5.8 KiB
Apache Kafka connector for Cosmos DB Gremlin API
This is a sink connector from Apache Kafka into Microsoft Azure Cosmos DB Graph account. It allows modelling events as vertices and edges of a graph and manipulating them using Apache Tinkerpop Gremlin language.
This connector supports primitive, Binary, Json and Avro serializers.
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.microsoft.com.
When you submit a pull request, a CLA-bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., label, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Setup
Setup instructions are applicable after Confluent or Apache Kafka are up and running.
- Clone the repository
- Open root folder in terminal and execute
mvn package
This command will produce connector and dependencies.
/target/dependencies/*.*
/target/kafka-connect-cosmosdb-graph-0.1.jar
- Copy these dependencies into your Kafka cluster plugin folder. For Confluent platform please create a folder and copy all dependencies and connector:
<kafka path>/share/java/kafka-connect-gremlin
- Restart your Connect worker process. It will discover new connector automatically by inspecting plugin folder.
Configuration
To start using connector please open your Confluence Control Center and navigate to Management -> Kafka Connect -> Send data out -> Add Connector
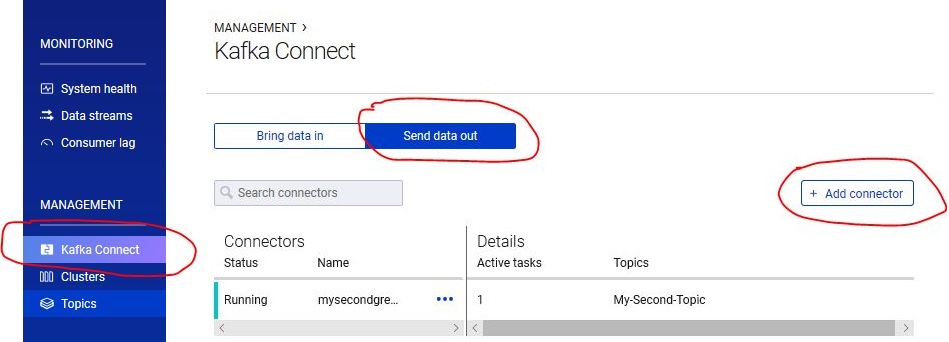
On the next page please select KafkaGremlinSinkConnector. If this connector is not available, likely Connect worker did not pick up the changes and it is recommended to restart worker again and let him finish directory scan before trying to add a connector again.
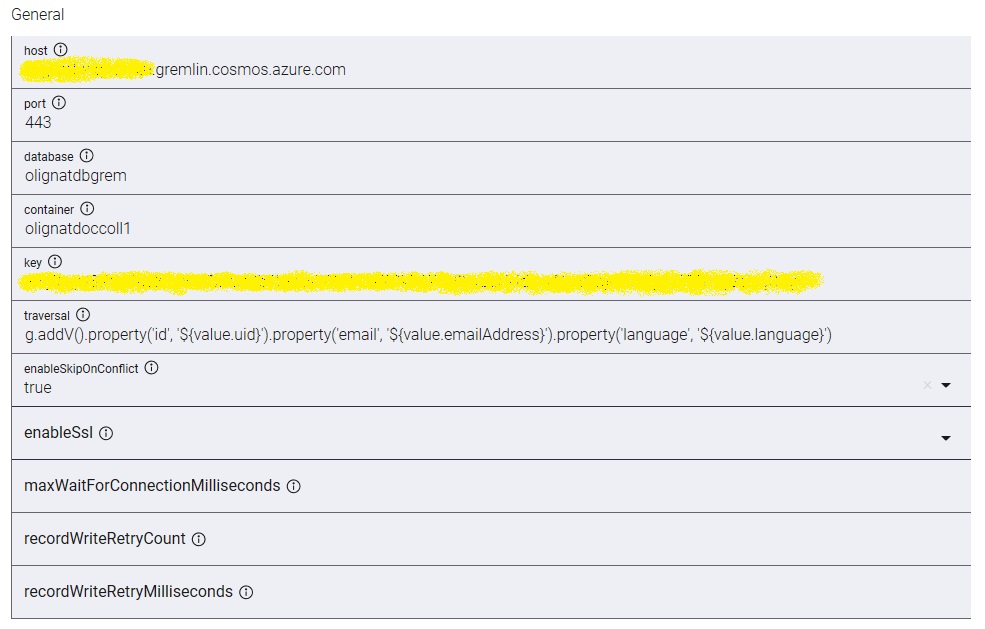
host - fully qualified domain name of gremlin account. Please specify DNS record in zone gremlin.cosmos.azure.com for public Azure. Please do not put documents.azure.com, it will not work.
port - default HTTPS port 443
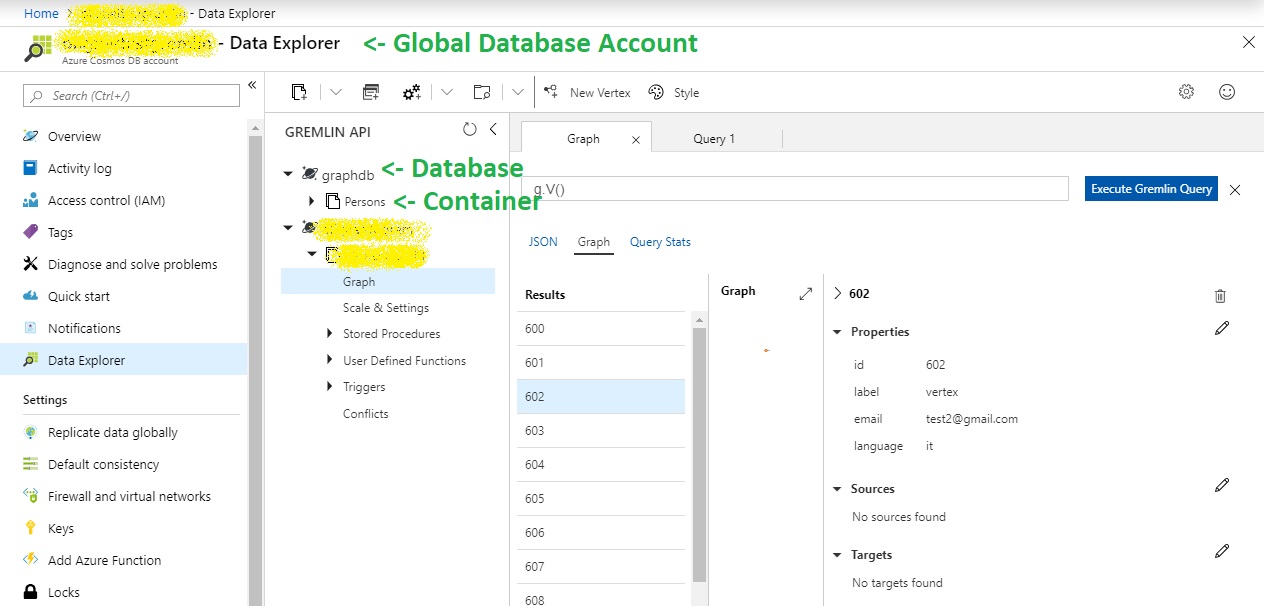
database - this is database resource in Cosmos DB, not to be confused with global database account. This value appears in Data Explorer after "New Graph" is created.
container - name of Cosmos DB collection that contains graph data.
traversal - gremlin traversal to execute for every Kafka message published to the Kafka Topic and received by connector. Sample traversal could be adding a vertex for every event
g.addV()
.property('id', ${value.uid})
.property('email', ${value.emailAddress})
.property('language', ${value.language})
Support event syntax
Each Kafka event contains a key and a value properties, each of which has schema. Both can be resolved independently in a traversal template configured on a connector.
| Schema type | Mapping | Result |
|---|---|---|
| INT8, INT16, INT32, INT64, FLOAT32, FLOAT64, BOOLEAN, STRING | ${key} or ${value} |
Value as is |
| STRUCT | ${key.field} or ${value.field} |
Resolves to structure field |
| MAP | ${key.key} or ${value.key} |
Resolves to value of the key in the map |
| ARRAY | ${key[index]} or ${value[index]} |
Resolves to a positional element in an array |
| BYTES | ${key} or ${value} |
Resolves to Java string representation of an array |
Gremlin is a very powerful language as such a great deal of transformations of events can be done within gremlin itself on the server side. For example, Cosmos DB requires id property be string, but incoming stream may carry id as integer.
g.addV()
.property('id', ${value.uid}.toString())
References
It is worth looking through this material to get better understanding how this connector works and how to use it
Kafka, Avro Serialization, and the Schema Registry