5
Local Tutorial Tag Aggregate to metrics
Dinesh Chandnani редактировал(а) эту страницу 2019-04-15 17:28:29 -07:00
In the previous tutorial we saw how to Tag streaming data when certain conditions are met. In this tutorial you will learn how you can set up rules to tag the data based on aggregate values without writing any code.
Steps to follow
- Open your flow
- Let's use a more rich event schema for this tutorial, the one used in HomeAutomationLocal, also shown below. Copy the schema to your flow, and delete any existing queries from the Query tab.
{
"type": "struct",
"fields": [
{
"name": "deviceDetails",
"type": {
"type": "struct",
"fields": [
{
"name": "deviceId",
"type": "long",
"nullable": false,
"metadata": {
"allowedValues": [
1,
2,
3,
4,
5,
6
]
}
},
{
"name": "deviceType",
"type": "string",
"nullable": false,
"metadata": {
"allowedValues": [
"DoorLock",
"WindowLock",
"Heating"
]
}
},
{
"name": "eventTime",
"type": "long",
"nullable": false,
"metadata": {
"useCurrentTimeMillis": true
}
},
{
"name": "homeId",
"type": "long",
"nullable": false,
"metadata": {
"allowedValues": [
32,
150,
25,
81
]
}
},
{
"name": "status",
"type": "long",
"nullable": false,
"metadata": {
"allowedValues": [
0,
1
]
}
}
]
},
"nullable": false,
"metadata": {}
}
]
}
- Switch to Rules tab and click on "+ Add | Tag Rule" button:

- With Sub type set to 'Aggregate' and Target table set to 'DataXProcessedInput' (which is the default input table), provide a description of the rule and add a Tag value. Any message/event satisfying the condition will be tagged with the value provided for Tag.
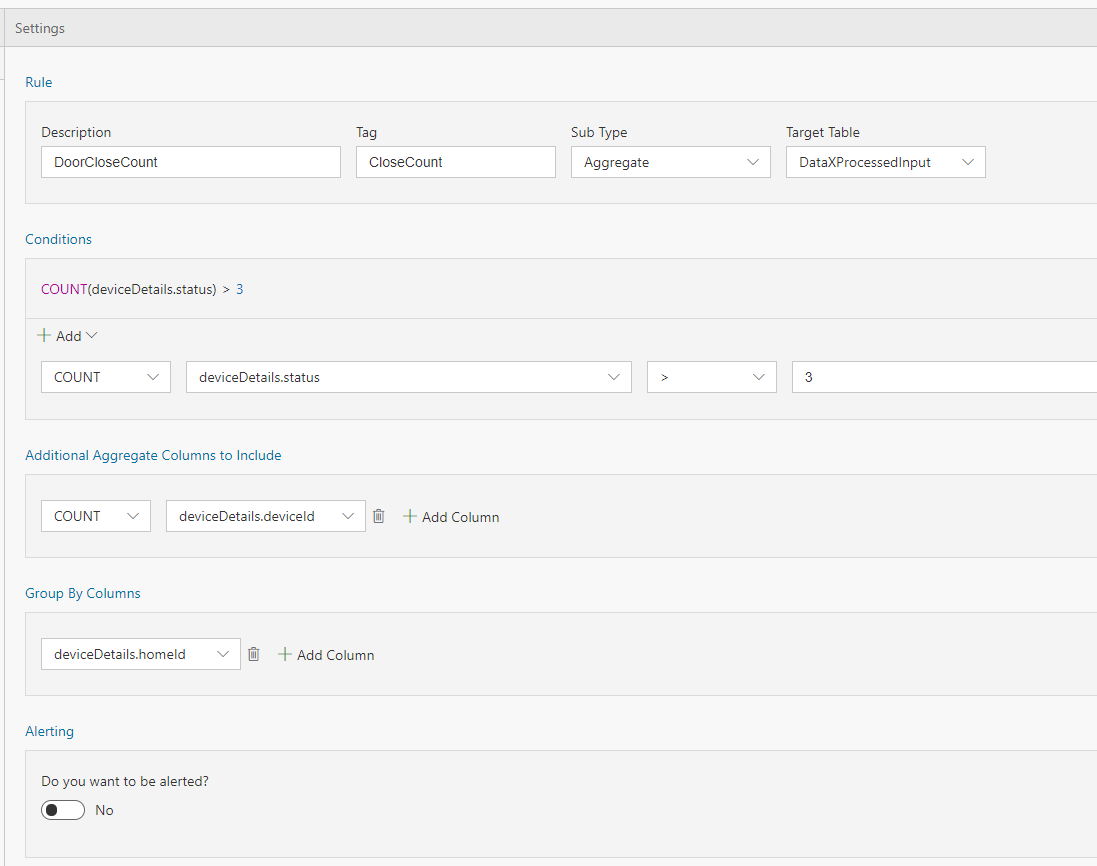
- Use the intuitive UI to set up the condition for tagging as shown above. For this example, the data ingested is home automation data. Anytime more than 3 devices are locked in a house, the data is tagged with "DoorLocked". A new column 'Tag' will be aded to the data with this information. Note, deviceDetails.status of 1 means locked, 0 means unlocked.
- In the Query tab, call ProcessAggregateRules() API and route the data to your desired output sink.
--DataXQuery--
T2 = ProcessAggregateRules(DataXProcessedInput);
OUTPUT T2 TO myOutput;
- Click Deploy
T2 will now contain the DataXProcessedInput data, along with tags from the rule set in this Flow.
- Click "Deploy" button. That's it! You have now created an aggregate rule for tagging that will be output to disk.

View the data
You can view the tagged data flowing in the location as defined in the previous tutorial.