Add Mozilla Code of Conduct |
||
|---|---|---|
| _locales/en | ||
| dist | ||
| icons | ||
| .gitignore | ||
| CODE_OF_CONDUCT.md | ||
| LICENSE | ||
| README.md | ||
| background.js | ||
| content.js | ||
| manifest.json | ||
| package-lock.json | ||
| package.json | ||
README.md
Bubo Eye Extension
Bubo Eye is an accessibility extension that allows screen reader users to click on an image and obtain the text content of that image. It is not a description of the image but the actual text content within the image that was previously inaccessible to screen reader users. Think of memes, comics, diagrams and any photos with superimposed text on them as part of the image, this is content non-sighted users are unable to access.

Typically the text in this image would not be accessible to a screen reader and therefore to its user. Bubo Eye allows you to obtain the image text on demand by right clicking on the image to be scanned and passing the text into the reassigned alt attribute. Image scanning is done with the use of Tesseract.js, a JavaScript library that has been around for several years and initially developed by HP.
Scanning accuracy is not 100%. There are multiple variables within the image itself that diminish the accuracy of the scanning, poorest accuracy is seen with memes and images that contain significant "noise" around the text portion of the image. Best results, highest accuracy is seen with images or screenshots of text; images with the text on a white background and similar cases where the text within the image is unobstructed. Training of tesseract is possible to increase accuracy and this will be the next step in making this extension more helpful to the user.
How to use Extension
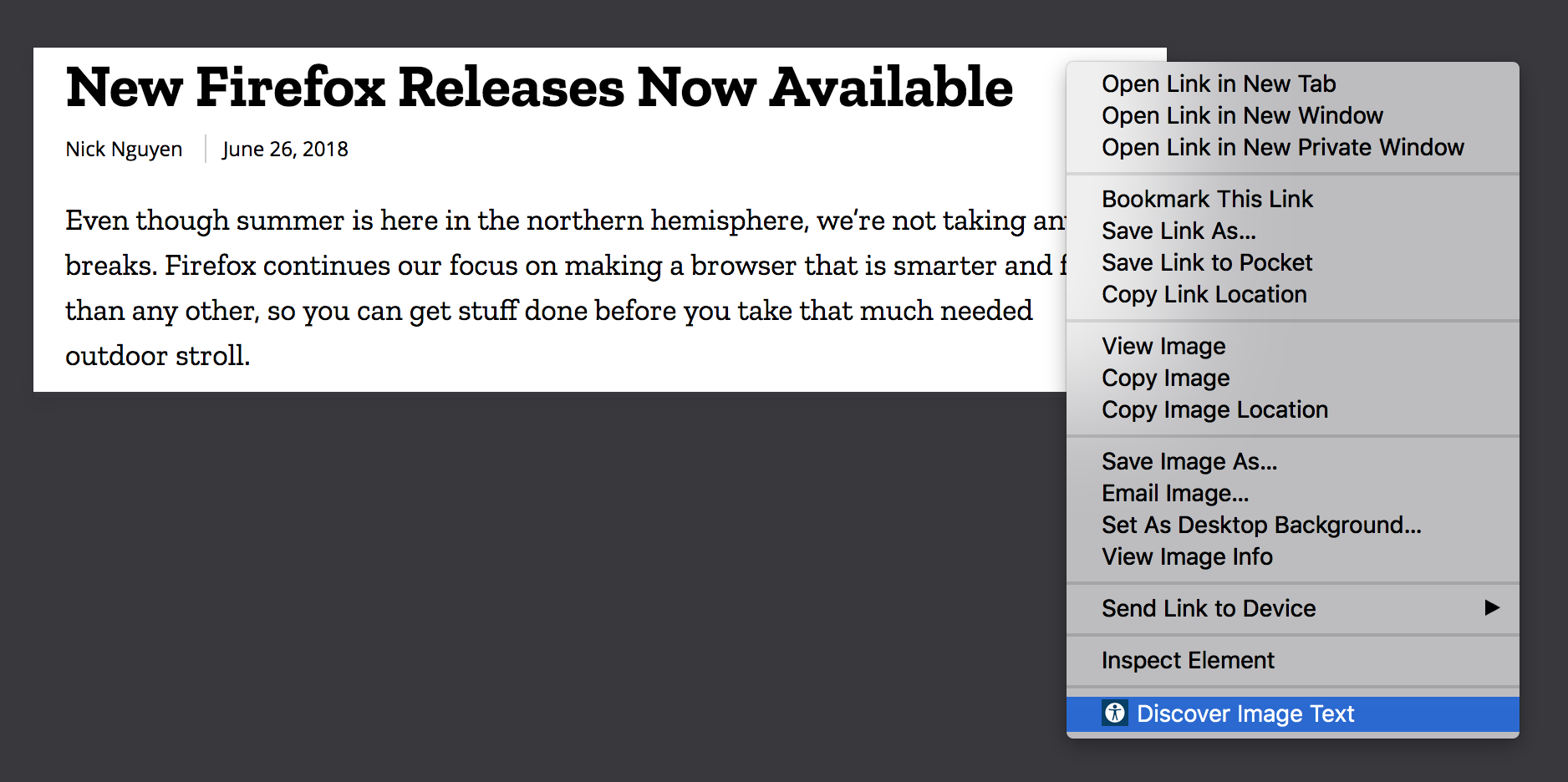 Once the extension is installed, right click on the image you want to scan. The Bubo Eye icon and "Discover Image Text" option will show at the bottom of the context menu.
Once the extension is installed, right click on the image you want to scan. The Bubo Eye icon and "Discover Image Text" option will show at the bottom of the context menu.
 Prior to scanning and clicking "Discover Image Text" you can see the img alt attribute is empty. The attribute will be reassigned and scanned text will be injected there.
Prior to scanning and clicking "Discover Image Text" you can see the img alt attribute is empty. The attribute will be reassigned and scanned text will be injected there.
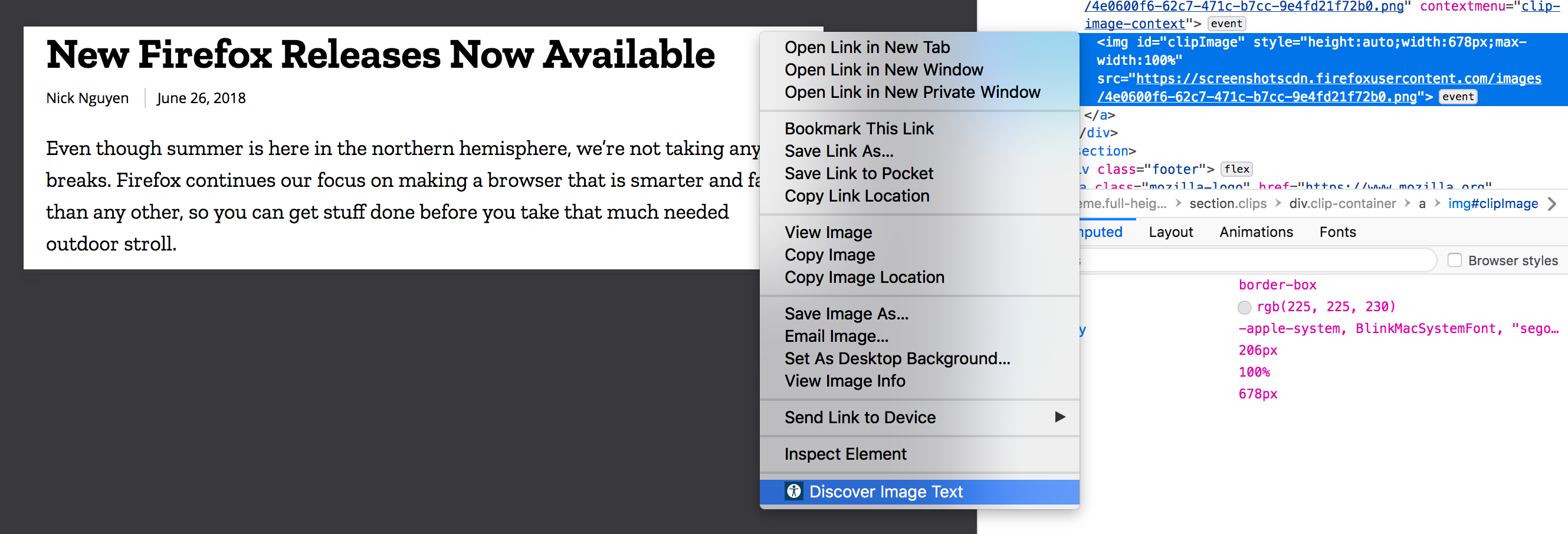 With inspector still open (which is not needed during regular use), alt attribute still empty, right click and "Discover Image Text".
With inspector still open (which is not needed during regular use), alt attribute still empty, right click and "Discover Image Text".
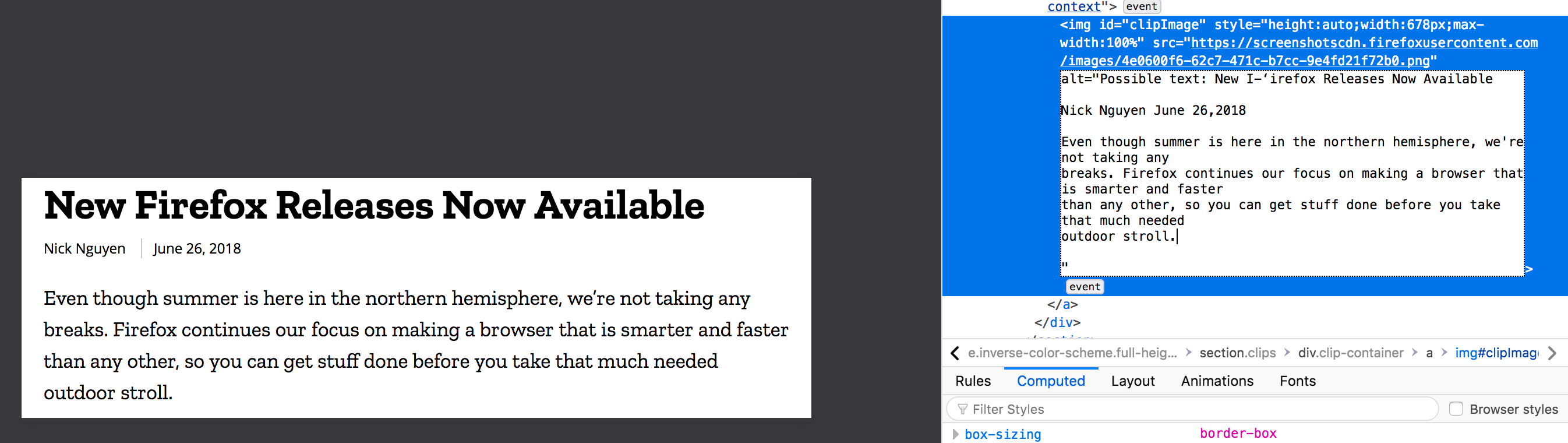 Image has been scanned and the alt attribute now has text from image. Alt attribute text always starts with "Possible text:" due to the potential inaccuracies mentioned above.
Image has been scanned and the alt attribute now has text from image. Alt attribute text always starts with "Possible text:" due to the potential inaccuracies mentioned above.