2.7 KiB
Executable File
Self-Supervised Document Similarity Ranking (SDR) via Contextualized Language Models and Hierarchical Inference
This repo is the implementation for SDR.
Tested environment
- Python 3.7
- PyTorch 1.7
- CUDA 11.0
Lower CUDA and PyTorch versions should work as well.
Contents
License, Security, support and code of conduct specifications are under the Instructions directory.
Installation
Run
bash instructions/installation.sh
Datasets
The published datasets are:
- Video games
- 21,935 articles
- Expert annotated test set. 90 articles with 12 ground-truth recommendations.
- Examples:
- Grand Theft Auto - Mafia
- Burnout Paradise - Forza Horizon 3
- Wines
- 1635 articles
- Crafted by a human sommelier, 92 articles with ~10 ground-truth recommendations.
- Examples:
- Pinot Meunier - Chardonnay
- Dom Pérignon - Moët & Chandon
For more details and direct download see Wines and Video Games.
Training
The training process downloads the datasets automatically.
python train_doc_sim.py --dataset_name video_games
The code is based on PyTorch-Lightning, all PL hyperparameters are supported. (limit_train/val/test_batches, check_val_every_n_epoch etc.)
Tensorboard support
All metrics are being logged automatically and stored in
SDR/output/document_similarity/SDR/arch_SDR/dataset_name_<dataset>/<time_of_run>
Run tesnroboard --logdir=<path> to see the the logs.
Inference
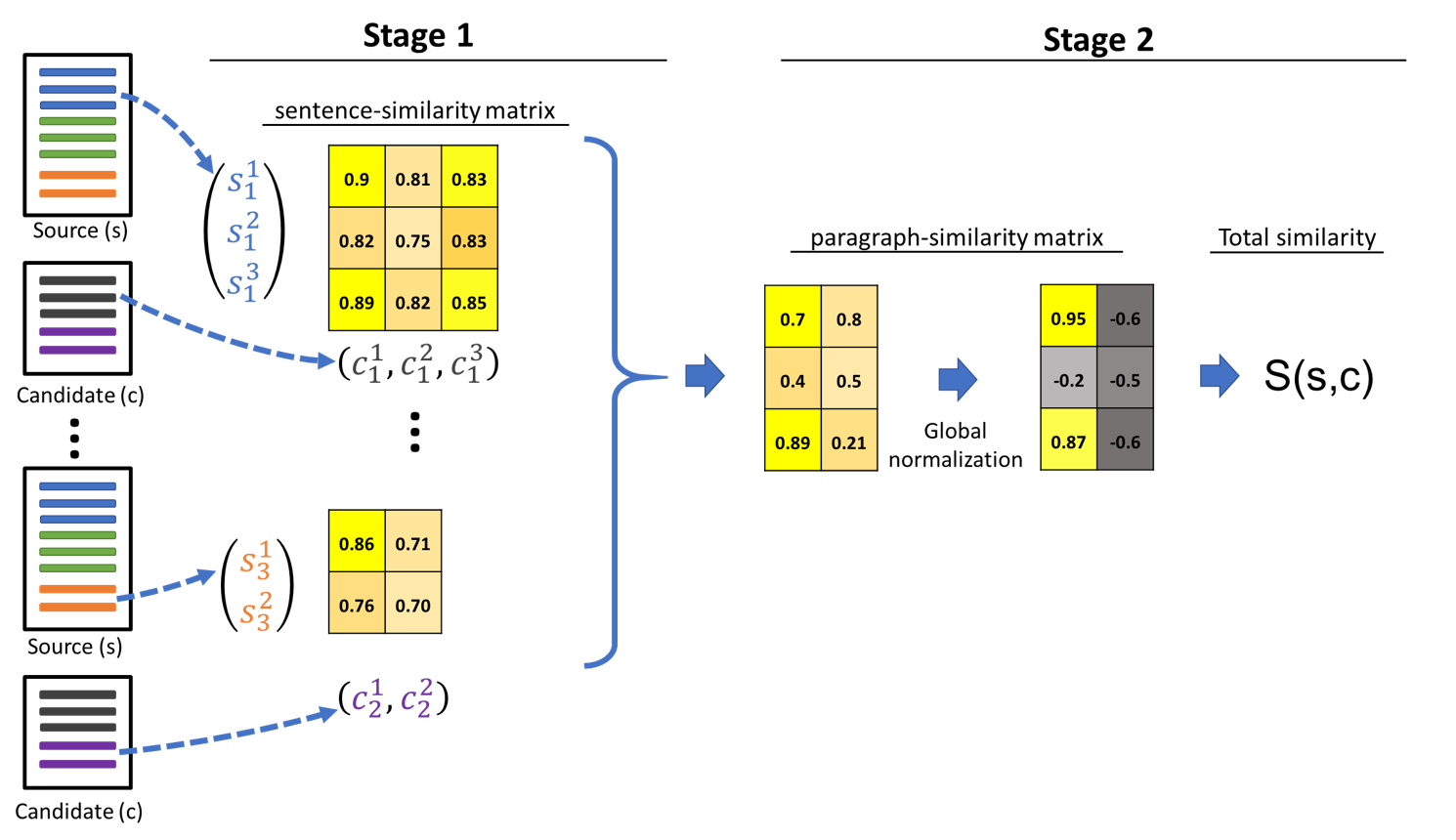
The hierarchical inference described in the paper is implemented as a stand-alone service and can be used with any backbone algorithm (models/reco/hierarchical_reco.py).
python train_doc_sim.py --dataset_name <name> --resume_from_checkpoint <checkpoint> --test_only
Results

Citing & Authors
If you find this repository or the annotated datasets helpful, feel free to cite our publication -
SDR: Self-Supervised Document-to-Document Similarity Ranking viaContextualized Language Models and Hierarchical Inference
Link will be uploaded soon!
Contact person: Dvir Ginzburg