|
|
||
|---|---|---|
| Code-Code | ||
| Code-Text/code-to-text | ||
| Text-Code | ||
| Text-Text/text-to-text | ||
| webpage_files | ||
| .gitignore | ||
| CODE_OF_CONDUCT.md | ||
| Data_LICENCE | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
| baselines.jpg | ||
| index.html | ||
| tasks.jpg | ||
| time-cost.jpg | ||
{kind=link}
{kind=link}
{kind=link}
README.md
Introduction
According to Evans Data Corporation, there are 23.9 million professional developers in 2019, and the population is expected to reach 28.7 million in 2024. With the growing population of developers, code intelligence, which aims to leverage AI to help software developers improve the productivity of the development process, is growing increasingly important in both communities of software engineering and artificial intelligence.
When developers want to find code written by others with the same intent, code search systems can help automatically retrieve semantically relevant code given natural language queries. When developers are confused about what to write next, code completion systems can help by automatically completing the following tokens given the context of the edits being made. When developers want to implement Java code with the same function of some existing body of Python code, code-to-code translation systems can help translate from one programming language (Python) to another (Java).
Code intelligence therefore plays a vital role in Microsoft’s mission to empower developers. As highlighted by Microsoft CEO Satya Nadella at Microsoft Build 2020, the role of developers is more important than ever. GitHub is increasingly the default home for source code, and Visual Studio Code is the most popular code editor. Microsoft offers the most complete toolchain for developers, bringing together the best of GitHub, Visual Studio, and Microsoft Azure to help developers to go from idea to code and code to cloud.
Recent years have seen a surge of applying of statistical models, including neural nets, to code intelligence tasks. Very recently, pre-trained models learned from big programming language data have been inspired by the great success of large pre-trained models like BERT and GPT in natural language processing (NLP). These models, including IntelliCode and CodeBERT, obtain further improvements on code understanding and generation problems. However, the area of code intelligence lacks a benchmark suite that covers a wide range of tasks. We have seen that a diversified benchmark dataset is significant for the growth of an area of applied AI research, like ImageNet for computer vision and GLUE for NLP.
To address this, researchers from Microsoft Research Asia, Developer Division, and Bing introduce CodeXGLUE, a benchmark dataset and open challenge for code intelligence. It includes a collection of code intelligence tasks and a platform for model evaluation and comparison. CodeXGLUE stands for General Language Understanding Evaluation benchmark for CODE. It includes 14 datasets for 10 diversified code intelligence tasks covering the following scenarios:
- code-code (clone detection, defect detection, cloze test, code completion, code repair, and code-to-code translation)
- text-code (natural language code search, text-to-code generation)
- code-text (code summarization)
- text-text (documentation translation)
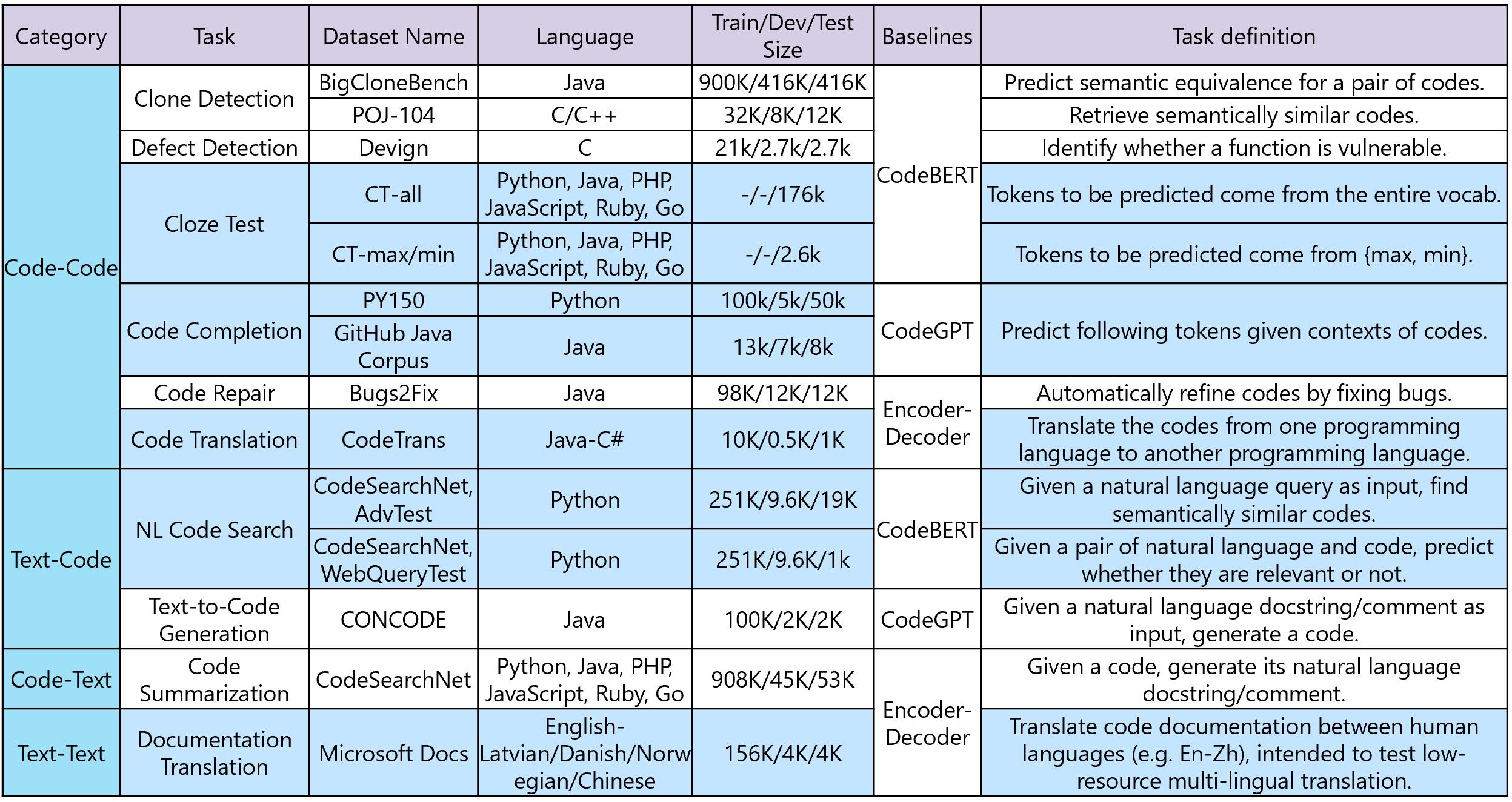
A brief summary of CodeXGLUE is given below, including tasks, datasets, language, sizes in various states, baseline systems, providers, and short definitions of each task. Datasets highlighted in BLUE are newly introduced.
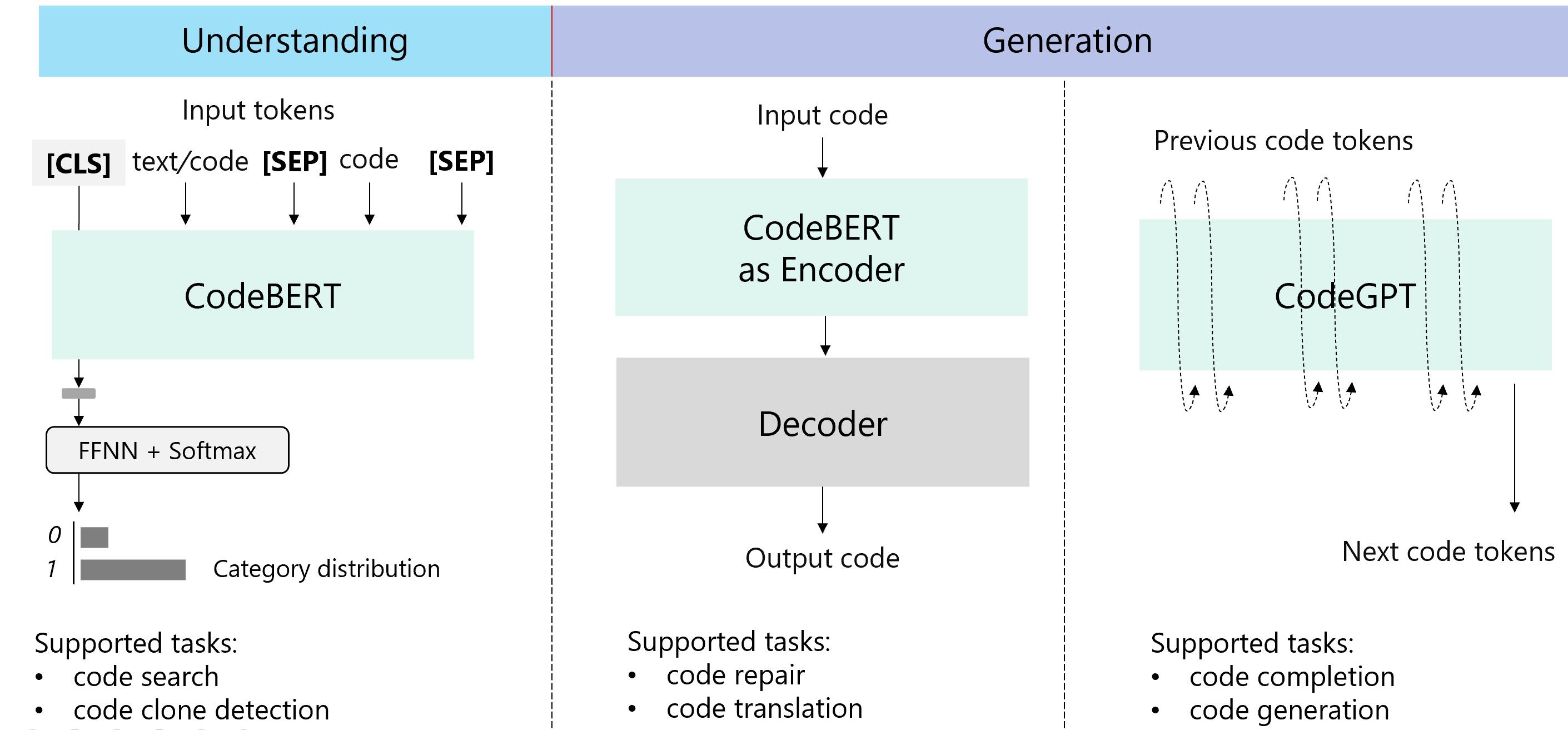
To make it easy for participants, we provide three baseline models to support these tasks, including a BERT-style pre-trained model (in this case, CodeBERT), which is good at understanding problems. We also include a GPT-style pre-trained model, which we call CodeGPT, to support completion and generation problems. Finally, we include an Encoder-Decoder framework that supports sequence-to-sequence generation problems.
Three pipelines including CodeBERT, CodeGPT, and Encoder-Decoder are provided to make it easy for participants.
With CodeXGLUE, we seek to support the development of models that can be applied to various code intelligence problems, with the goal of increasing the productivity of software developers. We encourage researchers to participate in the open challenges to continue progress in code intelligence. Moving forward, we’ll extend CodeXGLUE to more programming languages and downstream tasks while continuing to push forward pre-trained models by exploring new model structures, introducing new pre-training tasks, using different types of data, and more.
Relevant Links
Leaderboard | CodeXGLUE paper | Access from HuggingFace datasets
Tasks and Datasets
Below, we elaborate on the task definition for each task and newly introduced datasets that are highlighted in the table above.
- Clone detection (BigCloneBench, POJ-104). A model is tasked with measure the semantic similarity between codes. Two existing datasets are included. One is for binary classification between code and the other is for retrieving semantically similar code given code as the query.
- Defect detection (Devign). A model is tasked with identifying whether a body of source code contains defects that may be used to attack software systems, such as resource leaks, use-after-free vulnerabilities and DoS attack. An existing dataset is included.
- Cloze test (CT-all, CT-max/min). A model is tasked with predicting the masked token from code, formulated as a multi-choice classification problem. The two datasets are newly created, one with candidates from the (filtered) vocabulary and the other with candidates among “max” and “min”.
- Code completion (PY150, GitHub Java Corpus). A model is tasked with predicting following tokens given a code context. Both token-level and line-level completion are covered. The token-level task is analogous to language modeling, and we include two influential datasets here. Line-level datasets are newly created to test a model’s ability to autocomplete a line.
- Code translation (CodeTrans). A model is tasked with translating the code in one programming language to the code in another one. A dataset between Java and C# is newly created.
- Code search (CodeSearchNet, AdvTest; CodeSearchNet, WebQueryTest). ). A model is given the task of measuring semantic similarity between text and code. In the retrieval scenario, a test set is newly created where function names and variables in test sets are replaced to test the generalization ability of a model. In text-code classification scenario, a test set where natural language queries come from Bing query log is created to test on real user queries.
- Code repair (Bugs2Fix). A model is tasked with trying to automatically refine the code, which could be buggy or complex. An existing dataset is included.
- Text-to-code generation (CONCODE). A model is given the task to generate code given natural language description. An existing dataset is included.
- Code summarization (CodeSearchNet). A model is given the task to generate natural language comments for a code. Existing datasets are included.
- Documentation translation (Microsoft Docs). A model is given the task to translate code documentation between human languages. A dataset, focusing on low-resource multilingual translation, is newly created.
Submission Instructions
Once you have built a model that meets your expectations on evaluation with the dev set, you can submit your test results to get official evaluation on the test set. To ensure the integrity of the official test results, we do not release the correct answers for test set to the public. To submit your model for official evaluation on the test set, follow the below steps:
- Generate your prediction output for the dev set.
- Run the official evaluation methodologies found in the task specific git repo and verify your systems are running as expected.
- Generate your prediction output for the test set.
- Submit the following information by emailing to
codexglue@microsoft.com.
Your email should include:
- Prediction results on test set. [Required]
- Prediction results on dev set. [Recommended]
- Individual/Team Name: Name of the individual or the team to appear in the leaderboard. [Required]
- Individual/Team Institution: Name of the institution of the individual or the team to appear in the leaderboard. [Optional]
- Model code: Training code for the model. [Recommended]
- Model information: Name of the model/technique to appear in the leaderboard. [Required]
- Paper Information: Name, Citation, URL of the paper if model is from a published work to appear in the leaderboard. [Optional]
To avoid "P-hacking" we discourage too many submissions from the same group in a short period of time.
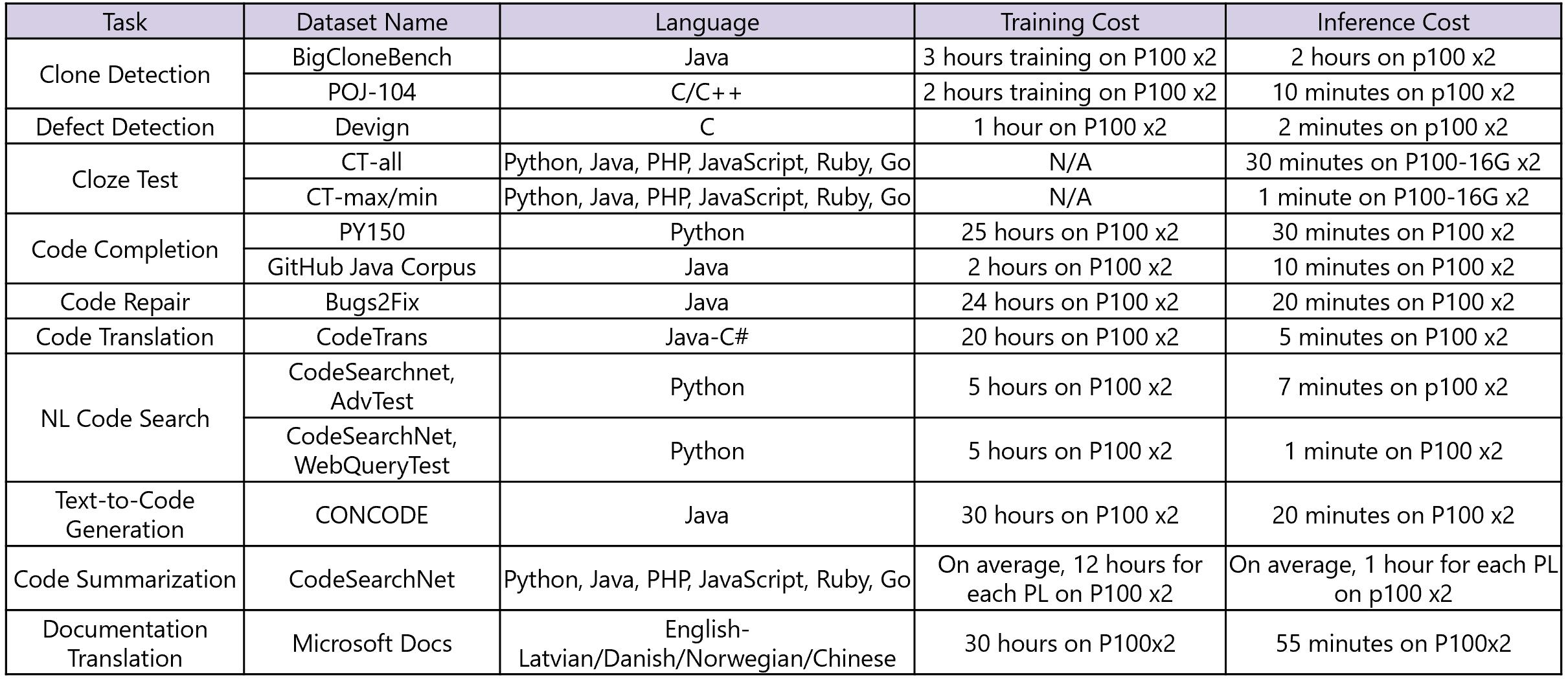
Training and Inference Time Cost
We calculate the training and inference time cost for each dataset with 2 P100 GPUs. Results are shared in the following table.
LICENSE
Our codes follow MIT License.
Our datasets follow Computational Use of Data Agreement (C-UDA) License.
Reference
If you use this code or CodeXGLUE, please consider citing us.
@article{DBLP:journals/corr/abs-2102-04664,
author = {Shuai Lu and
Daya Guo and
Shuo Ren and
Junjie Huang and
Alexey Svyatkovskiy and
Ambrosio Blanco and
Colin B. Clement and
Dawn Drain and
Daxin Jiang and
Duyu Tang and
Ge Li and
Lidong Zhou and
Linjun Shou and
Long Zhou and
Michele Tufano and
Ming Gong and
Ming Zhou and
Nan Duan and
Neel Sundaresan and
Shao Kun Deng and
Shengyu Fu and
Shujie Liu},
title = {CodeXGLUE: {A} Machine Learning Benchmark Dataset for Code Understanding
and Generation},
journal = {CoRR},
volume = {abs/2102.04664},
year = {2021}
}This research was conducted by Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Daya Guo, Duyu Tang, Junjie Huang, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, Shuai Lu, Shujie Liu, and Shuo Ren.