Bump setuptools from 46.1.3 to 65.5.1 in /Containers/base-r |
||
|---|---|---|
| Containers | ||
| Documentation | ||
| Examples | ||
| Notebooks | ||
| .gitignore | ||
| APIDeliverables.md | ||
| AcceptanceCriteria.md | ||
| CODEOFCONDUCT.md | ||
| JupyterNotebook.md | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
README.md
Due to new featues that have since been added to Azure Machine Learning, this repository is now deprecated.
AI for Earth - Creating APIs
These images and examples are meant to illustrate how to build containers for use in the AI for Earth API system. The following images and tags (versions/images) are available on Dockerhub:
-
mcr.microsoft.com/aiforearth/base-py
- Available Tags
- The latest base-py images are available derived from several CUDA images:
- 1.15 - nvidia/cuda:9.2-runtime-ubuntu16.04
- 1.15-cuda-9.0 - nvidia/cuda:9.0-runtime-ubuntu16.04
- 1.15-cuda-9.0-devel - nvidia/cuda:9.0-devel-ubuntu16.04
- The base-py image can be built using any Ubuntu image of your choice by building with the optional BASE_IMAGE build argument.
- Example of how to build with the CUDA 9.0 devel image (inside Containers):
docker build . -f base-py/Dockerfile -t base-py:1.13-cuda-9.0-devel --build-arg BASE_IMAGE=nvidia/cuda:9.0-devel-ubuntu16.04
- Example of how to build with the CUDA 9.0 devel image (inside Containers):
-
mcr.microsoft.com/aiforearth/blob-py
- Available Tags
- The latest base-py images are available derived from several CUDA images:
- 1.5 - nvidia/cuda:9.2-runtime-ubuntu16.04
-
mcr.microsoft.com/aiforearth/base-r
- Available Tags
- The latest base-r images are available derived from gdal:
- 1.8 - osgeo/gdal:ubuntu-full-3.0.3
-
mcr.microsoft.com/aiforearth/blob-r
- Available Tags
- The latest base-r images are available derived from gdal:
- 1.5 - osgeo/gdal:ubuntu-full-3.0.3
Notice
Additional to a running docker environment, GPU images require NVIDIA Docker package to support CUDA.
CUDA Toolkit
To view the license for the CUDA Toolkit included in the cuda base image, click here
CUDA Deep Neural Network library (cuDNN)
To view the license for cuDNN included in the cuda base image, click here
Contents
- Repo Layout
- Quickstart Tutorial
- Choose a base image or example
- Insert code to call your model
- Input handling
- Output handling
- Function decorator detail
- Create AppInsights instrumentation keys
- Install required packages
- Set environment variables
- Build and run your image
- Make requests
- Publish to Azure Container Registry
- Run your container in ACI
- FAQs
- Contributing
Repo Layout
- Containers
- base-py [Base AI for Earth Python image]
- API hosting libraries
- Azure Blob libraries
- Monitoring libraries
- base-r [Base AI for Earth R image]
- API hosting libraries
- Azure Blob libraries
- Monitoring libraries
- blob-py [Base AI for Earth Python image with Azure Blob mounting tools]
- AI for Earth base-py base
- AI for Earth Azure Blob mounting tools
- blob-r [Base AI for Earth R image with Azure Blob mounting tools]
- AI for Earth base-r base
- AI for Earth Azure Blob mounting tools
- base-py [Base AI for Earth Python image]
- Examples
Notes
- Docker commands for the base and blob images must be run at the version level of the repo. Ex.
docker build . -f base-py/Dockerfile. Example Docker commands can be run within the example codebase.
Quickstart Tutorial
This quickstart will walk you through turning a model into an API. Starting with a trained model, we will containerize it, deploy it on Azure, and expose an endpoint to call the API. We will leverage Docker containers, Azure Application Insights, Azure Container Registry, and Azure Container Instances.
We are assuming that you have a trained model that you want to expose as an API. To begin, download or clone this repository to your local machine.
Create an Azure Resource Group
Throughout this quickstart tutorial, we recommend that you put all Azure resources created into a single new Resource Group. This will organize these related resources together and make it easy to remove them as a single group.
From the Azure Portal, click Create a resource from the left menu. Search the Marketplace for "Resource Group", select the resource group option and click Create.
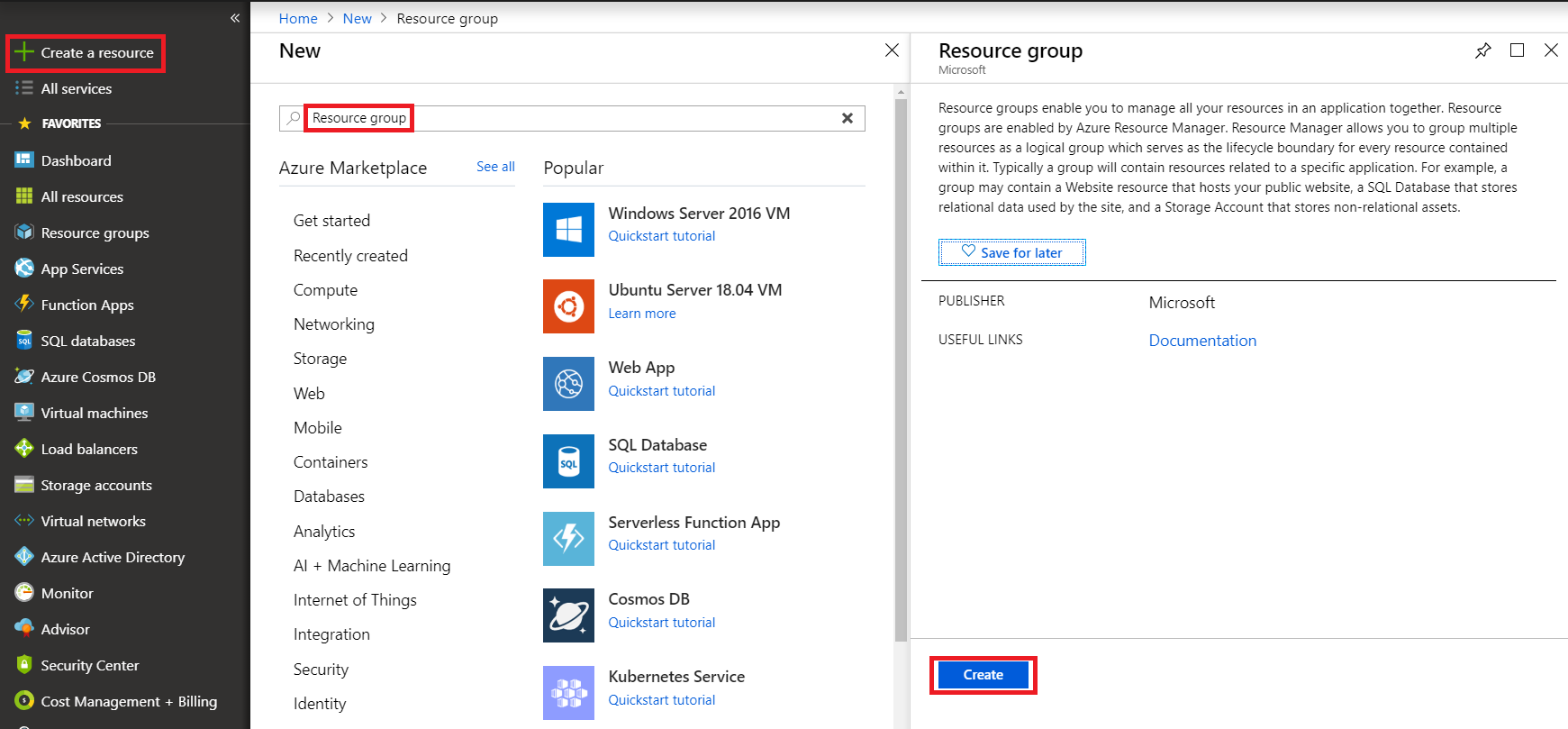
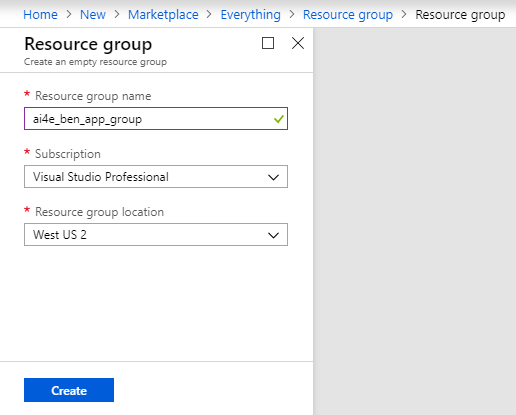
Use a descriptive resource group name, such as "ai4e_yourname_app_rg". Then click Create.
Machine Setup
You will need an active Azure subscription as well as the following software installed.
- Azure CLI
- Docker Desktop
- Postman
- Any Python/R/etc. environment you need to invoke your model
Choose a base image or example
AI for Earth APIs are all built from an AI for Earth base image. You may use a base image directly or start with an example. The following sections will help you decide.
Base images
- base-py
- base-r
- blob-py
- blob-r
Examples
- Basic Python API (Sync and Async)
- Basic R API (Sync and Async)
- Blob Python API
- Synchronous PyTorch API
- Asynchronous Tensorflow API
In general, if you're using Python, you will want to use an image or example with the base-py or blob-py images. If you are using R, you will want to use an image or example with the base-r or blob-r images. The difference between them: the blob-* image contains everything that the cooresponding base-* image contains, plus additional support for mounting Azure blob storage. This may be useful if you need to process (for example) a batch of images all at once; you can upload them all to Azure blob storage, the container in which your model is running can mount that storage, and access it like it is local storage.
Asynchronous (async) vs. Synchronous (sync) Endpoint
In addition to your language choice, think about whether your API call should be synchronous or asynchronous.
- A synchronous API call will invoke your model, get results, and return immediately. This is a good paradigm to use if you want to perform classification with your model on a single image, for example.
- An asynchronous API call should be used for long-running tasks, like processing a whole folder of images using your model and storing the results, or constructing a forecasting model from historical data that the user provides.
Asynchronous Implementation Examples
The following examples demonstrate async endpoints:
- base-py's
exampleendpoint - base-r
- tensorflow
Synchronous Implementation Examples
The following examples demonstrate sync endpoints:
Input/Output Patterns
While input patterns can be used for sync or async designs, your output design is dependent on your sync/async choice, therefore, we have identified recommended approaches for each.
Input Recommendations
JSON
JSON is the recommended approach for data ingestion.
Binary Input
Many applications of AI apply models to image/binary inputs. Here are some approaches:
- Send the image directly via request data. See the tensorflow example to see how it is accomplished.
- Upload your binary input to an Azure Blob, create a SAS key, and add a JSON field for it.
- If you would like users to use your own Azure blob storage, we provide tools to mount blobs as local drives within your service. You may then use this virtual file system, locally.
- Serializing your payload is a very efficient method for transmission. BSON is an open standard, binary-encoded serialization for such purposes.
Asynchronous Pattern
The preferred way of handling asynchronous API calls is to provide a task status endpoint to your users. When a request is submitted, a new taskId is immediately returned to the caller to track the status of their request as it is processed.
We have several tools to help with task tracking that you can use for local development and testing. These tools create a database within the service instance and are not recommended for production use.
Once a task is completed, the user needs to retrieve the result of their service call. This can be accomplished in several ways:
- Return a SAS-keyed URL to an Azure Blob Container via a call to the
taskendpoint. - Request that a writable SAS-keyed URL is provided as input to your API call. Indicate completion via the task interface and write the output to that URL.
- If you would like users to use your own Azure blob storage, you can write directly to a virtually-mounted drive.
Examples
We have provided several examples that leverage these base images to make it easier for you to get started.
- base-py: Start with this example if you are using Python and don't need Azure blob storage integration, and none of the below more specific examples are a good fit. It contains both synchronous and asynchronous endpoints. It is a great example to use for asynchronous, long-running API calls.
- base-r: Start with this example if you are using R.
- blob-mount-py: Start with this example if you are using Python and you need Azure blob storage integration.
- pytorch: This example is a modification of the base-py example, using a synchronous API call to call a PyTorch model. It is a great example to use if you are using PyTorch or if you are making a synchronous API call.
- tensorflow: This example is a modification of the base-py example, using an asynchronous API call to call a TensorFlow model. It is a great example to use if you are using TensorFlow or if you are making an asynchronous API call.
After you've chosen the example that best fits your scenario, make a copy of that directory, which you can use as your working directory in which you apply your changes.
Insert code to call your model
Next, in your new working directory, we need to update the example that you chose with code to call your specific model. This should be done in the runserver.py file (if you are using a Python example) or the api_example.R file (if you are using an R example) in the my_api (or similarly named) subfolder.
Input handling
Your model has inputs and outputs. For example, let's consider a classification model that takes an image and classifies its contents as one of multiple species of animal. The input that you need to provide to this model is an image, and the output that you provide may be JSON-formatted text of the classifications and their confidence.
Some examples of how to send parameters as inputs into your APIs follow.
GET URL parameters
For GET operations, best practice dictates that a noun is used in the URL in the segment before the related parameter. An echo example is as follows.
Python and Flask
@ai4e_service.api_sync_func(api_path = '/echo/<string:text>', methods = ['GET'], maximum_concurrent_requests = 1000, trace_name = 'get:echo', kwargs = {'text'})
def echo(*args, **kwargs):
return 'Echo: ' + kwargs['text']
R and Plumber
#* @param text The text to echo back
#* @get /echo/<text>
GetProcessDataTaskStatus<-function(text){
print(text)
}
POST body
For non-trivial parameters, retrieve parameters from the body sent as part of the request. JSON is the preferred standard for API transmission. The following gives an example of sample input, followed by Python and R usage.
Sample Input
{
"container_uri": "https://myblobacct.blob.core.windows.net/user?st=2018-08-02T12%3A01%3A00Z&se=5200-08-03T12%3A01%3A00Z&sp=rwl&sv=2017-04-17&sr=c&sig=xxx",
"run_id": "myrunid"
}
Python and Flask
from flask import Flask, request
import json
post_body = request.get_json()
print(post_body['run_id'])
print(post_body['container_uri'])
R and Plumber
library(jsonlite)
#* @post /process-data
ProcessDataAPI<-function(req, res){
post_body <- req$postBody
input_data <- fromJSON(post_body, simplifyDataFrame=TRUE)
print(input_data$run_id)
print(input_data$container_uri)
}
Output handling
Then, you need to send back your model's results as output. Two return types are important when dealing with hosted ML APIs: non-binary and binary.
Non-binary data
You may need to return non-binary data, like simple strings or numbers. The preferred method to return non-binary data is to use JSON.
Python and Flask
import json
def post(self):
ret = {}
ret['run_id'] = myrunid
ret['container_uri'] = 'https://myblobacct.blob.core.windows.net/user?st=2018-08-02T12%3A01%3A00Z&se=5200-08-03T12%3A01%3A00Z&sp=rwl&sv=2017-04-17&sr=c&sig=xxx'
return json.dumps(ret)
R and Plumber
ProcessDataAPI<-function(req, res){
post_body <- req$postBody
input_data <- fromJSON(post_body, simplifyDataFrame=TRUE)
# Return JSON containing run_id and container_uri
data.frame(input_data$run_id, input_data$container_uri)
}
Binary data
You may also need to return binary data, like images.
Python and Flask
from io import BytesIO
import tifffile
from flask import send_file
ACCEPTED_CONTENT_TYPES = ['image/tiff', 'application/octet-stream']
if request.headers.get("Content-Type") in ACCEPTED_CONTENT_TYPES:
tiff_file = tifffile.imread(BytesIO(request.data))
# Do something with the tiff_file...
prediction_stream = BytesIO()
# Create your image to return...
prediction_stream.seek(0)
return send_file(prediction_stream)
Function decorator detail
We use function decorators to create APIs out of your functions, such as those that execute a model. Here, we will detail the two decorators and their parameters.
There are two decorators:
@ai4e_service.api_async_func, which wraps the function as an async/long-running API.@ai4e_service.api_sync_func, which wraps the function as a sync API that returns right away.
Each decorator contains the following parameters:
api_path = '/': Specifies the endpoint of the API. This comes after the API_PREFIX value in the Dockerfile. For example, if the Dockerfile entry isENV API_PREFIX=/v1/my_api/taskerand the api_path is as it is specified here, the complete endpoint of your API will be http://localhost:80/v1/my_api/tasker/methods = ['POST']: Specifies the methods accepted by the API.request_processing_function = process_request_data: Specifies the function to call before your endpoint function is called. This function will pre-process the request data and is located in your code. To work with request data, you must assign and return the request data as part of a dictionary that will be extracted later in your model function.maximum_concurrent_requests = 5: If the number of requests exceed this limit, a 503 is returned to the caller.content_types = ['application/json']: An array of accepted content types. If the requested type is not found in the array, a 503 will be returned.content_max_length = 1000: The maximum length of the request data (in bytes) permitted. If the length of the data exceeds this setting, a 503 will be returned.trace_name = 'post:my_long_running_funct': A trace name to associate with this function. This allows you to search logs and metrics for this particular function.
Create AppInsights instrumentation keys
Application Insights is an Azure service for application performance management. We have integrated with Application Insights to provide advanced monitoring capabilities. You will need to generate both an Instrumentation key and an API key to use in your application.
The instrumentation key is for general logging and tracing. This is found under the "Properties" section for your Application Insights instance in the Azure portal.
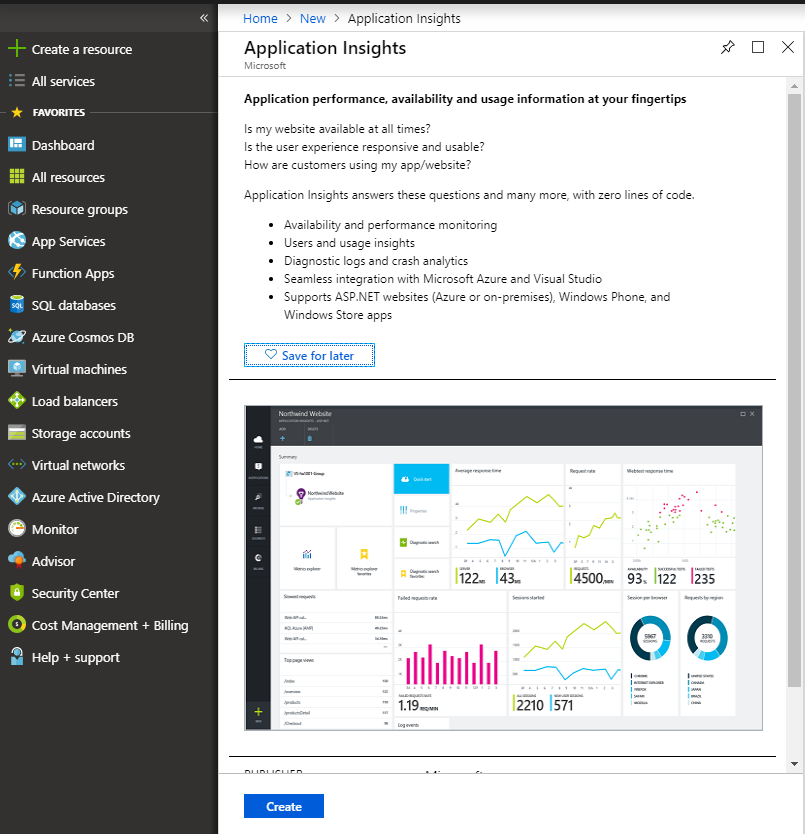
Click Create, then choose a name for your Application Insight resource. For Application Type, choose General from the drop-down menu. For Resource Group, select "Use existing" and choose the resource group that you created earlier.
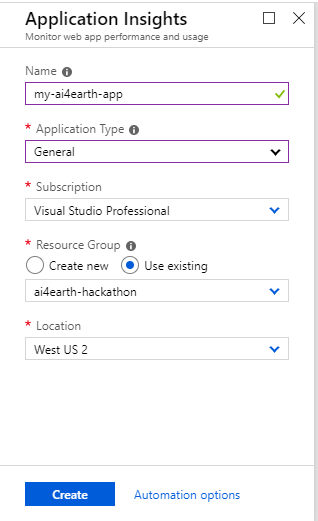
Once your AppInsights resource has successfully deployed, navigate to the resource from your home screen, and locate the Instrumentation Key.
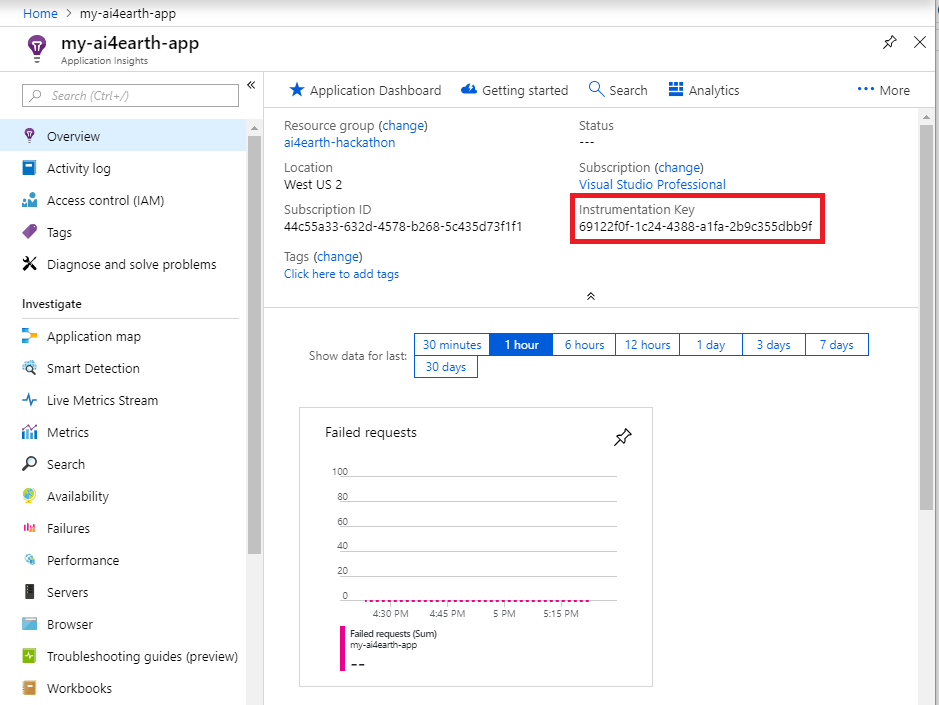
Next, create a Live Metrics API key. Scroll down in the left menu to find API Access within Application Insights, and click Create API key. When creating the key, be sure to select "Authenticate SDK control channel".
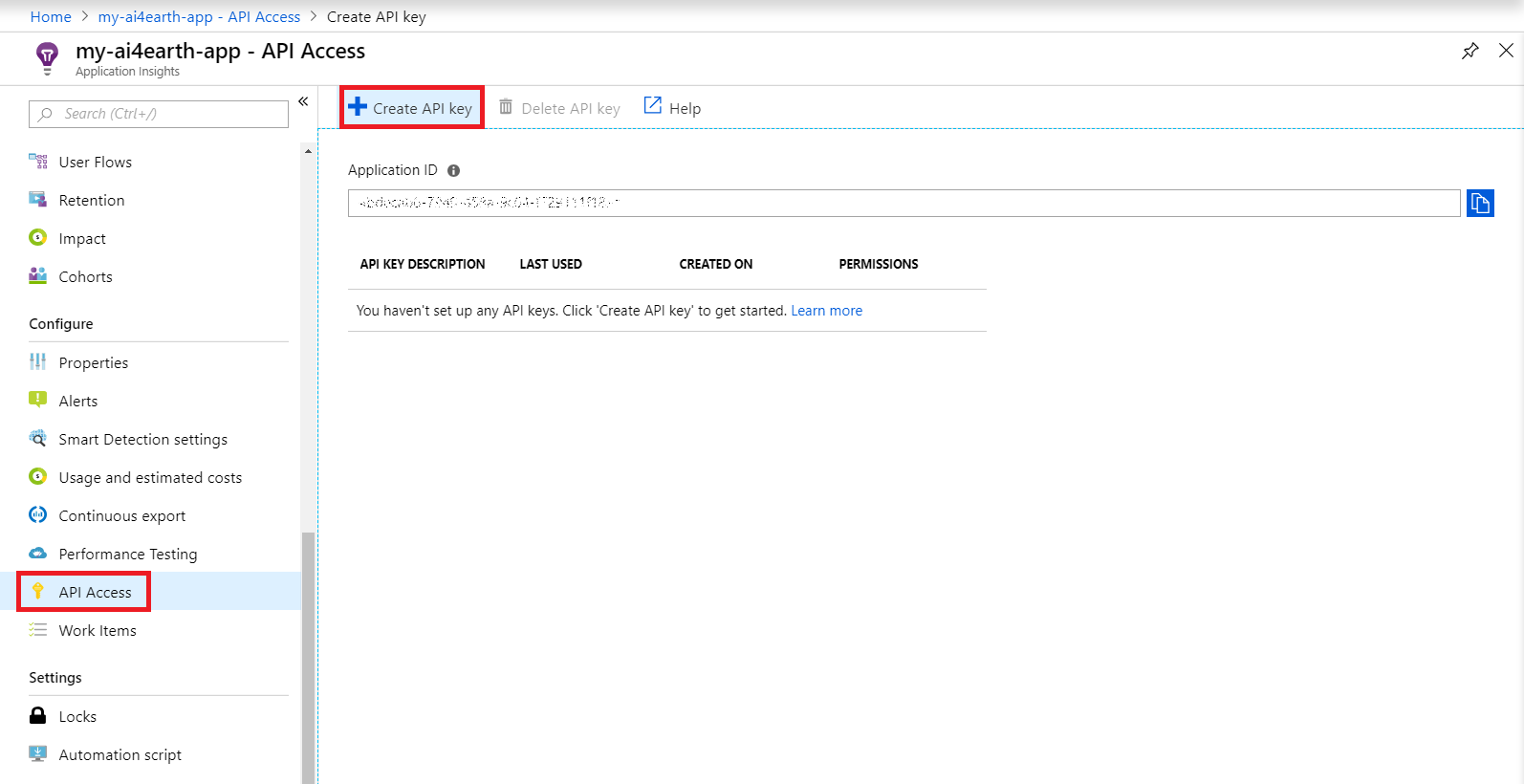
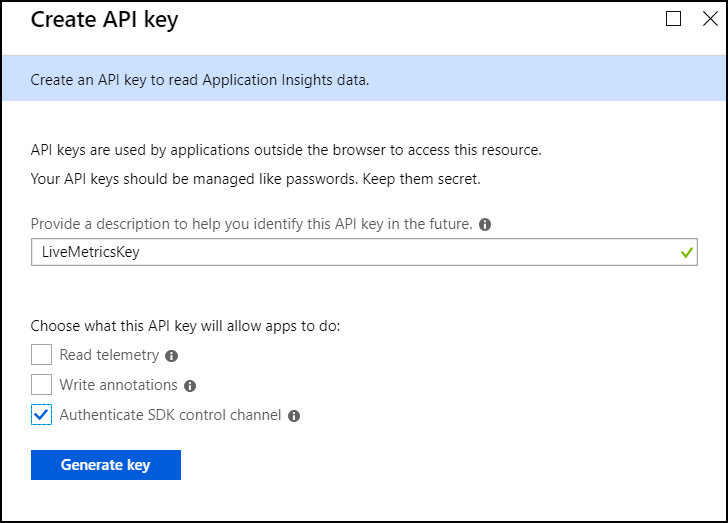
Copy and store both of these keys in a safe place.
Install required packages
Now, let's look at the Dockerfile in your code. Update the Dockerfile to install any required packages. There are several ways to install packages. We cover popular ones here:
- pip
RUN /usr/local/envs/ai4e_py_api/bin/pip install grpcio opencensus
- apt-get
RUN apt-get install gfortran -y
- R packages
RUN R -e 'install.packages("rgeos"); library(rgeos)'
Set environment variables
The Dockerfile also contains several environment variables that should be set for proper logging. You will need to add your two Application Insights keys here as well. Follow the instructions within the file.
# Application Insights keys and trace configuration
ENV APPINSIGHTS_INSTRUMENTATIONKEY=your_instrumentation_key_goes_here \
LOCALAPPDATA=/app_insights_data \
OCAGENT_TRACE_EXPORTER_ENDPOINT=localhost:55678
# The following variables will allow you to filter logs in AppInsights
ENV SERVICE_OWNER=AI4E_Test \
SERVICE_CLUSTER=Local\ Docker \
SERVICE_MODEL_NAME=base-py example \
SERVICE_MODEL_FRAMEWORK=Python \
SERVICE_MODEL_FRAMEOWRK_VERSION=3.6.6 \
SERVICE_MODEL_VERSION=1.0
# The API_PREFIX is the URL path that will occur after your domain and before your endpoints
ENV API_PREFIX=/v1/my_api/tasker
You may modify other environment variables as well. In particular, you may want to change the environment variable API_PREFIX. We recommend using the format "/<version-number>/<api-name>/<function>" such as "/v1/my_api/tasker".
(Optional) Set up Azure blob storage
You will want to follow these steps if you are working from the blob-mount-py example. If you do not plan to use Azure blob storage in your app, skip ahead to Build and run your image.
First you will need create a new Azure Blob Container with a file named config.csv. We also recommend using Azure Storage Explorer to aid in storage upload/download.
Create an Azure storage account by selecting "Storage Accounts" from the left menu and clicking the Add button. Make sure to select the resource group you previously created, and use a descriptive name for your storage account (must be lowercase letters or numbers). You may configure advanced options for your account here, or simply click "Review + create".
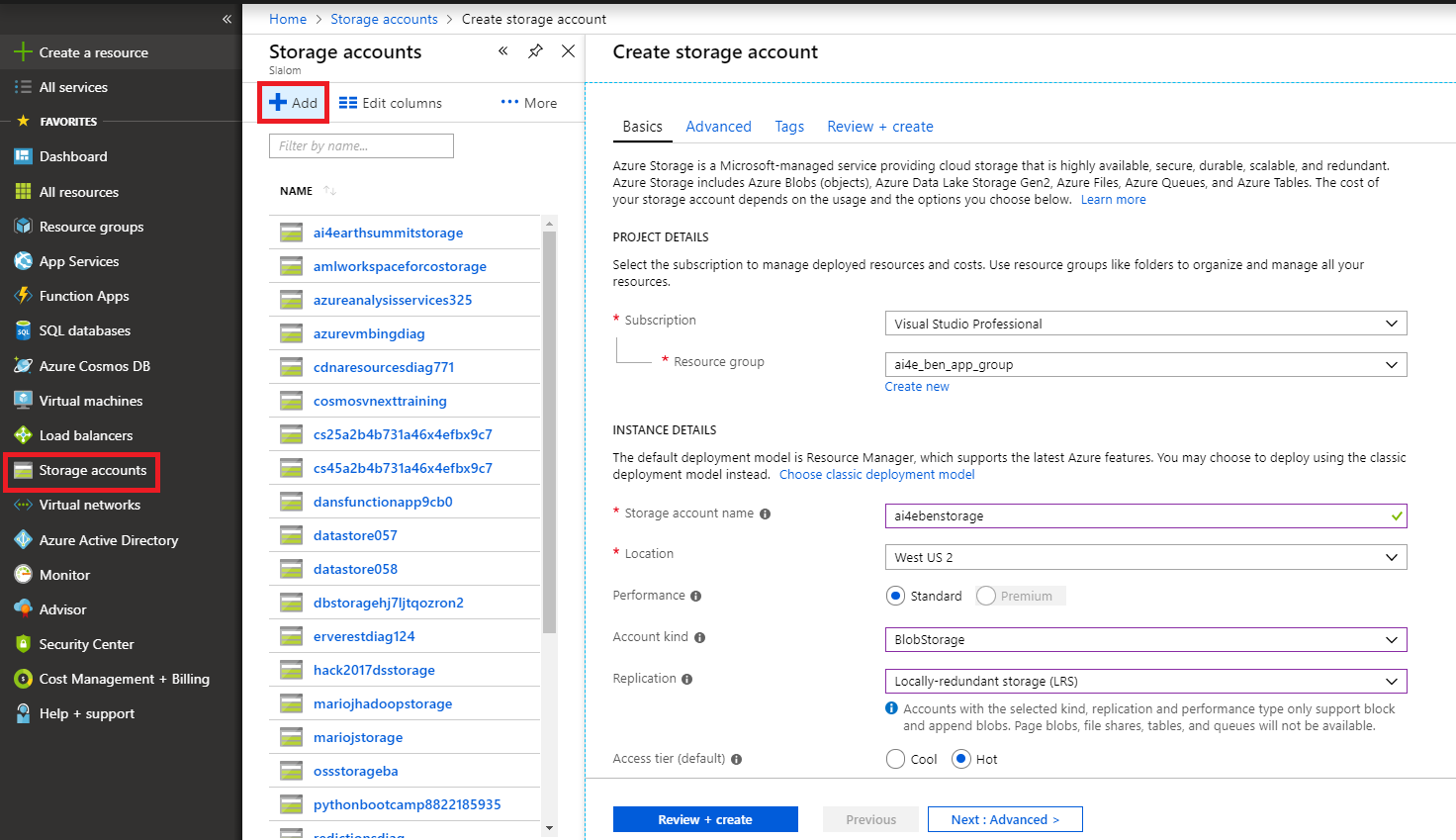
Click "Create" on the validation screen that appears. Once the storage account is deployed, click "Go to resource". You still need to create a container within your storage account. To do this, scroll down on the left menu of your storage account to click on "Blobs". Click the plus sign in the top left to create a new container.
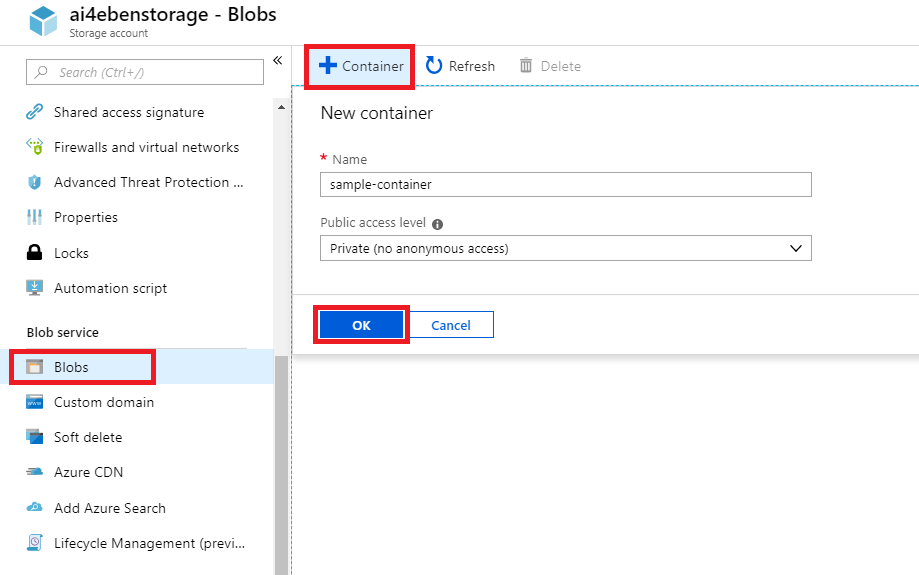
Use a text editor to create an empty file named config.csv on your local machine. You can now navigate to your empty Azure container and upload the file as a blob.
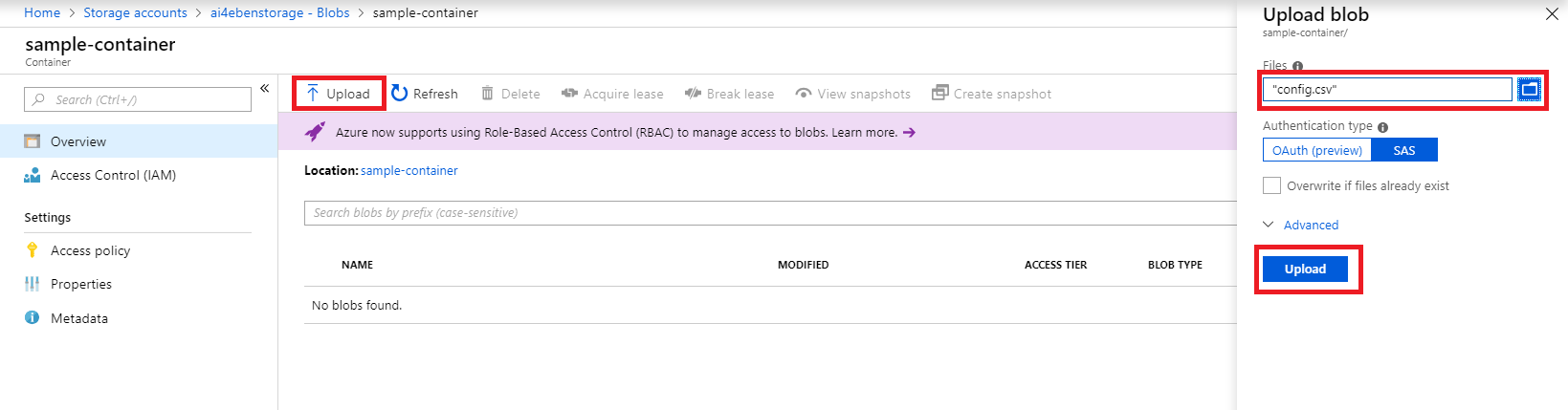
Next, from within the Azure Portal or within Azure Storage Explorer, copy your blob's storage key. You can find your storage keys by clicking "Keys" on the left menu of your storage account.
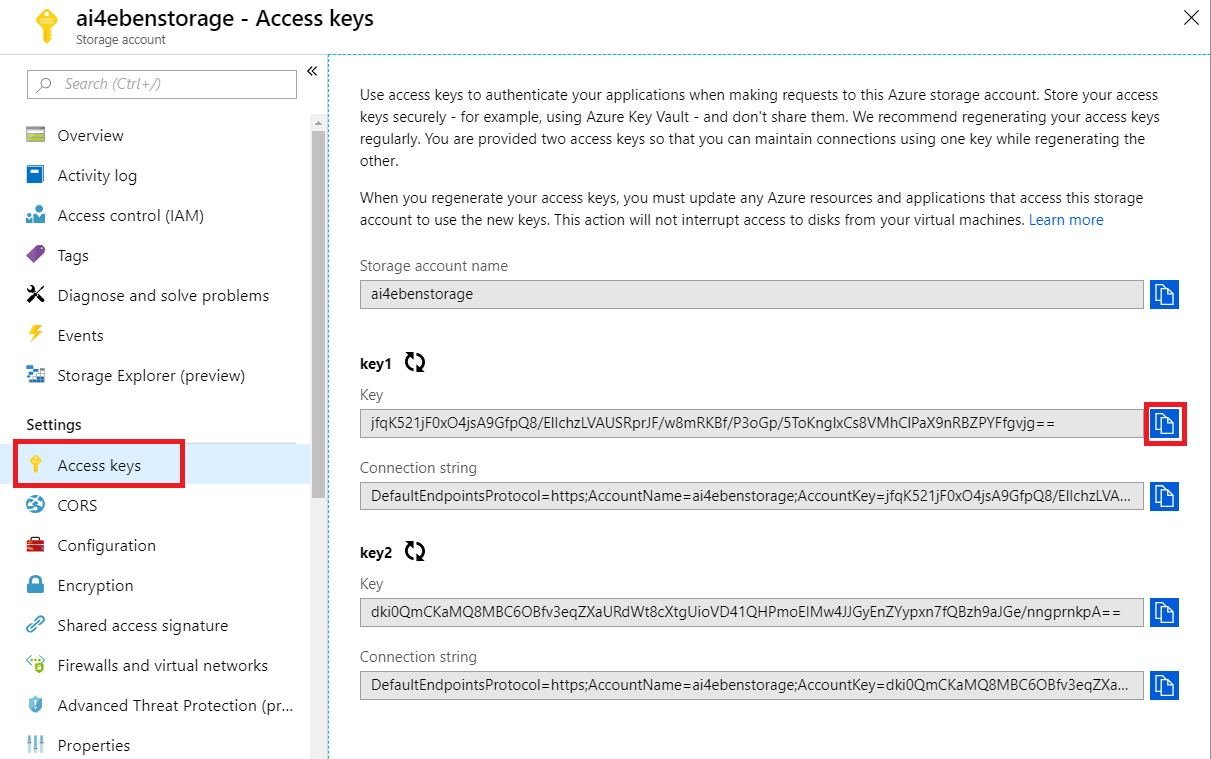
You must also modify the blob_mount.json file as follows:
- accountName: This is the name of your blob storage account.
- accountKey: This is storage account key that you copied.
- containerName: This is the name of the container that you created within your storage account. It is the container that will be mapped, locally.
- mappedDirectory: This is the local path where your container will be mounted.
Note: You may map as many containers as you would like in this file. The blob mounter will mount all of them.
Build and run your image
This section features a step-by-step guide to building and running your image.
Build your image
- Navigate to the directory containing your Dockerfile.
- Execute the docker build command:
docker build . -t your_custom_image_name:1
In the above command, -t denotes that you wish to label your image with the name "your_custom_image_name" and with the tag of 1. Typically tags represent the build number.
If you will be pushing your image to a repository, your docker build command will resemble:
docker build . -t your_registry_name.azurecr.io/your_custom_image_name:1
Run your image, locally
Run a container based on your image:
docker run -p 8081:80 "your_custom_image_name:1"
In the above command, the -p switch designates the local port mapping to the container port. -p host_port:container_port. The host_port is arbitrary and will be the port to which you issue requests. Ensure, however, that the container_port is exposed in the Dockerfile with the Dockerfile entry:
EXPOSE 80
TIP: Depending on your git settings and your operating system, the "docker run" command may fail with the error standard_init_linux.go:190: exec user process caused "no such file or directory". If this happens, you need to change the end-of-line characters in startup.sh to LF. One way to do this is using VS Code; open the startup.sh file and click on CRLF in the bottom right corner in the blue bar and select LF instead, then save.
If you find that there are errors and you need to go back and rebuild your docker container, run the following commands:
# This lists all of the docker processes running
docker ps
# Find the container ID in the list from the previous command, and replace <container-id> with that value to end the process
docker kill <container-id>
Then you can execute your docker build and docker run commands again. Additionally, the docker logs are located in your user account's AppData\Local\Docker folder (i.e. C:\Users\jennmar\AppData\Local\Docker).
Make requests
Now that you have a local instance of your container running, you should issue requests and debug it, locally. For this exercise, you may issue requests in whatever way that you would like, but we prefer using Postman to quickly test our endpoints.
Test endpoints
- Open Postman or your favorite API development tool.
- From your service code, determine which endpoint you want to test. If you are following one of our examples, the endpoint is:
http://localhost:<host_port>/<my_api_prefix>/<route>. Also, understand if you will issuing a POST or a GET. - In your API dev tool, select POST or GET and enter the endpoint you would like to test.
- If you are performing a POST, construct valid JSON for your endpoint and enter it into the body of the request. Alternatively, if you are POSTing an image, upload it to Postman (see screenshots below).
- Click "Send" or execute the call to your endpoint. The running container shell will contain any messages that are printed to the console.
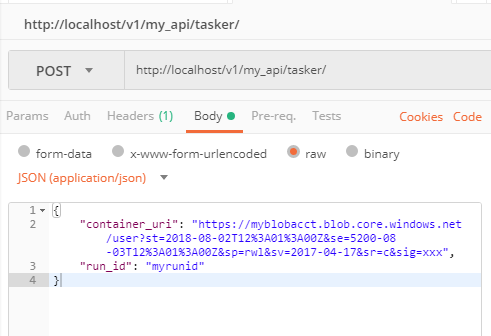
Posting JSON
From the Body tab, select "raw". Ensure that "JSON (application/json)" is selected from the drop-down option (note that a Content-type header is automatically added when you do this). Construct valid JSON in the window.
Posting an Image
In the Headers tab, create a Content-Type header of either image/jpeg or image/png. From the Body tab, select "binary". Upload your JPEG or PNG image here.
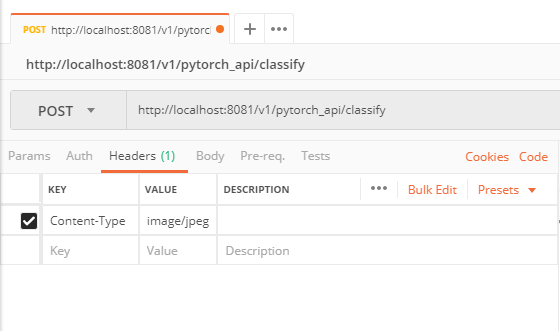
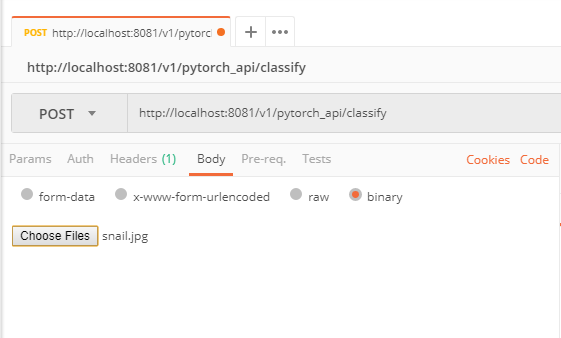
Publish to Azure Container Registry
If you haven't already, create an instance of Azure Container Registry (ACR) in your subscription.
-
Log into the Azure Portal and click on +Create a Resource. Click on "Containers" and select "Container Registry". Select a name for your registry and make sure you choose the same subscription and resource group you used for the AppInsight step above. Before creating the registry make sure Admin user is set to "enable".
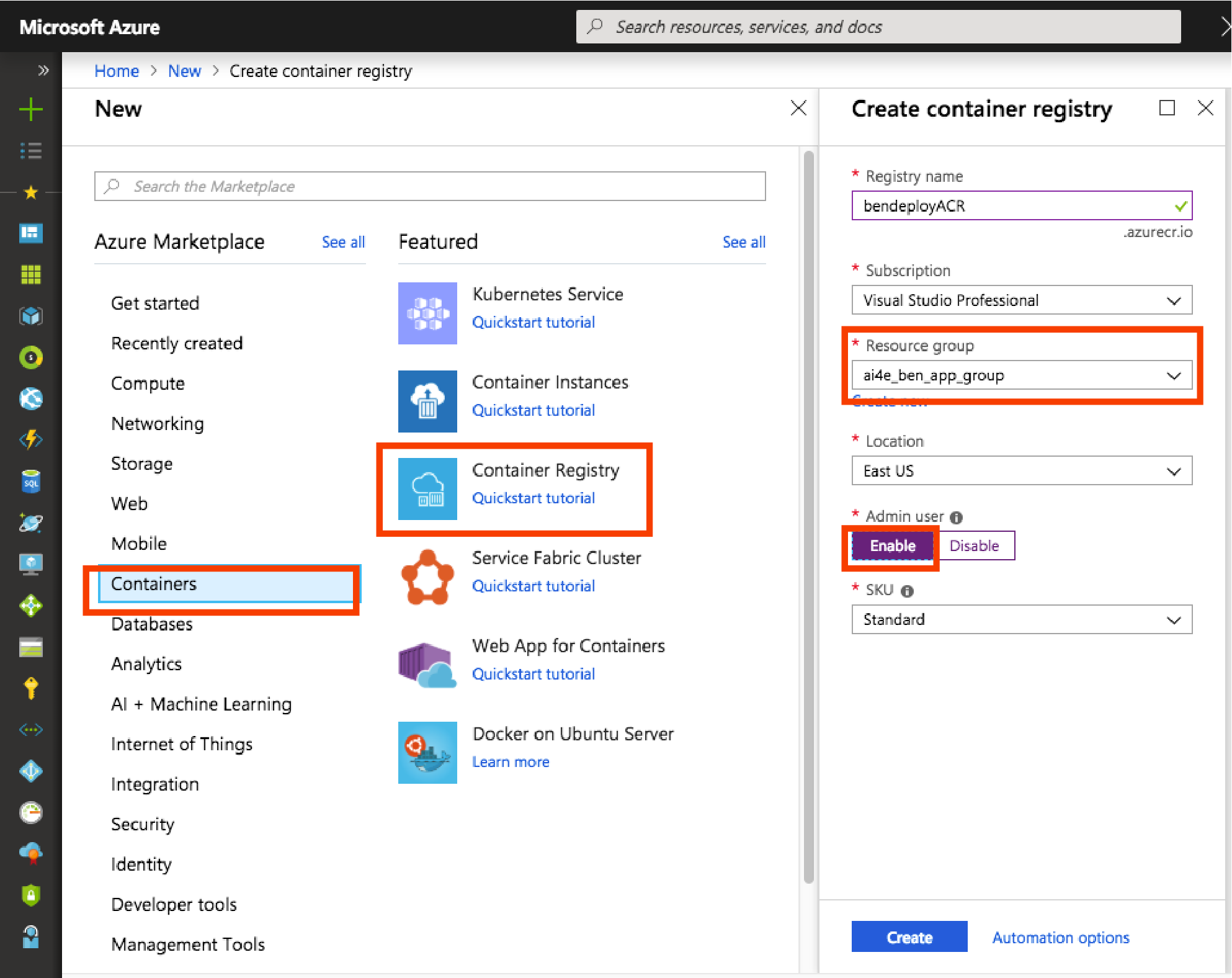
-
After your Azure Container Registry is created, you can click on it to find your login server.
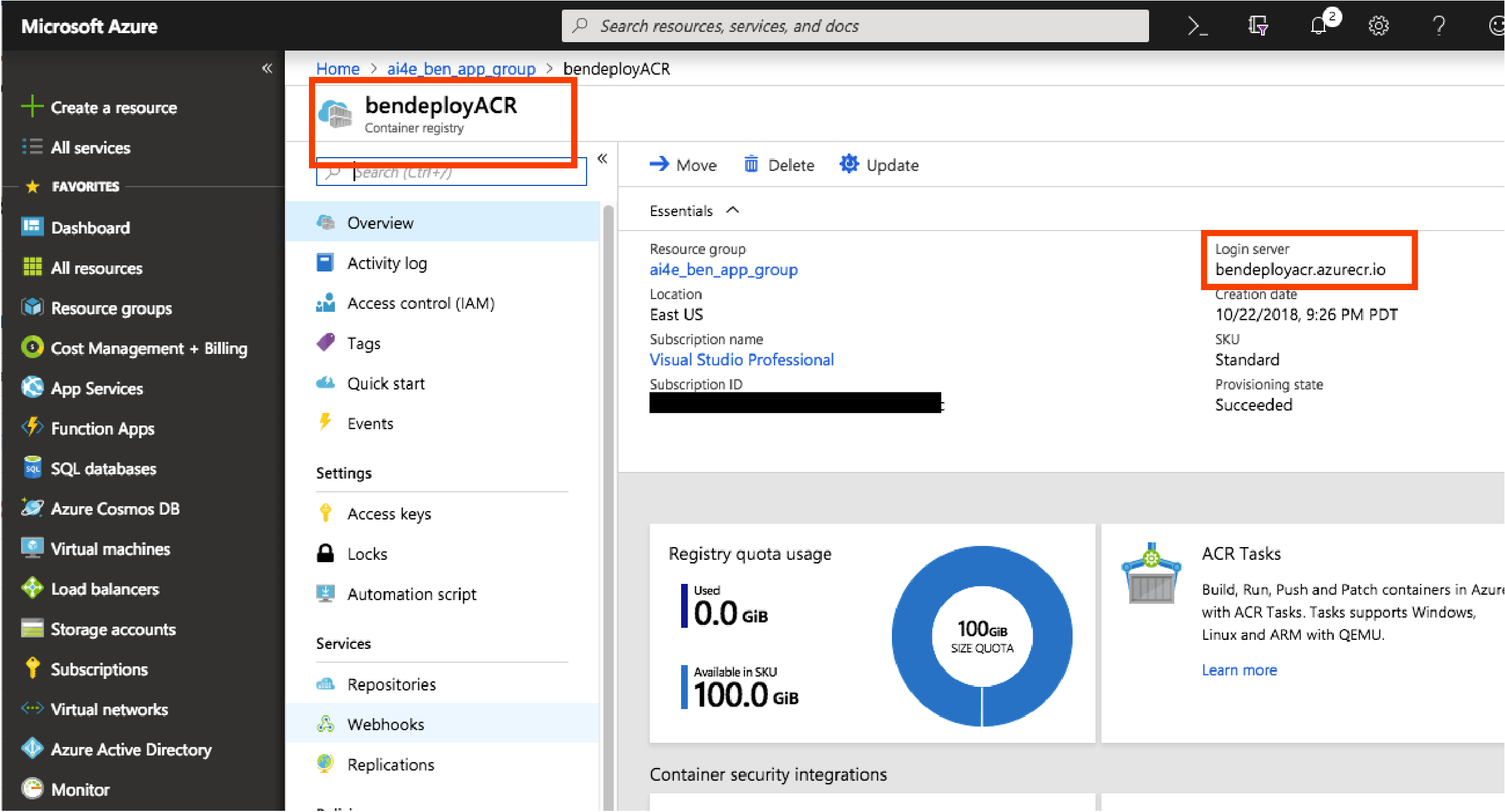
Note: if you just created an ACR (i.e., did not include an ACR uri in your previous build), you will need to tag your container image with your ACR uri.
- Tag your docker image:
docker tag your_custom_image_name:tag <your_login_server>/your_custom_image_name:tag
- Log into your ACR:
docker login --username <username> --password <password> <your_login_server>
You can find your admin ACR credentials on Azure portal.
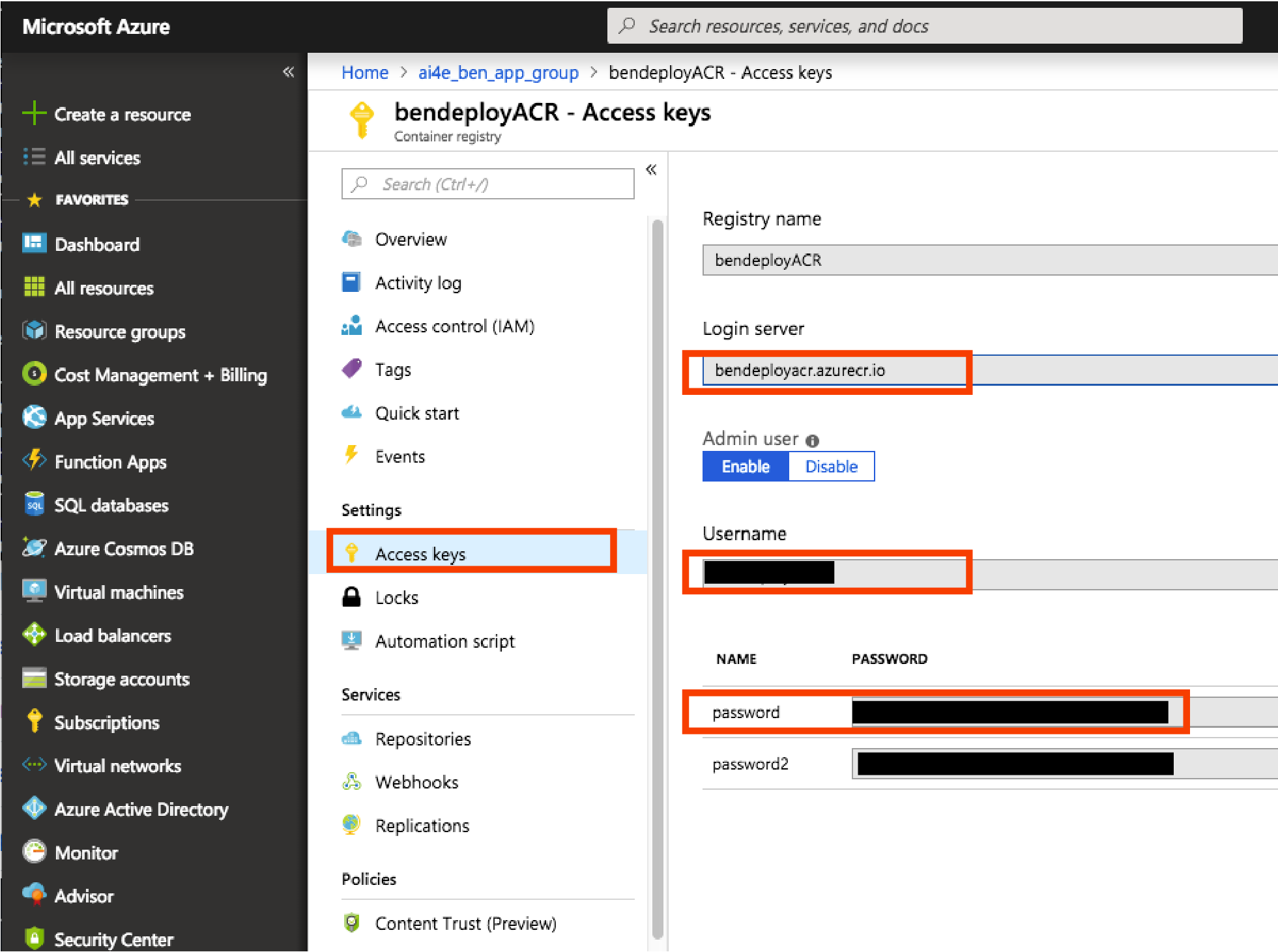
- Push your image to your ACR:
docker push <your_login_server>/your_custom_image_name:tag
Run your container in Azure Container Instances
Running your container in ACI is easy. The easiest way is to open the Azure Portal to your ACR, select the repository and tag that corresponds to the image you just pushed, click on it and select "Run Instance." This will create a new ACI instance of your image.
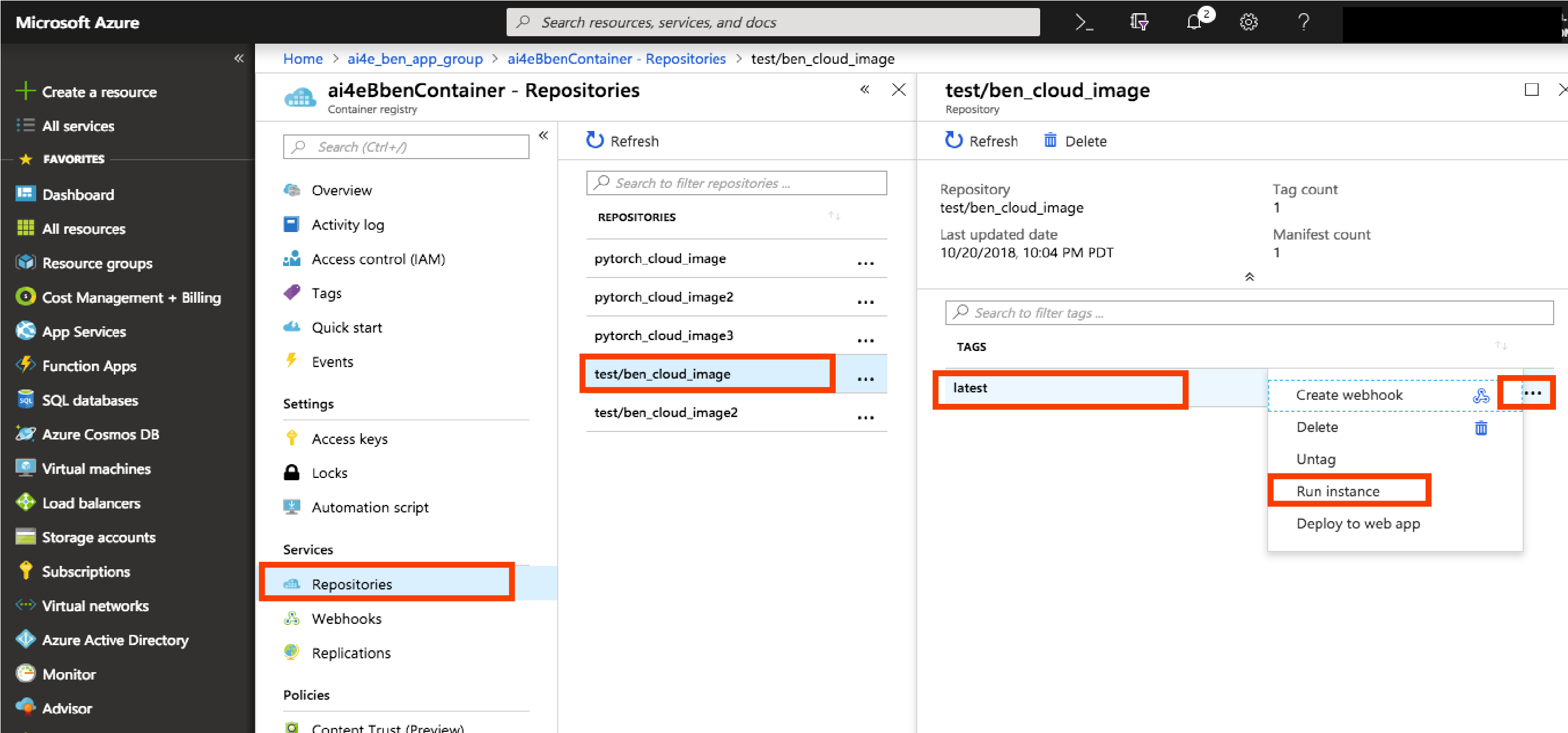
Issue requests to your hosted API
Now that your service is running within ACI, we can issue requests to it.
- Open the Azure Portal to your ACI. Click on the "Overview" tab and copy the "IP address".
- In your API tool, change localhost:port to the IP that you just copied.
- Issue your request.
To see logs/console output in your running container, click on "Containers" in your ACI in the Azure Portal and click the "Logs" tab. If you configured Application Insights, you may use that to review logs, identify issues, and view metrics.
Conclusion and Next Steps
Congratulations! You have successfully hosted a model in Azure and exposed it to be accessed as an API.
Cost implications
The services we used today are very reasonably priced. Here are the pricing details.
- Azure Application Insights Pricing
- Azure Container Registry Pricing
- Azure Container Instances Pricing
- Azure Blob Storage Pricing
How to remove Azure resources
We hope you find this a valuable way to provide access to your machine learning model. But if you don't plan to use your API immediately and you want to release these resources in Azure to reduce your costs, you may do so. If you put all resources in a single resource group, then you can navigate to the Azure portal, click on "Resource Groups", and select the resource group that you have been using throughout this tutorial. From there, you can select "Delete resource group" and remove all of the resources at once. (If you didn't add them all to the same resource group, you can delete them all separately.)
Next Steps
Upon completion of this quickstart tutorial, you may want to investigate the following.
- Azure API Management: Integration with API Management will allow you to publish your APIs to external, partner, and employee developers securely and at scale.
- Azure Kubernetes Services: If you expect significant traffic, you may want to consider a managed Kubernetes cluster instead of a single Azure container instance for hosting your model.
FAQs
- What is "my_api_prefix"? "my_api_prefix" is a variable that denotes the prefix for all of your API endpoints. Typically, you would create a versioned path, so that you can easily make breaking changes in the future without harming existing users. A good prefix example would be: /v1/my_api/.
- In the Python example, why is there an "AppInsights" and an "AI4EAppInsights" library? The Application Insights Python SDK is not an officially supported SDK, but it does provide great Flask integration. Because of this, in our examples, we use the SDK's Flask integration, but we also provide a hardended (AI4EAppInsights) library that you should use for logging.
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.microsoft.com.
When you submit a pull request, a CLA-bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., label, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.