
-
Click Publish. After a few seconds a window will appear displaying Publishing to Power BI Success! with a green check mark. To find detailed instructions, see Publish from Power BI Desktop.
-
To create a new dashboard: click the + sign next to the Dashboards section on the left pane. Name this dashboard "Customer 360 Profile".
-
-
Schedule refresh of the data source (Optional).
- To schedule refresh of the data, hover your mouse over the dataset, click "..." and then choose Schedule Refresh.
Note: If you see a warning massage, click Edit Credentials and make sure your blob path is using the SAS key generated from the CIQS deploy and described in step #1.
-
Expand the Schedule Refresh section. Turn on "keep your data up-to-date".
-
Schedule the refresh based on your needs. To find more information, see Data refresh in Power BI.
Exit and Clean up
You’ll be charged for running the solution in Azure. To avoid incurring charges, please remove the deployment after you have completed the tutorial deployment and evaluation. You can remove it by selecting and deleting the created resource group from Azure Portal.
Copyright
© 2017 Microsoft Corporation. All rights reserved. This information is provided "as-is" and may change without notice. Microsoft makes no warranties, express or implied, with respect to the information provided here. Third party data was used to generate the solution. You are responsible for respecting the rights of others, including procuring and complying with relevant licenses to create similar datasets.
License
The MIT License (MIT) Copyright © 2017 Microsoft Corporation
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.