|
|
||
|---|---|---|
| AutoFormer | ||
| AutoFormerV2 | ||
| CDARTS | ||
| Cream | ||
| EfficientViT | ||
| MiniViT | ||
| TinyCLIP | ||
| TinyViT | ||
| iRPE | ||
| .gitignore | ||
| CODE_OF_CONDUCT.md | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
README.md
Neural Architecture Design and Search 
This is a collection of our NAS and Vision Transformer work
TinyCLIP (
@ICCV'23): TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
EfficientViT (
@CVPR'23): EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
TinyViT (
@ECCV'22): TinyViT: Fast Pretraining Distillation for Small Vision Transformers
MiniViT (
@CVPR'22): MiniViT: Compressing Vision Transformers with Weight Multiplexing
CDARTS (
@TPAMI'22): Cyclic Differentiable Architecture Search
AutoFormerV2 (
@NeurIPS'21): Searching the Search Space of Vision Transformer
iRPE (
@ICCV'21): Rethinking and Improving Relative Position Encoding for Vision Transformer
AutoFormer (
@ICCV'21): AutoFormer: Searching Transformers for Visual Recognition
Cream (
@NeurIPS'20): Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search
We also implemented our NAS algorithms on Microsoft NNI (Neural Network Intelligence).
News
- ☀️ Hiring research interns for next-generation model design, efficient large model inference: houwen.peng@microsoft.com
- 💥 Sep, 2023: Code for TinyCLIP is now released.
- 💥 Jul, 2023: TinyCLIP accepted to ICCV'23
- 💥 May, 2023: Code for EfficientViT is now released.
- 💥 Mar, 2023: EfficientViT accepted to CVPR'23
- 💥 Jul, 2022: Code for TinyViT is now released.
- 💥 Apr, 2022: Code for MiniViT is now released.
- 💥 Mar, 2022: MiniViT has been accepted by CVPR'22.
- 💥 Feb, 2022: Code for CDARTS is now released.
- 💥 Feb, 2022: CDARTS has been accepted by TPAMI'22.
- 💥 Jan, 2022: Code for AutoFormerV2 is now released.
- 💥 Oct, 2021: AutoFormerV2 has been accepted by NeurIPS'21, code will be released soon.
- 💥 Aug, 2021: Code for AutoFormer is now released.
- 💥 July, 2021: iRPE code (with CUDA Acceleration) is now released. Paper is here.
- 💥 July, 2021: iRPE has been accepted by ICCV'21.
- 💥 July, 2021: AutoFormer has been accepted by ICCV'21.
- 💥 July, 2021: AutoFormer is now available on arXiv.
- 💥 Oct, 2020: Code for Cream is now released.
- 💥 Oct, 2020: Cream was accepted to NeurIPS'20
Works
TinyCLIP
TinyCLIP is a novel cross-modal distillation method for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. This work unleashes the capacity of small CLIP models, fully leveraging large-scale models as well as pre-training data and striking the best trade-off between speed and accuracy.

EfficientViT
EfficientViT is a family of high-speed vision transformers. It is built with a new memory efficient building block with a sandwich layout, and an efficient cascaded group attention operation which mitigates attention computation redundancy.
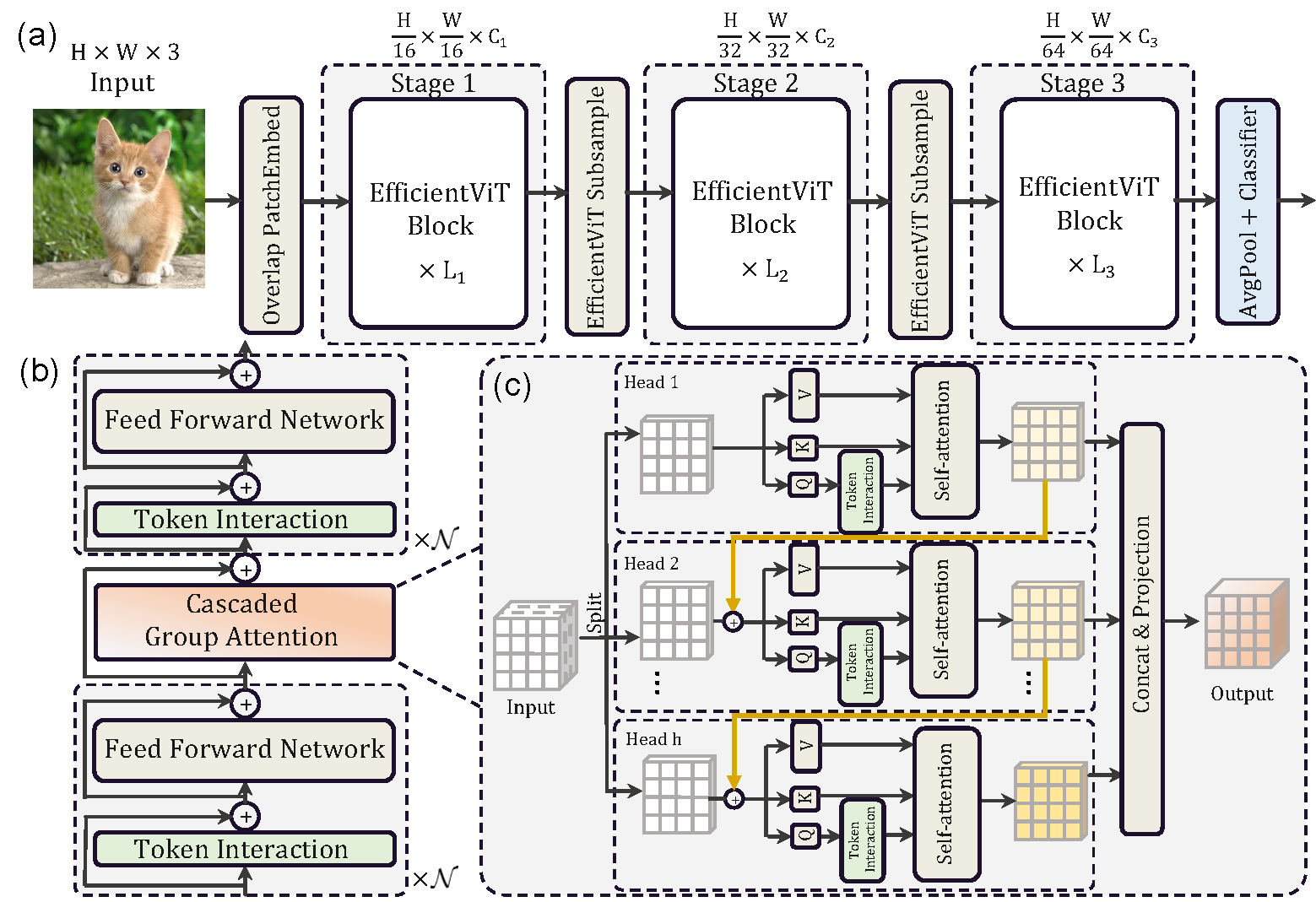
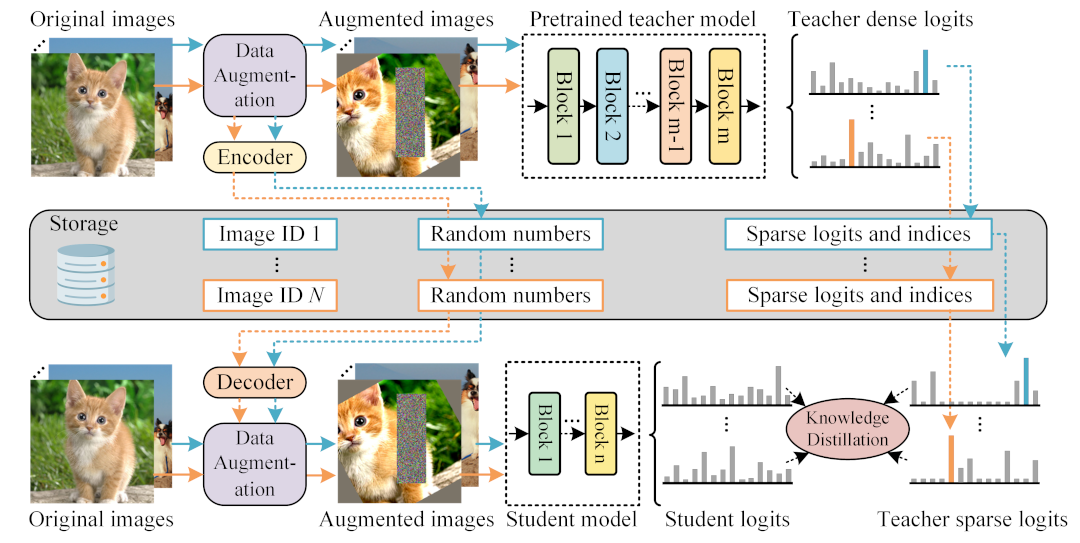
TinyViT
TinyViT is a new family of tiny and efficient vision transformers pretrained on large-scale datasets with our proposed fast distillation framework. The central idea is to transfer knowledge from large pretrained models to small ones. The logits of large teacher models are sparsified and stored in disk in advance to save the memory cost and computation overheads.
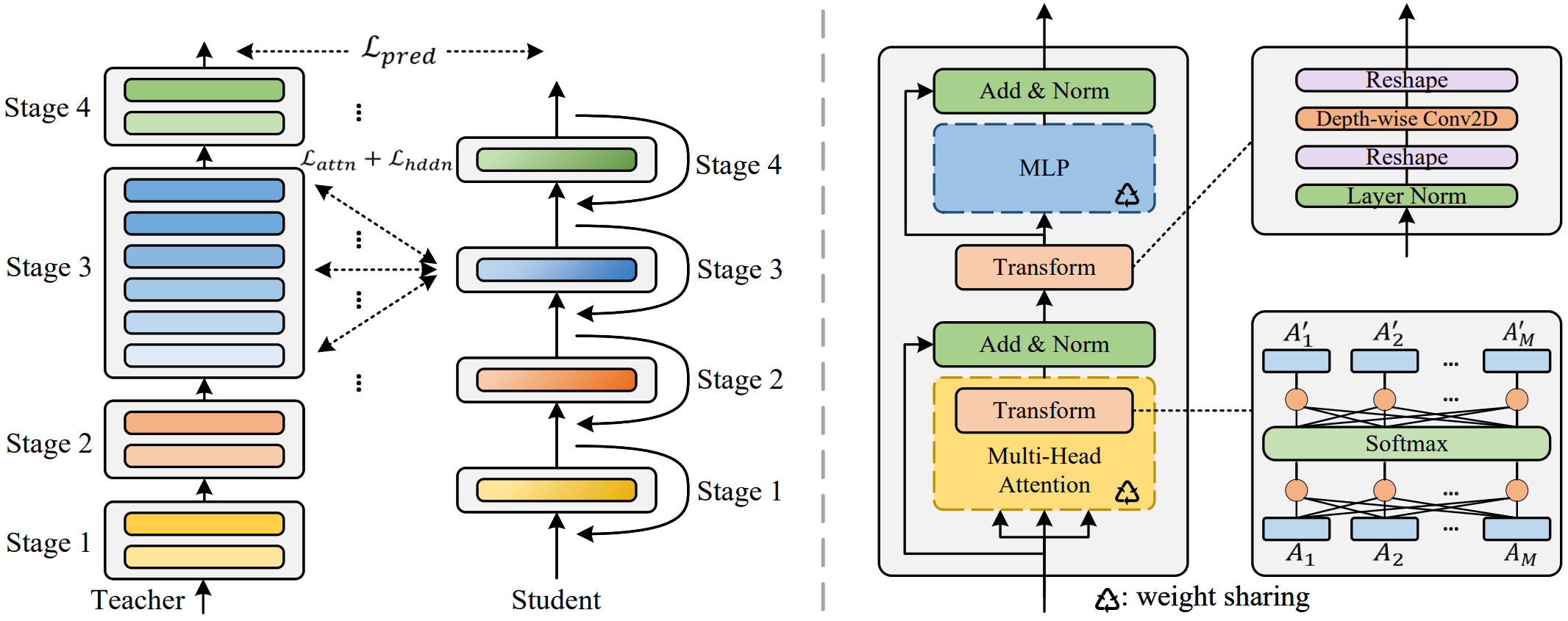
MiniViT
MiniViT is a new compression framework that achieves parameter reduction in vision transformers while retaining the same performance. The central idea of MiniViT is to multiplex the weights of consecutive transformer blocks. Specifically, we make the weights shared across layers, while imposing a transformation on the weights to increase diversity. Weight distillation over self-attention is also applied to transfer knowledge from large-scale ViT models to weight-multiplexed compact models.
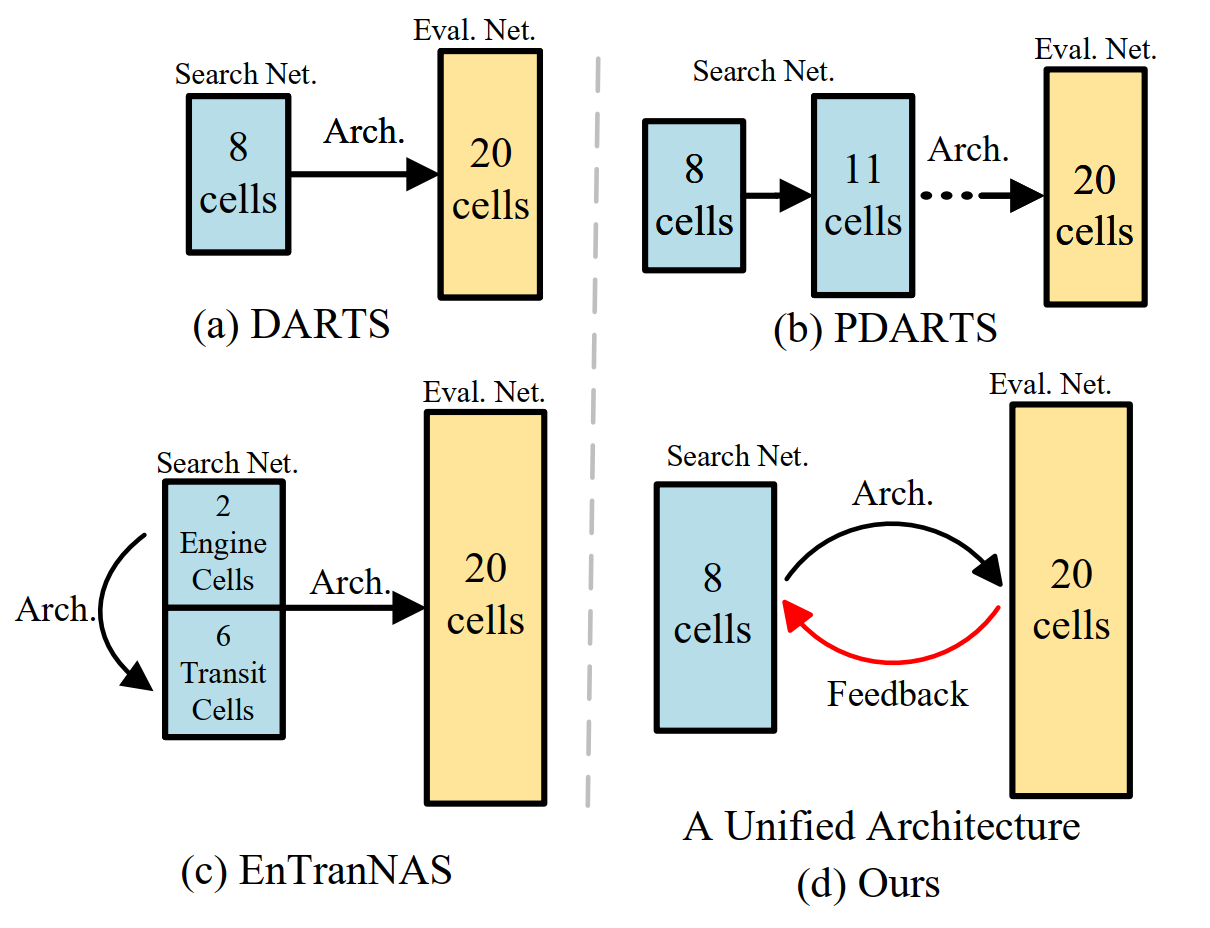
CDARTS
In this work, we propose new joint optimization objectives and a novel Cyclic Differentiable ARchiTecture Search framework, dubbed CDARTS. Considering the structure difference, CDARTS builds a cyclic feedback mechanism between the search and evaluation networks with introspective distillation.
AutoFormerV2
In this work, instead of searching the architecture in a predefined search space, with the help of AutoFormer, we proposed to search the search space to automatically find a great search space first. After that we search the architectures in the searched space. In addition, we provide insightful observations and guidelines for general vision transformer design.

AutoFormer
AutoFormer is new one-shot architecture search framework dedicated to vision transformer search. It entangles the weights of different vision transformer blocks in the same layers during supernet training. Benefiting from the strategy, the trained supernet allows thousands of subnets to be very well-trained. Specifically, the performance of these subnets with weights inherited from the supernet is comparable to those retrained from scratch.
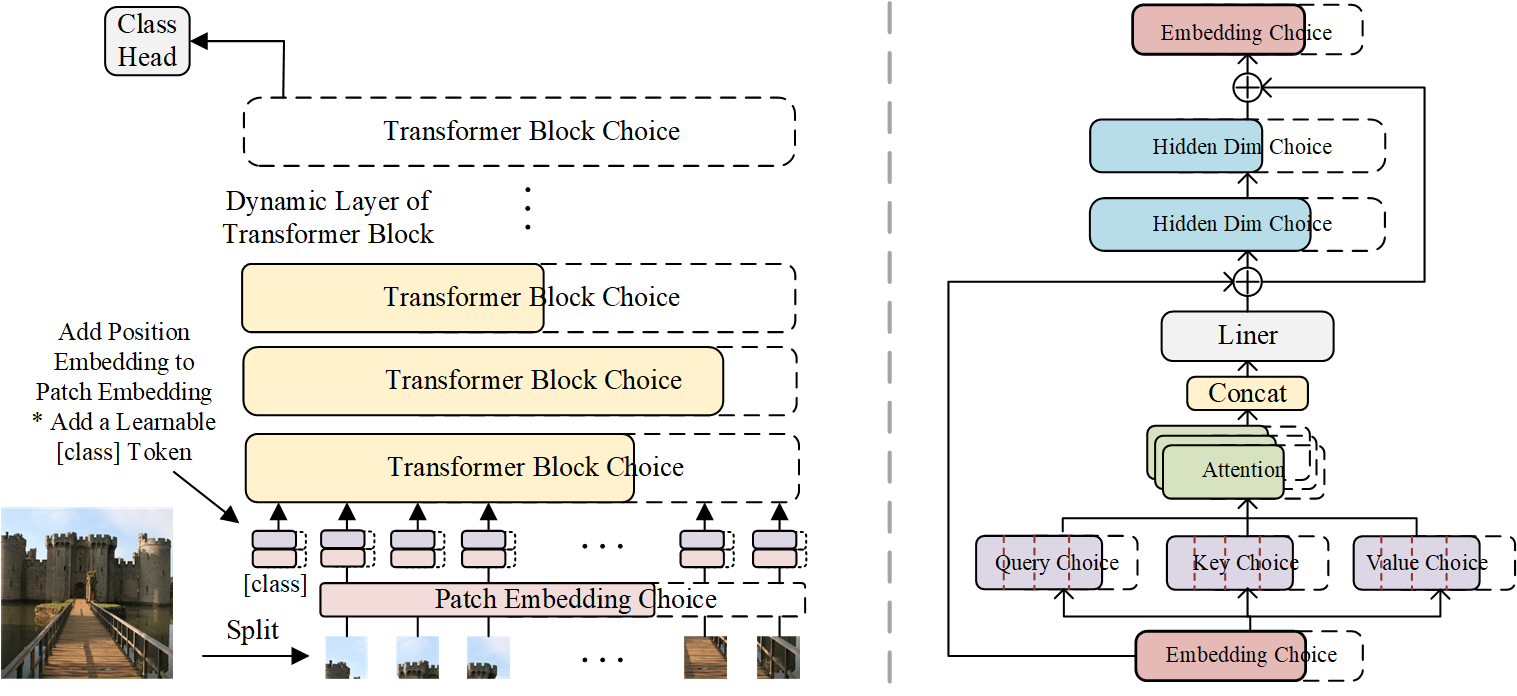
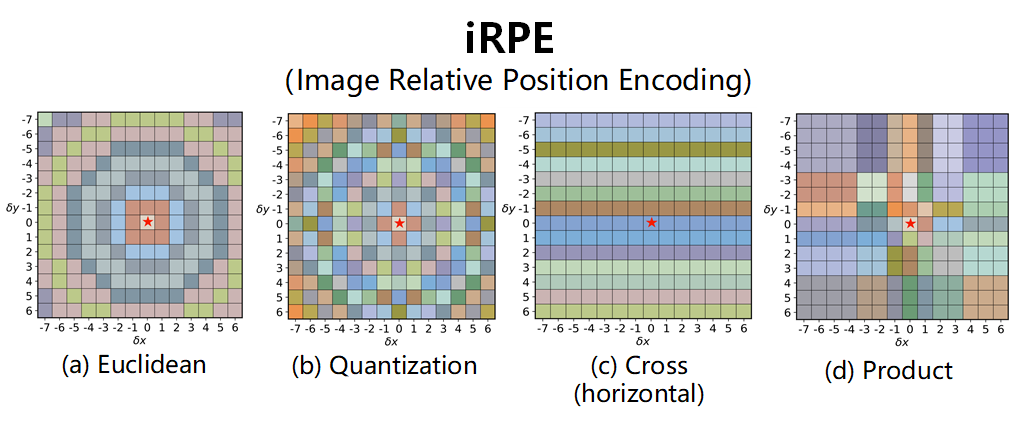
iRPE
Image RPE (iRPE for short) methods are new relative position encoding methods dedicated to 2D images, considering directional relative distance modeling as well as the interactions between queries and relative position embeddings in self-attention mechanism. The proposed iRPE methods are simple and lightweight, being easily plugged into transformer blocks. Experiments demonstrate that solely due to the proposed encoding methods, DeiT and DETR obtain up to 1.5% (top-1 Acc) and 1.3% (mAP) stable improvements over their original versions on ImageNet and COCO respectively, without tuning any extra hyperparamters such as learning rate and weight decay. Our ablation and analysis also yield interesting findings, some of which run counter to previous understanding.
Cream
[Paper] [Models-Google Drive][Models-Baidu Disk (password: wqw6)] [Slides] [BibTex]
In this work, we present a simple yet effective architecture distillation method. The central idea is that subnetworks can learn collaboratively and teach each other throughout the training process, aiming to boost the convergence of individual models. We introduce the concept of prioritized path, which refers to the architecture candidates exhibiting superior performance during training. Distilling knowledge from the prioritized paths is able to boost the training of subnetworks. Since the prioritized paths are changed on the fly depending on their performance and complexity, the final obtained paths are the cream of the crop.

Bibtex
@InProceedings{tinyclip,
title = {TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance},
author = {Wu, Kan and Peng, Houwen and Zhou, Zhenghong and Xiao, Bin and Liu, Mengchen and Yuan, Lu and Xuan, Hong and Valenzuela, Michael and Chen, Xi (Stephen) and Wang, Xinggang and Chao, Hongyang and Hu, Han},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {21970-21980}
}
@InProceedings{liu2023efficientvit,
title = {EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention},
author = {Liu, Xinyu and Peng, Houwen and Zheng, Ningxin and Yang, Yuqing and Hu, Han and Yuan, Yixuan},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023},
}
@InProceedings{tiny_vit,
title={TinyViT: Fast Pretraining Distillation for Small Vision Transformers},
author={Wu, Kan and Zhang, Jinnian and Peng, Houwen and Liu, Mengchen and Xiao, Bin and Fu, Jianlong and Yuan, Lu},
booktitle={European conference on computer vision (ECCV)},
year={2022}
}
@InProceedings{MiniViT,
title = {MiniViT: Compressing Vision Transformers With Weight Multiplexing},
author = {Zhang, Jinnian and Peng, Houwen and Wu, Kan and Liu, Mengchen and Xiao, Bin and Fu, Jianlong and Yuan, Lu},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {12145-12154}
}
@article{CDARTS,
title={Cyclic Differentiable Architecture Search},
author={Yu, Hongyuan and Peng, Houwen and Huang, Yan and Fu, Jianlong and Du, Hao and Wang, Liang and Ling, Haibin},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2022}
}
@article{S3,
title={Searching the Search Space of Vision Transformer},
author={Minghao, Chen and Kan, Wu and Bolin, Ni and Houwen, Peng and Bei, Liu and Jianlong, Fu and Hongyang, Chao and Haibin, Ling},
booktitle={Conference and Workshop on Neural Information Processing Systems (NeurIPS)},
year={2021}
}
@InProceedings{iRPE,
title = {Rethinking and Improving Relative Position Encoding for Vision Transformer},
author = {Wu, Kan and Peng, Houwen and Chen, Minghao and Fu, Jianlong and Chao, Hongyang},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {10033-10041}
}
@InProceedings{AutoFormer,
title = {AutoFormer: Searching Transformers for Visual Recognition},
author = {Chen, Minghao and Peng, Houwen and Fu, Jianlong and Ling, Haibin},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {12270-12280}
}
@article{Cream,
title={Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search},
author={Peng, Houwen and Du, Hao and Yu, Hongyuan and Li, Qi and Liao, Jing and Fu, Jianlong},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
License
License under an MIT license.