Users/sam/docs refactoring |
||
|---|---|---|
| .devcontainer | ||
| docs | ||
| src | ||
| .gitignore | ||
| .pylintrc | ||
| CODE_OF_CONDUCT.md | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
| SUPPORT.md | ||
| dev.env | ||
| requirements.txt | ||
| workspace.code-workspace | ||
README.md
![]()
About this repository
This repository contains the Databricks development framework for delivering any Data Engineering projects, and machine learning projects based on the Azure Technologies.
Details of the accelerator
The accelerator contains few of the core features of Databricks development which can be extended or reused in any implementation projects with Databricks.
- Logging Framework using the Opensensus Azure Monitor Exporters
- Support for Databricks development from VS Code IDE using the Databricks Connect feature.
- continuous development with Python Local Packaging
- Implementation of the Databricks utilities in VS Code such as dbutils, notebook execution, secret handling.
- Example Model file which uses the framework end to end.
Prerequisites
To successfully complete your solution, you will need to have access to and or provisioned the following:
- Access to an Azure subscription
- Service Principal (valid Client ID and secret ) which has the contributor permission the subscription. We are going to create the resource group using the service principal.
- VS Code installed.
- Docker Desktop Installed.
Create the Service Principal
- Instruction to create the service principal
- Instruction to assign role to the service principal access over the Subscription. Please provide contributor access over the subscription.
- Instruction to Get application ID and tenant ID for the application you registered
- Instruction to create application secret. The application Secret is needed at the later part of this setup. Please copy the value and store it in a notepad for now.
Getting Started
The below sections provide the step by step approach to set up the solution. As part of this solution, we need the following resources to be provisioned in a resource group.
- Azure Databricks
- Application Insight Instance.
- A log analytics workspace for the App Insight.
- Azure Key Vault to store the secrets.
- A Storage Account.
Section 1: Docker image load in VS Code

- Clone the Repository : https://github.com/microsoft/dstoolkit-ml-ops-for-databricks/pulls
- Install Docker Desktop. In this solution, the Visual Code uses the docker image as a remote container to run the solution.
- Create .env file in the root folder, and keep the file blank for now. (root folder is the parent folder of the project)
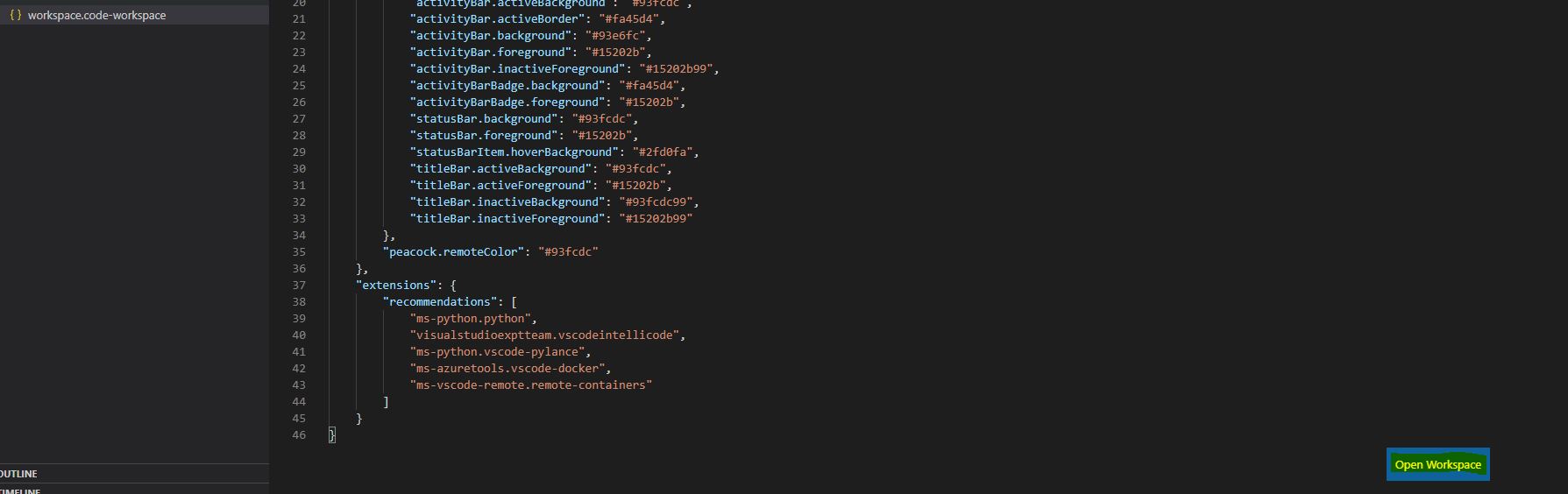
- In the repo, open the workspace. File: workspace.ode-workspace.
Once you click the file, you will get the "Open Workspace" button at right bottom corner in the code editor. Click it to open the solution into the vscode workspace.
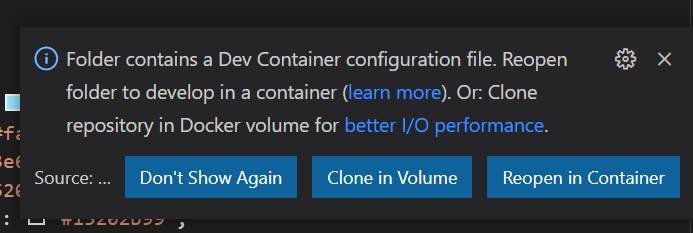
- We need to connect to the docker image as remote container in vs code. In the code repository, we have ./.devcontainer folder that has required docker image file and docker configuration file. Once we load the repo in the vscode, we generally get the prompt. Select "Reopen in Container". Otherwise we can go to the VS code command palette ( ctrl+shift+P in windows), and select the option "Remote-Containers: Rebuild and Reopen in Containers"
- In the background, it is going to build a docker image. We need to wait for sometime to complete build. the docker image will basically contain the a linux environment which has python 3.7 installed. Please have a look at the configuration file(.devcontainer\devcontainer.json) for more details.
- Once it is loaded. we will be able to see the python interpreter is loaded successfully. Incase it does not show, we need to load the interpreter manually. To do that, click on the select python interpreter => Entire workspace => /usr/local/bin/python

- You will be prompted with installing the required extension on the right bottom corner. Install the extensions by clicking on the prompts.
- Once the steps are completed, you should be able to see the python extensions as below:
Section 2: Databricks environment creation

The objectives of this section are:
-
Create the required resources.
- Azure Databricks
- Application Insight Instance.
- A log analytics workspace for the App Insight.
- Azure Key Vault to store the secrets.
- A Storage Account.
-
Create the .env file for the local development.
You don't need to create the environment again if you already had a databricks environment. You can directly create the .env file ( Section 4 ) with the details of your environment.
- Go to src/setup/config/setup_config.json, and complete the json files with the values; according to your environment. The service principal should be having the contributor access over the subscription you are using. Or if you choose to create the resource group manually, or reuse an existing resource group, then it should have the contributor access on the resource group itself.
These details would be used to connect to the Azure Subscription for the resource creation.
{
"applicationID":"deeadfb5-27xxxaad3-9fd39049b450",
"tenantID":"72f988bf-8xxxxx2d7cd011db47",
"subscriptionID":"89c37dd8xxxx-1cfb98c0262e",
"resourceGroupName":"AccleratorDBKMLOps2",
"resourceGroupLocation":"NorthEurope"
}
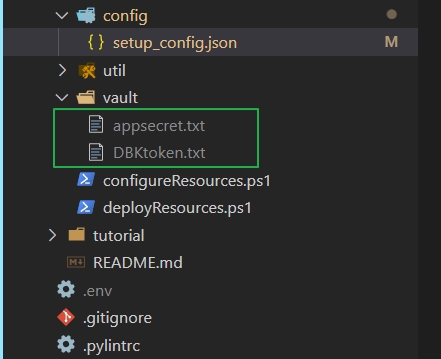
- create the file and provide the client ID secret in this file : src/setup/vault/appsecret.txt
Incase you are not able to create the file from the solution, you can directly go to the file explorer to create the file.
NOTE: DBToken.txt will be created in the later section, please ignore it for now.
At the end of the secret files creation, the folder structure will like below:
- Open the Powershell ISE in your local machine. We are going to run the Powershell script to create the required resources. The name of the resources are basically having a prefix to the resourcegroup name.
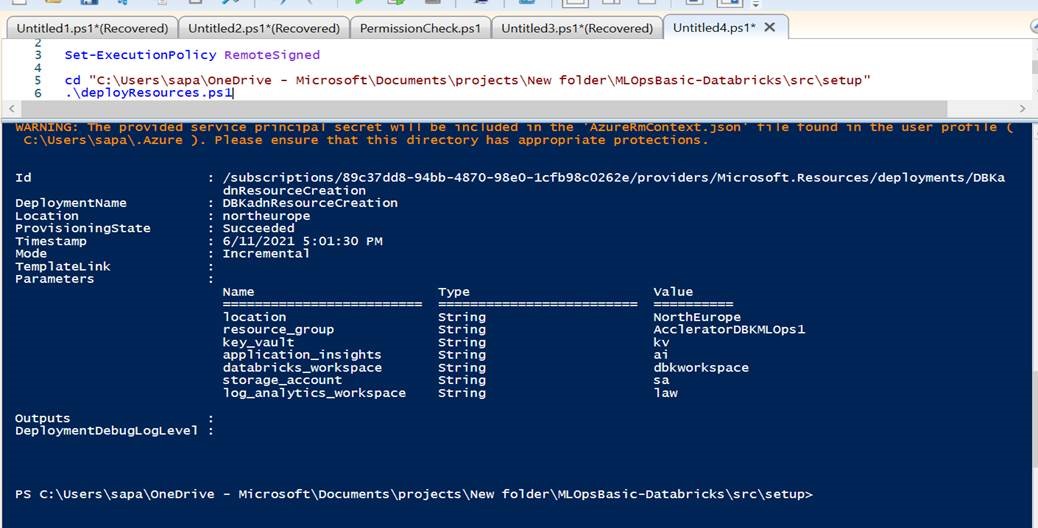
- set the root path of the Powershell terminal till setup, and execute the deployResource.ps1
cd "C:\Users\projects\New folder\MLOpsBasic-Databricks\src\setup"
.\deployResources.ps1
If you receive the below error, execute the command [Set-ExecutionPolicy RemoteSigned]
>.\deployResources.ps1 : File C:\Users\projects\New
folder\MLOpsBasic-Databricks\src\setup\deployResources.ps1 cannot be loaded because running scripts is disabled on this.
if you get the error module is not found, and if Powershell ISE is not able to recognize any specific Powershell command, then Install the Powershell Az Module. Instructions
Install-Module Az
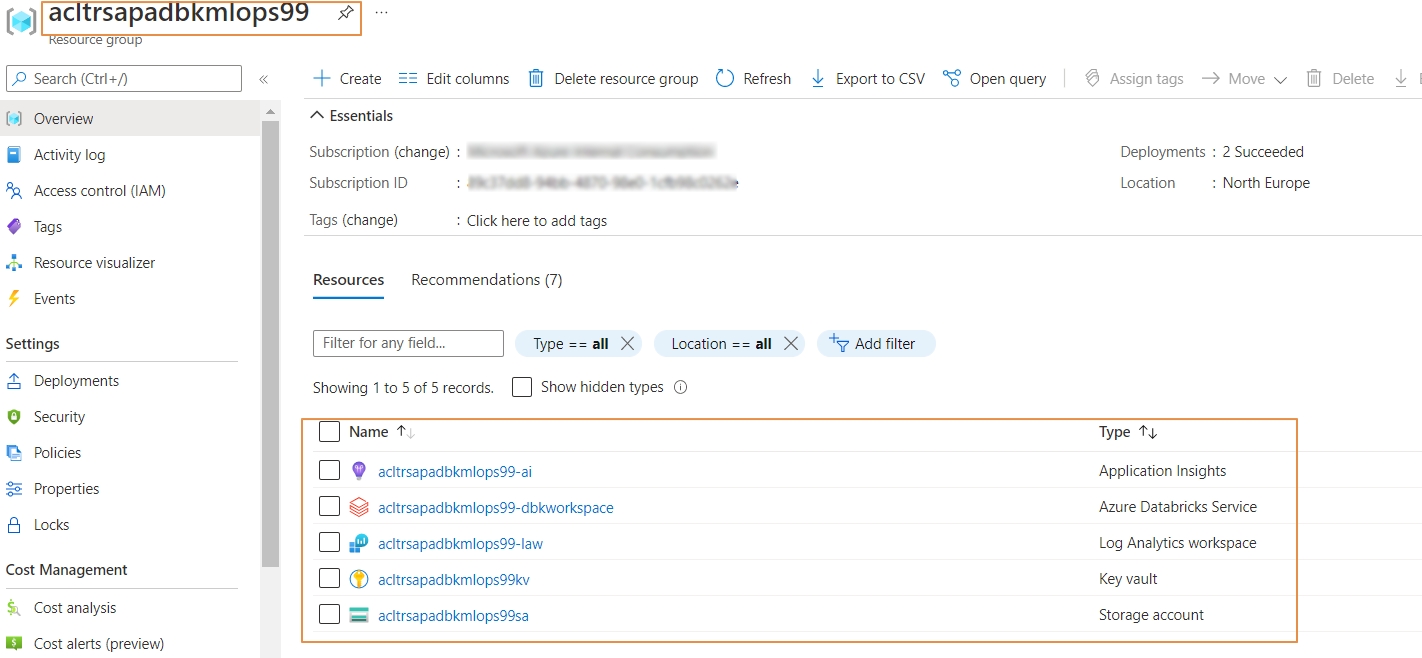
Post successful execution of the script, we can see the resources created successfully in the Azure Subscription.
Section 3: Databricks cluster creation

- To create the databricks cluster we need to have personal Access token created. Go to the Databricks workspace, and get the personal access token from the user setting, and save it in the file src/setup/vault/DBKtoken.txt
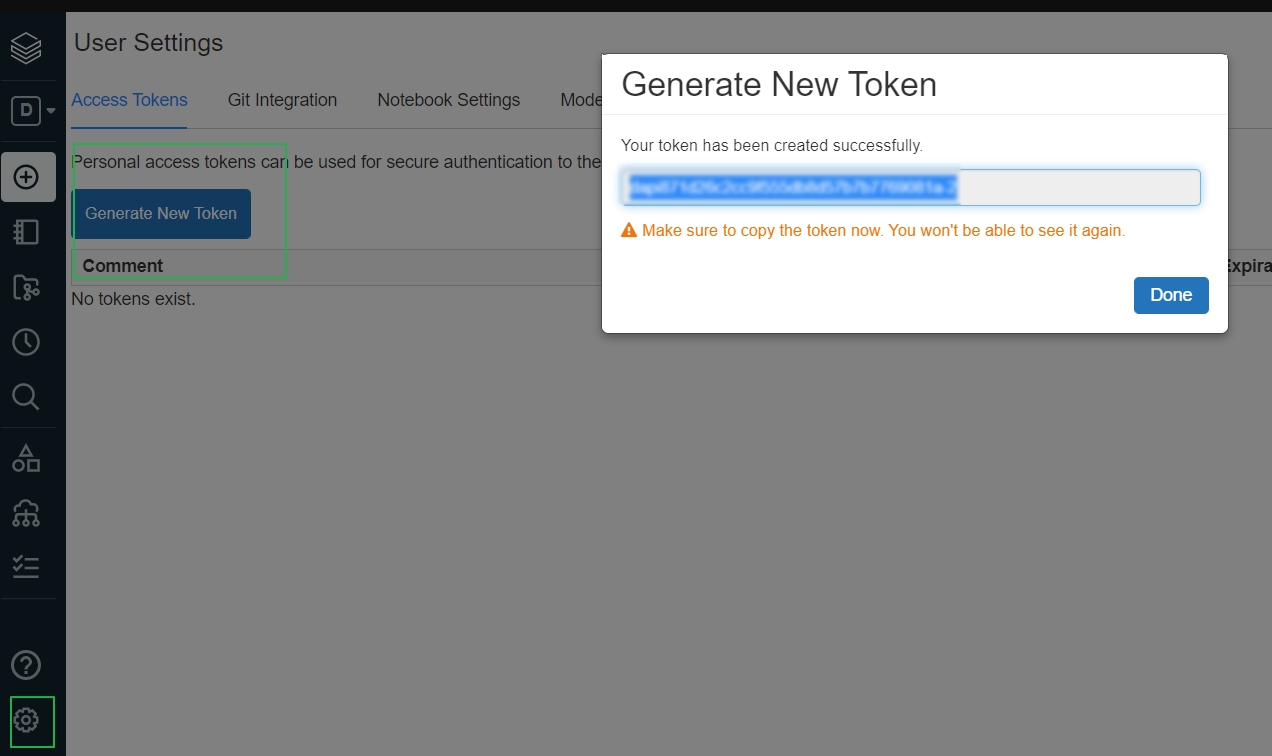
- Run the following command
cd "C:\Users\projects\New folder\MLOpsBasic-Databricks\src\setup"
.\configureResources.ps1
- At the end of the script execution, we will be able to see the databricks cluster has been created successfully.the config file: src\setup\util\DBCluster-Configuration.json is being used to create the cluster.
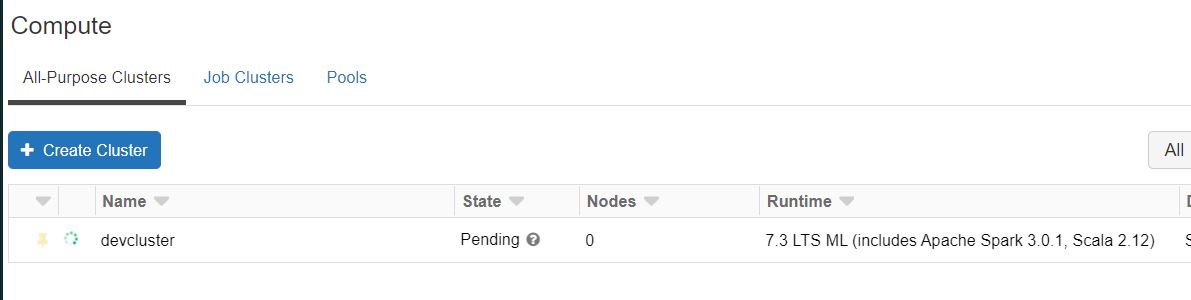
- Copy the output of the script and paste it to the .env file which we had created previously. Please note that the values of the variables will be different as per your environment configuration. the later section (Section 4) describes the creation of .env file in detail.

Section 4: Create the .env file

We need to manually change the databricks host and appI_IK values. Other values should be "as is" from the output of the previous script.
- PYTHONPATH: /workspaces/dstoolkit-ml-ops-for-databricks/src/modules [This is full path to the module folder in the repository.]
- APPI_IK: connection string of the application insight
- DATABRICKS_HOST: The URL of the databricks workspace.
- DATABRICKS_TOKEN: Databricks Personal Access Token which was generated in the previous step.
- DATABRICKS_ORDGID: OrgID of the databricks that can be fetched from the databricks URL.

Application Insight Connection String

At the end, our .env file is going to look as below. You can copy the content and change the values according to your environment.
PYTHONPATH=/workspaces/dstoolkit-ml-ops-for-databricks/src/modules
APPI_IK=InstrumentationKey=e6221ea6xxxxxxf-8a0985a1502f;IngestionEndpoint=https://northeurope-2.in.applicationinsights.azure.com/
DATABRICKS_HOST=https://adb-7936878321001673.13.azuredatabricks.net
DATABRICKS_TOKEN= <Provide the secret>
DATABRICKS_ORDGID=7936878321001673
Section 5: Configure the Databricks connect

- In this step we are going to configure the databricks connect for VS code to connect to databricks. Run the below command for that from the docker (VS Code) terminal.
$ python "src/tutorial/scripts/local_config.py" -c "src/tutorial/cluster_config.json"
Note: If you get any error saying that "ModelNotFound : No module names dbkcore". Try to reload the VS code window and see if you are getting prompt right bottom corner saying that configuration file changes, rebuild the docker image. Rebuild it and then reload the window. Post that you would not be getting any error. Also, check if the python interpreter is being selected properly. They python interpreter path should be **/usr/local/bin/python **

Verify
- You will be able to see the message All tests passed.
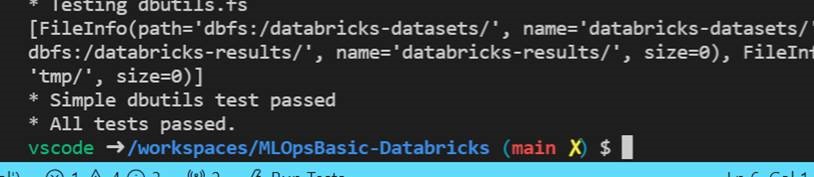
Section 6: Wheel creation and workspace upload

In this section, we will create the private python package and upload it to the databricks environment.
- Run the below command:
python src/tutorial/scripts/install_dbkframework.py -c "src/tutorial/cluster_config.json"
Post Execution of the script, we will be able to see the module to be installed.
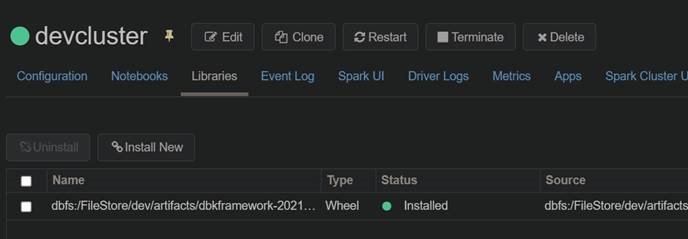
Section 7: Using the framework

We have a pipeline that performs the data preparation, unit testing, logging, training of the model.
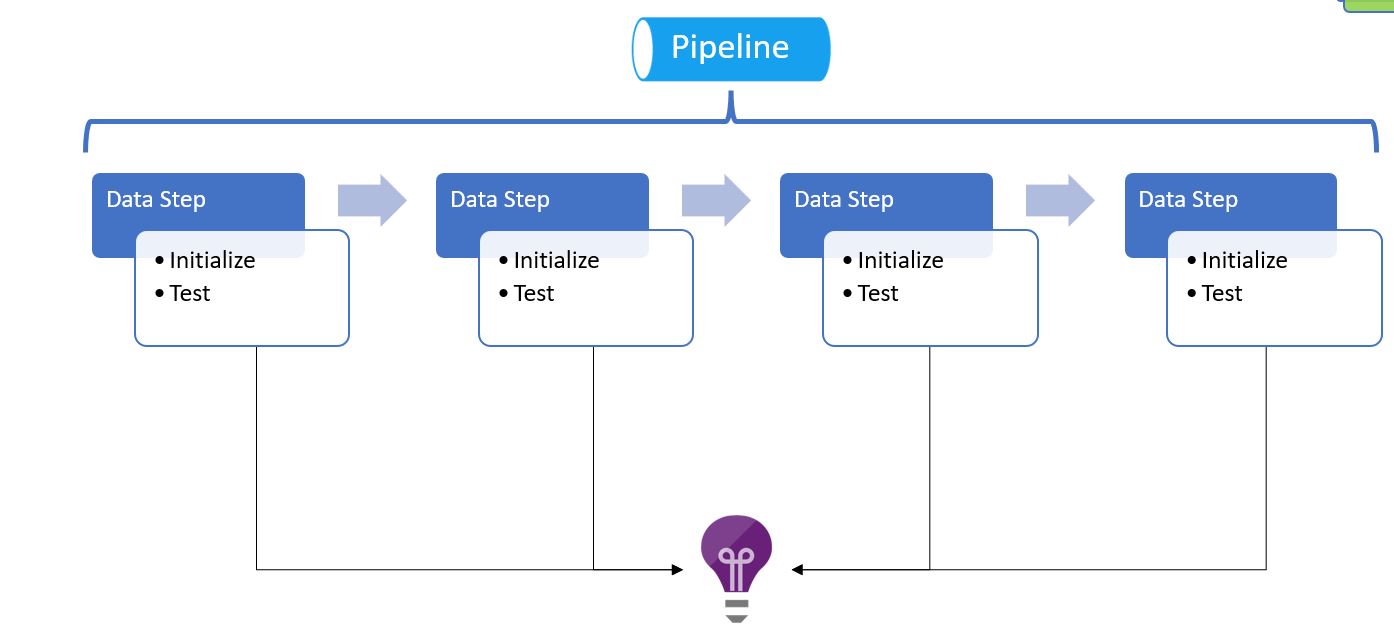
Execution from Local VS Code
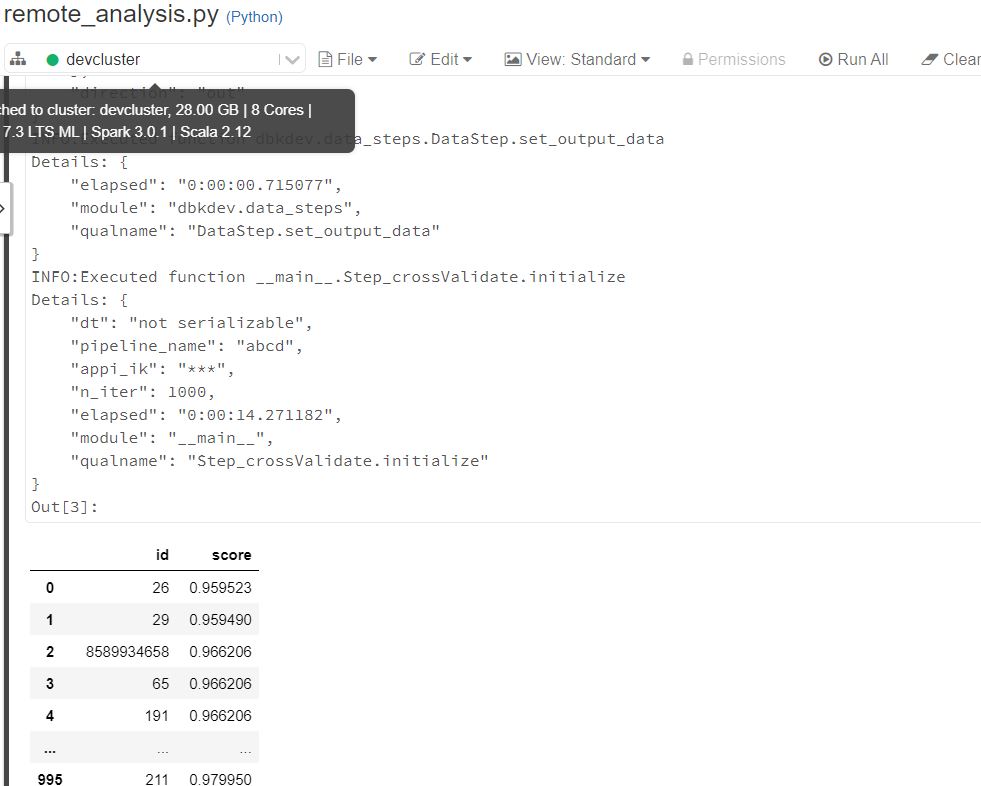
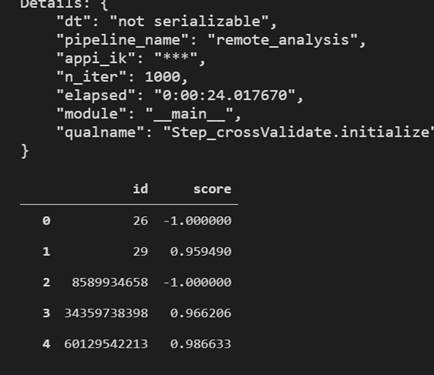
To check if the framework is working fine or not, let's execute this file : src/tutorial/scripts/framework_testing/remote_analysis.py . It is better to execute is using the interactive window. As the Interactive window can show the pandas dataframe which is the output of the script. Otherwise the script can be executed from the Terminal as well. To run the script from the interactive window, select the whole script => right click => run the selection in the interactive window.
Post running the script, we will be able to see the data in the terminal.
Execution from Databricks
In order to run the same notebook in the databricks, we just need to create a databricks secrets for the application insight connection string.
For this, we can execute the below query:
python src/tutorial/create_databricks_secrets.py
After copying the content of the remote_analysis.py in the databricks notebook, we get the output as below: