This pr is auto merged as it contains a mandatory file and is opened for more than 10 days. |
||
|---|---|---|
| figure | ||
| model | ||
| .gitignore | ||
| CODE_OF_CONDUCT.md | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
| dataset.py | ||
| l2w.py | ||
| run_classifiy.py | ||
| train.py | ||
README.md
Multi-source Weak Social Supervision for Fake News Detection
Authors: Guoqing Zheng (zheng@microsoft.com), Yichuan Li (yli29@wpi.edu), Kai Shu (kshu@iit.edu)
This repository contains code for fake news detection with Multi-source Weak Social Supervision (MWSS), published at ECML-PKDD 2020 at: Early Detection of Fake News with Multi-source Weak Social Supervision
Model Structure
The structure of the MWSS model:
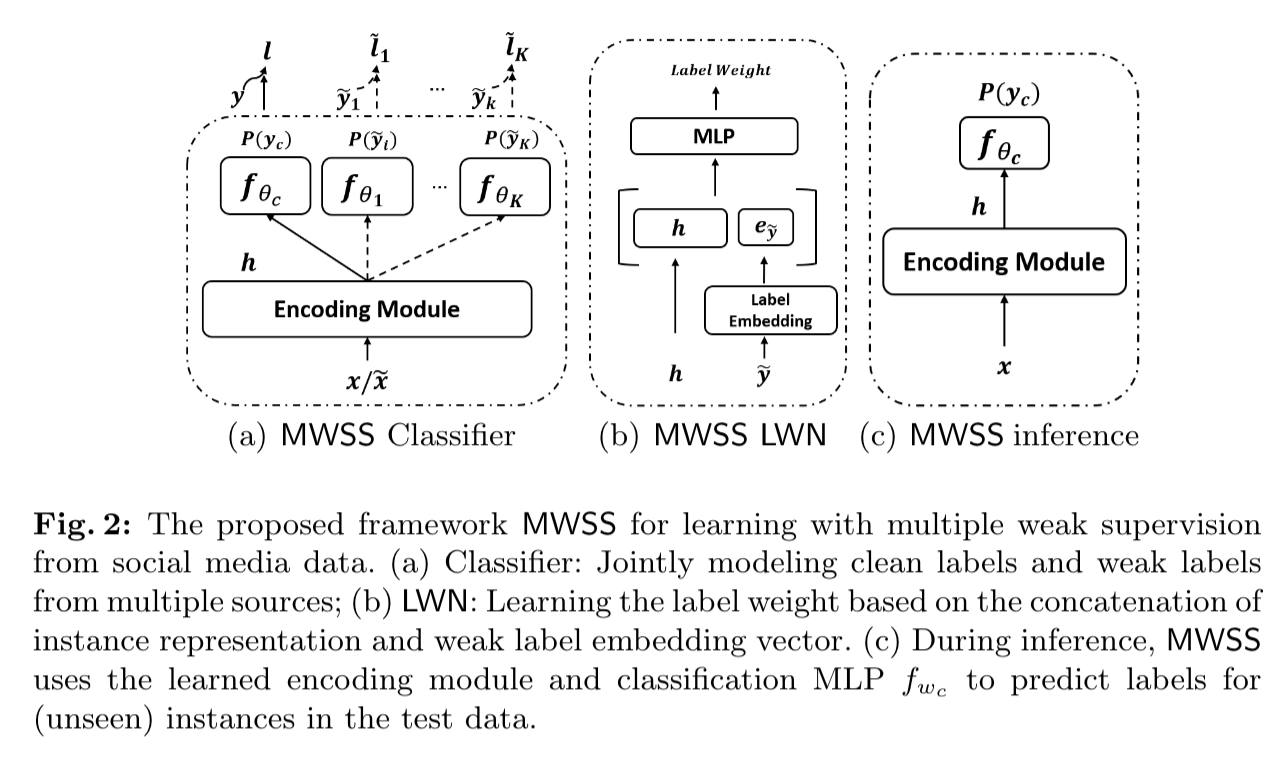
The training process of MWSS model:

Requirements
torch=1.x
transformers=2.4.0
Prepare dataset
The weak labeled dataset is in the format of:
| news | Weak_Label_1 | Weak_Label_2 | ... | Weak_Label_K |
|---|---|---|---|---|
| Hello this is MWSS readme | 1 | 0 | ... | 1 |
The clean labeled dataset is in the format of:
| News | label |
|---|---|
| Hello this is MWSS readme | 1 |
Usage
a. train_type is {0:"clean", 1:"noise", 2:"clean+noise"}
b. "--meta_learn" is to set the instance weight for each noise samples.
c. "--multi_head" is to set the weak source count, if you have three different weak source, you should set it to 3.
d. "--group_opt": specific optimizer for group weight. You can choose Adam and SGD.
e. "--gold_ratio": Float gold ratio for the training data. Default is 0 which will use [0.02, 0.04, 0.06, 0.08, 0.1] all the gold ratio. For gold ratio 0.02, set it as "--gold_ratio 0.02"
f. "--weak_type": type of weak label.
1. "none" is the default setting for our paper, where each weak labeled instance will have the number of weak label sources for the model training.
2. "flat" will copy the weak labeled instance for number of weak labeling sources, and ignore the difference of weak sources.
3. "most_vote",
4. "0" for weak_label_1, "1" for weak_label_2 and etc.
If you choose other variables except "none", you should change the multi_head to 2 (one for the clean dataset and another one for the weak labeled data).
-
Finetune on RoBERTa Group Weight
python3 run_classifiy.py
--model_name_or_path roberta-base
--evaluate_during_training --do_train --do_eval
--num_train_epochs 15
--output_dir ./output/
--logging_steps 100
--max_seq_length 256
--train_type 0
--per_gpu_eval_batch_size 16
--g_train_batch_size 5
--s_train_batch_size 5
--clf_model "robert"
--meta_learn
--weak_type "none"
--multi_head 3
--use_group_net
--group_opt "adam"
--train_path "./data/political/weak"
--eval_path "./data/political/test.csv"
--fp16
--fp16_opt_level O1
--learning_rate 1e-4
--group_adam_epsilon 1e-9
--group_lr 1e-3
--gold_ratio 0.04
--id "ParameterGroup1"
The log information will stored in
~/output
-
CNN Baseline Model
python run_classifiy.py
--model_name_or_path distilbert-base-uncased
--evaluate_during_training --do_train --do_eval --do_lower_case
--num_train_epochs 30
--output_dir ./output/
--logging_steps 10
--max_seq_length 256
--train_type 0
--weak_type most_vote
--per_gpu_train_batch_size 256
--per_gpu_eval_batch_size 256
--learning_rate 1e-3
--clf_model cnn -
CNN Instance Weight Model with multi classification heads
python run_classifiy.py
--model_name_or_path distilbert-base-uncased
--evaluate_during_training --do_train --do_eval --do_lower_case
--num_train_epochs 256
--output_dir ./output/
--logging_steps 10
--max_seq_length 256
--train_type 0
--per_gpu_eval_batch_size 256
--g_train_batch_size 256
--s_train_batch_size 256
--learning_rate 1e-3
--clf_model cnn
--meta_learn
--weak_type "none" -
CNN group weight
python run_classifiy.py
--model_name_or_path distilbert-base-uncased
--evaluate_during_training --do_train --do_eval --do_lower_case
--num_train_epochs 256
--output_dir ./output/
--logging_steps 10
--max_seq_length 256
--train_type 0
--per_gpu_eval_batch_size 256
--g_train_batch_size 256
--s_train_batch_size 256
--learning_rate 1e-3
--clf_model cnn
--meta_learn
--weak_type "none"
--multi_head 3
--use_group_weight
--group_opt "SGD"
--group_momentum 0.9
--group_lr 1e-5 -
RoBERTa Baseline Model
python run_classifiy.py
--model_name_or_path roberta-base
--evaluate_during_training
--do_train --do_eval --do_lower_case
--num_train_epochs 30
--output_dir ./output/
--logging_steps 10
--max_seq_length 256
--train_type 0
--weak_type most_vote
--per_gpu_train_batch_size 16
--per_gpu_eval_batch_size 16
--learning_rate 5e-5
--clf_model robert -
RoBERTa Instance Weight with Multi Head Classification
python run_classifiy.py
--model_name_or_path roberta-base
--evaluate_during_training --do_train --do_eval --do_lower_case
--num_train_epochs 256
--output_dir ./output/
--logging_steps 10
--max_seq_length 256
--weak_type most_vote
--per_gpu_eval_batch_size 16
--g_train_batch_size 16
--s_train_batch_size 16
--learning_rate 5e-5
--clf_model robert
--meta_learn
--weak_type "none"
--multi_head 3 \ -
RoBERTa Group Weight
python run_classifiy.py
--model_name_or_path roberta-base
--evaluate_during_training --do_train --do_eval --do_lower_case
--num_train_epochs 256
--output_dir ./output/
--logging_steps 10
--max_seq_length 256
--weak_type most_vote
--per_gpu_eval_batch_size 16
--g_train_batch_size 16
--s_train_batch_size 16
--learning_rate 5e-5
--clf_model robert
--meta_learn
--weak_type "none"
--multi_head 3
--use_group_weight
--group_opt "SGD"
--group_momentum 0.9
--group_lr 1e-5 -
Finetune on RoBERTa Group Weight
python3 run_classifiy.py
--model_name_or_path roberta-base
--evaluate_during_training --do_train --do_eval
--num_train_epochs 15
--output_dir ./output/
--logging_steps 100
--max_seq_length 256
--train_type 0
--per_gpu_eval_batch_size 16
--g_train_batch_size 1
--s_train_batch_size 1
--clf_model "robert"
--meta_learn
--weak_type "none"
--multi_head 3
--use_group_net
--group_opt "adam"
--train_path "./data/political/weak"
--eval_path "./data/political/test.csv"
--fp16
--fp16_opt_level O1
--learning_rate "1e-4,5e-4,1e-5,5e-5"
--group_adam_epsilon "1e-9, 1e-8, 5e-8"
--group_lr "1e-3,1e-4,3e-4,5e-4,1e-5,5e-5"
--gold_ratio 0.04
The log information will stored in
~/ray_results/GoldRatio_{}_GroupNet
You can run the following command to extract the best result which is sorted by the average of accuracy and f1.
export LOG_FILE=~/ray_results/GoldRatio_{}_GroupNet
python read_json.py --file_name $LOG_FILE --save_dir ./output
In the meantime, you can visualize the log text by tensorboard
tensorboard --logdir $LOG_FILE