# Overview
Enterprise organizations use multitude of line of business (LOB) applications that requires information flow between their LOB applications. With Dynamics 365 for Finance and Operations (D365FO) hosted on Azure, there is a need to move data in/out of D365FO and on-premises LOB applications. Recurring Integrations Scheduler aka QuartzAX is one of the reference implementations that enables such integrations. We see this tool to be a good implementation accelerator for use during the implementation phase of the project for data migration, ad hoc file integration needs and to be used as a proof of concept validator among others.
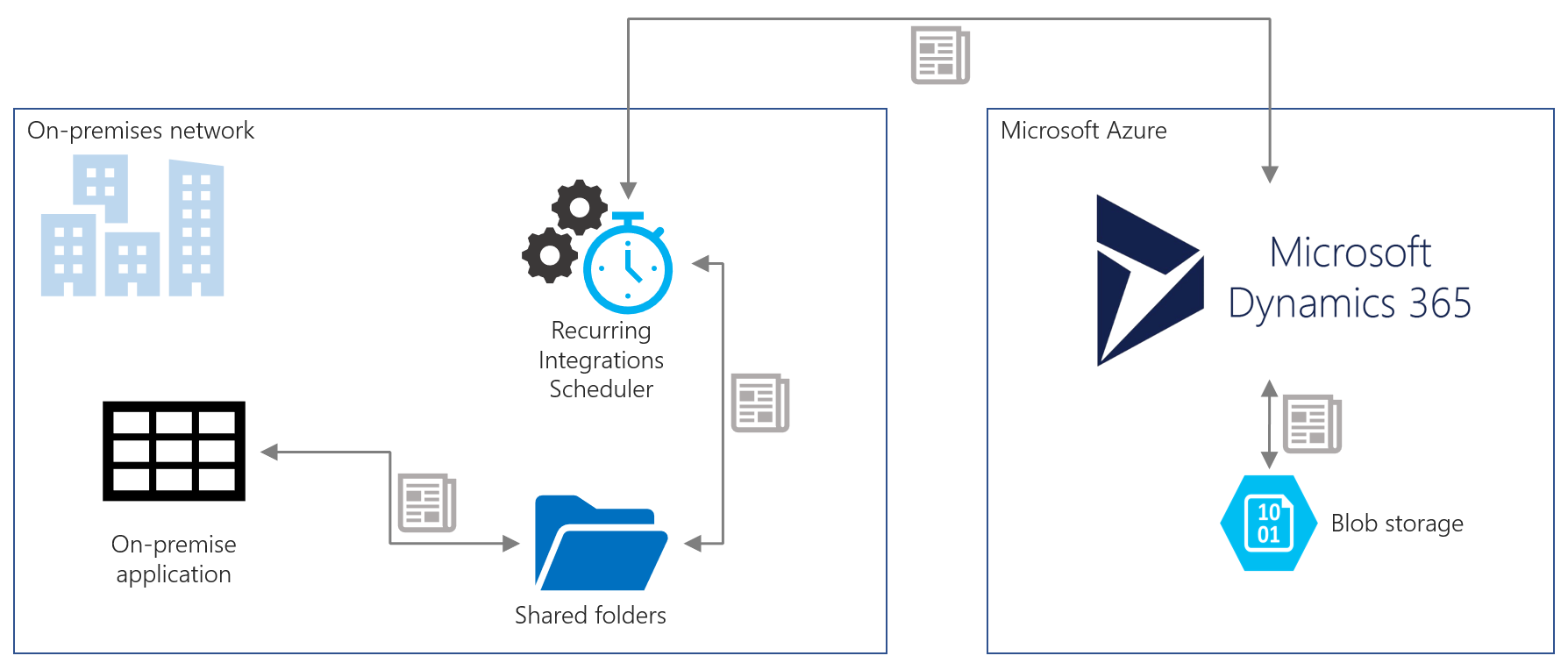
Data flow between these LOB applications can occur at a predefined frequency on periodic basis.
RIS is a solution that transports files/messages between on-premises folders and D365FO. It calls methods exposed by D365FO to import or export files and data packages. It can also monitor status of D365FO internal processing of imported data. Based on this status it can move input files to “status” folders.
RIS is only one of the solutions that fulfill that purpose. Other like Logic Apps, Azure Functions or BizTalk HTTP adapter offer much richer, enterprise ready capabilities like high availability, scalability and monitoring. RIS advantage is its small footprint and the fact it is ready to use immediately after installation.
| Pros | Cons |
|---|---|
| Install on any Windows machine using a simple installer | Enterprise ready features needs to be implemented by customer (Alerts, Log Analysis, High Availability, Disaster Recovery, Secrets Management, Dashboards integration, Management audit logs, Exception handling) |
| Useful for Ad-hoc scenarios during project implementation, data migration, POC and testing | Community supported (GitHub/Yammer) |
| No additional Azure cost | On-premises machine management & maintenance by customer |
| Writes to local on-premises disk folders directly | Not auto scalable |
Solution components
Recurring Integrations Scheduler is a job scheduling application that is based on Quartz.NET solution. Quartz.NET is a C# and .NET based job scheduling system. Job scheduling is often referred to as running batch jobs or batch processing. These batch jobs typically run in the background and do not involve user interaction.
Recurring Integrations Scheduler consists of two components:
-
Recurring Integrations Scheduler service: Windows service that can be used in integration scenarios where you need to send files to D365FO or download files exported from D365FO to blob storage.
-
Recurring Integrations Scheduler application: .NET application that can be used as a configuration front-end for Recurring Integrations Scheduler service or as a completely independent, interactive application used to upload or download files to and from D365FO without Recurring Integrations Scheduler Service.
Data Entities
A data entity is an abstraction from the physical implementation of database tables. For example, in normalized tables, a lot of the data for each customer might be stored in a customer table, and then the rest might be spread across a small set of related tables. In this case, the data entity for the customer concept appears as one denormalized view, in which each row contains all the data from the customer table and its related tables.
A data entity encapsulates a business concept into a format that makes development and integration easier. The abstracted nature of a data entity can simplify application development and customization. Later, the abstraction also insulates application code from the inevitable churn of the physical tables between versions.
Data entity provides conceptual abstraction and encapsulation (denormalized view) of underlying table schemas to represent key data concepts and functionalities.

Installation
Prerequisites and requirements
Recurring Integrations Scheduler requires Windows machine with .Net Framework 4.6.1 installed. To connect to D365FO instance it requires registration of an application in Azure Active Directory. It is described in detail in Registering an application in Azure Active Directory section.
Installation of Recurring Integrations Scheduler service and app
Download latest release from releases section or compile your own installation package by following instructions found in Setup folder.
Execute installer package.
System will prompt for the path where you want it to be installed.

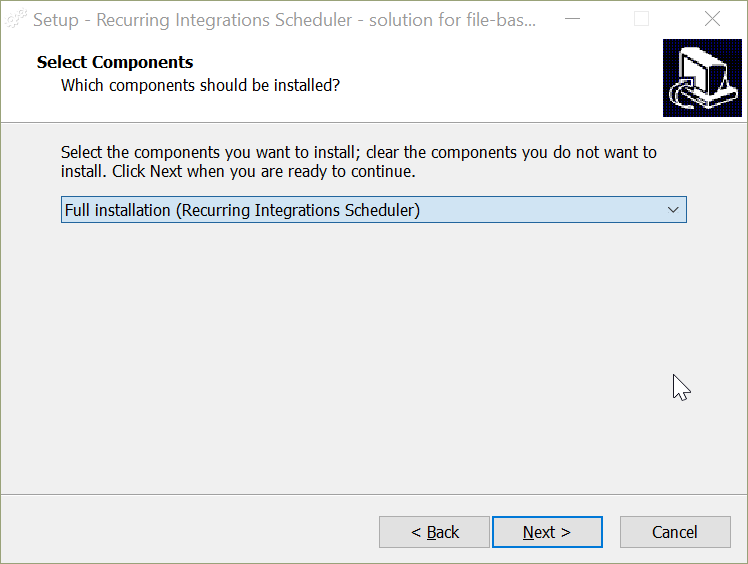
Recurring Integrations Scheduler can be installed in three ways – Full Installation (App and Service), App only, Service only. Recurring Integrations Scheduler App can be installed by itself to manage Recurring Integrations Scheduler Service running on a different machine. It is possible to deploy Service on one machine and manage it with App on different machine.
For the initial installation, choose the Full Installation and complete it.
If you chose to install the service or both components, then the new Windows service will be created and automatically started. Its startup type is set to Automatic and it is running as Local System.
Note! You might need to change this account if the service needs to access some shared network folders.**
Recurring Integrations Scheduler App shortcut can be found in Start menu. It requires Administrative rights to be able to save schedule file in its folder (when installed in Program Files folder).
Registering an application in Azure Active Directory
D365FO implements Azure Active Directory based authentication for Web Services. Azure Active Directory Service provides identity as a service with support for industry-standard protocols. D365FO outsources authentication to Azure AD and any integration application like Recurring Integrations Scheduler must be registered in directory prior to use.
To integrate an application like Recurring Integrations Scheduler with Azure Active Directory (Azure AD) to provide secure sign-in and authorization for services, we need to register the details of this application with Azure AD through Azure Management portal. There are two versions of Azure Management Portal: https://portal.azure.com and https://manage.windowsazure.com. It is possible to register the application using any of them. Register an application by following the instructions published here Recurring Integrations in Dynamics 365 for Operations.
As part of the setup for registering an application in Azure AD, we will provide and obtain the fields that are required. The most important fields are listed below. We recommend registering web api application type and define secret key to be able to use the service-to-service authentication flow.
| Field | Description | Suggested value |
|---|---|---|
| Application name | Friendly name of the application | |
| Redirect URI | In the case of a web API or web application, the Reply URL is the location to which Azure AD will send the authentication response, including a token if authentication was successful. In the case of a native application, the Redirect URI is a unique identifier to which Azure AD will redirect the user-agent in an OAuth 2.0 request | https://localhost:44307 or any other value. |
| Client ID | The ID for an application, which is generated by Azure AD when the application is registered. When requesting an authorization code or token, the client ID and secret key are sent to Azure AD during authentication. | Generated by Azure AD. Please save this value in safe place as it will be needed later during configuration of Recurring Integrations Scheduler. |
| Secret Key | The key that is sent along with a client ID when authenticating to Azure AD to call a web API. | Generated by Azure AD. Please save this value in safe place as it will be needed later during configuration of Recurring Integrations Scheduler. |
It is recommended to create a new application registration for every instance of D365FO that Recurring Integrations Scheduler will connect to. For example, with the base subscription offer, we get three environments Sandbox: Dev and Test, Sandbox: User Acceptance Test and Production. There should be separate applications registered in Azure Management portal for each of these instances.
Granting access for AAD application in D365FO
The Azure AD Application(s) created in the previous step need(s) to be granted access to the specific instance of D365FO. This is required only if you are going to use service to service authentication type using secret key instead of user impersonation.
Configuration is done by setting up the Client ID and user security context that this application runs against. Navigate to System Administration -> Setup -> Azure Active Directory applications. Enter the Client ID, Name of the application (can be different than the one specified in AAD setup) and User ID that this application is running under.
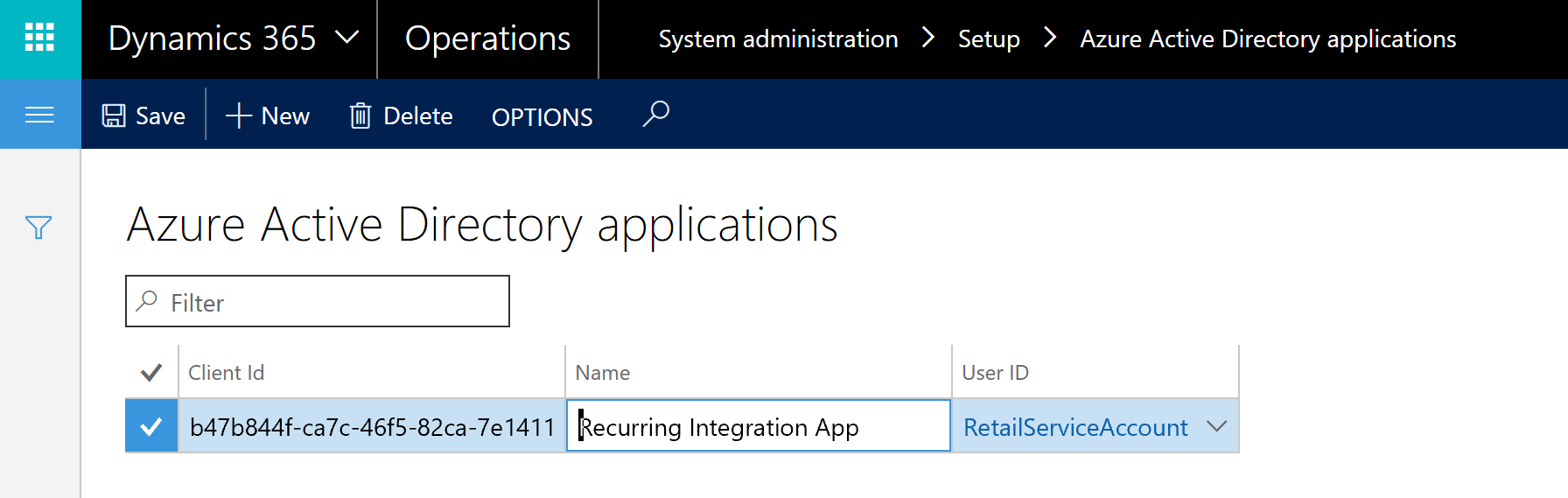
Note! User Id RetailServiceAccount used above is only an example.
Configuration of common parameters
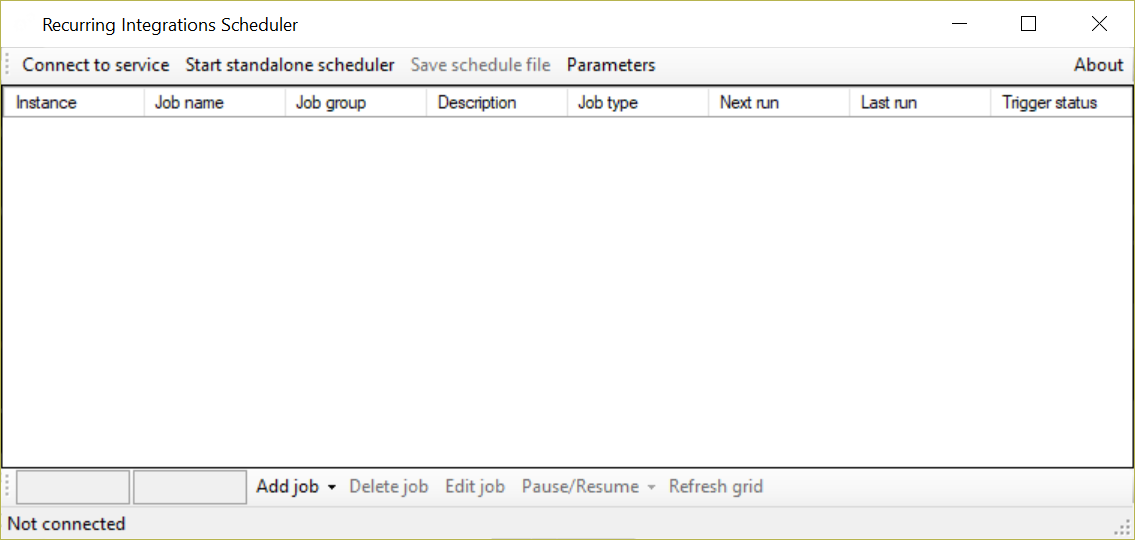
Recurring Integrations Scheduler App can be run with two modes – connected to an existing Scheduler service or as a standalone scheduler.
Choose “Connect to service” and connect to scheduler service that was installed. Do not adjust scheduler name. It can be changed, but this is out of scope for this guide.
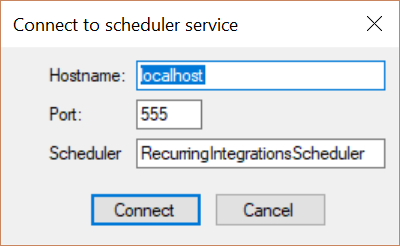
Specify the machine name where Recurring Integrations Scheduler service is running in the Hostname field. If it is local machine, leave the default “localhost”. Service is running on port 555 by default. Click on Connect.
Click on Parameters to configure Azure Active Directory App details and other parameters required by job configuration. After the initial installation, you will find demo parameters here set as an example.
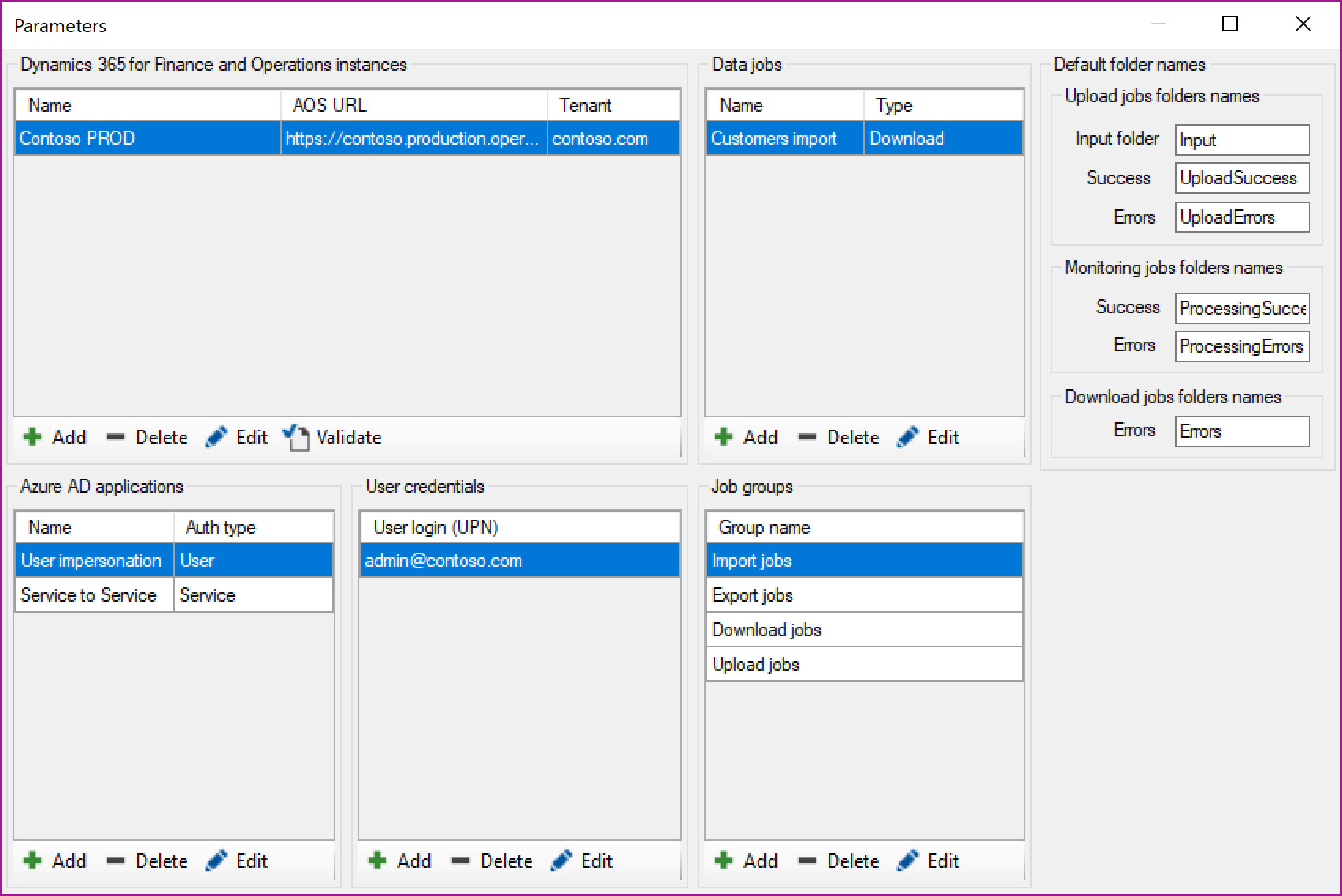
D365FO Instances
Instances grid provides option configure the D365FO instance that Recurring Integrations Scheduler is going to connect for integration. It is possible to configure more than one instance of D365FO instance with one Recurring Integrations Scheduler.
Click on + (plus) to add new one or edit to modify the default one that is available.

-
Friendly Name: Provide a name for the instance of D365FO instance that application is connecting to
-
AOS URL: URL for the AOS
-
Authentication endpoint: https://login.microsoftonline.com
-
Tenant Id: Tenant Id for your instance. This is the tenant that was used to deploy the D365FO instance. It can be domain name or GUID
Azure Active Directory applications
Recurring Integrations Scheduler supports both Native and Service to Service (Web API application types) in Azure AD. User impersonation and service to service authentication using secret keys.

Click on + to add or Edit to edit the sample Service to Service application details and provide the information for following fields

-
Friendly name: Name of the application registered in the Azure Active Directory for easy cross-reference
-
Client Id: Client ID generated during app registration process in the Azure Active Directory
-
Client secret: Secret key generated during app registration process in the Azure Active Directory
-
Authentication type: Service
For Authentication type - User you do not need to specify secret key in app details form, but it requires user credentials setup in next section of Parameters form

Validation of parameters and connectivity
Validation of settings provided above, and connectivity check can be done by using the Validate button under Instances grid of Parameters form of Recurring Integrations Scheduler App.


Choose the authentication mechanism and click on validate. “OK” is displayed in the results window if connectivity and all the settings are valid. Otherwise you should see error message that will help you identify the issue.
Job Groups
This section of settings form is used to define job groups and provide meaningful grouping for them.
Data Jobs
This section in Parameters form is used to defined various export and import recurring data jobs that Recurring Integrations Scheduler will interact with.
This Docs article talks about how to setup data projects and export or import recurring data jobs. Please follow the article to setup data jobs in D365FO instance.
Note! Recurring data jobs are not the recommended way of integrating with D365FO anymore. In platform update 5 a new method was introduced. This new method does not require any batch jobs running in D365FO (unlike recurring data jobs) and its setup is simplified. This new method is supported by Recurring Integrations Scheduler and is described later in this guide.**
Click on (+) to add or edit to modify the default one as applicable.
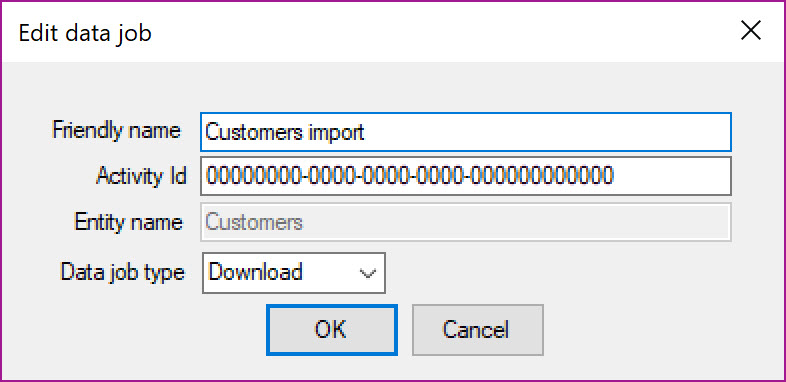
The following fields need to be specified here for various recurring data jobs defined in the D365FO instance
-
Friendly name: Name of the Recurring Data job
-
Activity Id: ID field in the Manage Scheduled Data Jobs form of D365FO instance specified without curly braces. For example, ID in Manage Schedule Data jobs form has a value {124AFE11-DFA4-4B90-875B-ABF086BDDF78}, it is provided as 124AFE11-DFA4-4B90-875B-ABF086BDDF78
-
Data job type Specify download as data job type. Download indicates that data will be downloaded from D365FO instance and Upload indicates data will be uploaded to D365FO instance
-
Entity name If data job type is Upload then it is required to specify target data entity name (it’s EN-US label)
Folder names
This section of Parameters forms specifies default folder names used by scheduler jobs to move message files based on their status.
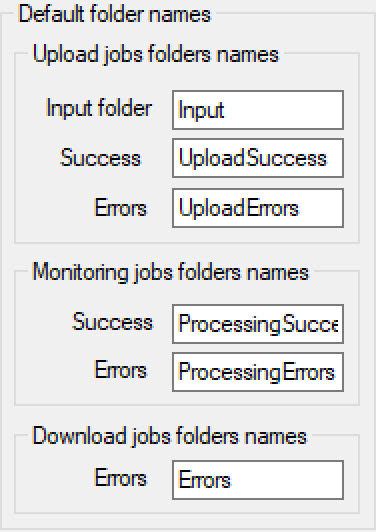
Configuration of scheduler jobs
There are six job types in the solution: export, import, execution monitor, download, upload and processing monitor. The types: export, import, execution monitor, support the new package API methods introduced in platform update 5. Those are recommended for integration scenarios. The types: download, upload and processing monitor, support recurring data jobs present in D365FO since its first release.
Export job

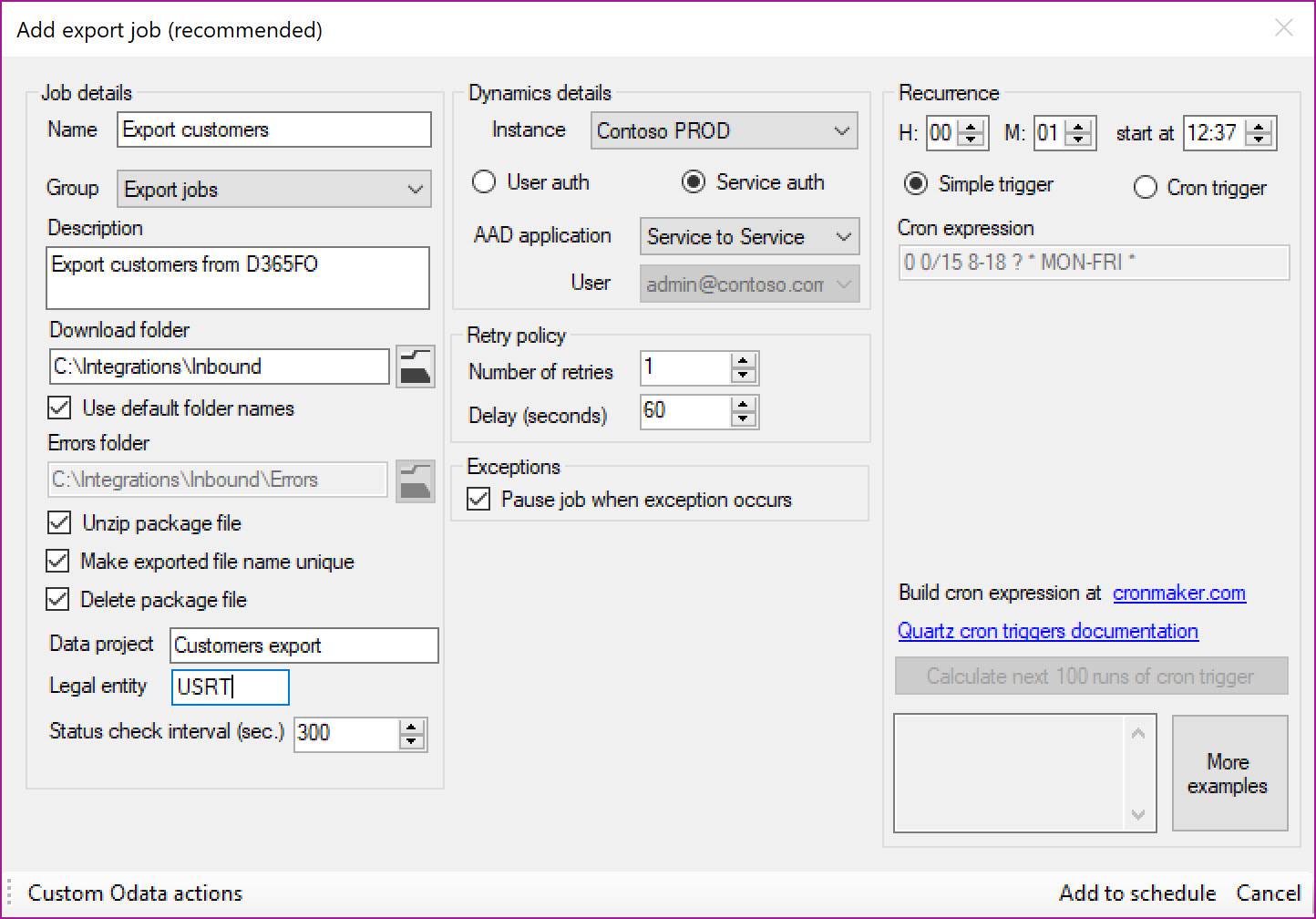
-
Name: Provide a meaningful name for the job
-
Group: Grouping defined in the parameters form for categorization
-
Description: An optional description
-
Download folder: Specify the path where data package needs to be saved after download from D365FO instance. Use default folder names uses the folder names specified in the Parameters form for subfolder paths
-
Errors folder: Error file will be written to this folder if there are any errors in integration
-
Unzip package file: Choose this option if you want data package to be automatically extracted
-
Make exported file name unique: Scheduler will add the timestamp to the exported file name if this option is chosen
-
Delete package file: The package file is deleted post extraction if this option is chosen
-
Data project: Existing data project in D365FO that specifies data entity, mapping, file format, filters and if data project exports differential data changes or full data set
-
Legal entity: Legal entity from which data should be exported
-
Status check interval (sec.): Interval in which job will query D365FO for status of export task (see GetExecutionSummaryStatus request on diagram above). Default value is 5 minutes (300 seconds)
-
Instance: Specify the D365FO Instance to connect
-
User auth or Service auth: Choose authentication method
-
AAD application: Choose AAD application
-
User: Choose user if user impersonation method was specified earlier
-
Number of retries: Select the number of retries that will be done to attempt for a succesfull execution
-
Delay (seconds): Specify the delay in seconds for starting a new attempt for executing a failed job
-
Pause job when exception occurs: Select if you want to pause (put the job on hold) when the job was not able to execute succesfully (incl. the retries)
-
Recurrence: Define simple recurrence trigger when job should run or complex Cron expression based trigger that provide tremendously scheduling flexibility. For example – expression “0 0 12 * * ?” indicates run at 12pm (noon) every day. Extensive list of expressions and how to define these are provided as part of Quartz.NET documentation
Click Add to Schedule to add job to list of scheduled jobs.
Import job

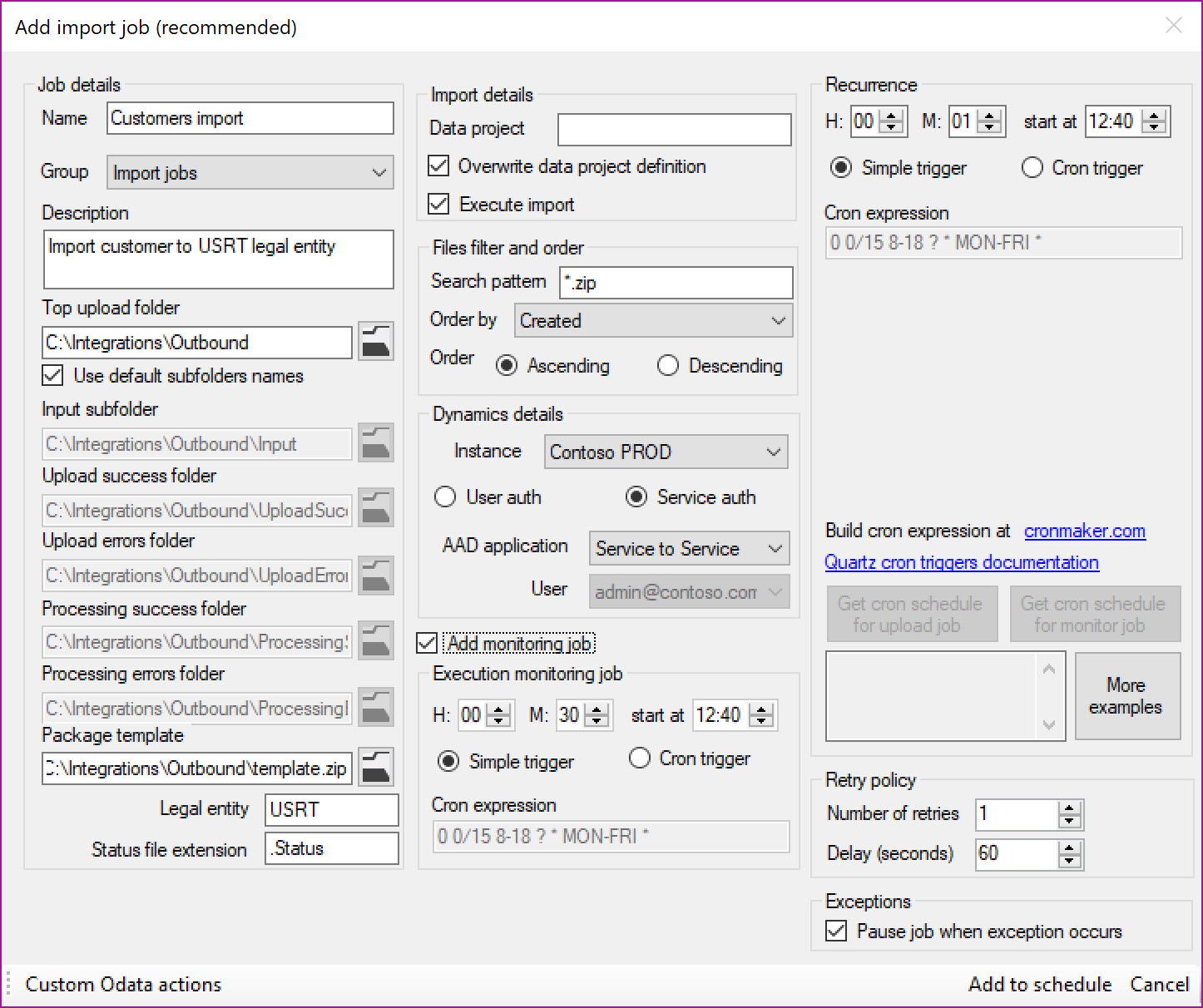
-
Name: Provide a meaningful name for the job
-
Group: Grouping defined in the parameters form for categorization
-
Description: An optional description
-
Top upload folder: Specify the root folder for subfolders used to move uploaded files. Use default subfolder names uses the folder names specified in the Parameters form for subfolder paths
-
Input folder: Folder where files are stored initially
-
Upload success folder: Files are moved to this folder after upload was successful
-
Upload errors folder: Files are moved to this folder when there was an error during upload
-
Processing success folder: Files are moved to this folder when Execution monitor job is enabled and when import status is successful
-
Processing errors folder: Files are moved to this folder when Execution monitor job is enabled and when import status is not successful
-
Package template: Path to package template file (zip archive). When it specified then the import job will zip source files from Input folder into package template “envelope”. Package template (manifest file in it) needs to be in sync with input file format and content. When this field is empty then it is assumed that files in Input folder are already data packages
-
Legal entity: Target legal entity to which data should be imported
-
Status file extension: Enabled when Add monitoring option is selected. Specifies extension of text file that will contain execution status details for Execution monitor job
-
Data project: Data project name in D365FO. If it does not exist it will be created based on information in manifest file inside package template. If it exists it will be overwritten if Overwrite data project definition is selected, otherwise import will fail
-
Execute import: Flag that specifies if import should be executed, if not selected then file will be uploaded, data project saved, but data will not be imported
-
File Filter and Order: File Filter provides an option to define wildcard pattern for imported files. Order by provides an option to define the order in which the files should be uploaded when there are multiple input files. “Created” provides an option to process file based on created date time. “Modified” provides an option to use modified data time. “FileName” uses filename as an order sequence. “Size” uses the file size as an order sequence. The options “asc” or “desc” can be used along with Order by to define the sequence desired.
Note! Files in all subfolders of input folder will be scanned and sorted
-
Instance: Specify the D365FO Instance to connect
-
User auth or Service auth: Choose authentication method
-
AAD application: Choose AAD application
-
User: Choose user if user impersonation method was specified earlier
-
Recurrence: Define simple recurrence trigger when job should run or complex Cron expression based trigger that provide tremendously scheduling flexibility. For example – expression “0 0 12 * * ?” indicates run at 12pm (noon) every day. Extensive list of expressions and how to define these are provided as part of Quartz.NET documentation
-
Number of retries: Select the number of retries that will be done to attempt for a succesfull execution
-
Delay (seconds): Specify the delay in seconds for starting a new attempt for executing a failed job
-
Pause job when exception occurs: Select if you want to pause (put the job on hold) when the job was not able to execute succesfully (incl. the retries)
Click Add to Schedule to add job to list of scheduled jobs.
Note! You can create a data package from template file with only one data entity input file inside. Data projects with multiple data entities can only be used if you create your data package outside of RIS.
Execution monitor job

When enabled execution monitor job will scan Successful uploads folder looking for files with extension specified in Status file extension field on Import job configuration form. It will then query D365FO for the status of an execution id. Based on the response, the input file will be moved to the Processing success or Processing errors folder. The third option is that the file was not yet processed, and it will stay in Successful uploads folder waiting for next run of execution monitor job.
After a file is moved another request is sent to D365FO. In response D365FO sends URL to execution summary page. It is saved as internet shortcut in the same folder as input file.
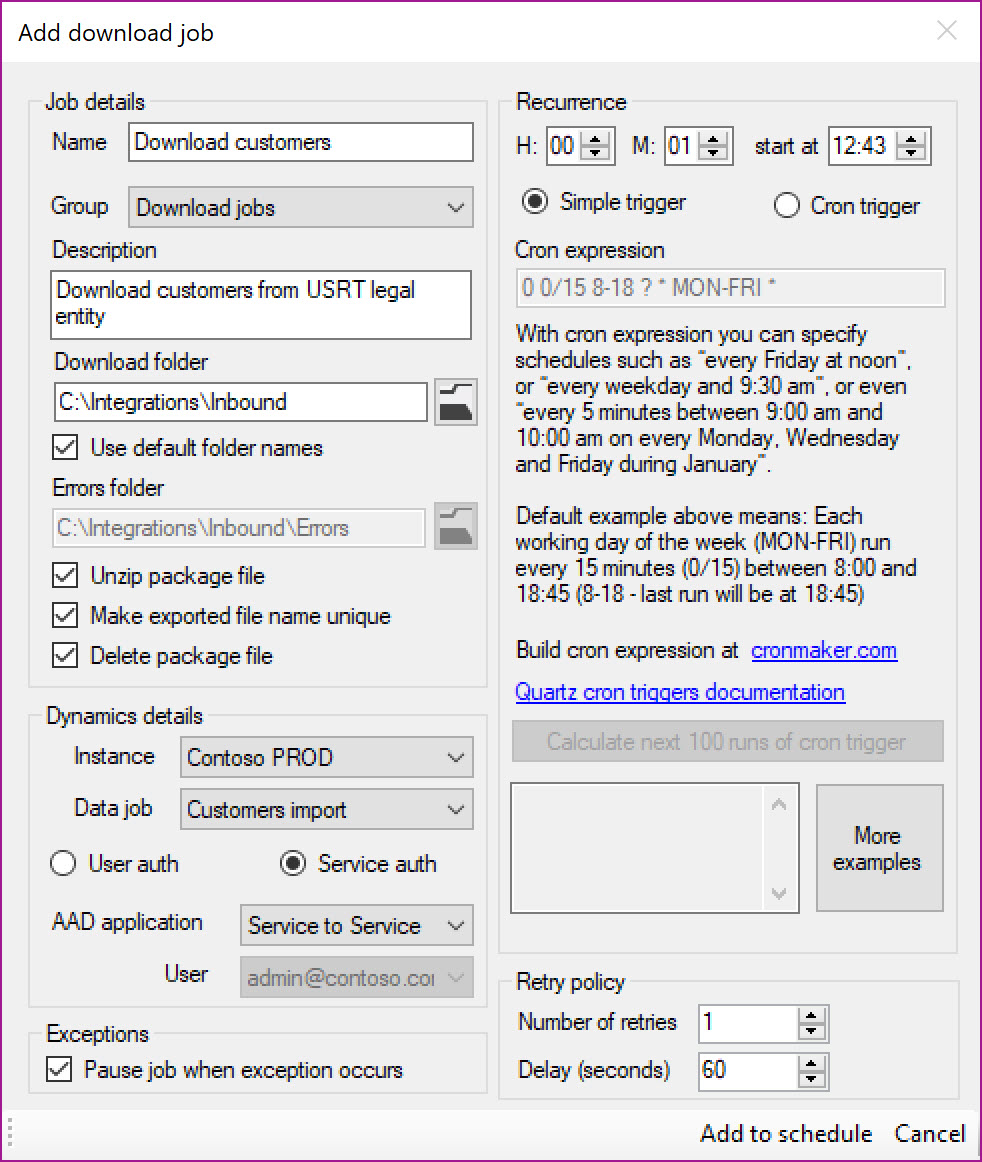
Download job

-
Name: Provide a meaningful name for the job
-
Group: Grouping defined in the parameters form for categorization
-
Description: An optional description
-
Download folder: Specify the path where data package needs to be saved after download from D365FO instance. Use default folder names uses the folder names specified in the Parameters form for sub folder paths
-
Errors folder: Error file will be written to this folder if there are any errors in integration
-
Unzip package file: Choose this option if you want data package to be automatically extracted
-
Make exported file name unique: Scheduler will add the timestamp to the exported file name if this option is chosen
-
Delete package file: The package file is deleted post extraction if this option is chosen
-
Instance: Specify the D365FO Instance to connect
-
Data job: Data job definition entry specified on Parameters form. Contains Activity Guid of target data job
-
User auth or Service auth: Choose authentication method
-
AAD application: Choose AAD application
-
User: Choose user if user impersonation method was specified earlier
-
Recurrence: Define simple recurrence trigger when job should run or complex Cron expression based trigger that provide tremendously scheduling flexibility. For example – expression “0 0 12 * * ?” indicates run at 12pm (noon) every day. Extensive list of expressions and how to define these are provided as part of Quartz.NET documentation
-
Number of retries: Select the number of retries that will be done to attempt for a succesfull execution
-
Delay (seconds): Specify teh delay in seconds for starting a new attempt for executing a failed job
-
Pause job when exception occurs: Select if you want to pause (put the job on hold) when the job was not able to execute succesfully (incl. the retries)
Click Add to Schedule to add job to list of scheduled jobs.
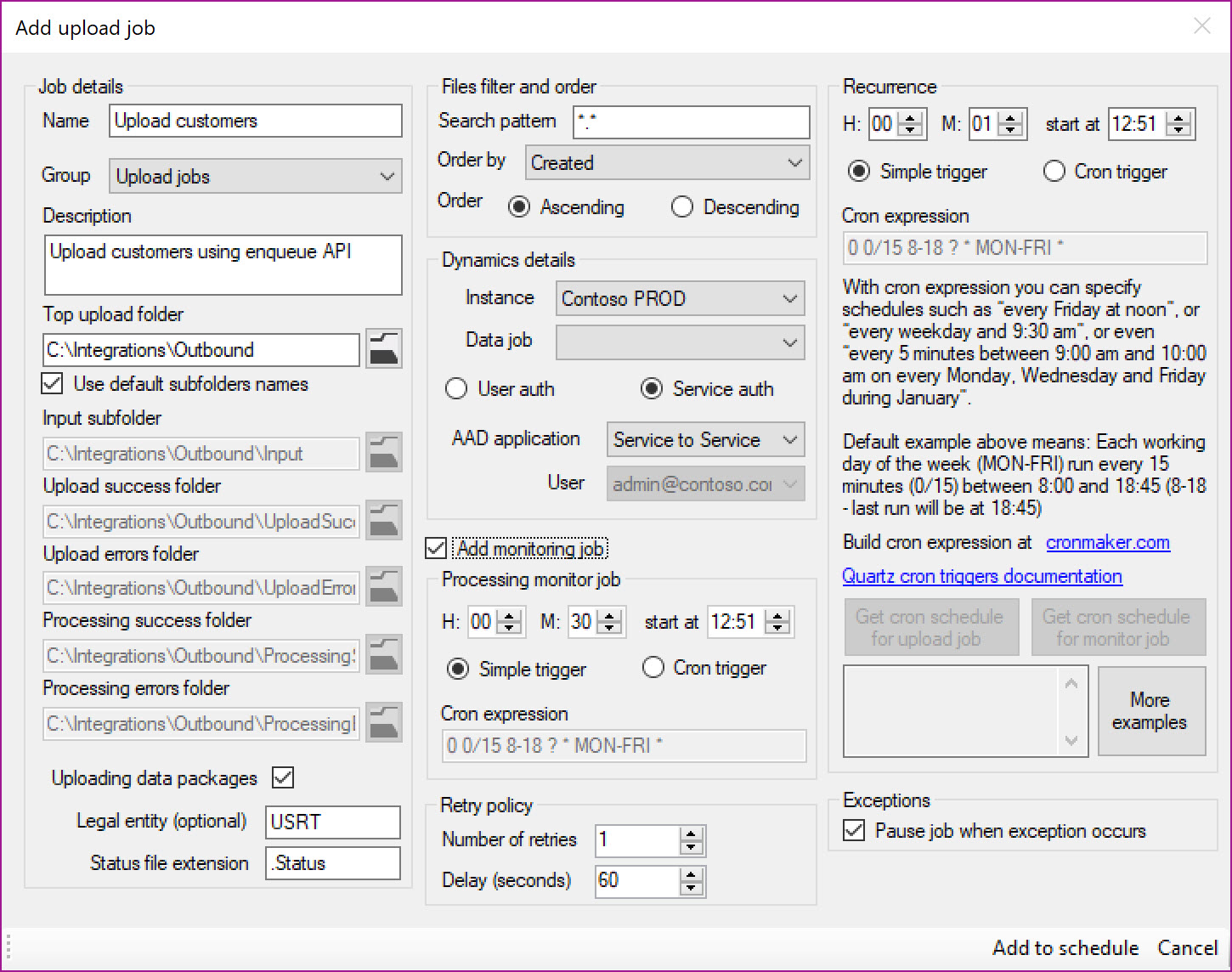
Upload Job

-
Name: Provide a meaningful name for the job
-
Group: Grouping defined in the parameters form for categorization
-
Description: An optional description
-
Top upload folder: Specify the root folder for subfolders used to move uploaded files. Use default subfolder names uses the folder names specified in the Parameters form for subfolder paths
-
Input folder: Folder where files are stored initially
-
Upload success folder: Files are moved to this folder after upload was successful
-
Upload errors folder: Files are moved to this folder when there was an error during upload
-
Processing success folder: Files are moved to this folder when Processing monitor job is enabled and when import status is successful
-
Processing errors folder: Files are moved to this folder when Processing monitor job is enabled and when import status is not successful
-
Uploading data packages: Flag that specifies if uploaded files are data packages
-
Legal entity (optional): Target legal entity to which data should be imported. If not specified, then data will be imported to legal entity in which batch job associated with data job was configured
-
Status file extension: Enabled when Add monitoring option is selected. Specifies extension of text file that will contain processing status details for Processing monitor job
-
File Filter and Order: File Filter provides an option to define wildcard pattern for imported files. Order by provides an option to define the order in which the files should be uploaded when there are multiple input files. “Created” provides an option to process file based on created date time. “Modified” provides an option to use modified data time. “FileName” uses filename as an order sequence. “Size” uses the file size as an order sequence. The options “asc” or “desc” can be used along with Order by to define the sequence desired.
Note! Files in all subfolders of input folder will be scanned and sorted
-
Instance: Specify the D365FO Instance to connect
-
Data job: Data job definition entry specified on Parameters form. Contains Activity Guid of target data job and data entity name
-
User auth or Service auth: Choose authentication method
-
AAD application: Choose AAD application
-
User: Choose user if user impersonation method was specified earlier
-
Recurrence: Define simple recurrence trigger when job should run or complex Cron expression based trigger that provide tremendously scheduling flexibility. For example – expression “0 0 12 * * ?” indicates run at 12pm (noon) every day. Extensive list of expressions and how to define these are provided as part of Quartz.NET documentation
-
Number of retries: Select the number of retries that will be done to attempt for a succesfull execution
-
Delay (seconds): Specify teh delay in seconds for starting a new attempt for executing a failed job
-
Pause job when exception occurs: Select if you want to pause (put the job on hold) when the job was not able to execute succesfully (incl. the retries)
Click Add to Schedule to add job to list of scheduled jobs.
Processing monitor job

When enabled processing monitor job will scan Successful uploads folder looking for files with extension specified in Status file extension field on Upload job configuration form. It will then query D365FO for status of message id. Based on the response, the input file will be moved to the Processing success or Processing errors folder. The third option is that file was not yet processed, and it will stay in Successful uploads folder waiting for next run of processing monitor job.
Schedule.xml file
When the scheduler service is used then jobs configuration needs to be saved in the Schedule.xml file in installation folder. Application will prompt you when any change was made to the schedule and file needs to be saved. Standalone scheduler keeps its schedule in memory and does not use schedule file.

Job management
Delete job
Delete job will remove the selected job from the schedule processed by the scheduler.
Edit job
Edit job can be used to edit selected job from the schedule and modify it settings.
Note! When you change setting on Parameters form this change will not be updated in job settings. You need to edit it and select new or updated setting (in example AAD application entry with updated secret key)**
Pause and Resume Job
Pause job can be used to pause selected job from the schedule and running it at the scheduled frequency. Resume job is used to restart the job that has been paused. Once the job is resumed, it will restart the run from that point of time, but it will respect trigger recurrence.
Pause all will pause all the jobs defined in the schedule and all of them will not run. Resume all will resume all the paused jobs and put them back on schedule. They will run again based on the frequency defined.
Refresh Grid
Refreshes information on the main grid. You can see last time when job was run and next planned trigger. Grid does not refresh automatically. Use F5 keyboard shortcut for fastest refresh.
Filters
It is possible to filter the grid by instance name or job name. Enter searched string in one of the two textboxes in bottom left part of the main form.
Logging
Recurring Integrations Scheduler logs its events to Event Log. Dedicated log can be found in Application and Services Logs section of Event Viewer.
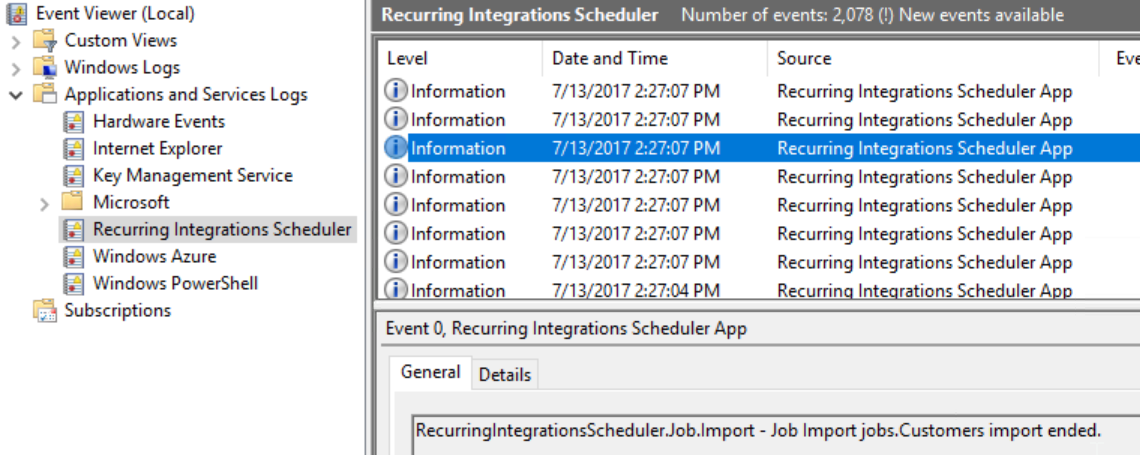
By default, Recurring Integrations Scheduler logs only errors and limited amount of information events. Log level can be changed to more explicit when additional information is logged for tracing purpose.
References
Quartz.NET - Quartz.NET is a full-featured, open source job scheduling system that can be used from smallest apps to large scale enterprise systems and Recurring Integrations Scheduler is using it.