4.4 KiB
- Feature Name: Terminology Presentation
- Created: 2020-03-24
- Associated Bug: https://bugzilla.mozilla.org/show_bug.cgi?id=1624557
Summary
Terminology is a group of specialized words, compound words or multi-word expressions (terms) relating to a particular field. This feature adds the ability to store such terms in Pontoon, identify them in original strings and present them in the translation workbench.
Motivation
- Improving translation consistency: it’s hard to expect all authors to always use the same translations for the same words and phrases without any help from the tool.
- Speeding up translation process: localizers need to manually search for existing translations of terms found in the strings they are translating.
- Fixing brand translations: trademarks present a special case for localization as they have legal and semantic significance, which isn't always obvious to localizers.
- Advancing content comprehension: it's not always clear what the (standard) expression means, especially if the comment isn't provided.
Out of scope
- Terminology creation: the ability to manually add, remove and review terms.
- Terminology translation: the ability to manually add, remove and review term translations.
- VCS integration: the ability to sync terminology with VCS.
- Checks: the ability to check if translations include term translations.
Feature explanation
As the first step, we need the ability to store terms in the database. Data model should allow for importing terms stored in a TBX file and the initial Mozilla term list.
The following information needs to be saved for each term:
- term itself
- review status (new, review, approved, obsolete)
- part of speech (verb, noun, adjective, adverb)
- definition
- usage example
- notes for term managers
- case sensitive (boolean, used when finding terms in strings)
- exact match (boolean, used when finding terms in strings)
- do not translate (boolean, used when translating terms)
- forbidden (boolean, note for developers)
- term translations (separate table)
Next, we need to identify stored terms in any original string used in translation workbench. We should take into account that terms can take various grammatical forms when used in strings, so simple if term in string isn't enough. As it turned out in our previous attempt, stemming yields false positives (e.g "extension" matches "extensibility") and singularization yields false negatives (because e.g. "curricula" results in "curricula"), so we should't use them. See the Algorithm section for more details.
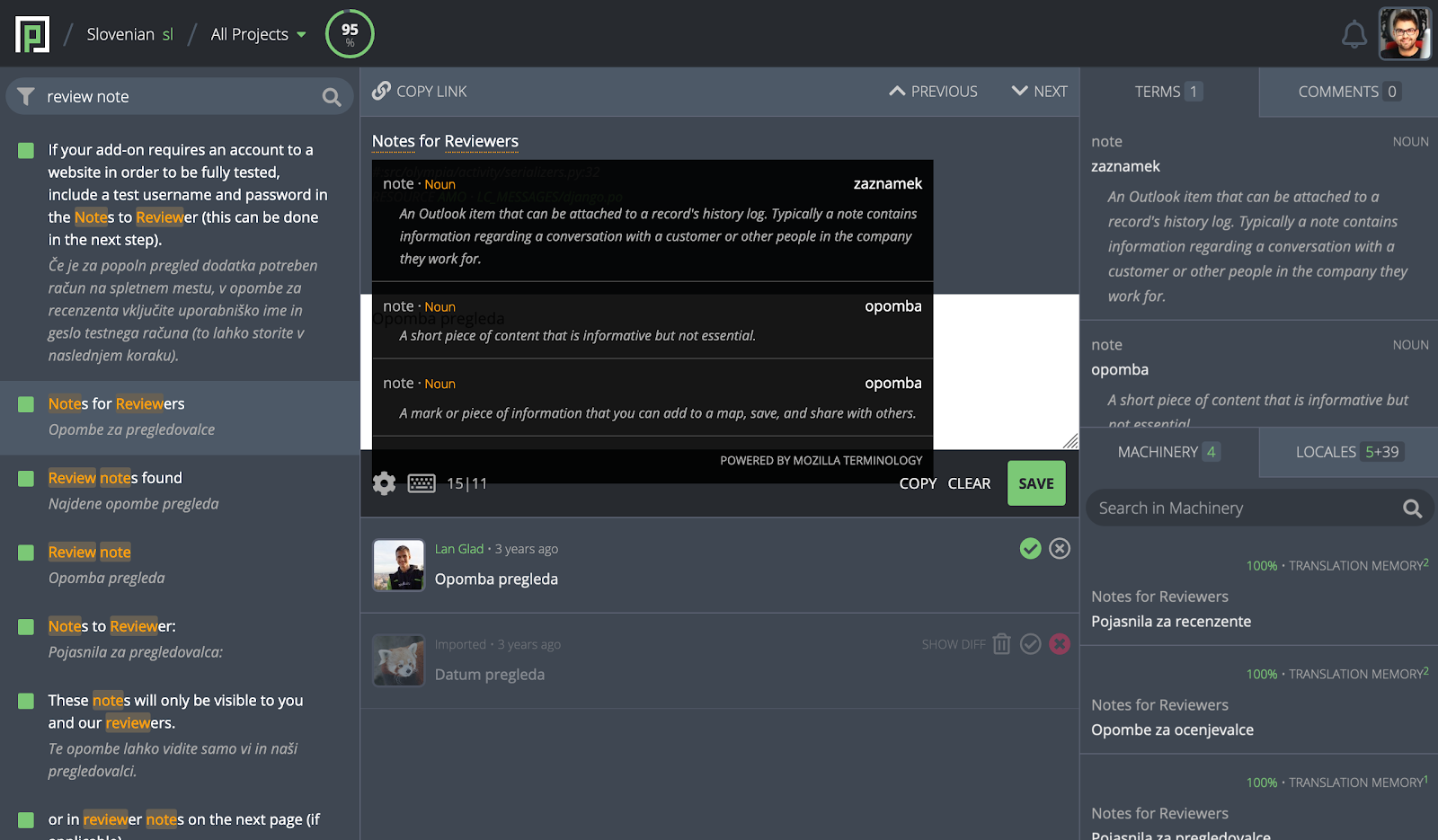
Terms should be highlighted in the original string, similarly to how we highlight placeables. On term hover, a popup should appear with a list of matching terms and the corresponding metadata (part of speech, definition, translation). On click, translation of the first term in the list (if exists) should be inserted into the editor.
Additionally, we could also introduce the Terms panel in the 3rd column with the contents of the term popups of the entire string always visbile. On click, translation of the clicked term (if exists) should be inserted into the editor. Since this 3rd column is getting crowded with tabs, we should either split it vertically (as shown in the mockup) or (at least on narrow screens) replace tab titles with icons.
Algorithm
The following combination of tokenization and substring matching correctly identifies terms in their usage examples within the initial Mozilla term list, so let's build the algorithm to find terms in a string around this logic:
create a list of source string words using nltk.word_tokenize()
for each term:
if term.exact_match == True:
if exact match of the term exists in source string:
collect term
else:
if term.case_sensitive == False:
set re.IGNORECASE flag for the regexes
for each source string word:
if term is a match or substring of the word:
collect term
The algorithm need to be further improved to also supports multi-word terms.
Mockup