9.8 KiB
TFJob
Prerequisites
Summary
In this module you will learn how to describe a TensorFlow training using TfJob object.
Kubernetes Custom Resource Definition
Kubernetes has a concept of Custom Resources (often abbreviated CRD) that allows us to create custom object that we will then be able to use.
In the case of Kubeflow, after installation, a new TFJob object will be available in our cluster. This object allows us to describe a TensorFlow training.
TFJob Specifications
Before going further, let's take a look at what the TFJob object looks like:
Note: Some of the fields are not described here for brevity.
TFJob Object
| Field | Type | Description |
|---|---|---|
| apiVersion | string |
Versioned schema of this representation of an object. In our case, it's kubeflow.org/v1alpha1 |
| kind | string |
Value representing the REST resource this object represents. In our case it's TFJob |
| metadata | ObjectMeta |
Standard object's metadata. |
| spec | TFJobSpec |
The actual specification of our TensorFlow job, defined below. |
spec is the most important part, so let's look at it too:
TFJobSpec Object
| Field | Type | Description |
|---|---|---|
| ReplicaSpecs | TFReplicaSpec array |
Specification for a set of TensorFlow processes, defined below |
Let's go deeper:
TFReplicaSpec Object
| Field | Type | Description |
|---|---|---|
| TfReplicaType | string |
What type of replica are we defining? Can be MASTER, WORKER or PS. When not doing distributed TensorFlow, we just use MASTER which happens to be the default value. |
| Replicas | int |
Number of replicas of TfReplicaType. Again this is useful only for distributed TensorFLow. Default value is 1. |
| Template | PodTemplateSpec |
Describes the pod that will be created when executing a job. This is the standard Pod description that we have been using everywhere. |
Here is what a simple TensorFlow training looks like using this TFJob object:
apiVersion: kubeflow.org/v1alpha1
kind: TFJob
metadata:
name: example-tfjob
spec:
replicaSpecs:
- template:
spec:
containers:
- image: wbuchwalter/<SAMPLE IMAGE>
name: tensorflow
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
restartPolicy: OnFailure
Note that we are note specifying TfReplicaType or Replicas as the default values are already what we want.
Exercises
Exercise 1: A Simple TFJob
Let's schedule a very simple TensorFlow job using TFJob first.
Note: If you completed the exercise in Module 1 and 2, you can change the image to use the one you pushed instead.
When using GPU, we need to request for one (or multiple), and the image we are using also needs to be based on TensorFlow's GPU image.
apiVersion: kubeflow.org/v1alpha1
kind: TFJob
metadata:
name: module6-ex1-gpu
spec:
replicaSpecs:
- template:
spec:
containers:
- image: wbuchwalter/tf-mnist:gpu
name: tensorflow
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
restartPolicy: OnFailure
Save the template that applies to you in a file, and create the TFJob:
kubectl create -f <template-path>
Let's look at what has been created in our cluster.
First a TFJob was created:
kubectl get tfjob
Returns:
NAME AGE
module6-ex1-gpu 5s
As well as a Job, which was actually created by the operator:
kubectl get job
Returns:
NAME DESIRED SUCCESSFUL AGE
module6-ex1-master-xs4b-0 1 0 2m
and a Pod:
kubectl get pod
Returns:
NAME READY STATUS RESTARTS AGE
module6-ex1-master-xs4b-0-6gpfn 1/1 Running 0 2m
Note that the Pod might take a few minutes before actually running, the docker image needs to be pulled on the node first.
Once the Pod's status is either Running or Completed we can start looking at it's logs:
kubectl logs <your-pod-name>
This container is pretty verbose, but you should see a TensorFlow training happening:
[...]
INFO:tensorflow:2017-11-20 20:57:22.314198: Step 480: Cross entropy = 0.142486
INFO:tensorflow:2017-11-20 20:57:22.370080: Step 480: Validation accuracy = 85.0% (N=100)
INFO:tensorflow:2017-11-20 20:57:22.896383: Step 490: Train accuracy = 98.0%
INFO:tensorflow:2017-11-20 20:57:22.896600: Step 490: Cross entropy = 0.075210
INFO:tensorflow:2017-11-20 20:57:22.945611: Step 490: Validation accuracy = 91.0% (N=100)
INFO:tensorflow:2017-11-20 20:57:23.407756: Step 499: Train accuracy = 94.0%
INFO:tensorflow:2017-11-20 20:57:23.407980: Step 499: Cross entropy = 0.170348
INFO:tensorflow:2017-11-20 20:57:23.457325: Step 499: Validation accuracy = 89.0% (N=100)
INFO:tensorflow:Final test accuracy = 88.4% (N=353)
[...]
That's great and all, but how do we grab our trained model and TensorFlow's summaries?
Well currently we can't. As soon as the training is complete, the container stops and everything inside it, including model and logs are lost.
Thankfully, Kubernetes Volumes can help us here.
If you remember, we quickly introduced Volumes in module 2 - Kubernetes, and that's what we already used to mount the drivers from the node into the container.
But Volumes are not just for mounting things from a node, we can also use them to mount a lot of different storage solutions, you can see the full list here.
In our case we are going to use Azure Files, as it is really easy to use with Kubernetes.
Exercise 2: Azure Files to the Rescue
Creating a New File Share and Kubernetes Secret
In the official documentation: Persistent volumes with Azure files, follow the steps listed under Create storage account, Create storage class, and Create persistent volume claim.
Be aware of a few details first:
- It is very important that you create your storage account in the same region and the same resource group (with MC_ prefix) as your Kubernetes cluster: because Azure File uses the
SMBprotocol it won't work cross-regions.AKS_PERS_LOCATIONshould be updated accordingly. - While this document specifically refers to AKS, it will work for any K8s cluster
- Once the PVC is created, you will see a new file share under that storage account. All subsequent modules will be writing to that file share.
Once you completed all the steps, run:
kubectl get pvc
Which should return:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
azurefile Bound pvc-346ab93b-4cbf-11e8-9fed-000d3a17b5e9 5Gi RWO azurefile 5m
Updating our example to use our Azure File Share
Now we need to mount our new file share into our container so the model and the summaries can be persisted.
Turns out mounting an Azure File share into a container is really easy, we simply need to reference our PVC in the Volume definition:
[...]
containers:
- image: <IMAGE>
name: tensorflow
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
volumeMounts:
- name: azurefile
mountPath: <MOUNT_PATH>
volumes:
- name: azurefile
persistentVolumeClaim:
claimName: azurefile
Update your template from exercise 1 to mount the Azure File share into your container,and create your new job.
Note that by default our container saves everything into /tmp/tensorflow so that's the value you will want to use for MOUNT_PATH.
Once the container starts running, if you go to the Azure Portal, into your storage account, and browse your tensorflow file share, you should see something like that:
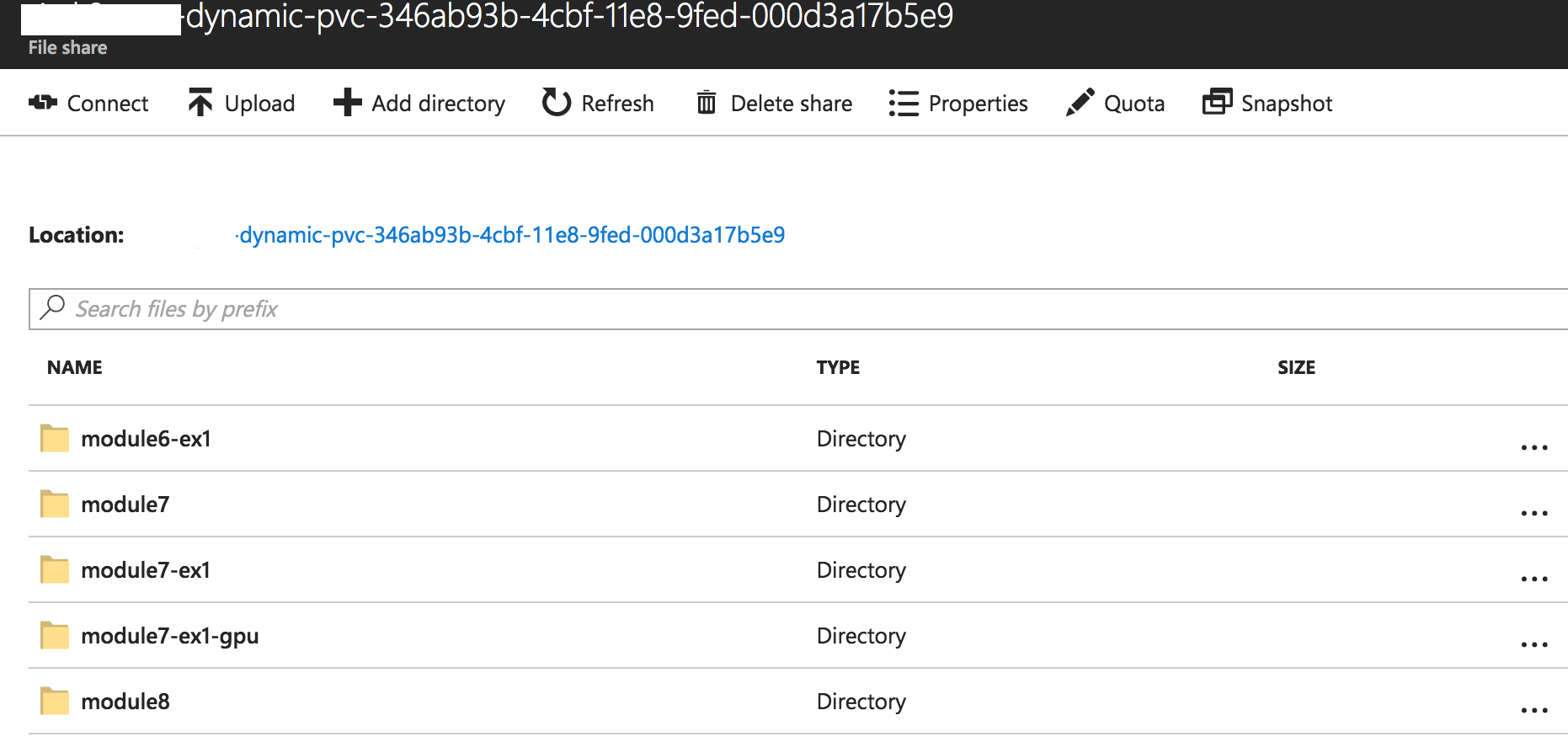
This means that when we run a training, all the important data is now stored in Azure File and is still available as long as we don't delete the file share.
Solution for Exercise 2
Solution
apiVersion: kubeflow.org/v1alpha1
kind: TFJob
metadata:
name: module6-ex2
spec:
replicaSpecs:
- template:
spec:
containers:
- image: wbuchwalter/tf-mnist:gpu
name: tensorflow
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
volumeMounts:
# By default our classifier saves the summaries in /tmp/tensorflow,
# so that's where we want to mount our Azure File Share.
- name: azurefile
# The subPath allows us to mount a subdirectory within the azure file share instead of root
# this is useful so that we can save the logs for each run in a different subdirectory
# instead of overwriting what was done before.
subPath: module6-ex2
mountPath: /tmp/tensorflow
volumes:
- name: azurefile
persistentVolumeClaim:
claimName: azurefile
restartPolicy: OnFailure