7.8 KiB
Sharing Updatable Models (SUM) on Blockchain
(formerly Decentralized & Collaborative AI on Blockchain)
| Demo | Simulation | Security |
|---|---|---|
Sharing Updatable Models (SUM) on Blockchain is a framework to host and train publicly available machine learning models. Ideally, using a model to get a prediction is free. Adding data consists of validation by three steps as described below.
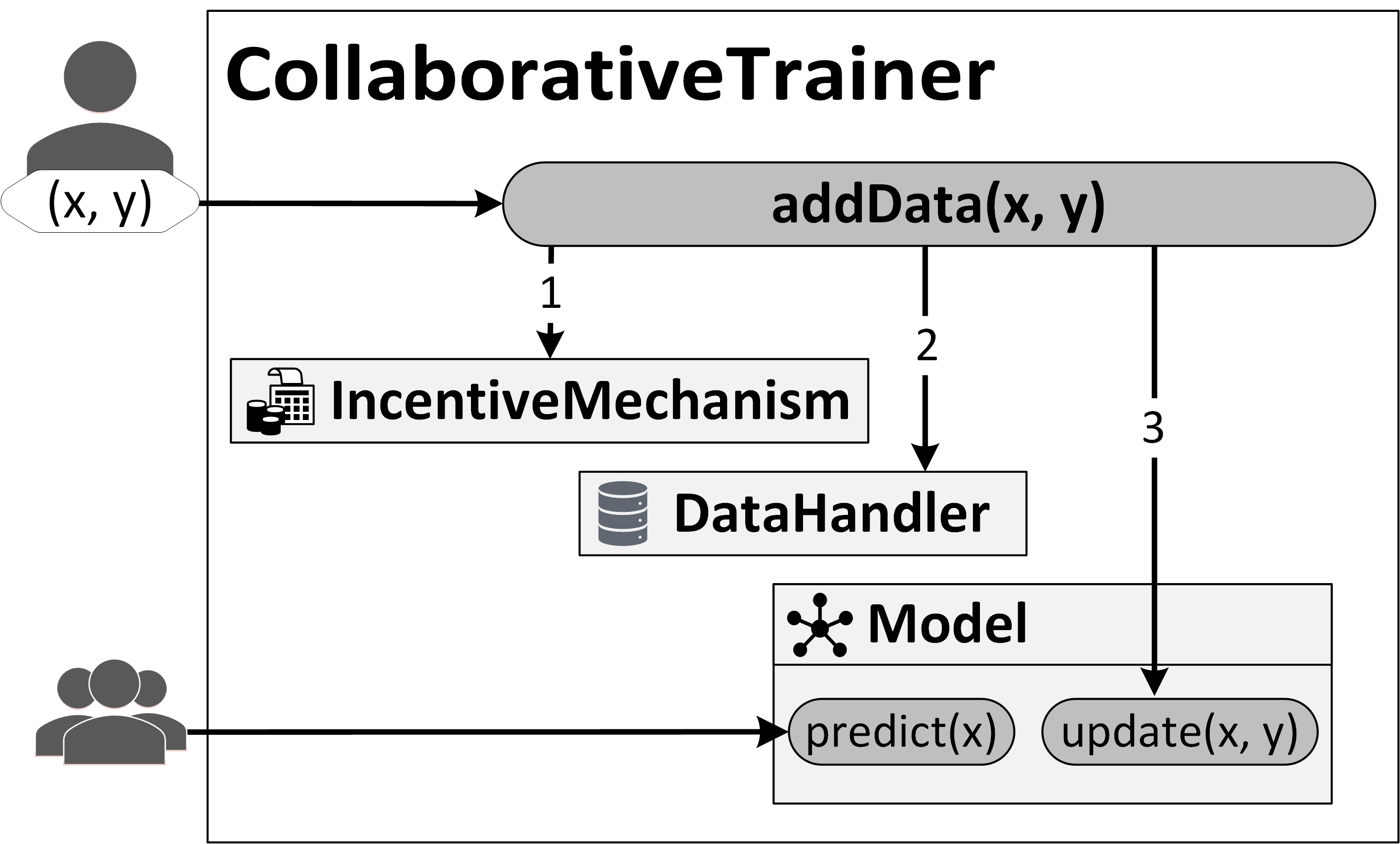
- The IncentiveMechanism validates the request to add data, for instance, in some cases a "stake" or deposit is required. In some cases, the incentive mechanism can also be triggered later to provide users with payments or virtual "karma" points.
- The DataHandler stores data and meta-data on the blockchain. This ensures that it is accessible for all future uses, not limited to this smart contract.
- The machine learning model is updated according to predefined training algorithms. In addition to adding data, anyone can query the model for predictions for free.
The basics of the framework can be found in our blog post. A demo of one incentive mechanism can be found here. More details can be found in the initial paper describing the framework, accepted to Blockchain-2019, The IEEE International Conference on Blockchain.
This repository contains:
- Demos showcasing some proof of concept systems using the Ethereum blockchain. There is a locally deployable test blockchain and demo dashboard to interact with smart contracts written in Solidity.
- Simulation tools written in Python to quickly see how models and incentive mechanisms would work when deployed.

FAQ/Concerns
Aren't smart contracts just for simple code?
There are many options. We can restrict the framework to simple models: Perceptron, Naive Bayes, Nearest Centroid, etc. We can also combine off-chain computation with on-chain computation in a few ways such as:
- encoding off-chain to a higher dimensional representation and just have the final layers of the model fine-tuned on-chain,
- using secure multiparty computation, or
- using external APIs, or as they are called the blockchain space, oracles, to train and run the model
We can also use algorithms that do not require all models parameters to be updated (e.g. Perceptron). We hope to inspire more research in efficient ways to update more complex models.
Some of those proposals are not in the true spirit of this system which is to share models completely publicly but for some applications they may be suitable. At least the data would be shared so others can still use it to train their own models.
Will transaction fees be too high?
Fees in Ethereum are low enough for simple models: a few cents as of July 2019. Simple machine learning models are good for many applications. As described the previous answer, there are ways to keep transactions simple. Fees are decreasing: Ethereum is switching to proof of stake. Other blockchains may have lower or possibly no fees.
What about storing models off-chain?
Storing the model parameters off-chain, e.g. using IPFS, is an option but many of the popular solutions do not have robust mirroring to ensure that the model will still be available if a node goes down. One of the major goals of this project is to share models and improve their availability, the easiest way to do that now is to have the model stored and trained in a smart contract.
We're happy to make improvements! If you do know of a solution that would be cheaper and more robust than storing models on a blockchain like Ethereum then let us know by filing an issue!
What if I just spam bad data?
This depends on the incentive mechanism (IM) chosen but essentially, you will lose a lot of money. Others will notice the model is performing badly or does not work as expected and then stop contributing to it. Depending on the IM, such as in Deposit, Refund, and Take: Self-Assessment, others that already submitted "good" data will gladly take your deposits without submitting any more data.
Furthermore, people can easily automatically correct your data using techniques from unsupervised learning such as clustering. They can then use the data offline for their own private model or even deploy a new collection system using that model.
What if no one gives bad data, then no one can profit?
That’s great! This system will work as a source for quality data and models. People will contribute data to help improve the machine learning models they use in their daily life.
Profit depends on the incentive mechanism (IM). Yes, in Deposit, Refund, and Take: Self-Assessment, the contributors will not profit and should be able to claim back their own deposits. In the Prediction Market based mechanism, contributors can still get rewarded by the original provider of the bounty and test set.
Learn More
Papers
More details can be found in our initial paper, Decentralized & Collaborative AI on Blockchain, which describes the framework, accepted to Blockchain-2019, The IEEE International Conference on Blockchain.
An analysis of several machine learning models with the self-assessment incentive mechanism can be found in our second paper, Analysis of Models for Decentralized and Collaborative AI on Blockchain, which was accepted to The 2020 International Conference on Blockchain.
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.microsoft.com.
When you submit a pull request, a CLA-bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., label, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.